2023-03-20干活
transformer复现
from torch.utils.data import Dataset,DataLoader
import numpy as np
import torch
import torch.nn as nn
import os
import time
import math
from tqdm import tqdmdef get_data(path,num=None):all_text = []all_label = []with open(path,"r",encoding="utf8") as f:all_data = f.read().split("\n")for data in all_data:try:if len(data) == 0:continuedata_s = data.split(" ")if len(data_s) != 2:continuetext,label = data_slabel = int(label)except Exception as e:print(e)else:all_text.append(text)all_label.append(int(label))if num is None:return all_text,all_labelelse:return all_text[:num], all_label[:num]def build_word2index(train_text):word_2_index = {"PAD":0,"UNK":1}for text in train_text:for word in text:if word not in word_2_index:word_2_index[word] = len(word_2_index)return word_2_indexclass TextDataset(Dataset):def __init__(self,all_text,all_lable):self.all_text = all_textself.all_lable = all_labledef __getitem__(self, index):global word_2_indextext = self.all_text[index]text_index = [word_2_index.get(i,1) for i in text]label = self.all_lable[index]text_len = len(text)return text_index,label,text_lendef process_batch_batch(self, data):global max_len,word_2_index,index_2_embedingbatch_text = []batch_label = []batch_len = []for d in data:batch_text.append(d[0])batch_label.append(d[1])batch_len.append(d[2])min_len = min(batch_len)batch_text = [i[:max_len] for i in batch_text]batch_text = [i + [0]*(max_len-len(i)) for i in batch_text]# batch_emebdding = []# for text_idx in batch_text:# text_embdding = []# for idx in text_idx:# word_emb = index_2_embeding[idx]# text_embdding.append(word_emb)# batch_emebdding.append(text_embdding)return torch.tensor(batch_text),torch.tensor(batch_label),batch_lendef __len__(self):return len(self.all_text)class Positional(nn.Module):def __init__(self,embedding_num,max_len = 3000):super().__init__()self.position = torch.zeros(size=(max_len,embedding_num),requires_grad=False) # 3000 * embeddingt = torch.arange(1,max_len+1,dtype=torch.float).unsqueeze(1)w_i = 1/(10000**((torch.arange(0,embedding_num,2))/embedding_num))w_i_t = w_i*tself.position[:,::2] = torch.sin(w_i_t)self.position[:,1::2] = torch.cos(w_i_t)self.normal = nn.LayerNorm(normalized_shape=embedding_num)self.dropout = nn.Dropout(0.2)def forward(self,batch_x): # batch * len * 200pos = self.position[:batch_x.shape[1],:]pos = pos.unsqueeze(dim=0)pos = pos.to(batch_x.device)result = batch_x + posresult = self.normal(result)result = self.dropout(result)return resultclass M_Self_Attention(nn.Module):def __init__(self,embedding_num,n_heads):super(M_Self_Attention, self).__init__()self.W_Q = nn.Linear(embedding_num,embedding_num,bias=False)self.W_K = nn.Linear(embedding_num,embedding_num,bias=False)# self.W_L = nn.Linear(embedding_num,max_len,bias=False)self.W_V = nn.Linear(embedding_num,embedding_num,bias=False)self.softmax = nn.Softmax(dim=-1)self.n_heads = n_headsdef forward(self,x):b,l,n = x.shapex_ = x.reshape(b, self.n_heads, -1, n)Q = self.W_Q(x_) # 查询K = self.W_K(x_) # 关键V = self.W_V(x_) # 值# s = (Q@(K.transpose(-1,-2)) + L) / (math.sqrt(x.shape[-1]/1.0))s = (Q@(K.transpose(-1,-2)) ) / (math.sqrt(x.shape[-1]/1.0))score = self.softmax(s)r = score @ Vr = r.reshape(b,l,n)return rclass Add_Norm(nn.Module):def __init__(self,embedding_num):super().__init__()self.Add = nn.Linear(embedding_num,embedding_num)self.Norm = nn.LayerNorm(embedding_num)def forward(self,x): # B * Layer * embadd_x = self.Add(x)norm_x = self.Norm(add_x)return norm_xclass Feed_Forward(nn.Module):def __init__(self,embedding_num,feed_num):super(Feed_Forward, self).__init__()self.l1 = nn.Linear(embedding_num,feed_num)self.relu = nn.ReLU()self.l2 = nn.Linear(feed_num,embedding_num)def forward(self,x):l1_x = self.l1(x)r_x = self.relu(l1_x)l2_x = self.l2(r_x)return l2_xclass Block(nn.Module):def __init__(self,embeding_dim,n_heads,feed_num):super(Block, self).__init__()self.att_layer = M_Self_Attention(embeding_dim, n_heads)self.add_norm1 = Add_Norm(embeding_dim)self.feed_forward = Feed_Forward(embeding_dim, feed_num)self.add_norm2 = Add_Norm(embeding_dim)self.n = 100def forward(self,x):att_x = self.att_layer(x)adn_x1 = self.add_norm1(att_x)adn_x1 = x + adn_x1 # 残差网络ff_x = self.feed_forward(adn_x1)adn_x2 = self.add_norm2(ff_x)adn_x2 = adn_x1 + adn_x2 # 残差网络return adn_x2class TransformerEncoder(nn.Module):def __init__(self,word_size,embeding_dim,class_num,n_heads,feed_num,N):super().__init__()"""1. 随机数表示字向量2. 预训练字向量 : 使用bert 字向量替换, 使用sougou字向量3. 自己基于train_text 训练字向量 """self.embedding = torch.nn.Embedding(word_size,embeding_dim)self.positional = Positional(embeding_dim)# 5W~18W 短文本数据# self.blocks = nn.ModuleList([Block(embedding_num,n_heads,feed_num)]*N)self.blocks = nn.Sequential(*[Block(embedding_num,n_heads,feed_num) for i in range(N)])self.linear1 = nn.Linear(embeding_dim,class_num)self.loss_fun = nn.CrossEntropyLoss()def forward(self,x,batch_len,label=None):x = self.embedding(x)x = self.positional(x)# mask_x = torch.ones(size=(*x.shape[:2],1),device=x.device)mask_x = torch.ones_like(x,device=x.device)for i in range(len(batch_len)):mask_x[i][batch_len[i]:] = 0x = mask_x * xx = self.blocks(x)pre = self.linear1.forward(x)pre = torch.mean(pre,dim=1)if label is not None:loss = self.loss_fun(pre,label)return losselse:return torch.argmax(pre,dim=-1)def same_seeds(seed):torch.manual_seed(seed) # 固定随机种子(CPU)if torch.cuda.is_available(): # 固定随机种子(GPU)torch.cuda.manual_seed(seed) # 为当前GPU设置torch.cuda.manual_seed_all(seed) # 为所有GPU设置np.random.seed(seed) # 保证后续使用random函数时,产生固定的随机数torch.backends.cudnn.benchmark = False # GPU、网络结构固定,可设置为Truetorch.backends.cudnn.deterministic = True # 固定网络结构# word2vec 复现if __name__ == "__main__":same_seeds(1007)train_text,train_lable = get_data(os.path.join("..","data","文本分类","train.txt"),70000)dev_text,dev_lable = get_data(os.path.join("..","data","文本分类","dev.txt"),10000)assert len(train_lable) == len(train_text),"训练数据长度都不一样,你玩冒险呢?"assert len(dev_text) == len(dev_lable),"验证数据长度都不一样,你玩冒险呢?"embedding_num = 200word_2_index = build_word2index(train_text)train_batch_size = 50max_len = 30epoch = 10lr = 0.001n_heads = 2N = 2feed_num = int(embedding_num*1.2)class_num = len(set(train_lable))device = "cuda:0" if torch.cuda.is_available() else "cpu"# device = "cpu"train_dataset = TextDataset(train_text,train_lable)train_dataloader = DataLoader(train_dataset,batch_size=train_batch_size,shuffle=True,collate_fn=train_dataset.process_batch_batch)dev_dataset = TextDataset(dev_text, dev_lable)dev_dataloader = DataLoader(dev_dataset, batch_size=10, shuffle=False,collate_fn=dev_dataset.process_batch_batch)model = TransformerEncoder(len(word_2_index),embedding_num,class_num,n_heads,feed_num,N).to(device)opt = torch.optim.Adam(model.parameters(),lr)s_time = time.time()for e in range(epoch):print("*" * 100)for bi,(batch_text,batch_label,batch_len) in (enumerate(train_dataloader,start=1)):batch_text = batch_text.to(device)batch_label = batch_label.to(device)loss = model.forward(batch_text,batch_len,batch_label)loss.backward()opt.step()opt.zero_grad()print(f"loss:{loss:.2f}")e_time = time.time()# print(f"cost time :{e_time - s_time:.2f}s")s_time = time.time()right_num = 0for bi,(batch_text,batch_label,batch_len) in (enumerate(dev_dataloader)):batch_text = batch_text.to(device)batch_label = batch_label.to(device)pre = model.forward(batch_text,batch_len)right_num += int(torch.sum(pre == batch_label))print(f"acc:{right_num/len(dev_dataset) * 100:.2f}%")相关文章:

2023-03-20干活
transformer复现 from torch.utils.data import Dataset,DataLoader import numpy as np import torch import torch.nn as nn import os import time import math from tqdm import tqdmdef get_data(path,numNone):all_text []all_label []with open(path,"r",e…...
)
Java 注解(详细学习笔记)
注解 注解英文为Annotation Annotation是JDK5引入的新的技术 Annotation的作用: 不是程序本身,可以对程序做出解释可以被其他程序(比如编译器)读取。 Annotation的格式: 注解是以注解名在代码中存在的,还…...

LeetCode:35. 搜索插入位置
🍎道阻且长,行则将至。🍓 🌻算法,不如说它是一种思考方式🍀算法专栏: 👉🏻123 一、🌱35. 搜索插入位置 题目描述:给定一个排序数组和一个目标值&…...

菜鸟刷题Day2
菜鸟刷题Day2 一.判定是否为字符重排:字符重排 描述 给定两个由小写字母组成的字符串 s1 和 s2,请编写一个程序,确定其中一个字符串的字符重新排列后,能否变成另一个字符串。 解题思路: 这题思路与昨天最后两道类似&…...

Selenium基础篇之不打开浏览器运行
文章目录前言一、场景二、设计1.引入库2.引入浏览器配置3.设置无头模式4.启动浏览器实例,添加配置信息5.访问质量分地址6.隐式等待5秒7.定位到输入框8.输入博文地址9.定位到查询按钮10.点击查询按钮11.定位到查询结果模块div12.打印结果13.结束webdriver进程三、结果…...

【数据结构初阶】栈与队列笔试题
前言在我们学习了栈和队列之后,今天来通过几道练习题来巩固一下我们的知识。题目一 用栈实现队列题目链接:232. 用栈实现队列 - 力扣(Leetcode)这道题难度不是很大,重要的是我们对结构认识的考察,由于这篇文…...
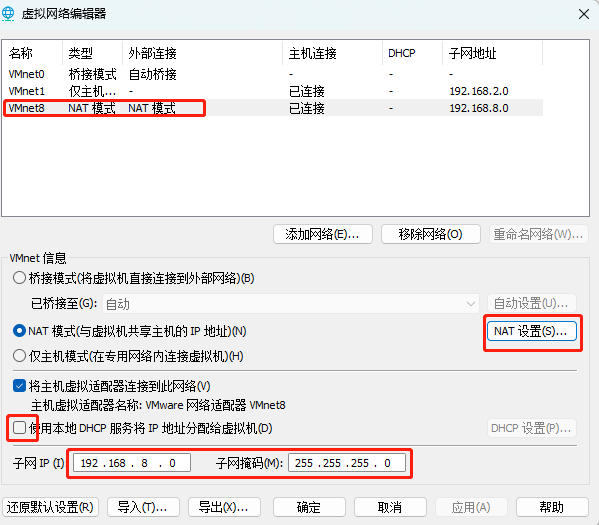
【Linux入门篇】操作系统安装、网络配置
目录 🍁Linux详解 🍂1.操作系统 🍂2.操作系统组成 🍂3.操作系统历史 🍂4.常见的Linux系统 🍂5.centos7下载 🍂6.安装centos7 🍁linux初始化配置 🍃1.虚拟机系统安装后操作…...

Selenium:找不到对应的网页元素?常见的一些坑
目录 1. 用Xpath查找数据时无法直接获取节点属性 2. 使用了WebDriverWait以后仍然无法找到元素 2.1. 分辨率原因 2.2. 需要滚动页面 2.3. 由于其他元素的遮挡 1. 用Xpath查找数据时无法直接获取节点属性 通常在我们使用xpath时,可以使用class的方式直接获取节…...
flex布局优化(两端对齐,从左至右)
文章目录前言方式一 nth-child方式二 gap属性方式三 设置margin左右两边为负值总结前言 flex布局是前端常用的布局方式之一,但在使用过程中,我们总是感觉不太方便,因为日常开发中,大多数时候,我们想要的效果是这样的 …...
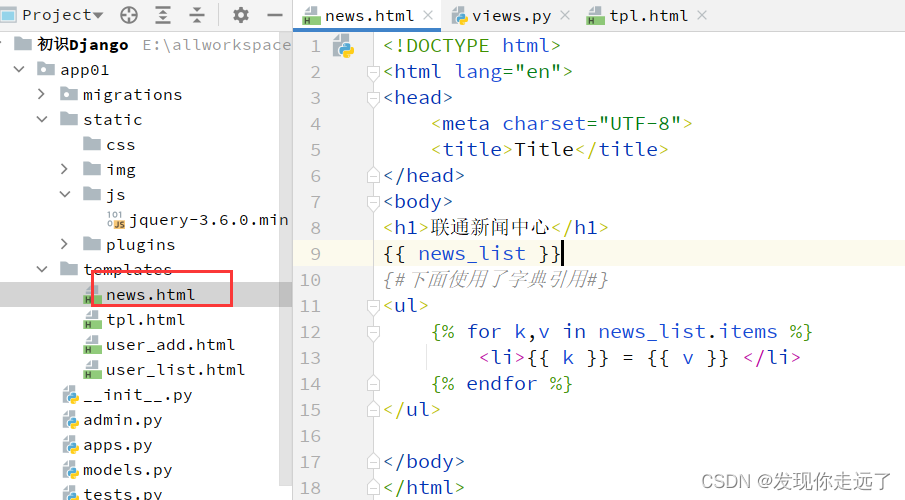
【Django 网页Web开发】03. 初识Django(保姆级图文)
目录1. 命令行创建与pycharm创建的区别2. 项目结构信息2.1 项目结构2.2 项目app结构2.3 快速查看项目结构树3. 创建并注册app3.1 创建app3.2 注册app4. 编写URL与视图的对应关系5. 编写视图文件6. 启动项目7. 写多个页面8. templates模板的使用8.1 编写html文件8.3 导入html文件…...

KubeSphere All in one安装配置手册
KubeSphere All in one安装配置手册 1. 初始化 1.1 配置apt源 # vi /etc/apt/sources.list deb https://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse deb-src https://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiversedeb…...

Spring Boot 核心配置文件
Spring Boot 核心配置文件1、application.properties2、application.yml使用建议3、常用配置项服务器配置数据库配置日志配置其他配置4、配置文件的加载顺序5、配置文件的占位符6、配置文件的动态刷新7、配置文件的属性分组定义属性分组绑定属性分组使用属性分组总结Spring Boo…...

个人小站折腾后记
个人小站折腾后记 🏠个人主页:shark-Gao 🧑个人简介:大家好,我是shark-Gao,一个想要与大家共同进步的男人😉😉 🎉目前状况:23届毕业生,目前在某…...

WebService简单入门
1. JAX-WS发布WebService 创建web工程 创建simple包,和server、client两个子包。正常情况下server和client应该是两个项目,这里我们只是演示效果,所以简化写到一个项目中: 1.1 创建服务类Server package simple.server;import ja…...
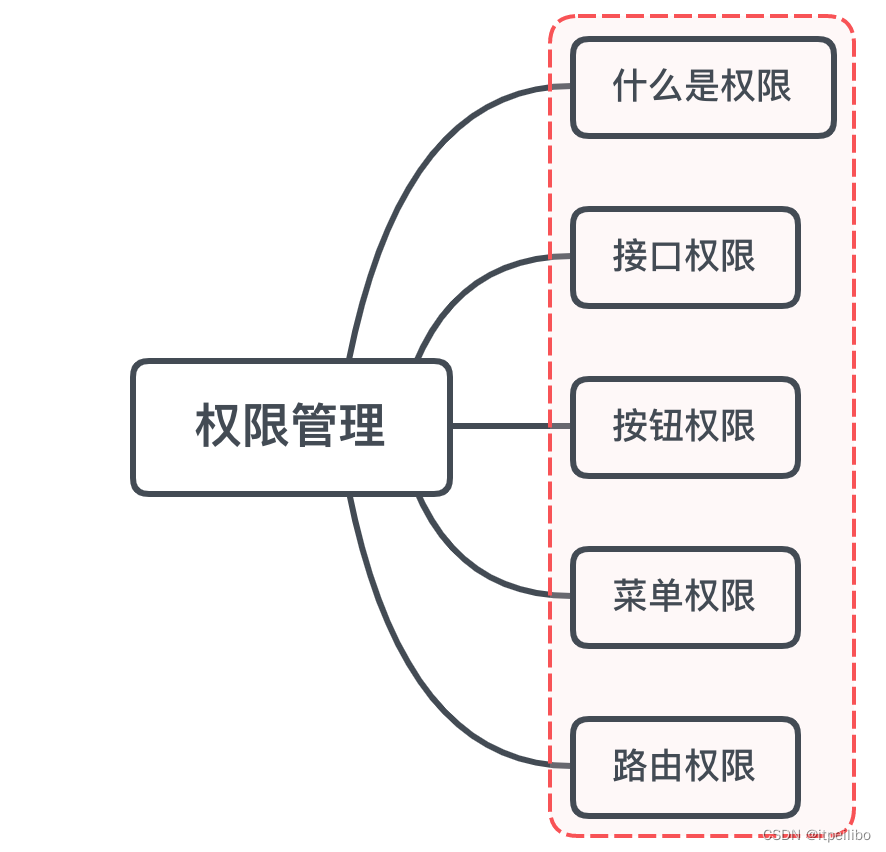
「Vue面试题」vue要做权限管理该怎么做?如果控制到按钮级别的权限怎么做?
文章目录一、是什么二、如何做接口权限路由权限控制菜单权限方案一方案二按钮权限方案一方案二小结参考文章一、是什么 权限是对特定资源的访问许可,所谓权限控制,也就是确保用户只能访问到被分配的资源 而前端权限归根结底是请求的发起权,…...
Docker部署springcloud项目(清晰明了)
概述 最近在想做个cloud项目,gitee上找了个模板项目,后端使用到 Nacos、Gateway、Security等技术,需要到 Docker 容器部署,在此总结一下,若有不足之处,望大佬们可以指出。 什么是 Docker Docker 使用 Google 公司推…...
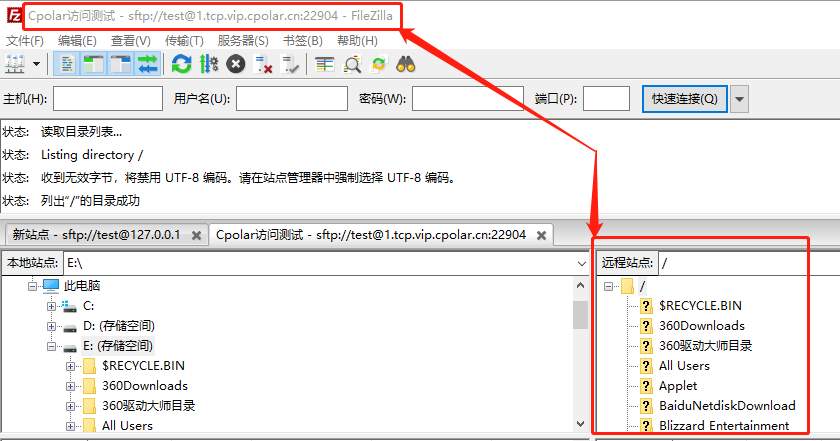
搭建SFTP服务安全共享文件,实现在外远程访问「内网穿透」
文章目录1.前言2.本地SFTP服务器搭建2.1.SFTP软件的下载和安装2.2.配置SFTP站点2.3.Cpolar下载和安装3.SFTP服务器的发布3.1.Cpolar云端设置3.2.Cpolar本地设置4.公网访问测试5.结语1.前言 现在的网络发达,个人电脑容量快速上升,想要保存的数据资料也越…...
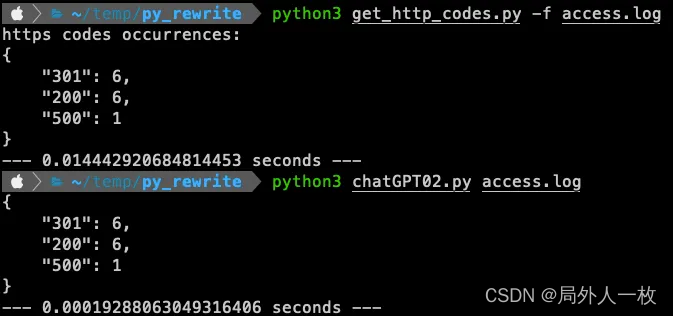
ChatGPT优化Python代码的小技巧
使用 chatGPT 优化代码并降低运行时的云成本 许多开发人员说“过早的优化是万恶之源”。 这句话的来源归功于Donald Knuth。在他的书《计算机编程的艺术》中,他写道: “真正的问题是,程序员在错误的时间和错误的地方花费了太多时间来担心效率…...
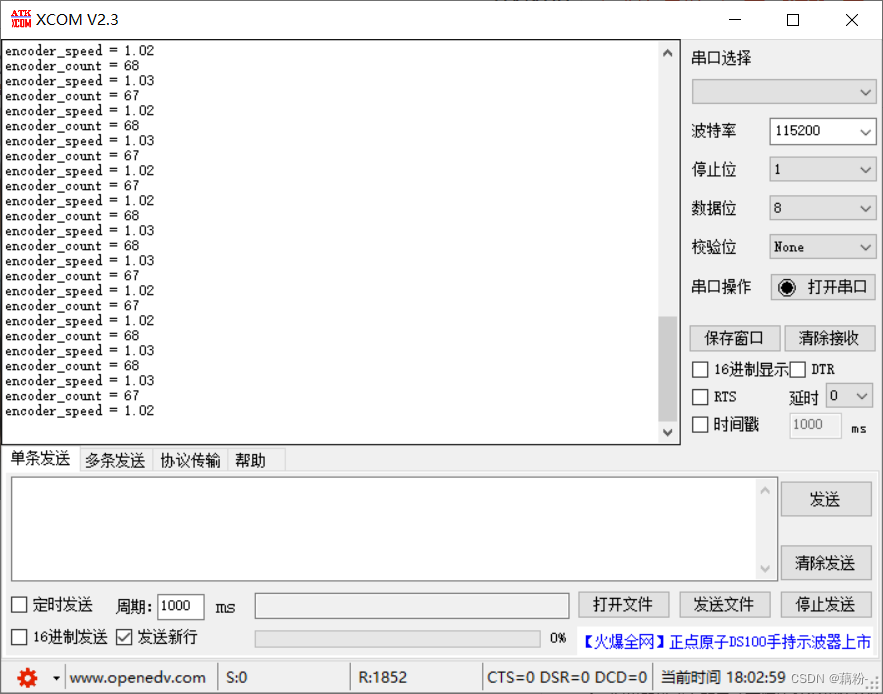
Stm32-使用TB6612驱动电机及编码器测速
这里写目录标题起因一、电机及编码器的参数二、硬件三、接线四、驱动电机1、TB6612电机驱动2、定时器的PWM模式驱动电机五、编码器测速1、定时器的编码器接口模式2、定时器编码器模式测速的原理3、编码器模式的配置4、编码器模式相关代码5、测速方法六、相关问题以及解答1、编码…...

【JS】常用js方法
1、判断是否是数组、字符串等方法a instanceof ba是你需要判断的数据b是判断的类型//直接判断原型 var a [1,5,8] var b 123456console.log(a instanceof Array)//true console.log(a instanceof String)//falseconsole.log(b instanceof String)//true2、分割字符串a.split(…...

5个关键步骤:OpenCore Legacy Patcher让老旧Mac焕发新生
5个关键步骤:OpenCore Legacy Patcher让老旧Mac焕发新生 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款基于Pytho…...

告别重复造轮子:用快马AI一键生成SpringBoot通用后台管理模块
最近在做一个后台管理系统的项目,发现每次从零开始搭建SpringBoot框架都要重复写很多样板代码,特别浪费时间。后来尝试用InsCode(快马)平台的AI生成功能,效率提升了好几倍。今天就来分享下如何快速生成SpringBoot通用后台模块。 1. 后台管理…...

51单片机开发环境搭建指南:从Keil5安装到程序烧录全流程
1. 51单片机开发环境搭建全攻略 刚接触51单片机的朋友可能会被一堆陌生的名词搞懵——Keil5、CH340、HEX文件、烧录工具...别担心,我当初也是这样过来的。今天我就用最直白的语言,手把手带你搭建完整的开发环境。整个过程就像组装乐高积木,只…...

Matlab_Simulink与Carsim的联合仿 擅长基于群智能算法优化的LQR、PID控制算法,能清晰讲解其中要点哦。对于基于群智能算法的一般路径规划
Matlab/Simulink与Carsim的联合仿 擅长基于群智能算法优化的LQR、PID控制算法,能清晰讲解其中要点哦。对于基于群智能算法的一般路径规划 稍长智能车轨迹跟踪控制方向 熟悉Matlab/Simulink和Carsim的联合仿真呢。这是一个非常专业且热门的研究方向(群智能…...

intv_ai_mk11GPU利用率提升:Llama中型模型批处理与并发请求调优方案
intv_ai_mk11 GPU利用率提升:Llama中型模型批处理与并发请求调优方案 1. 背景与挑战 intv_ai_mk11 是基于 Llama 架构的中等规模文本生成模型,在实际部署中我们发现单请求处理时GPU利用率往往不足30%。这种低效的资源使用导致两个主要问题:…...
)
ESP32-S3玩转微雪2.8寸触摸屏:从零到LVGL的保姆级避坑指南(ESP-IDF 5.3)
ESP32-S3与微雪2.8寸触摸屏深度适配:LVGL全流程实战手册 刚拿到微雪2.8寸触摸屏开发板的开发者,往往既兴奋又忐忑——这块搭载ESP32-S3芯片、配备8M PSRAM的硬件平台,理论上能流畅运行LVGL图形库,但实际开发中总会遇到各种"坑…...

Postman实战指南:深入解析CORS预检请求与响应头配置
1. 为什么CORS会成为开发者的噩梦? 第一次遇到CORS问题时,我盯着浏览器控制台那个鲜红的报错信息整整发呆了十分钟。"Access-Control-Allow-Origin"这个看起来人畜无害的响应头,竟然能让整个前端应用瘫痪。后来才发现,这…...

重新定义交通安全研究范式:基于无人机轨迹数据的数字孪生解决方案
重新定义交通安全研究范式:基于无人机轨迹数据的数字孪生解决方案 【免费下载链接】UCF-SST-CitySim1-Dataset 项目地址: https://gitcode.com/gh_mirrors/ucf/UCF-SST-CitySim-Dataset 在自动驾驶技术快速发展的今天,传统交通安全研究面临着一个…...

一键部署雪女-斗罗大陆-造相Z-Turbo:小白也能轻松生成动漫女神
一键部署雪女-斗罗大陆-造相Z-Turbo:小白也能轻松生成动漫女神 1. 镜像简介与核心功能 1.1 什么是雪女-斗罗大陆-造相Z-Turbo 雪女-斗罗大陆-造相Z-Turbo是一款基于Xinference部署的文生图AI模型服务,专门用于生成斗罗大陆中雪女角色的高质量动漫图像…...

LSLib:从游戏资源新手到MOD制作专家的完整路径
LSLib:从游戏资源新手到MOD制作专家的完整路径 【免费下载链接】lslib Tools for manipulating Divinity Original Sin and Baldurs Gate 3 files 项目地址: https://gitcode.com/gh_mirrors/ls/lslib 你是否曾经想过修改《神界原罪》系列或《博德之门3》的游…...