昇思25天训练营Day11 - 基于 MindSpore 实现 BERT 对话情绪识别
模型简介
BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),它是Google于2018年末开发并发布的一种新型语言模型。与BERT模型相似的预训练语言模型例如问答、命名实体识别、自然语言推理、文本分类等在许多自然语言处理任务中发挥着重要作用。模型是基于Transformer中的Encoder并加上双向的结构,因此一定要熟练掌握Transformer的Encoder的结构。
BERT模型的主要创新点都在pre-train方法上,即用了Masked Language Model和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
在用Masked Language Model方法训练BERT的时候,随机把语料库中15%的单词做Mask操作。对于这15%的单词做Mask操作分为三种情况:80%的单词直接用[Mask]替换、10%的单词直接替换成另一个新的单词、10%的单词保持不变。
因为涉及到Question Answering (QA) 和 Natural Language Inference (NLI)之类的任务,增加了Next Sentence Prediction预训练任务,目的是让模型理解两个句子之间的联系。与Masked Language Model任务相比,Next Sentence Prediction更简单些,训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,BERT模型预测B是不是A的下一句。
BERT预训练之后,会保存它的Embedding table和12层Transformer权重(BERT-BASE)或24层Transformer权重(BERT-LARGE)。使用预训练好的BERT模型可以对下游任务进行Fine-tuning,比如:文本分类、相似度判断、阅读理解等。
对话情绪识别(Emotion Detection,简称EmoTect),专注于识别智能对话场景中用户的情绪,针对智能对话场景中的用户文本,自动判断该文本的情绪类别并给出相应的置信度,情绪类型分为积极、消极、中性。 对话情绪识别适用于聊天、客服等多个场景,能够帮助企业更好地把握对话质量、改善产品的用户交互体验,也能分析客服服务质量、降低人工质检成本。
下面以一个文本情感分类任务为例子来说明BERT模型的整个应用过程。
import osimport mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nn, contextfrom mindnlp._legacy.engine import Trainer, Evaluator
from mindnlp._legacy.engine.callbacks import CheckpointCallback, BestModelCallback
from mindnlp._legacy.metrics import Accuracy# prepare dataset
class SentimentDataset:"""Sentiment Dataset"""def __init__(self, path):self.path = pathself._labels, self._text_a = [], []self._load()def _load(self):with open(self.path, "r", encoding="utf-8") as f:dataset = f.read()lines = dataset.split("\n")for line in lines[1:-1]:label, text_a = line.split("\t")self._labels.append(int(label))self._text_a.append(text_a)def __getitem__(self, index):return self._labels[index], self._text_a[index]def __len__(self):return len(self._labels)数据集
这里提供一份已标注的、经过分词预处理的机器人聊天数据集,来自于百度飞桨团队。数据由两列组成,以制表符('\t')分隔,第一列是情绪分类的类别(0表示消极;1表示中性;2表示积极),第二列是以空格分词的中文文本,如下示例,文件为 utf8 编码。
label--text_a
0--谁骂人了?我从来不骂人,我骂的都不是人,你是人吗 ?
1--我有事等会儿就回来和你聊
2--我见到你很高兴谢谢你帮我
这部分主要包括数据集读取,数据格式转换,数据 Tokenize 处理和 pad 操作。
# download dataset
!wget https://baidu-nlp.bj.bcebos.com/emotion_detection-dataset-1.0.0.tar.gz -O emotion_detection.tar.gz
!tar xvf emotion_detection.tar.gz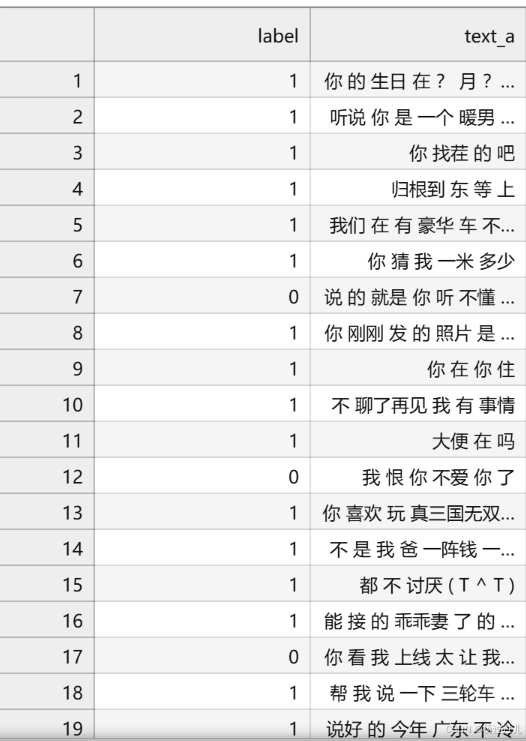
数据加载和数据预处理¶
新建 process_dataset 函数用于数据加载和数据预处理,具体内容可见下面代码注释。
import numpy as npdef process_dataset(source, tokenizer, max_seq_len=64, batch_size=32, shuffle=True):is_ascend = mindspore.get_context('device_target') == 'Ascend'column_names = ["label", "text_a"]dataset = GeneratorDataset(source, column_names=column_names, shuffle=shuffle)# transformstype_cast_op = transforms.TypeCast(mindspore.int32)def tokenize_and_pad(text):if is_ascend:tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len)else:tokenized = tokenizer(text)return tokenized['input_ids'], tokenized['attention_mask']# map datasetdataset = dataset.map(operations=tokenize_and_pad, input_columns="text_a", output_columns=['input_ids', 'attention_mask'])dataset = dataset.map(operations=[type_cast_op], input_columns="label", output_columns='labels')# batch datasetif is_ascend:dataset = dataset.batch(batch_size)else:dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),'attention_mask': (None, 0)})return dataset昇腾NPU环境下暂不支持动态Shape,数据预处理部分采用静态Shape处理:
from mindnlp.transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')tokenizer.pad_token_iddataset_train = process_dataset(SentimentDataset("data/train.tsv"), tokenizer)
dataset_val = process_dataset(SentimentDataset("data/dev.tsv"), tokenizer)
dataset_test = process_dataset(SentimentDataset("data/test.tsv"), tokenizer, shuffle=False)dataset_train.get_col_names()['input_ids', 'attention_mask', 'labels']
print(next(dataset_train.create_tuple_iterator()))[Tensor(shape=[32, 64], dtype=Int64, value= [[ 101, 872, 679 ... 0, 0, 0],[ 101, 1557, 8024 ... 0, 0, 0],[ 101, 6929, 1168 ... 0, 0, 0],...[ 101, 2828, 800 ... 0, 0, 0],[ 101, 1521, 1506 ... 0, 0, 0],[ 101, 6820, 1962 ... 0, 0, 0]]), Tensor(shape=[32, 64], dtype=Int64, value= [[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],...[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0]]), Tensor(shape=[32], dtype=Int32, value= [0, 0, 1, 1, 1, 1, 1, 2, 1, 1, 0, 0, 1, 1, 1, 2, 1, 0, 1, 1, 0, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 0])]
模型构建
通过 BertForSequenceClassification 构建用于情感分类的 BERT 模型,加载预训练权重,设置情感三分类的超参数自动构建模型。后面对模型采用自动混合精度操作,提高训练的速度,然后实例化优化器,紧接着实例化评价指标,设置模型训练的权重保存策略,最后就是构建训练器,模型开始训练。
from mindnlp.transformers import BertForSequenceClassification, BertModel
from mindnlp._legacy.amp import auto_mixed_precision# set bert config and define parameters for training
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3)
model = auto_mixed_precision(model, 'O1')optimizer = nn.Adam(model.trainable_params(), learning_rate=2e-5)metric = Accuracy()
# define callbacks to save checkpoints
ckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='bert_emotect', epochs=1, keep_checkpoint_max=2)
best_model_cb = BestModelCallback(save_path='checkpoint', ckpt_name='bert_emotect_best', auto_load=True)trainer = Trainer(network=model, train_dataset=dataset_train,eval_dataset=dataset_val, metrics=metric,%%time
# start training
trainer.run(tgt_columns="labels")The train will start from the checkpoint saved in 'checkpoint'.Epoch 0: 100%
302/302 [04:12<00:00, 4.21s/it, loss=0.3291704]
Checkpoint: 'bert_emotect_epoch_0.ckpt' has been saved in epoch: 0.Evaluate: 100%
34/34 [00:07<00:00, 1.10s/it]
Evaluate Score: {'Accuracy': 0.9361111111111111} ---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 0.---------------Epoch 1: 100%
302/302 [02:33<00:00, 2.02it/s, loss=0.18864435]
Checkpoint: 'bert_emotect_epoch_1.ckpt' has been saved in epoch: 1.Evaluate: 100%
34/34 [00:04<00:00, 7.94it/s]
Evaluate Score: {'Accuracy': 0.9629629629629629} ---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 1.---------------Epoch 2: 100%
302/302 [02:34<00:00, 1.98it/s, loss=0.12532383]
The maximum number of stored checkpoints has been reached. Checkpoint: 'bert_emotect_epoch_2.ckpt' has been saved in epoch: 2.Evaluate: 100%
34/34 [00:04<00:00, 8.05it/s]
Evaluate Score: {'Accuracy': 0.9805555555555555} ---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 2.---------------Epoch 3: 100%
302/302 [02:34<00:00, 1.97it/s, loss=0.08664711]
The maximum number of stored checkpoints has been reached. Checkpoint: 'bert_emotect_epoch_3.ckpt' has been saved in epoch: 3.Evaluate: 100%
34/34 [00:04<00:00, 8.11it/s]
Evaluate Score: {'Accuracy': 0.9916666666666667} ---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 3.---------------Epoch 4: 100%
302/302 [02:34<00:00, 1.97it/s, loss=0.060646668]
The maximum number of stored checkpoints has been reached. Checkpoint: 'bert_emotect_epoch_4.ckpt' has been saved in epoch: 4.Evaluate: 100%
34/34 [00:04<00:00, 7.80it/s]
Evaluate Score: {'Accuracy': 0.9879629629629629} Loading best model from 'checkpoint' with '['Accuracy']': [0.9916666666666667]... ---------------The model is already load the best model from 'bert_emotect_best.ckpt'.--------------- CPU times: user 22min 1s, sys: 13min 27s, total: 35min 28s Wall time: 15min 9s
模型验证
将验证数据集加再进训练好的模型,对数据集进行验证,查看模型在验证数据上面的效果,此处的评价指标为准确率。
evaluator = Evaluator(network=model, eval_dataset=dataset_test, metrics=metric)
evaluator.run(tgt_columns="labels")Evaluate: 100%
33/33 [00:07<00:00, 1.12s/it]
Evaluate Score: {'Accuracy': 0.8947876447876448}
模型推理¶
遍历推理数据集,将结果与标签进行统一展示。
dataset_infer = SentimentDataset("data/infer.tsv")def predict(text, label=None):label_map = {0: "消极", 1: "中性", 2: "积极"}text_tokenized = Tensor([tokenizer(text).input_ids])logits = model(text_tokenized)predict_label = logits[0].asnumpy().argmax()info = f"inputs: '{text}', predict: '{label_map[predict_label]}'"if label is not None:info += f" , label: '{label_map[label]}'"print(info)from mindspore import Tensorfor label, text in dataset_infer:predict(text, label)inputs: '我 要 客观', predict: '中性' , label: '中性' inputs: '靠 你 真是 说 废话 吗', predict: '消极' , label: '消极' inputs: '口嗅 会', predict: '中性' , label: '中性' inputs: '每次 是 表妹 带 窝 飞 因为 窝路痴', predict: '中性' , label: '中性' inputs: '别说 废话 我 问 你 个 问题', predict: '消极' , label: '消极' inputs: '4967 是 新加坡 那 家 银行', predict: '中性' , label: '中性' inputs: '是 我 喜欢 兔子', predict: '积极' , label: '积极' inputs: '你 写 过 黄山 奇石 吗', predict: '中性' , label: '中性' inputs: '一个一个 慢慢来', predict: '中性' , label: '中性' inputs: '我 玩 过 这个 一点 都 不 好玩', predict: '消极' , label: '消极' inputs: '网上 开发 女孩 的 QQ', predict: '中性' , label: '中性' inputs: '背 你 猜 对 了', predict: '中性' , label: '中性' inputs: '我 讨厌 你 , 哼哼 哼 。 。', predict: '消极' , label: '消极'
自定义推理数据集
自己输入推理数据,展示模型的泛化能力。
predict("家人们咱就是说一整个无语住了 绝绝子叠buff")inputs: '家人们咱就是说一整个无语住了 绝绝子叠buff', predict: '中性'
相关文章:
昇思25天训练营Day11 - 基于 MindSpore 实现 BERT 对话情绪识别
模型简介 BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),它是Google于2018年末开发并发布的一种新型语言模型。与BERT模型相似的预训练语言模型例如问答、命名实体识别、自然语言推理、…...

本地开发微信小程序,使用巴比达内网穿透
在微信小程序开发的热潮中,开发者常面临的一个挑战是如何在复杂的网络环境下测试和调试内网环境中的服务。巴比达正为这一难题提供了一条解决方案,极大简化了微信小程序与内网服务器之间通信的流程,加速了开发迭代周期。 以往,开…...

【LeetCode】快乐数
目录 一、题目二、解法完整代码 一、题目 编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变…...

大模型未来发展深度分析
大模型未来发展方向的深度探讨 近年来,人工智能技术的飞速发展,特别是大模型技术的崛起,为全球科技产业带来了前所未有的变革。大模型,以其强大的推理能力、创意生成能力和情绪智能,正在逐步成为推动社会经济发展的核…...
[线性RNN系列] Mamba: S4史诗级升级
前言 iclr24终于可以在openreview上看预印本了 这篇(可能是颠覆之作)文风一眼c re组出品;效果实在太惊艳了,实验相当完善,忍不住写一篇解读分享分享。 TL;DR (overview) Structured State-Sp…...

【鸿蒙学习笔记】元服务
官方文档:元服务规格 目录标题 什么是元服务特征第一个元服务-案例介绍创建项目源码启动模拟器启动entry创建卡片出发元服务 什么是元服务 特征 免安装分包预加载老化和更新机制 第一个元服务-案例介绍 创建项目 源码 Entry Component struct WidgetCard {buil…...

LIS+找规律,CF 582B - Once Again...
一、题目 1、题目描述 2、输入输出 2.1输入 2.2输出 3、原题链接 582B - Once Again... 二、解题报告 1、思路分析 考虑朴素做法对T *n的数组求LIS 但是T * n可达1e9 思考一下,最优解无非就是几个循环节拼接,我们最差情况下对sqrt(T)个a[]求LIS即…...
——开发:数据拆分——实施过程、应用特点)
数据赋能(145)——开发:数据拆分——实施过程、应用特点
实施过程 数据拆分的实施过程通常涉及以下几个关键步骤: 确定拆分目标和需求: 明确数据拆分的目的和需求,例如是为了减少数据处理的复杂性、提高查询效率还是为了满足特定的业务需求。根据需求确定拆分后的数据结构和拆分规则。选择拆分方法…...

【漏洞复现】Splunk Enterprise for Windows 任意文件读取漏洞 CVE-2024-36991
声明:本文档或演示材料仅用于教育和教学目的。如果任何个人或组织利用本文档中的信息进行非法活动,将与本文档的作者或发布者无关。 一、漏洞描述 Splunk Enterprise 是一款强大的机器数据管理和分析平台,广泛应用于企业中,用于实…...

FastAPI -- 第一弹
Hello World 经典的 Hello World 安装 pip install fastapi pip install "uvicorn[standard]"main.py from typing import Unionfrom fastapi import FastAPIapp FastAPI()app.get("/") def read_root():return {"Hello": "World"}…...

C++入门基础篇(1)
欢迎大家来到海盗猫鸥的博客—— 断更许久,让我们继续好好学习吧! 目录 1.namespace命名空间 命名空间的存在价值: 命名空间的定义: 命名空间的使用: 2.C输入输出函数 使用: 3.缺省参数 4.函数重载…...

基于html开发的在线网址导航在线工具箱源码
基于html开发的在线网址导航在线工具箱源码,将全部文件复制到服务器,入口文件是index.html 如需修改网址,可修改index.html 如需修改关于页面,可修改about里面的index页面 源码下载:https://download.csdn.net/down…...

【密码学】大整数分解问题和离散对数问题
公钥密码体制的主要思想是通过一种非对称性,即正向计算简单,逆向计算复杂的加密算法设计,来解决安全通信。本文介绍两种在密码学领域内最为人所熟知、应用最为广泛的数学难题——大整数分解问题与离散对数问题 一、大整数分解问题 …...

解析 pdfminer layout.py LAParams类及其应用实例
解析 pdfminer layout.py LAParams类及其应用实例 引言类的定义1. line_overlap2. char_margin3. word_margin4. line_margin5. boxes_flow6. detect_vertical7. all_texts 类的初始化参数验证类的表示总结 引言 在这篇文章中,我们将解析一个叫做 LAParams 的类。这…...

Redis官方可视化管理工具
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl RedisInsight是一个Redis可视化工具,提供设计、开发和优化 Redis 应用程序的功能。RedisInsight分为免费的社区版和一个付费的企业版,免费版具有基本…...

android 固定图片大小
在Android中,固定图片大小可以通过多种方法实现,这些方法主要涉及到ImageView控件的使用、Bitmap类的操作,以及第三方库(如Glide)的辅助。以下是几种常见的方法: 1. 使用ImageView控件 在Android的布局文…...

操作系统——内存管理(面试准备)
虚拟内存 单片机没有操作系统,每次写完代码,都需要借助工具把程序烧录进去,这样程序才能跑起来。 另外,单片机的CPU是直接操作内存的物理地址。 在这种情况下,想在内存中同时运行两个程序是不可能的,如果第…...

vue3实现vuedraggable实现拖拽到垃圾桶图标位置进行删除
当使用Vue 3和vuedraggable库时,你可以按照以下方式实现拖拽到垃圾桶图标位置进行删除的功能: 首先,确保你已经安装了vuedraggable库。如果没有安装,可以通过以下命令进行安装: vuedraggable 和vue-draggable-plus使…...

MySQL向自增列插入0失败问题
问题 在一次上线时,发现通过脚本添加的状态表中,待提交的状态不正确,本来应该是0,线上是101。 原因 默认情况下,MySQL对应自增列,认为0和null等价(因为mysql认为0不是最佳实践不推荐使用&…...
Python:Python基础知识(注释、命名、数据类型、运算符)
.注释 Python有两种注释方法:单行注释和多行注释。单行注释以#开头,多行注释以三个单引号 或三个双引号 """ 开头和结尾。 2.命名规则 命名规则: 大小写字母、数字、下划线和汉字等字符及组合; 注意事项: 大小写敏感、首…...

Navicat Mac版试用期重置终极指南:3种简单方法实现永久免费使用
Navicat Mac版试用期重置终极指南:3种简单方法实现永久免费使用 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 你…...

如何高效实现Android Studio中文界面革命性升级
如何高效实现Android Studio中文界面革命性升级 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因为Android Studio的英…...
如何让Windows任务栏变透明?TranslucentTB从入门到精通全攻略
如何让Windows任务栏变透明?TranslucentTB从入门到精通全攻略 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否曾经盯着…...

Triton模型服务化:构建高可用AI推理生产系统
1. 项目概述:当模型走出Jupyter,真正开始呼吸真实世界空气“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题本身就像一句暗号,专为那些在Jupyter里调通了模型、画出了漂亮ROC曲线、却在部署时被生产环境…...

从QPLL与CPLL选型到线速计算:一份给Xilinx GTY新手的时钟配置速查手册
从QPLL与CPLL选型到线速计算:一份给Xilinx GTY新手的时钟配置速查手册 第一次接触Xilinx UltraScale系列FPGA的GTY收发器时,最让人头疼的莫过于时钟配置。面对QPLL0、QPLL1和CPLL三种时钟源,以及N1、N2、M、D等分频参数,新手工程师…...

第一性原理计算在半导体缺陷研究中的应用:以氢掺杂氧化镓为例
1. 项目概述:从“掺杂”与“缺陷”说起在半导体材料的研究与开发中,我们常常听到“掺杂”这个词。简单来说,就像在炒菜时撒入不同的调料来改变风味,掺杂就是在纯净的半导体材料(本征材料)中,有目…...

深圳不锈钢五金冲压件
在深圳,不锈钢五金冲压件的市场需求巨大,广泛应用于智能家居、无人机、医疗器械、安防设备等众多领域。然而,面对众多的供应商,如何挑选到合适的合作伙伴成为了许多企业的难题。今天,我们就来对比测评几家深圳的不锈钢…...

MATLAB实战:用冲激响应不变法设计IIR低通滤波器,手把手教你滤除信号噪声
MATLAB实战:用冲激响应不变法设计IIR低通滤波器,手把手教你滤除信号噪声 在工程实践中,信号噪声无处不在。无论是传感器采集的数据,还是音频信号中的背景干扰,噪声都会严重影响后续的分析和处理。IIR(无限脉…...

别再手动写远程搜索了!手把手教你封装一个通用的 Element Plus el-select-v2 组件
打造高复用性远程搜索组件:Element Plus el-select-v2 深度封装指南 在Vue 3和Element Plus构建的中后台系统中,远程搜索下拉框几乎是每个表单页面的标配功能。当项目中有十几个甚至几十个表单都需要实现类似功能时,直接复制粘贴代码不仅导致…...
