Dify 与 Xinference 最佳组合 GPU 环境部署全流程
背景介绍
在前一篇文章 RAG 项目对比 之后,确定 Dify 目前最合适的 RAG 框架。本次就尝试在本地 GPU 设备上部署 Dify 服务。
Dify 是将模型的加载独立出去的,因此需要选择合适的模型加载框架。调研一番之后选择了 Xinference,理由如下:
- 支持多种类型的模型,包括 LLM,Embedding, Rerank, Audio 等多种业务场景的模型需求,一个框架全搞定;
- 方便的模型管理能力,提供可视化页面快速部署模型
- 支持直接从 ModelScope 下载模型,避免 huggingface 被墙的问题;
本文是 Dify 与 Xinference 最佳组合的 GPU 设备部署流程。为了充分利用 nvidia GPU 的能力,需要先安装显卡驱动,CUDA 和 CuDNN,这部分网上的教程比较多了,大家可以自行搜索参考安装,安装时需要注意版本需要与自己的 GPU 显卡版本匹配。
Dify 部署
参考 Dify 官方文档 进行安装。
首先需要下载 Dify 对应的代码:
git clone https://github.com/langgenius/dify.git
之后创建环境变量文件 .env, 根据需要进行修改,之后就可以基于 docker compose 启动:
cd dify/docker
cp .env.example .env
docker compose up -d
默认访问 http:// 应该就可以看到 Dify 的页面。
docker 镜像问题
实际执行镜像拉取时发现,Docker hub 因为监管的原因已经无法访问了。为了解决这个问题,目前相对可行的方案:
- 利用一些目前可用的镜像服务,当前(2024-7-11)可用的是 public-image-mirror,通过修改本地的镜像下载地址进行加速;
- 利用 Github Action 将镜像拉取至个人阿里云的的私有镜像仓库,可以参考 教程;
实际为了简单直接采用方案 1,在本地文件 /etc/docker/daemon.json 中添加:
{"registry-mirrors": ["https://docker.m.daocloud.io"]
}
如果上面的地址不可用,可以尝试另一个测试可用的地址:
{"registry-mirrors": ["https://docker.anyhub.us.kg"]
}
修改之后执行下面命令重启 docker 服务:
sudo systemctl daemon-reload
sudo systemctl restart docker
接下来就可以正常拉取镜像了。
Xinference 部署
XInference 的部署也选择基于 docker 部署,可以参考 XInference 部署,实际使用的部署命令为:
docker run -e XINFERENCE_MODEL_SRC=modelscope -v <local model path>:/models -e XINFERENCE_HOME=/models -p 9998:9997 --gpus all registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:latest xinference-local -H 0.0.0.0
各位使用时将上面命令行中的 <local model path> 替换为期望服务器上模型存储的路径即可
上面的命令利用 XINFERENCE_MODEL_SRC=modelscope 指定了模型最终是从 modelscope 下载的,这样国内下载模型镜像的速度比较快。
上面的命令会将 docker 中的 9997 端口映射至本地的 9998 端口,部署完成后访问 http://<server ip>:9998/ui 就可以看到 XInference 可视化页面,有需要可以调整服务器上实际占用的端口。
docker GPU 不可用
上面的命令实际执行时会报错 docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]]., docker 目前是不能直接使用 GPU 设备的。
此时需要参考 Nvidia 文档 安装 nvidia-container-toolkit
首先需要先补全 apt-get 下载源:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
接下来更新源,安装对应的包:
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
安装完成之后修改 docker 配置文件 /etc/docker/daemon.json :
{"default-runtime": "nvidia","runtimes": {"nvidia": {"path": "nvidia-container-runtime","runtimeArgs": []}}
}
之后执行 sudo systemctl restart docker 重启 docker。
此时再执行上面的 docker run 命令去使用 GPU 设备就没问题了。
Dify 模型配置
上述服务配置好之后,就可以在 Xinference 下载所需的模型,XInference 启动后实际会占用服务器上的 9998。因此访问 http://<server ip>:9998/ui 就可以进入可视化页面下载所需的模型;
在 Xinference 上下载和运行所需的模型后可以返回 Dify 可视化页面,在 Dify 的设置页中配置对应的模型,对应的页面如下所示:

RAG 一般情况下需要配置上 LLM, Text Embedding 和 Rerank 模型。配置完成后就可以自由玩耍了。
总结
本文是实际部署 Dify + Xinference 组合的完整流程,实际上如果 docker 可用的话,整体的流程还是比较丝滑的。期望给后面折腾 Dify 部署的一些帮助,减少重复的踩坑。
相关文章:
Dify 与 Xinference 最佳组合 GPU 环境部署全流程
背景介绍 在前一篇文章 RAG 项目对比 之后,确定 Dify 目前最合适的 RAG 框架。本次就尝试在本地 GPU 设备上部署 Dify 服务。 Dify 是将模型的加载独立出去的,因此需要选择合适的模型加载框架。调研一番之后选择了 Xinference,理由如下&…...

MICCAI 2024Centerline Boundary Dice Loss for Vascular Segmentation
MICCAI 2024 Centerline Boundary Dice Loss for Vascular Segmentation MICCAI 2024Centerline Boundary Dice Loss for Vascular Segmentation中心线边界Dice损失用于血管分割**摘要**:1. 引言相关工作: 2. 方法预备知识Dice的变化 3 实验3.1 数据集3.2 设置3.3 结…...

golang验证Etherscan上的智能合约
文章目录 golang验证Etherscan上的智能合约为什么要验证智能合约如何使用golang去验证合约获取EtherscanAPI密钥Verify Source Code接口Check Source Code Verification Status接口演示示例及注意事项网络问题无法调用Etherscan接口(最重要的步骤) golan…...

Visual Studio编译优化选项
目录 /O1 和 /O2 /Ox 内联函数 虚函数优化 代码重排 循环优化 链接时间优化 代码分割 数学优化 其他优化选项 在Visual Studio中,编译优化选项是用于提高程序性能的重要工具。编译器提供了多种优化级别和选项,可以根据不同的需要进行选择。 在…...

sql业务场景分析思路参考
1、时间可以进行排序,也可以用聚合函数对时间求最大值max(时间) 例如下面的例子:取最晚入职的人,那就是将入职时间倒序排序,然后limit 1 表: 场景:查找最晚入职员工的所有信息 se…...

Django权限系统如何使用?
Django的权限系统是一个强大而灵活的特性,允许你控制不同用户对应用程序中资源的访问。以下是使用Django权限系统的几个基本步骤: 1. 定义模型权限 在你的models.py文件中,你可以为每个模型定义自定义权限。这通过在模型的Meta类里设置perm…...
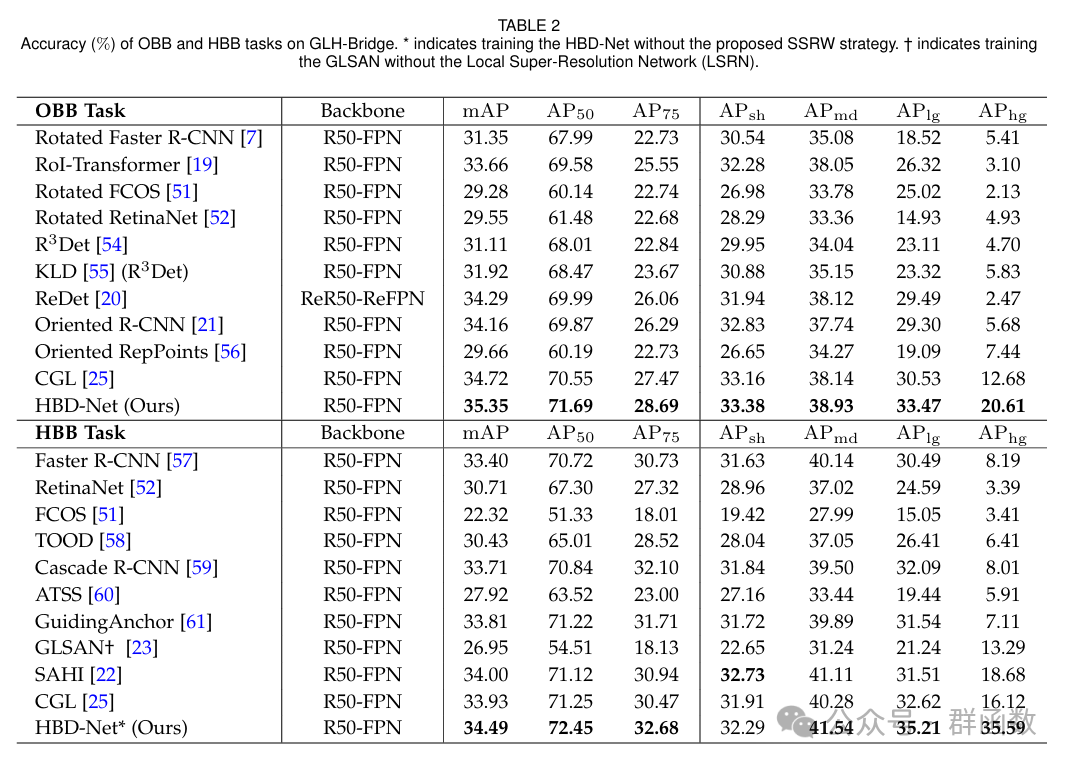
基于整体学习的大幅面超高分遥感影像桥梁目标检测(含数据集下载地址)
文章摘要 在遥感图像(RSIs)中进行桥梁检测在各种应用中起着至关重要的作用,但与其他对象检测相比,桥梁检测面临独特的挑战。在RSIs中,桥梁在空间尺度和纵横比方面表现出相当大的变化。因此,为了确保桥梁的…...

逻辑回归模型(非回归问题,而是解决二分类问题)
目录: 一、Sigmoid激活函数:二、逻辑回归介绍:三、决策边界四、逻辑回归模型训练过程:1.训练目标:2.梯度下降调整参数: 一、Sigmoid激活函数: Sigmoid函数是构建逻辑回归模型的重要激活函数&am…...

QT的OpenGL渲染窗QOpenGLWidget Class
Qt - QOpenGLWidget (class) (runebook.dev) 一、说明 QOpenGLWidget 类是用于渲染 OpenGL 图形的小部件。从Qt 5.4就开始退出,它对于OpenGL有专门的配合设计。 二、QOpenGLWidget类的成员 2.1 Public类函数 QOpenGLWidget(QWidget *parent nullptr,Qt…...

单元测试和集成测试
软件测试中,单元测试和集成测试是比较常见的方法 单元测试:这是一种专注于最小可测试单元(通常是函数或方法)的测试,用于验证单个组件的行为是否符合预期。它通常由开发者自己完成,可以尽早发现问题&#…...

【JAVA入门】Day15 - 接口
【JAVA入门】Day15 - 接口 文章目录 【JAVA入门】Day15 - 接口一、接口是对“行为”的抽象二、接口的定义和使用三、接口中成员的特点四、接口和类之间的关系五、接口中新增的方法5.1 JDK8开始接口中新增的方法5.1.1 接口中的默认方法5.1.2 接口中的静态方法 5.2 JDK9 开始接口…...
)
ES6 之 Set 与 Map 数据结构要点总结(一)
Set 数据结构 Set 对象允许你存储任何类型的唯一值,无论是原始值还是对象引用。 特性: 所有值都是唯一的,没有重复。值的顺序是根据添加的顺序确定的。可以使用迭代器遍历 Set。 常用方法: 1. add(value):添加一个新…...
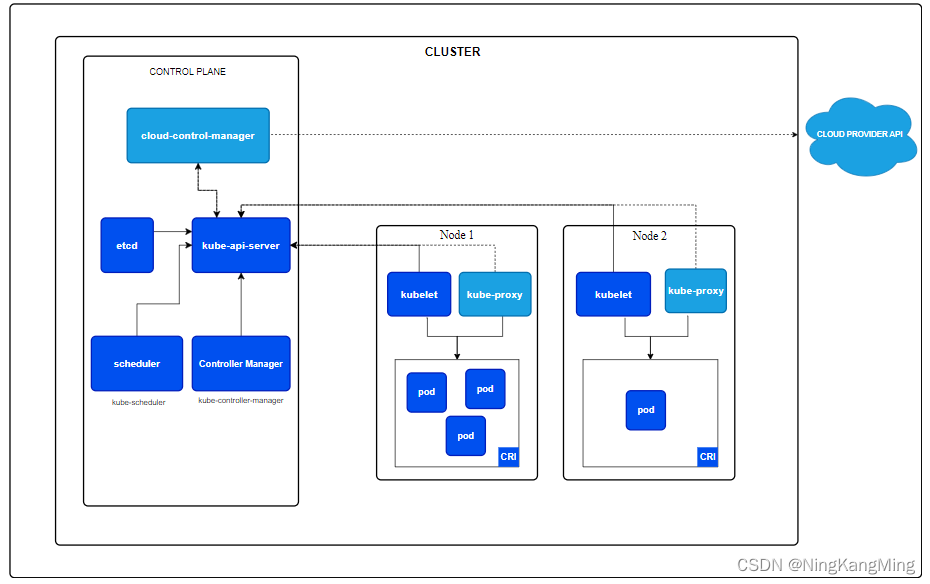
一文学会用RKE部署高可用Kubernetes集群
k8s架构图 RKE简介 RKE全称Rancher Kubernetes Engine,是一个快速的,多功能的 Kubernetes 安装工具。通过RKE,我们可以快速的安装一个高可用K8S集群。RKE 支持多种操作系统,包括 MacOS、Linux 和 Windows。 K8S原生安装需要的先…...

数据加密的常见方法
数据加密是一门历史悠久的技术,它通过加密算法和加密密钥将明文(原始的或未加密的数据)转变为密文,而解密则是通过解密算法和解密密钥将密文恢复为明文。这一技术的核心是密码学,它利用密码技术对信息进行加密,实现信息隐蔽&#…...

天童美语:推荐给孩子的人文历史纪录片
孩子们都有自己的偏好,有的孩子喜欢打游戏,有的孩子喜欢看剧看电影,有的孩子喜欢看书。针对不同的孩子我们要因材施教,所以,广州天童教育给大家推荐一下适合给孩子看的人文历史类的纪录片,让精美的画面&…...

数字人技术如何推动教育事业可持续创新发展?
数字人技术作为一种新兴的教育手段,无论是幼儿园还是大学课堂,数字人都可以融入于各阶段教育中,结合动作捕捉、AI等技术,提高教育资源的利用。 AI智能交互数字人应用: 数字人结合NLP自然语言处理技术以及AI大模型技术…...
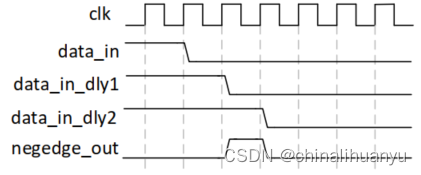
FPGA程序设计
在设计FPGA时,多运用模块化的思想取设计模块,将某一功能设计成module。 设计之前要先画一下模块设计图,列出输入输出接口,再进一步设计内部功能。 状态机要画图,确定每个状态和状态之间怎么切换。状态用localparam定…...

彻底开源,免费商用,上海AI实验室把大模型门槛打下来
终于,业内迎来了首个全链条大模型开源体系。 大模型领域,有人探索前沿技术,有人在加速落地,也有人正在推动整个社区进步。 就在近日,AI 社区迎来首个统一的全链条贯穿的大模型开源体系。 虽然社区有LLaMA等影响力较大…...

MTEB评估基准使用指北
文章目录 介绍评估数据 介绍 文本嵌入通常是在单一任务的少量数据集上进行评估,这些数据集未涵盖其可能应用于其他任务的情况,不清楚在语义文本相似性(semantic textual similarity, STS)等任务上的最先进嵌入是否同样适用于聚类或…...

31. 1049. 最后一块石头的重量 II, 494.目标和,474.一和零
class Solution { public:int lastStoneWeightII(vector<int>& stones) {int sum 0;for(int stone : stones) sum stone;int bagSize sum /2;vector<int> dp(bagSize 1, 0);for(int i 0; i < stones.size(); i){ //遍历物品for(int j bagSize; j >…...
)
AI动态简报之技术前沿篇(2026.05.22)
📅 2026年5月22日 | 关注方向:AI技术突破 大模型创新 AI Agent 生成式AI 多模态AI 🔥 第1条:谷歌I/O 2026三箭齐发——Gemini 3.5 Flash速度碾压4倍、Spark全天候Agent、Omni全栈多模态 核心内容: 谷歌I/O 2026以…...

【火箭】基于matlab模拟运载火箭俯仰控制系统中基于IMU的故障检测并结合执行器动力学【含Matlab源码 15550期】含报告
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

FlashAttention 深度解读:让大模型注意力机制“一口气算完“
FlashAttention:让大模型注意力机制"一口气算完" 想象你在厨房做菜。冰箱在远处(HBM,高带宽内存),料理台在面前(SRAM,片上缓存)。每次要切菜,都得走过去开冰箱…...

如何快速配置FanControl风扇控制:从安装到优化的完整指南
如何快速配置FanControl风扇控制:从安装到优化的完整指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

【Go i18n】TOML语言包
一、VS Code 必备的 TOML 插件1. Even Better TOML(核心高亮与语法检查 👑)搜索关键字:Even Better TOML为什么要装:它是目前全网公认第一的 TOML 插件。装上它之后,你的 .toml 文件不仅会变得色彩斑斓&…...

JMeter分布式压测原理与高可用集群搭建实战
1. 为什么单台JMeter跑不出真实流量——分布式压测不是“加机器”那么简单 你有没有试过用Jmeter对一个新上线的订单服务做压测,本地配了200个线程,结果TPS卡在80就上不去了,CPU才用了35%,网络IO几乎为零?我第一次遇到…...

2026亲测:专业降AI率工具选这款就对了3秒改写无痕迹
2026 年降 AIGC 工具已从“基础语义替换”进化为多维度智能优化系统,核心评估指标涵盖 AI 痕迹清除效率、专业表达准确性、格式结构完整性、长段落逻辑稳定性、内容重合度降低效果及高校检测平台兼容性。本次测评深入分析 5 款主流工具,测试范围包括中英…...

Unity构建性能分析工具:四层数据采集与包体优化实战
1. 这不是又一个“构建日志查看器”,而是一把能切开Unity构建黑箱的手术刀 我第一次在客户项目里看到Build Report Tool时,它正安静地躺在一个被遗忘的Plugins文件夹里,名字叫 BuildReportTool_v2.3.1.unitypackage 。当时团队正为一个中型…...

Go语言Web应用部署与运维实战
Go语言Web应用部署与运维实战 引言 部署和运维是Web应用生命周期的重要环节。本文将深入探讨Go语言Web应用的部署策略和运维最佳实践,帮助开发者构建稳定可靠的生产环境。 一、部署前准备 1.1 编译优化 // main.go package mainimport "github.com/gin-gonic/g…...

终极游戏模组管理指南:Nexus Mods App如何让你轻松玩转模组世界
终极游戏模组管理指南:Nexus Mods App如何让你轻松玩转模组世界 【免费下载链接】NexusMods.App Home of the development of the Nexus Mods App 项目地址: https://gitcode.com/gh_mirrors/ne/NexusMods.App 厌倦了手动安装模组时的各种冲突和兼容性问题&a…...