使用 Python 制作一个属于自己的 AI 搜索引擎
1. 使用到技术
- OpenAI KEY
- Serper KEY
- Bing Search
2. 原理解析
使用Google和Bing的搜搜结果交由OpenAI处理并给出回答。
3. 代码实现
import requests
from lxml import etree
import os
from openai import OpenAI# 从环境变量中加载 API 密钥
os.environ["OPENAI_API_KEY"] = "sk-xxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
os.environ["SERPER_API_KEY"] = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# 确保在执行代码前已经设置了环境变量
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
SERPER_API_KEY = os.getenv("SERPER_API_KEY")def search_bing(query):headers = {'Referer': 'https://www.bing.com/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36',}params = {'q': query,'mkt': 'zh-CN'}response = requests.get('https://www.bing.com/search', params=params, headers=headers)html = etree.HTML(response.text)li_list = html.xpath("//li[@class='b_algo']")result = []for index in range(len(li_list)):title = ";".join(li_list[index].xpath("./h2/a/text()"))link = li_list[index].xpath("./h2/a/@href")[0]snippet = ";".join(li_list[index].xpath("./div/p/text()"))position = indexprint(title, link, snippet, position)result.append({'title': title,'link': link,'snippet': snippet,'position': position,})return resultdef search_serper(query):"""使用Serper API进行搜索并返回结果。"""url = "https://google.serper.dev/search"headers = {"X-API-KEY": SERPER_API_KEY,"Content-Type": "application/json",}params = {'q': query,'gl': "cn",'hl': "zh-cn",}try:response = requests.post(url, headers=headers, json=params)response.raise_for_status() # 检查HTTP请求状态serper_data = response.json()if not serper_data:return "无法获取搜索结果", []google_context = serper_data.get('organic', [])google_other = serper_data.get('relatedSearches', [])return google_context, google_otherexcept requests.RequestException as e:print(f"请求失败: {e}")return Nonedef search_openai(query, context):"""利用OpenAI API回答问题并引用相关上下文,并使用流的方式输出。"""context_template = ("你是GinLynn构建的大型语言AI助手。给你一个用户问题,请正确、简洁、准确的讲述这个问题的答案。""你会得到一组与问题相关的上下文,其中每个对象都是一个json字符串,""'snippet'字段表示片段,'title'字段表示标题,'link'字段表示链接,'position'字段表示位置。""请使用这些上下文并在每个句子的末尾引用上下文(如果适用)。""你的答案必须是正确、准确的,由专家以公正和专业的语气撰写。请限制为2048token。""不要给出任何与问题无关的信息,也不要重复。如果给定的上下文没有提供足够的信息,""那么在相关主题后面加上“information is missing on”。请以[position]的格式注明出处和参考编号。""以下是一组上下文:")client = OpenAI(api_key=OPENAI_API_KEY)try:completion = client.chat.completions.create(model="gpt-4o",messages=[{"role": "system", "content": context_template + context},{"role": "user", "content": query}],stream=True # 启用流式响应)# 逐条打印流式输出的结果for chunk in completion:if chunk.choices[0].delta.content is not None:print(chunk.choices[0].delta.content, end="")print() # 输出换行return "完成输出"except Exception as e:print(f"OpenAI API request failed: {e}")return "无法完成请求", []if __name__ == '__main__':query = input("请输入查询: ")if query.strip() == "":query = "最新俄乌局势信息"print("正在搜索...")serper_context, other_queries = search_serper(query)bing_context = search_bing(query)context = []if bing_context:context.extend(bing_context)if serper_context:# 为Serper上下文的每个条目重置 position 值,以防止重复for index, item in enumerate(serper_context, start=len(bing_context)):item['position'] = index # 从当前Bing结果的数量开始context.extend(serper_context)print("搜索结果:", context)search_openai(query, str(context))if other_queries:print("相关搜索:", other_queries)4. 运行结果

相关文章:
使用 Python 制作一个属于自己的 AI 搜索引擎
1. 使用到技术 OpenAI KEYSerper KEYBing Search 2. 原理解析 使用Google和Bing的搜搜结果交由OpenAI处理并给出回答。 3. 代码实现 import requests from lxml import etree import os from openai import OpenAI# 从环境变量中加载 API 密钥 os.environ["OPENAI_AP…...

rust读取csv文件,匹配搜索字符
1.代码 use std::fs::File; use std::io::{BufRead, BufReader}; use regex::{Regex};fn main() {let f File::open("F:\\0-X-RUST\\1-systematic\\ch2-fileRead\\data\\test.csv").unwrap();let mut reader BufReader::new(f);let re Regex::new("45asd&qu…...

隐藏采购订单类型
文章目录 1 Introduction2 code 1 Introduction The passage is that how to hiden purchase type . 2 code DATA: ls_shlp_selopt TYPE ddshselopt. IF ( sy-tcode ME21N OR sy-tcode ME22N OR sy-tcode ME23N or sy-tcode ME51N OR sy-tcode ME52N OR sy-tcode ME5…...

ESP32人脸识别开发- 基础介绍(一)
一、ESP32人脸识别的方案介绍 目前ESP32和ESP32S3都是支持的,官方推的开发板有两种,一种 ESP-EYE ,没有LCD 另一种是ESP32S3-EYE,有带LCD屏 二、ESP32人脸识别选用ESP32的优势 ESP32S3带AI 加速功能,在人脸识别的速度是比ESP32快了不少 | S…...

编程学习指南:语言选择、资源推荐与高效学习策略
目录 一、编程语言选择 1. Java:广泛应用的基石 2. C/C:深入底层的钥匙 3. Python:AI与大数据的宠儿 4. Web前端技术:构建交互界面的艺术 二、学习资源推荐 1. 国内外在线课程平台 2. 官方文档与教程 3. 书籍与电子书 4…...

AWS开发人工智能:如何基于云进行开发人工智能AI
随着人工智能技术的飞速发展,企业对高效、易用的AI服务需求日益增长。Amazon Bedrock是AWS推出的一项创新服务,旨在为企业提供一个简单、安全的平台,以访问和集成先进的基础模型。本文中九河云将详细介绍Amazon Bedrock的功能特点以及其收费方…...

CentOS 8 的 YUM 源替换为国内的镜像源
CentOS 8 的 YUM 源替换为国内的镜像源 1.修改 DNS 为 114.114.114.1141.编辑 /etc/resolv.conf 文件:2.在文件中添加或修改如下内容:3.保存并退出编辑器。 2.修改 YUM 源为国内镜像1.备份原有的 YUM 源配置:2.下载新的 YUM 源配置3.清理缓存…...

网络安全入门教程(非常详细)从零基础入门到精通_网路安全 教程
前言 1.入行网络安全这是一条坚持的道路,三分钟的热情可以放弃往下看了。2.多练多想,不要离开了教程什么都不会了,最好看完教程自己独立完成技术方面的开发。3.有时多百度,我们往往都遇不到好心的大神,谁会无聊天天给…...

浅学爬虫-爬虫维护与优化
在实际项目中,爬虫的稳定性和效率至关重要。通过错误处理与重试机制、定时任务以及性能优化,可以确保爬虫的高效稳定运行。下面我们详细介绍这些方面的技巧和方法。 错误处理与重试机制 在爬虫运行过程中,网络不稳定、目标网站变化等因素可…...

STM32G070系列芯片擦除、写入Flash错误解决
在用G070KBT6芯片调用HAL_FLASHEx_Erase(&EraseInitStruct, &PageError)时,调试发现该函数返回HAL_ERROR,最后定位到FLASH_WaitForLastOperation(FLASH_TIMEOUT_VALUE)函数出现错误,pFlash.ErrorCode为0xA0,即FLASH错误标…...

08.02_111期_Linux_NAT技术
NAT(network address translation)技术说明 IP报文在转发的时候需要考虑 源IP地址 和 目的IP地址, IP报文每到达一个节点,就会更改一次IP地址和目的IP地址,其中节点是指主机、服务器、路由器 那么这个更改是如何进行的呢? 除了…...

【2024蓝桥杯/C++/B组/小球反弹】
题目 分析 Sx 2 * k1 * x; Sy 2 * k2 * y; (其中k1, k2为整数) Vx * t Sx; Vy * t Sy; k1 / k2 (15 * y) / (17 * x); 目标1:根据k1与k2的关系,找出一组最小整数组(k1, k2)ÿ…...

PHP中如何实现函数的可变参数列表
在PHP中,实现函数的可变参数列表主要有两种方式:使用func_get_args()函数和使用可变数量的参数(通过...操作符,自PHP 5.6.0起引入)。 1. 使用func_get_args()函数 func_get_args()函数用于获取传递给函数的参数列表&…...

串---链串实现
链串详解 本文档将详细介绍链串的基本概念、实现原理及其在 C 语言中的具体应用。通过本指南,读者将了解如何使用链串进行各种字符串操作。 1. 什么是链串? 链串是一种用于存储字符串的数据结构,它使用一组动态分配的节点来保存字符串中的…...

科技赋能生活——便携气象站
传统气象站往往庞大而复杂,需要专业人员维护,它小巧玲珑,设计精致,可以轻松放入背包或口袋,随身携带,不占空间。无论是城市白领穿梭于高楼大厦间,还是户外爱好者深入山林湖海,都能随…...

Golang——GC原理
1.垃圾回收的目的 将未被引用到的对象销毁,回收其所占的内存空间。 2.根对象是什么 全局变量:在编译器就能确定的存在于程序整个生命周期的变量。 执行栈:每个goroutine都包含自己的执行栈,这些执行栈上包含栈上的变量及指向分配…...
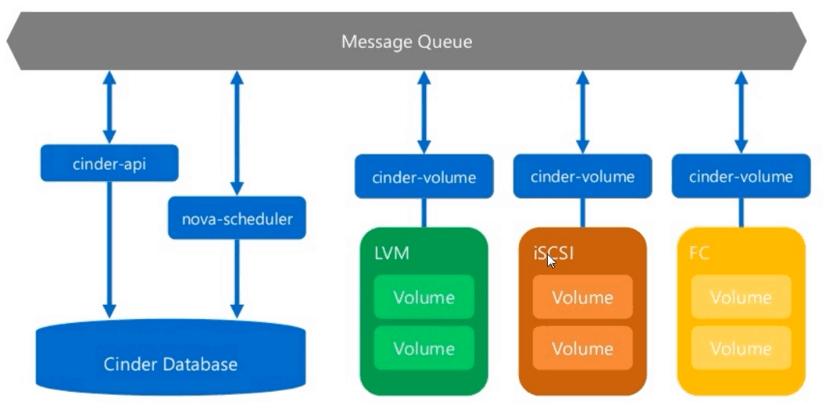
OpenStack概述
一、初识OpenStack OpenStack Docs: 概况 一)OpenStack架构简述 1、理解OpenStack OpenStack既是一个社区,也是一个项目和一个开源软件,提供开放源码软件,建立公共和私有云,它提供了一个部署云的操作平台或工具集&…...
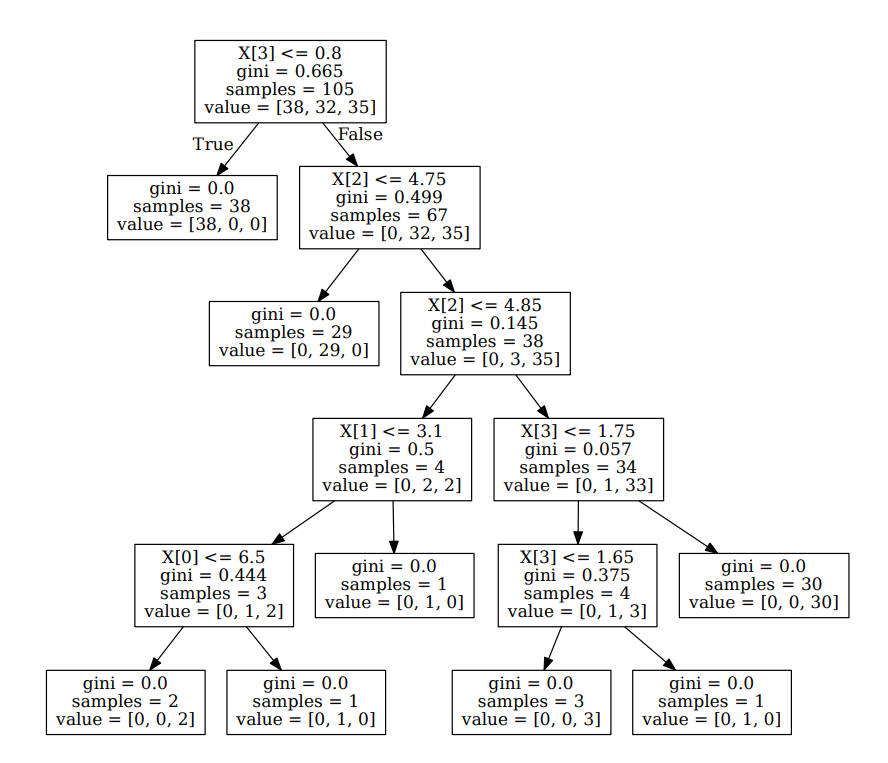
机器学习练手(三):基于决策树的iris 多分类和波士顿房价预测
总结:本文为和鲸python 可视化探索训练营资料整理而来,加入了自己的理解(by GPT4o) 原活动链接 原作者:vgbhfive,多年风控引擎研发及金融模型开发经验,现任某公司风控研发工程师,对…...

PS 2024 百种常用插件下载安装教程【免费使用,先到先得】
文章目录 软件介绍软件下载安装步骤 专栏推荐: 超多精品软件(持续更新中…) 软件推荐: PS 2024 PR 2024 软件介绍 PS常用插件 此软件整合了市面近百款ps处理插件,可实现:一键制作背景,一键抠图…...

逻辑推理之lora微调
逻辑推理微调 比赛介绍准备内容lora微调lora微调介绍lora优势代码内容 start_vllm相关介绍调用 运行主函数提交结果总结相应连接 比赛介绍 本比赛旨在测试参与者的逻辑推理和问题解决能力。参与者将面对一系列复杂的逻辑谜题,涵盖多个领域的推理挑战。 比赛的连接:…...

探索One-Language/One:统一编程范式如何重塑全栈开发体验
1. 项目概述:从“One”到“One-Language/One”的深度解构最近在GitHub上看到一个挺有意思的项目,叫“One-Language/One”。光看这个名字,可能很多人会有点懵,这到底是个啥?是又一个编程语言?还是一个框架&a…...

AI设计风格Prompt实战指南:从32种风格词典到精准生成
1. 项目概述:一份给AI设计师的“风格词典”如果你和我一样,经常用 Claude、Cursor 或者 v0 这类 AI 工具来生成网页界面,那你肯定遇到过这个头疼的问题:脑子里想的是“赛博朋克”或者“瑞士风格”,但打出来的 prompt 却…...

Windows动态光标优化:LuumaCursorHelper工具包详解与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的小工具,起因是发现很多朋友在用LuumaCursor这款动态光标主题时,总会遇到一些“小麻烦”。比如,安装后光标在某些应用里不显示、动画卡顿,或者想自定义一下效果却无从下手。我自己也…...

OpenClaw:让 AI 从 “对话” 走向 “实干” 的开源智能体
在人工智能技术快速发展的今天,大语言模型的对话能力已日趋成熟,但 “能说不能做” 的痛点始终制约着 AI 的实际应用价值。2026 年,一款名为 OpenClaw(社区昵称 “小龙虾 AI”)的开源项目迅速走红,它以 “真…...

9 款 AI 写论文哪个好?2026 深度实测|虎贲等考 AI 凭真文献 + 真实图表 + 全流程实证,稳坐毕业论文首选
毕业季高频提问:9 款 AI 写论文哪个好?市面上工具看似大同小异,实则在文献真实性、实证图表、全流程覆盖、学术合规上差距巨大。通用大模型文献造假、普通工具无实证能力、小众平台功能残缺,选错轻则反复改稿,重则查重…...

3步解锁联想刃7000k BIOS隐藏功能:安全提升硬件性能的完整指南
3步解锁联想刃7000k BIOS隐藏功能:安全提升硬件性能的完整指南 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 联想刃7…...

深度解析:HS2-HF Patch如何通过模块化架构彻底重塑游戏体验
深度解析:HS2-HF Patch如何通过模块化架构彻底重塑游戏体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch作为《Honey Select 2》最全…...

【PTA实战】矩阵乘法:从输入格式到核心算法的完整解析
1. 矩阵乘法在PTA平台的核心挑战 第一次在PTA平台做矩阵乘法题时,我被那个"格式卡顿"坑得差点怀疑人生。明明算法逻辑完全正确,提交后却总是提示"格式错误",这种经历相信很多同学都遇到过。矩阵乘法作为线性代数的基础运…...

保姆级教程:小白也能轻松上手 AI 硬件
大家好,我是siuser小伟如果你是一个小白,又想玩一下硬件的话,那我一定推荐你去接触 AI 小智。因为他们的生态非常好,教程非常详细,你也可以跑一个专属于你自己的 AI 硬件。这篇文章专门写给第一次部署小智 Go 后端的人…...

3步解锁网易云音乐NCM文件:ncmdump让你的音乐自由播放
3步解锁网易云音乐NCM文件:ncmdump让你的音乐自由播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的加密NCM文件无法在其他设备播放而烦恼吗?ncmdump作为一款专业的网易云音乐NCM文件…...