2024第五届华数杯数学建模竞赛C题思路+代码
目录
- 原题背景
- 背景分析
- 问题一
- 原题
- 思路
- Step1:数据读取与处理
- Step2:计算最高评分(Best Score, BS)
- Step3:统计各城市的最高评分(BS)景点数量
- 程序
- 读取数据
- 数据预处理
- 问题二
- 原题
- 思路
- Step1: 定义评价指标
- Step2: 收集数据
- Step3: 标准化数据
- Step4: 加权评分
- Step5: 选出前50个城市
- 程序
- 问题三
- 原题
- 思路
- Step1: 数据准备
- Step2: 优化目标
- Step3: 建立模型
- 参考代码
- 问题四
- 原题
- 思路
- Step1:数据准备
- Step2: 优化目标
- Step3: 建立模型
- 参考代码
- 问题五
- 原题
- 思路
- Step1: 数据准备
- Step2: 优化目标
- Step3: 选择入境城市
- Step4: 建立模型
- 程序
原题背景
最近,“city 不 city”这一网络流行语在外国网红的推动下备受关注。随着我国过境免签政策的落实,越来越多外国游客来到中国,通过网络平台展示他们在华旅行的见闻,这不仅推动了中国旅游业的发展,更是在国际舞台上展现了一个 真实而生动的中国,一举多得。
假设外国游客入境后能在中国境内逗留 144 小时,且能从任一城市附近的机场出境。由于每个城市景点较多,为了便于外国游客能够游览到更多的城市,现假定“每个城市只选择一个评分最高的景点游玩”,称之为“城市最佳景点游览原 则”。
现有一个包含中国(不含港澳台)352 个城市的旅游景点的数据集,每个城 市的 csv 文件中有 100
个景点,每个景点的信息包含有景点名称、网址、地址、 景点介绍、开放时间、图片网址、景点评分、建议游玩时长、建议游玩季节、门票信息、小贴士等。
背景分析
提取关键信息:
(1)“城市最佳景点游览原则”:假设外国游客入境后能在中国境内逗留 144 小时,且能从任一城市附近的机场出境。由于每个城市景点较多,为了便于外国游客能够游览到更多的城市,现假定“每个城市只选择一个评分最高的景点游玩”,称之为“城市最佳景点游览原则”。
(2)数据说明:现有一个包含中国(不含港澳台)352 个城市的旅游景点的数据集,每个城 市的 csv 文件中有 100个景点,每个景点的信息包含有景点名称、网址、地址、 景点介绍、开放时间、图片网址、景点评分、建议游玩时长、建议游玩季节、门票信息、小贴士等。
分析题目背景:
本题为了帮助外国游客在有限的时间内游览中国的最佳景点,我们需要利用数据集中的信息进行一些分析和建模。
- 首先根据关键信息(1),我们需要从每个城市的数据集中提取评分最高的景点信息。假设我们已经有了包含352个城市旅游景点的CSV文件。对每个城市,找到评分最高的景点,并记录其信息。我们可以编写一个脚本来处理这些CSV文件,并提取所需的数据。
- 其次,考虑到游客在144小时内需要游览多个城市,并且可能需要在不同城市之间进行交通转换,我们可以使用以下几种数学模型进行优化:
- 旅行商问题 (TSP):
这个问题可以被看作是一个典型的旅行商问题,其中每个城市是一个节点,景点是游客需要访问的地方。目标是找到一个路径,使得总的旅行时间或距离最小,同时确保游客在每个城市的停留时间在合理范围内。 - 时变网络模型:
考虑到不同交通方式(如高铁、飞机)的时间和费用,我们可以构建一个时变网络模型来优化旅行路径和时间。
- 旅行商问题 (TSP):
下面,我们将根据具体的问题进行分析和解答。
问题一
原题
请问 352 个城市中所有 35200 个景点评分的最高分(Best Score,简称 BS)是多少?全国有多少个景点获评了这个最高评分(BS)?获评了这个最高评分(BS)景点最多的城市有哪些?依据拥有最高评分(BS)景点数量的多少排序,列出前 10 个城市。
思路
Step1:数据读取与处理
首先,我们需要读取所有352个城市的CSV文件,并提取每个景点的评分数据。我们可以使用Python中的Pandas库来处理这些数据。
其次,因为数据中存在数据缺失和类型不匹配问题,我们需要将空值剔除或者用0来填补,并将str型数据转换成float型。
Step2:计算最高评分(Best Score, BS)
我们需要遍历所有景点的评分数据,找到最高评分(BS)。然后统计获得最高评分(BS)的景点数量以及这些景点所在的城市。
Step3:统计各城市的最高评分(BS)景点数量
我们需要统计每个城市中获得最高评分(BS)的景点数量,并按数量排序,列出前10个城市。
程序
读取数据
import pandas as pd
import os# 假设所有城市的CSV文件都存储在 "cities_data" 目录下
directory = "./附件"# 用于存储所有景点评分数据
all_sights = []# 遍历每个城市的CSV文件
for filename in os.listdir(directory):if filename.endswith(".csv"):city = filename.split('.')[0]df = pd.read_csv(os.path.join(directory, filename))df['城市'] = cityall_sights.append(df)# 合并所有城市的数据
all_sights_df = pd.concat(all_sights)all_sights_df

数据预处理
处理空值,将空值替换为数字0
将数据中的评分列转为数值型
# ValueError: could not convert string to float: '--
all_sights_df['评分'] = pd.to_numeric(all_sights_df['评分'], errors='coerce')
# Convert '评分' column from object to float
all_sights_df['评分'] = all_sights_df['评分'].astype(float)

寻找最终答案并输出结果:
# 找到最高评分(BS)
best_score = all_sights_df['评分'].max()# 统计获得最高评分(BS)的景点数量
best_sights = all_sights_df[all_sights_df['评分'] == best_score]
best_sights_count = best_sights.shape[0]# 统计每个城市中获得最高评分(BS)的景点数量
city_best_sights_count = best_sights['城市'].value_counts()# 找到拥有最高评分(BS)景点数量最多的前10个城市
top_10_cities = city_best_sights_count.head(10)# 输出结果
print(f"最高评分(BS)为:{best_score}")
print(f"全国共有 {best_sights_count} 个景点获得最高评分(BS)")
print("拥有最高评分(BS)景点最多的前10个城市为:")
print(top_10_cities)

问题二
原题
假如外国游客遵循“城市最佳景点游览原则”,结合城市规模、环境环保、人文底蕴、交通便利,以及气候、美食等因素,请你对 352 个城市进行综合评价,选出“最令外国游客向往的 50 个城市”。
思路
要对352个城市进行综合评价,选出“最令外国游客向往的50个城市”,我们需要建立一个多因素评价模型。这些因素包括城市规模、环境环保、人文底蕴、交通便利、气候、美食等。我们可以通过加权评分的方法来综合评估这些城市。
Step1: 定义评价指标
- 城市规模:可以用城市人口或GDP来衡量。
- 环境环保:可以用PM2.5平均浓度或城市绿化率来衡量。
- 人文底蕴:可以用历史遗迹数量、博物馆数量等来衡量。
- 交通便利:可以用公共交通覆盖率、交通便捷性等来衡量。
- 气候:可以用气候舒适度指数来衡量。
- 美食:可以用美食评价、餐厅数量等来衡量。
Step2: 收集数据
假设我们已经收集了上述指标的数据,可以用一个CSV文件来表示,其中每一列代表一个城市,每一列代表一个评价指标。
因为在原始的数据文件中指包含地点名称、网址、地址、景点介绍、开放时间、图片网址、评分、建议游玩时长、建议游玩季节、门票信息、小贴士等。并没有题目中的城市规模、环境保护、人文底蕴等信息,所以这部分数据需要我们自己补充。
Step3: 标准化数据
由于各个指标的量纲不同,需要对数据进行标准化处理。
Step4: 加权评分
给每个指标分配权重,根据加权评分计算每个城市的综合评分。
Step5: 选出前50个城市
根据综合评分进行排序,选出前50个城市。
程序
import pandas as pd
from sklearn.preprocessing import MinMaxScaler# 假设已经有一个包含所有城市及其各个评价指标的CSV文件
data = pd.read_csv('city_evaluation_data.csv')# 定义各个评价指标的权重
weights = {'城市规模': 0.2,'环境环保': 0.2,'人文底蕴': 0.2,'交通便利': 0.2,'气候': 0.1,'美食': 0.1
}# 对数据进行标准化处理
scaler = MinMaxScaler()
normalized_data = pd.DataFrame(scaler.fit_transform(data[list(weights.keys())]), columns=list(weights.keys()))# 计算综合评分
normalized_data['综合评分'] = 0
for key in weights.keys():normalized_data['综合评分'] += normalized_data[key] * weights[key]# 将综合评分添加回原始数据
data['综合评分'] = normalized_data['综合评分']# 根据综合评分进行排序,选出前50个城市
top_50_cities = data.sort_values(by='综合评分', ascending=False).head(50)import ace_tools as tools; tools.display_dataframe_to_user(name="Top 50 Cities for Foreign Tourists", dataframe=top_50_cities)# 输出结果
print("最令外国游客向往的前50个城市为:")
print(top_50_cities[['城市', '综合评分']])问题三
原题
现有一名外国游客从广州入境,他想在 144 小时以内游玩尽可能多的城市,同时要求综合游玩体验最好,请你规划他的游玩路线。需要结合游客的要求给出具体的游玩路线,包括总花费时间,门票和交通的总费用以及可以游玩的景点数量。他的要求有:
- ① 遵循城市最佳景点游览原则;
- ② 城市之间的交通方式只选择高铁;
- ③ 只在“最令外国游客向往的 50 个城市”中选择要游玩的城市。
思路
为了解决这个问题,我们需要建立一个优化模型,该模型考虑了游客的需求、时间限制以及交通方式。以下是具体步骤:
Step1: 数据准备
- 城市数据:包括“最令外国游客向往的50个城市”以及每个城市的最佳景点。
- 高铁交通数据:包括城市之间的高铁行程时间和费用。
- 景点数据:包括每个城市最佳景点的门票费用和游玩时间。
Step2: 优化目标
我们的目标是在144小时内最大化游客能够游玩的城市数量,同时保证综合游玩体验最佳。这可以通过以下步骤实现:
- 定义时间约束:包括每个城市的游玩时间和城市之间的交通时间,确保总时间不超过144小时。
- 综合评分:根据前面定义的综合评分标准,确保选择的城市能够提供最佳的游玩体验。
- 费用计算:计算总花费,包括门票费用和高铁交通费用。
Step3: 建立模型
我们可以使用整数规划(Integer Programming)来解决这个优化问题。
为了建立问题3的模型,我们需要优化外国游客在144小时内游览尽可能多的城市,同时使综合游玩体验最好。这个问题可以通过整数规划(Integer Programming)来解决。以下是模型的详细步骤、公式和Python代码实现。
-
数据准备:
- 从数据集中读取“最令外国游客向往的50个城市”及其最佳景点的信息。
- 获取城市之间的高铁交通时间和费用。
-
定义决策变量:
- x i x_i xi:表示是否选择城市 i i i(1 表示选择,0 表示不选择)。
-
定义约束条件:
- 总游玩时间不超过144小时。
-
定义目标函数:
- 最大化游客可以游览的城市数量,同时综合考虑游玩体验。
模型公式:
-
决策变量:
- x i x_i xi:城市 i i i 是否被选择游览, x i ∈ { 0 , 1 } x_i \in \{0, 1\} xi∈{0,1}。
-
约束条件:
- 总游玩时间不超过144小时:
∑ i = 1 n ( t t r a v e l , i + t s i g h t , i ) ⋅ x i ≤ 144 \sum_{i=1}^{n} (t_{travel, i} + t_{sight, i}) \cdot x_i \leq 144 i=1∑n(ttravel,i+tsight,i)⋅xi≤144
其中 t t r a v e l , i t_{travel, i} ttravel,i 是从当前城市到城市 i i i 的旅行时间, t s i g h t , i t_{sight, i} tsight,i 是城市 i i i 的游玩时间。
- 总游玩时间不超过144小时:
-
目标函数:
- 最大化游览城市数量,并考虑游玩体验评分:
Maximize ∑ i = 1 n ( s i ⋅ x i ) \text{Maximize} \quad \sum_{i=1}^{n} (s_i \cdot x_i) Maximizei=1∑n(si⋅xi)
其中 s i s_i si 是城市 i i i 的综合评分。
- 最大化游览城市数量,并考虑游玩体验评分:
参考代码
import pandas as pd
from ortools.linear_solver import pywraplp# 读取数据
top_50_cities = pd.read_csv('top_50_cities.csv') # 包含最令外国游客向往的50个城市及其综合评分
high_speed_rail = pd.read_csv('high_speed_rail.csv') # 包含城市之间的高铁交通时间和费用
city_best_sights = pd.read_csv('city_best_sights.csv') # 包含每个城市最佳景点的游玩时间和门票费用# 初始化模型
solver = pywraplp.Solver.CreateSolver('SCIP')# 定义变量
cities = top_50_cities['城市'].tolist()
n = len(cities)
x = {}
for i in range(n):x[i] = solver.IntVar(0, 1, f'x[{i}]')# 时间和费用数据
travel_time = high_speed_rail.set_index('目的地')['时间'].to_dict()
sight_time = city_best_sights.set_index('城市')['建议游玩时长'].to_dict()
sight_cost = city_best_sights.set_index('城市')['门票费用'].to_dict()
city_score = top_50_cities.set_index('城市')['综合评分'].to_dict()# 定义约束条件:时间限制
time_limit = 144 # 小时
time_constraints = solver.Constraint(0, time_limit)
for i in range(n):city = cities[i]time_constraints.SetCoefficient(x[i], travel_time.get(city, 0) + sight_time.get(city, 0))# 定义目标函数:最大化综合游玩体验(评分)
objective = solver.Objective()
for i in range(n):city = cities[i]objective.SetCoefficient(x[i], city_score[city])
objective.SetMaximization()# 求解模型
status = solver.Solve()if status == pywraplp.Solver.OPTIMAL:total_time = 0total_cost = 0total_sights = 0visited_cities = []for i in range(n):if x[i].solution_value() == 1:city = cities[i]total_time += travel_time.get(city, 0) + sight_time.get(city, 0)total_cost += sight_cost.get(city, 0)total_sights += 1visited_cities.append(city)print("总游玩时间:", total_time, "小时")print("总费用:", total_cost, "元")print("总游玩景点数量:", total_sights, "个")print("游玩城市列表:", visited_cities)
else:print("No optimal solution found.")# 显示数据框
import ace_tools as tools; tools.display_dataframe_to_user(name="Top 50 Cities for Foreign Tourists", dataframe=top_50_cities)问题四
原题
如果将问题 3 的游览目标改为:既要尽可能的游览更多的城市,又需要使门票和交通的总费用尽可能的少。请重新规划游玩路线,并给出门票和交通的总费用,总花费时间以及可以游玩的城市数量。
思路
Step1:数据准备
假设我们仍然有相同的数据集,包括“最令外国游客向往的50个城市”及其相关信息。
Step2: 优化目标
- 最大化游玩城市数量:通过整数规划来选择尽可能多的城市。
- 最小化费用:在第一个目标的基础上,最小化门票和交通的总费用。
Step3: 建立模型
-
数据准备:
- 从数据集中读取“最令外国游客向往的50个城市”及其最佳景点的信息。
- 获取城市之间的高铁交通时间和费用。
-
定义决策变量:
- x i x_i xi:表示是否选择城市 i i i(1 表示选择,0 表示不选择)。
-
定义约束条件:
- 总游玩时间不超过144小时。
-
定义目标函数:
- 在144小时内,最大化游览城市数量,并最小化总费用。
模型公式:
-
决策变量:
- x i x_i xi:城市 i i i是否被选择游览, x i ∈ { 0 , 1 } x_i \in \{0, 1\} xi∈{0,1}。
-
约束条件:
- 总游玩时间不超过144小时:
∑ i = 1 n ( t t r a v e l , i + t s i g h t , i ) ⋅ x i ≤ 144 \sum_{i=1}^{n} (t_{travel, i} + t_{sight, i}) \cdot x_i \leq 144 i=1∑n(ttravel,i+tsight,i)⋅xi≤144
- 总游玩时间不超过144小时:
-
目标函数:
- 最大化游览城市数量,并最小化费用:
Maximize ∑ i = 1 n x i − λ ( ∑ i = 1 n ( c t r a v e l , i + c s i g h t , i ) ⋅ x i ) \text{Maximize} \quad \sum_{i=1}^{n} x_i - \lambda \left( \sum_{i=1}^{n} (c_{travel, i} + c_{sight, i}) \cdot x_i \right) Maximizei=1∑nxi−λ(i=1∑n(ctravel,i+csight,i)⋅xi)
其中: - λ \lambda λ 是一个调整参数,用于平衡游览数量和费用之间的权重。
- c t r a v e l , i c_{travel, i} ctravel,i 是城市 i i i 的交通费用。
- c s i g h t , i c_{sight, i} csight,i 是城市 i i i 的门票费用。
- 最大化游览城市数量,并最小化费用:
参考代码
import pandas as pd
from ortools.linear_solver import pywraplp# 读取数据
top_50_cities = pd.read_csv('top_50_cities.csv') # 包含最令外国游客向往的50个城市及其综合评分
high_speed_rail = pd.read_csv('high_speed_rail.csv') # 包含城市之间的高铁交通时间和费用
city_best_sights = pd.read_csv('city_best_sights.csv') # 包含每个城市最佳景点的游玩时间和门票费用# 初始化模型
solver = pywraplp.Solver.CreateSolver('SCIP')# 定义变量
cities = top_50_cities['城市'].tolist()
n = len(cities)
x = {}
for i in range(n):x[i] = solver.IntVar(0, 1, f'x[{i}]')# 时间和费用数据
travel_time = high_speed_rail.set_index('目的地')['时间'].to_dict()
travel_cost = high_speed_rail.set_index('目的地')['费用'].to_dict()
sight_time = city_best_sights.set_index('城市')['建议游玩时长'].to_dict()
sight_cost = city_best_sights.set_index('城市')['门票费用'].to_dict()# 定义约束条件:时间限制
time_limit = 144 # 小时
time_constraints = solver.Constraint(0, time_limit)
for i in range(n):city = cities[i]time_constraints.SetCoefficient(x[i], travel_time.get(city, 0) + sight_time.get(city, 0))# 定义目标函数:最大化游览城市数量,并最小化费用
# 这里我们使用一个权重参数 lambda 来平衡两者
lambda_weight = 0.01
objective = solver.Objective()
for i in range(n):objective.SetCoefficient(x[i], 1 - lambda_weight * (travel_cost.get(cities[i], 0) + sight_cost.get(cities[i], 0)))
objective.SetMaximization()# 求解模型
status = solver.Solve()if status == pywraplp.Solver.OPTIMAL:total_time = 0total_cost = 0total_sights = 0visited_cities = []for i in range(n):if x[i].solution_value() == 1:city = cities[i]total_time += travel_time.get(city, 0) + sight_time.get(city, 0)total_cost += travel_cost.get(city, 0) + sight_cost.get(city, 0)total_sights += 1visited_cities.append(city)print("总游玩时间:", total_time, "小时")print("总费用:", total_cost, "元")print("总游玩景点数量:", total_sights, "个")print("游玩城市列表:", visited_cities)
else:print("No optimal solution found.")# 显示数据框
import ace_tools as tools; tools.display_dataframe_to_user(name="Top 50 Cities for Foreign Tourists", dataframe=top_50_cities)问题五
原题
现有一名外国游客只想游览中国的山景,他乘飞机入境中国的城市不限。请你为他选择入境的机场和城市,并个性化定制他的 144 小时旅游路线,既要尽可能的游览更多的山,又需要使门票和交通的总费用尽可能的少。需要结合游客的要求给出具体的游玩路线,包括总花费时间,门票和交通的总费用以及可以游玩的景点数量。他的要求有:
- ① 每个城市只游玩一座评分最高的山;
- ② 城市之间的交通方式只选择高铁;
- ③ 旅游城市不局限于“最令外国游客向往的 50 个城市”,游览范围拓展到
352 个城市。
思路
为了帮助这名外国游客在144小时内游览尽可能多的山景,并且在控制费用的情况下选择最佳路线,我们需要建立一个多目标优化模型。以下是具体步骤:
Step1: 数据准备
- 城市和山景数据:包括352个城市及其评分最高的山景、游玩时间、门票费用等信息。
- 高铁交通数据:包括城市之间的高铁行程时间和费用。
- 机场数据:包括352个城市中主要机场的位置和信息。
Step2: 优化目标
- 最大化游览山景数量:尽可能多地游览不同城市的评分最高的山景。
- 最小化费用:在游览尽可能多山景的基础上,最小化总的门票和交通费用。
Step3: 选择入境城市
选择入境城市的策略可以基于入境城市到其他城市的高铁交通便利性和山景的分布情况。
Step4: 建立模型
我们同样可以使用整数规划(Integer Programming)来解决这个优化问题。
程序
如果需要更多详细代码,请把上述思路复制粘贴到川川gpt网站 传送门
相关文章:
2024第五届华数杯数学建模竞赛C题思路+代码
目录 原题背景背景分析 问题一原题思路Step1:数据读取与处理Step2:计算最高评分(Best Score, BS)Step3:统计各城市的最高评分(BS)景点数量 程序读取数据数据预处理 问题二原题思路Step1: 定义评价指标Step2: 收集数据Step3: 标准化…...

FFmpeg源码:av_reduce函数分析
AVRational结构体和其相关的函数分析: FFmpeg有理数相关的源码:AVRational结构体和其相关的函数分析 FFmpeg源码:av_reduce函数分析 一、av_reduce函数的声明 av_reduce函数声明在FFmpeg源码(本文演示用的FFmpeg源码版本为7.0…...

nginx: [error] open() “/run/nginx.pid“ failed (2: No such file or directory)
今天 准备访问下Nginx服务,但是 启动时出现如下报错:(80端口被占用,没有找到nginx.pid文件) 解决思路: 1、 查看下排查下nginx服务 #确认下nginx状态 ps -ef|grep nginx systemctl status nginx#查看端口…...

<数据集>BDD100K人车识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:15807张 标注数量(xml文件个数):15807 标注数量(txt文件个数):15807 标注类别数:7 标注类别名称: [pedestrian, car, bus, rider, motorcycle, truck, bicycle] 序号…...

利用SSE打造极简web聊天室
在B/S场景中,通常我们前端主动访问后端可以使用axios,效果很理想,而后端要访问前端则不能这样操作了,可以考虑SSE、websocket等方式,实时和性能均有保障。 下面给出一个简单的SSE例子,后端是nodeexpress&am…...
)
代码随想录第二十天|动态规划(4)
目录 LeetCode 322. 零钱兑换 LeetCode 279. 完全平方数 LeetCode 139. 单词拆分 总结 LeetCode 322. 零钱兑换 题目链接:LeetCode 322. 零钱兑换 思想:首先定义dp数组的含义,dp[j]即总金额为j的情况下所需的最少的硬币个数。接下来确定…...

TreeSize:免费的磁盘清理与管理神器,解决C盘爆满的燃眉之急
目录 TreeSize:免费的磁盘清理与管理神器,解决C盘爆满的燃眉之急 一、TreeSize介绍 二、下载安装TreeSize 2.1、下载地址 2.2、下载步骤 2.3、安装步骤 三、professional版的TreeSize试用 3.1、分析磁盘空间 3.2、显示拓展名统计信息 3.3、显…...

如何建立自己的技术知识体系
已经工作五年了,慢慢的觉得不能再继续像以前一样,工作中用到啥才去学啥,平时积累的知识也是非常的零碎,我现在要做的就是建立自己的技术知识体系。 我感觉学习技术知识就想是探索一个城市一样,技术知识体系就好比是这…...

JS优化了4个自定义倒计时
<!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><title>4个自定义倒计时</title><style>* {margin: 0;padding: 0;box-sizing: border-box;user-select: none;body {background: #0b1b2c;}}hea…...

模型实战(25)之 基于LoFTR深度学习匹配算法实现图像拼接
模型实战(25)之 基于LoFTR深度学习匹配算法实现图像拼接 图像拼接在全景图、大图或者多目场景下经常会被使用,常用的方法有传统图像处理算法和深度学习直接获取对应点的算法传统图像处理算法过程繁琐,阈值少且整体算法结果对调参比较敏感,其主要通过形状、特征点等描述子对…...

计算机毕业设计Python+Spark知识图谱高考志愿推荐系统 高考数据分析 高考可视化 高考大数据 大数据毕业设计
《Spark高考推荐系统》开题报告 一、选题背景及意义 1. 选题背景 随着我国高考制度的不断完善和大数据技术的飞速发展,高考志愿填报已成为考生和家长高度关注的重要环节。传统的志愿填报方式依赖于考生和家长手动查找和对比各种信息,不仅效率低下且容…...

【python】文件
在python中可以通过文件操作,将数据保存到计算机硬盘中文件,可以包含文本数据,也可以包含二进制数据(图片,视频,音频等)。 目录 前言 正文 一、基本语法 1、函数open()打开file 返回一个文件对象 1.1、文件路径 1&a…...

《Attention Is All You Need》核心观点及概念
这个文件据说是一篇很厉害的AI论文,https://arxiv.org/pdf/1706.03762 这篇论文《Attention Is All You Need》确实是AI领域中的一个里程碑,它改变了我们处理语言的方式。 下面小编会用简单的语言来解释这篇文章的核心观点和学术概念,并告诉大家它为什么很厉害。 核心观点…...

【中项】系统集成项目管理工程师-第9章 项目管理概论-9.9价值交付系统
前言:系统集成项目管理工程师专业,现分享一些教材知识点。觉得文章还不错的喜欢点赞收藏的同时帮忙点点关注。 软考同样是国家人社部和工信部组织的国家级考试,全称为“全国计算机与软件专业技术资格(水平)考试”&…...
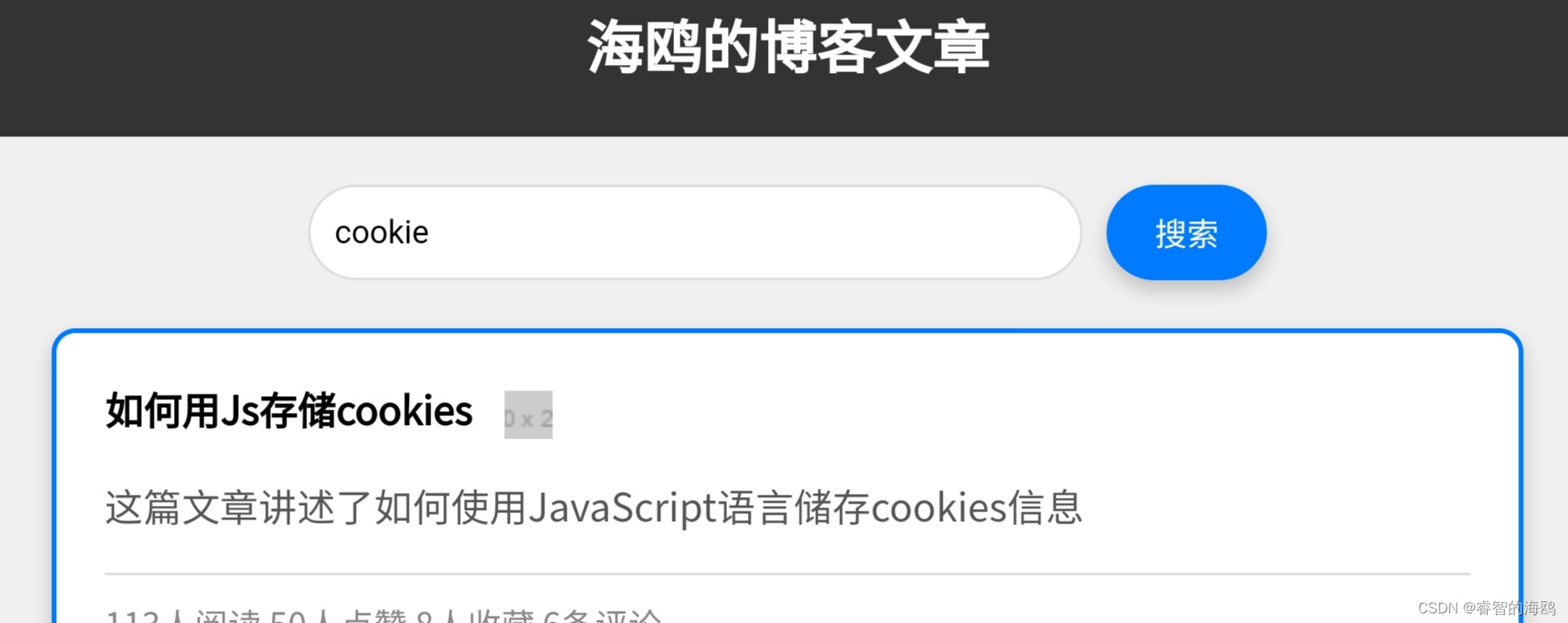
JS+H5美观的带搜索的博客文章列表(可搜索多个参数)
实现 美观的界面(电脑、手机端界面正常使用)多参数搜索(文章标题,文章简介,文章发布时间等)文章链接跳转 效果图 手机端 电脑端 搜索实现 搜索功能实现解释 定义文章数据: 文章数据保存在一个 JavaScri…...
)
牛客周赛 Round 54 (c++题解)
比赛地址 : 牛客竞赛_ACM/NOI/CSP/CCPC/ICPC算法编程高难度练习赛_牛客竞赛OJ A 输出o的个数; #include<bits/stdc.h> #define IOS ios::sync_with_stdio(0);cin.tie(0);cout.tie(0); #define endl \n using namespace std; typedef long long LL;inlin…...

htsjdk库Genotype及相关类介绍
在 HTSJDK 库中,处理基因型的主要类包括 Genotype、FastGenotype、GenotypeBuilder 以及相关的类和接口。以下是这些类和接口的详细介绍: Genotype 类 主要功能 表示基因型:Genotype 类用于表示个体在特定变异位置上的基因型。基因型是对个体在变异位置上的等位基因组合的…...
 洛谷)
C++ 最短路(spfa) 洛谷
拉近距离 题目背景 我是源点,你是终点。我们之间有负权环。 ——小明 题目描述 在小明和小红的生活中,有 N 个关键的节点。有 M 个事件,记为一个三元组 (Si,Ti,Wi),表示从节点 Si 有一个事件可以转移到 Ti,事件…...

MySQL的数据类型
文章目录 数据类型分类整型bit类型浮点类型字符串类型charvarchar 日期和时间类型enum和set find_ in_ set 数据类型分类 整型 在MySQL中,整型可以指定是有符号的和无符号的,默认是有符号的。 可以通过UNSIGNED来说明某个字段是无符号的。 在MySQL中如…...

xss漏洞(四,xss常见类型)
本文仅作为学习参考使用,本文作者对任何使用本文进行渗透攻击破坏不负任何责任。 前言: 1,本文基于dvwa靶场以及PHP study进行操作,靶场具体搭建参考上一篇: xss漏洞(二,xss靶场搭建以及简单…...
)
2026软考高项论文题目预测!十大管理+绩效域双押题(附答题思路)
备考软考高项的同学都知道,论文是决定成败的关键一科。随着2025年绩效域全面上位,论文考核方式已从“单一知识点”升级为“绩效域协同五大过程组联动可量化测量指标”的实战型命题。2026年考什么?如何准备?本文基于近3年命题规律&…...

基于Qwen3-ASR的智能会议纪要系统:从语音识别到文本摘要全流程
基于Qwen3-ASR的智能会议纪要系统:从语音识别到文本摘要全流程 1. 系统整体效果展示 今天给大家展示一个基于Qwen3-ASR-1.7B语音识别模型构建的智能会议纪要系统。这个系统不仅能准确识别会议中的语音内容,还能自动区分不同说话人,提取关键…...

Ostrakon-VL处理网络协议:从数据包捕获文件可视化网络流量
Ostrakon-VL处理网络协议:从数据包捕获文件可视化网络流量 1. 网络流量分析的痛点与机遇 网络工程师每天都要面对海量的网络数据包,传统的分析工具虽然功能强大,但存在几个明显痛点: 数据量大:一个中等规模企业的日…...

合规刚需下,游戏行业适合的内网通讯软件怎么选
一、背景 2026年,游戏行业在合规监管、信创推进与降本增效三重驱动下,内部协作与数据安全需求持续升级。《数据安全法》《网络安全法》对游戏企业研发代码、运营数据、用户信息的存储与传输提出明确合规要求,数据泄露、权限失控、协作低效等…...

GLM-4.1V-9B-Base开源大模型:面向中文场景优化的轻量级视觉理解基座
GLM-4.1V-9B-Base开源大模型:面向中文场景优化的轻量级视觉理解基座 1. 模型概述 GLM-4.1V-9B-Base是智谱AI开源的一款专注于视觉多模态理解的基础模型,特别针对中文场景进行了优化。这个9B参数的轻量级模型在保持高效推理能力的同时,提供了…...

seo优化一个月大概要花费多少_seo 优化一个月需要多少预算
SEO 优化一个月需要多少预算:详细分析与实用建议 在当今的数字时代,网站的SEO优化是提升网站流量和品牌知名度的关键。SEO 优化一个月大概要花费多少,SEO 优化一个月需要多少预算呢?这个问题困扰着许多企业和个人。本文将从问题分…...
万象视界灵坛保姆级教程:Bright-Pixel UI下上传图片+输入神谕标签全流程
万象视界灵坛保姆级教程:Bright-Pixel UI下上传图片输入神谕标签全流程 1. 教程概述 万象视界灵坛是一款基于OpenAI CLIP技术的高级多模态智能感知平台,通过独特的Bright-Pixel UI设计,将复杂的图像语义分析转化为直观有趣的交互体验。本教…...

ESP32/ESP8266轻量级MQTT连接管理库espMqttManager
1. 项目概述espMqttManager是一个面向 ESP32/ESP8266 平台、基于 Arduino 框架的轻量级 MQTT 连接管理库。它并非独立 MQTT 协议栈,而是对espMqttClient(由marvinroger 开发的高性能异步 MQTT 客户端)进行工程化封装的“胶水层”,…...
)
告别PX4,试试APM!用ArduPilot+Gazebo搭建你的第一个无人机仿真环境(附QGC地面站连接)
从PX4到APM:ArduPilot无人机仿真环境全攻略 如果你已经熟悉PX4生态,却对ArduPilot(APM)固件在仿真领域的表现充满好奇,这篇文章将为你打开一扇新的大门。不同于市面上大量聚焦PX4的教程,我们将深入探讨APM在…...

GCC编译选项详解与优化技巧
1. GCC编译选项核心功能解析作为Linux环境下最常用的编译器套件,GCC的编译选项直接影响着代码的生成质量与运行效率。在实际开发中,合理配置编译选项往往能达到事半功倍的效果。本文将系统梳理GCC的核心编译选项,重点解析那些容易被忽视但极具…...