大模型微调:参数高效微调(PEFT)方法总结
PEFT (Parameter-Efficient Fine-Tuning) 参数高效微调是一种针对大模型微调的技术,旨在减少微调过程中需要调整的参数量,同时保持或提高模型的性能。
以LORA、Adapter Tuning 和 Prompt Tuning 为主的PEFT方法总结如下

LORA
- 论文题目:LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- 论文链接:https://arxiv.org/pdf/2106.09685
- 发表时间:2021.10.16

含义
一种用于微调大型预训练语言模型(如GPT-3或BERT)的方法。核心思想是在模型的关键层中添加小型、低秩的矩阵来调整模型的行为,而不是直接改变整个模型的结构。
原理
低秩矩阵分解: LoRA通过将权重矩阵分解为两个较低秩的矩阵来减少参数量。具体来说,对于模型中的某个权重矩阵 W,LoRA将其表示为两个较小的矩阵 A 和 B,使得 W≈A×B。这样可以有效地减少需要更新的参数数量。
保持预训练权重不变: LoRA保留了预训练模型的原始权重,并在此基础上进行调整。通过添加低秩更新矩阵 ΔW=A×B 到原始权重矩阵 W,来得到新的权重矩阵 W′=W+ΔW。这种方法允许模型在保留预训练知识的同时,适应新的任务。
Adapter Tuning
- 论文题目:Parameter-Efficient Transfer Learning for NLP
- 论文链接:https://arxiv.org/pdf/1902.00751
- 发表时间:2019.6.13

含义
通过在预训练模型的基础上添加适配器层(adapters),来实现特定任务的微调。这种方法旨在保留预训练模型的原始权重,仅在需要适应新任务的地方进行小规模的参数调整。
原理
插入适配器层: 在预训练模型的特定位置(通常是在每个 Transformer 层的内部或后面)插入适配器层。
适配器层结构: 这些适配器层是一些小规模的神经网络,通常由一个下采样层(减少维度)、一个激活函数(如 ReLU)和一个上采样层(恢复维度)组成。
冻结预训练权重: 在微调过程中,预训练模型的原始权重保持不变,仅训练适配器层的权重。
高效微调: 由于适配器层的参数数量相对较少,微调过程变得更加高效。适配器层可以针对不同任务进行训练,而不影响预训练模型的核心结构。
Prompt Tuning
- 论文题目:The Power of Scale for Parameter-Efficient Prompt Tuning
- 论文链接:https://arxiv.org/pdf/2104.08691
- 发表时间:2021.9.2
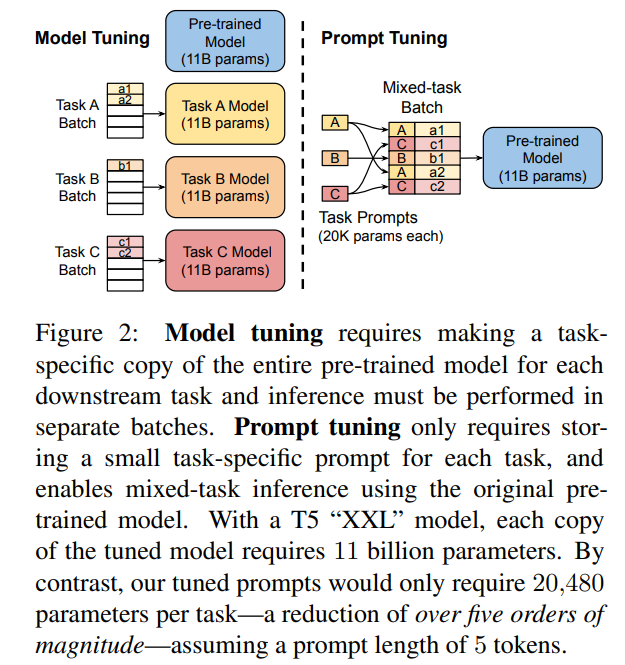
含义
在预训练语言模型的输入中添加可学习的嵌入向量作为提示。其核心思想是通过引入任务特定的提示(prompts),而非对整个模型进行全参数更新,从而实现对模型的高效微调
原理
设计提示词: 输入提示(prompt)通常包含任务描述、示例或特定的输入格式。例如,对于情感分类任务,可以设计一个提示词:“这段文字的情感是:”。
优化提示词: Prompt Tuning 的优化对象是输入提示的词嵌入(embedding)。通过梯度下降等优化算法,调整提示词的词嵌入,使得模型在特定任务上的表现达到最优。
冻结预训练模型: 在 Prompt Tuning 中,预训练模型的权重保持不变,仅优化提示词的嵌入。
Prefix-Tuning
- 论文题目:Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 论文链接:https://arxiv.org/pdf/2101.00190
- 发表时间:2021.1.1
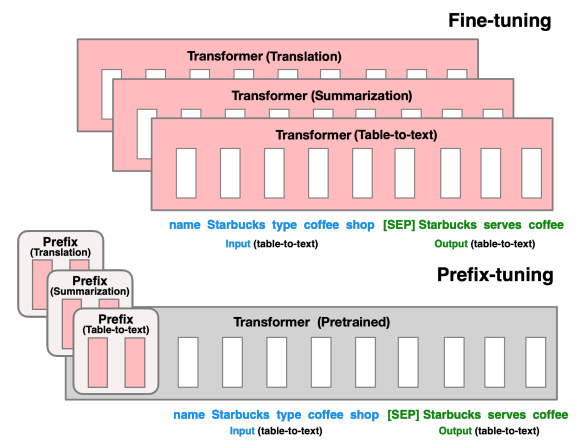
含义
通过固定预训练模型的参数,仅在输入序列的前面添加一个可训练的前缀(prefix),从而在不改变模型参数的情况下实现特定任务的适应
原理
固定模型参数: 不对预训练语言模型(如 GPT-3、BERT 等)的参数进行微调
添加可训练前缀: 在输入序列的前面添加一个可训练的前缀向量。这个前缀向量的长度和维度可以根据具体任务进行调整
任务适应: 在实际应用中,前缀向量与输入序列一起输入到预训练模型中。由于前缀向量是可训练的,模型可以通过调整前缀向量来适应特定的任务,而无需改变模型本身的参数。
P-Tuning
-
论文题目:GPT Understands, Too
-
论文链接:https://arxiv.org/pdf/2103.10385v1
-
发表时间:2021.3.18
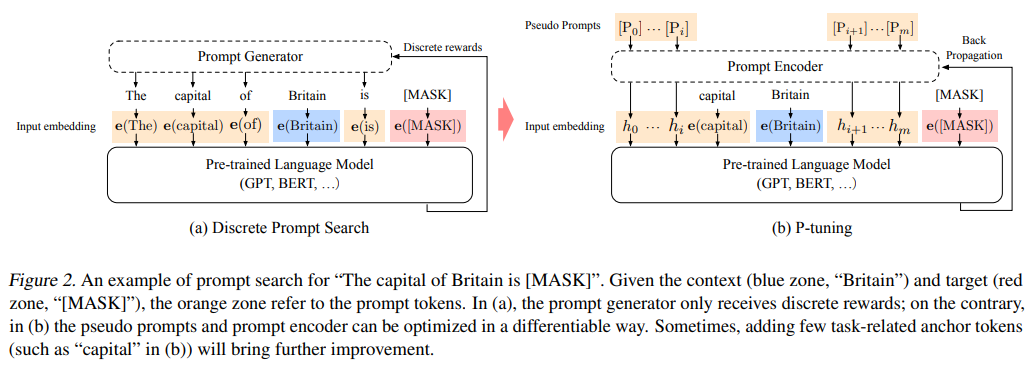
含义
在模型输入中插入一些可训练的提示(prompts),这些提示是嵌入向量(embedding vectors),在训练过程中被优化
原理
固定模型参数: 和 Prefix-Tuning 类似,不改模型参数
插入可训练提示: 在输入序列的适当位置插入一些可训练的提示向量。
任务适应: 在训练过程中,这些提示向量与输入序列一起输入到预训练模型中
P-Tuning V2
- 论文题目:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- 论文链接:https://arxiv.org/pdf/2110.07602v2
- 发表时间:2021.10.18
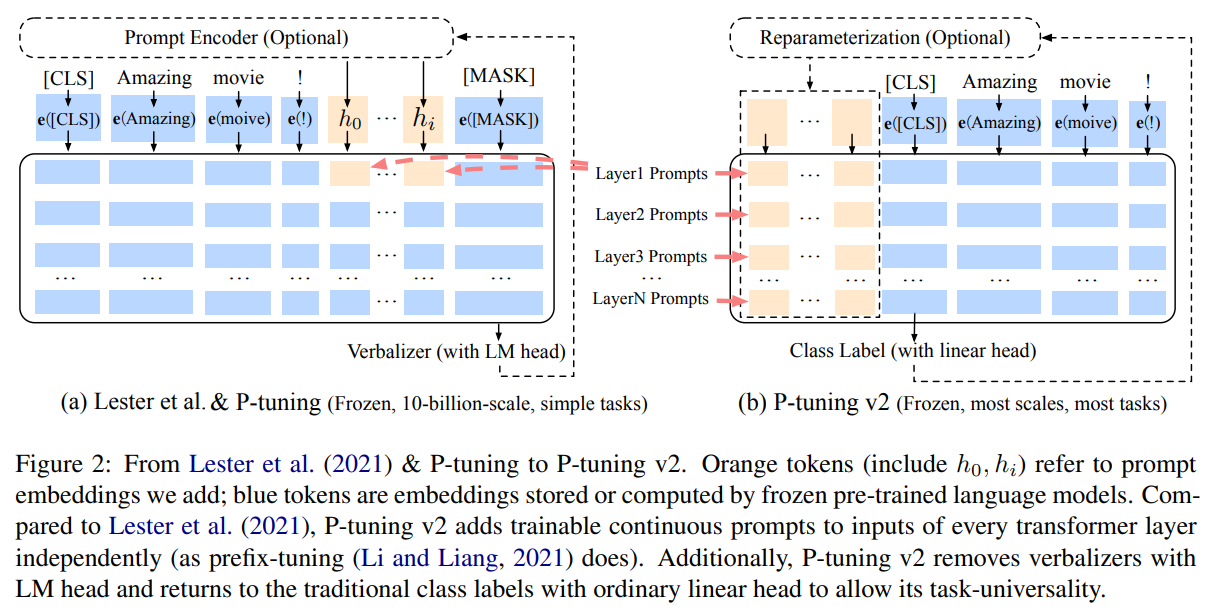
含义
保留了 P-Tuning 的核心思想,即通过优化输入提示向量来引导预训练模型处理特定任务
原理
相比较于P-Tuning:
动态提示优化: 采用动态提示优化方法
多层提示插入: P-Tuning V2 不仅在输入序列的前面插入提示向量,还在模型的不同层次(如中间层)插入提示向量
BitFit
- 论文题目:BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
- 论文链接:https://arxiv.org/abs/2106.10199
- 发表时间:2021.6.18
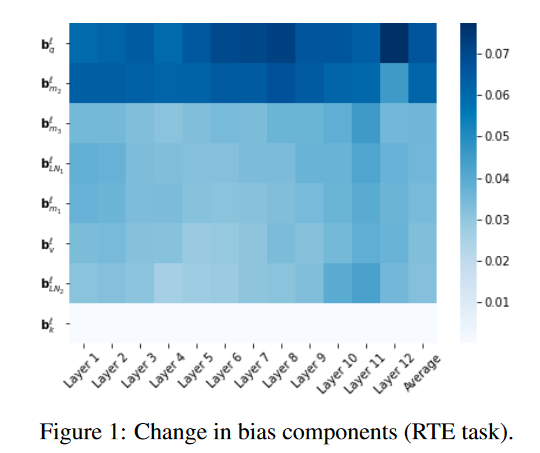
含义
通过仅微调模型的偏置参数来适应新的任务,从而减少了需要调整的参数量。
原理
-
原始 BERT 模型:包含多层 Transformer,每层有权重矩阵 W 和偏置 b。
-
BitFit 微调:保持所有权重矩阵 W 不变,只微调每层的偏置参数 b
DistilBERT
- 论文题目:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- 论文链接:https://arxiv.org/abs/1910.01108
- 发表时间:2020.3.1
含义
使用知识蒸馏技术将大模型压缩成更小的模型,从而减少微调所需的计算资源和时间。
原理
知识蒸馏是一种模型压缩技术,通过训练一个较小的学生模型(student model)来模仿较大教师模型(teacher model)的行为。具体步骤如下:
- 教师模型:使用预训练的 BERT 模型作为教师模型。
- 学生模型:构建一个较小的 BERT 模型,即 DistilBERT。
- 训练过程:在训练过程中,学生模型通过模仿教师模型的输出来学习。损失函数不仅包括学生模型和教师模型输出之间的差异,还包括学生模型和真实标签之间的差异。> PEFT (Parameter-Efficient Fine-Tuning) 参数高效微调是一种针对大模型微调的技术,旨在减少微调过程中需要调整的参数量,同时保持或提高模型的性能。
以LORA、Adapter Tuning 和 Prompt Tuning 为主的PEFT方法总结如下

LORA
- 论文题目:LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- 论文链接:https://arxiv.org/pdf/2106.09685
- 发表时间:2021.10.16
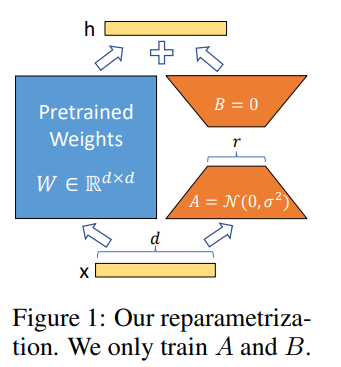
含义
一种用于微调大型预训练语言模型(如GPT-3或BERT)的方法。核心思想是在模型的关键层中添加小型、低秩的矩阵来调整模型的行为,而不是直接改变整个模型的结构。
原理
低秩矩阵分解: LoRA通过将权重矩阵分解为两个较低秩的矩阵来减少参数量。具体来说,对于模型中的某个权重矩阵 W,LoRA将其表示为两个较小的矩阵 A 和 B,使得 W≈A×B。这样可以有效地减少需要更新的参数数量。
保持预训练权重不变: LoRA保留了预训练模型的原始权重,并在此基础上进行调整。通过添加低秩更新矩阵 ΔW=A×B 到原始权重矩阵 W,来得到新的权重矩阵 W′=W+ΔW。这种方法允许模型在保留预训练知识的同时,适应新的任务。
Adapter Tuning
- 论文题目:Parameter-Efficient Transfer Learning for NLP
- 论文链接:https://arxiv.org/pdf/1902.00751
- 发表时间:2019.6.13
含义
通过在预训练模型的基础上添加适配器层(adapters),来实现特定任务的微调。这种方法旨在保留预训练模型的原始权重,仅在需要适应新任务的地方进行小规模的参数调整。
原理
插入适配器层: 在预训练模型的特定位置(通常是在每个 Transformer 层的内部或后面)插入适配器层。
适配器层结构: 这些适配器层是一些小规模的神经网络,通常由一个下采样层(减少维度)、一个激活函数(如 ReLU)和一个上采样层(恢复维度)组成。
冻结预训练权重: 在微调过程中,预训练模型的原始权重保持不变,仅训练适配器层的权重。
高效微调: 由于适配器层的参数数量相对较少,微调过程变得更加高效。适配器层可以针对不同任务进行训练,而不影响预训练模型的核心结构。
Prompt Tuning
- 论文题目:The Power of Scale for Parameter-Efficient Prompt Tuning
- 论文链接:https://arxiv.org/pdf/2104.08691
- 发表时间:2021.9.2
含义
在预训练语言模型的输入中添加可学习的嵌入向量作为提示。其核心思想是通过引入任务特定的提示(prompts),而非对整个模型进行全参数更新,从而实现对模型的高效微调
原理
设计提示词: 输入提示(prompt)通常包含任务描述、示例或特定的输入格式。例如,对于情感分类任务,可以设计一个提示词:“这段文字的情感是:”。
优化提示词: Prompt Tuning 的优化对象是输入提示的词嵌入(embedding)。通过梯度下降等优化算法,调整提示词的词嵌入,使得模型在特定任务上的表现达到最优。
冻结预训练模型: 在 Prompt Tuning 中,预训练模型的权重保持不变,仅优化提示词的嵌入。
Prefix-Tuning
- 论文题目:Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 论文链接:https://arxiv.org/pdf/2101.00190
- 发表时间:2021.1.1
含义
通过固定预训练模型的参数,仅在输入序列的前面添加一个可训练的前缀(prefix),从而在不改变模型参数的情况下实现特定任务的适应
原理
固定模型参数: 不对预训练语言模型(如 GPT-3、BERT 等)的参数进行微调
添加可训练前缀: 在输入序列的前面添加一个可训练的前缀向量。这个前缀向量的长度和维度可以根据具体任务进行调整
任务适应: 在实际应用中,前缀向量与输入序列一起输入到预训练模型中。由于前缀向量是可训练的,模型可以通过调整前缀向量来适应特定的任务,而无需改变模型本身的参数。
P-Tuning
-
论文题目:GPT Understands, Too
-
论文链接:https://arxiv.org/pdf/2103.10385v1
-
发表时间:2021.3.18
含义
在模型输入中插入一些可训练的提示(prompts),这些提示是嵌入向量(embedding vectors),在训练过程中被优化
原理
固定模型参数: 和 Prefix-Tuning 类似,不改模型参数
插入可训练提示: 在输入序列的适当位置插入一些可训练的提示向量。
任务适应: 在训练过程中,这些提示向量与输入序列一起输入到预训练模型中
P-Tuning V2
- 论文题目:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- 论文链接:https://arxiv.org/pdf/2110.07602v2
- 发表时间:2021.10.18
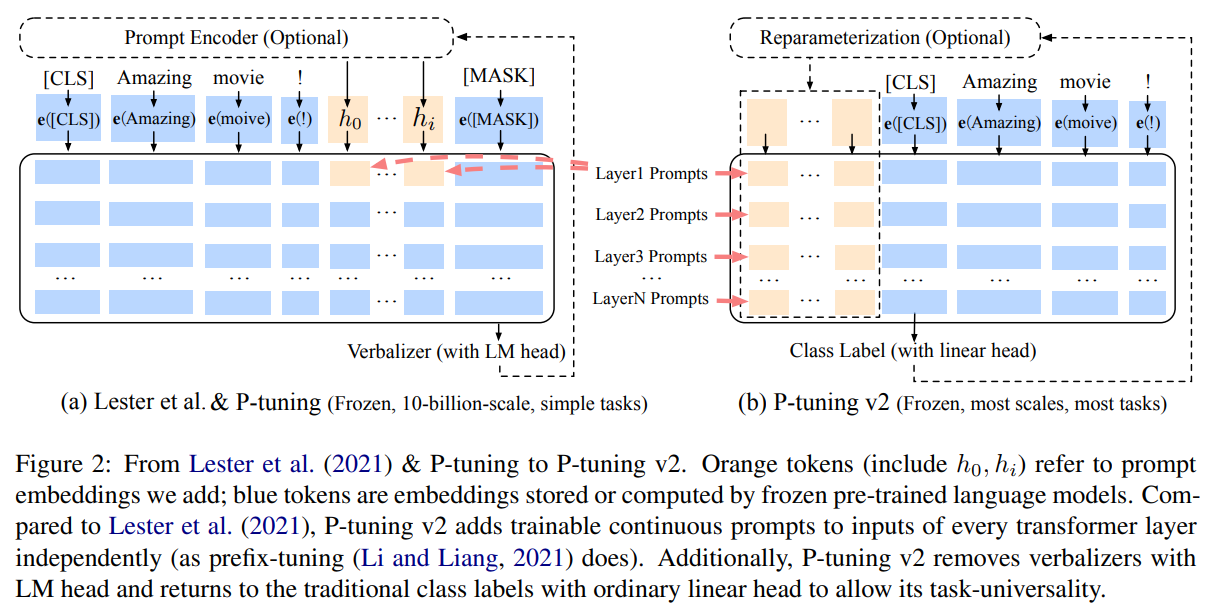
含义
保留了 P-Tuning 的核心思想,即通过优化输入提示向量来引导预训练模型处理特定任务
原理
相比较于P-Tuning:
动态提示优化: 采用动态提示优化方法
多层提示插入: P-Tuning V2 不仅在输入序列的前面插入提示向量,还在模型的不同层次(如中间层)插入提示向量
BitFit
- 论文题目:BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
- 论文链接:https://arxiv.org/abs/2106.10199
- 发表时间:2021.6.18
含义
通过仅微调模型的偏置参数来适应新的任务,从而减少了需要调整的参数量。
原理
-
原始 BERT 模型:包含多层 Transformer,每层有权重矩阵 W 和偏置 b。
-
BitFit 微调:保持所有权重矩阵 W 不变,只微调每层的偏置参数 b
DistilBERT
- 论文题目:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- 论文链接:https://arxiv.org/abs/1910.01108
- 发表时间:2020.3.1
含义
使用知识蒸馏技术将大模型压缩成更小的模型,从而减少微调所需的计算资源和时间。
原理
知识蒸馏是一种模型压缩技术,通过训练一个较小的学生模型(student model)来模仿较大教师模型(teacher model)的行为。具体步骤如下:
- 教师模型:使用预训练的 BERT 模型作为教师模型。
- 学生模型:构建一个较小的 BERT 模型,即 DistilBERT。
- 训练过程:在训练过程中,学生模型通过模仿教师模型的输出来学习。损失函数不仅包括学生模型和教师模型输出之间的差异,还包括学生模型和真实标签之间的差异。
相关文章:
大模型微调:参数高效微调(PEFT)方法总结
PEFT (Parameter-Efficient Fine-Tuning) 参数高效微调是一种针对大模型微调的技术,旨在减少微调过程中需要调整的参数量,同时保持或提高模型的性能。 以LORA、Adapter Tuning 和 Prompt Tuning 为主的PEFT方法总结如下 LORA 论文题目:LORA:…...

Spark+实例解读
第一部分 Spark入门 学习教程:Spark 教程 | Spark 教程 Spark 集成了许多大数据工具,例如 Spark 可以处理任何 Hadoop 数据源,也能在 Hadoop 集群上执行。大数据业内有个共识认为,Spark 只是Hadoop MapReduce 的扩展(…...

WPF多语言国际化,中英文切换
通过切换资源文件的形式实现中英文一键切换 在项目中新建Language文件夹,添加资源字典(xaml文件),中文英文各一个。 在资源字典中写上想中英文切换的字符串,需要注意,必须指定key值,并且中英文…...
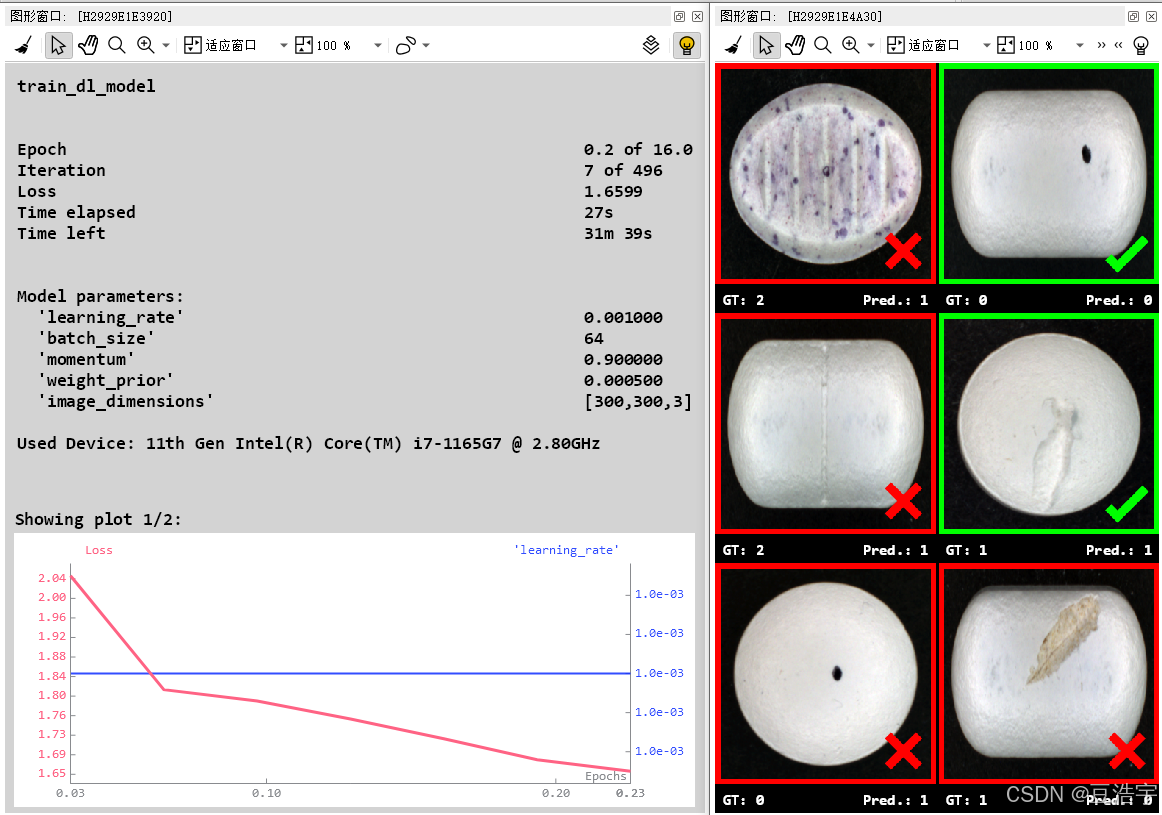
Halcon深度学习分类模型
1.Halcon20之后深度学习支持CPU训练模型,没有money买显卡的小伙伴有福了。但是缺点也很明显,就是训练速度超级慢,推理效果也没有GPU好,不过学习用足够。 2.分类模型是Halcon深度学习最简单的模型,可以用在物品分类&…...

洗地机哪种牌子好?洗地机排行榜前十名公布
洗地机市场上品牌琳琅满目,每个品牌都有其独特的魅力和优势。消费者在选择时,往往会根据自己的实际需求、预算以及对产品性能的期望来做出决策。因此,无论是哪个品牌的洗地机,只要能够满足用户的清洁需求,提供便捷的操…...

C++中的虚函数与多态机制如何工作?
在C中,虚函数和多态机制是实现面向对象编程的重要概念。 虚函数是在基类中声明的函数,可以在派生类中进行重写。当基类的指针或引用指向派生类的对象时,通过调用虚函数可以实现动态绑定,即在运行时确定要调用的函数。 多态是指通…...

《LeetCode热题100》---<哈希三道>
本篇博客讲解 LeetCode热题100道中的哈希篇中的三道题。分别是 1.第一道:两数之和(简单) 2.第二道:字母异位词分组(中等) 3.第三道:最长连续序列(中等) 第一道࿱…...
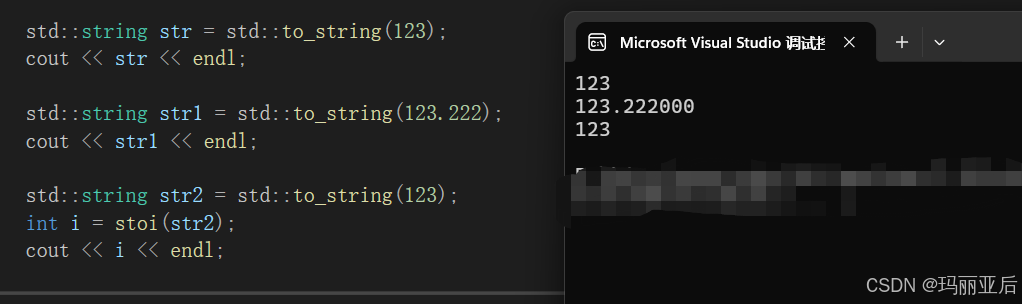
秒懂C++之string类(下)
目录 一.接口说明 1.1 erase 1.2 replace(最好别用) 1.3 find 1.4 substr 1.5 rfind 1.6 find_first_of 1.7 find_last_of 二.string类的模拟实现 2.1 构造 2.2 无参构造 2.3 析构 2.4.【】运算符 2.5 迭代器 2.6 打印 2.7 reserve扩容 …...
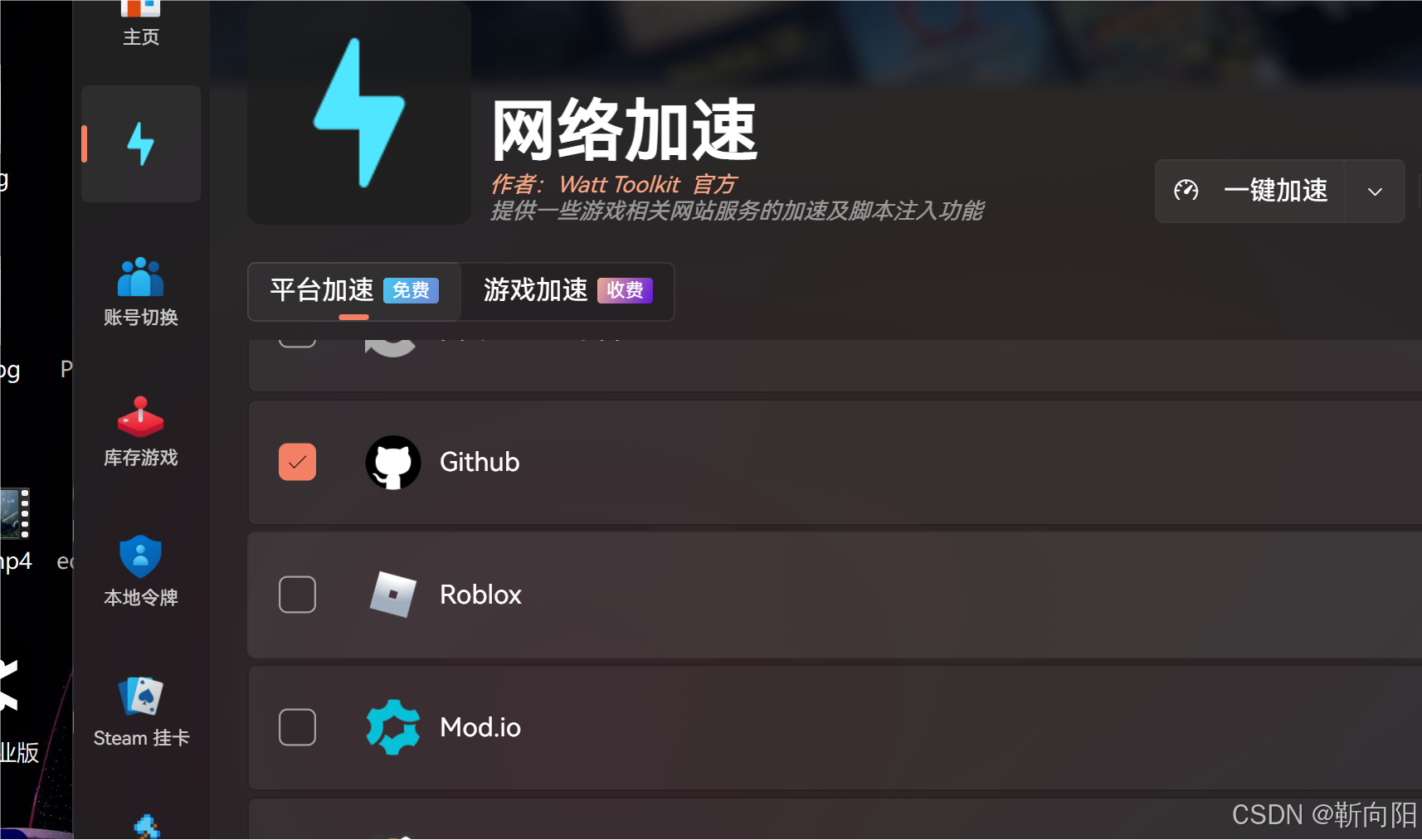
github简单地操作
1.调节字体大小 选择options 选择text 选择select 选择你需要的参数就可以了。 2.配置用户名和邮箱 桌面右键,选择git Bash Here git config --global user.name 用户名 git config --global user.email 邮箱名 3.用git实现代码管理的过程 下载别人的项目 git …...

模型改进-损失函数合集
模版 第一步在哪些地方做出修改: 228行 self.use_wiseiouTrue 230行 self.wiou_loss WiseIouLoss(ltypeMPDIoU, monotonousFalse, inner_iouTrue, focaler_iouFalse) 238行 wiou self.wiou_loss(pred_bboxes[fg_mask], target_bboxes[fg_mask], ret_iouFalse…...
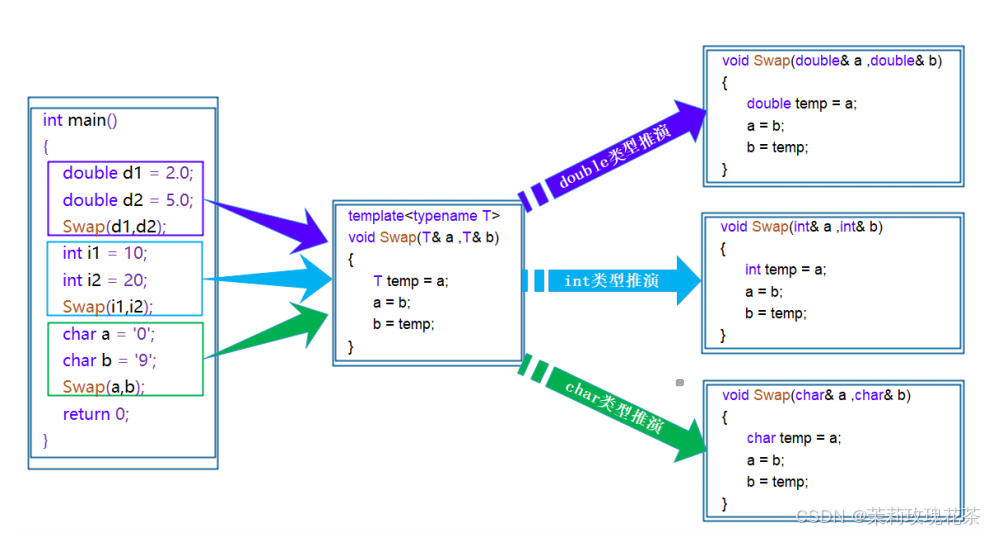
C++模板(初阶)
1.引入 在之前的笔记中有提到:函数重载(特别是交换函数(Swap)的实现) void Swap(int& left, int& right) {int temp left;left right;right temp; } void Swap(double& left, double& right) {do…...

下面关于Date类的描述错误的一项是?
下面关于Date类的描述错误的一项是? A. java.util.Date类下有三个子类:java.sql.Date、java.sql.Timestamp、java.sql.Time; B. 利用SimpleDateFormat类可以对java.util.Date类进行格式化显示; C. 直接输出Date类对象就可以取得日…...
【Python面试题收录】Python编程基础练习题①(数据类型+函数+文件操作)
本文所有代码打包在Gitee仓库中https://gitee.com/wx114/Python-Interview-Questions 一、数据类型 第一题(str) 请编写一个Python程序,完成以下任务: 去除字符串开头和结尾的空格。使用逗号(","&#…...
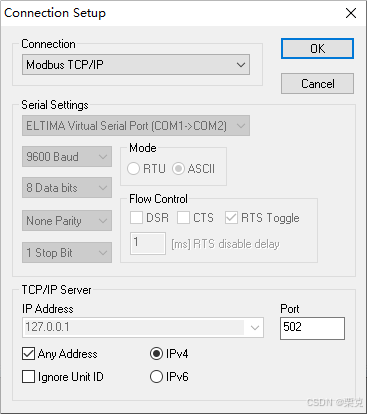
C# Nmodbus,EasyModbusTCP读写操作
Nmodbus读写 两个Button控件分别为 读取和写入 分别使用控件的点击方法 ①引用第三方《NModbus4》2.1.0版本 全局 public SerialPort port new SerialPort("COM2", 9600, Parity.None, 8, (StopBits)1); ModbusSerialMaster master; public Form1() port.Open();…...

spark常用参数调优
目录 1.set spark.grouping.sets.reference.hivetrue;2.set spark.locality.wait.rack0s3.set spark.locality.wait0s;4.set spark.executor.memoryOverhead 2G;5.set spark.sql.shuffle.partitions 1000;6.set spark.shuffle.file.buffer 256k7. set spark.reducer.maxSizeInF…...
C#/WinFrom TCP通信+ 网线插拔检测+客服端异常掉线检测
Winfor Tcp通信(服务端) 今天给大家讲一下C# 关于Tcp 通信部分,这一块的教程网上一大堆,不过关于掉网,异常断开连接的这部分到是到是没有多少说明,有方法 不过基本上最多的两种方式(1.设置一个超时时间,2.…...

一篇文章掌握Python爬虫的80%
转载:一篇文章掌握Python爬虫的80% Python爬虫 Python 爬虫技术在数据采集和信息获取中有着广泛的应用。本文将带你掌握Python爬虫的核心知识,帮助你迅速成为一名爬虫高手。以下内容将涵盖爬虫的基本概念、常用库、核心技术和实战案例。 一、Python 爬虫…...

【用户会话信息在异步事件/线程池的传递】
用户会话信息在异步事件/线程池的传递 author:shengfq date:2024-07-29 version:1.0 背景: 同事写的一个代码功能,是在一个主线程中通过如下代码进行异步任务的执行,结果遇到了问题. 1.ThreadPool.execute(Runnable)启动一个子线程执行异步任务 2.applicationContext.publis…...

Java8: BigDecimal
Java8:BigDecimal 转两位小数的百分数-CSDN博客 BigDecimal 先做除法 然后取绝对值 在Java 8中,如果你想要对一个BigDecimal值进行除法操作,并随后取其绝对值,你可以通过组合divide方法和abs方法来实现这一目的。不过,需要注意的…...

苹果推送iOS 18.1带来Apple Intelligence预览
🦉 AI新闻 🚀 苹果推送iOS 18.1带来Apple Intelligence预览 摘要:苹果向iPhone和iPad用户推送iOS 18.1和iPadOS 18.1开发者预览版Beta更新,带来“Apple Intelligence”预览。目前仅支持M1芯片或更高版本的设备。Apple Intellige…...

PyTorch模型参数管理:从torch.nn.Parameter到高效训练实践
1. 理解torch.nn.Parameter的本质 第一次接触PyTorch的torch.nn.Parameter时,我也曾困惑它和普通Tensor的区别。直到在实际项目中踩了几个坑,才真正明白它的价值。让我们从一个简单的例子开始: import torch import torch.nn as nn# 普通Te…...

Unlock Music:3种创新用法让你重新掌控被加密的音乐收藏
Unlock Music:3种创新用法让你重新掌控被加密的音乐收藏 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: htt…...

如何快速上手Unitree Go2 ROS2 SDK:模块化机器人开发完整指南
如何快速上手Unitree Go2 ROS2 SDK:模块化机器人开发完整指南 【免费下载链接】go2_ros2_sdk Unofficial ROS2 SDK support for Unitree GO2 AIR/PRO/EDU 项目地址: https://gitcode.com/gh_mirrors/go/go2_ros2_sdk Unitree Go2 ROS2 SDK是为宇树科技GO2系列…...

三菱FX3U串口通讯无协议编程与RS指令实现Modbus协议
引言 在工业自动化系统中,PLC与上位机之间的通讯至关重要。Modbus RTU协议 作为一种广泛应用的通讯协议,通常用于不同设备之间的数据交换。 对于三菱 FX3U系列PLC 来说,虽然它没有直接内置完整的Modbus RTU从站功能(早期型号需通过…...
服务启停、远程连接与基础排查)
国产化服务器运维笔记:手把手搞定MariaDB/PostgreSQL(瀚高)服务启停、远程连接与基础排查
国产化环境数据库运维实战:MariaDB与瀚高数据库深度管理指南 在信息技术应用创新背景下,国产服务器与开源数据库的组合已成为企业基础架构的重要选择。面对复杂的生产环境,掌握数据库服务的精细化管理能力,是每位运维工程师的必备…...

Visual C++运行库全家桶:一站式解决Windows软件兼容性问题的终极方案
Visual C运行库全家桶:一站式解决Windows软件兼容性问题的终极方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还在为"应用程序无法启动&qu…...

ClawX:桌面化AI Agent编排平台,降低OpenClaw使用门槛
1. 项目概述:ClawX,为OpenClaw AI Agent打造的桌面门户如果你和我一样,对AI Agent(智能体)的潜力感到兴奋,但又对在终端里敲命令、编辑YAML配置文件、管理进程这些繁琐操作感到头疼,那么ClawX的…...

如何高效配置智能游戏助手:绝区零一条龙完整使用攻略
如何高效配置智能游戏助手:绝区零一条龙完整使用攻略 【免费下载链接】ZenlessZoneZero-OneDragon 绝区零 一条龙 | 全自动 | 自动闪避 | 自动每日 | 自动空洞 | 支持手柄 项目地址: https://gitcode.com/gh_mirrors/ze/ZenlessZoneZero-OneDragon 还在为《绝…...
--CubeMX配置说明)
基于STM32HAL库的平衡小车设计(二)--CubeMX配置说明
项目开源链接 本项目资料完全开源。资料包获取方式: github : https://github.com/snqx-lqh/ProjectReleasePage gitee(国内镜像) :https://gitee.com/snqx-lqh/ProjectOpenSourceReleasePage。 项目属于 32 的编号 B005 ,在发…...

SecureVault - 基于新范式的Windows文件加密工具
前言作为一个常年和各种文件打交道的普通人,我一直有个困扰:现有的加密工具要么太复杂,要么太贵,要么用的都是几十年的老算法。我想,能不能做一款简单、便宜、但加密方式完全不同的新工具?于是就有了 Secur…...