【论文解读】大模型算法发展
一、简要介绍

论文研究了自深度学习出现以来,预训练语言模型的算法的改进速度。使用Wikitext和Penn Treebank上超过200个语言模型评估的数据集(2012-2023年),论文发现达到设定性能阈值所需的计算大约每8个月减半一次,95%置信区间约为5到14个月,大大快于摩尔定律下的硬件增益。论文估计了增强的scaling law,这使论文能够量化算法的进展,并确定scaling模型与训练算法中的创新的相对贡献。尽管算法的快速发展和transformer等新架构的发展,在这段时间内,计算量的增加对整体性能的提高做出了更大的贡献。虽然受到有噪声的基准数据的限制,但论文的分析量化了语言建模的快速进展,揭示了计算和算法的相对贡献。
二、方法论
2.1模型定义
论文希望估计更新的语言模型能够比旧的模型更有效地达到一定性能水平的速率。论文通过拟合一个模型,满足两个关键需求: (1)该模型必须与之前关于神经scaling law的工作广泛一致,和(2)该模型应该允许分解对提高性能的主要贡献者,例如改进模型中的数据或自由参数的使用效率。


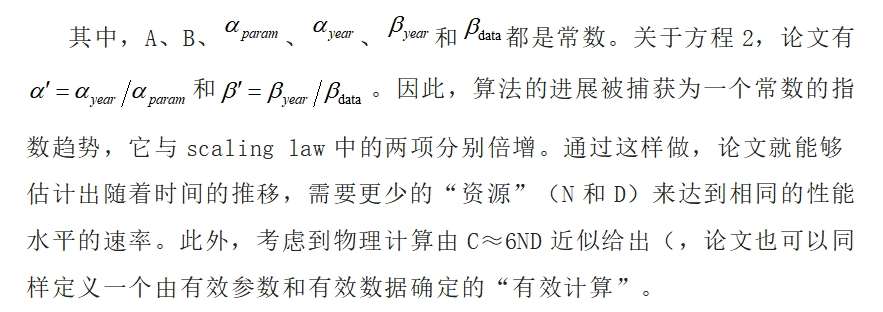
2.2估算方法
2.2.1模型选择
论文在语言模型评估数据集上估计了公式(3)中提出的增广scaling law的变量。论文执行广泛的交叉验证练习,以确定最适合数据的模型的变体。本练习的目的是考虑捕获不同效果的不同模型(例如,不同模型架构之间的不同scaling行为、不同形式的算法进展等)。


论文试图在交叉验证分析中解释这种可能性。特别地,论文引入了三个模型(模型13到15),它们解释了不同类型的scaling指数,包括指数随时间变化的可能性。论文选择的主模型(模型7)在交叉验证中优于这些模型,但这些替代方案也表现出同样的效果,通常R2在0.88到0.91之间。这个分析在附录J中有更详细的描述。 论文还考虑了其他可能影响测量的困惑的因素,从而测量算法进展的速度。例如,在某些情况下,预处理过程中不同的标记化方案可以改善WT103的困惑,多个epoch的训练模型是提高性能的常见方法。论文发现,当改变这些自由度时,论文的核心结果是大致相同的——论文在附录中提供了关于这些实验的更多细节。 最后,为了解释模型规范中的不确定性,论文比较了在交叉验证分析中考虑的不同模型的模型预测。 2.2.2数据 论文的数据集包含超过400种语言模型,在 WikiText-103 (WT103), WikiText-2 (WT2), Penn Treebank (PTB)上评估,其中大约60%作者可以在论文的分析中使用。特别是,作者从大约200篇不同的论文中检索到了相关信息,以及使用Gao,Tow等人2021年的框架对自己执行的25个模型的评估。然后,论文考虑数据的子集,其中包含拟合论文提出的模型结构所需的信息:令牌级测试困惑(它决定交叉熵损失)、发布日期、模型参数数量和训练数据集大小。这就给论文留下了大约231个模型可供分析。
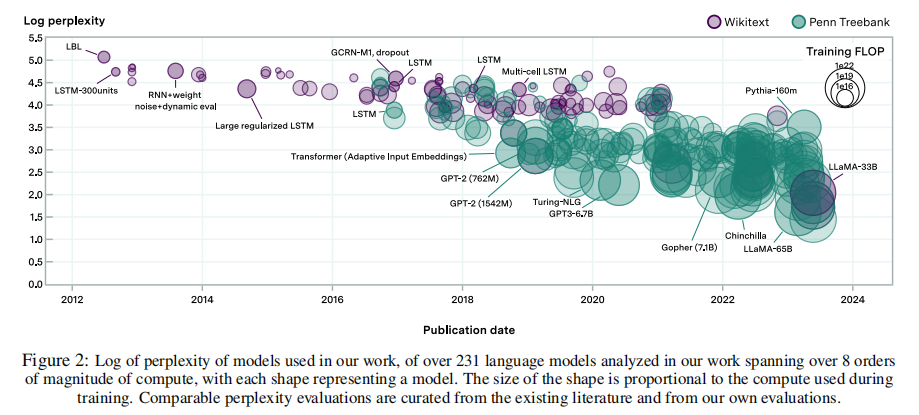
在某些情况下,从同一篇论文中检索到多个模型,即使它们构成了类似的算法创新。这可能会给自相关带来问题,这可能导致低估论文单个参数估计的不确定性。因此,在接下来的主要分析中,每篇论文最多只包含三个模型,这导致大约50个模型被排除。为了验证这种方法的稳健性,论文还考虑了另一种技术,直接解释自相关,它产生与论文的主要结果一致的加倍时间和置信区间估计(见附录I)。
三、实验结果
3.1模型大约每8个月需要的计算减少2倍


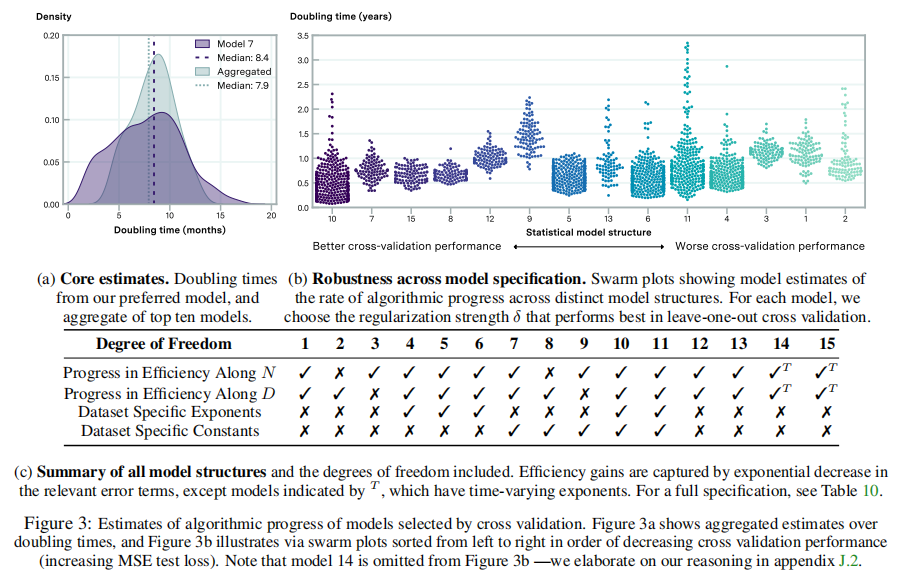
通过观察来自不同模型的预测,论文进一步检验了这个结果的稳健性。特别是,因为论文使用留一交叉验证来执行模型选择,所以论文可以将论文的首选模型的预测与论文所考虑的其他模型的预测进行比较。根据论文的交叉验证练习,连接前10个模型的倍增时间估计数,论文发现中位倍增时间为7.8个月[95%CI:1.5-17.6个月],这与论文所首选的模型相似。 另一种方法依赖于计算方案,而不是倍增时间的封闭解。论文首先计算通过加倍计算预算来实现的损失∆L的减少,假设N和D在估计的模型下是最优的。然后,论文确定了算法改进所需的时间,以产生等效的损失∆L减少。结果表明,这些方法产生的结果几乎相同,中位数的倍增时间为8.6个月,95%的置信区间为4.5-14.5个月。本程序在附录G中有更详细的说明。 该估计在计算机视觉算法进展率(Erdil和Besiroglu 2022)、强化学习的样本效率改进(Dorner 2021)以及特定输入大小下常见算法家族的估计速率的置信区间范围内。总的来说,论文的研究结果表明,语言模型的算法进展与之前研究的领域中算法和软件的进展速度相当,而且可能更快(见图1)。
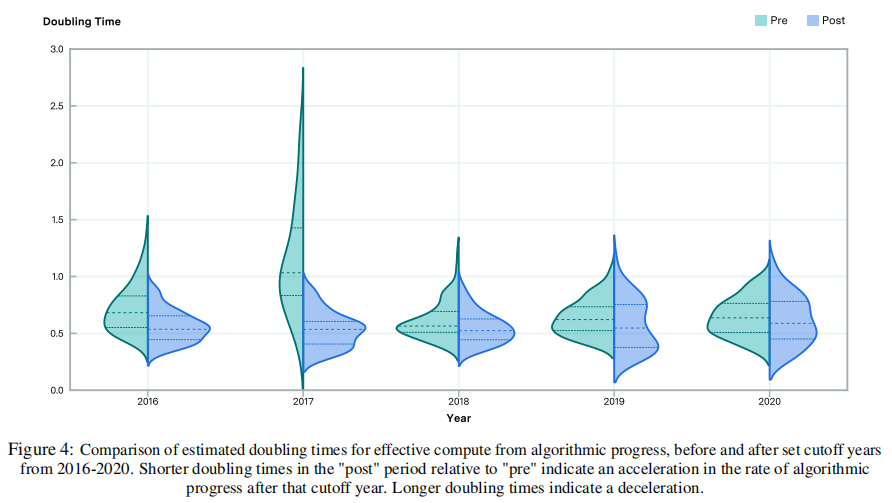
虽然论文的模型的结构不适合分析算法改进速度上的细粒度加速或减速,但论文仍然可以测试增长率在整个时间段内一次性增加或减少的可能性。为此,论文考虑了论文的首选模型(模型7)的一个变体,其中引入了一个虚拟变量——对于在某一年开始之前发布的任何模型,这都等于0,否则为1。这允许论文考虑在某一年的截止时间前后倍增时间(例如2017年),论文对几个这样的截止时间进行分析。 其结果如图4所示。在这里,论文可以看到,2017年初前后估计的倍增时间的差异非常明显,但截止年份的其他选择并非如此。在每一年,截止年开始后,中位数的倍增时间都要快,但通常只是略快。总的来说,这并没有提供算法进步的急剧加速的有力证据。这并不排除效应量较弱的可能性,因为论文的方法在统计上的动力不足。
3.2最近的下一个令牌预测的性能提高都来自于计算scaling 天真地推断论文估计的倍增时间表明,在2014年到2023年之间,预训练算法的进步使性能提高了大约22000倍的计算。与此同时,自深度学习开始以来,物理计算预算大约每6个月就增加一倍,包括语言模型。这表明,物理计算增长了大约100万倍。这描绘了一幅程式化的画面,自2014年以来,“有效计算”增长了约220亿倍,几乎三分之二的规模是由于实际物理计算资源的使用增加。
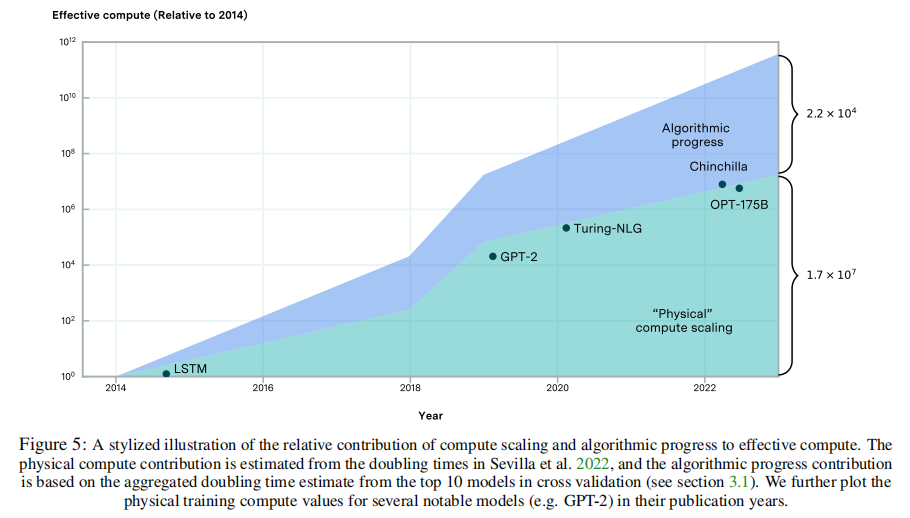
论文有理由对这种幼稚的推理保持谨慎。首先,论文并没有在数据集中的任何地方直接观察到22,000倍(甚至10,000倍)的增益。然而,考虑到早期的研究人员不太可能用大量的计算来训练语言模型,因此论文不太可能在分析的时间段内观察到如此大的下降。然而,缺乏这样的观察结果仍然提出了关于在长时间的多年时期之间推断这些趋势的可靠性的问题。 值得注意的一个具体原因是,推理法忽略了算法创新的规模依赖性。随着时间的推移,随着模型在更大的计算规模上进行训练,一些算法创新可能会变得过时——例如,特定标记器或超参数设置的有效性可能会降低,使它们对未来更大的模型不那么有用。
相反,最近的创新在更小的规模上实施时,比现在的模型可能无法产生很大的或任何好处。例如,从scaling law中获得的收益与所使用的计算规模有关(见附录B),而较老的体系结构,如LSTM和卷积网络,可以在相对于transformer的小尺度上表现出更高的效率。 虽然倍增时间的简单外推预测了计算需求的大幅减少,但论文的工作并没有提供令人信服的证据,证明论文可以在当前或未来通过应用完整的现代创新来训练非常小的模型来实现更大的模型的性能。算法改进的规模依赖性,以及在论文的数据集中缺乏对如此大的效率提高的直接观察,这表明需要进一步的研究和更全面的数据来验证这些外推。 除了倍增时间外,论文还可以分解算法的相对贡献,并通过直接评估论文估计的模型来计算比例。
鉴于论文的模型是非线性的,因此不可能简单地将性能改进归因于计算、数据的扩展和基于系数比的算法的改进。因此,论文使用Shapley值分析,其中论文估计了每个因素在减少预测困惑方面的平均预期边际贡献。这一分析微弱地支持了上面的程式化图,即自2014年以来,计算scaling在解释性能改进方面比算法的进步更重要。 研究结果表明,算法进步对性能改进的相对贡献随着时间的推移而减少,至少在历史上接近最先进技术的模型数据集中是如此。这一观察结果与图5中的程式化表示以及Erdil和Besiroglu对计算机视觉的发现一致,在计算机视觉中,计算随着时间的推移,scaling显示出越来越重要。 对算法进步的相对贡献不断减少的一种解释是,对扩大物理计算的投资已经大幅增加,超过了算法改进的速度。相对于基本算法或架构的变化,这一框架在过去几年中与对大型语言模型的重视相一致,特别是自2019年引入GPT-2以来。图5说明了这一观点的一个程式化版本,描述了2018-2019年前后物理计算比例的急剧增加,随后恢复到之前的计算比例增长率。 还有其他可能的解释——例如,transformer架构可能是一个关键的创新(见第3.3节),而随后的算法进步则不那么重要。
另外,这一观察结果也可以用算法创新速度的长期下降来解释。然而,论文发现这两种解释不如图4的结果令人信服,在图4中,算法的进展速度并没有明显下降(例如2018年截止)。如果说有什么不同的话,那就是概率略有上升,这与这两种解释所预测的相反。
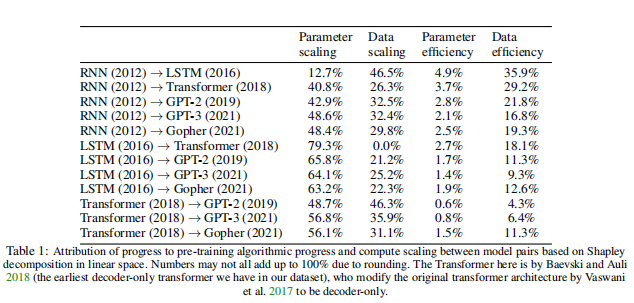
3.3transformer架构的意义 自2017年推出以来,transformer架构已成为语言建模中的主导算法架构,形成了多个著名系统的基础。transformer也被广泛应用于视觉模型中,并且有丰富的现有文献评估了transformer架构与其他视觉架构相比的优点。 论文试图根据“计算等效增益”来量化transformer体系结构对数据集中其他体系结构(lstm、rnn、state space model等)的贡献。这类似于戴维森等人2023年中概述的方法——在这种情况下,计算等效增益是必须调整训练计算以提高基准性能的量,与引入transformer的相同的量。例如,Eernandeds和T. Brown 2020发现transformer(2017)在WMT-14-EN-FR基准上实现了与Seq2Seq(2014)模型相同的性能,计算量少61倍。 为了获取transformer所代表的改进,论文修改了论文的核心模型如下:

其中,σ: R→(0,1)为sigmoid函数,由σ(x) = 1/(1 + e−x)给出。γT是一个常数,所有其他术语都具有与原始模型中相同的含义。关键的直觉是,transformer可以使论文能够比它之前的架构更有效地使用计算(或数据)。 经过预处理后,论文的数据集包含103个transformer模型和127个非transformer模型,主要由循环网络组成,如LSTM。根据该数据拟合模型表明,transformer结构通常可按比例降低4.6% [95% CI: 3.0%,7.0%]。 论文可以用“计算等效增益”来计算其贡献:论文首先计算具有N和D的transformer的预测损耗,以及具有相同输入的非transformer的预测损耗。然后,论文确定N和D的减少,以匹配损失的差异。然后计算近似,如C≈6ND。简而言之,如果一个创新将实现特定损失所需的计算量减少一半,那么该创新的计算等效增益为2。 基于100次自举,论文获得了transformer的计算等效增益的中值估计为7.2×[95%CI:3.3×,45.7×]。这一可观的增益表明,transformer架构提供的效率约相当于log (7)/ log(2e4),占过去9年算法总增益的20%,或该领域近2年的算法进步。此外,如果transformer架构还提供了一种方便的工具,通过它可以有效地传输计算,从而通过计算的scaling促进了一些增益,这些增益很可能主导了论文最近看到的总体增益。 这里需要注意的是,transformer的测量显著性可能取决于如何评估它。例如,transformer可能比循环网络更能适应长上下文,并且使用更长上下文(如>1000个token)可能表明transformer比使用更短的上下文的评估有更大的改进。论文在这里没有明确地控制上下文长度,论文在附录E.2.1中更详细地讨论了这个假设的潜在影响。
四、讨论和结论
4.1对论文的发现的总结
本文对2012-2023年语言模型预训练的算法进展进行了全面的实证分析。通过在 WikiText 和Penn Treebank基准上管理超过200种语言模型评估的数据集,论文量化了计算scaling和算法效率提高对总体性能增益的相对贡献。论文的主要发现如下:
首先,论文估计,自2012年以来,达到集合语言建模性能水平所需的计算量平均每8-9个月减少了一半。这一速度大大超过了摩尔定律的硬件收益,并使语言建模与计算机视觉和强化学习一起成为算法进步最快的领域之一。这支持了一种普遍的直觉,即语言建模是计算机科学中一个异常快速发展的领域。
其次,论文的工作表明,最近在语言建模方面的大部分进展更多地来自于scaling模型和数据集,而不是来自于预训练的算法创新。基于Shapley值的分析表明,60-95%的性能提高来自于计算scaling,而算法仅贡献了5-40%。
第三,2017年引入的transformer架构是算法的重大进步,计算等效增益为3倍到46倍,占过去十年预训练语言模型中算法创新的10%以上。这突出了transformer作为该领域的一个关键框架突破的意义。
4.2限制
虽然论文的分析是量化算法进展方面的进步,但一些限制降低了论文的精度,降低了论文估计的信心:
缺乏对特定创新所获得的收益的估计。论文的模型被指定用来量化算法在相对较大的时间段内(例如在几年)的进展。然而,它无法提供可靠的细粒度信息,如在较短的时间尺度内取得的进展,或特定创新的重要性。实验工作更适合于估计特定算法创新的效率增益。
高质量数据的可用性有限。论文在分析中使用的方法在很大程度上依赖于多年来的数据样本。这被证明是非常具有挑战性的,原因有很多——例如,模型并不总是在同一基准上进行评估,2017年之前的数据相对稀疏,论文可能不报告相关信息,如参数量。在其他原因中,这可能导致论文的估计非常嘈杂,产生广泛的置信区间。此外,算法的改进和scaling历来是同时引入的,在论文的数据集中,这两者之间的相关性使得很难理清它们对总体有效计算增长的相对贡献。
模型训练和评估中的不一致。评估中的不一致是众所周知的。虽然论文已经从数据集中排除了非标准评估,但论文的数据集跨越了具有不同标记化方案、文本预处理、步长和其他细节的模型。这在论文对算法进展的估计中引入了噪声和潜在的偏差,因为随着时间的推移,研究人员可能会采用更有利的评估方案。然而,论文估计算法改进的困惑减少很大;可能比评估程序的变化所能解释的要大。论文将在附录E.2.3中扩展一下这些点。
无法在数据使用中区分数据质量和效率。论文在本文中定义效率改进的方式是,随着时间的推移,减少达到一定性能水平所需的资源数量。然而,在数据效率的情况下,这遇到了一个问题——论文测量到的数据需求的减少是由于数据质量的提高,还是由于算法使用数据的能力的改进?这不是一个论文的模型能回答的问题。因此,值得注意的是,论文测量的计算需求的减少与算法改进和数据质量改进有关,它们的相对贡献可能是未来研究的一个主题。
依赖于Chinchilla scaling law。论文的模型推导出的scaling law适用于遵循GPT-3架构的密集transformer。论文使用这个scaling law来建模不同transformer架构、递归神经网络等的算法改进。未来的算法也可能遵循不同的scaling law。然而,论文相信论文的核心结果很可能仍然成立:首先,神经scaling并不是一种局限于transformer的现象。论文发现广泛的统计模型结构提供一致的估计,和替代方法估计预训练算法进展也给类似的结果(见附录),所以很可能论文的核心结果是鲁棒的。
对未来进展的了解有限。虽然本文的结果可以用来告知语言建模的未来进展,但论文的论文的重点是历史的改进。未来的进展速度可能会更慢,但它们也可能会更快(例如,由于研究兴趣和投资的增加)。对未来进展的期望需要考虑到这些因素,论文大部分没有深入讨论。
4.3结论
使用Wikitext 和 Penn Treebank上2012-2023年的200多个语言模型评估数据集,论文发现达到固定性能阈值所需的计算大约每8个月减少一半。这比摩尔定律和许多其他计算领域的速率要快得多。虽然算法创新发生迅速,但计算规模在同一时期扩展了100万倍,超过了算法的收益,构成了近年来性能改进的主要来源。
总的来说,论文的工作提供了一个对语言建模的快速发展速度的定量估计。它还揭示了计算规模对最近的收益的起主导作用而不是算法进步。未来的工作可以受益于将这种分析扩展到额外的、具体的基准,并更仔细地检查数据质量改进的影响和其他具体创新的成果。尽管有其局限性,但这项研究证明了可以从对机器学习结果的广泛数据集的详细统计分析中获得的有价值的见解。通过确定绩效改进的主要驱动因素,这项工作为进一步探索和理解该领域的这些趋势奠定了基础。
相关文章:
【论文解读】大模型算法发展
一、简要介绍 论文研究了自深度学习出现以来,预训练语言模型的算法的改进速度。使用Wikitext和Penn Treebank上超过200个语言模型评估的数据集(2012-2023年),论文发现达到设定性能阈值所需的计算大约每8个月减半一次,95%置信区间约为5到14个月…...

WebApi配置Swagger、Serilog、NewtonsoftJson、Sqlsugar、依赖注入框架Autofac、MD5加密
文章目录 项目准备1、创建WebApi项目配置Swagger、Serilog、NewtonsoftJsonNewtonsoftJsonSwaggerSerilog 使用ORM框架SqlSugar创建Service类库构成MVC框架使用AutoFac进行依赖注入 创建用户登录接口添加用户时进行安全防护 项目准备 1、创建WebApi项目 配置Swagger、Serilog…...

【ffmpeg命令基础】视频选项讲解
文章目录 前言设置输出文件的帧数设置每秒播放的帧数设置输出视频的帧率示例1:更改输出视频的帧率示例2:将图像序列转换为视频 设置输入视频的帧率示例3:处理高帧率视频示例4:处理低帧率视频 同时设置输入和输出帧率示例5…...

使用uniapp开发小程序(基础篇)
本文章只介绍微信小程序的开发流程,如果需要了解其他平台的开发的流程的话,后续根据情况更新相应的文章,也可以根据uniapp官网的链接了解不同平台的开发流程 HBuilderX使用:https://uniapp.dcloud.net.cn/quickstart-hx.html 开发工具 开始…...

vue3【详解】组合式函数
什么是组合式函数? 利用 Vue 的组合式 API 来封装和复用有状态逻辑的函数,用于实现逻辑复用,类似 react18 中的 hook 函数名称 – 以 use 开头,采用驼峰命名,如 useTitle参数 – 建议使用 toValue() 处理(…...

微服务实战系列之玩转Docker(六)
前言 刚进入大暑,“清凉不肯来,烈日不肯暮”,空调开到晚,还是满身汗。——碎碎念 我们知道,仓库可见于不同领域,比如粮食仓库、数据仓库。在容器领域,自然也有镜像仓库(registry&…...

Python题解Leetcode Hot100之动态规划
动态规划解题步骤-5部曲 确定dp数组(dp table)以及下标的含义确定递推公式dp数组如何初始化确定遍历顺序举例推导dp数组 70. 爬楼梯 题目描述 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到…...

你了解GD32 MCU上下电要求吗
你了解GD32 MCU的上下电要求吗?MCU的上下电对于系统的稳定运行非常重要。 以GD32F30X为例,上电/掉电复位波形如如下图所示。 上电过程中,VDD/VDDA电压上电爬坡,当电压高于VPOR(上电复位电压)MCU开始启动&a…...

二、【Python】入门 - 【PyCharm】安装教程
往期博主文章分享文章: 【机器学习】专栏http://t.csdnimg.cn/sQBvw 目录 第一步:PyCharm下载 第二步:安装(点击安装包打开下图页面) 第三步:科学使用,请前往下载最新工具及教程:…...

2、程序设计语言基础知识
这一章节的内容在我们的软件设计师考试当中,考的题型比较固定,基本都是选择题,分值大概在2~4分左右。 而且考的还多是程序设计语言的一些基本语法,特别是这两年比较火的Python。 所以对于有一定要编程基础的即使本章的内容不学习&…...
:TP-Link联洲)
ARM/Linux嵌入式面经(十八):TP-Link联洲
文章目录 虚拟内存,页表,copy on write面试题1:面试题2:面试题3:进程和线程的区别红黑树和b+树的应用红黑树的应用B+树的应用视频会议用了哪些协议1. H.323协议2. SIP协议(会话发起协议)3. WebRTC(网页实时通信)4. 其他协议io多路复用(select,poll,epoll)面试题li…...

解读vue3源码-响应式篇2
提示:看到我 请让我滚去学习 文章目录 vue3源码剖析reactivereactive使用proxy代理一个对象1.首先我们会走isObject(target)判断,我们reactive全家桶仅对对象类型有效(对象、数组和 Map、Set 这样的集合类型),而对 str…...

【测开能力提升-fastapi框架】fastapi能力提升 - 中间件与CORS
1. 中间件 1.1 介绍(ChatGPT抄的,大致可以理解) 一种机制,用于在处理请求和响应之前对其进行拦截、处理或修改。中间件可以在应用程序的请求处理管道中插入自定义逻辑,以实现一些通用的功能,如身份验证、…...

centos7安装es及简单使用
为了方便日后查看,简单记录下! 【启动es前,需要调整这个配置文件(/opt/elasticsearch-6.3.0/config/elasticsearch.yml)的两处ip地址,同时访问页面地址的ip:9200时,ip地址也对应修改】 【启动kibana前,需要调整这个配置文件(/opt/kibana-6.3.0/config/k…...
)
2024年自动驾驶SLAM面试题及答案(更新中)
自动驾驶中的SLAM(Simultaneous Localization and Mapping,即同步定位与地图构建)是关键技术,它能够让车辆在未知环境中进行自主定位和地图建构。秋招来临之际,相信大家都已经在忙碌的准备当中了,尤其是应届…...
HTML零基础自学笔记(上)-7.18
HTML零基础自学笔记(上) 参考:pink老师一、HTML, Javascript, CSS的关系是什么?二、什么是HTML?1、网页,网站的概念2、THML的基本概念3、THML的骨架标签/基本结构标签 三、HTML标签1、THML标签介绍2、常用标签图像标签ÿ…...

数学建模--图论与最短路径
目录 图论与最短路径问题 最短路径问题定义 常用的最短路径算法 Dijkstra算法 Floyd算法 Bellman-Ford算法 SPFA算法 应用实例 结论 延伸 如何在实际应用中优化Dijkstra算法以提高效率? 数据结构优化: 边的优化: 并行计算&…...

FLINK-checkpoint失败原因及处理方式
在 Flink 或其他分布式数据处理系统中,Checkpoint 失败可能由多种原因引起。以下是一些常见的原因: 资源不足: 如果 TaskManager 的内存或磁盘空间不足,可能无法完成状态的快照,导致 Checkpoint 失败。 网络问题&am…...

Hbase映射为Hive外表
作者:振鹭 Hbase对应Hive外表 (背景:在做数据ETL中,可能原始数据在列式存储Hbase中,这个时候,如果我们想清洗数据,可以考虑把Hbase表映射为Hive的外表,然后使用Hive的HQL来清除处理数据) 1. …...
题解)
洛谷P1002(过河卒)题解
题目传送门 思路 直接爆搜会TLE,所以考虑进行DP。 由于卒只可以从左边和上面走,所以走到(i,j)的路程总数为从上面走的路程总数加上从左边走的路程总数。我们用dp[i][j]表示从起点走到(i,j)的路程总数,那么状态转移方程为: dp[…...

多店铺场景下如何通过快手订单接口实现订单数据的统一聚合管理?
对于电商业务管理系统的开发者而言,服务在快手平台经营多个店铺的商家是常见需求。然而,每个店铺都有独立的授权凭证(access_token)和独立的订单流,若分别对接和管理,不仅开发维护成本高,还容易…...
)
别光看代码!聊聊51单片机做计算器时,那些新手容易踩的坑(键盘消抖、变量溢出、显示刷新)
51单片机计算器开发进阶指南:从功能实现到工程优化的深度解析 第一次在51单片机上实现计算器功能时,那种按下按键能看到数码管显示正确结果的兴奋感至今难忘。但真正投入实际使用后,各种问题接踵而至——按键偶尔失灵、大数运算出错、显示闪烁…...

护眼钢化膜是智商税?圆偏振光+AR降反射实测,观复盾用硬核技术给出答案
护眼钢化膜是智商税?圆偏振光AR降反射实测,观复盾用硬核技术给出答案“花上百块买的护眼钢化膜,贴上后屏幕又黄又暗,眼睛反而更累了。”这样的抱怨在数码社区里比比皆是。与此同时,也有用户表示换了圆偏振光膜后&#…...

【技术解析】从点测量到全场感知:DIC三维应变测量如何革新传统应变片测试范式
1. 从点到面的技术革命:为什么我们需要全场应变测量? 记得我第一次接触材料力学测试时,导师让我用传统应变片测量一块铝合金板的拉伸变形。我花了整整三天时间,在试样上贴了二十多个应变片,结果数据还是支离破碎。那时…...

证件照换装API实战指南:一键换装,告别服装不合格!
还在为证件照服装不符合要求而烦恼?可立图ClipImg证件照换装API,自动识别身形与姿态,一键替换为正装,让你的照片瞬间专业起来!一、痛点场景:你的证件照是否也遇到过这些尴尬吗?求职简历…...

微控制器自检技术:从原理到实践,构建嵌入式系统的可靠性基石
1. 为什么微控制器自检不是“可有可无”的选项?如果你是一名嵌入式开发者,或者你的产品里用到了单片机,那你一定遇到过这样的场景:产品在实验室里跑得好好的,一到客户现场就莫名其妙死机;或者设备运行了几个…...

智能体进化蓝图:构建具备持续学习能力的AI系统架构设计
1. 项目概述:一个开源智能体进化蓝图最近在开源社区里,一个名为planck-lab/hermes-evolving-agents-public-blueprint的项目引起了我的注意。乍一看这个标题,包含了几个关键信息:planck-lab(普朗克实验室,一…...

别再让电池充不满!用CN3791芯片设计太阳能充电电路,这几个调试坑我帮你踩了
太阳能充电电路实战:CN3791芯片调试避坑指南 当阳光洒在太阳能板上,理论上我们应该获得源源不断的清洁能源。但现实往往比理想骨感得多——尤其当你发现精心设计的CN3791充电电路始终无法将锂电池充满时。这不是芯片的错,而是我们在参数设置和…...

TPS40192与TPS40193多相降压控制器:DCR与CS电流检测方案深度对比与设计实践
1. 项目概述:从两颗芯片说起最近在做一个大电流的分布式电源项目,板子上需要给核心处理器和一堆外围芯片供电,电流需求从几安培到几十安培不等,电压轨也有好几路。这种场景下,传统的线性稳压器(LDO…...

STM32 FSMC/FMC接口详解:地址映射、时序配置与实战优化
1. 项目概述:深入理解STM32的FSMC/FMC接口在嵌入式开发中,尤其是涉及大屏显示、高速数据采集或复杂外部设备交互的项目里,我们常常会遇到一个绕不开的“硬骨头”——如何让STM32单片机高效、稳定地与外部并行存储器或设备通信。这时ÿ…...