DuckDB核心模块揭秘 | 第1期 | 向量化执行引擎之Pipeline
DuckDB核心模块揭秘 | 第1期 | 向量化执行引擎之Pipeline
DuckDB是一款非常火的OLAP嵌入式数据库,性能超级棒。它分为多个组件:解析器、逻辑规划器、优化器、物理规划器、执行器以及事务和存储管理层。其中解析器原语PgSQL的解析器;逻辑规划器包含binder、plan generator,前者解析所有引用的schema中的对象的表达式,将其与列名和类型匹配,后者将binder生成的AST转换成由基本逻辑查询运算符组成的树;优化器产生优化的查询计划;物理规划器将优化的查询计划转换成物理执行计划,即PhysicalOperator树。它的高性能主要得益于它的push-based pipeline向量化执行引擎。本文介绍下它的向量化引擎pipeline生成原理。
1、物理执行计划长什么样?有哪些算子?
physical_plan_generator.cpp中CreatePlan函数将逻辑计划节点转换成物理计划节点,即PhysicalOperator。有哪些算子类型呢?PhysicalOperatorType:
//===--------------------------------------------------------------------===//
// Physical Operator Types
//===--------------------------------------------------------------------===//
enum class PhysicalOperatorType : uint8_t {INVALID,ORDER_BY,LIMIT,STREAMING_LIMIT,LIMIT_PERCENT,TOP_N,WINDOW,UNNEST,UNGROUPED_AGGREGATE,HASH_GROUP_BY,PERFECT_HASH_GROUP_BY,FILTER,PROJECTION,COPY_TO_FILE,BATCH_COPY_TO_FILE,FIXED_BATCH_COPY_TO_FILE,RESERVOIR_SAMPLE,STREAMING_SAMPLE,STREAMING_WINDOW,PIVOT,// -----------------------------// Scans// -----------------------------TABLE_SCAN,DUMMY_SCAN,COLUMN_DATA_SCAN,CHUNK_SCAN,RECURSIVE_CTE_SCAN,CTE_SCAN,DELIM_SCAN,EXPRESSION_SCAN,POSITIONAL_SCAN,// -----------------------------// Joins// -----------------------------BLOCKWISE_NL_JOIN,NESTED_LOOP_JOIN,HASH_JOIN,CROSS_PRODUCT,PIECEWISE_MERGE_JOIN,IE_JOIN,DELIM_JOIN,INDEX_JOIN,POSITIONAL_JOIN,ASOF_JOIN,// -----------------------------// SetOps// -----------------------------UNION,RECURSIVE_CTE,CTE,// -----------------------------// Updates// -----------------------------INSERT,BATCH_INSERT,DELETE_OPERATOR,UPDATE,// -----------------------------// Schema// -----------------------------CREATE_TABLE,CREATE_TABLE_AS,BATCH_CREATE_TABLE_AS,CREATE_INDEX,ALTER,CREATE_SEQUENCE,CREATE_VIEW,CREATE_SCHEMA,CREATE_MACRO,DROP,PRAGMA,TRANSACTION,CREATE_TYPE,ATTACH,DETACH,// -----------------------------// Helpers// -----------------------------EXPLAIN,EXPLAIN_ANALYZE,EMPTY_RESULT,EXECUTE,PREPARE,VACUUM,EXPORT,SET,LOAD,INOUT_FUNCTION,RESULT_COLLECTOR,RESET,EXTENSION
};让我们看一个简单inner join的例子:物理执行计划最上头是投影算子PROJECTION,然后其左子树是HASH_JOIN算子,HASH_JOIN两个子算子分别为两个顺序扫描SEQ_SCAN:

基于物理执行计划构建出pipeline,真正执行的是pipeline。
2、物理执行计划如何构建pipeline?
2.1什么是MetaPipeline
MetaPipeline 表示一组都具有相同Sink的Pipeline。Source为输入,Sink为输出,Other Node就是其他节点,将一个物理执行计划树转换成多个pipeline。一个pipeline包含一个source和一个sink以及若干个operators。
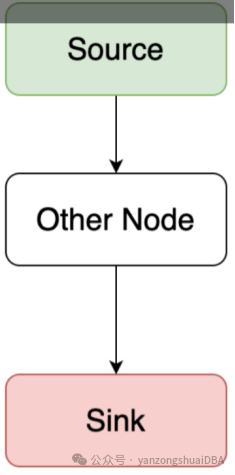
pipeline还存在一定的依赖关系,hashjoin节点必须依赖build端的pipeline产生的数据才行,所以就需要MetaPipeline构建多个pipeline依赖关系,最后执行时仅关注pipeline就可以。
以1中的例子介绍pipeline的构建过程:
2.2 Pipeline的构建
1)最开始由Executor::InitializeInteral函数创建一个MetaPipeline。该MetaPipeline的sink为NULL,vector<>pipelines容器创建一个pipeline,该pipeline的sink为NULL。
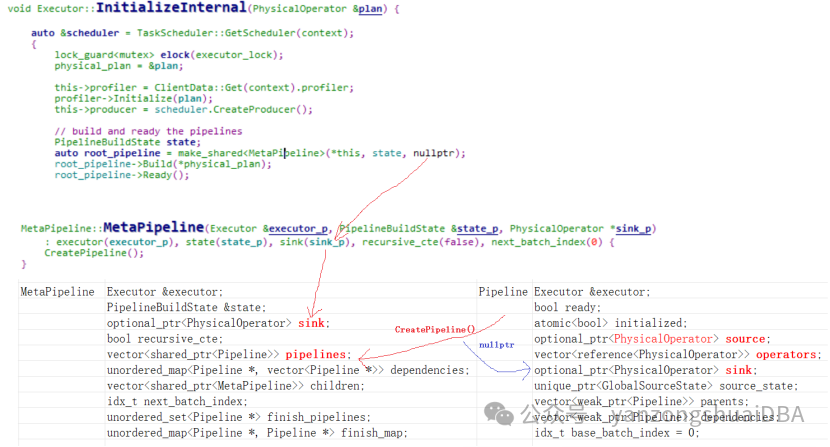
2)接着调用root_pipeline->Build(*physical_plan)使用上面的MetaPipeline继续构建pipeline
3)physical_plan为RESULT_COLLECTOR,Build会调用对应operator的Buildipelines,即调用PhysicalResultCollector::BuildPipelines,PhysicalResultCollector为PhysicalOperator的子类。
 将当前operator即PhysicalResultCollector作为当前pipeline的source,如上图所示。
将当前operator即PhysicalResultCollector作为当前pipeline的source,如上图所示。
4)接着在调用CreateChildMetaPipeline创建一个child_meta_pipeline,sink节点为当前节点,即PhysicalResultCollector:并构建出和上一个pipeline的父子关系

代码:

5)紧接着使用child_meta_pipeline继续构建pipeline。下一个算子是PROJECTION:PhysicalProjection,它没有重写基类的BuildPipelines,那么就调用PhysicalOperator的BuildPipelines:
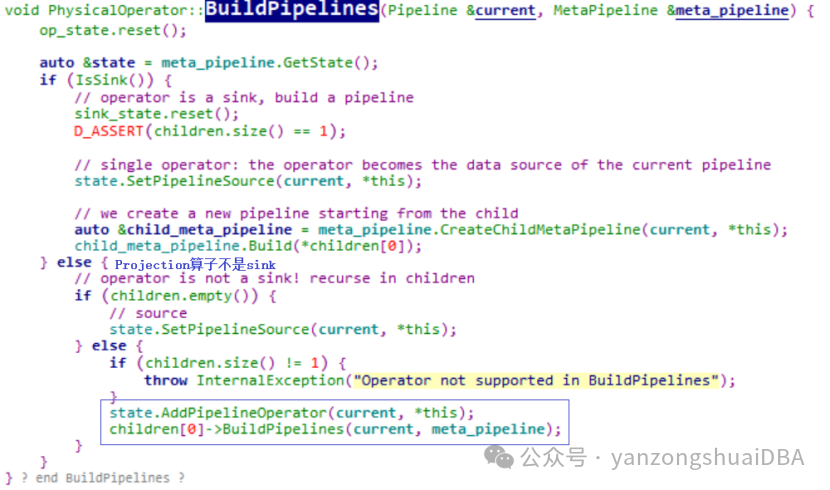
projection不是sink,并且它的子节点不为空,所以在当前pipeline添加一个算子即PhysicalProjection:也就是将PhysicalProjection放到当前pipeline的operators容器中

6)children[0]->BuildPipelines构建当前算子PhysicalProjection子节点的pipeline。此时到了HashJoin,即需要调用PhysicalHashJoin的PhysicalJoin::BuildJoinPipelines继续构建pipeline

首先将HashJoin添加到当前pipeline的operator容器中(因为作为探测端的pipeline);然后保留一份当前MetaPipeline中的所有pipeline到pipelines_so_for后面使用;接着构建build端的MetaPipeline:CreateChildMetaPipeline函数完成:主要是构建一个pipeline,sink为当前PhysicalHashJoin,source为PhysicalTableScan:此时构建的pipeline如下图所示:

7)然后调用op.children[0].BuildPipelines继续build探测端的pipeline,实际上将左表的PhysicalTableScan设置到探测端pipeline的Source中。如上图所示。
8)外连接需要使用步骤6)保存的pipeline,构建一个childpipeline:

即使用Metapipeline2的pipeline再构建一个childpipeline,需要将PhysicalProjection操作符算子也加进去,此时结构如下图所示:
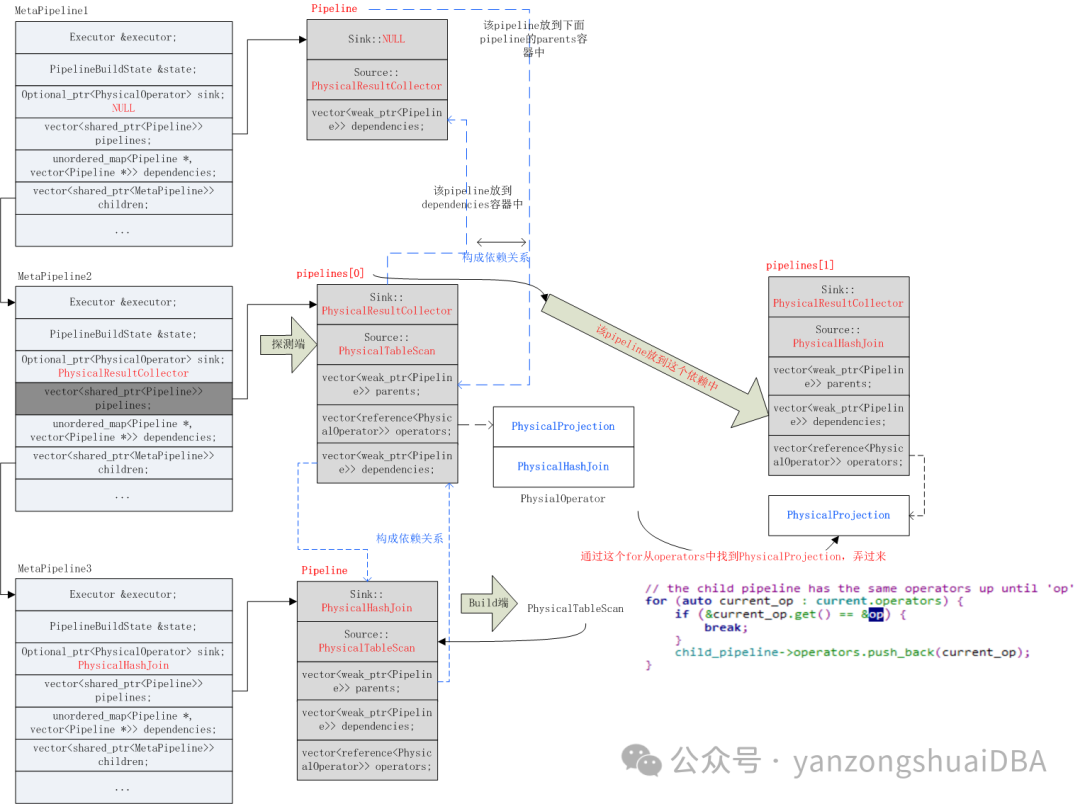
9)接着会添加依赖,都是在CreateChildPipeline函数中完成。对于当前的metapipeline,即MetaPipeline2它有两个pipeline:pipeline[0]:probe端;pipeline[1]:child pipeline。首先将当前pipeline(pipeline[0])放到dependencies[child_pipeline]中;然后调用AddDependenciesFrom(child_pipeline, last_pipeline, false)继续添加依赖关系,从last_pipeline开始继续向dependencies中添加。
例如,当前metapipeline中有n个pipeline,下面pipeline[1]为起使pipeline,pipeline[m]为dependant,那么会将中间所有的pipeline都添加到dependant依赖数组里面。
pipelines[0]
....
pipelines[s] ---> start
.....
pipelines[m] ---> dependantpipelines[n-1]结构:unordered_map<Pipeline *, vector<Pipeline *>> dependencies;完成依赖后:
pipelines[m] : [pipelines[s]......pipelines[m-1]]
由于这里的s=0;m=1所以依赖关系为:pipelines[1] : [ pipelines[0] ],其中pipeline[1]就是child_pipeline。如此:child_pipeline : [probe pipeline],表示probe pipeline依赖child_pipeline.
10)返回到1),此时进入root_pipeline->Ready()

以8)的metapipeline2中的pipeline[0]为例,反转前:

反转后:
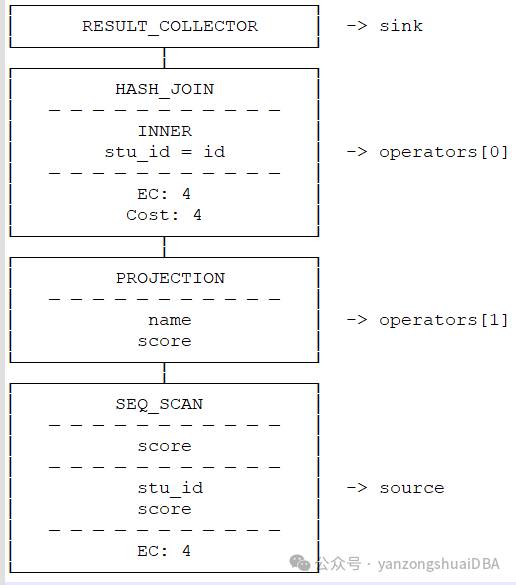
11)总结:8)中为所有Metapipeline和pipeline:
第一个Metapipeline:
{pipelines[1], children[1]}
第二个Metapipeline:Children Metapipeline:
{pipelines[2], children[1]}
第三个Metapipeline:children metapipeline:
{pipelines[1], children[0]}
注意:表示的是数组大小
12)最后再次回到1)Executor::InitializeInternal函数,会从root_pipeline(他是metapipeline),递归调用所有的metapipeline的pipelines数组,将pipeline汇总到root_pipelines中:
root_pipeline->GetPipelines(root_pipelines, false);
//vector<shared_ptr<Pipeline>> root_pipelines;这就是pipeline的一个生成过程,下期介绍这些pipeline是如何调度的
相关文章:
DuckDB核心模块揭秘 | 第1期 | 向量化执行引擎之Pipeline
DuckDB核心模块揭秘 | 第1期 | 向量化执行引擎之Pipeline DuckDB是一款非常火的OLAP嵌入式数据库,性能超级棒。它分为多个组件:解析器、逻辑规划器、优化器、物理规划器、执行器以及事务和存储管理层。其中解析器原语PgSQL的解析器;逻辑规划器…...

Vue如何让用户通过a链接点击下载一个excel文档
在Vue中,通过<a>标签让用户点击下载Excel文档,通常需要确保服务器支持直接下载该文件,并且你有一个可以直接访问该文件的URL。以下是一些步骤和示例,展示如何在Vue应用中实现这一功能。 1. 服务器端支持 首先,…...

美摄科技企业级视频拍摄与编辑SDK解决方案
在数字化浪潮汹涌的今天,视频已成为企业传递信息、塑造品牌、连接用户不可或缺的强大媒介。为了帮助企业轻松驾驭这一视觉盛宴的制作过程,美摄科技凭借其在影视级非编技术领域的深厚积累,推出了面向企业的专业视频拍摄与编辑SDK解决方案&…...

MySQL:增删改查、临时表、授权相关示例
目录 概念 数据完整性 主键 数据类型 精确数字 近似数字 字符串 二进制字符串 日期和时间 MySQL常用语句示例 SQL结构化查询语言 显示所有数据库 显示所有表 查看指定表的结构 查询指定表的所有列 创建一个数据库 创建表和列 插入数据记录 查询数据记录 修…...

初识git工具~~上传代码到gitee仓库的方法
目录 1.背景~~其安装 2.gitee介绍 2.1新建仓库 2.2进行相关配置 3.拉取仓库 4.服务器操作 4.1克隆操作 4.2查看本地仓库 4.3代码拖到本地仓库 4.4关于git三板斧介绍 4.4.1add操作 4.4.2commit操作 4.4.3push操作 5.一些其他说明 5.1.ignore说明 5.2git log命令 …...
Redis知识点总价
1 redis的数据结构 2 redis的线程模型 1) Redis 采用单线程为什么还这么快 之所以 Redis 采用单线程(网络 I/O 和执行命令)那么快,有如下几个原因: Redis 的大部分操作都在内存中完成,并且采用了高效的…...

大语言模型-GPT-Generative Pre-Training
一、背景信息: GPT是2018 年 6 月由OpenAI 提出的预训练语言模型。 GPT可以应用于复杂的NLP任务中,例如文章生成,代码生成,机器翻译,问答对话等。 GPT也采用两阶段的训练过程,第一阶段是无监督的方式来预训…...

mybatis批量插入、mybatis-plus批量插入、mybatis实现insertList、mybatis自定义实现批量插入
文章目录 一、mybatis新增批量插入1.1、引入依赖1.2、自定义通用批量插入Mapper1.3、把通用方法注册到mybatisplus注入器中1.4、实现InsertList类1.5、需要批量插入的dao层继承批量插入Mapper 二、可能遇到的问题2.1、Invalid bound statement 众所周知,mybatisplus…...

Springboot项目的行为验证码AJ-Captcha(源码解读)
目录 前言1. 复用验证码2. 源码解读2.1 先走DefaultCaptchaServiceImpl类2.2 核心ClickWordCaptchaServiceImpl类 3. 具体使用 前言 对于Java的基本知识推荐阅读: java框架 零基础从入门到精通的学习路线 附开源项目面经等(超全)【Java项目…...

【初阶数据结构篇】时间(空间)复杂度
文章目录 算法复杂度时间复杂度1. 定义2. 表示方法3. 常见时间复杂度4.案例计算分析冒泡排序二分查找斐波那契数列(递归法)斐波那契数列(迭代法) 空间复杂度案例分析冒泡排序斐波那契数列(递归法)斐波那契数…...

C# 设计模式分类
栏目总目录 1. 创建型模式(Creational Patterns) 创建型模式主要关注对象的创建过程,包括如何实例化对象,并隐藏实例化的细节。 单例模式(Singleton):确保一个类只有一个实例,并提…...

前端模块化CommonJS、AMD、CMD、ES6
在前端开发中,模块化是一种重要的代码组织方式,它有助于将复杂的代码拆分成可管理的小块,提高代码的可维护性和可重用性。CommonJS、AMD(异步模块定义)和CMD(通用模块定义)是三种不同的模块规范…...
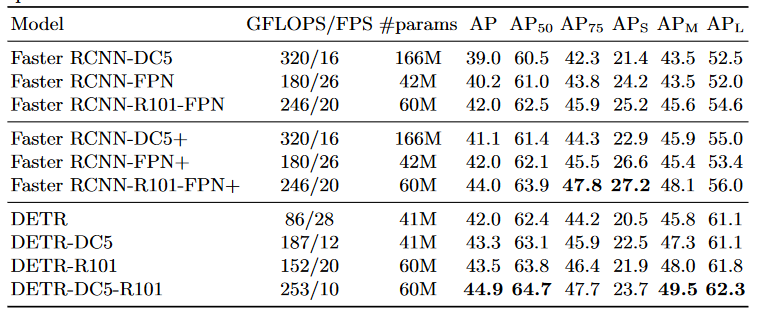
论文阅读:(DETR)End-to-End Object Detection with Transformers
论文阅读:(DETR)End-to-End Object Detection with Transformers 参考解读: 论文翻译:End-to-End Object Detection with Transformers(DETR)[已完结] - 怪盗kid的文章 - 知乎 指示函数&…...

react中路由跳转以及路由传参
一、路由跳转 1.安装插件 npm install react-router-dom 2.路由配置 路由配置:react中简单的配置路由-CSDN博客 3.实现代码 // src/page/index/index.js// 引入 import { Link, useNavigate } from "react-router-dom";function IndexPage() {const …...

C++ STL set_symmetric_difference
一:功能 给定两个集合A,B;求出两个集合的对称差(只属于其中一个集合,而不属于另一个集合的元素),即去除那些同时在A,B中出现的元素。 二:用法 #include <vector>…...

postman请求响应加解密
部分接口,需要请求加密后,在发动到后端。同时后端返回的响应内容,也是经过了加密。此时,我们先和开发获取到对应的【密钥】,然后在postman的预执行、后执行加入js脚本对明文请求进行加密,然后在发送请求&am…...

数据集,批量更新分类数值OR批量删除分类行数据
数据集批量更新分类OR删除分类行数据 import osdef remove_class_from_file(file_path, class_to_remove):"""从YOLO格式的标注文件中删除指定类别的行记录,并去除空行。:param file_path: YOLO标注文件路径:param class_to_remove: 需要删除的类别…...

一款功能强大的视频编辑软件会声会影2023
会声会影2023是一款功能强大的视频编辑软件,由加拿大Corel公司制作,正版英文名称为Corel VideoStudio。它具备图像抓取和编修功能,可以处理和转换多种视频格式,如MV、DV、V8、TV和实时记录抓取画面文件。会声会影提供了…...

政安晨【零基础玩转各类开源AI项目】基于Ubuntu系统部署LivePortrait :通过缝合和重定向控制实现高效的肖像动画制作
目录 项目论文介绍 论文中实际开展的工作 非扩散性的肖像动画 基于扩散的肖像动画 方法论 基于Ubuntu的部署实践开始 1. 克隆代码并准备环境 2. 下载预训练权重 3. 推理 快速上手 驱动视频自动裁剪 运动模板制作 4. Gradio 界面 5. 推理速度评估 社区资源 政安…...

在Spring项目中使用Maven和BCrypt来实现修改密码功能
简介 在数字时代,信息安全的重要性不言而喻,尤其当涉及到个人隐私和账户安全时。每天,无数的用户登录各种在线服务,从社交媒体到银行账户,再到电子邮件和云存储服务。这些服务的背后,是复杂的系统架构&am…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...