【pytorch】使用deepsort算法进行目标跟踪,原理+pytorch实现
目录
- deepsort流程
- 一、匈牙利算法
- 二、卡尔曼滤波
- 车速预测例子
- 动态模型的概念
- 卡尔曼滤波在deepsort中的动态模型
- 三、预测值及测量值的含义
- deepsort在pytorch中的运行
deepsort流程
DeepSORT是一种常用的目标跟踪算法,它结合了深度学习和传统的目标跟踪方法。DeepSORT的核心思想是将深度学习的目标检测结果与传统的目标跟踪器相结合,实现在连续帧之间对目标的跟踪。
DeepSORT主要包括两个部分:目标检测和目标跟踪。对于目标检测,DeepSORT使用现有的目标检测算法,例如YOLO、Faster R-CNN等,来检测出图像中的目标。对于目标跟踪,DeepSORT使用卡尔曼滤波器来预测目标的位置,同时通过匈牙利算法来匹配跟踪目标和检测目标。
具体来说,DeepSORT的目标跟踪过程如下:
对于输入的当前帧,使用目标检测算法检测出所有的目标。
对于之前的每个跟踪目标,使用卡尔曼滤波器预测它在当前帧中的位置。
使用匈牙利算法将检测到的目标与之前的跟踪目标进行匹配,以便为每个跟踪目标分配检测目标。
对于未被分配的检测目标,将其视为新的跟踪目标,并使用卡尔曼滤波器进行位置预测。
对于长时间未被检测到的跟踪目标,将其删除。
重复上述步骤,以进行下一帧的目标跟踪。
总的来说,DeepSORT通过结合目标检测和目标跟踪,能够更加准确地跟踪目标,具有较高的实时性和鲁棒性。
一、匈牙利算法
在DeepSORT中,匈牙利算法用来将前一帧中的跟踪框tracks与当前帧中的检测框detections进行关联,通过外观信息(appearance information)和马氏距离(Mahalanobis distance),或者IOU来计算代价矩阵,通过代价矩阵完成新一帧检测框与原被跟踪对象的最优匹配。即匈牙利算法可以告诉我们当前帧的某个目标,是否与前一帧的某个目标相同。
二、卡尔曼滤波
卡尔曼滤波的核心思想是通过动态模型和测量模型来估计系统的状态。动态模型描述了系统的状态如何随时间变化,测量模型描述了如何将系统的状态转换为测量结果。卡尔曼滤波将这两个模型结合起来,通过状态预测和测量更新来估计系统的状态。
卡尔曼滤波的过程可以分为两个阶段:预测和更新。在预测阶段,卡尔曼滤波器根据动态模型预测系统的状态,并计算出预测误差。在更新阶段,卡尔曼滤波器将预测的状态与测量结果进行比较,计算出状态的估计值和估计误差。卡尔曼滤波器通过不断进行预测和更新,逐步提高对系统状态的估计精度。
卡尔曼滤波的优点在于可以根据系统的动态模型和测量模型来估计状态,可以适应不同的系统和环境。同时,卡尔曼滤波器可以对测量结果进行加权平均,有效抑制测量误差和干扰。不过,卡尔曼滤波的缺点在于需要对系统进行建模,并且对于非线性系统需要进行扩展卡尔曼滤波等变种方法的处理。
卡尔曼滤波被广泛应用于无人机、自动驾驶、卫星导航等领域,简单来说,其作用就是基于传感器的测量值来更新预测值,以达到更精确的估计。
DeepSORT算法使用卡尔曼滤波进行预测的原因是,通过对目标运动状态的建模,能够更加准确地预测目标的未来位置,从而提高目标跟踪的准确性和鲁棒性。
如果不使用卡尔曼滤波进行预测,直接跟踪目标的位置和大小,可能会受到多种因素的影响,例如目标运动的加速度、噪声干扰等等,从而导致目标跟踪的不稳定,容易出现跟踪丢失或误判的情况。而卡尔曼滤波则可以对这些因素进行建模,并对目标的位置、速度等状态进行估计和预测,从而在一定程度上保证目标跟踪的稳定性和准确性。
此外,卡尔曼滤波还能够根据目标的运动特性对跟踪结果进行优化,例如对于匀速直线运动的目标,卡尔曼滤波能够更加准确地预测目标的位置和速度,从而提高跟踪的效果。
车速预测例子
假设你有一个车速传感器,但是由于传感器的误差和外界干扰等原因,传感器测量的车速数据会存在一定程度的误差。现在你希望通过这个传感器测量的数据来估计车辆的真实速度,这时候就可以使用卡尔曼滤波。
卡尔曼滤波的基本思想是将观测数据和模型预测结果加权平均,得到更精确的状态估计结果。因此,在这个例子中,我们可以将车速传感器的测量结果作为观测值,将车速模型预测的结果作为模型预测值,然后使用卡尔曼滤波算法来对两者进行融合,得到更加准确的车速估计值。
具体来说,卡尔曼滤波算法可以分为两个步骤:预测和更新。在预测步骤中,我们使用车速模型来预测当前时刻车速的值和协方差矩阵;在更新步骤中,我们将车速传感器测量的值和预测值进行比较,计算卡尔曼增益,然后使用卡尔曼增益对预测值进行修正,得到当前时刻的最优估计值和协方差矩阵。
通过这种方式,我们可以将传感器测量的数据和模型预测的结果进行融合,得到更加精确的车速估计值,从而提高了行车安全。
动态模型的概念
动态模型指的是描述系统状态随时间变化的数学模型。在卡尔曼滤波中,动态模型通常用状态转移矩阵和控制向量来表示系统状态的演化规律。
状态转移矩阵描述了系统状态在没有控制输入情况下的演化规律,它将当前时刻的状态向量映射到下一时刻的状态向量,表示为:
X_k = F_k * X_{k-1}
其中,X_k和X_{k-1}分别表示第k和第k-1时刻的系统状态向量,F_k为状态转移矩阵。
控制向量描述了外部输入对系统状态的影响,它通常用来修正状态转移矩阵,表示为:
X_k = F_k * X_{k-1} + B_k * u_k
其中,B_k为控制矩阵,u_k为控制向量。
动态模型的建立需要根据具体的系统进行选择和设计,一般需要考虑系统的物理特性、运动规律等因素。在卡尔曼滤波中,动态模型的准确性对滤波器的估计精度有重要影响,因此需要根据实际情况进行适当的调整和优化。
卡尔曼滤波在deepsort中的动态模型
在DeepSORT中,卡尔曼滤波的动态模型是针对目标运动状态建立的。具体来说,DeepSORT使用了一个匀速模型,即假设目标在运动过程中保持匀速运动。在这个假设下,目标的状态向量可以表示为:
X_k = [u, v, s, r, a, b]^T
其中,u和v表示目标在图像平面上的位置,s和r表示目标的大小和纵横比,a和b表示目标的加速度。
状态转移矩阵F_k可以表示为:
F_k = [1, 0, Δt, 0, 0, 0;
0, 1, 0, Δt, 0, 0;
0, 0, 1, 0, 0, 0;
0, 0, 0, 1, 0, 0;
0, 0, 0, 0, 1, 0;
0, 0, 0, 0, 0, 1]
其中,Δt表示两帧之间的时间间隔。
控制向量u_k为0,即没有外部控制影响。
根据上述动态模型,可以使用卡尔曼滤波器预测目标在下一帧中的状态,并计算出预测误差。同时,在更新阶段,可以将预测的状态与测量结果进行比较,计算出状态的估计值和估计误差,从而对目标进行跟踪。
需要注意的是,在实际应用中,动态模型的建立需要根据实际情况进行调整,例如对于不同的目标,可以根据其运动特征和目标跟踪的要求进行相应的优化。
三、预测值及测量值的含义
注意,预测值和测量值都不是真值,卡尔曼滤波最终输出值是对于真值的最优估计值。
预测值:指根据目标的历史状态和运动模型(上一帧的跟踪结果),对目标在当前帧出现的位置进行预测。
测量值:指在当前帧中通过目标检测得到的目标位置和大小信息。‘
在DeepSORT算法中,对于每一帧输入的目标检测结果,首先需要对其进行匹配,将其与之前跟踪的目标进行匹配,得到目标的标识信息以及当前帧中目标的位置和大小信息。然后,需要对这些目标进行预测,得到它们在下一帧中的位置和大小信息。这里的预测值是指在当前帧中通过之前跟踪的目标状态以及卡尔曼滤波来预测下一帧中目标的位置和大小信息。
需要注意的是,预测值和测量值并不是同一帧中的数据。预测值是根据之前的跟踪结果和模型预测出来的目标位置和大小信息,而测量值是当前帧中通过目标检测获取的目标位置和大小信息。因此,预测值和测量值是不同的,它们来自于不同的帧,用于不同的目的。
至于时间概念和帧间关系,DeepSORT算法是一个序列化的算法,需要对每一帧的输入数据进行处理,同时需要考虑到不同帧之间的目标运动状态变化和相邻帧之间的目标位置和大小变化。在进行目标预测和匹配时,需要考虑到这些因素,从而保证目标跟踪的连续性和准确性。因此,时间概念和帧间关系是DeepSORT算法中非常重要的概念。
检测器得到bbox → 生成detections → 卡尔曼滤波预测→ 使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(级联匹配和IOU匹配) → 卡尔曼滤波更新
例子:
Frame 0:检测器检测到了3个detections,当前没有任何tracks,将这3个detections初始化为tracks
Frame 1:检测器又检测到了3个detections,对于Frame 0中的tracks,先进行预测得到新的tracks,然后使用匈牙利算法将新的tracks与detections进行匹配,得到(track, detection)匹配对,最后用每对中的detection更新对应的track
deepsort在pytorch中的运行
下载https://github.com/HowieMa/DeepSORT_YOLOv5_Pytorch.git相关代码。
在base内已经装有pytorch环境,配置详见:
pytorch的docker环境的安装
conda create -n deepsort --clone base
conda activate deepsort
将清华源替换后,安装一个requirements.txt:
pip install -r requirements.txt
安装依赖库:
sudo apt-get install libgl1-mesa-glx
解决报错:
(1)在upsampling.py中报错行改为:return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners)
(2)报错行self.update(yaml.load(fo.read()))改为self.update(yaml.load(fo, Loader=yaml.FullLoader))
工程main.py中的视频源文件改为:
parser.add_argument('--input_path', type=str, default='/home/DeepSORT_YOLOv5_Pytorch-master/001.avi', help='source')
即可运行demo:
python3 main.py
相关文章:
【pytorch】使用deepsort算法进行目标跟踪,原理+pytorch实现
目录deepsort流程一、匈牙利算法二、卡尔曼滤波车速预测例子动态模型的概念卡尔曼滤波在deepsort中的动态模型三、预测值及测量值的含义deepsort在pytorch中的运行deepsort流程 DeepSORT是一种常用的目标跟踪算法,它结合了深度学习和传统的目标跟踪方法。DeepSORT的…...

Python 基础教程【3】:字符串、列表、元组
本文已收录于专栏🌻《Python 基础》文章目录🌕1、字符串🥝1.1 字符串基本操作🍊1.1.1 字符串创建🍊1.1.2 字符串元素读取🍊1.1.3 字符串分片🍊1.1.4 连接和重复🍊1.1.5 关系运算&…...
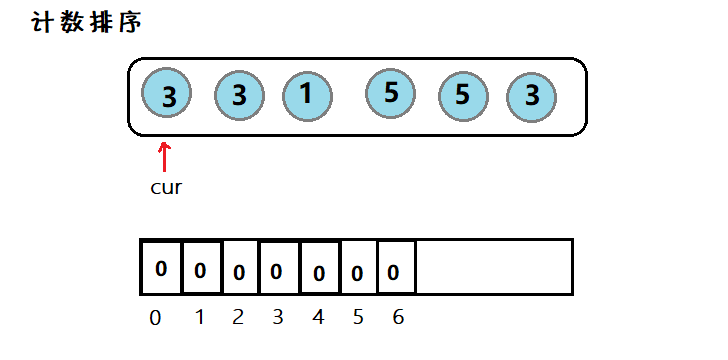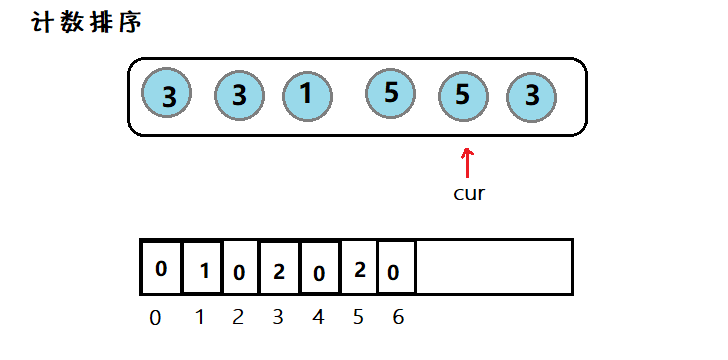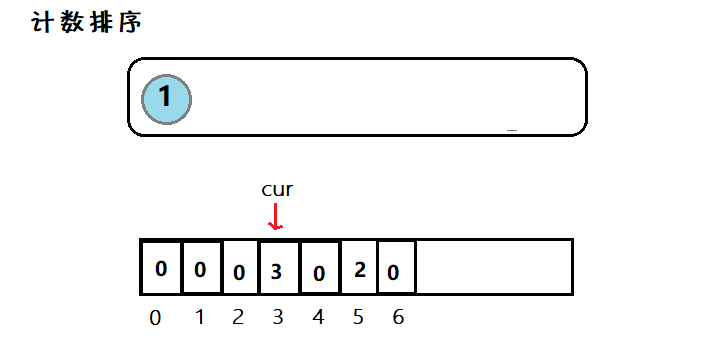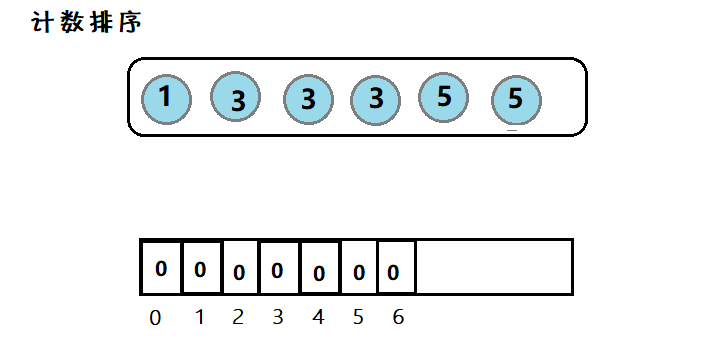
(数据结构)八大排序算法
目录一、常见排序算法二、实现1. 直接插入排序2.🌟希尔排序3. 选择排序4.🌟堆排序5. 冒泡排序7. 🌟快速排序7.1 其他版本的快排7.2 优化7.3 ⭐非递归7. 🌟归并排序7.1 ⭐非递归8. 计数排序三、总结1. 分析排序 (Sorting) 是计算机…...
构建GRE隧道打通不同云商的云主机内网
文章目录1. 环境介绍2 GRE隧道搭建2.1 华为云 GRE 隧道安装2.2 阿里云 GRE 隧道安装3. 设置安全组4. 验证GRE隧道4.1 在华为云上 ping 阿里云云主机内网IP4.2 在阿里云上 ping 华为云云主机内网IP5. 总结1. 环境介绍 华为云上有三台云主机,内网 CIDR 是 192.168.0.0…...
48天C++笔试强训 001
作者:小萌新 专栏:笔试强训 作者简介:大二学生 希望能和大家一起进步! 本篇博客简介:讲解48天笔试强训第一天的题目 笔试强训 day1选择题12345678910编程题12选择题 1 以下for循环的执行次数是(ÿ…...
Android 11新增系统服务
1.编写.aidl文件存放位置:frameworks/base/core/java/android/ospackage android.os;interface ISystemVoiceServer {void setHeightVoice(int flag);void setBassVoice(int flag);void setReverbVoice(int flag);}2.将.aidl文件添加到frameworks/base/Android.bp f…...

“你要多弄弄算法”
开始瞎掰 ▽ 2月的第一天,猎头Luna给我推荐了字节的机会,菜鸡我呀,还是有自知之明的,赶忙婉拒:能力有限,抱歉抱歉。 根据我为数不多的和猎头交流的经验,一般猎头都会稍微客套一下:…...

【数据结构】千字深入浅出讲解队列(附原码 | 超详解)
🚀write in front🚀 📝个人主页:认真写博客的夏目浅石. 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:C语言实现数据结构 💬总结:希望你看完…...
)
vue面试题(day04)
vue面试题vue插槽?vue3中如何获取refs,dom对象的方式?vue3中生命周期的和vue2中的区别?说说vue中的diff算法?说说 Vue 中 CSS scoped 的原理?vue3中怎么设置全局变量?Vue中给对象添加新属性时&a…...

自动标注工具 Autolabelimg
原理简介~~ 对于数据量较大的数据集,先对其中一部分图片打标签,Autolabelimg利用已标注好的图片进行训练,并利用训练得到的权重对其余数据进行自动标注,然后保存为xml文件。 一、下载yolov5v6.1 https://github.com/ultralytic…...

2023-03-20干活
transformer复现 from torch.utils.data import Dataset,DataLoader import numpy as np import torch import torch.nn as nn import os import time import math from tqdm import tqdmdef get_data(path,numNone):all_text []all_label []with open(path,"r",e…...
)
Java 注解(详细学习笔记)
注解 注解英文为Annotation Annotation是JDK5引入的新的技术 Annotation的作用: 不是程序本身,可以对程序做出解释可以被其他程序(比如编译器)读取。 Annotation的格式: 注解是以注解名在代码中存在的,还…...

LeetCode:35. 搜索插入位置
🍎道阻且长,行则将至。🍓 🌻算法,不如说它是一种思考方式🍀算法专栏: 👉🏻123 一、🌱35. 搜索插入位置 题目描述:给定一个排序数组和一个目标值&…...

菜鸟刷题Day2
菜鸟刷题Day2 一.判定是否为字符重排:字符重排 描述 给定两个由小写字母组成的字符串 s1 和 s2,请编写一个程序,确定其中一个字符串的字符重新排列后,能否变成另一个字符串。 解题思路: 这题思路与昨天最后两道类似&…...

Selenium基础篇之不打开浏览器运行
文章目录前言一、场景二、设计1.引入库2.引入浏览器配置3.设置无头模式4.启动浏览器实例,添加配置信息5.访问质量分地址6.隐式等待5秒7.定位到输入框8.输入博文地址9.定位到查询按钮10.点击查询按钮11.定位到查询结果模块div12.打印结果13.结束webdriver进程三、结果…...

【数据结构初阶】栈与队列笔试题
前言在我们学习了栈和队列之后,今天来通过几道练习题来巩固一下我们的知识。题目一 用栈实现队列题目链接:232. 用栈实现队列 - 力扣(Leetcode)这道题难度不是很大,重要的是我们对结构认识的考察,由于这篇文…...
【Linux入门篇】操作系统安装、网络配置
目录 🍁Linux详解 🍂1.操作系统 🍂2.操作系统组成 🍂3.操作系统历史 🍂4.常见的Linux系统 🍂5.centos7下载 🍂6.安装centos7 🍁linux初始化配置 🍃1.虚拟机系统安装后操作…...

Selenium:找不到对应的网页元素?常见的一些坑
目录 1. 用Xpath查找数据时无法直接获取节点属性 2. 使用了WebDriverWait以后仍然无法找到元素 2.1. 分辨率原因 2.2. 需要滚动页面 2.3. 由于其他元素的遮挡 1. 用Xpath查找数据时无法直接获取节点属性 通常在我们使用xpath时,可以使用class的方式直接获取节…...
flex布局优化(两端对齐,从左至右)
文章目录前言方式一 nth-child方式二 gap属性方式三 设置margin左右两边为负值总结前言 flex布局是前端常用的布局方式之一,但在使用过程中,我们总是感觉不太方便,因为日常开发中,大多数时候,我们想要的效果是这样的 …...
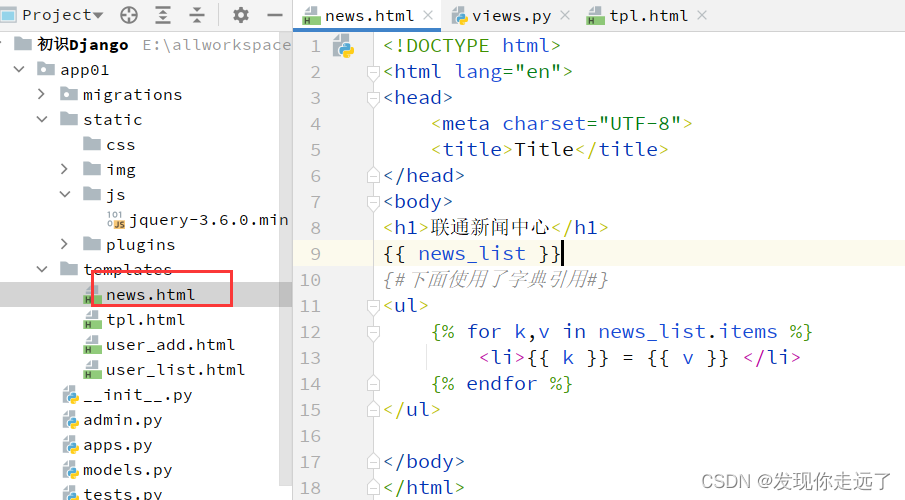
【Django 网页Web开发】03. 初识Django(保姆级图文)
目录1. 命令行创建与pycharm创建的区别2. 项目结构信息2.1 项目结构2.2 项目app结构2.3 快速查看项目结构树3. 创建并注册app3.1 创建app3.2 注册app4. 编写URL与视图的对应关系5. 编写视图文件6. 启动项目7. 写多个页面8. templates模板的使用8.1 编写html文件8.3 导入html文件…...

终极指南:如何使用Harepacker-resurrected打造个性化MapleStory游戏体验
终极指南:如何使用Harepacker-resurrected打造个性化MapleStory游戏体验 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾…...

intv_ai_mk11实际作品:面向管理层的OKR撰写建议与周报优化样例
intv_ai_mk11实际作品:面向管理层的OKR撰写建议与周报优化样例 1. 为什么管理者需要AI辅助撰写OKR和周报 在快节奏的商业环境中,管理者常常面临一个共同挑战:如何高效地制定清晰可衡量的目标(OKR),同时保…...

GitHub开源项目日报 · 2026年3月30日 · 微软开源VibeVoice语音模型登顶,Claude Code生态项目持续火爆
本期榜单涵盖了语音AI、Claude Code辅助编程工具、换脸技术、金融数据平台、在线教育、数据可视化等多个领域的开源项目。超过10000星以上的项目有9个,其中freeCodeCamp以近44万星稳居榜首,Apache Superset、OpenBB、Deep-Live-Cam等项目也获得广泛关注。微软开源的VibeVoice…...

如何彻底解决ComfyUI ControlNet Aux预处理功能异常的5个专业策略
如何彻底解决ComfyUI ControlNet Aux预处理功能异常的5个专业策略 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux ComfyUI ControlNet Aux作为ComfyUI的辅…...

2026年选鱼鹰,哪个厂家更靠谱?一文为你揭晓好用之选!
在水产养殖领域,鱼鹰是一种备受关注的养殖品种,其市场需求也在不断增长。选择一家靠谱的鱼鹰供应厂家至关重要,它不仅关系到鱼鹰的品质和健康,还会影响到养殖的效益和未来发展。在众多的厂家中,济宁百鸿养殖有限公司脱…...

攻克Switch 19.0.1系统Atmosphere启动故障:从诊断到优化的完整方案
攻克Switch 19.0.1系统Atmosphere启动故障:从诊断到优化的完整方案 【免费下载链接】Atmosphere Atmosphre is a work-in-progress customized firmware for the Nintendo Switch. 项目地址: https://gitcode.com/GitHub_Trending/at/Atmosphere 在Switch主机…...

带爱机出国攻略——大机箱反向升级小机箱C28?
大家好,欢迎来到机械大师频道,这不前几天有位粉丝找到我们,说是打算带着自己的爱机出国,但是奈何自己原本的主机实在太大台了,于是想在显卡和内存都不换的情况下,将其他硬件全换了,并且要求机箱…...

Qwen3.5-2B图文理解实战:上传建筑平面图,自动标注房间功能与面积
Qwen3.5-2B图文理解实战:上传建筑平面图,自动标注房间功能与面积 1. 引言:当AI遇见建筑设计 想象一下这样的场景:你刚拿到一张复杂的建筑平面图,需要快速标注每个房间的功能和面积。传统方法可能需要花费数小时手动测…...

Matlab_Simulink与Carsim的联合仿 擅长基于群智能算法优化的LQR、PID控制算法,能清晰讲解其中要点哦。对于基于群智能算法的一般路径规划
Matlab/Simulink与Carsim的联合仿 擅长基于群智能算法优化的LQR、PID控制算法,能清晰讲解其中要点哦。对于基于群智能算法的一般路径规划 稍长智能车轨迹跟踪控制方向 熟悉Matlab/Simulink和Carsim的联合仿真呢。这是一个非常专业且热门的研究方向(群智能…...

为什么选择Drawflow:5大优势让你爱上这个流程图库
为什么选择Drawflow:5大优势让你爱上这个流程图库 【免费下载链接】Drawflow Simple flow library 🖥️🖱️ 项目地址: https://gitcode.com/gh_mirrors/dr/Drawflow Drawflow是一个简单而强大的JavaScript流程图库,专为创…...