【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)

目录
一、引言
二、自动语音识别(automatic-speech-recognition)
2.1 概述
2.2 技术原理
2.2.1 whisper模型
2.2.2 Wav2vec 2.0模型
2.3 pipeline参数
2.3.1 pipeline对象实例化参数
2.3.2 pipeline对象使用参数
2.3.3 pipeline对象返回参数
2.4 pipeline实战
2.4.1 facebook/wav2vec2-base-960h(默认模型)
2.4.2 openai/whisper-medium
2.5 模型排名
三、总结
一、引言
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理(NLP)、多模态(Multimodal)等4大类,28小类任务(tasks),共计覆盖32万个模型。

今天介绍Audio音频的第二篇,自动语音识别(automatic-speech-recognition),在huggingface库内共有1.8万个音频分类模型。
二、自动语音识别(automatic-speech-recognition)
2.1 概述
自动语音识别 (ASR),也称为语音转文本 (STT),是将给定音频转录为文本的任务。主要应用场景有人机对话、语音转文本、歌词识别、字幕生成等。

2.2 技术原理
自动语音识别主要原理是音频切分成25ms-60ms的音谱后,采用卷机网络抽取音频特征,再通过transformer等网络结构与文本进行对齐训练。比较知名的自动语音识别当属openai的whisper和meta的Wav2vec 2.0。
2.2.1 whisper模型
语音部分:基于680000小时音频数据进行训练,包含英文、其他语言转英文、非英文等多种语言。将音频数据转换成梅尔频谱图,再经过两个卷积层后送入 Transformer 模型。
文本部分:文本token包含3类:special tokens(标记tokens)、text tokens(文本tokens)、timestamp tokens(时间戳),基于标记tokens控制文本的开始和结束,基于timestamp tokens让语音时间与文本对其。
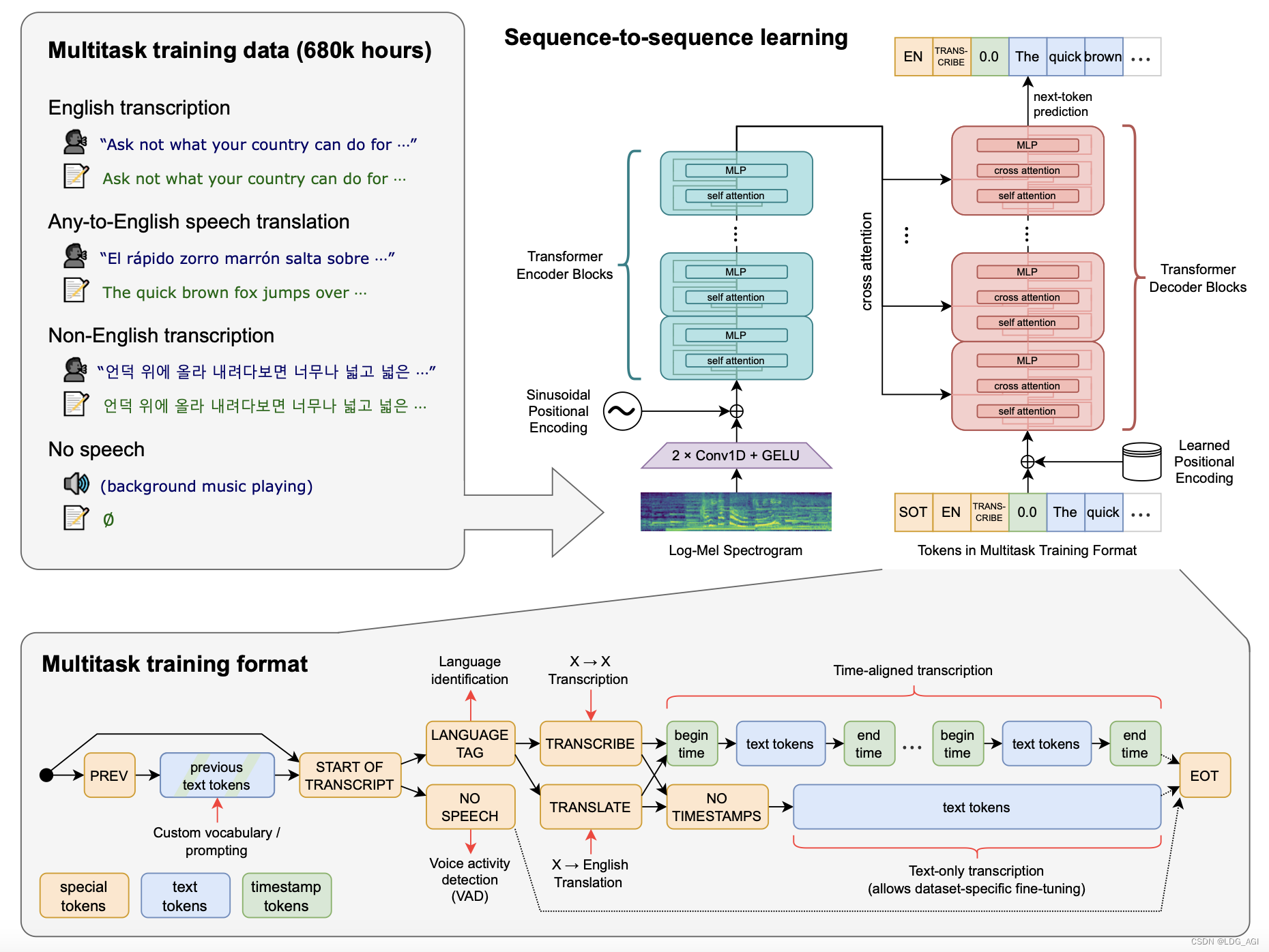
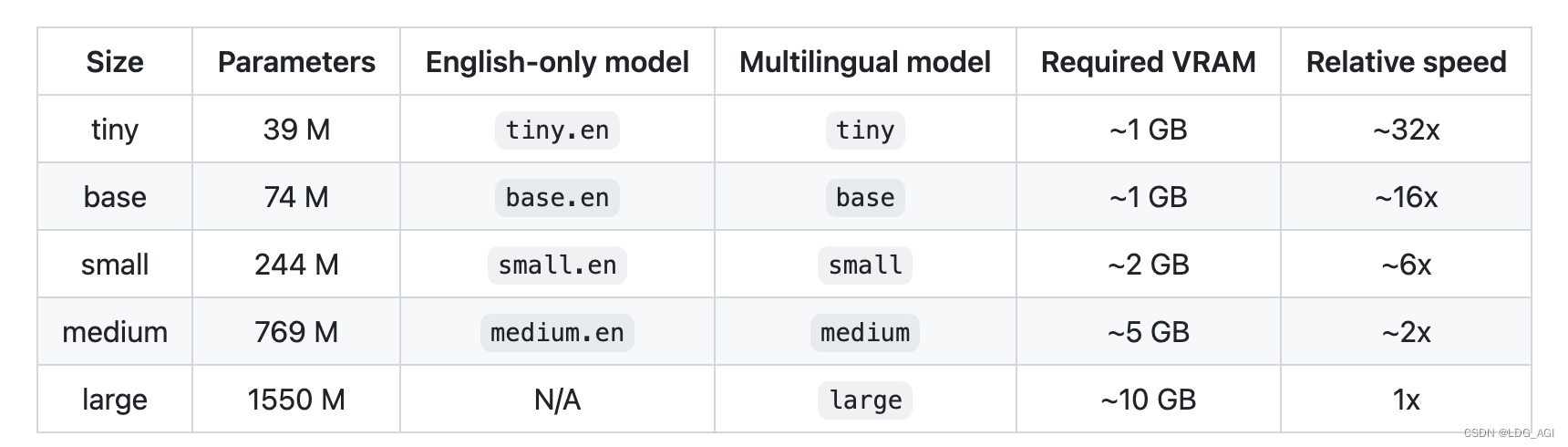
不同尺寸模型参数量、多语言支持情况、需要现存大小以及推理速度如下
2.2.2 Wav2vec 2.0模型
Wav2vec 2.0是 Meta在2020年发表的无监督语音预训练模型。它的核心思想是通过向量量化(Vector Quantization,VQ)构造自建监督训练目标,对输入做大量掩码后利用对比学习损失函数进行训练。模型结构如图,基于卷积网络(Convoluational Neural Network,CNN)的特征提取器将原始音频编码为帧特征序列,通过 VQ 模块把每帧特征转变为离散特征 Q,并作为自监督目标。同时,帧特征序列做掩码操作后进入 Transformer [5] 模型得到上下文表示 C。最后通过对比学习损失函数,拉近掩码位置的上下文表示与对应的离散特征 q 的距离,即正样本对。

2.3 pipeline参数
2.3.1 pipeline对象实例化参数
- 模型(PreTrainedModel或TFPreTrainedModel)— 管道将使用其进行预测的模型。 对于 PyTorch,这需要从PreTrainedModel继承;对于 TensorFlow,这需要从TFPreTrainedModel继承。
- feature_extractor(SequenceFeatureExtractor)——管道将使用其来为模型编码波形的特征提取器。
- tokenizer ( PreTrainedTokenizer ) — 管道将使用 tokenizer 来为模型编码数据。此对象继承自 PreTrainedTokenizer。
- 解码器(
pyctcdecode.BeamSearchDecoderCTC,可选)— PyCTCDecode 的 BeamSearchDecoderCTC 可以传递用于语言模型增强解码。有关更多信息,请参阅Wav2Vec2ProcessorWithLM 。- chunk_length_s (
float,可选,默认为 0) — 每个块的输入长度。如果chunk_length_s = 0禁用分块(默认)。- stride_length_s (
float,可选,默认为chunk_length_s / 6) — 每个块左侧和右侧的步幅长度。仅与 一起使用chunk_length_s > 0。这使模型能够看到更多上下文并比没有此上下文时更好地推断字母,但管道会在最后丢弃步幅位,以使最终的重构尽可能完美。- 框架(
str,可选)— 要使用的框架,"pt"适用于 PyTorch 或"tf"TensorFlow。必须安装指定的框架。如果未指定框架,则默认为当前安装的框架。如果未指定框架且两个框架都已安装,则默认为 的框架model,如果未提供模型,则默认为 PyTorch 的框架。- 设备(Union[
int,torch.device],可选)— CPU/GPU 支持的设备序号。设置为None将利用 CPU,设置为正数将在关联的 CUDA 设备 ID 上运行模型。- torch_dtype (Union[
int,torch.dtype],可选) — 计算的数据类型 (dtype)。将其设置为None将使用 float32 精度。设置为torch.float16或torch.bfloat16将在相应的 dtype 中使用半精度。
2.3.2 pipeline对象使用参数
- 输入(
np.ndarray或bytes或str或dict) — 输入可以是:
str即本地音频文件的文件名,或下载音频文件的公共 URL 地址。文件将以正确的采样率读取,以使用 ffmpeg获取波形。这需要系统上安装ffmpeg 。bytes它应该是音频文件的内容,并以相同的方式由ffmpeg进行解释。- (
np.ndarray形状为(n,)类型为np.float32或np.float64)正确采样率的原始音频(不再进行进一步检查)dict形式可用于传递任意采样的原始音频sampling_rate,并让此管道进行重新采样。字典必须采用{"sampling_rate": int, "raw": np.array}可选格式"stride": (left: int, right: int),可以要求管道在解码时忽略第一个left样本和最后一个right样本(但在推理时使用,为模型提供更多上下文)。仅用于strideCTC 模型。- return_timestamps(可选,
str或bool)— 仅适用于纯 CTC 模型(Wav2Vec2、HuBERT 等)和 Whisper 模型。不适用于其他序列到序列模型。对于 CTC 模型,时间戳可以采用以下两种格式之一:
"char":管道将返回文本中每个字符的时间戳。例如,如果您得到[{"text": "h", "timestamp": (0.5, 0.6)}, {"text": "i", "timestamp": (0.7, 0.9)}],则意味着模型预测字母“h”是在 秒后0.5和0.6秒之前说出的。"word":管道将返回文本中每个单词的时间戳。例如,如果您得到[{"text": "hi ", "timestamp": (0.5, 0.9)}, {"text": "there", "timestamp": (1.0, 1.5)}],则意味着模型预测单词“hi”是在 秒后0.5和0.9秒之前说的。对于 Whisper 模型,时间戳可以采用以下两种格式之一:
"word":与上文相同,适用于字级 CTC 时间戳。字级时间戳通过动态时间规整 (DTW)算法进行预测,该算法通过检查交叉注意权重来近似字级时间戳。True:管道将返回文本中单词片段的时间戳。例如,如果您得到[{"text": " Hi there!", "timestamp": (0.5, 1.5)}],则意味着模型预测“Hi there!” 片段是在 秒后0.5和1.5秒之前说的。请注意,文本片段指的是一个或多个单词的序列,而不是像单词级时间戳那样的单个单词。- generate_kwargs(
dict,可选generate_config)—用于生成调用的临时参数化字典。有关 generate 的完整概述,请查看以下指南。- max_new_tokens(
int,可选)— 要生成的最大令牌数,忽略提示中的令牌数。
2.3.3 pipeline对象返回参数
- 文本(
str):识别的文本。- chunks(可选(,
List[Dict])当使用时return_timestamps,chunks将成为一个列表,包含模型识别的所有各种文本块,例如*[{"text": "hi ", "timestamp": (0.5, 0.9)}, {"text": "there", "timestamp": (1.0, 1.5)}]。通过执行可以粗略地恢复原始全文"".join(chunk["text"] for chunk in output["chunks"])。
2.4 pipeline实战
2.4.1 facebook/wav2vec2-base-960h(默认模型)
pipeline对于automatic-speech-recognition的默认模型是facebook/wav2vec2-base-960h,使用pipeline时,如果仅设置task=automatic-speech-recognition,不设置模型,则下载并使用默认模型。
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"from transformers import pipelinespeech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="automatic-speech-recognition")
result = pipe(speech_file)
print(result)可以将.mp3内的音频转为文本:
{'text': "WELL TO DAY'S STORY MEETING IS OFFICIALLY STARTED SOMEONE SAID THAT YOU HAVE BEEN TELLING STORIES FOR TWO OR THREE YEARS FOR SUCH A LONG TIME AND YOU STILL HAVE A STORY MEETING TO TELL"}2.4.2 openai/whisper-medium
我们指定模型openai/whisper-medium,具体代码为:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"from transformers import pipelinespeech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")
result = pipe(speech_file)
print(result)输入为一段mp3格式的语音,输出为
{'text': " Well, today's story meeting is officially started. Someone said that you have been telling stories for two or three years for such a long time, and you still have a story meeting to tell."}2.5 模型排名
在huggingface上,我们筛选自动语音识别模型,并按下载量从高到低排序:

三、总结
本文对transformers之pipeline的自动语音识别(automatic-speech-recognition)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的代码极简的进行自动语音识别推理,应用于语音识别、字幕提取等业务场景。
期待您的3连+关注,如何还有时间,欢迎阅读我的其他文章:
《Transformers-Pipeline概述》
【人工智能】Transformers之Pipeline(概述):30w+大模型极简应用
《Transformers-Pipeline 第一章:音频(Audio)篇》
【人工智能】Transformers之Pipeline(一):音频分类(audio-classification)
【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)
【人工智能】Transformers之Pipeline(三):文本转音频(text-to-audio)
【人工智能】Transformers之Pipeline(四):零样本音频分类(zero-shot-audio-classification)
《Transformers-Pipeline 第二章:计算机视觉(CV)篇》
【人工智能】Transformers之Pipeline(五):深度估计(depth-estimation)
【人工智能】Transformers之Pipeline(六):图像分类(image-classification)
【人工智能】Transformers之Pipeline(七):图像分割(image-segmentation)
【人工智能】Transformers之Pipeline(八):图生图(image-to-image)
【人工智能】Transformers之Pipeline(九):物体检测(object-detection)
【人工智能】Transformers之Pipeline(十):视频分类(video-classification)
【人工智能】Transformers之Pipeline(十一):零样本图片分类(zero-shot-image-classification)
【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
《Transformers-Pipeline 第三章:自然语言处理(NLP)篇》
【人工智能】Transformers之Pipeline(十三):填充蒙版(fill-mask)
【人工智能】Transformers之Pipeline(十四):问答(question-answering)
【人工智能】Transformers之Pipeline(十五):总结(summarization)
【人工智能】Transformers之Pipeline(十六):表格问答(table-question-answering)
【人工智能】Transformers之Pipeline(十七):文本分类(text-classification)
【人工智能】Transformers之Pipeline(十八):文本生成(text-generation)
【人工智能】Transformers之Pipeline(十九):文生文(text2text-generation)
【人工智能】Transformers之Pipeline(二十):令牌分类(token-classification)
【人工智能】Transformers之Pipeline(二十一):翻译(translation)
【人工智能】Transformers之Pipeline(二十二):零样本文本分类(zero-shot-classification)
《Transformers-Pipeline 第四章:多模态(Multimodal)篇》
【人工智能】Transformers之Pipeline(二十三):文档问答(document-question-answering)
【人工智能】Transformers之Pipeline(二十四):特征抽取(feature-extraction)
【人工智能】Transformers之Pipeline(二十五):图片特征抽取(image-feature-extraction)
【人工智能】Transformers之Pipeline(二十六):图片转文本(image-to-text)
【人工智能】Transformers之Pipeline(二十七):掩码生成(mask-generation)
【人工智能】Transformers之Pipeline(二十八):视觉问答(visual-question-answering)
相关文章:
【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)
目录 一、引言 二、自动语音识别(automatic-speech-recognition) 2.1 概述 2.2 技术原理 2.2.1 whisper模型 2.2.2 Wav2vec 2.0模型 2.3 pipeline参数 2.3.1 pipeline对象实例化参数 2.3.2 pipeline对象使用参数…...

Mysql-错误处理: Found option without preceding group in config file
1、问题描述 安装MYSQL时,在cmd中“初始化”数据库时,输入命令: mysqld --initialize --consolecmd报错: D:\mysql-5.7.36-winx64\bin>mysql --initialize --console mysql: [ERROR] Found option without preceding group …...

[iOS]内存分区
[iOS]内存分区 文章目录 [iOS]内存分区五大分区栈区堆区全局区常量区代码区验证内存使用注意事项总结 函数栈堆栈溢出栈的作用 参考博客 在iOS中,内存主要分为栈区、堆区、全局区、常量区、代码区五大区域 还记得OC是C的超类 所以C的内存分区也是一样的 iOS系统中&a…...

sklearn基础教程:掌握机器学习入门的钥匙
sklearn基础教程:掌握机器学习入门的钥匙 在数据科学和机器学习的广阔领域中,scikit-learn(简称sklearn)无疑是最受欢迎且功能强大的库之一。它提供了简单而高效的数据挖掘和数据分析工具,让研究人员、数据科学家以及…...

【unity实战】使用unity制作一个红点系统
前言 注意,本文是本人的学习笔记记录,这里先记录基本的代码,后面用到了再回来进行实现和整理 素材 https://assetstore.unity.com/packages/2d/gui/icons/2d-simple-ui-pack-218050 框架: RedPointSystem.cs using System.…...

开发指南046-机构树控件
为了简化编程,平台封装了很多前端组件。机构树就是常用的组件之一。 基本用法: import QlmOrgTree from /qlmcomponents/tree/QlmOrgTree <QlmOrgTree></QlmOrgTree> 功能: 根据权限和控制参数显示机构树。机构树数据来源于核…...

SpringBatch文件读写ItemWriter,ItemReader使用详解
SpringBatch文件读写ItemWriter,ItemReader使用详解 1. ItemReaders 和 ItemWriters1.1. ItemReader1.2. ItemWriter1.3. ItemProcessor 2.FlatFileItemReader 和 FlatFileItemWriter2.1.平面文件2.1.1. FieldSet 2.2. FlatFileItemReader2.3. FlatFileItemWriter 3…...

如何评估AI模型:评估指标的分类、方法及案例解析
如何评估AI模型:评估指标的分类、方法及案例解析 引言第一部分:评估指标的分类第二部分:评估指标的数学基础第三部分:评估指标的选择与应用第四部分:评估指标的局限性第五部分:案例研究第六部分:…...

程序员学CFA——经济学(七)
经济学(七) 汇率外汇市场外汇市场的功能外汇市场的参与者卖方买方 汇率的计算汇率报价基础货币与计价货币直接报价与间接报价外汇报价习惯 名义汇率和实际汇率货币的升值与贬值交叉汇率计算即期汇率与远期汇率即期汇率与远期汇率的概念远期升水/贴水远期…...

imx335帧率改到10fps的方法
验证: imx335.c驱动默认的帧率是30fps,要将 IMX335 的帧率更改为 10fps,需要调整与帧率相关的参数。FPS(frames per second,每秒帧数)通常由 sensor 的曝光时间(exposure time)和垂直总时间(VTS,Vertical Total Size)共同决定。VTS 定义了 sensor 完成一帧图像采集…...

Large Language Model系列之二:Transformers和预训练语言模型
Large Language Model系列之二:Transformers和预训练语言模型 1 Transformer模型 Transformer模型是一种基于自注意力机制的深度学习模型,它最初由Vaswani等人在2017年的论文《Attention Is All You Need》中提出,主要用于机器翻译任务。随…...

java后端项目启动失败,解决端口被占用问题
报错信息: Web server failed to start . Port 8020 was already in use. 1、查看端口号 netstat -ano | findstr 端口号 2、终止进程 taskkill /F /PID 进程ID 举例:关闭8020端口...
PostgreSQL安装/卸载(CentOS、Windows)
说明:PostgreSQL与MySQL一样,是一款开源免费的数据库技术,官方口号:The World’s Most Advanced Open Source Relational Database.(世界上最先进的开源关系数据库),本文介绍如何在Windows、Cen…...

OutOfMemoryError异常OOM排查
目录 参考工具MAT(Memory Analyzer)一、产生原因二、测试堆溢出 java.lang.OutOfMemoryError: Java heap space测试代码运行手动导出dump文件mat排查打开dump文件查看Leak Suspects(泄露疑点)参考 【JVM】八、OOM异常的模拟 MAT工具分析Dump文件(大对象定位) 用arthas排…...

【Python】Arcpy将excel点生成shp文件
根据excel点经纬度数据,生成shp,参考博主的代码,进行了修改,在属性表中保留excel中的数据。 参考资料:http://t.csdnimg.cn/OleyT 注意修改以下两句中的数字。 latitude float(row[1]) longitude float(row[2])imp…...

torch之从.datasets.CIFAR10解压出训练与测试图片 (附带网盘链接)
前言 从官网上下载的是长这个样子的 想看图片,咋办咧,看下面代码 import torch import torchvision import numpy as np import os import cv2 batch_size 50transform_predict torchvision.transforms.Compose([torchvision.transforms.ToTensor(),…...

什么ISP?什么是IAP?
做单片机开发的工程师经常会听到两个词:ISP和IAP,但新手往往对这两个概念不是很清楚,今天就来和大家聊聊什么是ISP,什么是IAP? 一、ISP ISP的全称是:In System Programming,即在系统编程&…...

外卖霸王餐系统怎么快速盈利赚钱?
微客云外卖霸王餐系统,作为近年来外卖行业中的一股新兴力量,以其独特的商业模式和营销策略,迅速吸引了大量消费者的目光。该系统通过提供显著的折扣和返利,让顾客能够以极低的价格甚至免费享受到美味的外卖,同时&#…...

Linux环境下安装Nodejs
Linux环境下安装Nodejs 下载地址:https://nodejs.org/zh-cn/download/package-manager 一、使用压缩包自定义安装 上述链接下载好对应版本的软件包后,我存放到 /evn/nodejs 目录下(根据自己实际情况设置) 设置软链接 sudo ln…...

【Rust】字符串String类型学习
什么是String Rust的核心语言中只有一个String类型,那就是String slice,str通常被当作是&str的借用。String类型是通过标准库提供的,而不是直接编码到核心语言中,它是一个可增长的、可变的、utf-8编码的类型。str和String都是utf-8编码的…...

App抓包网络异常的三层防御机制与排查四步法
1. 这不是网络问题,是App在主动拦截你“App 抓包提示网络异常”——这句话我去年在三个不同客户的现场都听过。第一次是在某电商App的测试环境里,测试同学说“Fiddler一开,登录就报‘网络连接失败’,关掉就一切正常”;…...

2026年十家小程序开发公司榜单及全面解读
数字经济全行业渗透的当下,权威的小程序开发服务商排名,早已成为企业筛选技术合作方的核心参考坐标。市面上服务商定位差异大、水平参差不齐,企业如何才能找到技术实力过硬、同时匹配自身成本预期的合作方?本文结合2024-2025年行业…...

西安家谱企业服务商
如果你还认为家谱印刷只是老年市场的“老古董”,那你就错得离谱了。2024年,中国家谱印刷市场规模已突破58亿元,年复合增长率达21.3%,远超普通印刷行业。这背后,是新一代家庭对姓氏文化、家族记忆的数字化与实体化需求爆…...

MySQL 高频面试题-01
在去面试之前,很多人天天背“八股文”,结果一到现场被面试官稍微一变形就问懵了。比如:“你天天说 B 树,那为什么不用 B 树?不用红黑树?它俩到底差在哪?”“既然索引能加速,那我把所…...

MASA模组汉化包技术解析:构建高效中文游戏体验的技术解决方案
MASA模组汉化包技术解析:构建高效中文游戏体验的技术解决方案 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 在Minecraft模组生态系统中,MASA系列模组以其强大的…...

Unity WebGL底层原理与实战避坑指南
1. 这不是“把游戏搬上网页”那么简单:一场对Unity WebGL底层逻辑的硬核拆解 “疯狂特技赛车2”这个名字,对很多老玩家而言,是童年街机厅里手心冒汗、摇杆发烫的记忆。而当我在GitHub上第一次点开它被公开的Unity源码仓库,看到 B…...

G-Helper终极指南:华硕笔记本轻量控制中心的3步快速配置方案
G-Helper终极指南:华硕笔记本轻量控制中心的3步快速配置方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbo…...

ChatGPT写代码总出错?揭秘92%开发者忽略的3层提示工程校验机制
更多请点击: https://intelliparadigm.com 第一章:ChatGPT写代码总出错?揭秘92%开发者忽略的3层提示工程校验机制 当ChatGPT生成的代码在本地运行失败、逻辑错位或依赖缺失时,问题往往不在模型本身,而在于提示&#x…...

NotebookLM移动端隐私策略暗藏风险!第三方SDK调用图谱首次公开,3类敏感行为必须立即禁用
更多请点击: https://kaifayun.com 第一章:NotebookLM移动端隐私策略暗藏风险!第三方SDK调用图谱首次公开,3类敏感行为必须立即禁用 SDK调用图谱首次逆向披露 通过对NotebookLM iOS v2.4.1 与 Android v2.5.0 APK/IPA 的深度静态…...

云厂商AI基础设施争夺战:Bedrock、Azure AI Studio与Vertex AI深度对比
1. 项目概述:一场没有硝烟的AI基础设施争夺战你打开云厂商控制台,发现“Bedrock”“Azure AI Studio”“Vertex AI”这些名字突然变得比以前更醒目;你翻看技术团队的采购清单,GPU实例价格单旁多了一行加粗标注:“含专属…...