Hadoop权威指南-读书笔记-03-Hadoop分布式文件系统
Hadoop权威指南-读书笔记
记录一下读这本书的时候觉得有意思或者重要的点~

还是老样子~挑重点记录哈😁有兴趣的小伙伴可以去看看原著😊
第三章 Hadoop分布式文件系统
-
当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(
partition)并存储到若干台单独的计算机上。

-
管理网络中跨多台计算机存储的文件系统称为分布式文件系统(distributed file system)。
- 该系统架构于网络之上,势必会引人网络编程的复杂性,因此分布式文件系统比普通磁盘文件系统更为复杂。例如,使文件系统能够容忍节点故障且不丢失任何数据,就是一个极大的挑战。
3.1 HDFS的设计

HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上。
- 超大文件:目前已经有PB级数据的Hadoop集群了。

-
流式数据访问:
- HDFS的构建思路是这样的:一次写入、多次读取是最高效的访问模式。
- 数据集通常由数据源生成或从数据源复制而来,接着长时间在此数据集上进行各种分析。
- 每次分析都将涉及该数据集的大部分数据甚至全部,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更重要。
-
商用硬件:
- Hadoop并不需要运行在昂贵且高可靠的硬件上。
- 它是设计运行在商用硬件(在各种零售店都能买到的普通硬件")的集群上的。
- 因此至少对于庞大的集群来说,节点故障的几率还是非常高的。HDFS遇到上述故障时,被设计成能够继续运行且不让用户察觉到明显的中断。
- 低时间延迟的数据访问:
- 要求低时间延迟数据访问的应用,例如几十毫秒范围,不适合在HDFS上运行。记住,HDFS是为高数据吞量应用优化的,这可能会以提高时间延迟为代价。目前,对于低延迟的访问需求HBase(参见第 20 章)是更好的选择。
-
大量的小文件:
- 由于namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于namenode的内存容量。
-
多用户写入,任意修改文件:
- HDFS中的文件写入只支持单个写入者,而且写操作总是以“只添加”方式在文件末尾写数据。
- 它不支持多个写入者的操作,也不支持在文件的任意位置进行修改。
3.2 数据块
每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位。
构建于单个磁盘之上的文件系统通过磁盘块来管理该文件系统中的块,该文件系统块的大小可以是磁盘块的整数倍。
文件系统块一般为几千字节,而磁盘块一般为512字节。这些信息(文件系统块大小)对于需要读/写文件的文件系统用户来说是透明的。
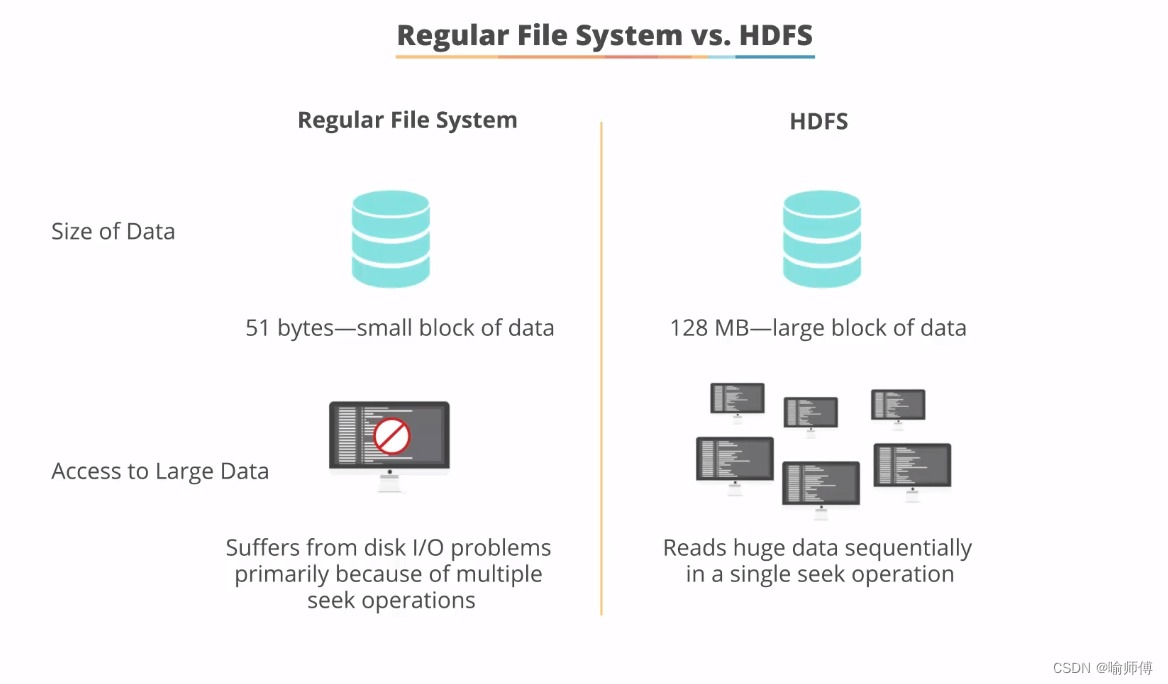
HDFS 同样也有块(block)的概念,但是大得多,默认为128MB。与单一磁盘上的文件系统相似,HDFS上的文件也被划分为块大小的多个分块(chunk),作为独立的存储单元。

但与面向单一磁盘的文件系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间(例如,当一个1MB的文件存储在一个128MB的块中时,文件只使用1MB的磁盘空间,而不是128MB)。
为什么HDFS中的块这么大?
- HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。
- 如果块足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的大文件的时间取决于磁盘传输速率。
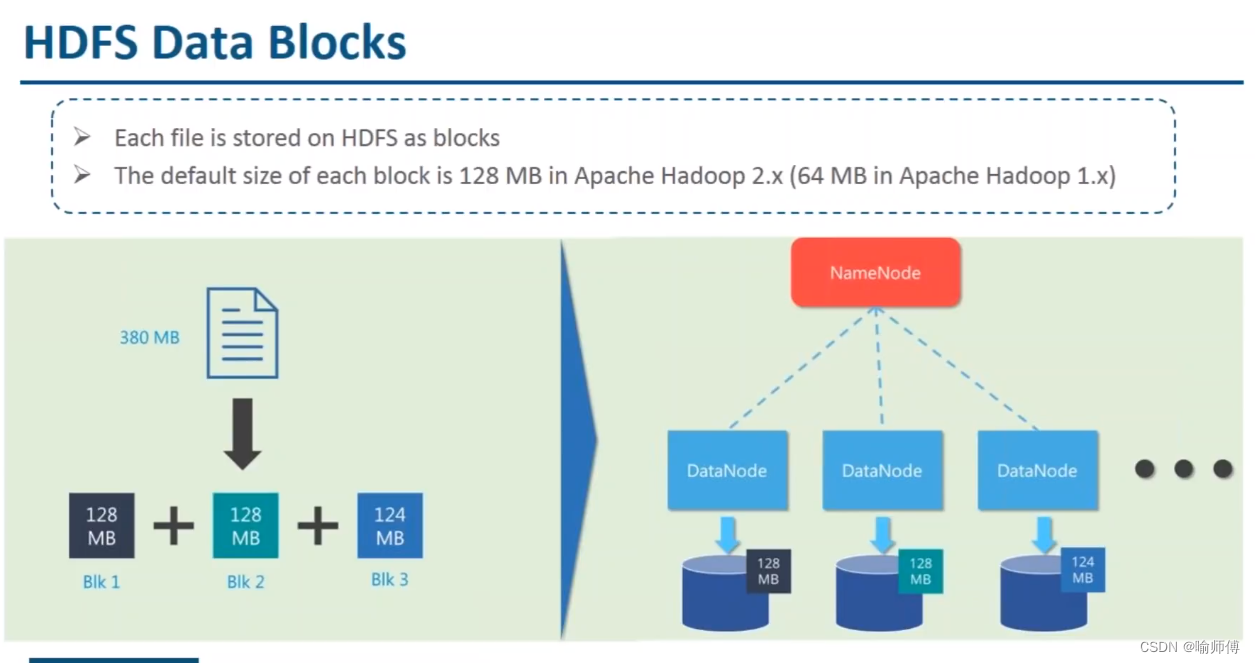
我们来做一个速算,如果寻址时间约为10ms,传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。默认的块大小实际为 128 MB,但是很多情况下 HDFS 安装时使用更大的块。以后随着新一代磁盘驱动器传输速率的提升,块的大小会被设置得更大。
但是这个参数也不会设置得过大。MapReduce中的map任务通常一次只处理一个块中的数据,因此如果任务数太少(少于集群中的节点数量),作业的运行速度就会比较慢。
对分布式文件系统中的块进行抽象会带来很多好处。
- 第一个最明显的好处是,一个文件的大小可以大于网络中任意一个磁盘的容量。
- 文件的所有块并不需要存储在同一个磁盘上,因此它们可以利用集群上的任意一个磁盘进行存储。
- 第二个好处是,使用抽象块而非整个文件作为存储单元,大大简化了存储子系统的设计。
- 简化是所有系统的目标,但是这对于故障种类繁多的分布式系统来说尤为重要。
- 将存储子系统的处理对象设置为块,可简化存储管理(由于块的大小是固定的,因此计算单个磁盘能存储多少个块就相对容易)。同时也消除了对元数据的顾虑(块只是要存储的大块数据,而文件的元数据,如权限信息,并不需要与块一同存储,这样一来,其他系统就可以单独管理这些元数据)。
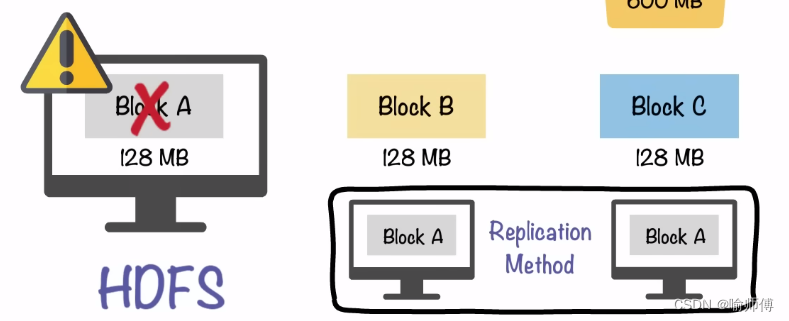
- 不仅如此,块还非常适合用于数据备份进而提供数据容错能力和提高可用性。
-
将每个块复制到少数几个物理上相互独立的机器上(默认为3个),可以确保在块、磁盘或机器发生故障后数据不会丢失。
-
如果发现一个块不可用,系统会从其他地方读取另一个复本,而这个过程对用户是透明的。一个因损坏或机器故障而丢失的块可以从其他候选地点复制到另一台可以正常运行的机器上,以保证复本的数量回到正常水平。
-
- 同样,有些应用程序可能选择为一些常用的文件块设置更高的复本数量进而分散集群中的读取负载。
3.3 namenode 和 datanode
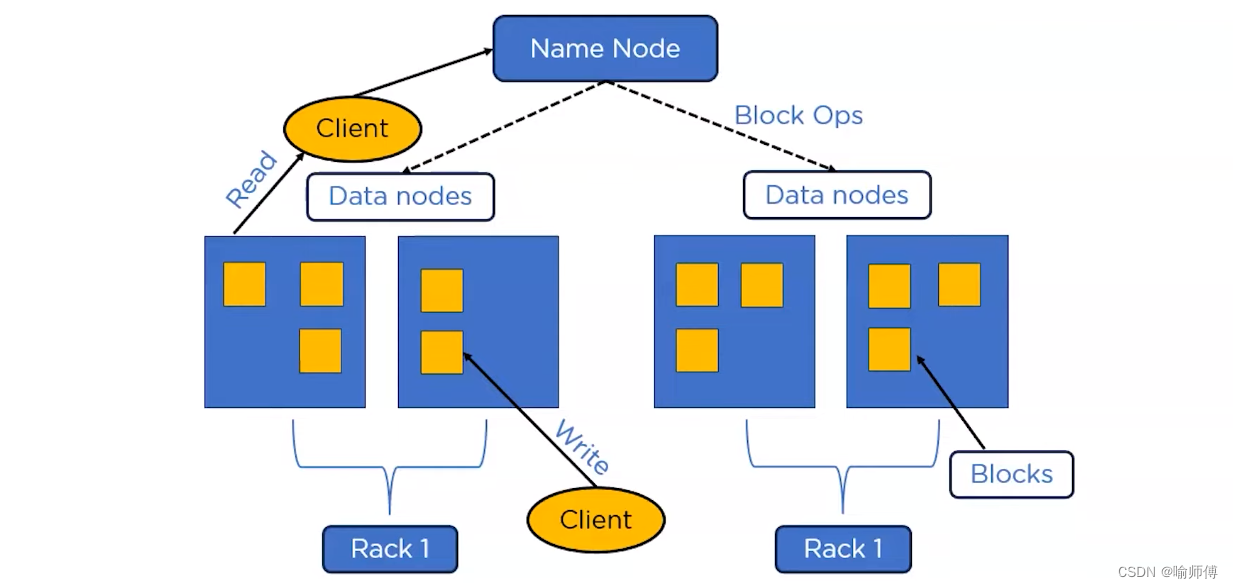
HDFS 集群有两类节点以管理节点-工作节点模式运行,即一个namenode(管理节点)和多个 datanode(工作节点)。

-
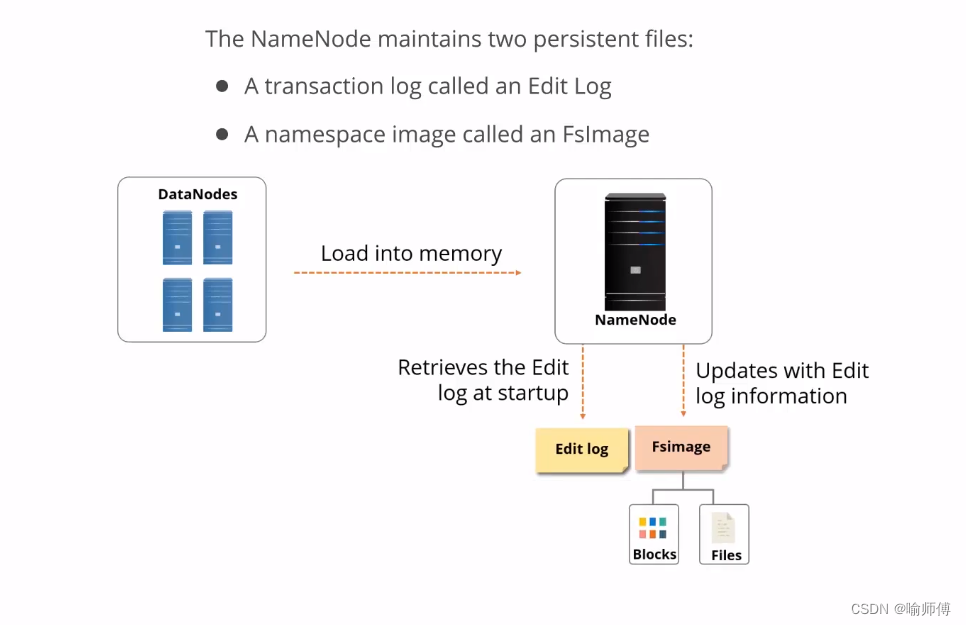
namenode 管理文件系统的命名空间。
- 它维护着文件系统树及整棵树内所有的文件和目录。
- 这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。
- namenode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时根据数据节点信息重建。

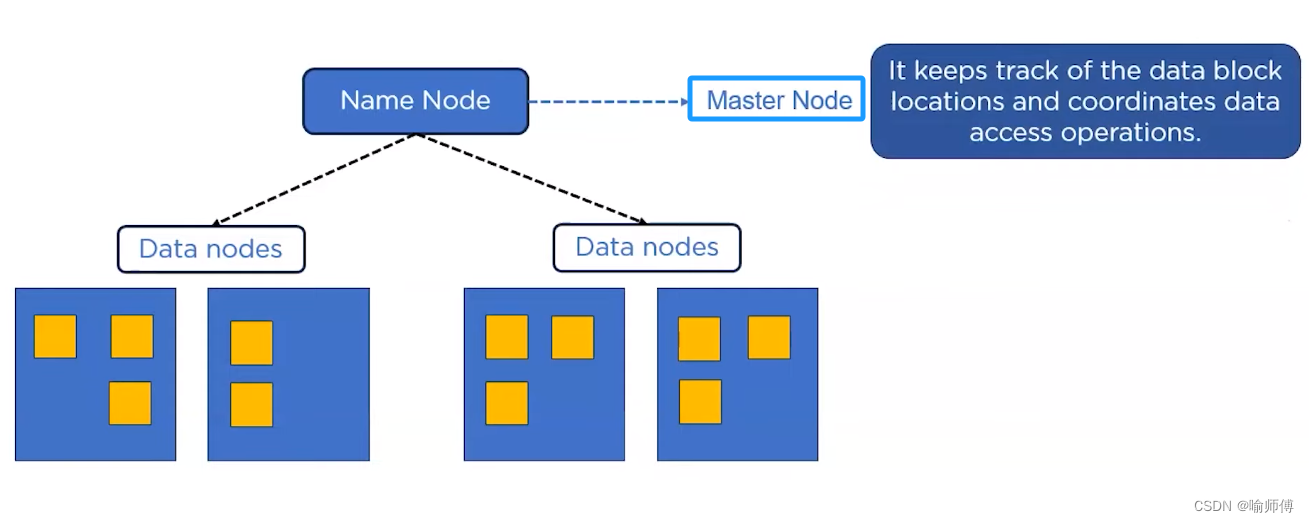
- 客户端(client)代表用户通过与namenode和 datanode 交互来访问整个文件系统。
- 客户端提供一个类似于POSIX(可移植操作系统界面)的文件系统接口,因此用户在编程时无需知道namenode和datanode 也可实现其功能。
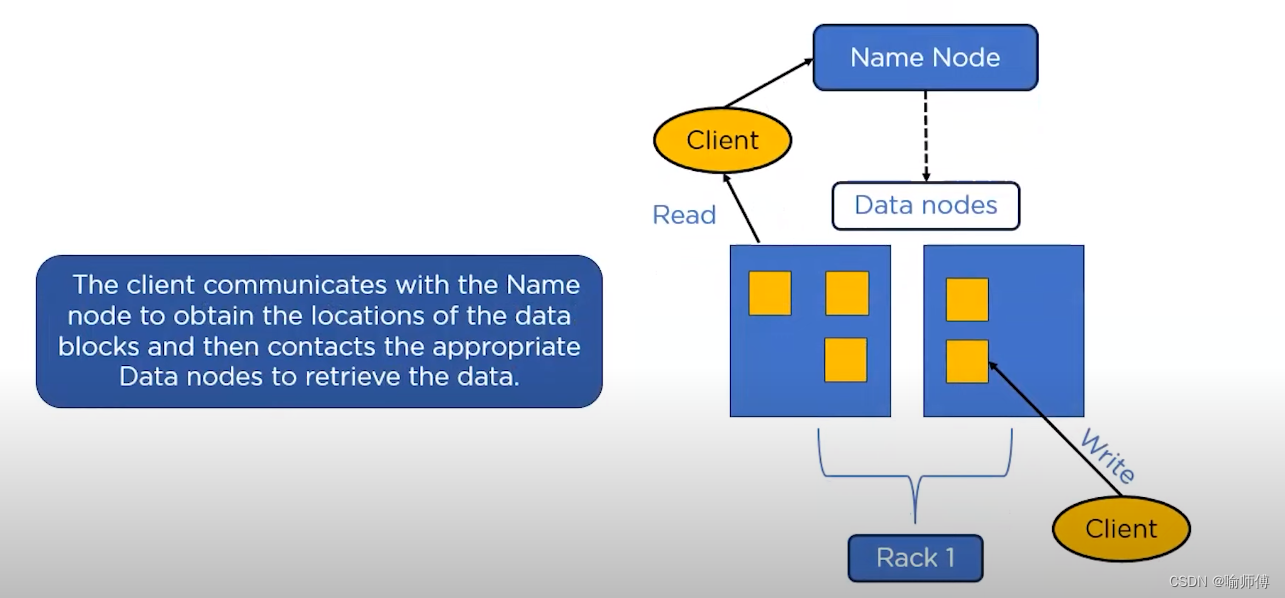
- datanode是文件系统的工作节点。
- 它们根据需要存储并检索数据块(受客户端或namenode 调度),并且定期向namenode发送它们所存储的块的列表。
- 没有namenode,文件系统将无法使用。
- 事实上,如果运行namenode服务的机器毁坏,文件系统上所有的文件将会丢失,因为我们不知道如何根据datanode的块重建文件。
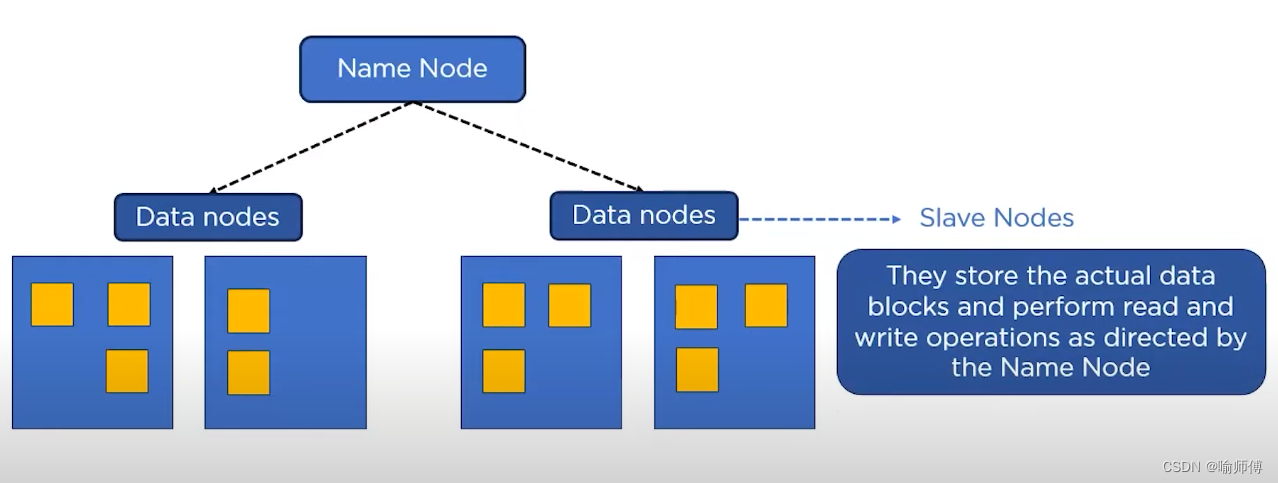
因此,对namenode实现容错非常重要,Hadoop为此提供两种机制。
- 第一种机制是备份那些组成文件系统元数据持久状态的文件。
- Hadoop可以通过配置使
namenode在多个文件系统上保存元数据的持久状态。 - 这些写操作是实时同步的,且是原子操作。一般的配置是,将持久状态写入本地磁盘的同时,写入一个远程挂载的网络文件系统(NFS)。
- Hadoop可以通过配置使

- 另一种可行的方法是运行一个辅助namenode,但它不能被用作namenode。
- 这个辅助namenode的重要作用是定期合并编辑日志与命名空间镜像,以防止编辑日志过大。
- 这个辅助namenode 一般在另一台单独的物理计算机上运行,因为它需要占用大量CPU时间,并且需要与namenode一样多的内存来执行合并操作。
- 它会保存合并后的命名空间镜像的副本,并在namenode发生故障时启用。
- 但是,辅助namenode保存的状态总是滞后于主节点,所以在主节点全部失效时,难免会丢失部分数据。

在这种情况下,一般把存储在NFS上的namenode元数据复制到辅助namenode 并作为新的主 namenode 运行。(注意,也可以运行热备份namenode 代替运行辅助namenode,具体参见3.2.5节对HDFS高可用性的讨论。)
块缓存
- 通常datanode从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被显式地缓存在 datanode的内存中,以堆外块缓存(off-heapblock cache)的形式存在。
- 默认情况下,一个块仅缓存在一个datanode的内存中,当然可以针每个文件配置datanode 的数量。
- 作业调度器(用于MapReduce、Spark 和其他框架的)通过在缓存块的 datanode上运行任务,可以利用块缓存的优势提高读操作的性能。例如,连接(join)操作中使用的一个小的查询表就是块缓存的一个很好的候选。
- 用户或应用通过在缓存池(
cache pool)中增加一个cache directive 来告诉 namenode需要缓存哪些文件及存多久。缓存池是一个用于管理缓存权限和资源使用的管理性分组。
联邦HDFS
这个是我看这本书第一次听说的🤣之前都没听过联邦HDFS。
namenode在内存中保存文件系统中每个文件和每个数据块的引用关系,这意味着对于一个拥有大量文件的超大集群来说,内存将成为限制系统横向扩展的瓶颈。
- 在2.x发行版本系列中引入的联邦HDFS允许系统通过添加
namenode实现扩展,其中每个namenode管理文件系统命名空间中的一部分。 - 例如,一个namenode 可能管理/user目录下的所有文件,而另一个namenode 可能管理/share 目录下的所有文件。
- 在联邦环境下,每个namenode维护一个命名空间卷(
namespace volume),由命名空间的元数据和一个数据块池(blockpool)组成,数据块池包含该命名空间下文件的所有数据块。 - 命名空间卷之间是相互独立的,两两之间并不相互通信,甚至其中一个namenode的失效也不会影响由其他namenode 维护的命名空间的可用性。数据块池不再进行切分,因此集群中的datanode需要注册到每个namenode,并且存储着来自多个数据块池中的数据块。
故障切换与规避
- 系统中有一个称为故障转移控制器(
failover controller)的新实体,管理着将活动namenode转移为备用namenode的转换过程。

-
有多种故障转移控制器,但默认的一种是使用了
ZooKeeper来确保有且仅有一个活动namenode。每一个namenode运行着一个轻量级的故障转移控制器,其工作就是监视宿主namenode是否失效(通过一个简单的心跳机制实现)并在namenode失效时进行故障切换。 -
管理员也可以手动发起故障转移,例如在进行日常维护时。这称为“平稳的故障转移”(
graceful failover),因为故障转移控制器可以组织两个namenode 有序地切换角色。 -
但在非平稳故障转移的情况下,无法确切知道失效namenode是否已经停止运行。
-
例如,在网速非常慢或者网络被分割的情况下,同样也可能激发故障转移,但是先前的活动namenode依然运行着并且依旧是活动amenode。
-
高可用实现做了更进一步的优化,以确保先前活动的namenode不会执行危害系统并导致系统崩溃的操作,该方法称为“规避”(
fencing)。
- 同一时间QJM 仅允许一个namenode 向编辑日志中写入数据。
- 然而,对于先前的活动namenode而言,仍有可能响应并处理客户过时的读请求,因此,设置一个SSH规避命令用于杀死namenode的进程是一个好主意。
- 当使用NFS过滤器实现共享编辑日志时,由于不可能同一时间只允许一个namenode写入数据(这也是为什么推荐QJM的原因),因此需要更有力的规避方法。
- 规避机制包括:撤销
namenode访问共享存储目录的权限(通常使用供应商指定的NFS命令)、通过远程管理命令屏蔽相应的网络端口。 - 诉诸的最后手段是,先前活动namenode可以通过一个相当形象的称为“一枪爆头”STONITH,shoot the other node in the head)的技术进行规避,该方法主要通过一个特定的供电单元对相应主机进行断电操作,客户端的故障转移通过客户端类库实现透明处理。
- 最简单的实现是通过客户端的配置文件实现故障转移的控制。HDFSURI使用一个逻辑主机名,该主机名映射到一对namenode地址(在配置文件中设置),客户端类库会访问每一个namenode地址直至处理完成。
HDFS中的文件访问权限
- 针对文件和目录,HDFS的权限模式与POSIX的权限模式非常相似。
- 一共提供三类权限模式:只读权限®、写入权限(w)和可执行权限(x)。
- 读取文件或列出目录内容时需要只读权限。
- 写入一个文件或是在一个目录上新建及删除文件或目录,需要写入权限。
- 对于文件而言,可执行权限可以忽略,因为你不能在 HDFS 中执行文件(与 POSIX 不同),但在访问一个目录的子项时需要该权限。
-
每个文件和目录都有所属用户(
owner)、所属组别(group)及模式(mode)。 -
这个模式是由所属用户的权限、组内成员的权限及其他用户的权限组成的。
-
在默认情况下,Hadoop 运行时安全措施处于停用模式,意味着客户端身份是没有经过认证的。
-
由于客户端是远程的,一个客户端可以在远程系统上通过创建和任一个合法用户同名的账号来进行访问。
-
当然,如果安全设施处于启用模式,这些都是不可能的。无论怎样,为防止用户或自动工具及程序意外修改或删除文件系统的重要部分,启用权限控制还是很重要的(这也是默认的配置,参见
dfs.permissions.enabled属性)。
如果启用权限检查,就会检查所属用户权限,以确认客户端的用户名与所属用户是否匹配,另外也将检查所属组别权限,以确认该客户端是否是该用户组的成员:若不符,则检查其他权限。
- 这里有一个超级用户(super-user)的概念,超级用户是namenode 进程的标识。
- 对于超级用户,系统不会执行任何权限检查。
3.4HDFS数据流
读取文件
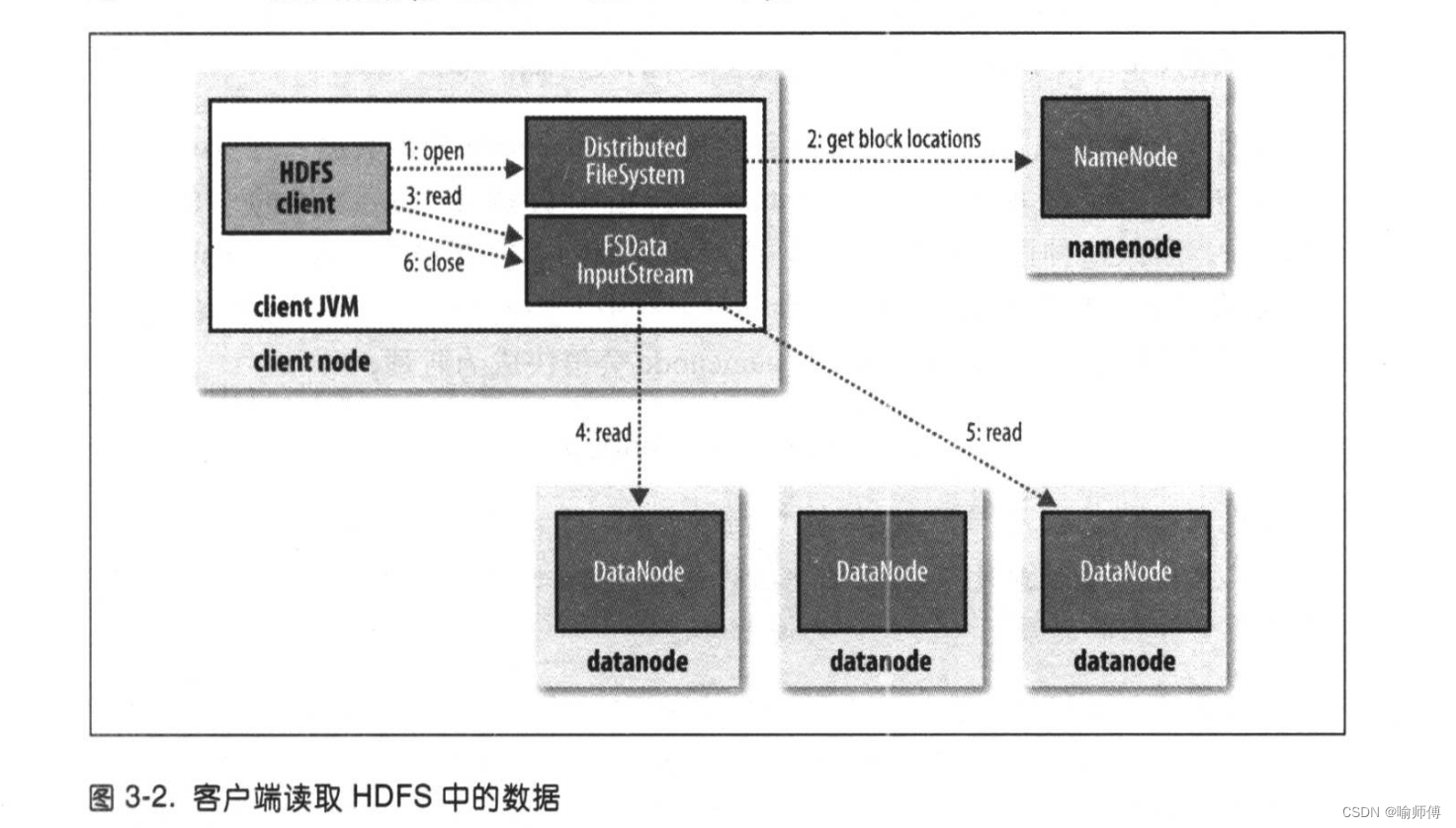
本节讲了一下HDFS的文件读取~
-
客户端通过调用Filesyste对象的open()方法来打开希望读取的文件,对于HDFS 来说,这个对象是DistributedFileSystem的一个实例(图 3-2 中的步骤1)。
-
DistributedFileSystem 通过使用远程过程调用(RPC)来调用namenode,以确定文件起始块的位置(步骤2)。
-
对于每一个块,namenode返回存有该块副本的datanode 地址。此外,这些datanode根据它们与客户端的距离来排序(根据集群的网络拓扑)。
-
如果该客户端本身就是一个datanode(比如,在一个MapReduce任务中),那么该客户端将会从保存有相应数据块复本的本地 datanode 读取数据。
- 在读取数据的时候,如果DFSInputstream在与datanode 通信时遇到错误,会尝试从这个块的另外一个最邻近datanode读取数据。
- 它也记住那个故障datanode,以保证以后不会反复读取该节点上后续的块。
- DFSInputstream也会通过校验和确认从 datanode 发来的数据是否完整。如果发现有损坏的块,DFSInputStream会试图从其他 datanode 读取其复本,也会将被损坏的块通知给namenode。
- 这个设计的一个重点是,客户端可以直接连接到datanode检索数据,且namenode告知客户端每个块所在的最佳datanode。
- 由于数据流分散在集群中的所有datanode,所以这种设计能使 HDFS 扩展到大量的并发客户端。同时,namenode只需要响应块位置的请求(这些信息存储在内存中,因而非常高效),无需响应数据请求,否则随着客户端数量的增长,namenode会很快成为瓶颈。
网络拓扑与Hadoop
- 在本地网络中,两个节点被称为“彼此近邻”是什么意思?
- 在海量数据处理中,其主要限制因素是节点之间数据的传输速率–带宽很稀缺。
- 这里的想法是将两个节点间的带宽作为距离的衡量标准。
- 不用衡量节点之间的带宽,实际上很难实现(它需要一个稳定的集群,并且在集群中两两节点对数量是节点数量的平方),Hadoop为此采用一个简单的方法:把网络看作一棵树,两个节点间的距离是它们到最近共同祖先的距离总和。
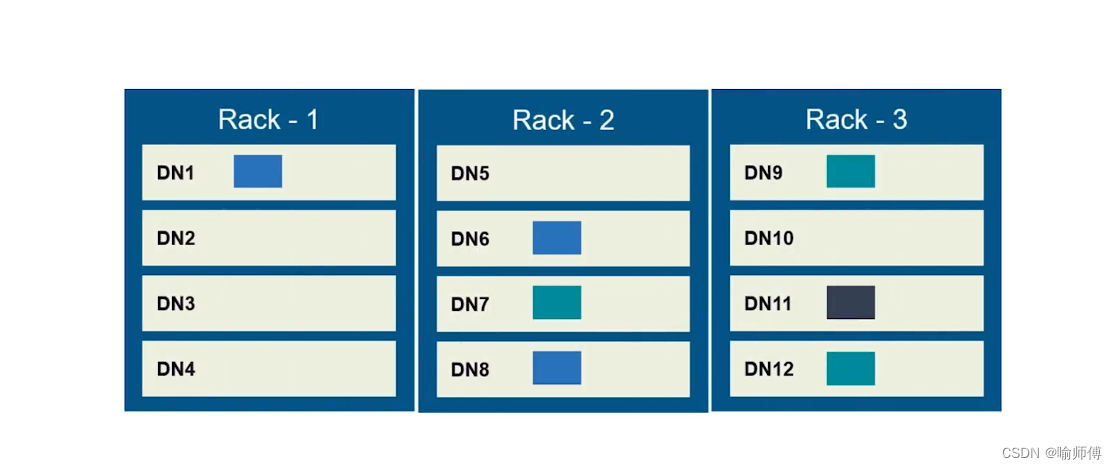
- 该树中的层次是没有预先设定的,但是相对于数据中心、机架和正在运行的节点,通常可以设定等级。具体想法是针对以下每个场景,可用带宽依次递减:

示例:


文件写入
接下来我们看看文件是如何写入HDFS的。
我们要考虑的情况是如何新建一个文件,把数据写入该文件,最后关闭该文件如图 3-4所示。
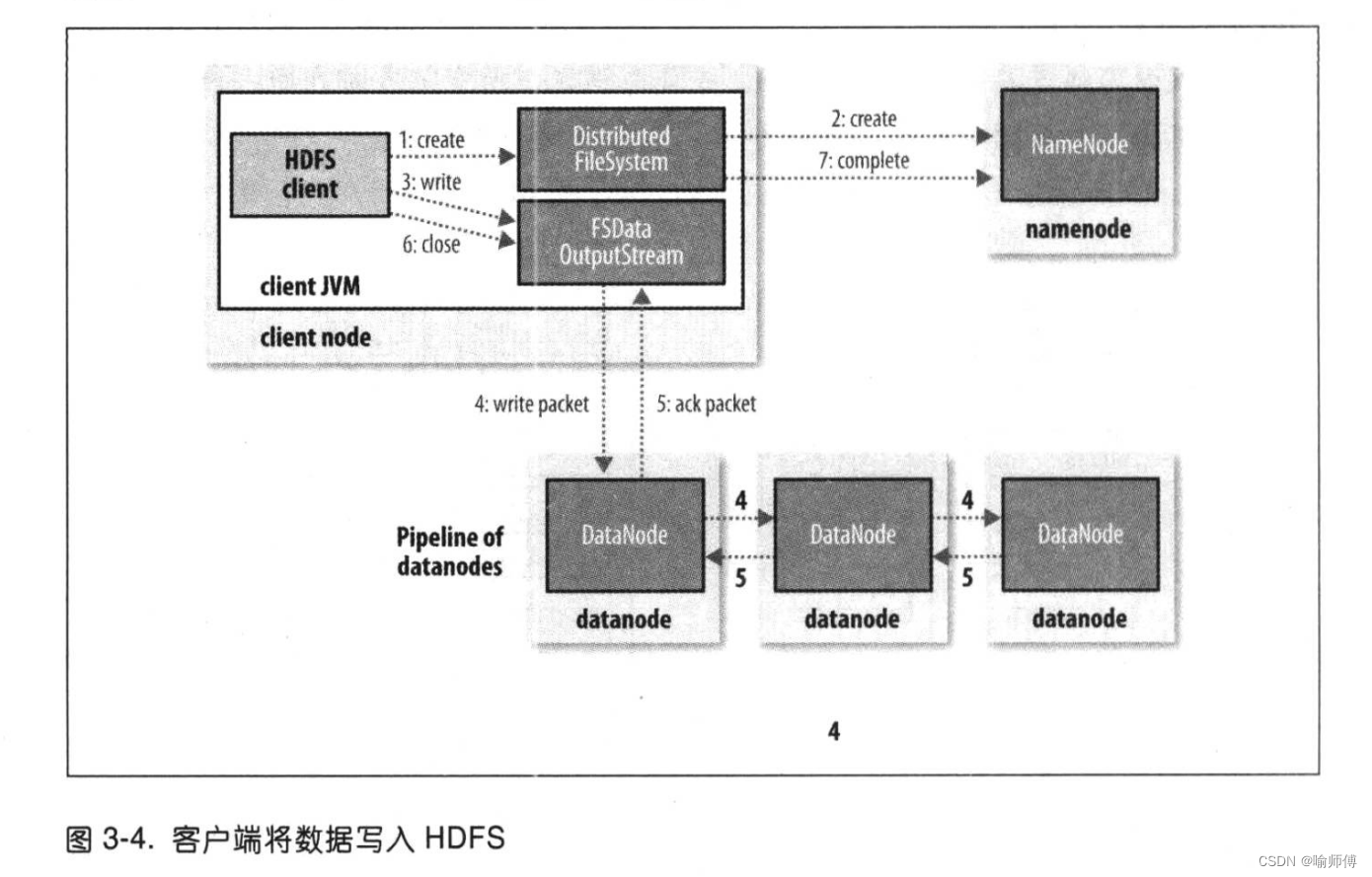
- 步骤一:
客户端通过对 Distributed FileSystem对象调用create()来新建文件(图 3-4中的步骤1)。
- 步骤二:
Distributed FileSystem对namenode 创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时该文件中还没有相应的数据块(步骤2)。
namenode执行各种不同的检查以确保这个文件不存在以及客户端有新建该文件的权限。
如果这些检查均通过,namenode就会为创建新文件记录一条记录;否则,文件创建失败并向客户端抛出一个 IOException异常。
Distributed FileSystem 向客户端返回一个 FSData 0utputstream对象,由此客户端可以开始写入数据。
就像读取事件一样,FSData0utputstream封装一个DFSoutPutstream对象,该对象负责处理 datanode 和 namenode 之间的通信。
- 步骤三:
在客户端写入数据时(步骤3),DFSOutputstream将它分成一个个的数据包,并写人内部队列,称为“数据队列”(data queue)。
Datastreamer处理数据队列,它的责任是挑选出适合存储数据复本的一组datanode,并据此来要求namenode分配新的数据块。
这一组datanode构成一个管线–我们假设复本数为3,所以管线中有3个节点。
- 步骤四:
Datastreamer将数据包流式传输到管线中第1个datanode,该datanode存储数据包并将它发送到管线中的第2个datanode。同样,第2个datanode存储该数据包并且发送给管线中的第3个(也是最后一个)datanode(步骤 4)。
DFSOutputStream也维护着一个内部数据包队列来等待datanode的收到确认回执,称为“确认队列”(ack queue)。
- 步骤五:
收到管道中所有datanode 确认信息后,该数据包才会从确认队列删除(步骤 5)。
-
如果任何datanode在数据写入期间发生故障,则执行以下操作(对写入数据的客户端是透明的)。
- 首先关闭管线,确认把队列中的所有数据包都添加回数据队列的最前端,以确保故障节点下游的datanode不会漏掉任何一个数据包。
- 为存储在另一正常 datanode 的当前数据块指定一个新的标识,并将该标识传送给namenode,以便故障datanode在恢复后可以删除存储的部分数据块。
- 从管线中删除故障datanode,基于两个正常datanode 构建一条新管线。余下的数据块写入管线中正常的 datanode。
- namenode 注意到块复本量不足时,会在另一个节点上创建一个新的复本。后续的数据块继续正常接受处理。
- 在一个块被写入期间可能会有多个datanode 同时发生故障,但非常少见。只要写入了dfs.namenode.replication.min 的复本数(默认为 1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标复本数(dfs.replication的默认值为 3)。
-
步骤六、七:
客户端完成数据的写入后,对数据流调用cose()方法(步6)。
该操作将剩余的所有数据包写入datanode管线,并在联系到namenode告知其文件写入完成之前,等待确认(步骤 7)。
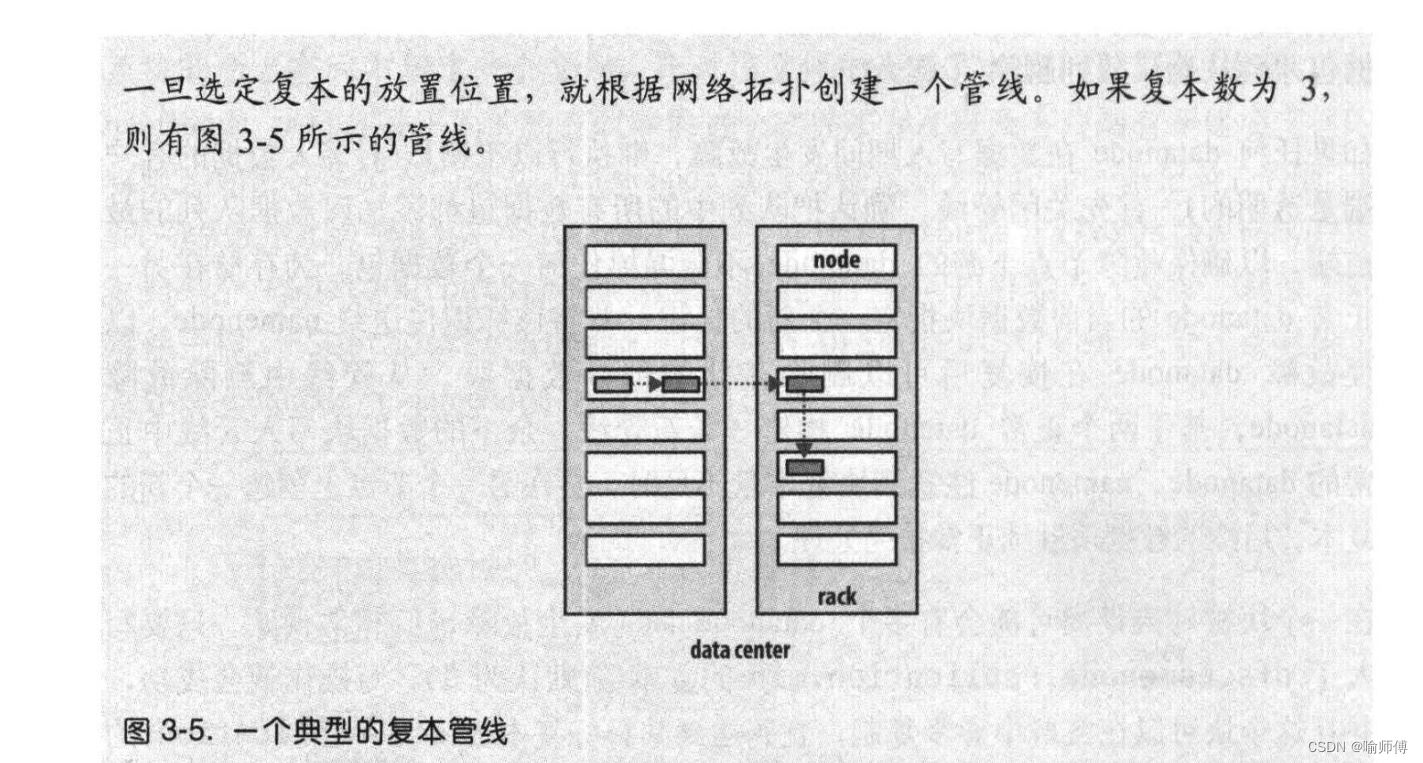
副本怎么存放?
namenode 如何选择在哪个 datanode 存储复本(replica)?
- 这里需要对可靠性、写入带宽和读取带宽进行权衡。
- 例如,把所有复本都存储在一个节点损失的写入带宽最小(因为复制管线都是在同一节点上运行),但这并不提供真实的冗余(如果节点发生故障,那么该块中的数据会丢失)。
- 同时,同一机架上服务器间的读取带宽是很高的。
- 另一个极端,把复本放在不同的数据中心可以最大限度地提高冗余,但带宽的损耗非常大。
即使在同一数据中心(到目前为止,所有Hadoop 集群均运行在同一数据中心内),也有多种可能的数据布局策略。
-
Hadoop 的默认布局策略是在运行客户端的节点上放第1个复本(如果客户端运行在集群之外,就随机选择一个节点,不过系统会避免挑选那些存储太满或太忙的节点)。
-
第2个复本放在与第一个不同且随机另外选择的机架中节点上(离架)。
-
第3个复本与第2个复本放在同一个机架上,且随机选择另一个节点。
-
其他复本放在集群中随机选择的节点上,不过系统会尽量避免在同一个的机架上放太多复本。

相关文章:
Hadoop权威指南-读书笔记-03-Hadoop分布式文件系统
Hadoop权威指南-读书笔记 记录一下读这本书的时候觉得有意思或者重要的点~ 还是老样子~挑重点记录哈😁有兴趣的小伙伴可以去看看原著😊 第三章 Hadoop分布式文件系统 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分…...

Rust入门实战 编写Minecraft启动器#2建立资源模型
首发于Enaium的个人博客 我们需要声明几个结构体来存储游戏的资源信息,之后我们需要将json文件解析成这几个结构体,所以我们需要添加serde依赖。 serde { version "1.0", features ["derive"] }资源相关asset.rs use serde::De…...

小白学C++(第一天)基础入门
温馨提醒:本篇文章,请各位c基础不行的童鞋不要贸然观看 C的第一个程序 第一个关键字namespace namespace 是定义空间的名字的关键字,使用格式格式如下: namespace 空间名 { } 其中{ }内的命名空间的成员,可以定义…...

谷歌正在试行人脸识别办公室安全系统
内容提要: 🧿据美国消费者新闻与商业频道 CNBC 获悉,谷歌正在为其企业园区安全测试面部追踪技术。 🧿测试最初在华盛顿州柯克兰的一间办公室进行。 🧿一份内部文件称,谷歌的安全和弹性服务 (GSRS) 团队将…...

【CSS01】CSS概述,使用样式的必要性,CSS语法及选择器
文章目录 一、什么是样式二、使用样式的必要性三、使用样式的几种方式四、CSS基本语法:五、CSS的注释六、CSS选择器——重点相关单词 一、什么是样式 概念: Cascade [kˈskeɪd] Style Sheet [ʃiːt] 级联样式单/表,层叠样式表 CSS有化腐…...

PostgreSQL的pg_bulkload工具
PostgreSQL的pg_bulkload工具 pg_bulkload 是一个针对 PostgreSQL 提供高性能批量数据加载的工具。相较于内置的 COPY 命令,pg_bulkload 更加灵活并且在许多情况下性能更高。它支持数据的强制加载、数据过滤、数据转换以及错误处理等多种功能,非常适合需…...

【Java伴学笔记】Day-01 命令行|环境|编译解释运行|Java的相关分支|Java的特性|字面量
一、关于命令行 图形化界面的缺点 需要加载图片等一系列资源 效率较低 命令行 CMDMicrosoft Learn-CMDWindows CMD常用命令大全(值得收藏) 二、环境 什么是JDK JDK是Java Development Kit的缩写,意为Java开发工具包。它是一个用于开发Java应用…...
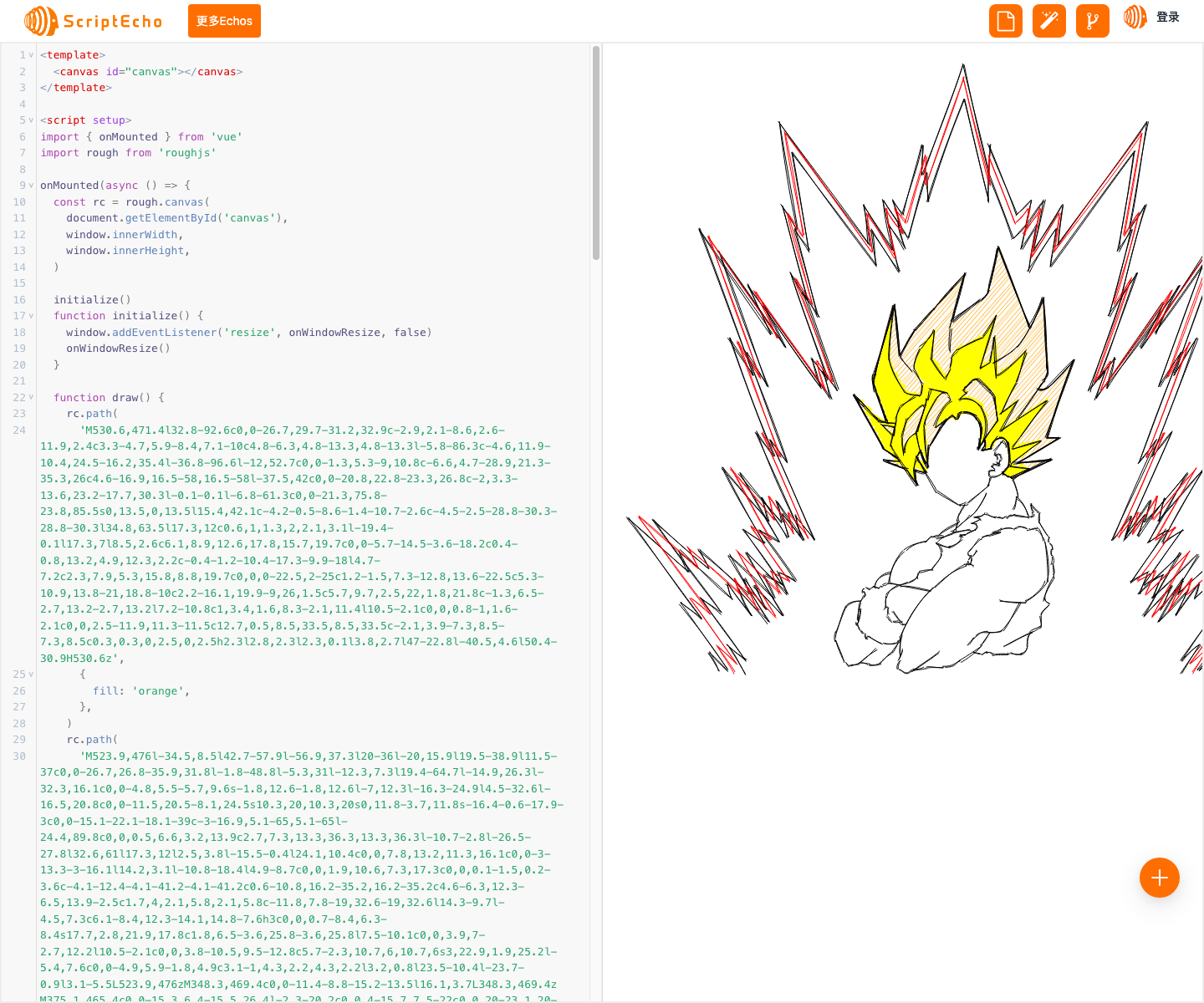
如何使用Vue3创建在线三维模型展示?
本文由ScriptEcho平台提供技术支持 项目地址:传送门 代码相关的技术博客 代码应用场景介绍 本段代码使用 RoughJS 库在 HTML5 Canvas 上创建了手绘风格的图像,展示了 RoughJS 库的强大功能,可用于创建具有有机手绘外观的图形。 代码基本…...
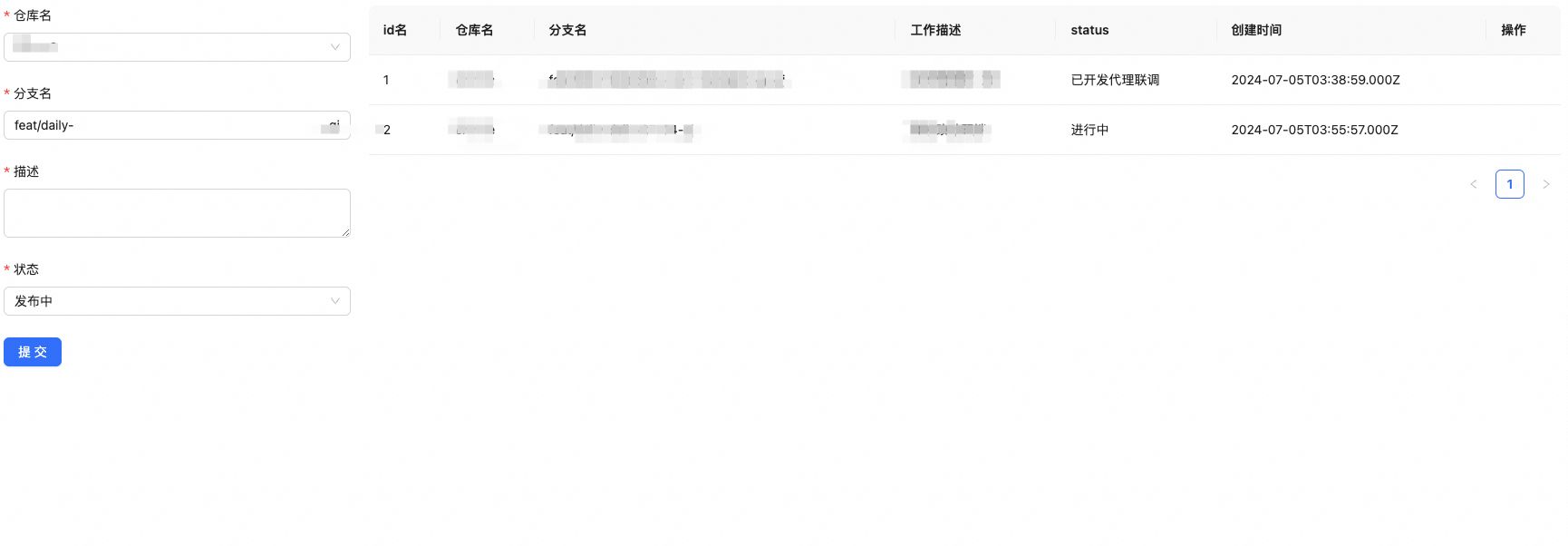
使用ndoe实现自动化完成增删改查接口
使用ndoe实现自动化完成增删改查接口 最近工作内容比较繁琐,手里需要开发的项目需求比较多,常常在多个项目之间来回切换,有时候某些分支都不知道自己开发了什么、做了哪些需求, 使用手写笔记的方式去记录分支到头来也是眼花缭乱&a…...

排序 -- 手撕归并排序(递归和非递归写法)
一、基本思想 归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有…...

防火墙基础及登录(华为)
目录 防火墙概述防火墙发展进程包过滤防火墙代理防火墙状态检测防火墙UTM下一代防火墙(NGFW) 防火墙分类按物理特性划分软件防火墙硬件防火墙 按性能划分百兆级别和千兆级别 按防火墙结构划分单一主机防火墙路由集成式防火墙分布式防火墙 华为防火墙利用…...

【Vue】使用html、css实现鱼骨组件
文章目录 预览图组件测试案例 预览图 组件 <template><div class"context"><div class"top"><div class"label-context"><div class"label" v-for"(item, index) in value" :key"index&qu…...

Python的多态
在 Python 中,多态(Polymorphism)是指不同的对象可以对相同的消息(方法调用)做出不同的响应。 简单来说,多态允许使用一个统一的接口来操作不同类型的对象,而这些对象会根据自身的类型来执行相应…...

001uboot体验
1.uboot的作用: 上电->uboot启动->关闭看门狗、初始化时钟、sdram、uart等外设->把内核文件从flash读取到SDRAM->引导内核启动->挂载根文件系统->启动根文件系统的应用程序 2.uboot编译 uboot是一个通用的裸机程序,为了适应各种芯片&…...

Flask之电子邮件
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 目录 一、使用Flask-Mail发送电子邮件 1.1、配置Flask-Mail 1.2、构建邮件数据 1.3、发送邮件 二、使用事务邮件服务SendGrid 2.1、注册SendGr…...

Vue 2 与 ECharts:结合使用实现动态数据可视化
在现代前端开发中,数据可视化变得越来越重要。ECharts 是一个强大的数据可视化库,而 Vue 2 则是一个流行的前端框架。本文将介绍如何将 Vue 2 和 ECharts 结合使用,以实现动态数据可视化。 安装与配置 首先,确保你的项目中已经安…...

.net core Redis 使用有序集合实现延迟队列
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。 不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。 有序集合的成员是唯一的,但分数(score)却可以重复。 集合是通过哈希表实现的…...
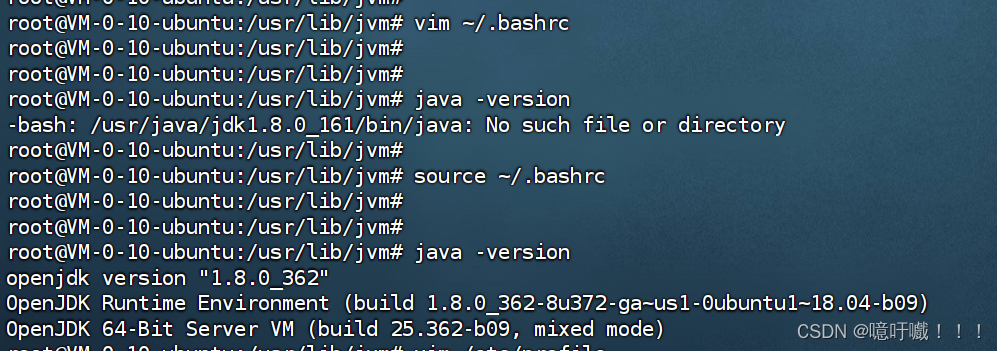
linux 安装Openjdk1.8
一、在线安装 1、更新软件包 sudo apt-get update 2、安装openjdk sudo apt-get install openjdk-8-jdk 3、配置openjdk1.8 openjdk默认会安装在/usr/lib/jvm/java-8-openjdk-amd64 vim ~/.bashrc export JAVA_HOME/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME${J…...

鸿蒙系统:未来智能生态的引领者
在当今这个日新月异的互联网领域,操作系统作为连接硬件与软件的桥梁,其重要性不言而喻。随着华为鸿蒙系统(HarmonyOS)的崛起,一场关于操作系统未来的讨论再次被推向高潮。 鸿蒙OS,华为的全新力作ÿ…...

Java语言程序设计——篇二(1)
Java语言基础 数据类型关键字与标识符关键字标识符 常量与变量1、常量2、变量 类型转换自动类型转换强制类型转换 数据类型 数据的基本要素数据的性质(数据结构)数据的取值范围(字节大小)数据的存储方式参与的运算 Java是一门强类…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

OpenClaw 连接阿里云百炼图文教程
OpenClaw 连接阿里云百炼图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已准备好可正常登录的阿里云账号。 可以正常访问阿里云百炼登录地址:https://bailian.console.aliyun.com/cn-beijing#/home 建议提…...
损坏诊断全解)
半导体元件(二极管/三极管/MOS管/IC)损坏诊断全解
半导体元件(二极管、三极管、MOS 管、集成电路)是 PCB 的核心功能单元,对过压、过流、ESD、高温极度敏感,损坏后直接导致电路功能失效、短路烧板。很多工程师维修时盲目更换芯片,不仅成本高,还易误判。一…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理?
League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理? 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit Leag…...