Apache Spark分布式计算框架架构介绍
目录
一、概述
二、Apache Spark架构组件栈
2.1 概述
2.2 架构图
2.3 架构分层组件说明
2.3.1 支持数据源
2.3.2 调度运行模式
2.3.3 Spark Core核心
2.3.3.1 基础设施
2.3.3.2 存储系统
2.3.3.3 调度系统
2.3.3.4 计算引擎
2.3.4 生态组件
2.3.4.1 Spark SQL
2.3.4.2 Spark Streaming
2.3.4.3 GraphX
2.3.4.4 Spark MLlib
2.3.4.5 Spark R
三、Apache Spark 的运行时架构
3.1 概述
3.2 架构图
3.3 组件角色说明
3.3.1 Cluster Manager
3.3.2 Worker
3.3.3 Executor
3.3.4 Driver
3.3.5 Application
3.4 Spark 运行流程
3.4.1 概述
3.4.2 运行流程图
3.4.3 运行流程步骤说明
四、Spark 的特点
4.1 计算速度快
4.2 易于使用
4.3 通用大数据框架
4.4 支持多种资源管理器
4.5 生态圈丰富
一、概述
Apache Spark 是通用的分布式大数据计算引擎 Spark UC Berkeley AMPLab(美国加州大学伯克 利分校的 AMP 实验室)开源的通用并行框架。 Spark 拥有 Hadoop MapReduce 所具有的优点,但不同于 Hadoop MapReduce 的是, Hadoop 每次经过 Job行的中间结果都存储到 HDFS 磁盘上,而 Spark Job 中间输出结果可以保存在内存中,而不再需要读写 HDFS 。因为内存的读写速度与磁盘的读写速度不在一个数量级上,所以Spark 利用内存中的数据能更快速地完成数据的处理。
Spark 启用了弹性分布式数据集( Resilient Distributed Dataset , RDD) ,除了能够提高交互式查询效率,还可以优化迭代器的工作负载。由于弹性分布式数据集的存在,使得数据挖掘与机器学习等需要迭代的 MapReduce 的算法更容易实现。
官网地址:spark.apache.org
二、Apache Spark架构组件栈
2.1 概述
Spark 基于 Spark Core 建立了 Spark SQL、Spark Streaming、MLlib、GraphX、SparkR 核心组件,基于不同组件可以实现不同的计算任务,这些计算任务的运行模式有:本地模式、独立模式(Standalone)、Mesos 模式、 YARN 模式。Spark 任务的计算可以从 HDFS、S3、Hypertable、HBase或Cassandra等多种数据源中存取数据。
2.2 架构图

2.3 架构分层组件说明
2.3.1 支持数据源
Spark 任务的计算可以从 HDFS、S3、Hypertable、HBase或Cassandra等多种数据源中存取数据。
2.3.2 调度运行模式
Spark 的运行模式主要包括 Local模式、 Standalone 模式、 On YARN、 On Mesos 和运行在 AWS 等公有云平台上。

2.3.3 Spark Core核心
Spark 的核心功能实现包括基础设施、存储系统、调度系统和计算引擎。
2.3.3.1 基础设施
Spark 中有很多基础设施,这些基础设施被 Spark 中的各种组件广泛使用,包括 SparkConf (配置信息) 、SparkContext ( Spark 上下文) 、Spark RPC (远程过程调用)、ListenerBu (事件总线) 、MetricsSystem (度量系统) 、SparkEnv (环境变量)等。
2.3.3.2 存储系统
Spark 存储系统用于管理 Spark 运行过程中依赖的数据的存储方式和存储位置。Spark 存储系统首先考虑在各节点的内存中存储数据,当内存不足时会将数据存储到磁盘上,这种内存优先的存储策略使得 Spark 的计算性能无论在实时流计算还是在批量'计算的场景下都表现很好。 Spark 的内存存储空间和执行存储空间之间的边界可以
灵活控制。
2.3.3.3 调度系统
Spark 调度系统主要由 DAGScheduler 、TaskScheduler组成。DAGScheduler 负责创建 Job 、将 DAG 中的RDD 划分到不同 Stage 、为 Stage 创建对应的Task 、批量提交 Task 等。 TaskScheduler 负责按照 FIFO (First Input First Output. 先进先出 ) 或 FAIR (公平调度)等调度算法对 Task 进行批量调度。
2.3.3.4 计算引擎
计算引擎由内存管理器、任务管理器、 Task Shuffle 管理器等组成。
2.3.4 生态组件
2.3.4.1 Spark SQL
Spark SQL 提供基于 SQL 的数据处理方式,使得分布式数据的处理变得更加简单。此外,Spark 提供了对 Hive SQL 的支持。
2.3.4.2 Spark Streaming
Spark Streaming 提供流计算能力,支持 Kafka 、flume、 Kinesis 、TCP 多种流式数据源。此外,Spark Streaming 提供了基于时间窗口的批量流操作,用于对一定时间周期内的流数据执行批量处理。
2.3.4.3 GraphX
GraphX 用于分布式图计算。通过 Pregel 提供的 API 可以快速解决图计算中的常见问题。
2.3.4.4 Spark MLlib
Spark MLlib 为 Spark机器学习库 。Spark MLlib 提供了统计、分类、回归等多种机器学习算法的实现,其简单易用的 API 接口降低 了机器学习的门槛。
2.3.4.5 Spark R
Spark R是一个R语言包, 提供了轻量级R语言使用Spark的方式。Spark R实现了分布式的数据框,支持类似查询、过滤及聚合的操作(类似R语言中的数据框包dplyr ),使得基于R语言能够更方便处理大规模的数据集。同时Spark R 支持基于Spark MLlib 进行机器学习。
三、Apache Spark 的运行时架构
3.1 概述
Spark 的集群架构主要由 Cluster Manager (管理器)、 Worker (工作节点)、 Executor(执行器)、 Driver (驱动器)、 Application (应用程序) 五部分组成。
3.2 架构图

3.3 组件角色说明
3.3.1 Cluster Manager
Spark 集群管理器,主要用于整个集群资源的管理和分配。根据部署模式的不同,可以分为 Local、 Standalone、 YARN、Mesos、AWS。
3.3.2 Worker
Spark 的工作节点,用于执行提交的任务。 Worker 的工作职责如下:
- 通过注册机制向Cluster Manager 汇报自身的CPU和内存等资源使用信息。
- 在Master 的指示下创建并启动 Executor,Executor 是真正的计算单元。
- 将资源和任务进一步分配给Executor 并运行。
- 同步资源信息和Executor 状态信息给Cluster Manager。
3.3.3 Executor
真正执行计算任务的组件,是某个Application 运行在 Worker 上的一 个进程。该进程负责 Task 的运行并且将运行的结果数据保存到内存或磁盘上。
Task 是运行在 Executor 上的任务单元,Spark 应用程序最终被划分为经过优化的多个 Task 的集合。
3.3.4 Driver
Application 的驱动程序,可以理解为驱动程序运行中的 main()函数,Driver 在运行过程中会创建SparkContext。Application 通过 Driver 与 Cluster Manager 和Executor 进行通信。Driver 可以运行在 Application 上,也可以由 Application 提交给Cluster Manager,再由 Cluster Manager 安排 Worker 运行。Driver 的主要职责如下:
- 运行应用程序的main()函数。
- 创建SparkContext。
- 划分RDD并生成 DAG。
- 构建Job 并将每个 Job 都拆分为多个 Task,这些 Task 的集合被称为Stage。各个Stage 相互独立,由于 Stage 由多个 Task 构成,因此也被称为 Task Set。Job 是由多个Task构建的并行计算任务,具体为 Spark 中的 Action操作(例如collect、save 等)。
- 与Spark中的其他组件进行资源协调。
- 生成并发送Task到Executor。
3.3.5 Application
基于Spark API编写的应用程序,其中包括实现 Driver 功能的代码和在集群中多个节点上运行的 Executor 代码。Application 通过 Spark API创建RDD、对RDD进行转换、创建DAG、通过Driver将Application 注册到 Cluster Manager。
3.4 Spark 运行流程
3.4.1 概述
Spark 的数据计算主要通过 RDD的选代完成,RDD是弹性分布式数据集,可以看作是对各种数据计算模型的统一抽象。在 RDD 的迭代计算过程中,其数据被分为多个分区并行计算,分区数量取决于应用程序设定的 Partition 数量,每个分区的数据都只会在一个Task上计算。所有分区可以在多个机器节点的 Executor 上并行执行。
3.4.2 运行流程图

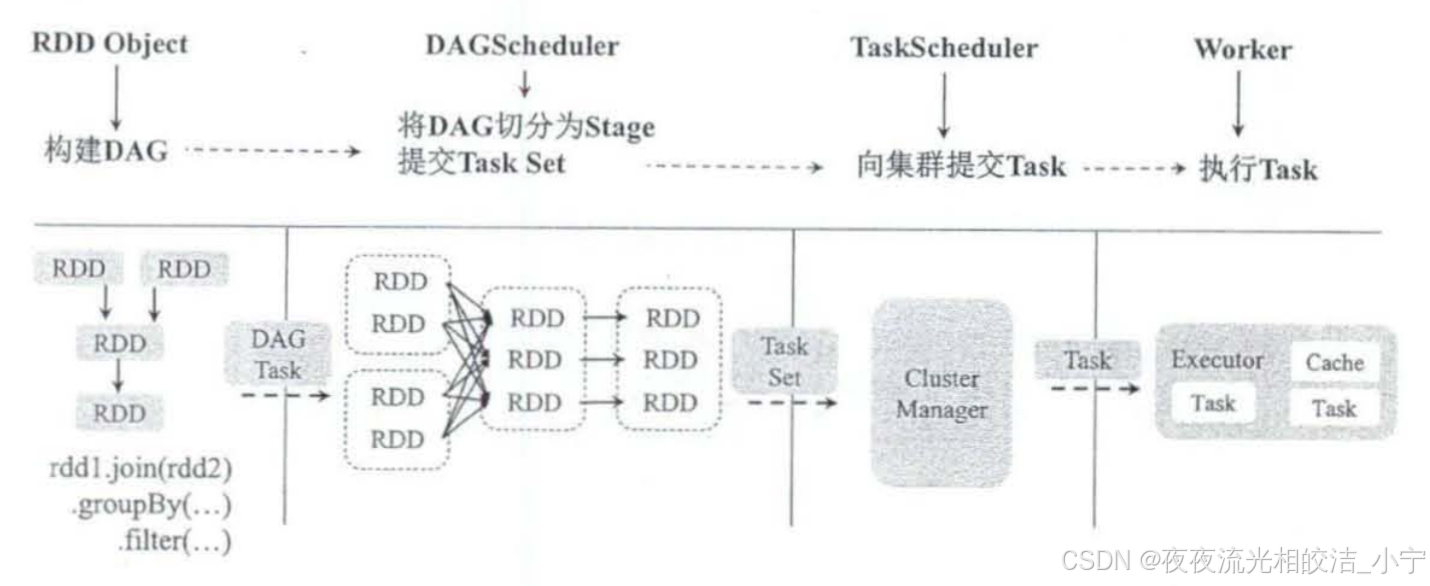
3.4.3 运行流程步骤说明
- 创建RDD对象,计算 RDD 之间的依赖关系,并将RDD生成一个DAG。
- DAGScheduler 将 DAG划分为多个 Stage,并将 Stage 对应的 Task Set 提交到集群管理中心。划分 Stage 的一个主要依据是当前计算因子的输人是否确定。如果确定,则将其分到同一个 Stage 中,避免多个 Stage 之间传递消息产生的系统资源开销。
- TaskScheduler 通过集群管理中心为每个 Task 都申请系统资源,并将 Task 提交到Worker
- Worker的Executor 执行具体的 Task。
四、Spark 的特点
4.1 计算速度快
Spark将每个任务都构造成一个DAG(Directed Acyclic Graph,有向无环图)来执行,其内部计算过程基于弹性分布式数据集在内存中对数据进行迭代计算,因此其运行效率很高。官方数据表明,如果计算的数据从磁盘上读取,则 Spark 的速度是 Hadoop MapReduce的10倍以上;如果计算的数据从内存中读取,则 Spark 的计算速度是Hadoop MapReduce的100倍以上。
4.2 易于使用
Spark 提供了 80多个高级运算操作,支持丰富的算子,开发人员只需要按照其封装好的API实现即可,不需要关心 Spark 的底层架构。同时,Spark 支持多种语言开发,包括Java、Scala、Python。
4.3 通用大数据框架
Spark 提供了多种类型的开发库,包括 Spark Core、Spark SQL(即时查询)、Spark Streaming(实时流处理)、Spark MLlib、GraphX(图计算),使得开发人员可以在同一个应用程序中无缝组合使用这些库,而不用像传统的大数据方案那样将离线任务放在Hadoop MapReduce 上运行,将实时流计算任务放在 Storm 上运行,并维护多个平台。Spark 提供了从实时流计算、MapReduce 离线计算、SOL计算、机器学习到图计算的一站式整体解决方案。
4.4 支持多种资源管理器
Spark 支持单机、Standalone、Hadoop YARN、Apache Mesos 等多种资源管理器,用户可以根据现有的大数据平台灵活地选择运行模式。
4.5 生态圈丰富
Spark生态圈以Spark Core 为核心,支持从HDFS、S3、HBase 等多种持久化层读取数据。同时,Spark 支持以 Hadoop YARN、Apache Mesos 和 Standalone 为资源管理器调度Job,完成Spark应用程序的计算。Spark 应用程序可以基于不同的组件实现,如SparkShell、Spark Submit 、Spark Streaming 、SparkSOL、BlinkDB(权衡查询)、MLlib/MLbase(机器学习)、GraphX 和SparkR(数学计算)等。Spark 生态圈已经从大数据计算和数据挖掘扩展到机器学习、自然语言处理和语音识别等领域。
今天Spark相关内容的介绍就分享到这里,可以关注Spark专栏《Spark》,后续不定期分享相关技术文章。如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!
相关文章:
Apache Spark分布式计算框架架构介绍
目录 一、概述 二、Apache Spark架构组件栈 2.1 概述 2.2 架构图 2.3 架构分层组件说明 2.3.1 支持数据源 2.3.2 调度运行模式 2.3.3 Spark Core核心 2.3.3.1 基础设施 2.3.3.2 存储系统 2.3.3.3 调度系统 2.3.3.4 计算引擎 2.3.4 生态组件 2.3.4.1 Spark SQL 2.…...

Visual Studio 2019 (VS2019) 中使用 CMake 配置 OpenCV 库(快捷版)
2024.07.11 测试有效 最近需要用一下 opencv 处理图像,简单配置了一下Cmake下的 opencv 库。 没有编译 opencv ,也不知道他们为什么要自己编译 opencv 。 一、下载并安装 OpenCV 1.前往 OpenCV 官方网站 下载适用于您的系统的 OpenCV 安装包。 2.点击直接…...
BUG解决:postman可以请求成功,但Python requests请求报403
目录 问题背景 问题定位 问题解决 问题背景 使用Python的requests库对接物联数据的接口之前一直正常运行,昨天突然请求不通了,通过进一步验证发现凡是使用代码调用接口就不通,而使用postman就能调通,请求参数啥的都没变。 接口…...

VScode常用快捷键
VScode介绍 VSCode(全称:Visual Studio Code)是一款由微软开发且跨平台的免费源代码编辑器。能够在windows、Linux、IOS等平台上运行,通过安装一些插件可以让这个编辑器变成一个编译器。与Visual Studio相比,它是免费…...
Day1每日编程题日记:数字统计、两个数组的交集、点击消除
前言:该篇用于记录自看。曾回看昨天的做题代码,竟然会觉得陌生,这竟然是我写的,细细读了一下,原来我当时是这么想的。因此我觉得记代码没有实际用处,重点是领悟了思想,这样子代码就在心中&#…...
ENSP实现防火墙区域策略与用户管理
目录 实验拓扑与要求编辑 交换机与防火墙接口的配置 交换机: 创建vlan 接口配置 防火墙配置及接口配置 防火墙IP地址配置 云配置编辑编辑编辑 在浏览器上使用https协议登陆防火墙,并操作 访问网址:https://192.168.100.1:844…...

c#实现23种常见的设计模式--动态更新
c#实现23种常见的设计模式 设计模式通常分为三个主要类别: 创建型模式 结构型模式 行为型模式。 这些模式是用于解决常见的对象导向设计问题的最佳实践。 以下是23种常见的设计模式并且提供c#代码案例: 创建型模式: 1. 单例模式&#…...
昇思25天训练营Day11 - 基于 MindSpore 实现 BERT 对话情绪识别
模型简介 BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),它是Google于2018年末开发并发布的一种新型语言模型。与BERT模型相似的预训练语言模型例如问答、命名实体识别、自然语言推理、…...

本地开发微信小程序,使用巴比达内网穿透
在微信小程序开发的热潮中,开发者常面临的一个挑战是如何在复杂的网络环境下测试和调试内网环境中的服务。巴比达正为这一难题提供了一条解决方案,极大简化了微信小程序与内网服务器之间通信的流程,加速了开发迭代周期。 以往,开…...

【LeetCode】快乐数
目录 一、题目二、解法完整代码 一、题目 编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变…...

大模型未来发展深度分析
大模型未来发展方向的深度探讨 近年来,人工智能技术的飞速发展,特别是大模型技术的崛起,为全球科技产业带来了前所未有的变革。大模型,以其强大的推理能力、创意生成能力和情绪智能,正在逐步成为推动社会经济发展的核…...
[线性RNN系列] Mamba: S4史诗级升级
前言 iclr24终于可以在openreview上看预印本了 这篇(可能是颠覆之作)文风一眼c re组出品;效果实在太惊艳了,实验相当完善,忍不住写一篇解读分享分享。 TL;DR (overview) Structured State-Sp…...

【鸿蒙学习笔记】元服务
官方文档:元服务规格 目录标题 什么是元服务特征第一个元服务-案例介绍创建项目源码启动模拟器启动entry创建卡片出发元服务 什么是元服务 特征 免安装分包预加载老化和更新机制 第一个元服务-案例介绍 创建项目 源码 Entry Component struct WidgetCard {buil…...

LIS+找规律,CF 582B - Once Again...
一、题目 1、题目描述 2、输入输出 2.1输入 2.2输出 3、原题链接 582B - Once Again... 二、解题报告 1、思路分析 考虑朴素做法对T *n的数组求LIS 但是T * n可达1e9 思考一下,最优解无非就是几个循环节拼接,我们最差情况下对sqrt(T)个a[]求LIS即…...
——开发:数据拆分——实施过程、应用特点)
数据赋能(145)——开发:数据拆分——实施过程、应用特点
实施过程 数据拆分的实施过程通常涉及以下几个关键步骤: 确定拆分目标和需求: 明确数据拆分的目的和需求,例如是为了减少数据处理的复杂性、提高查询效率还是为了满足特定的业务需求。根据需求确定拆分后的数据结构和拆分规则。选择拆分方法…...

【漏洞复现】Splunk Enterprise for Windows 任意文件读取漏洞 CVE-2024-36991
声明:本文档或演示材料仅用于教育和教学目的。如果任何个人或组织利用本文档中的信息进行非法活动,将与本文档的作者或发布者无关。 一、漏洞描述 Splunk Enterprise 是一款强大的机器数据管理和分析平台,广泛应用于企业中,用于实…...

FastAPI -- 第一弹
Hello World 经典的 Hello World 安装 pip install fastapi pip install "uvicorn[standard]"main.py from typing import Unionfrom fastapi import FastAPIapp FastAPI()app.get("/") def read_root():return {"Hello": "World"}…...

C++入门基础篇(1)
欢迎大家来到海盗猫鸥的博客—— 断更许久,让我们继续好好学习吧! 目录 1.namespace命名空间 命名空间的存在价值: 命名空间的定义: 命名空间的使用: 2.C输入输出函数 使用: 3.缺省参数 4.函数重载…...

基于html开发的在线网址导航在线工具箱源码
基于html开发的在线网址导航在线工具箱源码,将全部文件复制到服务器,入口文件是index.html 如需修改网址,可修改index.html 如需修改关于页面,可修改about里面的index页面 源码下载:https://download.csdn.net/down…...

【密码学】大整数分解问题和离散对数问题
公钥密码体制的主要思想是通过一种非对称性,即正向计算简单,逆向计算复杂的加密算法设计,来解决安全通信。本文介绍两种在密码学领域内最为人所熟知、应用最为广泛的数学难题——大整数分解问题与离散对数问题 一、大整数分解问题 …...

HS2-HF_Patch终极指南:如何快速获得完整汉化与去码体验
HS2-HF_Patch终极指南:如何快速获得完整汉化与去码体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是《Honey Select 2》游戏的全功…...

TrollInstallerX深度探索:iOS越狱应用安装的革命性解决方案
TrollInstallerX深度探索:iOS越狱应用安装的革命性解决方案 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 还在为iOS设备上安装TrollStore而烦恼吗…...

RK3568播放RTSP摄像头实测:软解1080P直接CPU跑满,降到360P才流畅,硬解到底怎么搞?
RK3568 RTSP摄像头解码实战:从软解瓶颈到硬解优化全解析 最近在调试RK3568开发板的RTSP摄像头播放功能时,遇到了一个典型问题:1080P软解直接让CPU跑满,降到360P才能勉强流畅。这让我开始深入探索瑞芯微平台的硬解方案,…...

告别拥塞:手把手优化Dragonfly网络性能,UGAL-LVC_H算法详解与配置
告别拥塞:手把手优化Dragonfly网络性能,UGAL-LVC_H算法详解与配置 在数据中心网络架构中,Dragonfly拓扑以其高度可扩展性和低直径特性脱颖而出,成为超大规模计算环境的理想选择。然而,当面对对抗性流量模式时ÿ…...

深度解析抖音直播回放下载架构设计:从FLV流捕获到多线程存储优化
深度解析抖音直播回放下载架构设计:从FLV流捕获到多线程存储优化 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fall…...

3个步骤:如何在Windows 11上实现Android应用无缝安装与管理
3个步骤:如何在Windows 11上实现Android应用无缝安装与管理 【免费下载链接】wsa-toolbox A Windows 11 application to easily install and use the Windows Subsystem For Android™ package on your computer. 项目地址: https://gitcode.com/gh_mirrors/ws/ws…...

别再手动改Hex了!用Vector HexView的/remap命令,5分钟搞定固件地址重映射
嵌入式开发革命:Vector HexView自动化重映射技术实战指南 在汽车电子和物联网设备开发中,固件地址调整如同家常便饭。每当内存布局变更、Bootloader升级或外设地址重新分配时,嵌入式工程师们就不得不面对一项枯燥且容易出错的任务——手动修改…...

别再为OLED图片显示发愁了!手把手教你用Image2Lcd和PCtoLCD2002搞定STM32图片取模
STM32 OLED图片显示实战:从取模到驱动的完整解决方案 在嵌入式开发中,OLED显示屏因其高对比度、低功耗和快速响应等特性,成为许多项目的首选显示方案。但对于初学者来说,如何将普通图片转换为单片机可识别的数据格式,并…...

对抗机器学习实战:从模型脆弱性到工业级鲁棒性工程
1. 项目概述:当模型开始“看走眼”,我们该怎么办?你有没有遇到过这样的情况:一张清晰的猫图,被模型坚定地判为“烤面包”;一段语音指令,加了点人耳几乎听不出的杂音,智能音箱就把它理…...

Unity里嵌入一个浏览器?用Embedded Browser插件5分钟搞定H5页面展示与交互
Unity项目快速集成H5页面:Embedded Browser插件实战指南 当Unity项目需要展示动态更新的网页内容时,传统方案往往需要重新开发UI或依赖第三方服务。而Embedded Browser插件提供了一种优雅的解决方案,让开发者能够在Unity中直接嵌入完整的浏览…...