sklearn基础教程:掌握机器学习入门的钥匙
sklearn基础教程:掌握机器学习入门的钥匙
在数据科学和机器学习的广阔领域中,scikit-learn(简称sklearn)无疑是最受欢迎且功能强大的库之一。它提供了简单而高效的数据挖掘和数据分析工具,让研究人员、数据科学家以及机器学习爱好者能够轻松地实现各种算法。本文将带你走进sklearn的世界,从基础安装到核心功能,一步步掌握这个强大的工具。
一、sklearn简介
scikit-learn是基于Python的一个开源机器学习库,它建立在NumPy、SciPy和matplotlib之上,提供了大量的算法和工具,用于数据挖掘和数据分析。无论是简单的线性回归,还是复杂的神经网络,sklearn都能提供直观易用的接口。
二、安装sklearn
在开始使用sklearn之前,你需要确保已经安装了Python环境。接下来,你可以通过pip命令轻松安装scikit-learn:
pip install scikit-learn
安装完成后,你就可以在Python代码中导入并使用sklearn了。
三、基础操作
1. 数据加载与预处理
sklearn提供了多种数据加载工具,如datasets模块,用于加载标准数据集进行测试。同时,它也提供了丰富的数据预处理功能,如特征缩放、编码分类变量等。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 加载iris数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
2. 模型训练与评估
sklearn支持多种机器学习算法,从简单的线性模型到复杂的集成方法。训练模型通常涉及选择适当的算法类、初始化模型对象、调用fit方法进行训练,并使用predict方法进行预测。
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 初始化逻辑回归模型
model = LogisticRegression()# 训练模型
model.fit(X_train_scaled, y_train)# 预测测试集
y_pred = model.predict(X_test_scaled)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
3. 模型选择与调优
在实际应用中,选择合适的模型和参数对模型性能至关重要。sklearn提供了交叉验证、网格搜索等工具,帮助用户自动进行模型选择和参数调优。
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'C': [0.1, 1, 10], 'max_iter': [100, 200]}# 初始化网格搜索对象
grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5)# 执行网格搜索
grid_search.fit(X_train_scaled, y_train)# 获取最佳参数和最佳模型
best_params = grid_search.best_params_
best_model = grid_search.best_estimator_# 使用最佳模型进行预测和评估(略)
四、进阶应用
除了上述基础操作外,sklearn还支持更高级的机器学习技术,如降维(PCA、LDA)、聚类(K-means)、集成学习(随机森林、梯度提升树)等。通过深入学习和实践,你可以逐步掌握这些技术,并应用于更复杂的实际问题中。
1. 降维
主成分分析(PCA)
理论背景: 主成分分析(PCA)是一种统计过程,通过正交变换将可能相关的变量转换为一组线性不相关的变量,称为主成分。这些主成分按照方差从大到小排列,第一个主成分具有最大的方差,后续主成分方差依次减小。PCA常用于降维,保留数据中的主要变化模式。
代码示例:
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler# 假设X_train是原始特征数据
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)# 选择要保留的主成分数量
n_components = 2
pca = PCA(n_components=n_components)
X_train_pca = pca.fit_transform(X_train_scaled)# 输出降维后的数据维度
print(X_train_pca.shape) # 应该是 (n_samples, n_components)# 可视化降维结果(如果n_components <= 3)
import matplotlib.pyplot as plt
plt.scatter(X_train_pca[:, 0], X_train_pca[:, 1], c=y_train)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Iris Dataset')
plt.show()
2. 聚类
K-means聚类
理论背景: K-means是一种迭代求解的聚类算法,目的是将数据分为K个簇,使得簇内点之间的距离尽可能小,而簇间距离尽可能大。算法首先随机选择K个点作为初始簇中心,然后将每个点分配给最近的簇中心,之后更新簇中心为簇内所有点的均值,重复这个过程直到簇中心不再发生变化或达到预定的迭代次数。
代码示例:
from sklearn.cluster import KMeans# 假设X_train_scaled是已经标准化处理的特征数据
k = 3 # 假设我们想要将数据聚成3类
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X_train_scaled)# 获取聚类标签
labels = kmeans.labels_# 可视化聚类结果(如果特征维度为2或可以使用PCA降维到2维)
plt.scatter(X_train_scaled[:, 0], X_train_scaled[:, 1], c=labels, cmap='viridis', marker='o')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75)
plt.title("K-means Clustering")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
3. 集成学习
随机森林
理论背景: 随机森林是一种集成学习方法,通过构建多个决策树并输出它们的预测结果的模式或平均值来改进预测性能。随机森林在构建每棵树时,不仅从原始数据集中随机抽取样本(带放回抽样),还从所有特征中随机选择一部分特征用于树的分裂。这种随机性有助于减少模型过拟合的风险。
代码示例:
from sklearn.ensemble import RandomForestClassifier# 初始化随机森林分类器
n_estimators = 100 # 决策树的数量
rf = RandomForestClassifier(n_estimators=n_estimators, random_state=42)# 训练模型
rf.fit(X_train_scaled, y_train)# 预测测试集
y_pred_rf = rf.predict(X_test_scaled)# 评估模型(使用准确率作为评估指标)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred_rf)
print(f"Accuracy: {accuracy:.2f}")
4. 模型调优
网格搜索(GridSearchCV)
理论背景: 网格搜索是一种通过遍历给定参数的网格来优化模型性能的方法。对于每种参数组合,网格搜索使用交叉验证来评估模型的性能,并保留最佳参数组合。这种方法虽然计算量大,但能够系统地探索参数空间,找到可能的最优解。
代码示例:
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 10, 20],'min_samples_split': [2, 5, 10]
}# 初始化随机森林分类器和网格搜索对象
rf = RandomForestClassifier(random_state=42)
grid_search = GridSearchCV(rf, param_grid, cv=5, scoring='accuracy')# 执行网格搜索
grid_search.fit(X_train_scaled, y_train)# 输出最佳参数和最佳模型的性能
best_params = grid_search.best_params_
print("Best parameters:", best_params)
best_model = grid_search.best_estimator_
best_score = grid_search.best_score_
print(f"Best cross-validation score: {best_score:.2f}")# 使用最佳模型进行预测(可选)
# y_pred_best = best_model.predict(X_test_scaled)
# ...(评估最佳模型的性能)
五、总结
scikit-learn作为Python中最为流行的机器学习库之一,以其简洁的API、丰富的算法和强大的功能赢得了广大用户的青睐。通过本文的介绍,相信你已经对sklearn有了初步的了解,并能够开始进行一些基础的机器学习任务。然而,机器学习是一个不断发展和深化的领域,只有不断学习和实践,才能真正掌握其中的精髓。希望本文能为你打开机器学习的大门,开启一段充满挑战与收获的旅程。
相关文章:

sklearn基础教程:掌握机器学习入门的钥匙
sklearn基础教程:掌握机器学习入门的钥匙 在数据科学和机器学习的广阔领域中,scikit-learn(简称sklearn)无疑是最受欢迎且功能强大的库之一。它提供了简单而高效的数据挖掘和数据分析工具,让研究人员、数据科学家以及…...

【unity实战】使用unity制作一个红点系统
前言 注意,本文是本人的学习笔记记录,这里先记录基本的代码,后面用到了再回来进行实现和整理 素材 https://assetstore.unity.com/packages/2d/gui/icons/2d-simple-ui-pack-218050 框架: RedPointSystem.cs using System.…...

开发指南046-机构树控件
为了简化编程,平台封装了很多前端组件。机构树就是常用的组件之一。 基本用法: import QlmOrgTree from /qlmcomponents/tree/QlmOrgTree <QlmOrgTree></QlmOrgTree> 功能: 根据权限和控制参数显示机构树。机构树数据来源于核…...

SpringBatch文件读写ItemWriter,ItemReader使用详解
SpringBatch文件读写ItemWriter,ItemReader使用详解 1. ItemReaders 和 ItemWriters1.1. ItemReader1.2. ItemWriter1.3. ItemProcessor 2.FlatFileItemReader 和 FlatFileItemWriter2.1.平面文件2.1.1. FieldSet 2.2. FlatFileItemReader2.3. FlatFileItemWriter 3…...

如何评估AI模型:评估指标的分类、方法及案例解析
如何评估AI模型:评估指标的分类、方法及案例解析 引言第一部分:评估指标的分类第二部分:评估指标的数学基础第三部分:评估指标的选择与应用第四部分:评估指标的局限性第五部分:案例研究第六部分:…...

程序员学CFA——经济学(七)
经济学(七) 汇率外汇市场外汇市场的功能外汇市场的参与者卖方买方 汇率的计算汇率报价基础货币与计价货币直接报价与间接报价外汇报价习惯 名义汇率和实际汇率货币的升值与贬值交叉汇率计算即期汇率与远期汇率即期汇率与远期汇率的概念远期升水/贴水远期…...

imx335帧率改到10fps的方法
验证: imx335.c驱动默认的帧率是30fps,要将 IMX335 的帧率更改为 10fps,需要调整与帧率相关的参数。FPS(frames per second,每秒帧数)通常由 sensor 的曝光时间(exposure time)和垂直总时间(VTS,Vertical Total Size)共同决定。VTS 定义了 sensor 完成一帧图像采集…...

Large Language Model系列之二:Transformers和预训练语言模型
Large Language Model系列之二:Transformers和预训练语言模型 1 Transformer模型 Transformer模型是一种基于自注意力机制的深度学习模型,它最初由Vaswani等人在2017年的论文《Attention Is All You Need》中提出,主要用于机器翻译任务。随…...

java后端项目启动失败,解决端口被占用问题
报错信息: Web server failed to start . Port 8020 was already in use. 1、查看端口号 netstat -ano | findstr 端口号 2、终止进程 taskkill /F /PID 进程ID 举例:关闭8020端口...
PostgreSQL安装/卸载(CentOS、Windows)
说明:PostgreSQL与MySQL一样,是一款开源免费的数据库技术,官方口号:The World’s Most Advanced Open Source Relational Database.(世界上最先进的开源关系数据库),本文介绍如何在Windows、Cen…...

OutOfMemoryError异常OOM排查
目录 参考工具MAT(Memory Analyzer)一、产生原因二、测试堆溢出 java.lang.OutOfMemoryError: Java heap space测试代码运行手动导出dump文件mat排查打开dump文件查看Leak Suspects(泄露疑点)参考 【JVM】八、OOM异常的模拟 MAT工具分析Dump文件(大对象定位) 用arthas排…...

【Python】Arcpy将excel点生成shp文件
根据excel点经纬度数据,生成shp,参考博主的代码,进行了修改,在属性表中保留excel中的数据。 参考资料:http://t.csdnimg.cn/OleyT 注意修改以下两句中的数字。 latitude float(row[1]) longitude float(row[2])imp…...

torch之从.datasets.CIFAR10解压出训练与测试图片 (附带网盘链接)
前言 从官网上下载的是长这个样子的 想看图片,咋办咧,看下面代码 import torch import torchvision import numpy as np import os import cv2 batch_size 50transform_predict torchvision.transforms.Compose([torchvision.transforms.ToTensor(),…...

什么ISP?什么是IAP?
做单片机开发的工程师经常会听到两个词:ISP和IAP,但新手往往对这两个概念不是很清楚,今天就来和大家聊聊什么是ISP,什么是IAP? 一、ISP ISP的全称是:In System Programming,即在系统编程&…...

外卖霸王餐系统怎么快速盈利赚钱?
微客云外卖霸王餐系统,作为近年来外卖行业中的一股新兴力量,以其独特的商业模式和营销策略,迅速吸引了大量消费者的目光。该系统通过提供显著的折扣和返利,让顾客能够以极低的价格甚至免费享受到美味的外卖,同时&#…...

Linux环境下安装Nodejs
Linux环境下安装Nodejs 下载地址:https://nodejs.org/zh-cn/download/package-manager 一、使用压缩包自定义安装 上述链接下载好对应版本的软件包后,我存放到 /evn/nodejs 目录下(根据自己实际情况设置) 设置软链接 sudo ln…...

【Rust】字符串String类型学习
什么是String Rust的核心语言中只有一个String类型,那就是String slice,str通常被当作是&str的借用。String类型是通过标准库提供的,而不是直接编码到核心语言中,它是一个可增长的、可变的、utf-8编码的类型。str和String都是utf-8编码的…...
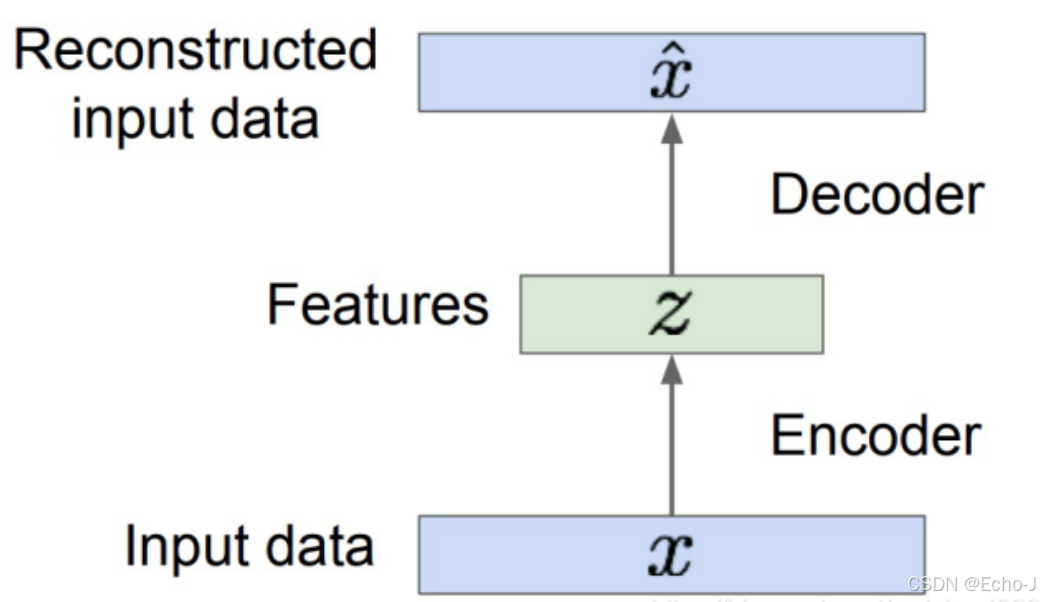
先验概率 后验概率 最大似然估计 自编码器AE
先验概率 先验概率:由因求果中的因 作用:后验概率是比较难以计算的,我们通常使用贝叶斯公式由先验概率计算后验概率。 贝叶斯公式:P(B|A)P(A|B)P(B)/P(A),其中P(B|A)为后验概率,P(A|B)为先验概率。 后验…...

qt 鼠标接近某线时,形状变化举例
1.qt 鼠标接近某线时,形状变化举例 在Qt中,要实现鼠标接近某条线时形状发生变化的效果,你需要利用QWidget的enterEvent和leaveEvent,或者更通用的mouseMoveEvent来检测鼠标的位置,并相应地改变鼠标的光标形状。 以下…...

800块,我从淘宝上买AGV……
导语 大家好,我是社长,老K。专注分享智能制造和智能仓储物流等内容。 新书《智能物流系统构成与技术实践》人俱乐部 从淘宝上打算够购买一台AGV小车,上去一搜,嘿,你别说,还真有。便宜的才200块钱。 很兴奋把…...

电动工具MCU选型与开发:从FOC算法到高集成度设计的工程实践
1. 项目概述:为什么电动工具需要一颗“聪明”的MCU?大家好,我是覃杰,在瑞萨电子上海分公司负责MCU相关的技术方案支持。今天我们不聊那些高大上的概念,就从一个工程师最熟悉的场景聊起:你手里那把正在“嗡嗡…...

解决Arm Compiler 5与6混合编译的链接警告问题
1. 问题现象解析当使用Arm Compiler 5工具链链接包含Arm Compiler 6构建对象文件的项目时,开发者常会遇到如下警告信息:Warning: L6418W: Tagging symbol __tagsym$$used.0 defined in .obj() is not recognized在包含MDK-Middleware组件的项目中&#x…...

用 MinIO 搭建 S3 兼容对象存储服务
用 MinIO 搭建 S3 兼容对象存储服务 分类:开源项目部署 MinIO 适合附件、备份归档和 S3 兼容对象文件。这类主题真正跑起来并不难,难的是上线后稳定、可备份、能排错。本文按实操方式整理一套可以直接落地的流程,默认你已经会登录 Linux 服务…...

KMS_VL_ALL_AIO终极指南:三步永久激活Windows和Office系统
KMS_VL_ALL_AIO终极指南:三步永久激活Windows和Office系统 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变…...

Node.js 服务端应用无缝集成 Taotoken API 的实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 服务端应用无缝集成 Taotoken API 的实践 对于 Node.js 后端开发者而言,将大模型能力集成到服务中已成为提升应…...
)
一文读懂如何申报国家企业技术中心(条件、流程、好处)
一、什么是企业技术中心?是指企业根据市场竞争需要设立的技术研发与创新机构,负责制定企业技术创新规划、开展产业技术研发、创造运用知识产权、建立技术标准体系、凝聚培养创新人才,推进技术创新全过程实施,是企业技术创新体系的…...

机器学习驱动的中微子-核散射截面建模:从数据学习到振荡分析
1. 项目概述与核心价值 中微子物理正步入一个前所未有的“精密测量”时代。像DUNE(深地下中微子实验)这样的下一代长基线实验,目标是将中微子混合参数的测量精度推至百分之一量级。然而,一个长期存在的“拦路虎”限制了这一目标的…...

【限时解密】:OpenAI DevDay未公布的Agent Runtime协议草案V2.1——它正悄然定义下一代智能体互操作标准
更多请点击: https://kaifayun.com 第一章:AI Agent智能体未来趋势 AI Agent正从单一任务执行者演变为具备自主目标分解、跨工具协同与持续环境反馈的类人智能体。其发展不再局限于模型规模扩张,而转向认知架构升级、可信机制构建与人机协作…...

【设计模式 13】命令:覆水能收
这一课讲命令模式。什么在变:决策需要记录、排队、撤销。怎么挡:把决策封装成命令对象,可执行可回滚。林衍那次决策失误,后来集团内部管它叫"黑色十月"。 起因是赵闯带回来一条消息:一家新晋竞争对手拿到了十…...

2026年AI论文平台盘点:12款神器助你高效完成选题大纲、撰稿和降重
随着 AI 技术的持续突破,2026 年的论文写作工具市场已迈入“智能化、精细化、合规化”的新阶段。从本科生的课程论文到研究生的学位论文,再到科研人员的期刊投稿,AI 工具正以前所未有的专业度覆盖各类学术场景。无论是选题构思、文献检索、初…...