ChatGPT相关技术必读论文100篇(2.27日起,几乎每天更新)
按上篇文章《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT-N、instructGPT》的最后所述
为了写本ChatGPT笔记,过去两个月翻了大量中英文资料/paper(中间一度花了大量时间去深入RL),大部分时间读的更多是中文资料
2月最后几天读的更多是英文paper,正是2月底这最后几天对ChatGPT背后技术原理的研究才真正进入状态(后还组建了一个“ChatGPT之100篇论文阅读组”,我和10来位博士、业界大佬从23年2.27日起100天读完ChatGPT相关技术的100篇论文),当然 还在不断深入,由此而感慨:
- 读的论文越多,你会发现大部分人对ChatGPT的技术解读都是不够准确或全面的,毕竟很多人没有那个工作需要或研究需要,去深入了解各种细节
- 因为100天100篇这个任务,让自己有史以来一篇一篇一行一行读100篇,之前看的比较散 不系统 抠的也不细
比如回顾“Attention is all you need”这篇后,对优化博客内的Transformer笔记便有了很多心得总之,读的论文越多,博客内相关笔记的质量将飞速提升 自己的技术研究能力也能有巨大飞跃
且考虑到为避免上篇文章篇幅太长而影响完读率,故把这100论文的清单抽取出来独立成本文
- Attention Is All You Need,Transformer原始论文
- GPT:Improving Language Understanding by Generative Pre-Training
GPT2:Language Models are Unsupervised Multitask Learners - GPT3原始论文:Language Models are Few-Shot Learners
- ICL原始论文
- Evaluating Large Language Models Trained on Code,Codex原始论文
预测当前序列的最后一个词时 可以选取概率最大的词(softmax最高的值),但没法全局最优且不具备多样性,当然 可以使用束搜索 一次性获取多个解
论文中用的是核采样,预测的各个词根据概率从大到小排序,选取前些个概率加起来为95%的词 - CoT原始论文:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
28 Jan 2022 · Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou
也从侧面印证,instructGPT从22年1月份之前 就开始迭代了 - Training language models to follow instructions with human feedback
InstructGPT原始论文 -
RLHF原始论文 - PPO原始论文
- 《Finetuned Language Models Are Zero-Shot Learners》,2021年9月Google提出FLAN大模型,其基于Instruction Fine-Tuning
FLAN is the instruction-tuned version of LaMDA-PT - Scaling Instruction-Finetuned Language Models,Flan-T5(2022年10月)
从三个方面改变指令微调,一是改变模型参数,提升到了540B,二是增加到了1836个微调任务,三是加上Chain of thought微调的数据 - LLaMA: Open and Efficient Foundation Language Models,2023年2月Meta发布了全新的650亿参数大语言模型LLaMA,开源,大部分任务的效果好于2020年的GPT-3
- Language Is Not All You Need: Aligning Perception with Language Models,微软23年3月1日发布的多模态大语言模型论文
- GLM: General Language Model Pretraining with Autoregressive Blank Infilling,国内唐杰团队的
-
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT:https://arxiv.org/pdf/2302.09419,预训练基础模型的演变史 - LaMDA: Language Models for Dialog Applications,Google在21年5月对外宣布内部正在研发对话模型LaMDA
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing,作者来自CMU的刘鹏飞,这是相关资源
- Multimodal Chain-of-Thought Reasoning in Language Models
23年2月,亚马逊的研究者则在这篇论文里提出了基于多模态思维链技术改进语言模型复杂推理能力的思想 - Offsite-Tuning: Transfer Learning without Full Model
对于许多的私有基础模型,数据所有者必须与模型所有者分享他们的数据以微调模型,这是非常昂贵的,并引起了隐私问题(双向的,一个怕泄露模型,一个怕泄露数据) - Emergent Abilities of Large Language Models
Google 22年8月份发的,探讨大语言模型的涌现能力 -
Large Language Models are Zero-Shot Reasoners
来自东京大学和谷歌的工作,关于预训练大型语言模型的推理能力的探究,“Let's think step by step”的梗即来源于此篇论文 - PaLM: Scaling Language Modeling with Pathways,这是翻译之一
22年4月发布,是Google的Pathways架构或openAI GPT2/3提出的小样本学习的进一步扩展 - PaLM-E: An Embodied Multimodal Language Model,Google于23年3月6日发布的关于多模态LLM
- Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models,微软于23年3月8日推出visual ChatGPT(另,3.9日微软德国CTO说,将提供多模态能力的GPT4即将一周后发布)
At the same time, Visual Foundation Models, such as Visual Transformers or Stable Diffusion, although showing great visual understanding and generation capabilities, they are only experts on specific tasks with one round fixed inputs and outputs.
To this end, We build a system called {Visual ChatGPT}, incorporating different Visual Foundation Models, to enable the user to interact with ChatGPT by
1) sending and receiving not only languages but also images
2) providing complex visual questions or visual editing instructions that require the collaboration of multiple AI models with multi-steps.
3) providing feedback and asking for corrected results.
We design a series of prompts to inject the visual model information into ChatGPT, considering models of multiple inputs/outputs and models that require visual feedback - 《The Natural Language Decathlon:Multitask Learning as Question Answering》,GPT-1、GPT-2论文的引用文献,Salesforce发表的一篇文章,写出了多任务单模型的根本思想
- Deep Residual Learning for Image Recognition,ResNet论文,短短9页,Google学术被引现15万多
这是李沐针对ResNet的解读,另 这是李沐针对一些paper的解读列表 - The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
-
AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
Transformer杀入CV界 - Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer V2: Scaling Up Capacity and Resolution
第一篇的解读戳这,第二篇的解读戳这里 - Denoising Diffusion Probabilistic Models
2020年提出Diffusion Models(所谓diffusion就是去噪点的意思) - CLIP: Connecting Text and Images - OpenAI
CLIP由OpenAI在2021年1月发布,超大规模模型预训练提取视觉特征,图片和文本之间的对比学习(简单粗暴理解就是发微博/朋友圈时,人喜欢发一段文字然后再配一张或几张图,CLIP便是学习这种对应关系)
2021年10月,Accomplice发布的disco diffusion,便是第一个结合CLIP模型和diffusion模型的AI开源绘画工具,其内核便是采用的CLIP引导扩散模型(CLIP-Guided diffusion model) - Hierarchical Text-Conditional Image Generation with CLIP Latents
DALL.E 2论文2022年4月发布(至于第一代发布于2021年初),通过CLIP + Diffusion models,达到文本生成图像新高度 - High-Resolution Image Synthesis with Latent Diffusion Models
2022年8月发布的Stable Diffusion基于Latent Diffusion Models,专门用于文图生成任务
Stable Diffusion和之前的Diffusion扩散化模型相比, 重点是做了一件事, 那就是把模型的计算空间,从像素空间经过数学变换,在尽可能保留细节信息的情况下降维到一个称之为潜空间(Latent Space)的低维空间里,然后再进行繁重的模型训练和图像生成计算
这些是相关解读:图解stable diffusion(翻译版之一)、这是另一解读,这里有篇AI绘画发展史的总结 - Aligning Text-to-Image Models using Human Feedback,这是解读之一
ChatGPT的主要成功要归结于采用RLHF来精调LLM,近日谷歌AI团队将类似的思路用于文生图大模型:基于人类反馈(Human Feedback)来精调Stable Diffusion模型来提升生成效果
目前的文生图模型虽然已经能够取得比较好的图像生成效果,但是很多时候往往难以生成与输入文本精确匹配的图像,特别是在组合图像生成方面。为此,谷歌最新的论文提出了基于人类反馈的三步精调方法来改善这个问题 -
SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions,代码地址
3月中旬,斯坦福发布Alpaca:只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型
而斯坦福团队微调LLaMA的方法,便是来自华盛顿大学Yizhong Wang等去年底提出的这个Self-Instruct具体而言,论文中提出,首先从自生成指令种子集中的175个人工编写的「指令-输出」对开始,然后,提示text-davinci-003使用种子集作为上下文示例来生成更多指令
而斯坦福版Alpaca,就是花了不到500美元使用OpenAI API生成了5.2万个这样的示例微调LLaMA搞出来的 -
Constitutional AI: Harmlessness from AI Feedback
OpenAI之前一副总裁离职搞了个ChatGPT的竞品,ChatGPT用人类偏好训练RM再RL(即RLHF),Claude则基于AI偏好模型训练RM再RL(即RLAIF) -
Improving alignment of dialogue agents via targeted human judgements
DeepMind的Sparrow,这个工作发表时间稍晚于instructGPT,其大致的技术思路和框架与 instructGPT 的三阶段基本类似,但Sparrow 中把奖励模型分为两个不同 RM 的思路 -
Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers代码地址,这篇文章则将ICL看作是一种隐式的Fine-tuning
-
WHAT LEARNING ALGORITHM IS IN-CONTEXT LEARNING? INVESTIGATIONS WITH LINEAR MODELS
-
Meta-learning via Language Model In-context Tuning
-
// 23年2.27日起,本榜单几乎每天更新中
相关文章:
)
ChatGPT相关技术必读论文100篇(2.27日起,几乎每天更新)
按上篇文章《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT-N、instructGPT》的最后所述 为了写本ChatGPT笔记,过去两个月翻了大量中英文资料/paper(中间一度花了大量时间去深入RL),大部分时间读的更多是中文资料 2月最后几天读的更多是英文…...
【算法】算法题解---电话号码的字符组合
算法名称 电话号码的字符组合 算法描述 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 示例 1: 输入&…...
提高上限之数学学习——数制转换及MECE原则学习
文章目录数制转换不同数制表达数制转换的方法换基法(换向十进制)除余法(十进制向其他进制转换)按位拆分法和按位合并法判断一个整数a,是否是2的整数次幂MECE原则学习数制转换 不同数制表达 数制转换的方法 换基法(换向十进制) 定义:给出数制转换的定量…...

字符函数和字符串函数(下)——“C”
各位CSDN的uu们你们好呀,今天小雅兰的内容依旧是字符函数和字符串函数呀,这篇博客会讲一些内存相关的函数,下面,让我们进入字符函数和字符串函数的世界吧 字符串查找 strstr strtok 错误信息报告 strerror 字符操作 内存操作函…...
kafka docker 安装
先启动起 zookeeper (1)服务: 192.168.190.35docker run -d --name kafka1 \-p 9092:9092 \-e KAFKA_BROKER_ID0 \-e delete.topic.enabletrue \-e num.partitions1 \-e KAFKA_ZOOKEEPER_CONNECT192.168.192.35:2181 \-e KAFKA_ADVERTISED_LI…...

SpringBean管理
一.什么是SpringBean? 在Spring中将管理对象称为 Bean.Bean是由一个SpringIOC容器实例化,组装和管理的对象.也就是说,Bean并不是由我们程序员编写的,而是在程序运行过程中,由Spring通过反射机制生成的. SpringBean是Spring框架在运行时管理的对象,我们编写的大多数逻辑代码都…...

关于Vue3中reactive的意义
在学习Vue3的时候产生疑问: const addForm reactive({ // 这里面的reactive啥意思sysPre: null,diaPre: null,tem: null })查询解决 在Vue3中,响应式对象是指通过reactive函数转换而来的对象,它的属性可以被Vue自动监测,当属性…...

平衡三进制
平衡三进制 一、定义 平衡三进制,也称为对称三进制。这是一个不太标准的 计数体系。 正规的三进制的数字都是由 0,1,2 构成的,而平衡三进制的数字是由 -1,0,1 构成的。它的基数也是 3(因为有三个可能的值)。由于将 -1 写成数字…...

python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据。正好之前学了python,练练手。 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了。 Unicode是一种编码方案,又称万国码…...

CSS的三大特性
🌟所属专栏:前端只因变凤凰之路🐔作者简介:rchjr——五带信管菜只因一枚😮前言:该系列将持续更新前端的相关学习笔记,欢迎和我一样的小白订阅,一起学习共同进步~👉文章简…...
Linux-scheduler之负载均衡(二)
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sched_domain_topology_level {sched_domain_mask_f mask; //函数指针,用于指定某个SDTL的cpumask位图sched_domain_flags_f sd_flags; //函数指针,用于指定某个SD…...
VScode第三方插件打开sqlite数据库
文章目录前言对比1.文本文件、表格软件打开2.专业软件3.pythonVScode 第三方库打开数据库1. 下载第三方库插件2.打开sqlite新建查询3.输入查询内容前言 最近在做的东西涉及SQLite数据库(一种常用在移动端的数据库类型,和mysql这些主流数据库也差不多&am…...

Kafka 监控
Kafka 监控主机监控JVM 监控集群监控监控 Kafka 客户端主机监控 主机监控 : 监控 Kafka 集群 Broker 所在的节点机器的性能 主机监控指标 : 机器负载 (Load) , CPU 使用率内存使用率 (空闲内存 , 已使用内存 (Used Memory) )磁盘 I/O 使用率 (读使用率/ 写使用率) , 网络 I/…...
MultipartFile与File的互转
MultipartFile与File的互转前言MultipartFile转File1.FileUtils.copyInputStreamToFile转换2.multipartFile.transferTo(tempFile);3. (推荐)FileUtils.writeByteArrayToFile(file, multipartFile.getBytes());File转MultipartFile前言 需求是上传Excel文件并读取E…...
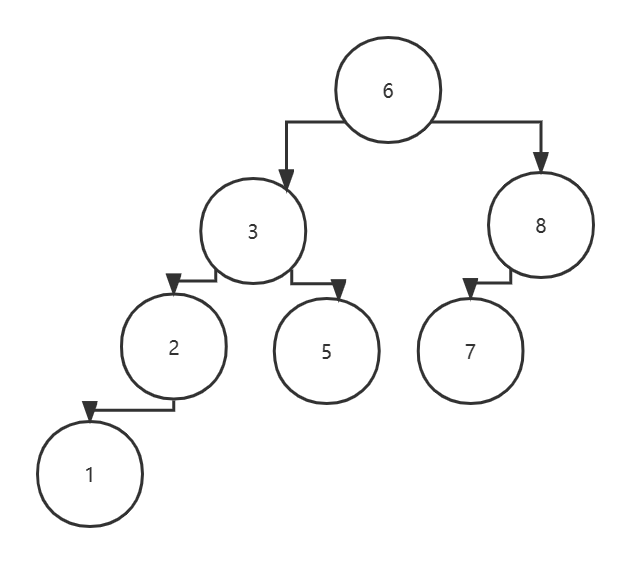
数据结构与算法基础-学习-15-二叉树
一、二叉树定义二叉树是N(N>0)个节点的有限集,它可能是空集或者由一个根节点及两棵互不相交的分别称作这个根的左子树和右子树的二叉树组成。二、二叉树特点1、每个节点最多两个孩子。(也就是二叉树的度小于等于2)2…...
接口测试要测试什么?
一. 什么是接口测试?为什么要做接口测试? 接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互…...

2023.03.12学习总结
项目部分写了内外菜单栏的伸缩,更新了导航栏,新增配置,scss变量 提交记录 学习了scss的使用和配置 ,设置了scss全局变量,组件样式 给element-plus配置了主题颜色,配置到了全局 http://t.csdn.cn/FhZYa …...

数据结构入门6-1(图)
目录 注 图的定义 图的基本术语 图的类型定义 图的存储结构 邻接矩阵 1. 邻接矩阵表示法 2. 使用邻接矩阵表示法创建无向网 3. 邻接矩阵表示法的优缺点 邻接表 1. 邻接表表示法 2. 通过邻接表表示法创建无向图 3. 邻接表表示法的优缺点 十字链表(有向…...
把C#代码上传到NuGet,大佬竟是我自己!!!
背景 刚发表完一篇博客总结自己写标准化C#代码的心历路程,立马就产生一个问题,就是我写好标准化代码后,一直存放磁盘的话,随着年月增加,代码越来越多,项目和版本的管理就会成为一个令我十分头疼的难题&…...

解决前端“\n”不换行问题
在日常开发过程中,换行显示是一种很常见的应用需求,但是偶然发现,有时候使用 "\n"并不会换行显示,只会被识别为空格,如下图。 通过上图可以看出,"\n"它被识别成了一个空格显示&#…...

Midjourney咖啡印相落地实操:3步完成色彩校准、5种纸张适配方案与打印机ICC配置清单
更多请点击: https://intelliparadigm.com 第一章:Midjourney Coffee印相技术原理与工艺边界 Midjourney Coffee印相并非官方命名的技术标准,而是社区对一类融合生成式AI图像(如Midjourney输出)与传统咖啡渍显影工艺的…...

轻量级代码同步工具codesyncer:P2P架构实现跨设备实时同步
1. 项目概述:一个被低估的代码同步利器如果你和我一样,经常需要在多台开发机、服务器甚至不同的云环境之间同步代码片段、配置文件或者小型项目,那你一定对那种“这台机器上有,那台机器上没有”的混乱感同身受。手动复制粘贴&…...

SIGTRAN协议:电信网络IP化的关键技术解析
1. SIGTRAN:下一代电信网络的信令传输基石2003年全球电信业寒冬中,一个技术决策正在悄然改变行业格局。当运营商们紧缩资本开支时,AT&T、Verizon等巨头却不约而同地加大了对IP网络的投入。这背后隐藏着一个关键技术转折——传统TDM网络向…...

告别模拟开关:用TLC7528双DAC为你的STM32项目扩展模拟输出通道
告别模拟开关:用TLC7528双DAC为你的STM32项目扩展模拟输出通道 在嵌入式系统开发中,模拟信号输出是许多控制系统的核心需求。无论是精密仪器、工业自动化还是音频处理,都需要稳定可靠的模拟输出通道。然而,大多数STM32微控制器内置…...
)
使用 LikeShop 搭建商城的完整流程(从0到上线)
先说结论用 LikeShop 搭建商城,本质可以拆成 5 步:👉 部署系统 → 配置基础 → 上架商品 → 打通交易 → 引流运营只要这 5 步跑通,就可以实现“可正常卖货”的商城。一、准备阶段(很多人会忽略)在动手之前…...

一台电脑变四台主机:Nucleus Co-Op如何让单人游戏秒变多人派对?
一台电脑变四台主机:Nucleus Co-Op如何让单人游戏秒变多人派对? 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 想象一下&a…...
)
PyTorch预训练模型‘解剖课’:以VGG19为例,彻底搞懂如何自定义输出层(避坑指南)
PyTorch预训练模型‘解剖课’:以VGG19为例,彻底搞懂如何自定义输出层(避坑指南) 当你第一次拿到一个预训练好的VGG19模型,兴奋地准备用它提取图像特征时,却发现自己被卡在了第一步——这个"黑箱"…...

51单片机内存空间全解析:从data、xdata到far,手把手教你用Keil C51访问任意地址
51单片机内存空间全解析:从data、xdata到far,手把手教你用Keil C51访问任意地址 在嵌入式开发领域,51单片机因其经典架构和广泛的应用基础,依然是许多工程师入门的首选。然而,当开发者从简单的GPIO控制进阶到复杂的内存…...
)
【UWB-IMU、UWB定位】【UWB-IMU】融合仅具有测距和6轴IMU传感器数据的位置信息研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
Gemini Deep Research调用失败?5类报错代码详解+官方未公开的API绕过方案(限时技术内参)
更多请点击: https://intelliparadigm.com 第一章:Gemini Deep Research功能怎么用 Gemini Deep Research 是 Google 推出的面向专业研究者的增强型推理能力模块,专为长上下文分析、跨文档信息整合与假设验证设计。启用该功能需通过 Gemini …...