1-认识网络爬虫
1.什么是网络爬虫
网络爬虫(Web Crawler)又称网络蜘蛛、网络机器人,它是一种按照一定规则,自动浏览万维网的程序或脚本。通俗地讲,网络爬虫就是一个模拟真人浏览万维网行为的程序,这个程序可以代替真人自动请求万维网,并接收从万维网返回的数据。与真人浏览万维网相比,网络爬虫能够浏览的信息量更大,效率也更高。
2.网络爬虫分类
网络爬虫历经几十年的发展,技术变得更加多样化,并结合不同的需求衍生出类型众多的网络爬虫。网络爬虫按照系统结构和实现技术大致可以分为4种类型,分别是通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。
2.1.通用网络爬虫
通用网络爬虫(General Purpose Web Crawler)又称全网爬虫(Scalable Web Crawler),是指访问全互联网资源的网络爬虫。通用网络爬虫是“互联网时代”早期出现的传统网络爬虫,它是搜索引擎(如百度、谷歌、雅虎等)抓取系统的重要组成部分,主要用于将互联网中的网页下载到本地,形成一个互联网内容的镜像备份。
2.2聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)又称主题网络爬虫(Topical Crawler),是指有选择性地访问那些与预定主题相关网页的网络爬虫,它根据预先定义好的目标,有选择性地访问与目标主题相关的网页,获取所需要的数据。
与通用网络爬虫相比,聚焦网络爬虫只需要访问与预定主题相关的网页,这不仅减少了访问和保存的页面数量,而且提高了网页的更新速度,可见,聚焦网络爬虫在一定程度度节省了网络资源,能满足一些特定人群采集特定领域数据的需求。
2.3增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是指对已下载的网页采取增量式更新,只抓取新产生或者已经发生变化的网页的网络爬虫。
增量式网络爬虫只会抓取新产生的或内容变化的网页,并不会重新抓取内容未发生变化的网页,这样可以有效地减少网页的下载量,减少访问时间和存储空间的耗费,但是增加了网页抓取算法的复杂度和实现难度。
2.4深层网络爬虫
深层网络爬虫(Deep Web Crawler)是指抓取深层网页的网络爬虫,它要抓取的网页层次比较深,需要通过一定的附加策略才能够自动抓取,实现难度较大。
3.网络爬虫的应用场景
随着互联网信息的“爆炸”,网络爬虫渐渐为人们所熟知,并被应用到了社会生活的众多领域。作为一种自动采集网页数据的技术,很多人其实并不清楚网络爬虫具体能应用到什么场景。事实上,大多数依赖数据支撑的应用场景都离不开网络爬虫,包括搜索引擎、舆情分析与监测、聚合平台、出行类软件等。
搜索引擎:是通用网络爬虫最重要的应用场景之一,它会将网络爬虫作为最基础的部分——互联网信息的采集器,让网络爬虫自动到互联网中抓取数据。例如,谷歌、百度、必应等搜索引擎都是利用网络爬虫技术从互联网上采集海量的数据。
舆情分析与检测:政府或企业通过网络爬虫技术自动采集论坛评论、在线博客、新闻媒体或微博等网站中的海量数据,采用数据挖掘的相关方法(如词频统计、文本情感计算、主题识别等)发掘舆情热点,跟踪目标话题,并根据一定的标准采取相应的舆情控制与引导措施。例如,百度热点排行榜、微博热搜排行榜。
聚合平台:如今出现的很多聚合平台,如返利网、慢慢买等,也是网络爬虫技术的常见的应用场景,这些平台就是运用网络爬虫技术对一些电商平台上的商品信息进行采集,将所有的商品信息放到自己的平台上展示,并提供横向数据的比较,帮助用户寻找实惠的商品价格。例如,用户在慢慢买平台搜索华为智能手表后,平台上展示了很多款华为智能手表的价格分析及价格走势等信息。
**出行类软件:**出行类软件,比如飞猪、携程、去哪儿等,也是网络爬虫应用比较多的场景。这类应用运用网络爬虫技术,不断地访问交通出行的官方售票网站刷新余票,一旦发现有新的余票便会通知用户付款买票。不过,官方售票网站并不欢迎网络爬虫的这种行为,因为高频率地访问网页极易造成网站出现瘫痪的情况。
3.网络爬虫合法性
网络爬虫在访问网站时,需要遵循“有礼貌”的原则,这样才能与更多的网站建立友好关系。即便如此,网络爬虫的爬行行为仍会给网站增加不小的压力,严重时甚至可能会影响网站的正常访问。为了约束网络爬虫的恶意行为,网站内部加入了一些防爬虫措施来阻止网络爬虫。与此同时,网络爬虫也研究了防爬虫措施的应对策略。
3.1Robots协议
Robots协议又称爬虫协议,它是国际互联网界通行的道德规范,用于保护网站数据和敏感信息,确保网站用户的个人信息和隐私不受侵犯。为了让网络爬虫了解网站的访问范围,网站管理员通常会在网站的根目录下放置一个符合Robots协议的robots.txt文件,通过这个文件告知网络爬虫在抓取该网站时存在哪些限制,哪些网页是允许被抓取的,哪些网页是禁止被抓取的。
当网络爬虫访问网站时,应先检查该网站的根目录下是否存在robots.txt文件。若robots.txt文件不存在,则网络爬虫会访问该网站上所有被口令保护的页面;若robots.txt文件存在,则网络爬虫会按照该文件的内容确定访问网站的范围。
robots.txt文件中的内容有着一套通用的写作规范。下面以豆瓣网站根目录下的robots.txt文件为例,分析robots.txt文件的语法规则。
User-agent: *
Disallow: /subject_search
...
Disallow: /share/
Allow: /ads.txt
Sitemap: https://www.douban.com/sitemap_index.xml
Sitemap: https://www.douban.com/sitemap_updated_index.xml
# Crawl-delay: 5
User-agent: Wandoujia Spider
Disallow: /
User-agent: Mediapartners-Google
...
lUser-agent:用于指定网络爬虫的名称。若该选项的值为“**”,则说明robots.txt文件对任何网络爬虫均有效。带有“*”号的User-agent选项只能出现一次。例如,示例的第一条语句User-agent: *。
lDisallow:用于指定网络爬虫禁止访问的目录。若Disallow选项的内容为空,说明网站的任何内容都是被允许访问的。在robots.txt文件中,至少要有一个包含Disallow选项的语句。例如,Disallow: /subject_search禁止网络爬虫访问目录/subject_search。
lAllow:用于指定网络爬虫允许访问的目录。例如,Allow: /ads.txt表示允许网络爬虫访问目录/ads.txt。
lSitemap:用于告知网络爬虫网站地图的路径。例如,Sitemap: https://www.douban.com/sitemap_index.xml和https://www.douban.com/sitemap_updated_index.xml这两个路径都是网站地图,主要说明网站更新时间、更新频率、网址重要程度等信息。
Robots协议只是一个网站与网络爬虫之间达成的**“君子”协议**,它并不是计算机中的防火墙**,没有实际的约束力**。如果把网站比作私人花园,那么robots.txt文件便是私人花园门口的告示牌,这个告示牌上写有是否可以进入花园,以及进入花园后应该遵守的规则,但告示牌并不是高高的围栏,它只对遵守协议的“君子”有用,对于违背协议的人而言并没有太大的作用。
尽管Robots协议没有一定的强制约束力,但网络爬虫仍然要遵守协议,违背协议可能会存在一定的法律风险。
3.2防爬虫应对策略
网络爬虫会采取一些应对策略继续访问网站,常见的应对策略包括添加User-Agent字段、降低访问频率、设置代理服务、识别验证码。
添加User-Agent字段:浏览器在访问网站时会携带固定的User-Agent(用户代理,用于描述浏览器的类型及版本、操作系统及版本、浏览器插件、浏览器语言等信息),向网站表明自己的真实身份。网络爬虫每次访问网站时可以模仿浏览器的上述行为,也就是在请求网页时携带User-Agent,将自己伪装成一个浏览器,如此便可以绕过网站的检测,避免出现被网站服务器直接拒绝访问的情况。
降低访问频率:如果同一账户在较短的时间内多次访问了网页,那么网站运维人员会推断此种访问行为可能是网络爬虫的行为,并将该账户加入到黑名单禁止访问网站。为防止网站运维人员从访问量上推断出网络爬虫的身份,可以降低网络爬虫访问网站的频率。不过,这种方式会降低网络爬虫的爬行效率,为了弥补这个不足,我们可以适当地调整一些操作,如让网络爬虫每抓取一次页面数据就休息几秒钟,或者限制每天抓取的页面数据的数量。
设置代理服务:网络爬虫在访问网站时,若反复使用同一IP地址进行访问,则极易被网站认出网络爬虫的身份后进行屏蔽、阻止、封禁等。此时可以在网络爬虫和Web服务器之间设置代理服务器。有了代理服务器之后,网络爬虫会先将请求发送给代理服务器,代理服务器再转发给服务器,这时服务器记录的是代理服务器的IP地址,而不是网络爬虫的IP地址。
识别验证码:有些网站在检测到某个客户端的IP地址访问次数过于频繁时,会要求该客户端进行登录验证,并随机提供一个验证码。为了应对这种突发情况,网络爬虫除了要输入正确的账户密码之外,还要像人类一样通过滑动或点击行为识别验证码,如此才能继续访问网站。由于验证码的种类较多,不同的验证码需要采用不同的技术进行识别,具有一定的技术难度。
4.网络爬虫的工作原理
4.1.通用网络爬虫的工作原理
通用网络爬虫的采集目标是整个互联网上的所有网页,它会从一个或多个初始URL开始,获取初始URL对应的网页数据,并不断从该网页数据中抽取新的URL放到队列中,直至满足一定的条件后停止。

(1)获取初始URL。既可以由用户指定,也可以由待采集的初始网页指定。
(2)抓取页面,并获得新URL。根据初始URL抓取对应的网页,之后将该网页存储到原始网页数据库中,并且在抓取网页的同时对网页内容进行解析,并从中提取出新URL。
(3)将新URL放入URL队列。有了新URL之后,我们需要将新URL放入URL队列中。
(4)读取新URL。从URL队列中读取新URL,并根据该URL获取对应网页数据,同时从新网页中抽取新的URL。
(5)是否满足停止条件。若网络爬虫满足设置的停止条件,则停止采集;若网络爬虫没有满足设置的停止条件,则继续根据新URL抓取对应的网页,并重复步骤(2)~(5)。
4.2.聚焦网络爬虫的工作原理
聚焦网络爬虫面向有特殊需求的人群,它会根据预先设定的主题顺着某个垂直领域进行抓取,而不是漫无目的地随意抓取。与通用网络爬虫相比,聚焦网络爬虫会根据一定的网页分析算法对网页进行筛选,保留与主题有关的网页链接,舍弃与主题无关的网页链接,其目的性更强。
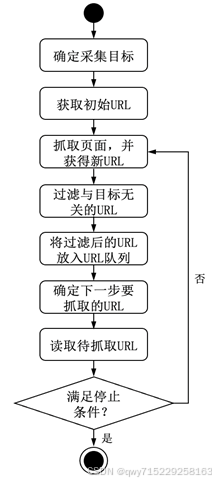
(1)根据需求确定好聚焦网络爬虫的采集目标,以及进行相关的描述。
(2)获取初始URL。
(3)根据初始URL抓取页面,并获得新URL。
(4)从新URL中过滤掉与采集目标无关的URL。
(5)将过滤后的URL放到URL队列中。
(6)根据一定的抓取策略,从URL队列中确定URL优先级,并确定下一步要抓取的URL。
(7)从下一步要抓取的URL中读取新URL,以准备根据新URL抓取下一个网页。
(8)若聚焦网络爬虫满足设置的停止条件,或没有可获取的URL时,停止采集;若网络爬虫没有满足设置的停止条件,则继续根据新URL抓取对应的网页,并重复步骤(3)~(8)。
5.网络爬虫的实现技术
5.1.网络爬虫的实现技术
为满足用户快速从网页上采集数据的需求,市面上出现了一些可视化界面的网络爬虫工具,比如八爪鱼采集器、火车头采集器等。除了直接使用这些现成的工具之外,我们也可以开发一个自己的网络爬虫。目前,开发网络爬虫的语言主要有PHP、Go、C++、Java、Python共5种。
PHP语言的优点是语法简洁,容易上手,拥有丰富的网络爬虫功能模块;缺点是对多线程的支持不太友好,需要借助扩展实现多线程技术,并发处理的能力相对较弱。
Go语言的优点是高并发能力强、开发效率高、丰富的标准库,通过Go语言开发的网络爬虫程序性能更好;缺点是普及性不高。
**C++**语言的优点是运行速度快、性能强;缺点是学习成本高、代码成型速度慢。
Java在网络爬虫方向已经形成了完善的生态圈,非常适合开发大型网络爬虫项目,但重构成本比较高。
使用Python在网络爬虫方向已经形成完善的生态圈,它拥有娇俏的多线程处理能力,但是网页解析能力不够强大。
5.2使用Python开发网络爬虫的优点
(1)语法简洁。对于同一个功能,使用Python只需要编写几十行代码,而使用Java可能需要编写几百行代码。
(2)容易上手。互联网中有很多关于Python的教学资源,便于大家学习,出现问题也很容易找到相关资料进行解决。
(3)开发效率高。网络爬虫的实现代码需要根据不同的网站内容进行局部修改,这种任务非常适合像Python这样灵活的脚本语言。
(4)模块丰富。Python提供了丰富的内置模块、第三方模块,以及成熟的网络爬虫框架,能够帮助开发人员快速实现网络爬虫的基本功能。
5.3Python网络爬虫的流程
(1)抓取网页数据:抓取网页数据是按照预先设定的目标,根据所有目标网页的URL向网站发送请求,并获得整个网页的数据。
(2)解析网页数据:解析网页数据是采用不同的解析网页的方式从整个网页的数据中提取出目标数据。
网络爬虫的基本功能。
5.3Python网络爬虫的流程
(1)抓取网页数据:抓取网页数据是按照预先设定的目标,根据所有目标网页的URL向网站发送请求,并获得整个网页的数据。
(2)解析网页数据:解析网页数据是采用不同的解析网页的方式从整个网页的数据中提取出目标数据。
(3)存储数据:存储数据的过程也是比较简单,就是将解析网页数据提取的目标数据以文件的形式存放到本地,也可以存储到数据库,方便后期对数据进行深入地研究。
相关文章:
1-认识网络爬虫
1.什么是网络爬虫 网络爬虫(Web Crawler)又称网络蜘蛛、网络机器人,它是一种按照一定规则,自动浏览万维网的程序或脚本。通俗地讲,网络爬虫就是一个模拟真人浏览万维网行为的程序,这个程序可以代替真人…...
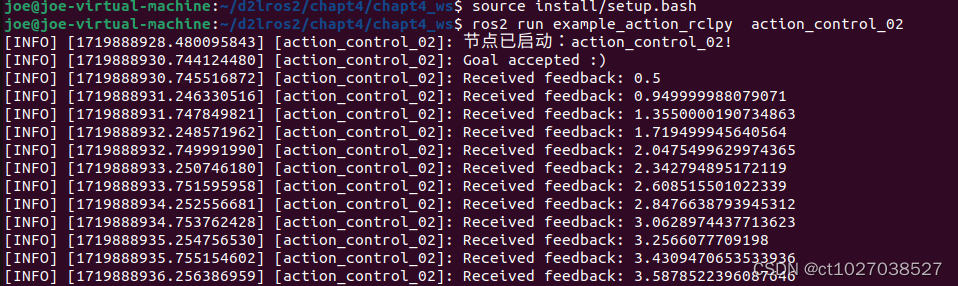
ROS2使用Python开发动作通信
1.创建接口节点 cd chapt4_ws/ ros2 pkg create robot_control_interfaces --build-type ament_cmake --destination-directory src --maintainer-name "joe" --maintainer-email "1027038527qq.com" mkdir -p src/robot_control_interfaces/action touch…...
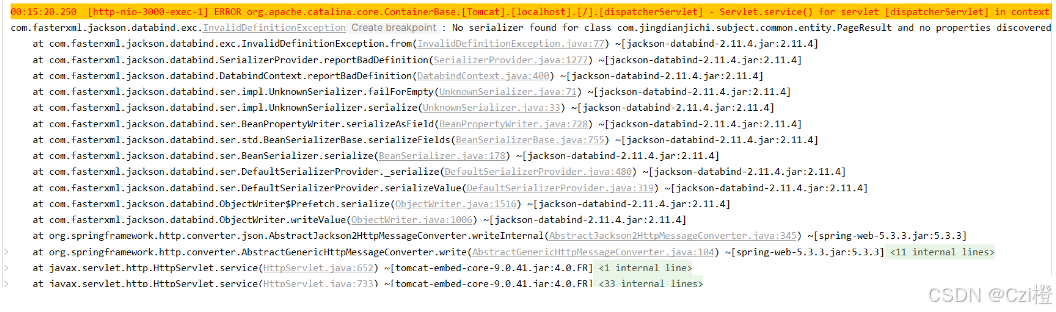
Bug记录:【com.fasterxml.jackson.databind.exc.InvalidDefinitionException】
bug记录 序列化错误 异常com.fasterxml.jackson.databind.exc.InvalidDefinitionException: 完整错误(主要是FAIL_ON_EMPTY_BEANS) 00:15:20.250 [http-nio-3000-exec-1] ERROR org.apache.catalina.core.ContainerBase.[Tomcat].[localhost].[/].[dispatcherServlet] - S…...

Mongodb索引的删除
学习mongodb,体会mongodb的每一个使用细节,欢迎阅读威赞的文章。这是威赞发布的第87篇mongodb技术文章,欢迎浏览本专栏威赞发布的其他文章。如果您认为我的文章对您有帮助或者解决您的问题,欢迎在文章下面点个赞,或者关…...
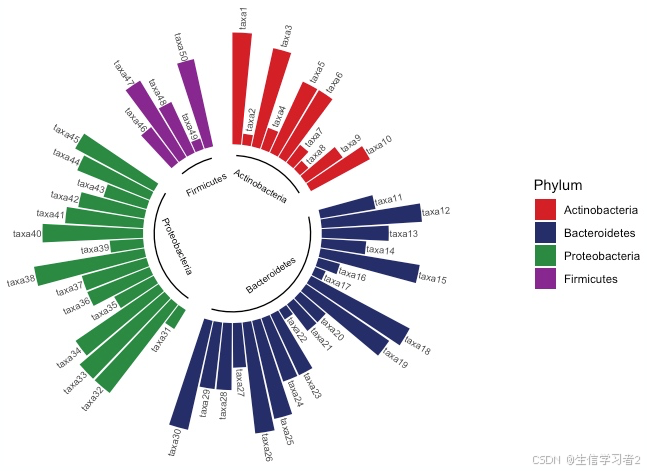
科研绘图系列:R语言径向柱状图(Radial Bar Chart)
介绍 径向柱状图(Radial Bar Chart),又称为雷达图或蜘蛛网图(Spider Chart),是一种在极坐标系中绘制的柱状图。这种图表的特点是将数据点沿着一个或多个从中心向外延伸的轴来展示,这些轴通常围绕着一个中心点均匀分布。 特点: 极坐标系统:数据点不是在直角坐标系中展…...

鸿蒙开发管理:【@ohos.account.distributedAccount (分布式帐号管理)】
分布式帐号管理 本模块提供管理分布式帐号的一些基础功能,主要包括查询和更新帐号登录状态。 说明: 本模块首批接口从API version 7开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。开发前请熟悉鸿蒙开发指导文档ÿ…...

【图书推荐】《HTML5+CSS3 Web前端开发与实例教程(微课视频版)》
本书用来干什么 详解HTML5、CSS3、Flex布局、Grid布局、AI技巧,通过两个网站设计案例提升Web前端开发技能,为读者深入学习Web前端开发打下牢固的基础。 配套资源非常齐全,可以当Web前端基础课的教材。 内容简介 本书秉承“思政引领&#…...
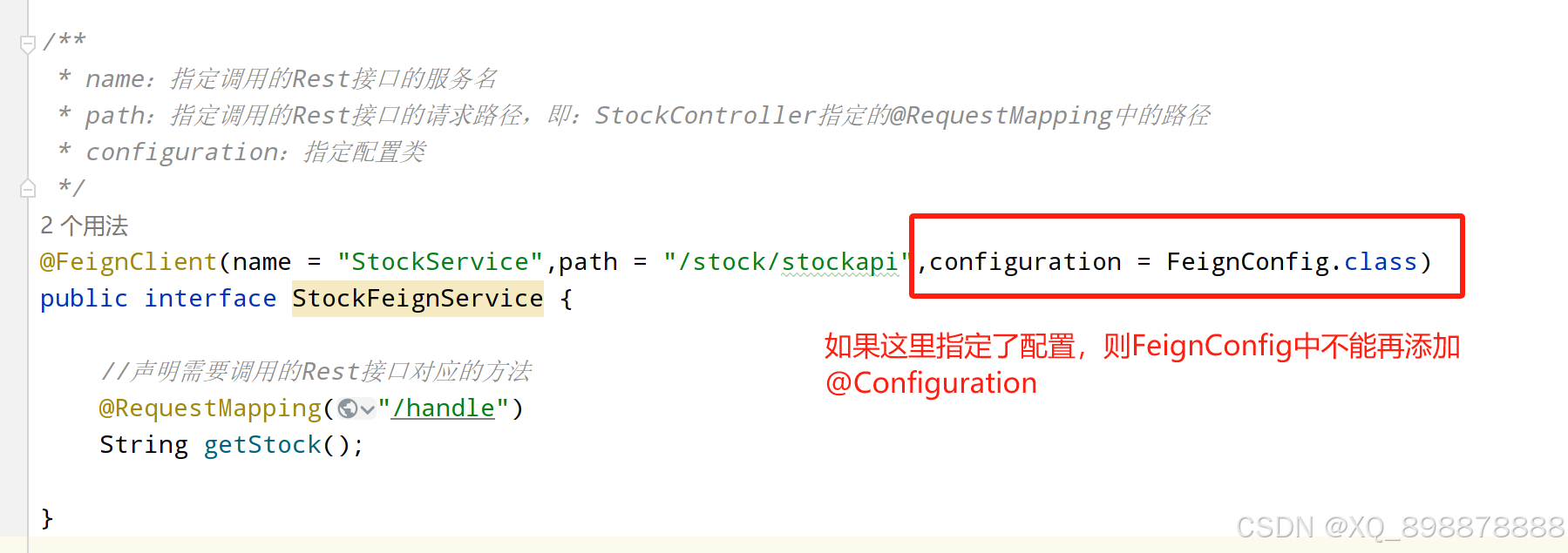
【04】微服务通信组件Feign
1、项目中接口的调用方式 1.1 HttpClient HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 Http 协议的客户端编程工具包,并且它支持 HTTP 协议最新版本和建议。HttpClient 相比传统 JDK 自带的 URLConnectio…...

为什么要设计DTO类
为什么要使用DTO类,下面以新增员工接口为例来介绍。 新增员工 1.1 需求分析和设计 1.1.1 产品原型 一般在做需求分析时,往往都是对照着产品原型进行分析,因为产品原型比较直观,便于我们理解业务。 后台系统中可以管理员工信息…...

流批一体计算引擎-11-[Flink]实战使用DataStream对接kafka
1 消费kafka[DataStreamAPI] 参考官网DataStream API 教程 参考官网DataStream中的Apache Kafka 连接器 flink 1.14版本及以前,不支持python flink 1.15版本为FlinkKafkaConsumer和FlinkKafkaProducer flink 1.16版本及以后为KafkaSource和KafkaSink pip install apache-flin…...

数据仓库面试题
一、ODS、DWD、DWS、ADS划分与职责 数据仓库中的ODS、DWD、DWS、ADS分别代表以下层次,并各自承担不同的职责:--ODS(Operational Data Store): 名称:贴源层 主要职责:作为数据仓库的第一层&…...
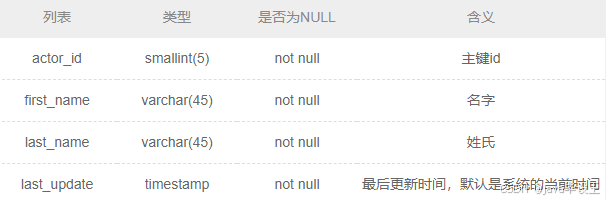
SQL 创建一个actor表,包含如下列信息
系列文章目录 文章目录 系列文章目录前言 前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给你的码吧。 描述 创建一个acto…...

STM32+ESP8266连接阿里云
完整工程文件(百度网盘免费下载,提取码:0625)在文章末尾,需要请移步至文章末尾。 目录 宏定义配置 串口通信配置 消息解析及数据发送 ESP8266初始化 注意事项 完整工程文件 经过基础教程使用AT指令连接阿里云后…...

shark云原生-日志体系-ECK
文章目录 0. ECK 介绍1. 部署 CRDS & Opereator2. 部署 Elasticsearch 集群3. 配置存储4. 部署示例 0. ECK 介绍 ECK(Elastic Cloud on Kubernetes)是Elasticsearch官方提供的一种方式,用于在Kubernetes上部署、管理和扩展Elasticsearch…...
第二次作业
一、数据库 1、登陆数据库 2、创建数据库zoo 3、修改数据库zoo字符集为gbk 4、选择当前数据库为zoo 5、查看创建数据库zoo信息 6、删除数据库zoo 一、数据库(步骤) 1、登陆数据库 mysql -hlocalhost -uadmin -p123456 2、创建…...

Java8 新特性stream、forEach常用方法总结
1、去重 List<Long> list new ArrayList<>();list.add(1L);list.add(2L);list.add(3L);list.add(3L);list.stream().distinct().collect(Collectors.toList()); 2、筛选出符合条件的数据 1)单条件筛选 筛选出性别为男的学生: List<…...

C语言4 运算符
目录 1. 算术运算符 2. 关系运算符 3. 逻辑运算符 4. 位运算符 5. 赋值运算符 6. 自增和自减运算符 7. 条件运算符(三元运算符) 8. 逗号运算符 9. sizeof 运算符 10. 取地址和解引用运算符 11.运算符的优先级 1. 算术运算符 (加法)࿱…...

【数据分析】Pandas_DataFrame读写详解:案例解析(第24天)
系列文章目录 一、 读写文件数据 二、df查询数据操作 三、df增加列操作 四、df删除行列操作 五、df数据去重操作 六、df数据修改操作 文章目录 系列文章目录前言一、 读写文件数据1.1 读写excel文件1.2 读写csv文件1.3 读写mysql数据库 二、df查询数据操作2.1 查询df子集基本方…...

quill编辑器使用总结
一、vue-quill-editor 与 quill 若使用版本1.0,这两个组件使用哪个都是一样的,无非代码有点偏差;若需要使用表格功能,必须使用 quill2.0 版本,因为 vue-quill-editor 不支持table功能。 二、webpack版本问题 在使用 q…...

快手矩阵管理系统:引领短视频运营新潮流
在短视频行业蓬勃发展的今天,如何高效运营和优化内容创作已成为企业和创作者关注的焦点。快手矩阵管理系统以其强大的核心功能,为短视频内容的创作、发布和管理提供了一站式解决方案。 智能创作:AI自动生成文案 快手矩阵管理系统的智能创作…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

CANN-昇腾NPU-RAG推理-检索增强生成怎么部署
RAG(Retrieval-Augmented Generation)是 LLM 知识库的组合:先检索相关文档,再让 LLM 基于文档回答。昇腾NPU 上部署 RAG 需要两个组件:Embedding 模型(做向量检索)和 LLM(做生成&am…...

为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析 在对17个采用DeepSeek-R1/VL模型开展定制化开发的工业级项目进行回溯审计后,我…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南
Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: http…...

JS中forEach与普通for
for就不用说了,最普通的循环函数forEach1. 只写 1 个参数只接收当前遍历元素let arr [10,20,30] arr.forEach(item > {console.log(item) // 依次 10、20、30 })2. 写 2 个参数依次接收元素值、下标索引let arr [10,20,30] arr.forEach((item, index) > {co…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...