力扣-dfs
何为深度优先搜索算法?
深度优先搜索算法,即DFS。就是找一个点,往下搜索,搜索到尽头再折回,走下一个路口。
695.岛屿的最大面积
695. 岛屿的最大面积
题目
给你一个大小为
m x n的二进制矩阵grid。岛屿 是由一些相邻的
1(代表土地) 构成的组合,这里的「相邻」要求两个1必须在 水平或者竖直的四个方向上 相邻。你可以假设grid的四个边缘都被0(代表水)包围着。岛屿的面积是岛上值为
1的单元格的数目。计算并返回
grid中最大的岛屿面积。如果没有岛屿,则返回面积为0。示例 1:
输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]] 输出:6 解释:答案不应该是 11 ,因为岛屿只能包含水平或垂直这四个方向上的 1。示例 2:
输入:grid = [[0,0,0,0,0,0,0,0]] 输出:0提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 50grid[i][j]为0或1
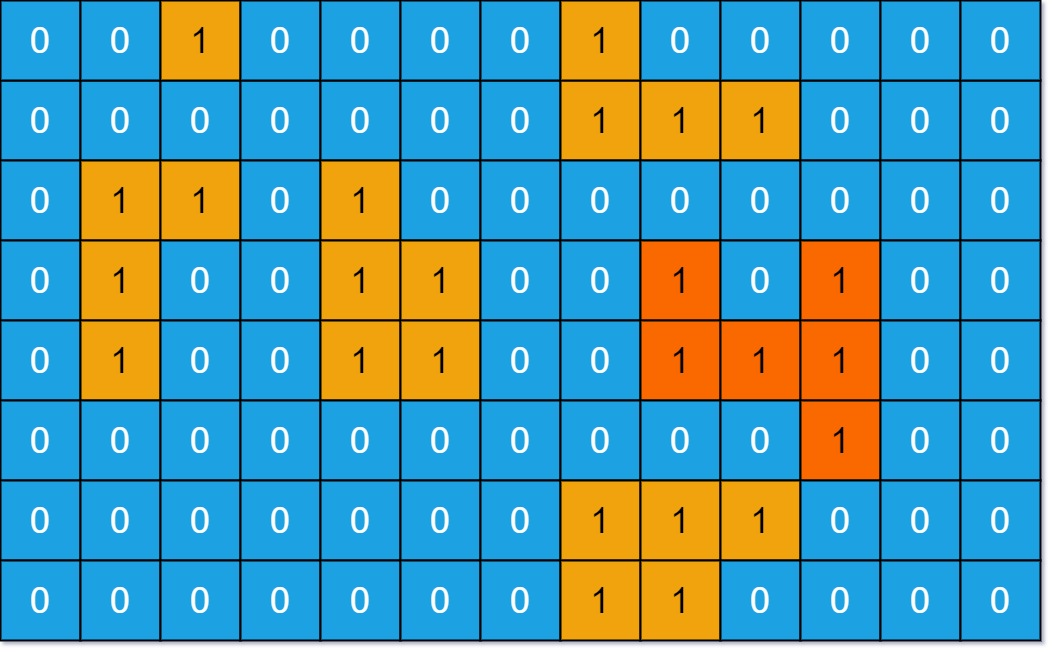
题解就是进行左右上下的搜索,选择第一个位置,如果为1,即陆地,就对周进行搜索,被搜索到的地方置为0.并且设置一个最大陆地,每一次得到新的陆地面积就进行比较,取最大值。
为什么搜索到就置为0呢?因为如果是同一片,那么搜索第一个陆地的时候就会把这一片全部搜索了,所以没必要重复搜索,节约时间。
class Solution { public:int maxAreaOfIsland(vector<vector<int>>& grid) {int max=0;int area=0;int i,j;for(i=0;i<grid.size();i++){for(j=0;j<grid[0].size();j++){if(grid[i][j]==1){area=findArea(grid,i,j);if(area>max)max=area;}}}return max;}int findArea(vector<vector<int>>& grid,int i,int j){if(i==grid.size()||i<0)return 0;else if(j==grid[0].size()||j<0)return 0;if(grid[i][j]==1){grid[i][j]=0;return 1+findArea(grid,i+1,j)+findArea(grid,i-1,j)+findArea(grid,i,j+1)+findArea(grid,i,j-1);}return 0;} };
547.省份数量
547. 省份数量
题目
有
n个城市,其中一些彼此相连,另一些没有相连。如果城市a与城市b直接相连,且城市b与城市c直接相连,那么城市a与城市c间接相连。省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个
n x n的矩阵isConnected,其中isConnected[i][j] = 1表示第i个城市和第j个城市直接相连,而isConnected[i][j] = 0表示二者不直接相连。返回矩阵中 省份 的数量。
示例 1:
输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] 输出:2示例 2:
输入:isConnected = [[1,0,0],[0,1,0],[0,0,1]] 输出:3提示:
1 <= n <= 200n == isConnected.lengthn == isConnected[i].lengthisConnected[i][j]为1或0isConnected[i][i] == 1isConnected[i][j] == isConnected[j][i]
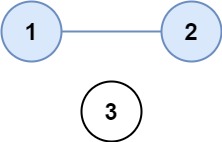
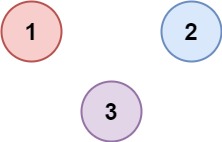
题解等于1就是二者相连。可以先设置一个visit数组来记录改行是否已经被遍历过了,避免重复计数。
一行一行遍历,如果没有访问过,则判断是否为0,不是则进行寻找。寻找的时候访问改行,并且对改行(即该节点)连接的也一起访问了。(这里递归解决)
class Solution {
public:int findCircleNum(vector<vector<int>>& isConnected) {int n=isConnected.size(),count=0;vector<bool> visit(n,false);int i;for(i=0;i<n;i++){if(!visit[i]){find(isConnected,visit,i);count++;}}return count;}void find(vector<vector<int>>& isConnected,vector<bool>& visit,int i){visit[i]=true;int j;for(j=0;j<isConnected.size();j++){if(!visit[j]&&isConnected[i][j]==1){find(isConnected,visit,j);}}}
};417.太平洋大西洋水流问题
417. 太平洋大西洋水流问题
题目
有一个
m × n的矩形岛屿,与 太平洋 和 大西洋 相邻。 “太平洋” 处于大陆的左边界和上边界,而 “大西洋” 处于大陆的右边界和下边界。这个岛被分割成一个由若干方形单元格组成的网格。给定一个
m x n的整数矩阵heights,heights[r][c]表示坐标(r, c)上单元格 高于海平面的高度 。岛上雨水较多,如果相邻单元格的高度 小于或等于 当前单元格的高度,雨水可以直接向北、南、东、西流向相邻单元格。水可以从海洋附近的任何单元格流入海洋。
返回网格坐标
result的 2D 列表 ,其中result[i] = [ri, ci]表示雨水从单元格(ri, ci)流动 既可流向太平洋也可流向大西洋 。示例 1:
输入: heights = [[1,2,2,3,5],[3,2,3,4,4],[2,4,5,3,1],[6,7,1,4,5],[5,1,1,2,4]] 输出: [[0,4],[1,3],[1,4],[2,2],[3,0],[3,1],[4,0]]示例 2:
输入: heights = [[2,1],[1,2]] 输出: [[0,0],[0,1],[1,0],[1,1]]提示:
m == heights.lengthn == heights[r].length1 <= m, n <= 2000 <= heights[r][c] <=

题解
水往低处流。如果一个一个点判断会比较麻烦,我们不妨换一种思路,从四条边出发。因为四边是确认可以流入其中一个海的。四条边开始进行dfs。反向思考,即水从高处来。分别设置两个标记函数标记是否可以流入某一个海。当两个标记函数都显示true,则代表该位置的水可以流入两个海。
find函数部分实现dfs。定义一个dirs,分别是前后左右四个方向。在每一个位置的时候进行判断,如果不是边界且大于0,并且下一步大于该位置,证明该位置是可以流的。然后往下一步走,一直遍历。
主函数则是定义两个函数分别从四条边出发一个记录可以流入太平洋,一个记录可以流入大西洋。二者都是true即该位置可以流入对应的海洋。
class Solution { public:vector<vector<int>> pacificAtlantic(vector<vector<int>>& heights) {if(heights.size()==0||heights[0].size()==0)return {};const int m=heights.size();const int n=heights[0].size();vector<vector<bool>> p_visit(m,vector<bool>(n,false));vector<vector<bool>> a_visit(m,vector<bool>(n,false));int i,j;for(i=0;i<m;i++){find(heights,p_visit,i,0);find(heights,a_visit,i,n-1);}for(j=0;j<n;j++){find(heights,p_visit,0,j);find(heights,a_visit,m-1,j);}vector<vector<int>> ans;for(i=0;i<m;i++){for(j=0;j<n;j++){if(p_visit[i][j]&&a_visit[i][j])ans.push_back({i,j});}}return ans;}void find(vector<vector<int>>& heights,vector<vector<bool>>& visit,int i,int j){int m=heights.size();int n=heights[0].size();visit[i][j]=true;vector<pair<int,int>> dirs={{0,1},{0,-1},{1,0},{-1,0}};for(auto d:dirs){int nx=i+d.first;int ny=j+d.second;if(nx>=0&&nx<m&&ny>=0&&ny<n&&!visit[nx][ny]&&heights[nx][ny]>=heights[i][j])find(heights,visit,nx,ny);}} };
相关文章:
力扣-dfs
何为深度优先搜索算法? 深度优先搜索算法,即DFS。就是找一个点,往下搜索,搜索到尽头再折回,走下一个路口。 695.岛屿的最大面积 695. 岛屿的最大面积 题目 给你一个大小为 m x n 的二进制矩阵 grid 。 岛屿 是由一些相…...

keepalived高可用集群
一、keepalived: 1.keepalive是lvs集群中的高可用架构,只是针对调度器的高可用,基于vrrp来实现调度器的主和备,也就是高可用的HA架构;设置一台主调度器和一台备调度器,在主调度器正常工作的时候࿰…...

文献翻译与阅读《Integration Approaches for Heterogeneous Big Data: A Survey》
CYBERNETICS AND INFORMATION TECHNOLOGIES’24 论文原文下载地址:原文下载 目录 1 引言 2 大数据概述 3 大数据的异构性 4 讨论整合方法 4.1 大数据仓库(BDW) 4.2 大数据联盟(BDF) 5 DW 和 DF 方法的比较、分…...

应用最优化方法及MATLAB实现——第3章代码实现
一、概述 在阅读最优方法及MATLAB实现后,想着将书中提供的代码自己手敲一遍,来提高自己对书中内容理解程度,巩固一下。 这部分内容主要针对第3章的内容,将其所有代码实现均手敲一遍,中间部分代码自己根据其公式有些许的…...

django的增删改查,排序,分组等常用的ORM操作
Django 的 ORM(对象关系映射)提供了一种方便的方式来与数据库进行交互。 1. Django模型 在 myapp/models.py 中定义一个示例模型:python from django.db import modelsclass Person(models.Model):name models.CharField(max_length100)age…...

Leetcode Java学习记录——树、二叉树、二叉搜索树
文章目录 树的定义树的遍历中序遍历代码 二叉搜索树 常见二维数据结构:树/图 树和图的区别就在于有没有环。 树的定义 public class TreeNode{public int val;public TreeNode left,right;public TreeNode(int val){this.val val;this.left null;this.right nu…...

华为HCIP Datacom H12-821 卷30
1.单选题 以下关于OSPF协议报文说法错误的是? A、OSPF报文采用UDP报文封装并且端口号是89 B、OSPF所有报文的头部格式相同 C、OSPF协议使用五种报文完成路由信息的传递 D、OSPF所有报文头部都携带了Router-ID字段 正确答案:A 解析: OSPF用IP报文直接封装协议报文,…...
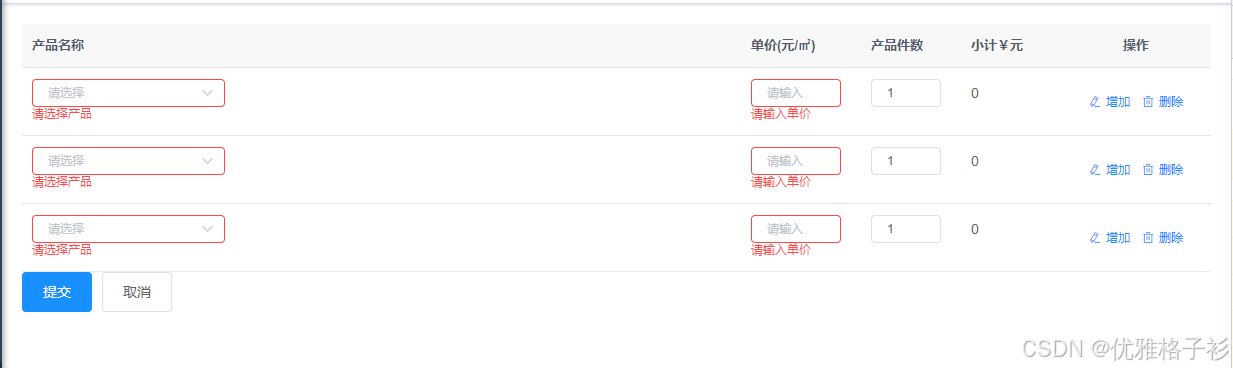
element el-table实现表格动态增加/删除/编辑表格行,带校验规则
本篇文章记录el-table增加一行可编辑的数据列,进行增删改。 1.增加空白行 直接在页面mounted时对form里面的table列表增加一行数据,直接使用push() 方法增加一列数据这个时候也可以设置一些默认值。比如案例里面的 产品件数 。 mounted() {this.$nextTi…...

QT调节屏幕亮度
1、目标 利用QT实现调节屏幕亮度功能:在无屏幕无触控时,将屏幕亮度调低,若有触控则调到最亮。 2、调节亮度命令 目标装置使用嵌入式Linux系统,调节屏幕亮度的指令为: echo x > /sys/class/backlight/backlight/…...

实变函数精解【3】
文章目录 点集求导集 闭集参考文献 点集 求导集 例1 E { 1 / n 1 / m : n , m ∈ N } 1. lim n → ∞ ( 1 / n 1 / m ) 1 / m 2. lim n , m → ∞ ( 1 / n 1 / m ) 0 3. E ′ { 0 , 1 , 1 / 2 , 1 / 3 , . . . . } E\{1/n1/m:n,m \in N\} \\1.\lim_{n \rightar…...

JVM:SpringBoot TomcatEmbeddedWebappClassLoader
文章目录 一、介绍二、SpringBoot中TomcatEmbeddedWebappClassLoader与LaunchedURLClassLoader的关系 一、介绍 TomcatEmbeddedWebappClassLoader 是 Spring Boot 在其内嵌 Tomcat 容器中使用的一个类加载器(ClassLoader)。在 Spring Boot 应用中&#…...

蜂窝互联网接入:连接世界的无缝体验
通过Wi—Fi,人们可以方便地接入互联网,但无线局域网的覆盖范围通常只有10~100m。当我们携带笔记本电脑在外面四处移动时,并不是在所有地方都能找到可接入互联网的Wi—Fi热点,这时候蜂窝移动通信系统可以为我们提供广域…...

Sprint Boot 2 核心功能(一)
核心功能 1、配置文件 application.properties 同基础入门篇的application.properties用法一样 Spring Boot 2 入门基础 application.yaml(或application.yml) 基本语法 key: value;kv之间有空格大小写敏感使用缩进表示层级关系缩进不允…...
GitLab CI/CD实现项目自动化部署
1 GitLab CI/CD介绍 GitLab CI/CD 是 GitLab 中集成的一套用于软件开发的持续集成(Continuous Integration)、持续交付(Continuous Delivery)和持续部署(Continuous Deployment)工具。这套系统允许开发团队…...

阿里云调整全球布局关停澳洲云服务器,澳洲服务器市场如何选择稳定可靠的云服务?
近日,阿里云宣布将关停澳大利亚地域的数据中心服务,这一决定引发了全球云计算行业的广泛关注。作为阿里云的重要海外市场之一,澳洲的数据中心下架对于当地的企业和个人用户来说无疑是一个不小的挑战。那么,在阿里云调整全球布局的…...
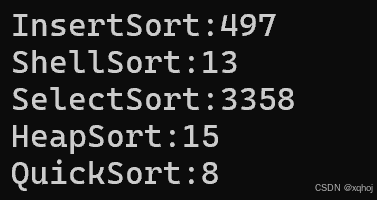
排序(二)——快速排序(QuickSort)
欢迎来到繁星的CSDN,本期内容包括快速排序(QuickSort)的递归版本和非递归版本以及优化。 一、快速排序的来历 快速排序又称Hoare排序,由霍尔 (Sir Charles Antony Richard Hoare) ,一位英国计算机科学家发明。霍尔本人是在发现冒泡排序不够快…...
<数据集>穿越火线cf人物识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:3440张 标注数量(xml文件个数):3440 标注数量(txt文件个数):3440 标注类别数:1 标注类别名称:[person] 使用标注工具:labelImg 标注规则:对…...

a+=1和a=a+1的区别
文章目录 a1 和a a1的区别一、实例代码二、代码解释三、总结 a1 和a a1的区别 一、实例代码 public class Test {public static void main(String[] args) {byte a 10; // a a 1; // a (byte) (a 1);a 1;System.out.println(a);} }上面的对变量a进行加一操作时&a…...
)
设计模式使用场景实现示例及优缺点(结构型模式——桥接模式)
结构型模式 桥接模式(Bridge Pattern) 桥接模式(Bridge Pattern)是一种结构型设计模式,其主要目的是“将抽象与实现解耦,使得两者可以独立地变化”。这种模式通过提供抽象化和实现化之间的桥接结构&#…...

Spring——自动装配Bean
自动装配是Spring满足bean依赖的一种方式 Spring会在上下文中自动寻找,并自动给bean装配属性 在Spring中有三种装配的方式: 1. 在xml中显示配置 2. 在java中显示配置 3. 隐式的自动装配bean【重要】 测试 记得创建Cat、Dog、People类 public clas…...

OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 [特殊字符]
OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 🔒 【免费下载链接】openupm OpenUPM - Open Source Unity Package Registry (UPM) 项目地址: https://gitcode.com/gh_mirrors/op/openupm OpenUPM作为开源Unity包管理器(UPM&…...

网安工具系列python系列【仅供参考】:Python实战:利用fofa API高效搜索网络资产
Python实战:利用fofa API高效搜索网络资产 Python实战:利用fofa API高效搜索网络资产 1. 从零开始:为什么你需要一个自动化的资产搜索工具? 2. 动手前的准备:你的fofa账户和Python环境 2.1 获取你的fofa API凭证 2.2 搭建Python脚本环境 3. 核心代码拆解:一行行理解搜索脚…...

【无人机路径规划】基于K-means 聚类和遗传算法实现多架无人机任务区域进行划分,并优化各区域内的访问路径附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

TrollInstallerX终极指南:3分钟完成iOS安装工具的零基础教程
TrollInstallerX终极指南:3分钟完成iOS安装工具的零基础教程 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS设备设计的智能越…...

如何通过DriverStore Explorer解决Windows驱动管理的三大核心难题
如何通过DriverStore Explorer解决Windows驱动管理的三大核心难题 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 作为一名系统管理员或技术爱好者,你是否曾面临这样的困境&…...

回溯算法:暴力枚举最优解
一、上期回顾 吃透二分查找三大模板:基础查找、左边界、右边界,掌握二分答案解题思维,有序数组最优解法全部拿下。今天正式攻克回溯算法,暴力枚举最优写法,解决排列、组合、子集、棋盘类所有搜索题。二、递归与回溯核心…...
)
ESP32开发板Flash型号傻傻分不清?教你用esptool.py一键查询并看懂ID(附厂商对照表)
ESP32开发板Flash型号识别全攻略:从ID解析到厂商对照 当你拿到一块ESP32开发板或模组时,是否经常遇到这样的困惑:Flash芯片的具体型号和容量不明,导致在menuconfig配置时无从下手?这种"盲盒"体验确实让人头疼…...

音乐标签混乱的终结者:music-tag-web如何用3个步骤帮你重建完美音乐库
音乐标签混乱的终结者:music-tag-web如何用3个步骤帮你重建完美音乐库 【免费下载链接】music-tag-web 音乐标签编辑器,可编辑本地音乐文件的元数据(Editable local music file metadata.) 项目地址: https://gitcode.com/gh_mi…...

Linux主机资产标识实战指南
Linux主机资产标识实战指南本文面向具备一定 Linux 基础的技术人员,围绕主机资产标识展开,重点讨论主机命名、标签规范和资产映射。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

APK安装器:在Windows系统上高效安装安卓应用的实用工具
APK安装器:在Windows系统上高效安装安卓应用的实用工具 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在移动应用生态日益丰富的今天,用户经常…...