RAG实践:ES混合搜索BM25+kNN(cosine)
1 缘起
最近在研究与应用混合搜索,
存储介质为ES,ES作为大佬牌数据库,
非常友好地支持关键词检索和向量检索,
当然,支持混合检索(关键词检索+向量检索),
是提升LLM响应质量RAG(Retrieval-augmented Generation)的一种技术手段,
那么,如何通过ES实现混合搜索呢?
请看本篇文章。
本系列分为两大部分:实践和理论。
先讲实践,应对快速开发迭代,可快速上手实践;
再讲理论,应对优化,如归一化。
RAG理论:ES混合搜索BM25+kNN(cosine)以及归一化https://blog.csdn.net/Xin_101/article/details/140237669

2 实践
2.1 环境准备
2.1.1 部署ES
- 下载ES镜像:8.12.2版本
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.12.2
- 下载ik分词器
https://github.com/infinilabs/analysis-ik/releases
选择与ES版本一致或者可用的版本,这里选择8.12.2版本分词器。

-
添加分词器
将分词器文件添加到目录:/home/xindaqi/data/es-8-12-2/plugins
新建分词器文件夹:mkdir -p /home/xindaqi/data/es-8-12-2/plugins/ik_analyzer_8.12.2
将zip文件复制到文件夹:ik_analyzer_8.12.2 -
启动ES
docker run -dit \
--restart=always \
--name es01-8-12-2 \
-p 9200:9200 \
-p 9300:9300 \
-v /home/xindaqi/data/es-8-12-2/data:/usr/share/elasticsearch/data \
-v /home/xindaqi/data/es-8-12-2/logs:/usr/share/elasticsearch/logs \
-v /home/xindaqi/data/es-8-12-2/plugins:/usr/share/elasticsearch/plugins \
-e ES_JAVA_OPS="-Xms512m -Xmx1g" \
-e discovery.type="single-node" \
-e ELASTIC_PASSWORD="admin-es" \
-m 1GB \
docker.elastic.co/elasticsearch/elasticsearch:8.12.2
2.1.2 数据准备
实践之前,需要准备数据,包括索引和索引中存储的数据。
为了演示混合搜索,这里创建两种类型的数据:text和dense_vector。
(1)创建索引
curl -X 'PUT' \'http://localhost:9200/vector_5' \-H 'accept: application/json' \-H 'Content-Type: application/json' \-H 'Authorization: Basic ZWxhc3RpYzphZG1pbi1lcw==' \-d '{"settings": {"index": {"number_of_shards": 1,"number_of_replicas": 1,"refresh_interval": "3s"}},"mappings": {"properties": {"dense_values": {"type": "dense_vector","dims": 5,"index": true,"similarity": "cosine"},"id": {"type": "keyword"},"ik_text": {"type": "text","analyzer": "ik_max_word"},"default_text": {"type": "text"},"timestamp": {"type": "long"},"dimensions": {"type": "integer"}}}
}'
(2)新建数据
新建两条数据:
curl -X POST 'http://localhost:9200/vector_5/_doc/1' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic ZWxhc3RpYzphZG1pbi1lcw==' \
--data '{"dense_values": [0.1, 0.2, 0.3, 0.4, 0.5],"id": "1","ik_text": "今天去旅游了","default_text":"今天去旅游了","timestamp": 1715659103373,"dimensions": 5
}'curl -X POST 'http://localhost:9200/vector_5/_doc/2' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic ZWxhc3RpYzphZG1pbi1lcw==' \
--data '{"dense_values": [0.1, 0.2, 0.3, 0.4, 0.5],"id": "1","ik_text": "好美的太阳","default_text":"好美的太阳","timestamp": 1715659103373,"dimensions": 5
}'
2.2 向量搜索
kNN搜索
ES中向量搜索使用k-Nearest Neighbor(k最近邻分类算法)进行搜索。
输入的请求参数如下:
| 参数 | 参数 | 描述 |
|---|---|---|
| knn | 向量搜索k-Nearest Neighbor | |
| field | 向量字段名称 | |
| query_vector | 向量值 | |
| k | 召回结果数量 | |
| num_candidates | 召回范围,每个分片选取的数量 |
请求样例如下:
由样例可知,存储向量数据的字段名称为:dense_values,填充向量值字段为query_vector(为固定属性),召回结果k为3个,每个分片选择100条数据(num_candidates),最大值为:10000。
实际应用过程中,又有向量数据较多(依据维度而定),为节约内存,检索时,在结果中排除,excludes。
curl -X POST 'http://localhost:9200/vector_5/_search' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic ZWxhc3RpYzphZG1pbi1lcw==' \
--data '{"knn": {"field": "dense_values","query_vector": [0.1,0.1,0.1,0.1,0.1],"k": 3,"num_candidates": 100},"_source": {"excludes": ["dense_values"]}
}'
检索结果如下,
由于创建过程中使用的向量数据相同,因此计算的结果也是相同的,
使用
{"took": 2,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 0.8427159,"hits": [{"_index": "vector_5","_id": "1","_score": 0.8427159,"_source": {"id": "1","ik_text": "今天去旅游了","default_text": "今天去旅游了","timestamp": 1715659103373,"dimensions": 5}},{"_index": "vector_5","_id": "2","_score": 0.8427159,"_source": {"id": "1","ik_text": "好美的太阳","default_text": "好美的太阳","timestamp": 1715659103373,"dimensions": 5}}]}
}
2.2 混合搜索
混合搜索即将搜索拆分成多个部分,每个部分使用不同的权重,实现混合搜索的效果。
ES中使用boost参数来分配不同部分的权重,搜索案例如下。
由案例可知,混合搜索使用关键词+向量搜索,关键词b1与向量总权重b2,其中b1+b2=1,
案例中关键词权重为0.6,向量权重0.4,
关键词搜索将搜索的内容映射到query上,权重映射到boost上,
default_text为实际存储的属性名称。
curl -X POST 'http://localhost:9200/vector_5/_search' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic ZWxhc3RpYzphZG1pbi1lcw==' \
--data '{"query": {"bool": {"must": [{"match": {"default_text": {"query": "好美的太阳","boost": 0.6}}}]}},"knn": {"field": "dense_values","query_vector": [0.1,0.1,0.1,0.1,0.1],"k": 3,"num_candidates": 100,"boost": 0.4},"_source": {"excludes": ["dense_values"]}
}'
3 小结
(1)ES混合搜索:通过boost配置比例,其中,关键词计算使用BM25计算分数,同时加入boost参数;
(2)关键词搜索boost基础比例为2.2,计算过程boost=2.2boost;
(3)向量搜索的最终分数为:final_score=boostkNN。
计算过程参见文章:RAG理论:ES混合搜索BM25+kNN(cosine)以及归一化
https://blog.csdn.net/Xin_101/article/details/140237669
相关文章:
RAG实践:ES混合搜索BM25+kNN(cosine)
1 缘起 最近在研究与应用混合搜索, 存储介质为ES,ES作为大佬牌数据库, 非常友好地支持关键词检索和向量检索, 当然,支持混合检索(关键词检索向量检索), 是提升LLM响应质量RAG(Retri…...
论文去AIGC痕迹:避免AI写作被检测的技巧
在数字化时代,AI正以其卓越的能力重塑学术写作的面貌。AI论文工具的兴起,为研究者们提供了前所未有的便利,但同时也引发了关于学术诚信和原创性的热烈讨论。当AI辅助写作成为常态,如何确保论文的独创性和个人思想的体现࿰…...

C#使用异步方式调用同步方法的实现方法
使用异步方式调用同步方法,在此我们使用异步编程模型(APM)实现 1、定义异步委托和测试方法 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading; using System.Threading.Task…...
【Go系列】 Go语言的入门
为什么要学习Go 从今天起,我们将一同启程探索 Go 语言的奥秘。我会用简单明了的方式,逐一讲解 Go 语言的各个知识点,帮助你从基础做起,一步步深化理解。不论你之前是否有过 Go 语言的接触经验,这个系列文章都将助你收获…...

Dify 与 Xinference 最佳组合 GPU 环境部署全流程
背景介绍 在前一篇文章 RAG 项目对比 之后,确定 Dify 目前最合适的 RAG 框架。本次就尝试在本地 GPU 设备上部署 Dify 服务。 Dify 是将模型的加载独立出去的,因此需要选择合适的模型加载框架。调研一番之后选择了 Xinference,理由如下&…...

MICCAI 2024Centerline Boundary Dice Loss for Vascular Segmentation
MICCAI 2024 Centerline Boundary Dice Loss for Vascular Segmentation MICCAI 2024Centerline Boundary Dice Loss for Vascular Segmentation中心线边界Dice损失用于血管分割**摘要**:1. 引言相关工作: 2. 方法预备知识Dice的变化 3 实验3.1 数据集3.2 设置3.3 结…...

golang验证Etherscan上的智能合约
文章目录 golang验证Etherscan上的智能合约为什么要验证智能合约如何使用golang去验证合约获取EtherscanAPI密钥Verify Source Code接口Check Source Code Verification Status接口演示示例及注意事项网络问题无法调用Etherscan接口(最重要的步骤) golan…...

Visual Studio编译优化选项
目录 /O1 和 /O2 /Ox 内联函数 虚函数优化 代码重排 循环优化 链接时间优化 代码分割 数学优化 其他优化选项 在Visual Studio中,编译优化选项是用于提高程序性能的重要工具。编译器提供了多种优化级别和选项,可以根据不同的需要进行选择。 在…...

sql业务场景分析思路参考
1、时间可以进行排序,也可以用聚合函数对时间求最大值max(时间) 例如下面的例子:取最晚入职的人,那就是将入职时间倒序排序,然后limit 1 表: 场景:查找最晚入职员工的所有信息 se…...

Django权限系统如何使用?
Django的权限系统是一个强大而灵活的特性,允许你控制不同用户对应用程序中资源的访问。以下是使用Django权限系统的几个基本步骤: 1. 定义模型权限 在你的models.py文件中,你可以为每个模型定义自定义权限。这通过在模型的Meta类里设置perm…...
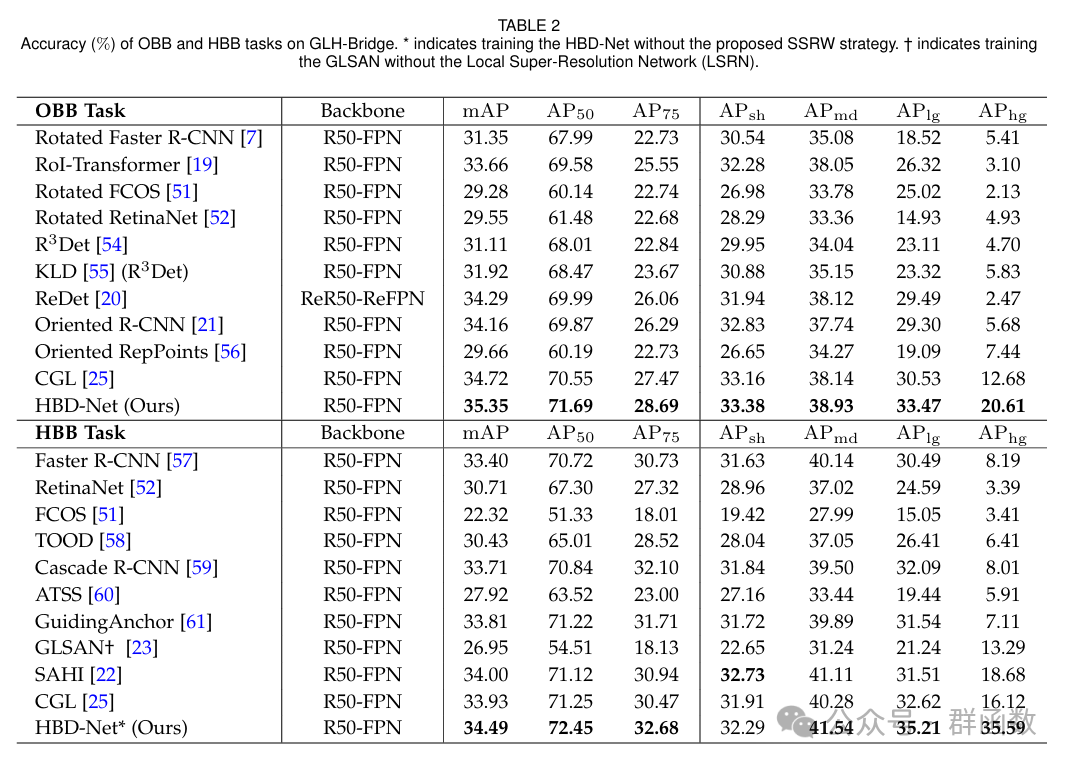
基于整体学习的大幅面超高分遥感影像桥梁目标检测(含数据集下载地址)
文章摘要 在遥感图像(RSIs)中进行桥梁检测在各种应用中起着至关重要的作用,但与其他对象检测相比,桥梁检测面临独特的挑战。在RSIs中,桥梁在空间尺度和纵横比方面表现出相当大的变化。因此,为了确保桥梁的…...

逻辑回归模型(非回归问题,而是解决二分类问题)
目录: 一、Sigmoid激活函数:二、逻辑回归介绍:三、决策边界四、逻辑回归模型训练过程:1.训练目标:2.梯度下降调整参数: 一、Sigmoid激活函数: Sigmoid函数是构建逻辑回归模型的重要激活函数&am…...

QT的OpenGL渲染窗QOpenGLWidget Class
Qt - QOpenGLWidget (class) (runebook.dev) 一、说明 QOpenGLWidget 类是用于渲染 OpenGL 图形的小部件。从Qt 5.4就开始退出,它对于OpenGL有专门的配合设计。 二、QOpenGLWidget类的成员 2.1 Public类函数 QOpenGLWidget(QWidget *parent nullptr,Qt…...

单元测试和集成测试
软件测试中,单元测试和集成测试是比较常见的方法 单元测试:这是一种专注于最小可测试单元(通常是函数或方法)的测试,用于验证单个组件的行为是否符合预期。它通常由开发者自己完成,可以尽早发现问题&#…...

【JAVA入门】Day15 - 接口
【JAVA入门】Day15 - 接口 文章目录 【JAVA入门】Day15 - 接口一、接口是对“行为”的抽象二、接口的定义和使用三、接口中成员的特点四、接口和类之间的关系五、接口中新增的方法5.1 JDK8开始接口中新增的方法5.1.1 接口中的默认方法5.1.2 接口中的静态方法 5.2 JDK9 开始接口…...
)
ES6 之 Set 与 Map 数据结构要点总结(一)
Set 数据结构 Set 对象允许你存储任何类型的唯一值,无论是原始值还是对象引用。 特性: 所有值都是唯一的,没有重复。值的顺序是根据添加的顺序确定的。可以使用迭代器遍历 Set。 常用方法: 1. add(value):添加一个新…...
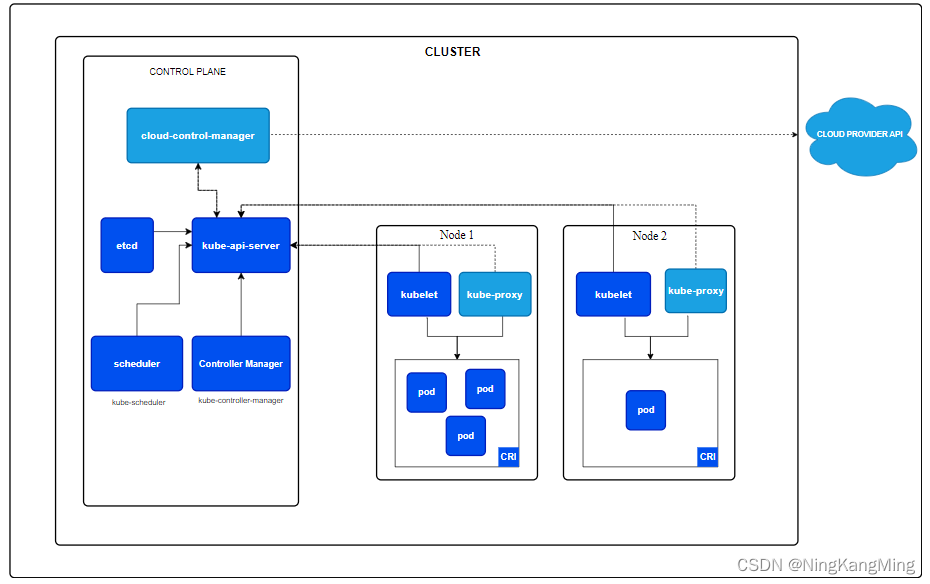
一文学会用RKE部署高可用Kubernetes集群
k8s架构图 RKE简介 RKE全称Rancher Kubernetes Engine,是一个快速的,多功能的 Kubernetes 安装工具。通过RKE,我们可以快速的安装一个高可用K8S集群。RKE 支持多种操作系统,包括 MacOS、Linux 和 Windows。 K8S原生安装需要的先…...

数据加密的常见方法
数据加密是一门历史悠久的技术,它通过加密算法和加密密钥将明文(原始的或未加密的数据)转变为密文,而解密则是通过解密算法和解密密钥将密文恢复为明文。这一技术的核心是密码学,它利用密码技术对信息进行加密,实现信息隐蔽&#…...

天童美语:推荐给孩子的人文历史纪录片
孩子们都有自己的偏好,有的孩子喜欢打游戏,有的孩子喜欢看剧看电影,有的孩子喜欢看书。针对不同的孩子我们要因材施教,所以,广州天童教育给大家推荐一下适合给孩子看的人文历史类的纪录片,让精美的画面&…...

数字人技术如何推动教育事业可持续创新发展?
数字人技术作为一种新兴的教育手段,无论是幼儿园还是大学课堂,数字人都可以融入于各阶段教育中,结合动作捕捉、AI等技术,提高教育资源的利用。 AI智能交互数字人应用: 数字人结合NLP自然语言处理技术以及AI大模型技术…...

私域矩阵系统的生态困境:用种群动力学模型,破解“流量养不活“的死局
你花了3个月、投了2万块,拉了5000人进私域——然后呢?90%的人沉默,5%的人屏蔽你,3%的人偶尔回一句"在吗",真正下单的不到2%。你以为是话术不行?是产品不行?是运气不好?都不…...

成都制造企业供应链价格波动频繁,AI智能体该先预警哪些信号?
一、价格波动不是采购一个部门能扛住的问题很多制造企业谈供应链价格波动,第一反应是让采购去谈价、催报价、找替代供应商。但在真实经营里,价格风险很少只停留在采购单价上。铜、铝、钢材、塑料、电子元器件、包装材料、运费、汇率和供应商产能变化&…...

混合专家MoE拆解:GPT-4、千问、DeepSeek为什么都选这个架构
去年我写了个小模型做文本分类,全部参数只有1.5B,单卡就能跑。结果效果还行,但跟大模型比就是被吊打。 我就想,为什么那些几百B甚至上T参数的大模型,推理速度没比我的小模型慢一万倍? 答案就在MoE&#x…...

7 年评测经验博主发布扫地机器人挑选指南,邀你探讨机器人革命!
评测多款扫地机器人,Matic 脱颖而出博主发布了关于挑选最佳扫地机器人的指南,近期评测了戴森的 Spot & Scrub、鲨客的 Power Detect 以及 Matic。在其 7 年的扫地机器人评测生涯中,Matic 是最有意思的新型扫地机器人。拨开营销迷雾&#…...

Python机器学习实战路线图:从EDA到模型部署的工业级路径
1. 这不是“速成课”,而是一份我带过37个转行学员后重写的Python机器学习实战路线图 你点开这篇,大概率正站在两个路口之间:一边是刷了三个月Kaggle入门赛却卡在特征工程上动弹不得,另一边是翻烂了《统计学习方法》却连一个能跑通…...

如何在3分钟内免费解决Windows HEIC缩略图预览难题
如何在3分钟内免费解决Windows HEIC缩略图预览难题 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 你是否经常遇到iPhone拍摄的照…...

政策快报网的申报引擎:从政策匹配到材料准备的全流程设计
用户通过政策匹配引擎找到了一条适合自己的政策,然后呢? 这是很多政策信息平台共同面临的问题。在传统的政策快报网设计思路中,价值链条往往止步于“告诉用户有这条政策”。但真正的需求远不止于此——用户需要知道申报截止时间、需要准备哪些材料、材料有什么格式要求、提…...

Taotoken用量看板如何帮助团队清晰掌控AI支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队清晰掌控AI支出 1. 从模糊到清晰:AI成本管理的挑战 在团队项目中集成大模型能力&#x…...

深入解析uCOSII就绪表:实时操作系统调度核心与优化实践
1. 项目概述:从“就绪表”窥探实时操作系统的调度心脏如果你接触过嵌入式实时操作系统,尤其是经典的ucOSII,那么“就绪表”这个词你一定不陌生。它不像任务创建、信号量、消息队列那样经常被挂在嘴边,但却是整个系统任务调度的核心…...

微信红包背后的技术博弈:一个Android辅助服务的实战剖析
微信红包背后的技术博弈:一个Android辅助服务的实战剖析 【免费下载链接】WeChatLuckyMoney :money_with_wings: WeChats lucky money helper (微信抢红包插件) by Zhongyi Tong. An Android app that helps you snatch red packets in WeChat groups. 项目地址:…...