Flink学习--第一章 初识Flink
Flink是Apache基金会旗下的一个开源大数据处理框架,如今已被很多人认为是大数据实时处理的方向和未来,许多公司也都在招聘和储备掌握Flink技术的人才。

1.1 Flink的源起和设计理念
Flink起源于一个叫作Stratosphere的项目,它是由3所地处柏林的大学和欧洲其他一些大学共同进行的研究项目,由柏林工业大学的教授沃克尔·马尔科(Volker Markl)领衔开发。2014年4月,Stratosphere的代码被复制并捐赠给了Apache软件基金会,Flink就是在此基础上被重新设计出来的。
⚫2014年8月,Flink第一个版本0.6正式发布(至于0.5之前的版本,那就是在Stratosphere名下的了)。与此同时Fink的几位核心开发者创办了Data Artisans公司,主要做Fink的商业应用,帮助企业部署大规模数据处理解决方案。
⚫2014年12月,Flink项目完成了孵化,一跃成为Apache软件基金会的顶级项目。
⚫2015年4月,Flink发布了里程碑式的重要版本0.9.0,很多国内外大公司也正是从这时开始关注、并参与到Flink社区建设的。
⚫2019年1月,长期对Flink投入研发的阿里巴巴,以9000万欧元的价格收购了Data Artisans公司;之后又将自己的内部版本Blink开源,继而与8月份发布的Flink1.9.0版本进行了合并。自此之后,Flink被越来越多的人所熟知,成为当前最火的新一代大数据处理框架。
由此可见,Flink从真正起步到火爆,只不过几年时间。在这短短几年内,Flink从最初的第一个稳定版本0.9,到目前本书编写期间已经发布到了1.13.0,这期间不断有新功能新特性加入。从一开始,Flink就拥有一个非常活跃的社区,而且一直在快速成长。
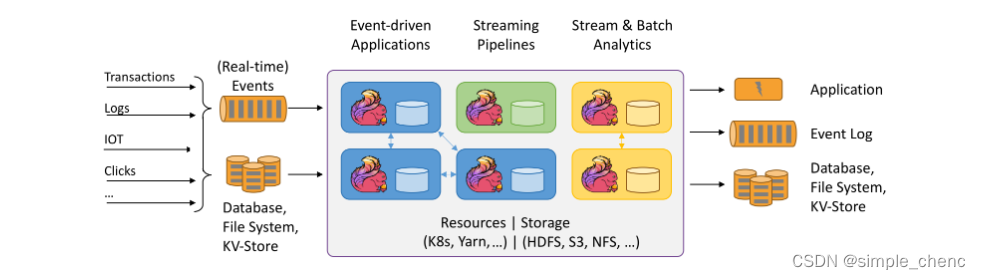
Flink的具体定位是:Apache Flink是一个框架和分布式处理引擎,如图所示,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
1.2 Flink的应用
Flink是一个大数据流处理引擎,它可以为不同的行业提供大数据实时处理的解决方案。随着Flink的快速发展完善,如今在世界范围许多公司都可以见到Flink的身影。
1.2.1 Flink主要的应用场景可以看到,各种行业的众多公司都在使用Flink,那到底他们用Flink来实现什么需求呢?换句话说,什么的场景最适合Flink大显身手呢?
具体来看,一些行业中的典型应用有:
1. 电商和市场营销举例:实时数据报表、广告投放、实时推荐在电商行业中,网站点击量是统计PV、UV的重要来源,也是如今“流量经济”的最主要数据指标。很多公司的营销策略,比如广告的投放,也是基于点击量来决定的。另外,在网站上提供给用户的实时推荐,往往也是基于当前用户的点击行为做出的。我们需要的是直接处理数据流,而Flink就可以做到这一点。
2. 物联网(IOT)举例:传感器实时数据采集和显示、实时报警,交通运输业物联网是流数据被普遍应用的领域。各种传感器不停获得测量数据,并将它们以流的形式传输至数据中心。而数据中心会将数据处理分析之后,得到运行状态或者报警信息,实时地显示在监控屏幕上。所以在物联网中,低延迟的数据传输和处理,以及准确的数据分析通常很关键。
3. 物流配送和服务业举例:订单状态实时更新、通知信息推送在很多服务型应用中,都会涉及订单状态的更新和通知的推送。这些信息基于事件触发,不均匀地连续不断生成,处理之后需要及时传递给用户。这也是非常典型的数据流的处理。
4. 银行和金融业举例:实时结算和通知推送,实时检测异常行为银行和金融业是另一个典型的应用行业。在全球化经济中,能够提供24小时服务变得越来越重要。现在交易和报表都会快速准确地生成,我们跨行转账也可以做到瞬间到账,还可以接到实时的推送通知。这就需要我们能够实时处理数据流。
1.3 流式数据处理的发展和演变
Flink的主要应用场景,就是处理大规模的数据流。那为什么一定要用Flink呢?数据处理还有没有其他的方式?要解答这个疑惑,我们就需要先从流处理和批处理的概念讲起。
1.3.1 流处理和批处理数据处理有不同的方式。
对于具体应用来说,有些场景数据是一个一个来的,是一组有序的数据序列,我们把它叫作“数据流”;而有些场景的数据,本身就是一批同时到来,是一个有限的数据集,这就是批量数据(有时也直接叫数据集)。
容易想到,处理数据流,当然应该“来一个就处理一个”,这种数据处理模式就叫作流处理;因为这种处理是即时的,所以也叫实时处理。与之对应,处理批量数据自然就应该一批读入、一起计算,这种方式就叫作批处理,也叫作离线处理。
在IT应用场景中,数据的生成,一般都是流式的。企业的绝大多数应用程序,都是在不停地接收用户请求、记录用户行为和系统日志,或者持续接收采集到的状态信息。所以数据会在不同的时间持续生成,形成一个有序的数据序列——这就是典型的数据流。
所以流数据更真实地反映了我们的生活方式。真实场景中产生的,一般都是数据流。显然,对于流式数据,用流处理是最好、也最合理的方式。
但我们知道,传统的数据处理架构并不是这样。无论是关系型数据库、还是数据仓库,都倾向于先“收集数据”,然后再进行处理。为什么不直接用流处理的方式呢?这是因为,分布式批处理在架构上更容易实现。想想生活中发消息聊天的例子,我们就很容易理解了:如果来一条消息就立即处理,“微信秒回”,这样做一定会很受人欢迎;但是这要求自己必须时刻关注新消息,这会耗费大量精力,工作效率会受到很大影响。如果隔一段时间查一下新消息,做个“批处理”,压力明显就小多了。当然,这样的代价就是可能无法及时处理有些消息,造成一定的后果。
1.3.2 flink:新一代的处理器设计
flink通过巧妙的设计,完美解决了乱序数据对结果正确性所造成的影响。这一代系统还做到了精确一次(exactly-once)的一致性保障,是第一个具有一致性和准确结果的开源流处理器。另外,先前的流处理器仅能在高吞吐和低延迟中二选一,而新一代系统能够同时提供这两个特性。所以可以说,这一代流处理器仅凭一套系统就完成了Lambda架构两套系统的工作,它的出现使得Lambda架构黯然失色。除了低延迟、容错和结果准确性之外,新一代流处理器还在不断添加新的功能,例如高可用的设置,以及与资源管理器(如YARN或Kubernetes)的紧密集成等等。
1.4 Flink的特性总结
Flink是第三代分布式流处理器,它的功能丰富而强大。
1.4.1 Flink的核心特性
Flink区别与传统数据处理框架的特性如下。
⚫高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
⚫结果的准确性。Flink提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
⚫精确一次(exactly-once)的状态一致性保证。
⚫可以连接到最常用的存储系统,如Apache Kafka、Apache Cassandra、Elasticsearch、JDBC、Kinesis和(分布式)文件系统,如HDFS和S3。
⚫高可用。本身高可用的设置,加上与K8s,YARN和Mesos的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的停机时间实现7×24全天候运行。
⚫能够更新应用程序代码并将作业(jobs)迁移到不同的Flink集群,而不会丢失应用程序的状态。
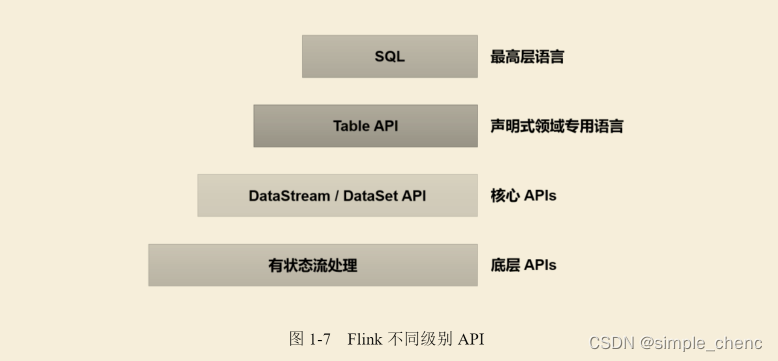
1.4.2 分层API
除了上述这些特性之外,Flink还是一个非常易于开发的框架,因为它拥有易于使用的分层API,整体API分层下图所示。
1.5 Flink vs Spark
谈到大数据处理引擎,不能不提Spark。Apache Spark是一个通用大规模数据分析引擎。它提出的内存计算概念让大家耳目一新,得以从Hadoop繁重的MapReduce程序中解脱出来,可以说是划时代的大数据处理框架。除了计算速度快、可扩展性强,Spark还为批处理(SparkSQL)、流处理(SparkStreaming)、机器学习(SparkMLlib)、图计算(SparkGraphX)提供了统一的分布式数据处理平台,整个生态经过多年的蓬勃发展已经非常完善。
然而正在大家认为Spark已经如日中天、即将一统天下之际,Flink如一颗新星异军突起,使得大数据处理的江湖再起风云。很多读者在最初接触都会有这样的疑问:想学习一个大数据处理框架,到底选择Spark,还是Flink呢?
1.5.1 数据处理架构
从根本上说,Spark和Flink采用了完全不同的数据处理方式。可以说,两者的世界观是截然相反的。
Spark以批处理为根本,并尝试在批处理之上支持流计算;在Spark的世界观中,万物皆批次,离线数据是一个大批次,而实时数据则是由一个一个无限的小批次组成的。所以对于流处理框架Spark Streaming而言,其实并不是真正意义上的“流”处理,而是“微批次”(micro-batching)处理,如图所示

而Flink则认为,流处理才是最基本的操作,批处理也可以统一为流处理。在Flink的世界观中,万物皆流,实时数据是标准的、没有界限的流,而离线数据则是有界限的流。
1. 无界数据流(Unbounded Data Stream)
所谓无界数据流,就是有头没尾,数据的生成和传递会开始但永远不会结束,如图1-9所示。我们无法等待所有数据都到达,因为输入是无界的,永无止境,数据没有“都到达”的时候。所以对于无界数据流,必须连续处理,也就是说必须在获取数据后立即处理。在处理无界流时,为了保证结果的正确性,我们必须能够做到按照顺序处理数据。
2. 有界数据流(Bounded Data Stream)
对应的,有界数据流有明确定义的开始和结束,如图1-9所示,所以我们可以通过获取所有数据来处理有界流。处理有界流就不需要严格保证数据的顺序了,因为总可以对有界数据集进行排序。有界流的处理也就是批处理。
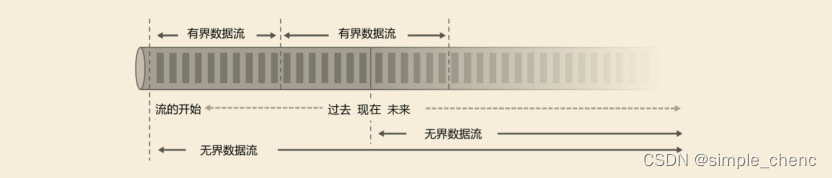
有界流和无界流
正因为这种架构上的不同,Spark和Flink在不同的应用领域上表现会有差别。一般来说,Spark 基于微批处理的方式做同步总有一个“攒批”的过程,所以会有额外开销,因此无法在流处理的低延迟上做到极致。在低延迟流处理场景,Flink 已经有明显的优势。而在海量数据的批处理领域,Spark能够处理的吞吐量更大,加上其完善的生态和成熟易用的API,目前同样优势比较明显。
1.5.2 数据模型和运行架构
Spark和Flink在底层实现最主要的差别就在于数据模型不同。
Spark底层数据模型是弹性分布式数据集(RDD),Spark Streaming 进行微批处理的底层接口DStream,实际上处理的也是一组组小批数据RDD的集合。可以看出,Spark在设计上本身就是以批量的数据集作为基准的,更加适合批处理的场景。
而Flink的基本数据模型是数据流(DataFlow),以及事件(Event)序列。Flink基本上是完全按照Google的DataFlow模型实现的,所以从底层数据模型上看,Flink是以处理流式数据作为设计目标的,更加适合流处理的场景。
数据模型不同,对应在运行处理的流程上,自然也会有不同的架构。Spark做批计算,需要将任务对应的DAG划分阶段(Stage),一个完成后经过shuffle再进行下一阶段的计算。而Flink是标准的流式执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。
1.5.3 Spark还是Flink?
通过前文的分析,我们已经可以看出,Spark和Flink可以说目前是各擅胜场,批处理领域Spark称王,而在流处理方面Flink当仁不让。具体到项目应用中,不仅要看是流处理还是批处理,还需要在延迟、吞吐量、可靠性,以及开发容易度等多个方面进行权衡。
如果在工作中需要从Spark和Flink这两个主流框架中选择一个来进行实时流处理,更加推荐使用Flink,主要的原因有:
⚫Flink的延迟是毫秒级别,而SparkStreaming的延迟是秒级延迟。
⚫Flink提供了严格的精确一次性语义保证。
⚫Flink的窗口API更加灵活、语义更丰富。
⚫Flink提供事件时间语义,可以正确处理延迟数据。
⚫Flink提供了更加灵活的可对状态编程的API。
基于以上特点,使用Flink可以解放程序员, 加快编程效率, 把本来需要程序员花大力气手动完成的工作交给框架完成。
当然,在海量数据的批处理方面,Spark还是具有明显的优势。而且Spark的生态更加成熟,也会使其在应用中更为方便。相信随着Flink的快速发展和完善,这方面的差距会越来越小。
另外,Spark 2.0之后新增的Structured Streaming流处理引擎借鉴DataFlow进行了大量优化,同样做到了低延迟、时间正确性以及精确一次性语义保证;Spark 2.3以后引入的连续处理(Continuous Processing)模式,更是可以在至少一次语义保证下做到1毫秒的延迟。而Flink自1.9版本合并Blink以来,在SQL的表达和批处理的能力上同样有了长足的进步。
相关文章:
Flink学习--第一章 初识Flink
Flink是Apache基金会旗下的一个开源大数据处理框架,如今已被很多人认为是大数据实时处理的方向和未来,许多公司也都在招聘和储备掌握Flink技术的人才。 1.1 Flink的源起和设计理念 Flink起源于一个叫作Stratosphere的项目,它是由3所地处柏林的…...

电脑技巧:常见的浏览器内核介绍
浏览器是大家日常使用电脑必备的软件,网上查资料、听音乐、办公等等,都不离不开浏览器给我们提供的方便,今天小编来给大家介绍一下常见的浏览器内核,一起来学习一下吧!1、Chromium 内核Google Chrom内核:统…...

【数据分析之道①】字符串
文章目录专栏导读1、字符串介绍2、访问字符串中的值3、字符串拼接4、转义字符5、字符串运算符6、字符串格式化7、字符串内置函数专栏导读 ✍ 作者简介:i阿极,CSDN Python领域新星创作者,专注于分享python领域知识。 ✍ 本文录入于《数据分析之…...
网络安全之防火墙
目录 网络安全之防火墙 路由交换终归结底是联通新设备 防御对象: 定义: 防火墙的区域划分: 包过滤防火墙 --- 访问控制列表技术 --- 三层技术 代理防火墙 --- 中间人技术 --- 应用层 状态防火墙 --- 会话追踪技术 --- 三层、四层 UTM …...

STM32之点亮一个LED小灯(轮询法)
目录 一、初始化GPIO口 二、按键点亮LED灯(轮询法) 一、初始化GPIO口 1、点亮LED小灯前,需要先初始化GPIO口 HAL_GPIO_Init(GPIO_TypeDef *GPIOx, GPIO_InitTypeDef *GPIO_Init) GPIO_TypeDef *GPIOx: //指初始化GPIO…...
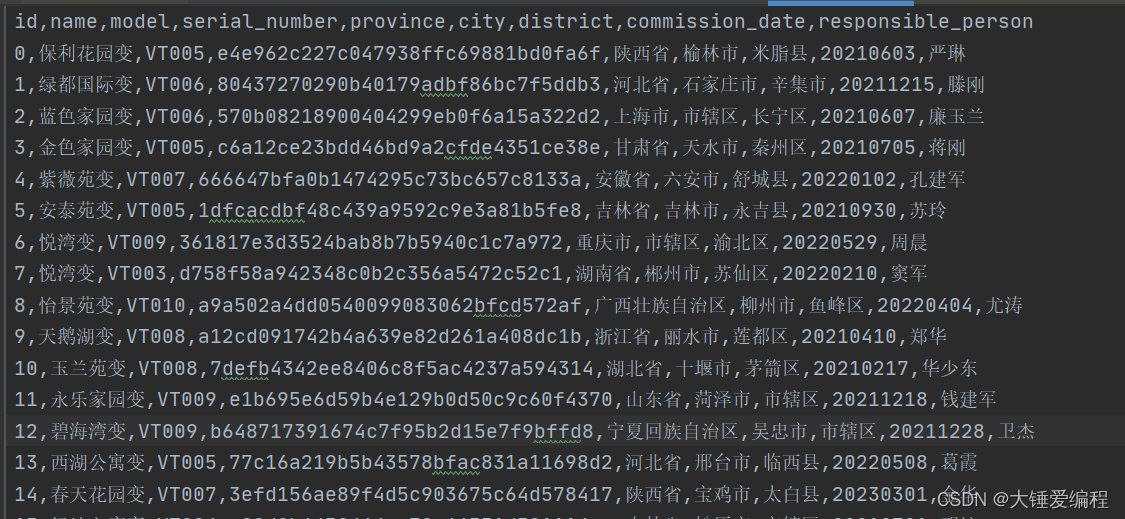
pandas读CSV、读JSON、Excel
学习让我快乐 pandas的数据读取基本操作 pandas是Python中非常流行的数据处理库,它提供了许多强大的工具来读取、处理和分析数据。在本文中,我们将介绍pandas中的一些基本数据读取操作。 读取CSV文件 CSV文件是最常见的数据文件格式之一,p…...

企业站项目
企业站项目 一、项目实现结果 该项目共分为七大类:头部区域(logo图片、输入框)、导航区域、轮播图区域、内容区域、市场项目区域、产品中心区域、尾部区域 如图所示: http://企业站项目源码http://xn--vhquvo17e18gllbz7h2v9d …...
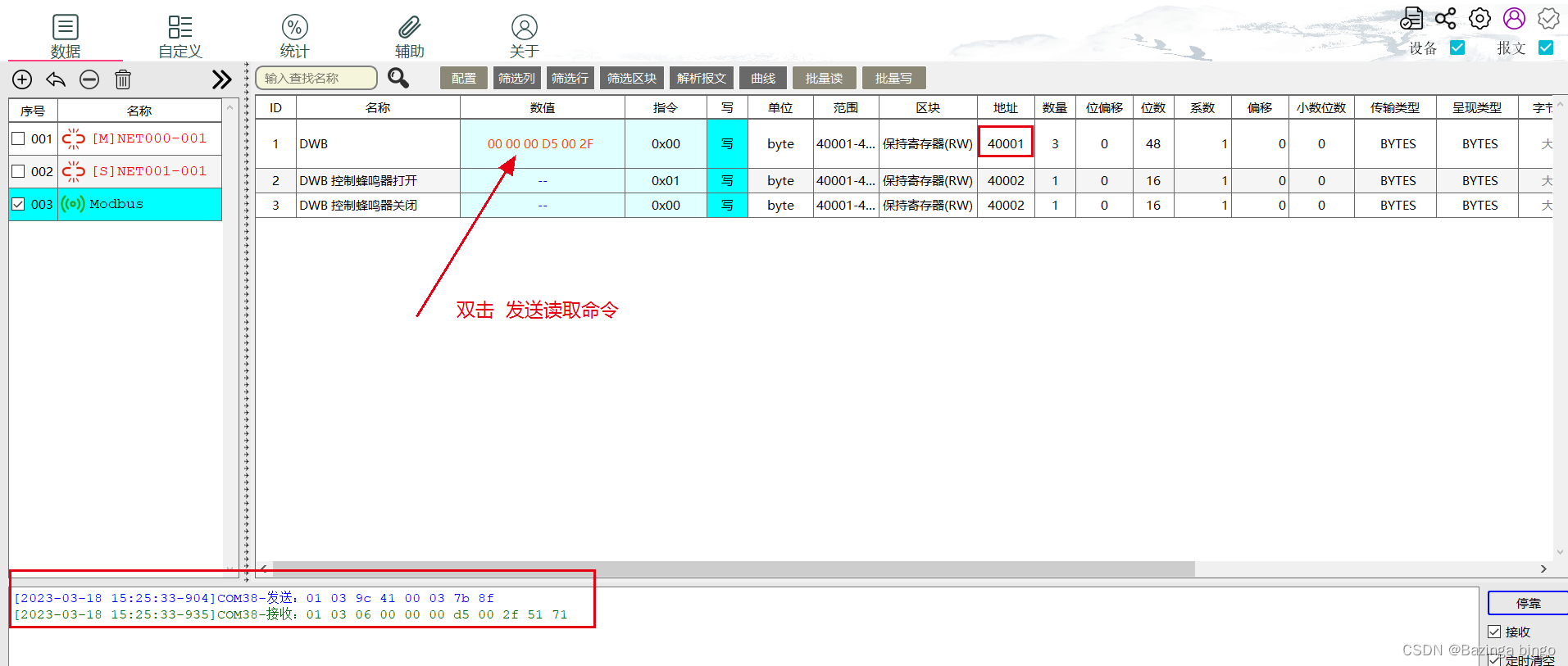
STM32开发(九)STM32F103 通信 —— I2C通信编程详解
文章目录一、基础知识点二、开发环境三、STM32CubeMX相关配置四、Vscode代码讲解GPIO模拟I2C代码SHT30相关代码main函数中循环代码五、结果演示方式一、示波器分析I2C数据方式2、通过Modbus将获取到的数据传到PC上一、基础知识点 本实验通过I2C通信获取SHT30温湿度值ÿ…...
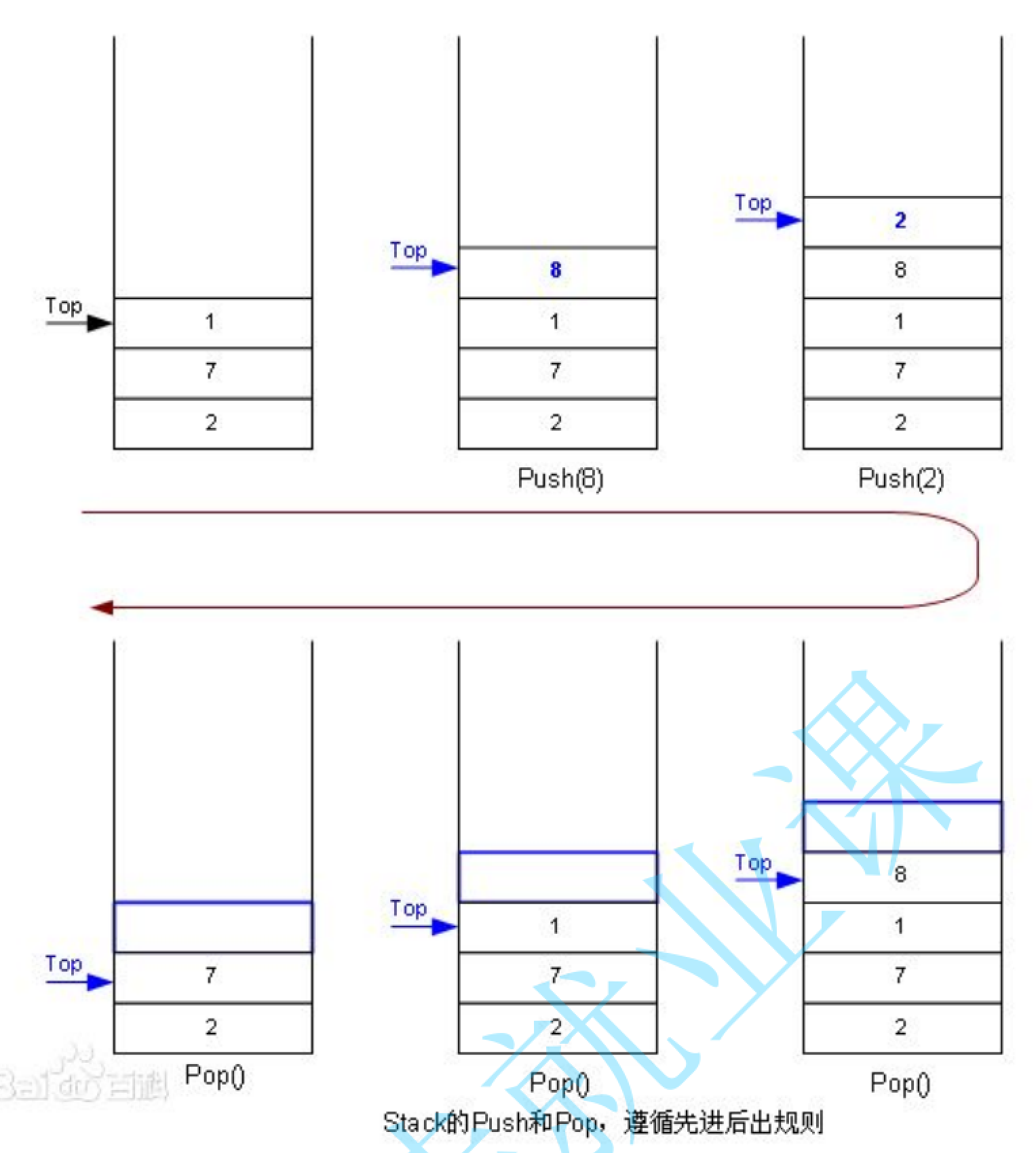
手撕数据结构—栈
Tips不得不再次提一下这个语法问题,当数组创建的时候,进行初始化的时候,分为全部初始化或者说部分初始化,对于不完全初始化而言,剩下的部分就全部默认为零。现在比如说你想对整型数组的1万个元素把它全部变成-1&#x…...

【java刷题】排序子序列
这里写目录标题问题描述解决思路实现代码问题描述 牛牛定义排序子序列为一个数组中一段连续的子序列,并且这段子序列是非递增或者非递减排序的。牛牛有一个长度为n的整数数组A,他现在有一个任务是把数组A分为若干段排序子序列,牛牛想知道他最少可以把这个数组分为几段排序子序…...
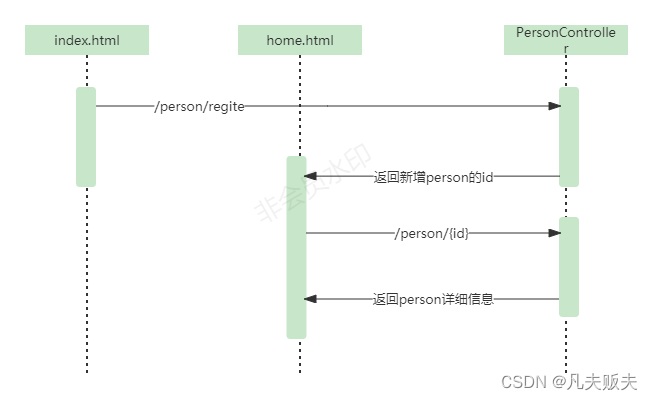
Springboot怎么快速集成Mybatis和thymeleaf?
前言有时候做方案,需要模拟一些业务上的一些场景来验证方案的可行性,基本上每次都是到处百度如何集成springbootmybatisthymeleaf这些东西的集成平时基本上一年也用不了一次,虽然比较简单,奈何我真得记不住详细的每一步࿰…...

shell常见面试题一
(1)、set //查看系统变量 (2)、chsh -s /bin/zsh test //修改用户登录shell (3)、2>&1 //标准错误重定向到标准输出 &> //同样可以将标准错误重定向到标准输出 如下: ls test.…...

python如何快速采集美~女视频?无反爬
人生苦短 我用python~ 这次康康能给大家整点好看的不~ 环境使用: Python 3.8 Pycharm mou歌浏览器 mou歌驱动 —> 驱动版本要和浏览器版本最相近 <大版本一样, 小版本最相近> 模块使用: requests >>> pip install requests selenium >>> pip …...
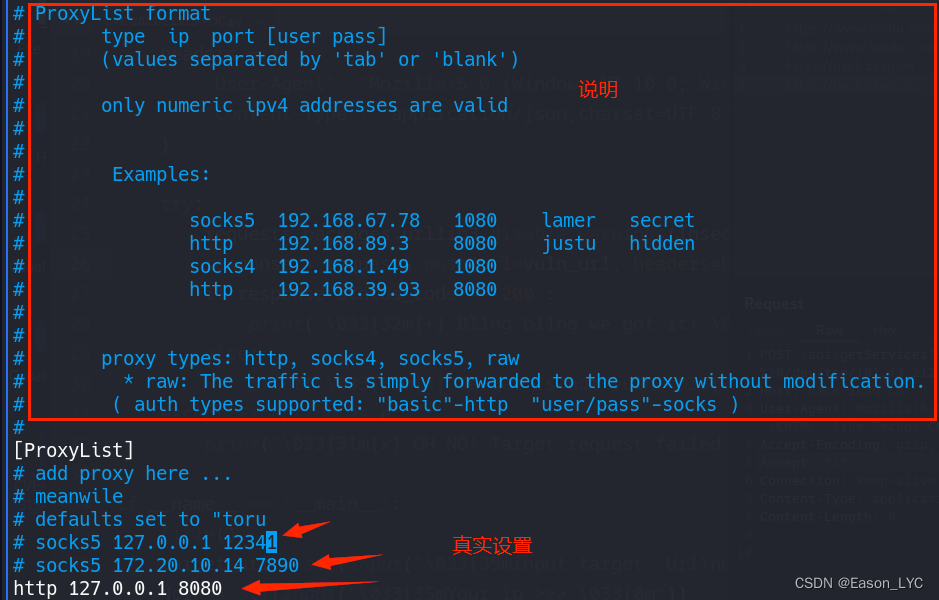
kali内置超好用的代理工具proxychains
作者:Eason_LYC 悲观者预言失败,十言九中。 乐观者创造奇迹,一次即可。 一个人的价值,在于他所拥有的。所以可以不学无术,但不能一无所有! 技术领域:WEB安全、网络攻防 关注WEB安全、网络攻防。…...

Java栈和队列·下
Java栈和队列下2. 队列(Queue)2.1 概念2.2 实现2.3 相似方法的区别2.4 循环队列3. 双端队列 (Deque)3.1 概念4.java中的栈和队列5. 栈和队列面试题大家好,我是晓星航。今天为大家带来的是 Java栈和队列下 的讲解!😀 继上一个讲完的栈后&…...
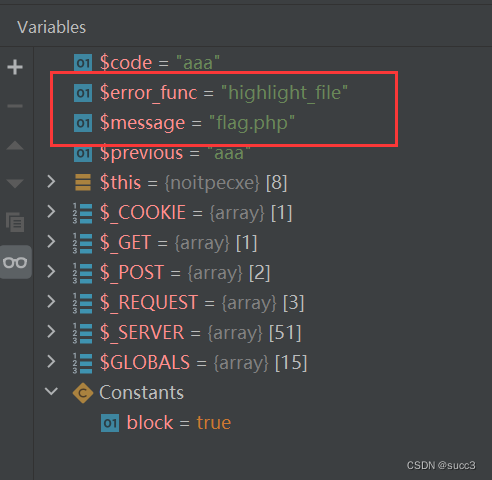
b01lers CTF web 复现
warmup 按照提示依次 base64 加密后访问,可以访问 ./flag.txt,也就是 Li9mbGFnLnR4dA 。 from base64 import b64decode import flaskapp flask.Flask(__name__)app.route(/<name>) def index2(name):name b64decode(name)if (validate(name))…...

三月份跳槽了,历经字节测开岗4轮面试,不出意外,被刷了...
大多数情况下,测试员的个人技能成长速度,远远大于公司规模或业务的成长速度。所以,跳槽成为了这个行业里最常见的一个词汇。 前几天,我看到有朋友留言说,他在面试字节的测试开发工程师的时候,灵魂拷问三小…...
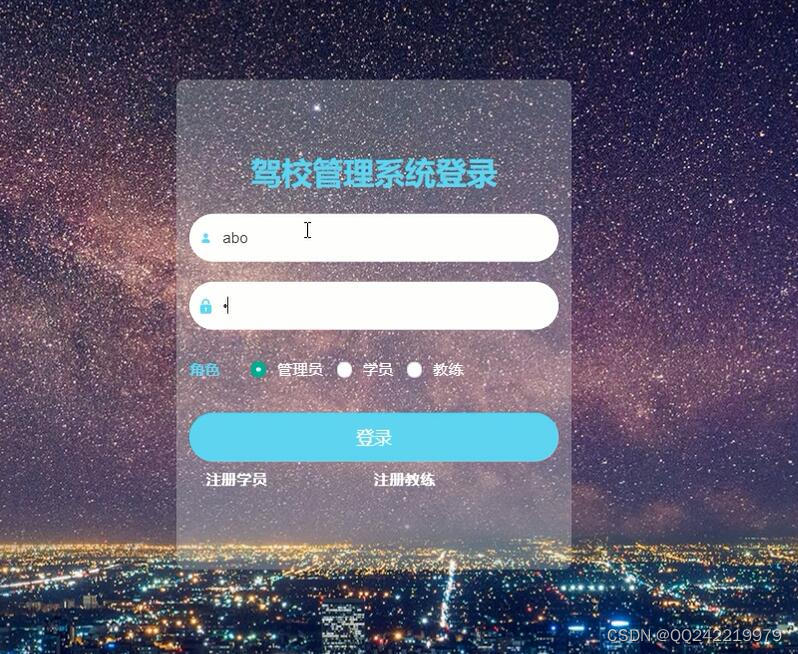
springboot+vue驾校管理系统 idea科目一四预约考试,练车
加大了对从事道路运输经营活动驾驶员的培训管理力度,但在实际的管理过程中,仍然存在以下问题:(1)管理部门内部人员在实际管理过程中存在人情管理,不进行培训、考试直接进行发证。(2)从业驾驶员培训机构不能严格执行管理部门的大纲…...
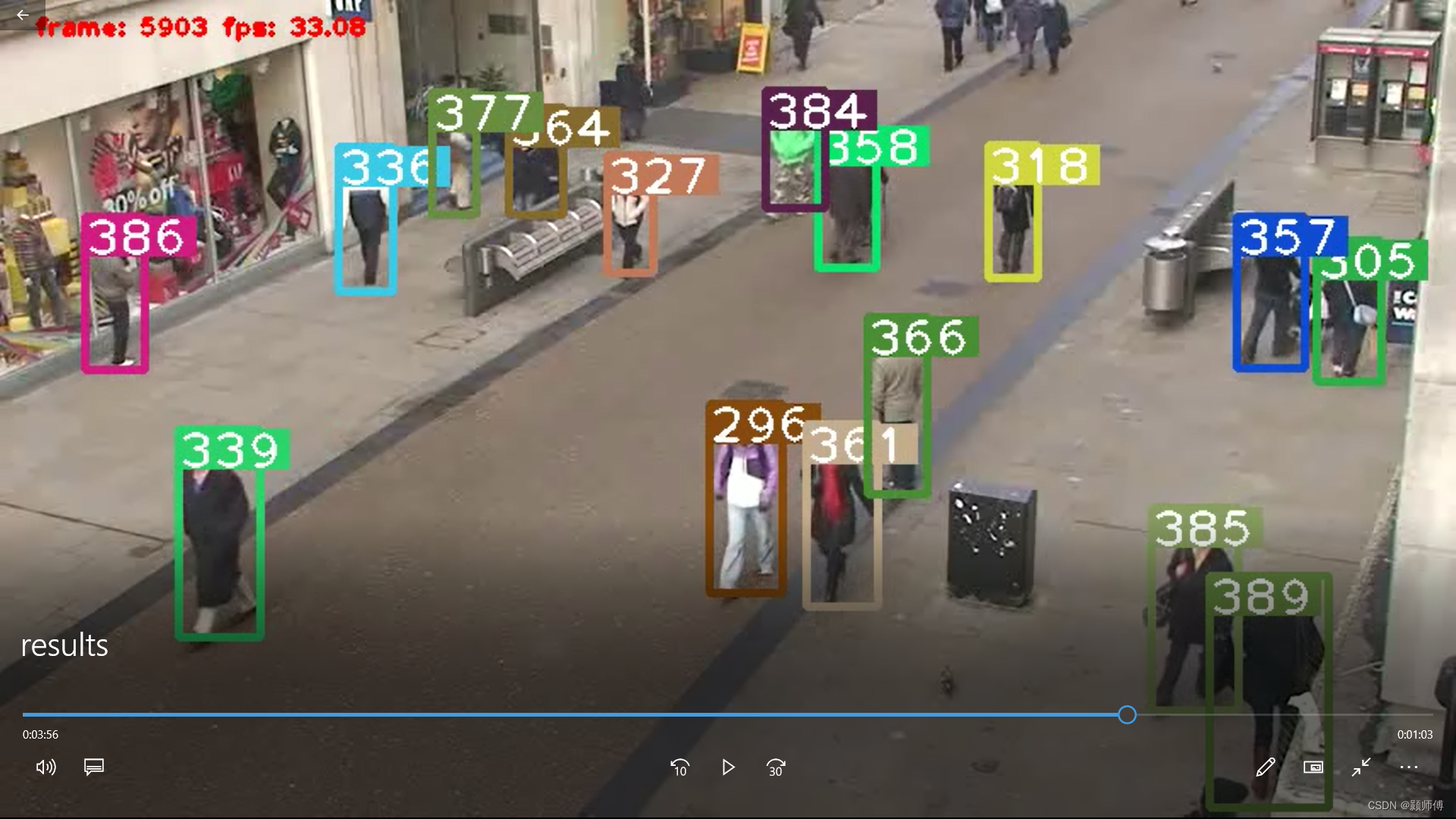
【pytorch】使用deepsort算法进行目标跟踪,原理+pytorch实现
目录deepsort流程一、匈牙利算法二、卡尔曼滤波车速预测例子动态模型的概念卡尔曼滤波在deepsort中的动态模型三、预测值及测量值的含义deepsort在pytorch中的运行deepsort流程 DeepSORT是一种常用的目标跟踪算法,它结合了深度学习和传统的目标跟踪方法。DeepSORT的…...

Python 基础教程【3】:字符串、列表、元组
本文已收录于专栏🌻《Python 基础》文章目录🌕1、字符串🥝1.1 字符串基本操作🍊1.1.1 字符串创建🍊1.1.2 字符串元素读取🍊1.1.3 字符串分片🍊1.1.4 连接和重复🍊1.1.5 关系运算&…...

SuperSplat部署完全指南:从开发到生产环境的终极教程
SuperSplat部署完全指南:从开发到生产环境的终极教程 【免费下载链接】super-splat 3D Gaussian Splat Editor 项目地址: https://gitcode.com/gh_mirrors/su/super-splat SuperSplat是一款基于Web的免费开源3D高斯泼溅编辑器,专为检查、编辑、优…...

51单片机开发环境搭建指南:从Keil5安装到程序烧录全流程
1. 51单片机开发环境搭建全攻略 刚接触51单片机的朋友可能会被一堆陌生的名词搞懵——Keil5、CH340、HEX文件、烧录工具...别担心,我当初也是这样过来的。今天我就用最直白的语言,手把手带你搭建完整的开发环境。整个过程就像组装乐高积木,只…...

Omni-Vision Sanctuary 网络协议分析辅助:可视化网络数据包与流量模式识别
Omni-Vision Sanctuary 网络协议分析辅助:可视化网络数据包与流量模式识别 1. 网络数据可视化的新思路 网络工程师每天面对海量的数据包和流量日志,传统的分析工具往往需要依赖复杂的命令行操作和专业图表解读。而Omni-Vision Sanctuary模型为我们提供…...

GNU Radio滤波器设计中的实时处理优化与性能权衡策略
GNU Radio滤波器设计中的实时处理优化与性能权衡策略 【免费下载链接】gnuradio GNU Radio – the Free and Open Software Radio Ecosystem 项目地址: https://gitcode.com/gh_mirrors/gn/gnuradio 在数字信号处理领域,滤波器设计始终是核心挑战之一&#x…...

VideoSrt:智能字幕生成工具重新定义视频创作效率
VideoSrt:智能字幕生成工具重新定义视频创作效率 【免费下载链接】video-srt-windows 这是一个可以识别视频语音自动生成字幕SRT文件的开源 Windows-GUI 软件工具。 项目地址: https://gitcode.com/gh_mirrors/vi/video-srt-windows VideoSrt是一款基于Golan…...

ClaudeCode 入门详细教程,手把手带你Vibe Coding
本文使用 Mac 进行演示。主要是在安装环节有环境差异。 1. Claude Code 简介 Claude Code 是 Anthropic 推出的面向开发者的 AI 编程协作工具。Claude Code 的核心目标是理解你的整个项目,并参与到真实的编码、修改和重构过程中。Claude Code 不是一个代码生成器&…...

Claude Code桌面控制实战:macOS开启Computer Use指南
Claude Code 的 computer use 功能,是 2026 年 3 月正式上线的原生 macOS 桌面控制能力,让 Claude 可以打开 App、点击、输入、截图,直接在你的真实桌面上完成 GUI 任务。它以内置 MCP 服务器的形式集成到 Claude Code CLI 中,通过…...

实战指南|OpenWrt磁盘扩容全流程解析与避坑技巧
1. 为什么需要给OpenWrt扩容? 很多朋友第一次接触OpenWrt时都会遇到一个尴尬的问题:系统默认分配的存储空间太小了。我自己刚开始用OpenWrt时也踩过这个坑,当时想装个Docker跑点服务,结果发现连最基本的镜像都拉不下来。这就像给…...

Wan2.2-I2V-A14B开源大模型部署:PyTorch 2.4+CUDA 12.4兼容性验证
Wan2.2-I2V-A14B开源大模型部署:PyTorch 2.4CUDA 12.4兼容性验证 1. 镜像概述与核心价值 Wan2.2-I2V-A14B是一款专注于文本到视频生成的开源大模型,其私有部署镜像经过深度优化,能够充分发挥RTX 4090D显卡的性能优势。这个镜像最大的特点在…...

C语言开发者视角:Kandinsky-5.0-I2V-Lite-5s高性能推理引擎调用
C语言开发者视角:Kandinsky-5.0-I2V-Lite-5s高性能推理引擎调用 1. 引言:当静态告警遇上动态生成 想象一下这样的场景:工业监控系统捕捉到设备异常,触发静态告警图片。传统方案中,这张图片需要人工介入分析ÿ…...