从数据到洞察:DataOps加速AI模型开发的秘密实践大公开!

作者 | 代立冬,白鲸开源科技联合创始人&CTO
引言
在AI驱动的商业世界中,DataOps作为连接数据与洞察的桥梁,正迅速成为企业数据战略的核心。
在WOT全球技术创新大会2024·北京站,白鲸开源联合创始人&CTO 代立冬 在「大数据技术与基础设施」专场深入分析DataOps的核心理念、AI大模型开发流程,并通过白鲸开源科技的实践案例,展望了DataOps的未来。
DataOps核心理念
DataOps是一种新兴的数据管理和开发方法论,旨在通过自动化和协作,提高数据管道的效率和质量。
DataOps 在大模型开发中的作用
大模型训练关键要素:
- 数据集:大量、多样化、高质量的数据是训练和微调大模型的基础
- 模型架构:包括网络层数、隐藏层的大小、参数的类型等
- 算力:大模型训练需要极其强大计算资源,包括高性能的GPU,如 A100 等
DataOps与AI模型开发的融合,将加速AI模型的开发周期,提升模型的准确性和效率。
大模型训练流程
大模型训练是一个多阶段过程,涉及数据工程、算法工程和运维。
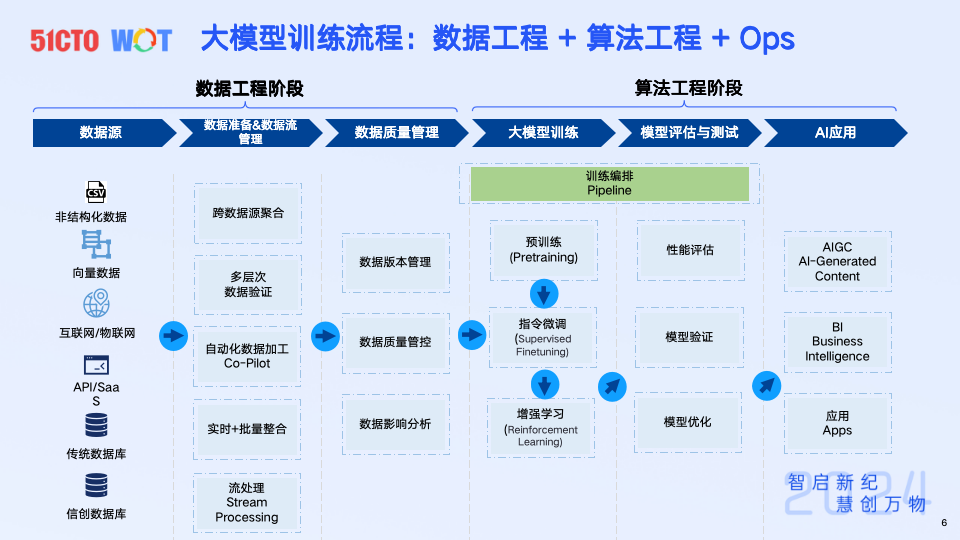
数据工程阶段包括:
- 数据源:确定数据起点,包括云、SaaS、本地等混合数据源。
- 数据准备与数据流管理:涉及数据抽取、转换、加载(ETL)和数据质量管理。
- 大模型训练:利用高质量数据训练模型,包括模型评估与测试。
- 数据质量管理:包括数据版本管理、数据质量管控、数据影响分析
算法工程阶段包括大模型训练、模型评估预测试,其中,经过预训练、指令微调、增强学习的步骤,并完成性能评估、模型验证和模型优化,训练编排的pipeline才算完成,最终将训练完成的模型应用于实际业务场景。
企业面临的数据挑战
企业在新技术环境下,面临数据源多样化、数据处理流程复杂化等挑战,具体包括:
- 企业内拥有多组 “数据平台”,数据资源和流程分散在各部门,难以掌控;
- 企业大数据开发处于“野蛮生长状态”,整体研发管理距离应用开发DevOps流程相差甚远;
- 大数据、流数据、AI数据加工缺乏工具管控形成了企业新的“蜘蛛网”;
- 多种新兴数据引擎、云原生、新数据架构的变化缺乏管控,数据血缘、同步、调度与数据发展严重落后。
新技术环境下EtLT架构出现
云、SaaS、本地混合数据源让传统的数据处理流程从ETL、ELT变为能更加快速满足业务需求的EtLT架构,EtLT能更加敏捷地应对离线/实时数据湖、数据仓库、AI模型训练当中的复杂多变的数据需求场景,从而解决以上企业面临的诸多数据挑战。
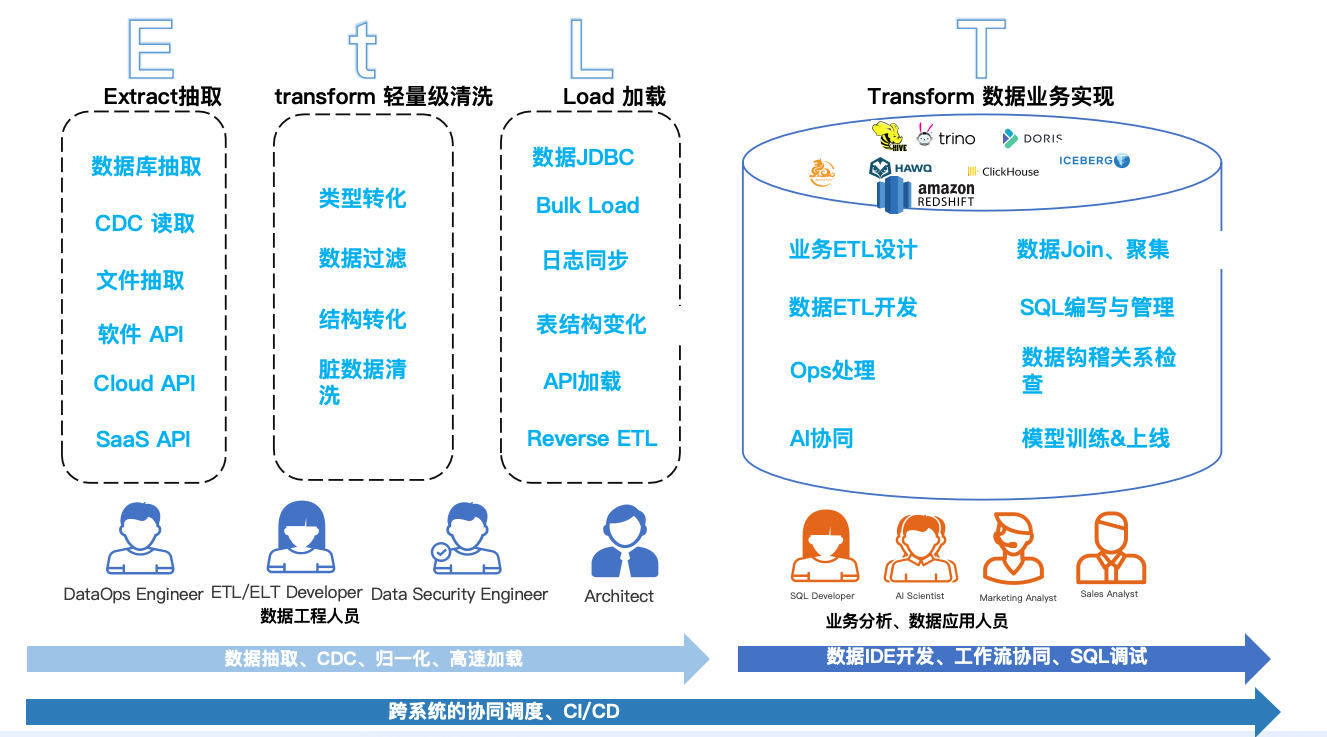
白鲸开源是一家开源原生的DataOps商业公司,由多个Apache Member成立,80%员工都是Apache Committer,主导2个 Apache顶级开源项目(Apache DolphinScheduler, Apache SeaTunnel),同时根据全球最佳实践发布商业版本 --WhaleStudio,帮助企业在大数据和AI时代智能化地完成多数据源、多云及信创环境的数据集成,数据开发、工作流编排运维及部署、数据质量管控、团队敏捷协作等一系列问题,已在 6000多家企业中得到实践和使用。

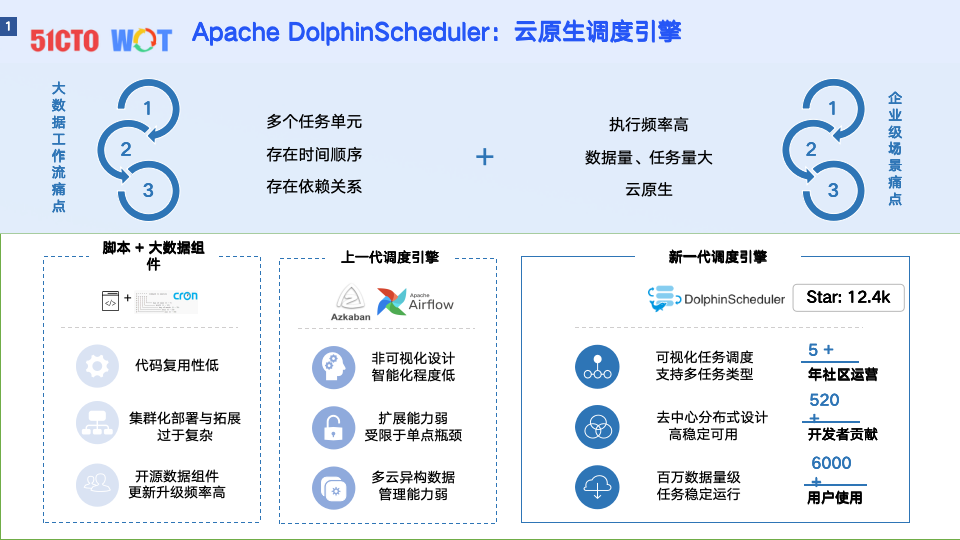
DataOps关键实践之任务调度平台
- Apache DolphinScheduler:云原生调度引擎
作为云原生的调度引擎,DolphinScheduler支持大数据工作流,解决企业级场景中的多个任务单元、高执行频率、数据量大等痛点。
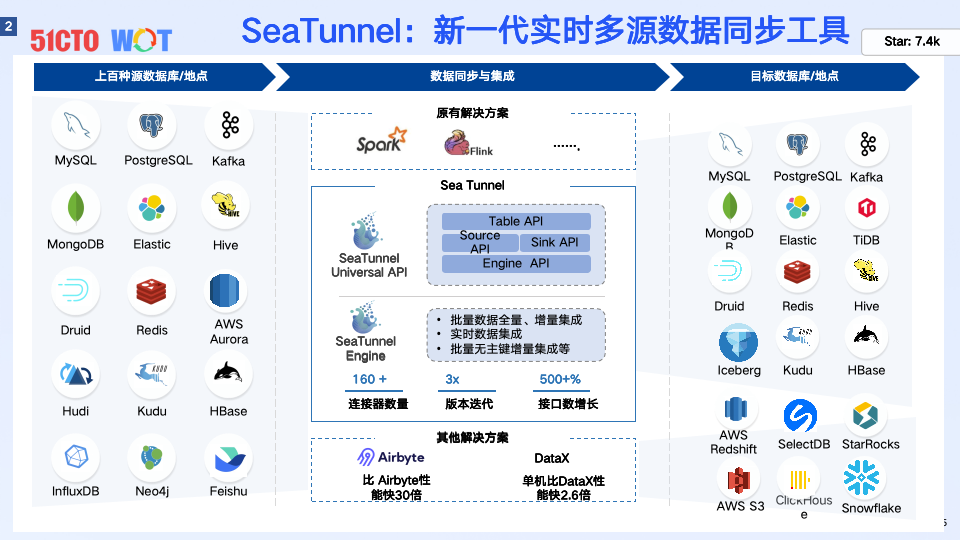
DataOps关键实践之数据集成工具
- Apache SeaTunnel:新一代实时多源数据同步工具
在数据集成领域,企业面临的技术和业务挑战同样严峻:
- 数据源多达几百种,版本间不兼容,而且不断有新的出现;
- 数据丢失与重复,无法一致性
- 出现问题无法回滚或者断点继续执行
- 同步过程不透明,缺少监控
- 频繁读取 binlog 对数据源端影响大
- 大事务、Schema 变更影响下游
- 低吞吐高时延导致数据无法及时到达
- 离线同步和实时同步常被分开管理,维护困难
- 数据割接人工进行
Apache SeaTunnel是新一代实时多源数据同步工具,支持130+种数据源,提供批量和实时数据集成。可以有效地解决以上企业面临的困境。
- Apache SeaTunnel特点

同时,为了实现更高效的数据集成,Apache SeaTunnel社区还“重复造轮子”,自研了专门为数据引擎而设计的SeaTunnel Zeta Engine。
与Spark、Flink等流行引擎相比,Apache SeaTunnel在数据同步上的优势显而易见:

- 典型案例
同样地,Apache SeaTunnel以其强大的数据同步和集成性能在数千家企业的大数据处理中作为重要的一环,发挥着不可替代的作用。典型的用户包括美国醉的商业银行摩根大通银行和哔哩哔哩,两者分别利用Apache SeaTunnel高效解决了跨云数据准备和异构数据实时数据同步的巨大挑战。
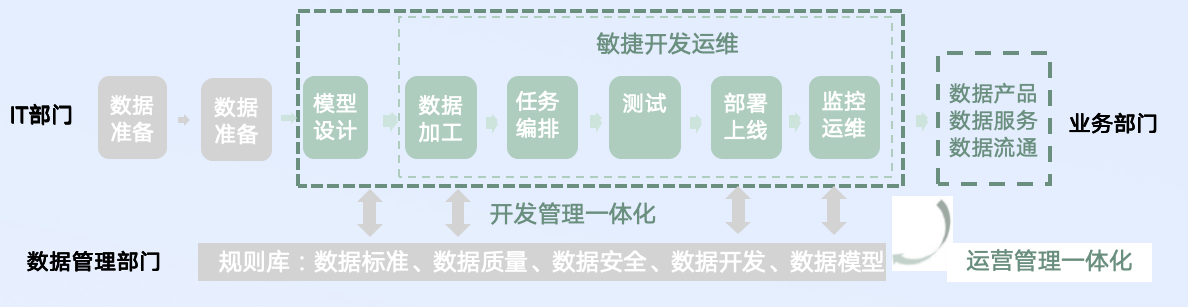
白鲸开源DataOps实践
白鲸开源科技是DataOps领域的领先实践者,提供开源解决方案和商业产品,为企业数据打造全流程DataOps闭环。

稳定高效的企业级dDataOps平台——WhaleStudio
WhaleStudio基于Apache DolphinScheduler和Apache SeaTunnel,是一个分布式、云原生并带有强大可视化界面的 DataOps系统,增加了商业客户所需的企业级特性:
- 完全自主研发,上下游生态圈广阔,支持 160+ 种数据源
- 全面支持云原生—云、仓、湖 实时/离线批流一体化任务管控
- 低代码实现企业大数据的操作系统和高速公路
- 完善的DataOps流程可无缝集成代码工具
- 丰富的数据源对接和传统ETL数据组件支持
- 一站式完成从开发-》测试-》上线-》的运维闭环
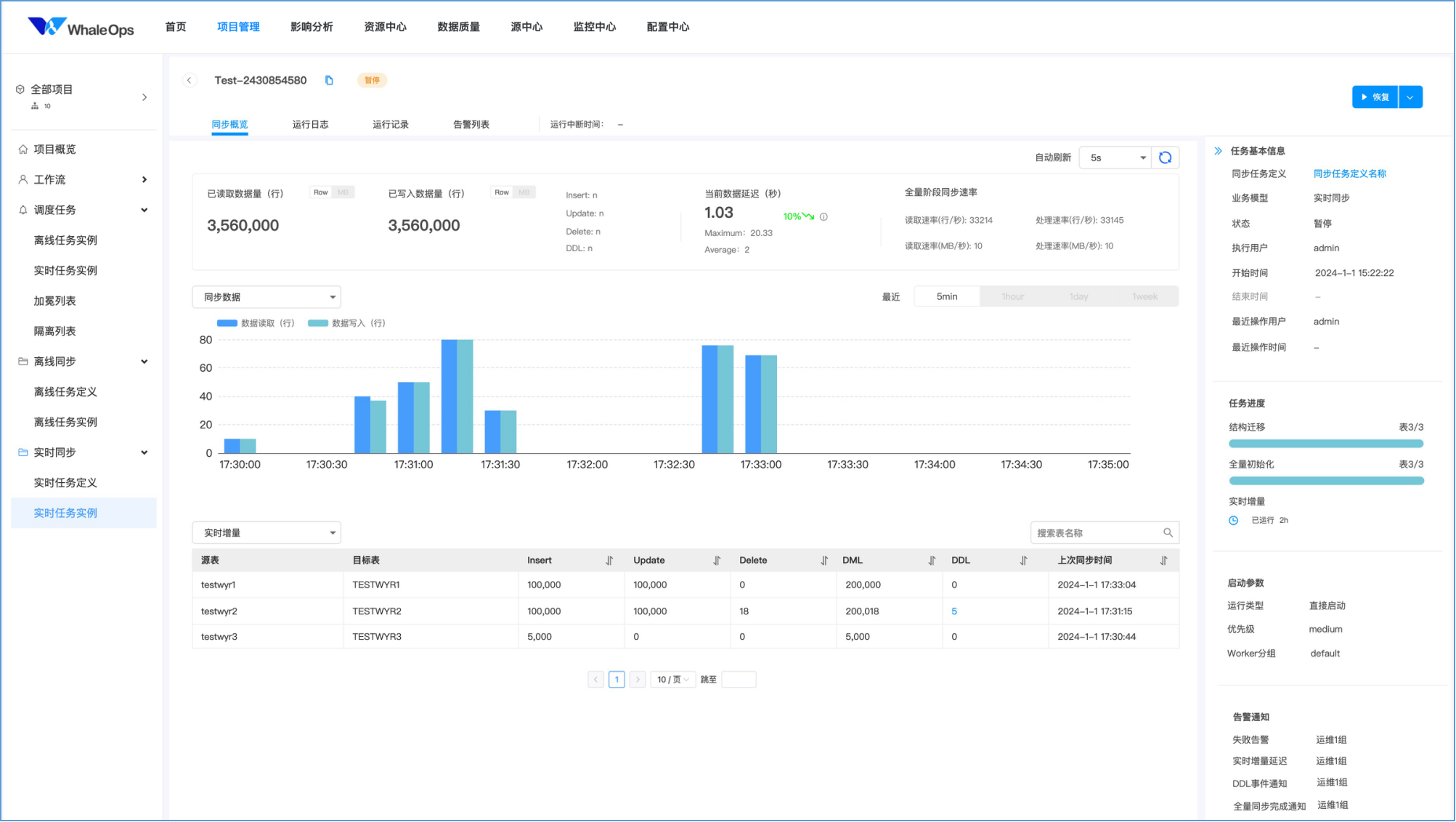
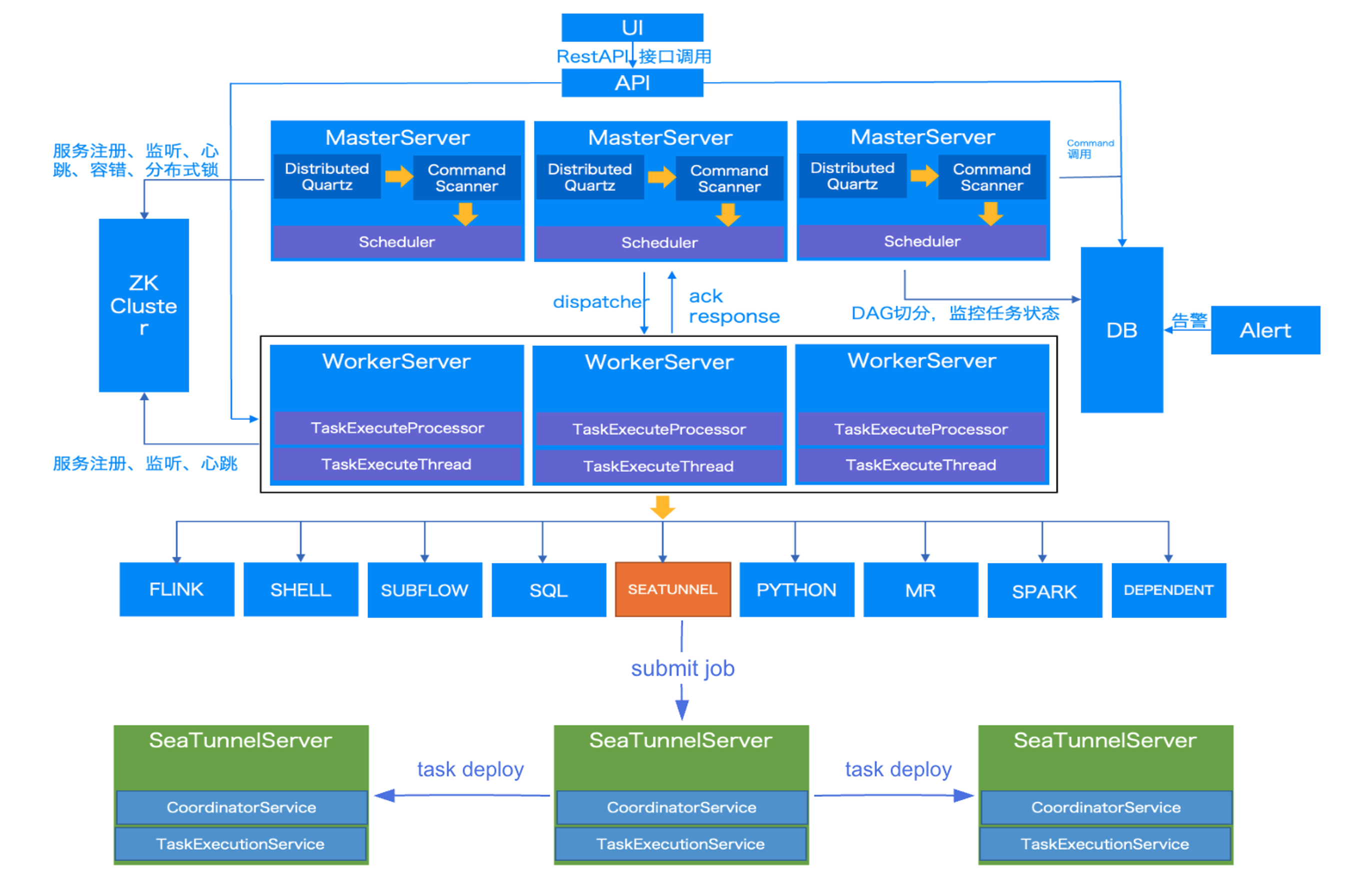 WhaleStudio技术架构
WhaleStudio技术架构
工作流编排能力
WhaleStudio具有强大的工作流编排能力:
- 支持各类计算任务组件:Amazon DMS、Azure Datafactory,Amazon Datasync、Apache Linkis,DataX,Sqoop,SeaTunnel等
- 支持各类云数据库和计算架构,支持 K8S、MLDB。
- 平台采用插件式设计,支持自由扩展数据源支持。
- 可视化的数据源管理,数据源统一集中管理,一次配置,到处使用,大大减少配置修改带来的工作量。
- 支持160种数据源接口,多种数据集成方式
支持160+种数据源
WhaleTunnel支持160+种数据源,例如MySQL,SAP Hana,Oracle,DB2,SQLServer,Gbase,Kafka,ClickHouse,RedShift、达梦等。平台采用插件式设计,支持自由扩展数据源。
支持多种数据同步方式:
- 批量数据全量、增量集成
- 实时数据集成
- 批量无主键增量集成等
支持商业数据库实时CDC
Mysql
PostGreSQL
SQLServer
Oracle
DB2
AWS Aurora
翰高
StarRocks
达梦
人大金仓
PolarDB

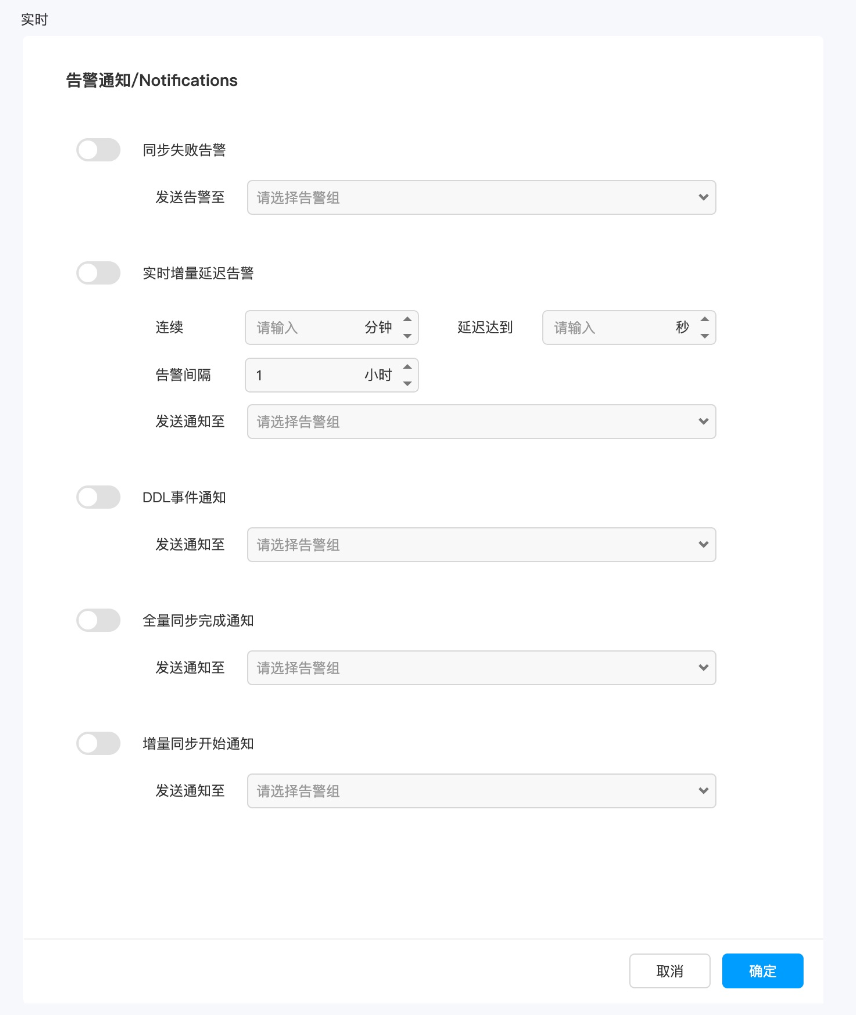
实时数据同步支持DDL变更触发暂停、报警以及延迟告警
实时数据处理支持多种实时数据监测处理:
- DDL变更暂停
- DDL变更告警
- DDL暂停加表
- DDL手工处理
支持多种方式控制&监测速率:
- 数据采集速率控制
- 并发控制
- 数据延迟告警
- 数据全量完成告警
- 数据CDC增量启动告警
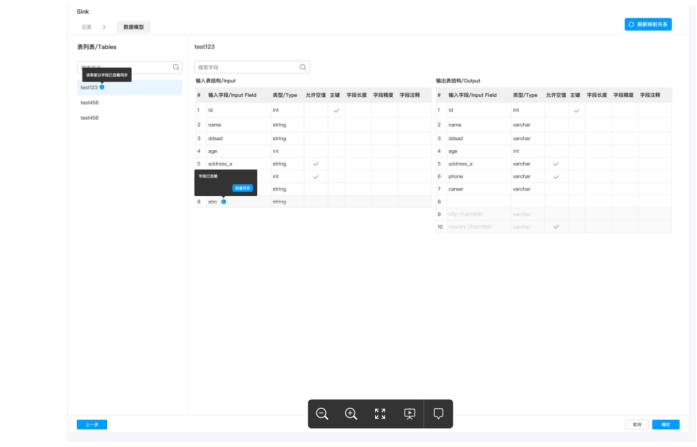
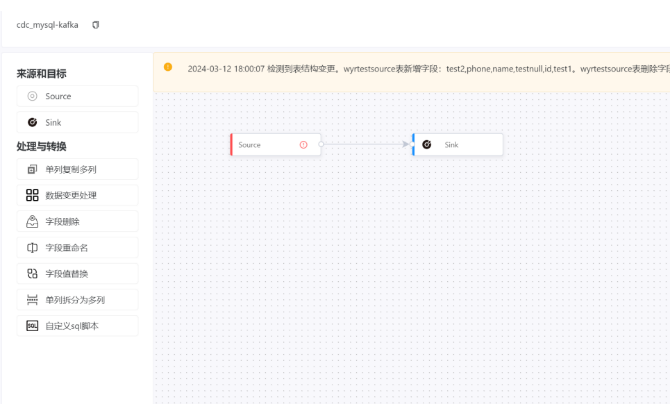
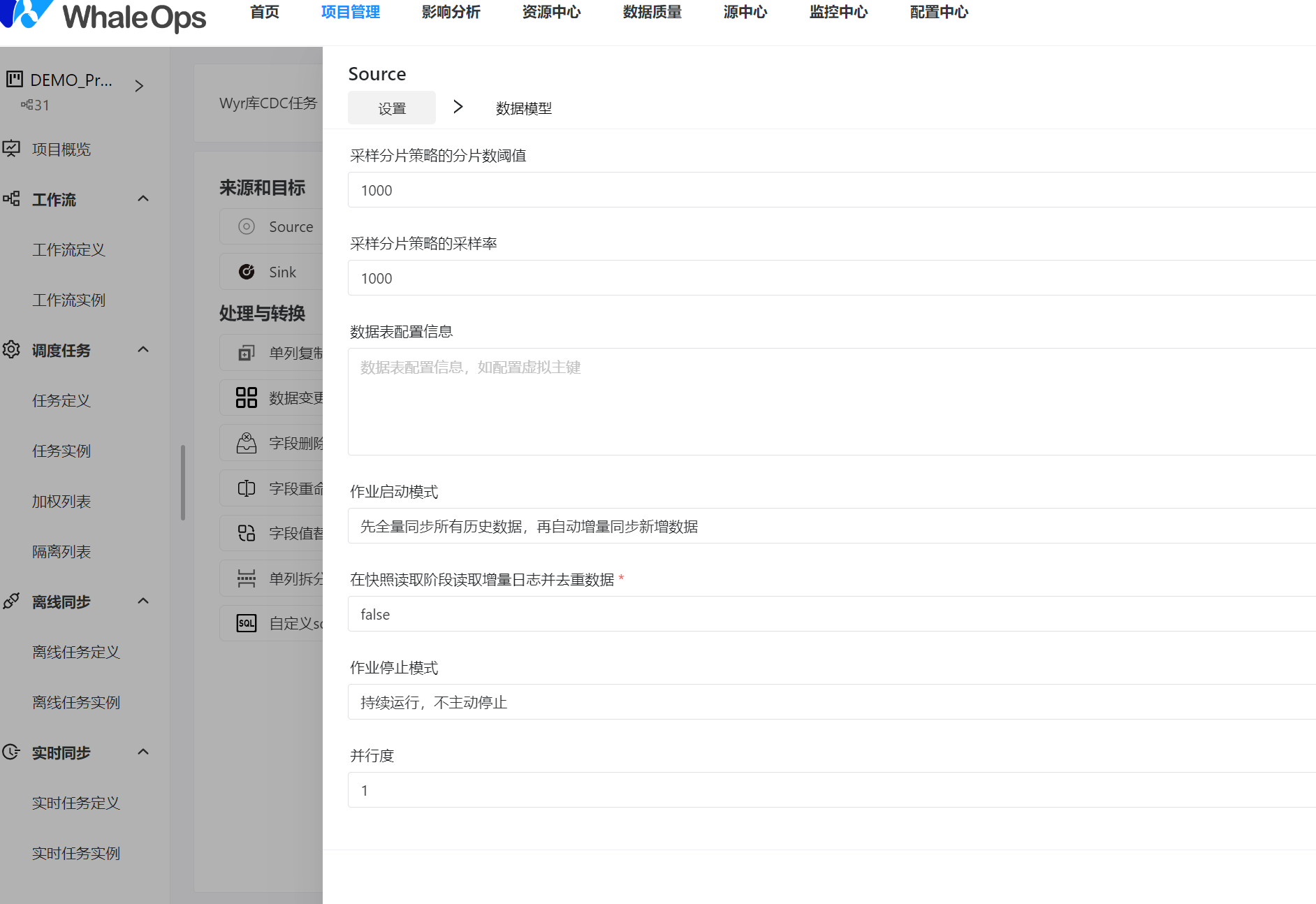
数据开发能力-在线IDE&集成,实现DataOps

数据质量把控–数据工作流血缘关系
- 全局跨工作流的任务和及实例间的依赖关系
- 结合任务与表定义,实现表及血缘分析以及任务操作
- 支持实例级别的依赖链路展示
- 支持全局视图进行停止、暂停、重跑、依赖链重跑等操作

智能基线–提前预知任务延迟从而提前采取行动
配置智能基线帮助“智能”告警: ✅定义核心任务基线,多一双“智能”的眼镜 ✅根据任务的执行历史只能推算时长 ✅设置安全预警时间,智能告警

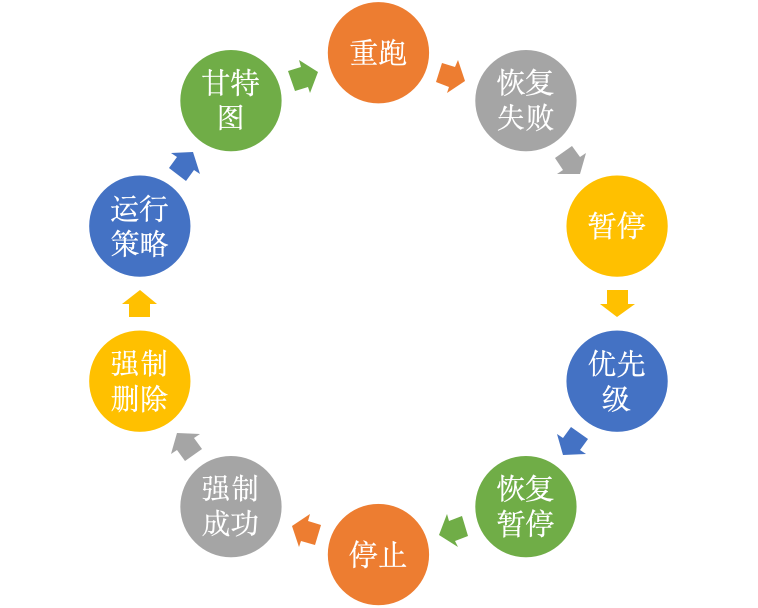
多种运维管理手段帮助运维人员快速处理故障
任务上线之后,面对各种突发情况,有多种手段来确保在任务发生异常时可以协助运维人员快速处理异常。
实践案例分析
中信建投DataOps布局
在经过对比调研后,中信建投采用了WhaleStudio平台来解决当时在谁开发中存在的挑战。
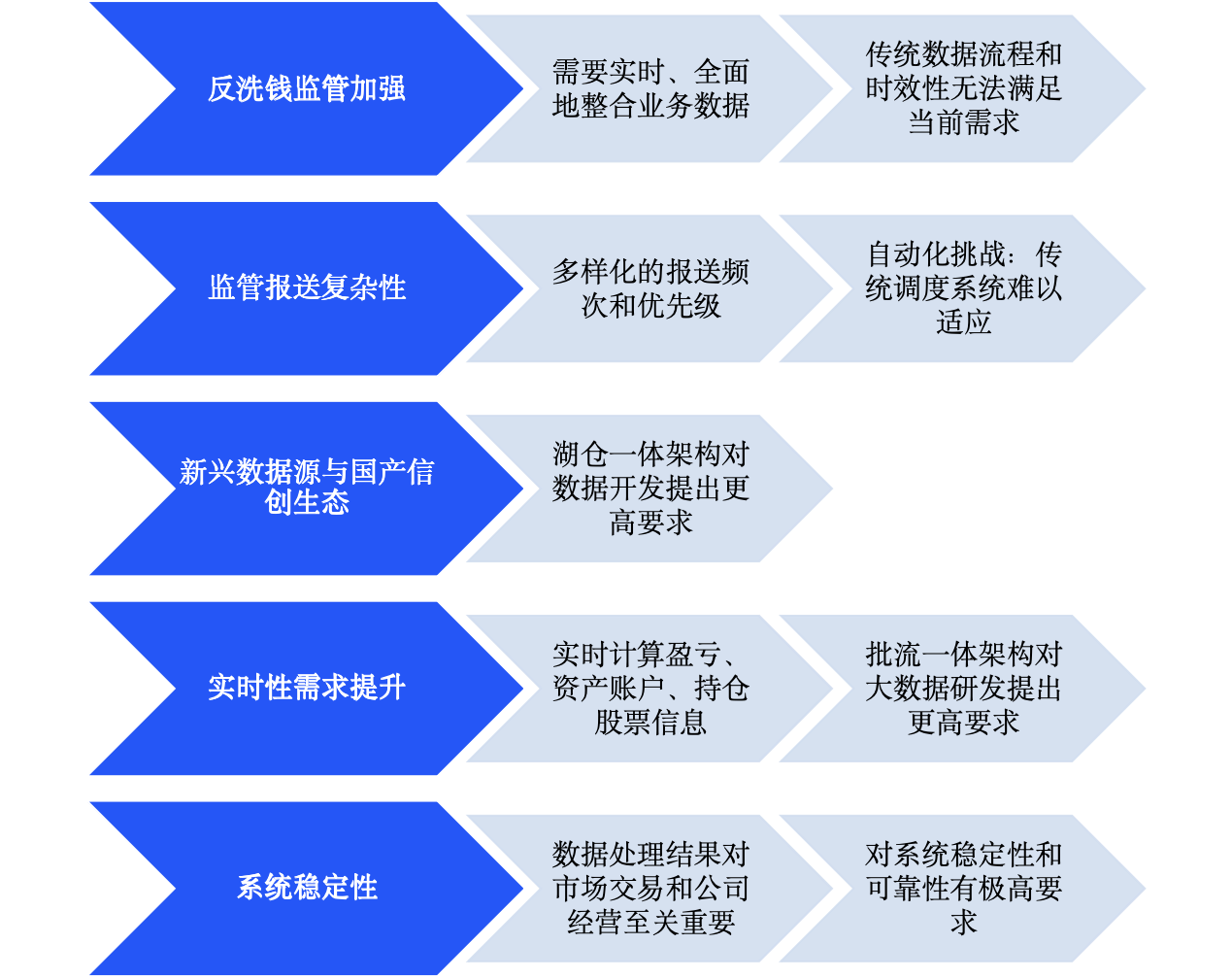
通过WhaleStudio平台,中信建投实现了数据一体化编辑、上线和管控,极大提升了数据研发效率。


- 工作流编排:定义超过3000个工作流,上线任务数量接近16000个。
- 核心应用:应用于反洗钱、实时盈亏计算、监管报送、数据精算等核心业务。
- 效率提升:日均运行工作流实例超过5000个,日均任务执行数量超过20000个。
目前公司各业务线数据处理任务还在持续上线DataOps平台,整个平台规模还在持续增长中。
DataOps未来
DataOps的未来将由AI技术进一步推动,实现更智能化的数据处理、数据安全保护和跨平台/云数据治理。
大模型在数据处理流程中可以扮演多种角色,提高整个数据处理流程的效率和智能化水平。大模型将应用于以下方面:
智能调度策略
数据处理涉及复杂的任务调度,大模型可以分析历史作业执行情况、资源使用状况,从而预测未来的工作流需求,智能地调度任务和分配资源。减少延迟,提高整体处理速度,并优化资源利用率。
数据质量检测与清洗
在数据同步过程中,大模型可以辅助自动检测数据质量问题,比如识别异常值、缺失数据或不一致性。通过机器学习算法,模型可以学习数据特征,自动清洗和修正数据,确保数据同步后的质量。
智能数据分类与标签
对于需要分类或标签化的数据,大模型可以自动分析数据内容,对其进行分类或附加有意义的标签,特别是在多模态数据处理场景下,这对于后续的数据分析和应用至关重要。
自适应数据同步策略
根据网络状况、数据变化频率和业务需求,大模型可以帮助动态调整数据同步策略,比如选择最合适的同步频率、确定优先级高的数据流,以优化同步效率和减少带宽消耗。
自动化异常处理
在数据传输或处理过程中遇到异常时,大模型可以基于历史数据和模式识别,自动识别异常原因并触发相应的处理机制,减少人工干预,提高处理效率。
结语
DataOps不仅是一种技术实践,更是一种文化和思维方式。随着AI技术的不断进步,DataOps将继续推动企业数据管理和AI模型开发的创新和发展。
相关资源
- 白鲸开源官网:https://www.whaleops.com
- Apache Dolphin Scheduler官网:https://dolphinscheduler.apache.org
- Apache SeaTunnel官网:https://seatunnel.apache.org
作者介绍
代立冬
- 白鲸开源科技联合创始人
- Apache 孵化器导师
- Apache DolphinScheduler PMC Chair
- Apache SeaTunnel PMC
- ApacheCon 亚洲大数据湖仓论坛出品人
- 中国科协 “2023开源创新榜” 优秀人物
本文由 白鲸开源科技 提供发布支持!
相关文章:
从数据到洞察:DataOps加速AI模型开发的秘密实践大公开!
作者 | 代立冬,白鲸开源科技联合创始人&CTO 引言 在AI驱动的商业世界中,DataOps作为连接数据与洞察的桥梁,正迅速成为企业数据战略的核心。 在WOT全球技术创新大会2024北京站,白鲸开源联合创始人&CTO 代立冬 在「大数据…...

全景图三维3D模型VR全景上传展示H5开发
全景图三维3D模型VR全景上传展示H5开发 3D互动体验平台的核心功能概览 兼容广泛格式:支持OBJ、FBX、GLTF等主流及前沿3D模型格式的无缝上传与展示,确保创意无界。 动态交互探索:用户可自由旋转、缩放、平移模型,深度挖掘每一处…...

前端面试题29(js闭包和主要用途)
JavaScript 中的闭包是一个非常强大的特性,它允许一个函数访问并操作其词法作用域之外的变量。闭包的形成主要依赖于函数的作用域链,即函数可以访问在其外部定义的变量,即使外部函数已经执行完毕。下面我会通过几个方面来帮助你理解闭包的概念…...

使用Keil 点亮LED灯 F103ZET6
1.新建项目 不截图了 2.startup_stm32f10x_hd.s Keil\Packs\Keil\STM32F1xx_DFP\2.2.0\Device\Source\ARM 搜索startup_stm32f10x_hd.s 复制到项目路径,双击Source Group 1 3.项目文件夹新建stm32f10x.h, 新建文件main.c #include "stm32f10x…...
实现拆分流和复制流)
流批一体计算引擎-12-[Flink]旁路输出getSideOutput(OutputTag)实现拆分流和复制流
官网旁路输出 Flink拆分流和复制流 我们在处理数据的时候,有时候想对不同情况的数据进行不同的处理,那么就需要把流进行拆分或者复制。 如果是使用filter来进行拆分,也能满足我们的需求,但每次筛选都要保留整个流,然后遍历整个流,显然很浪费性能,假如能够在一个流了多次…...

【Scrapy】 Scrapy 爬虫框架
准我快乐地重饰演某段美丽故事主人 饰演你旧年共寻梦的恋人 再去做没流着情泪的伊人 假装再有从前演过的戏份 重饰演某段美丽故事主人 饰演你旧年共寻梦的恋人 你纵是未明白仍夜深一人 穿起你那无言毛衣当跟你接近 🎵 陈慧娴《傻女》 Scrapy 是…...

【笔记】太久不用redis忘记怎么后台登陆了
!首先启动虚拟机linux的centos7 2.启动finalshell 我的redis启动在根目录用 redis-server redis.conf --启动 systemctl status redis --查看redis状态 是否active redis-cli -h centos的ip地址 -p 你要用的redis端口号(默认为6379) -a 你…...
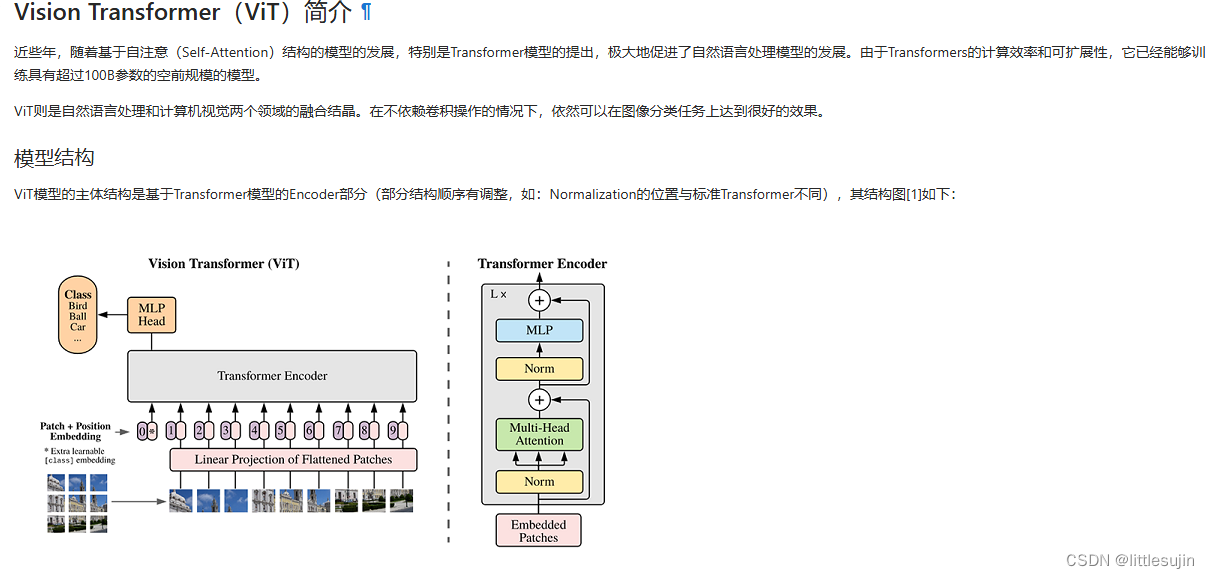
昇思25天打卡营-mindspore-ML- Day14-VisionTransformer图像分类
今天学习了Vision Transformer图像分类,这是一种基于Transformer模型的图像分类方法,它不依赖卷积操作,而是通过自注意力机制捕捉图像块之间的空间关系,从而实现图像分类。 基本原理: 图像分块: 将原始图像划分为多个…...

微信环境内H5网页,用开放标签wx-open-launch-app打开app
一、微信公众号后台配置安全域名 准备一个认证通过的公众号,打开公众号后台 1、设置与开发 2、公众号设置 3、功能设置 4、配置js接口安全域名 二、微信开放平台,将公众号与APP关联 打开微信开放平台后台 1、管理中心 2、公众号 3、选择一个需要操作…...

【c++基础】高精度数不进位加法
高精度数不进位加法 谈及数字即可想到运算,那么高精度数怎么运算呢?今天来系统介绍一下高精度数的加法。 思考一下加法运算,我们可以简单将加法运算这样区分: 有无进位。位数是否相同。 这篇文章我们就来讨论一下无进位的高精度…...

UniApp 中 Web/H5 正确使用反向代理解决跨域问题
因为 Vue3 的构建工具是 Vite,所以配置 vue.config.js 是没用的(Vue2 因为使用 webpack 所以才用这个文件) 这里提供一份 vue.config.js 的示例: module.exports {devServer: {proxy: {/api: {target: http://example.com,chan…...

Redis Stream:实时数据流的处理与存储
Redis Stream:实时数据流的处理与存储 引言 在当今数据驱动的世界中,实时数据处理和存储成为了许多应用的核心需求。Redis Stream作为一种新兴的数据结构,为Redis带来了强大的流处理能力。本文将深入探讨Redis Stream的特点、使用场景以及如何高效地利用它来处理实时数据流…...

【论文阅读】-- Visual Traffic Jam Analysis Based on Trajectory Data
基于轨迹数据的可视化交通拥堵分析 摘要1 引言2 相关工作2.1 交通事件检测2.2 交通可视化2.3 传播图可视化 3 概述3.1 设计要求3.2 输入数据说明3.3 交通拥堵数据模型3.4 工作流程 4 预处理4.1 路网处理4.2 GPS数据清理4.3 地图匹配4.4 道路速度计算4.5 交通拥堵检测4.6 传播图…...

修改编译依赖openssl的libcrypto.so
由于centos7默认使用openssl1.0.2k的libcrypto.so.10共享库。即使openssl升级为3.0.11后,编译使用ldd命令查看共享库依旧会引用libcrypto.so.10。 现希望引用libcrypto.so.3,需要在生成动态链接库的CMakeLists.txt中增加如下配置,明确指定ope…...

����: �Ҳ��������������� javafx.fxml ԭ��: java.lang.ClassNotFoundException解决方法
如果你出现了这个问题,恭喜你,你应该会花很多时间去找解决方法。别问我怎么知道的... 解决方法: 出现乱码的原因:配置vm时 这些配置看似由有空格,换行,实则没有。所以解决办法就是,重新配置你…...

【C++】———— 继承
作者主页: 作者主页 本篇博客专栏:C 创作时间 :2024年7月5日 一、什么是继承? 继承的概念 定义: 继承机制就是面向对象设计中使代码可以复用的重要手段,它允许在程序员保持原有类特性的基础上进行扩展…...

Python人生重开器
Life reopens stimulator """ 作者:->yjy 所有的惊艳都曾历经平庸 """ import random import sys import time# 打印初始界面 print(------------------------------) print(| |) print(| >>人生重…...

python 高级技巧 0708
python 33个高级用法技巧 使用装饰器计时函数 装饰器是一种允许在一个函数或方法调用前后运行额外代码的结构。 import timedef timer(func):"""装饰器函数,用于计算函数执行时间并打印。参数:func (function): 被装饰的函数返回:function: 包装后…...
)
HOW - React Router v6.x Feature 实践(react-router-dom)
目录 基本特性ranked routes matchingactive linksNavLinkuseMatch relative links1. 相对路径的使用2. 嵌套路由的增强行为3. 优势和注意事项4. . 和 ..5. 总结 data loadingloading or changing data and redirectpending navigation uiskeleton ui with suspensedata mutati…...

`padding`、`border`、`width`、`height` 和 `display` 这些 CSS 属性的作用
盒模型中的属性 padding(内边距) padding 用于控制元素内容与边框之间的空间,可以为元素的每个边(上、右、下、左)分别设置内边距。内边距的单位可以是像素(px)、百分比(%…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题
Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘爆红、…...

基于MAX78000的边缘AI语音识别:从模型训练到嵌入式部署实战
1. 项目概述与核心思路最近在捣鼓一个挺有意思的小项目,我把它叫做“声控转向控制器”。简单来说,这玩意儿能听懂你说的几个特定单词,比如“左转”、“右转”、“前进”、“后退”,然后控制对应的LED灯亮起。你可能会想࿰…...

从SIM800到BK A7670E:4G Cat.1模块硬件平替转接板设计全解析
1. 项目概述:从2G到4G的硬件平替升级 手头有个老项目,用的还是SIM800这种经典的2G模块,现在网络环境变了,2G退网是大势所趋,信号覆盖越来越差,项目得活下去,升级到4G成了刚需。但问题来了&#…...
)
Unity开发者速查手册:Sora 2模型权重量化适配指南(INT8精度损失<0.3%,已验证于RTX 4090/Apple M3 Ultra)
更多请点击: https://codechina.net 第一章:Sora 2与Unity整合概述 Sora 2 是 OpenAI 推出的下一代视频生成模型,具备高保真时序建模与物理感知能力;而 Unity 作为主流实时3D开发引擎,广泛用于游戏、仿真与数字孪生场…...

HoRain云--Ollama 安装
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

清华大学学位论文LaTeX模板:告别格式烦恼的终极指南
清华大学学位论文LaTeX模板:告别格式烦恼的终极指南 【免费下载链接】thuthesis LaTeX Thesis Template for Tsinghua University 项目地址: https://gitcode.com/gh_mirrors/th/thuthesis 还在为论文格式调整而烦恼吗?清华大学thuthesis LaTeX模…...