如何评估AI模型:评估指标的分类、方法及案例解析
如何评估AI模型:评估指标的分类、方法及案例解析
- 引言
- 第一部分:评估指标的分类
- 第二部分:评估指标的数学基础
- 第三部分:评估指标的选择与应用
- 第四部分:评估指标的局限性
- 第五部分:案例研究
- 第六部分:评估指标的改进与未来趋势
- 结语
引言
在人工智能领域,模型评估是确保机器学习算法有效性和可靠性的关键步骤。评估指标不仅帮助我们理解模型的性能,还指导我们对模型进行优化和改进。本文将深入探讨评估指标的分类、选择、应用以及实际应用案例。
第一部分:评估指标的分类
评估指标是用来衡量AI模型性能的一系列标准或量度。
以下是一些常见的评估指标,用于衡量AI模型的性能:
- 准确性(Accuracy):通过比较所有预测正确的样本数与总样本数来计算。
- 精确度(Precision):计算模型预测为正类别中实际为正的比例。
- 召回率(Recall):计算所有实际为正类别中被正确预测的比例。
- F1分数(F1 Score):计算精确度和召回率的调和平均值。
- ROC曲线和AUC值:使用不同的阈值绘制真正率与假正率的关系,计算曲线下面积。
- 混淆矩阵(Confusion Matrix):构建一个表格,展示每个类别的预测和实际标签。
- 模型鲁棒性(Robustness):评估模型对输入数据中的异常值、噪声或小的变化的抵抗能力。
- 模型泛化能力(Generalization):评估模型对新数据的适应能力。
以下是计算基本评估指标和模型鲁棒性、泛化能力的代码示例:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, roc_curve, auc
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
import numpy as np# 假设y_true和y_pred是模型的预测结果
y_true = [0, 1, 1, 0, 1]
y_pred = [0, 1, 0, 0, 1]# 计算基本评估指标
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)# 打印基本评估指标结果
print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1 Score: {f1}')# 评估模型泛化能力
# 生成模拟数据集
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)# 创建模型
model = RandomForestClassifier()# 使用交叉验证评估模型泛化能力
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')# 打印交叉验证结果
print(f'Cross-validation scores: {scores}')
print(f'Mean accuracy: {np.mean(scores)}')# 评估模型鲁棒性
# 选择一个样本进行扰动测试
sample_index = 0
original_sample = X[sample_index]# 在原始样本的基础上引入扰动
perturbed_sample = original_sample + np.random.normal(0, 0.1, original_sample.shape)
perturbed_sample = np.clip(perturbed_sample, 0, 1) # 确保扰动后的样本值在合理范围内# 训练模型
model.fit(X, y)# 预测原始样本和扰动样本
original_prediction = model.predict([original_sample])
perturbed_prediction = model.predict([perturbed_sample])# 打印模型鲁棒性结果
print(f'Original prediction: {original_prediction}')
print(f'Perturbed prediction: {perturbed_prediction}')
第二部分:评估指标的数学基础
评估指标的数学基础涉及概率论和统计学。
以下是一些关键概念:
- 条件概率与贝叶斯定理:在给定某个事件发生的情况下,另一个事件发生的概率。
- 信息熵与交叉熵:衡量样本集合纯度和两个概率分布差异的指标。
- 损失函数:衡量模型预测值与实际值差异的函数,如均方误差(MSE)和交叉熵损失。
以下是使用scipy库计算信息熵的示例:
from scipy.stats import entropy# 假设我们有两个概率分布
p = [0.7, 0.3]
q = [0.5, 0.5]# 计算信息熵
entropy_p = entropy(p)
entropy_q = entropy(q, base=2) # 以2为底# 计算交叉熵
cross_entropy = entropy(p, q)print(f'Entropy of p: {entropy_p}')
print(f'Entropy of q: {entropy_q}')
print(f'Cross-entropy of p and q: {cross_entropy}')
第三部分:评估指标的选择与应用
评估指标的选择应根据具体任务的需求和数据的特点来决定:
- 分类任务:通常使用准确率、精确度、召回率和F1分数。
- 回归任务:通常使用均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)等。
- 聚类任务:可以使用轮廓系数、戴维森堡丁指数等指标来评估聚类质量。
以下是使用scikit-learn进行分类任务评估的示例:
from sklearn.metrics import classification_report# 计算分类报告
report = classification_report(y_true, y_pred, output_dict=True)# 打印分类报告
for label, metrics in report.items():print(f'Metrics for class {label}:')for metric, value in metrics.items():print(f' {metric}: {value}')
第四部分:评估指标的局限性
评估指标可能存在局限性:
- 过拟合与欠拟合:评估指标可以帮助我们识别这些问题,但它们本身并不能解决这些问题。
- 数据不平衡问题:在数据不平衡的情况下,准确率可能会误导我们对模型性能的评估。
- 评估指标的误导性:某些评估指标可能会误导我们对模型性能的判断。
以下是使用交叉验证来识别过拟合的示例:
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification# 生成模拟数据集
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)# 创建模型
model = RandomForestClassifier()# 进行交叉验证
scores = cross_val_score(model, X, y, cv=5)# 打印交叉验证结果
print(f'Cross-validation scores: {scores}')
第五部分:案例研究
通过具体案例,展示评估指标在实际应用中的重要性和作用:
- 医疗诊断AI:评估指标的选择尤为重要,以确保不漏诊任何可能的病例。
- 自动驾驶系统:评估指标不仅需要考虑模型的准确性,还需要考虑模型的响应时间和鲁棒性。
- 推荐系统:评估指标可能包括精确度、召回率、覆盖率和新颖性等。
以下是使用实际数据集进行评估的示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = RandomForestClassifier()
model.fit(X_train, y_train)# 预测测试集
y_pred = model.predict(X_test)# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='macro')
recall = recall_score(y_test, y_pred, average='macro')
f1 = f1_score(y_test, y_pred, average='macro')# 打印评估指标
print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1 Score: {f1}')
第六部分:评估指标的改进与未来趋势
探讨如何改进现有评估方法,并展望未来可能出现的新评估技术:
- 集成学习与模型融合:通过结合多个模型的预测来提高整体的准确性和鲁棒性。
- 模型可解释性与公平性:构建更加透明和公正的AI系统。
- 机器学习中的新评估方法:使用深度学习模型的注意力机制来评估模型对输入特征的依赖程度。
以下是使用集成学习进行模型融合的示例:
from sklearn.ensemble import VotingClassifierclf1 = RandomForestClassifier(n_estimators=50)
clf2 = LogisticRegression(max_iter=1000)
estimators = [('rf', clf1), ('lr', clf2)]ensemble = VotingClassifier(estimators=estimators, voting='soft')
ensemble.fit(X_train, y_train)
y_pred_ensemble = ensemble.predict(X_test)
accuracy_ensemble = accuracy_score(y_test, y_pred_ensemble)print(f'Ensemble Accuracy: {accuracy_ensemble}')
结语
评估指标是AI模型开发过程中不可或缺的一部分。它们不仅帮助我们理解模型的性能,还指导我们对模型进行优化和改进。随着AI技术的不断发展,我们需要不断学习和适应新的评估方法。
相关文章:

如何评估AI模型:评估指标的分类、方法及案例解析
如何评估AI模型:评估指标的分类、方法及案例解析 引言第一部分:评估指标的分类第二部分:评估指标的数学基础第三部分:评估指标的选择与应用第四部分:评估指标的局限性第五部分:案例研究第六部分:…...

程序员学CFA——经济学(七)
经济学(七) 汇率外汇市场外汇市场的功能外汇市场的参与者卖方买方 汇率的计算汇率报价基础货币与计价货币直接报价与间接报价外汇报价习惯 名义汇率和实际汇率货币的升值与贬值交叉汇率计算即期汇率与远期汇率即期汇率与远期汇率的概念远期升水/贴水远期…...

imx335帧率改到10fps的方法
验证: imx335.c驱动默认的帧率是30fps,要将 IMX335 的帧率更改为 10fps,需要调整与帧率相关的参数。FPS(frames per second,每秒帧数)通常由 sensor 的曝光时间(exposure time)和垂直总时间(VTS,Vertical Total Size)共同决定。VTS 定义了 sensor 完成一帧图像采集…...

Large Language Model系列之二:Transformers和预训练语言模型
Large Language Model系列之二:Transformers和预训练语言模型 1 Transformer模型 Transformer模型是一种基于自注意力机制的深度学习模型,它最初由Vaswani等人在2017年的论文《Attention Is All You Need》中提出,主要用于机器翻译任务。随…...

java后端项目启动失败,解决端口被占用问题
报错信息: Web server failed to start . Port 8020 was already in use. 1、查看端口号 netstat -ano | findstr 端口号 2、终止进程 taskkill /F /PID 进程ID 举例:关闭8020端口...
PostgreSQL安装/卸载(CentOS、Windows)
说明:PostgreSQL与MySQL一样,是一款开源免费的数据库技术,官方口号:The World’s Most Advanced Open Source Relational Database.(世界上最先进的开源关系数据库),本文介绍如何在Windows、Cen…...

OutOfMemoryError异常OOM排查
目录 参考工具MAT(Memory Analyzer)一、产生原因二、测试堆溢出 java.lang.OutOfMemoryError: Java heap space测试代码运行手动导出dump文件mat排查打开dump文件查看Leak Suspects(泄露疑点)参考 【JVM】八、OOM异常的模拟 MAT工具分析Dump文件(大对象定位) 用arthas排…...

【Python】Arcpy将excel点生成shp文件
根据excel点经纬度数据,生成shp,参考博主的代码,进行了修改,在属性表中保留excel中的数据。 参考资料:http://t.csdnimg.cn/OleyT 注意修改以下两句中的数字。 latitude float(row[1]) longitude float(row[2])imp…...

torch之从.datasets.CIFAR10解压出训练与测试图片 (附带网盘链接)
前言 从官网上下载的是长这个样子的 想看图片,咋办咧,看下面代码 import torch import torchvision import numpy as np import os import cv2 batch_size 50transform_predict torchvision.transforms.Compose([torchvision.transforms.ToTensor(),…...

什么ISP?什么是IAP?
做单片机开发的工程师经常会听到两个词:ISP和IAP,但新手往往对这两个概念不是很清楚,今天就来和大家聊聊什么是ISP,什么是IAP? 一、ISP ISP的全称是:In System Programming,即在系统编程&…...

外卖霸王餐系统怎么快速盈利赚钱?
微客云外卖霸王餐系统,作为近年来外卖行业中的一股新兴力量,以其独特的商业模式和营销策略,迅速吸引了大量消费者的目光。该系统通过提供显著的折扣和返利,让顾客能够以极低的价格甚至免费享受到美味的外卖,同时&#…...

Linux环境下安装Nodejs
Linux环境下安装Nodejs 下载地址:https://nodejs.org/zh-cn/download/package-manager 一、使用压缩包自定义安装 上述链接下载好对应版本的软件包后,我存放到 /evn/nodejs 目录下(根据自己实际情况设置) 设置软链接 sudo ln…...

【Rust】字符串String类型学习
什么是String Rust的核心语言中只有一个String类型,那就是String slice,str通常被当作是&str的借用。String类型是通过标准库提供的,而不是直接编码到核心语言中,它是一个可增长的、可变的、utf-8编码的类型。str和String都是utf-8编码的…...
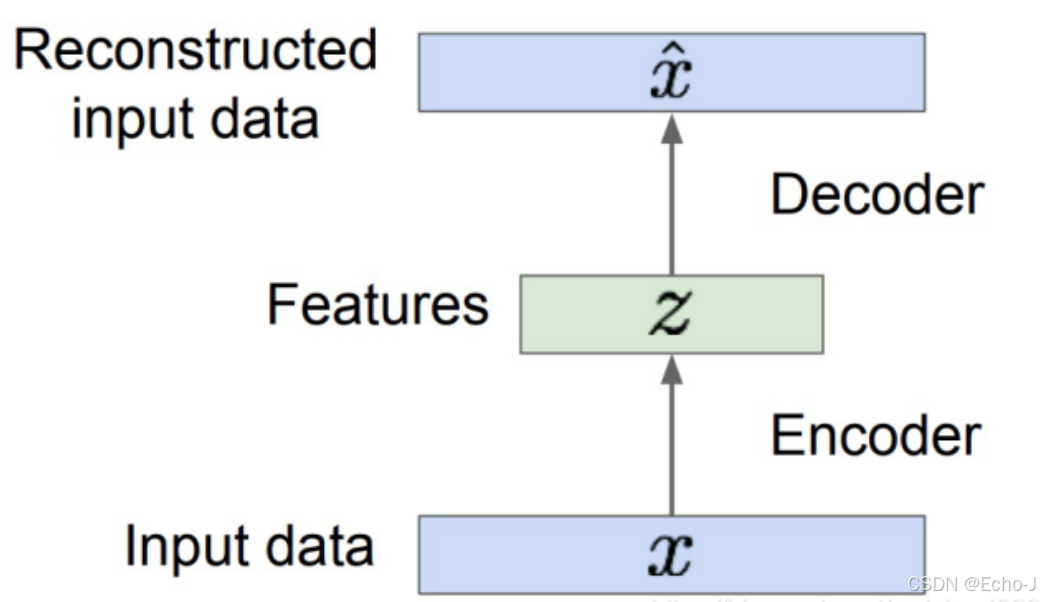
先验概率 后验概率 最大似然估计 自编码器AE
先验概率 先验概率:由因求果中的因 作用:后验概率是比较难以计算的,我们通常使用贝叶斯公式由先验概率计算后验概率。 贝叶斯公式:P(B|A)P(A|B)P(B)/P(A),其中P(B|A)为后验概率,P(A|B)为先验概率。 后验…...

qt 鼠标接近某线时,形状变化举例
1.qt 鼠标接近某线时,形状变化举例 在Qt中,要实现鼠标接近某条线时形状发生变化的效果,你需要利用QWidget的enterEvent和leaveEvent,或者更通用的mouseMoveEvent来检测鼠标的位置,并相应地改变鼠标的光标形状。 以下…...

800块,我从淘宝上买AGV……
导语 大家好,我是社长,老K。专注分享智能制造和智能仓储物流等内容。 新书《智能物流系统构成与技术实践》人俱乐部 从淘宝上打算够购买一台AGV小车,上去一搜,嘿,你别说,还真有。便宜的才200块钱。 很兴奋把…...

C++相关概念和易错语法(21)(虚函数、协变、析构函数的重写)
多态的核心是虚函数,本文从虚函数出发,根据原理慢慢推进得到结论,进而理解多态 1.虚函数 先看一下下面的代码,想想什么导致了这个结果 #include <iostream> using namespace std;class A { public:virtual void test(){co…...
SoulApp创始人张璐团队以AI驱动社交进化,平台社交玩法大变革
在科技飞速发展的今天,人工智能正逐步渗透到社交媒体的各个环节,赋能全链路社交体验。AI的引入不仅提升了内容推荐的精准度,使用户能够更快速地发现感兴趣的内容,还能通过用户行为预测,帮助平台更好地理解和满足用户需求。此外,AI驱动的虚拟助手和聊天机器人也正在改变用户互动…...

MySQL事务隔离级别+共享锁,排他锁,乐观锁,悲观锁
在操作数据库的时候,可能会由于并发问题而引起的数据的不一致性(数据冲突)。 MySQL事务隔离级别 一个事务的执行,本质上就是一条工作线程在执行,当出现多个事务同时执行时,这种情况则被称之为并发事务&am…...

Zynq系列FPGA实现SDI编解码转SFP光口传输(光端机),基于GTX高速接口,提供6套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐本博已有的 SDI 编解码方案本方案在Xilinx-Kintex7上的应用 3、详细设计方案设计原理框图输入Sensor之-->OV5640摄像头输入Sensor之-->HDMIVDMA图像缓存RGB转BT1120GTX 解串与串化SMPTE SD/HD/3G SDI IP核BT1120转RGBHDMI输…...

GPT-4稀疏激活真相:2%参数如何实现高效推理
1. 项目概述:参数规模与稀疏激活的真相拆解 “GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区反复刷屏,常被当作“大模型已突破算力瓶颈”的标志性论断。但作为从2017年就开始部署LSTM语音识别系统、…...

Maven依赖scope:从编译到打包,一张图理清生命周期与classpath
Maven依赖scope全解析:构建生命周期与classpath的精准控制 当你盯着pom.xml里那些<scope>compile</scope>标签时,是否曾好奇它们究竟如何影响你的构建流程?Maven的依赖scope就像一个个精密的开关,控制着依赖项在编译、…...

通过curl命令快速测试Taotoken上不同大模型的响应效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken上不同大模型的响应效果 对于开发者而言,在集成大模型能力时,快速验证接口连…...

P6 马铃薯病害识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 个人总结:了解VGG由 5 组卷积池化块堆叠构成,依靠小尺寸卷积核逐层提取图像浅层、深层特征,最后通过全连接层完成分类。&…...

实测taotoken在不同时段api调用的响应延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测taotoken在不同时段api调用的响应延迟与稳定性表现 对于依赖大模型API进行开发的团队而言,服务的响应延迟与稳定性…...

FlashAttention 深度解读:让大模型注意力机制“一口气算完“
FlashAttention:让大模型注意力机制"一口气算完" 想象你在厨房做菜。冰箱在远处(HBM,高带宽内存),料理台在面前(SRAM,片上缓存)。每次要切菜,都得走过去开冰箱…...
)
Flink架构与集群部署(一)
Apache Flink架构Flink组件栈在Flink的整个软件架构体系中,同样遵循这分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富且友好的接口。上图是Flink基本组件栈,从上图可以看出整个Flink的架构体系可…...

5月21日-23日微相携多款产品亮相2026世界无人机大会暨UASE无人机展以先进无人机侦测反制技术产品赋能城市低空安全防护
微相亮相2026世界无人机大会暨UASE无人机展...

百考通:AI一键生成期刊论文写作,全流程智能化支撑,让学术创作更高效
在学术研究领域,期刊论文的撰写是成果输出的关键环节,却也让众多科研工作者与学生倍感压力:选题迷茫、逻辑梳理困难、格式规范复杂、内容提炼耗时,严重拖慢了学术成果的发表节奏。百考通(https://www.baikaotongai.com…...

Wot Design Uni 文件上传组件:如何实现异步上传的强大功能
Wot Design Uni 文件上传组件:如何实现异步上传的强大功能 【免费下载链接】wot-design-uni 一个基于Vue3TS开发的uni-app组件库,提供70高质量组件,支持暗黑模式、国际化和自定义主题。 项目地址: https://gitcode.com/gh_mirrors/wo/wot-d…...