Kafka和RabbitMQ有哪些区别,各自适合什么场景?
目录标题
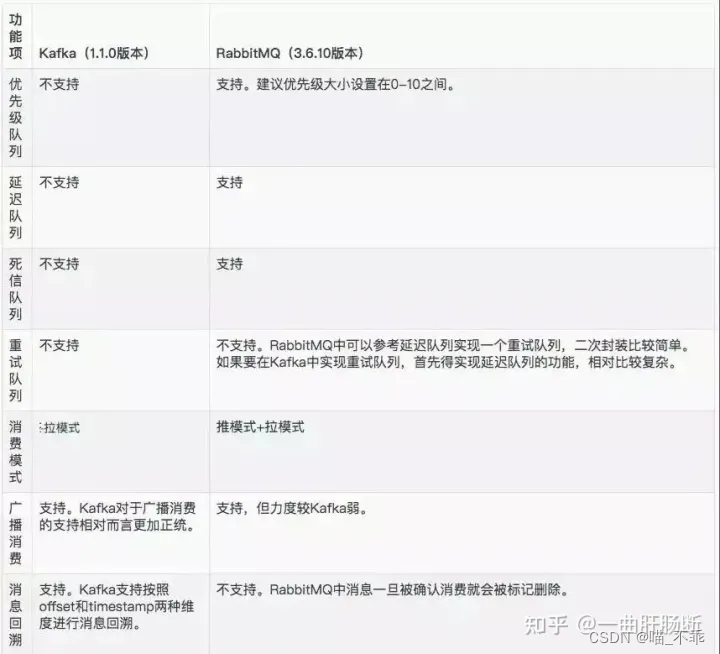
- 1. 消息的顺序
- 2. 消息的匹配
- 3. 消息的超时
- 4. 消息的保持
- 5. 消息的错误处理
- 6. 消息的吞吐量
- 总结
1. 消息的顺序
有这样一个需求:当订单状态变化的时候,把订单状态变化的消息发送给所有关心订单变化的系统。
订单会有创建成功、待付款、已支付、已发货的状态,状态之间是单向流动的。
好,现在我们把订单状态变化消息要发送给所有关心订单状态的系统上去,实现方式就是用消息队列。
在这种业务下,我们最想要的是什么?
消息的顺序:对于同一笔订单来说,状态的变化都是有严格的先后顺序的。
吞吐量:像订单的业务,我们自然希望订单越多越好。订单越多,吞吐量就越大。
在这种情况下,我们先看看 RabbitMQ 是怎么做的。
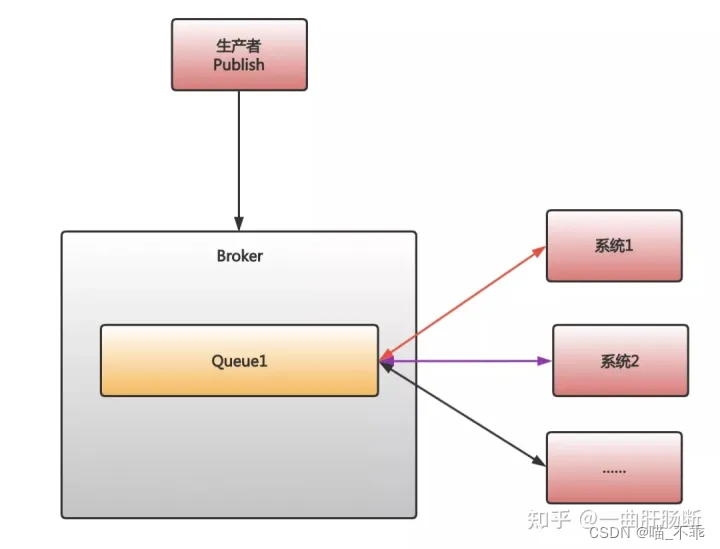
首先,对于发消息,并广播给多个消费者这种情况,RabbitMQ 会为每个消费者建立一个对应的队列。也就是说,如果有 10 个消费者,RabbitMQ 会建立 10 个对应的队列。然后,当一条消息被发出后,RabbitMQ 会把这条消息复制 10 份放到这 10 个队列里。
当 RabbitMQ 把消息放入到对应的队列后,我们紧接着面临的问题就是,我们应该在系统内部启动多少线程去从消息队列中获取消息。
如果只是单线程去获取消息,那自然没有什么好说的。但是多线程情况,可能就会有问题了……
RabbitMQ 有这么个特性,多线程消费一个消息的时候,当一个线程消费消息报错的时候,RabbitMQ 会把消费失败的消息再入队,此时就可能出现乱序的情况。
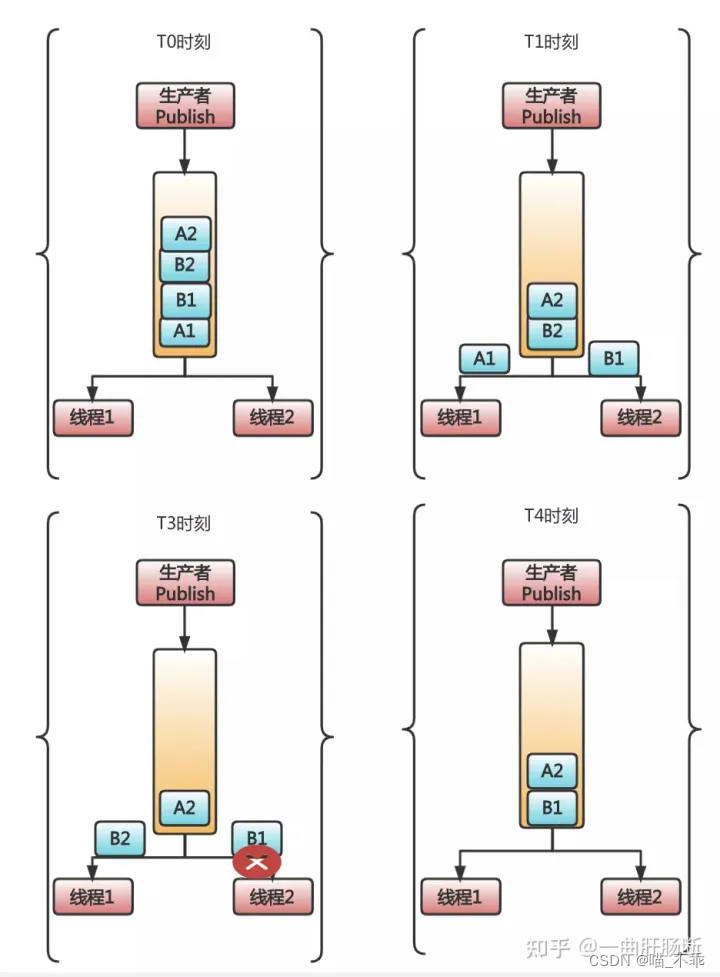
T0 时刻,队列中有四条消息 A1、B1、B2、A2。其中 A1、A2 表示订单 A 的两个状态:待付款、已付款。B1、B2 也同理,是订单 B 的待付款、已付款。
到了 T1 时刻,消息 A1 被线程 1 收到,消息 B1 被线程 2 收到。此时,一切都还正常。
到了 T3 时刻,B1 消费出错了,同时呢,由于线程 1 处理速度快,又从消息队列中获取到了 B2。此时,问题开始出现。
到了 T4 时刻,由于 RabbitMQ 线程消费出错,可以把消息重新入队的特性,此时 B1 会被重新放到队列头部。所以,如果不凑巧,线程 1 获取到了 B1,就出现了乱序情况,B2 状态明明是 B1 的后续状态,却被提前处理了。
所以,可以看到了,这个场景用 RabbitMQ,出现了三个问题:
- 为了实现发布订阅功能,从而使用的消息复制,会降低性能并耗费更多资源
- 多个消费者无法严格保证消息顺序
- 大量的订单集中在一个队列,吞吐量受到了限制
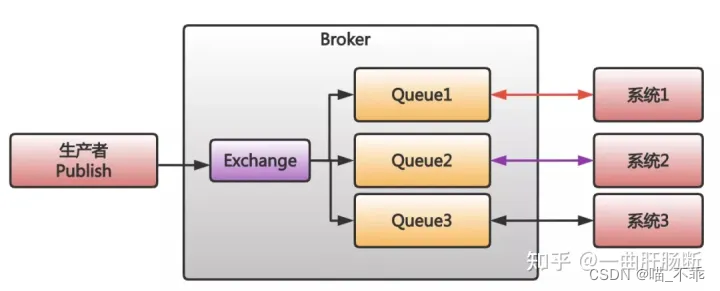
那么 Kafka 怎么样呢?Kafka 正好在这三个问题上,表现的要比 RabbitMQ 要好得多。
首先,Kafka 的发布订阅并不会复制消息,因为 Kafka 的发布订阅就是消费者直接去获取被 Kafka 保存在日志文件中的消息就好。无论是多少消费者,他们只需要主动去找到消息在文件中的位置即可。
其次,Kafka 不会出现消费者出错后,把消息重新入队的现象。
最后,Kafka 可以对订单进行分区,把不同订单分到多个分区中保存,这样,吞吐量能更好。
所以,对于这个需求 Kafka 更合适。
2. 消息的匹配
首先,先看看 RabbitMQ 的,RabbitMQ 是允许在消息中添加 routing_key 或者自定义消息头,然后通过一些特殊的 Exchange,很简单的就实现了消息匹配分发。开发几乎不用成本。
而 Kafka 呢?如果你要实现消息匹配,开发成本高多了。
首先,通过简单的配置去自动匹配和分发到合适的消费者端这件事是不可能的。
其次,消费者端必须先把所有消息不管需要不需要,都取出来。然后,再根据业务需求,自己去实现各种精准和模糊匹配。可能因为过度的复杂性,还要引入规则引擎。
这个场景下 RabbitMQ 扳回一分。
3. 消息的超时
在电商业务里,有个需求:下单之后,如果用户在 15 分钟内未支付,则自动取消订单。
你可能奇怪,这种怎么也会用到消息队列的?
我来先简单解释一下,在单一服务的系统,可以起个定时任务就搞定了。
但是,在 SOA 或者微服务架构下,这样做就不行了。因为很多个服务都关心是否支付这件事,如果每种服务,都自己实现一套定时任务的逻辑,既重复,又难以维护。
在这种情况下,我们往往会做一层抽象:把要执行的任务封装成消息。当时间到了,直接扔到消息队列里,消息的订阅者们获取到消息后,直接执行即可。
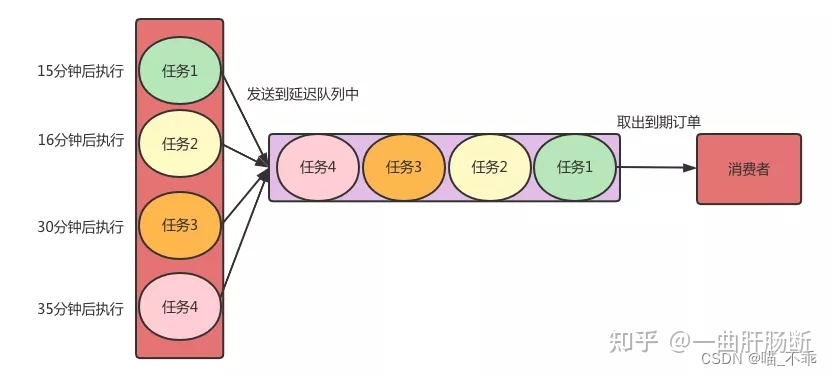
希望把消息延迟一定时间再处理的,被称为延迟队列。
对于订单取消的这种业务,我们就会在创建订单的时候,同时扔一个包含了执行任务信息的消息到延迟队列,指定15分钟后,让订阅这个队列的各个消费者,可以收到这个消息。随后,各个消费者所在的系统就可以去执行相关的扫描订单的任务了。
RabbitMQ 和 Kafka 消息队列如何选?
先看下 RabbitMQ 的。
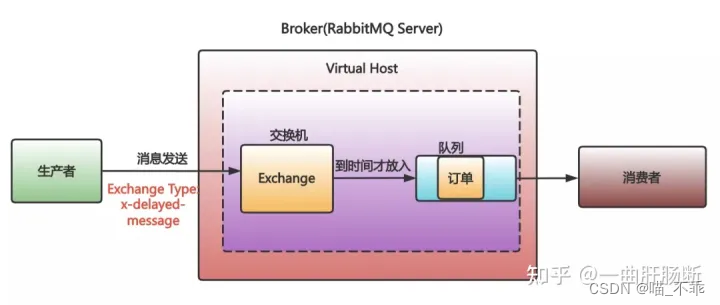
RabbitMQ 的消息自带手表,消息中有个 TTL 字段,可以设置消息在 RabbitMQ 中的存放的时间,超时了会被移送到一个叫死信队列的地方。
所以,延迟队列 RabbitMQ 最简单的实现方式就是设置 TTL,然后一个消费者去监听死信队列。当消息超时了,监听死信队列的消费者就收到消息了。
不过,这样做有个大问题:假设,我们先往队列放入一条过期时间是 10 秒的 A 消息,再放入一条过期时间是 5 秒的 B 消息。 那么问题来了,B 消息会先于 A 消息进入死信队列吗?
答案是否定的。B 消息会优先遵守队列的先进先出规则,在 A 消息过期后,和其一起进入死信队列被消费者消费。
在 RabbitMQ 的 3.5.8 版本以后,官方推荐的 rabbitmq delayed message exchange 插件可以解决这个问题。
用了这个插件,我们在发送消息的时候,把消息发往一个特殊的 Exchange。
同时,在消息头里指定要延迟的时间。
收到消息的 Exchange 并不会立即把消息放到队列里,而是在消息延迟时间到达后,才会把消息放入。
再看下 Kafka 的:
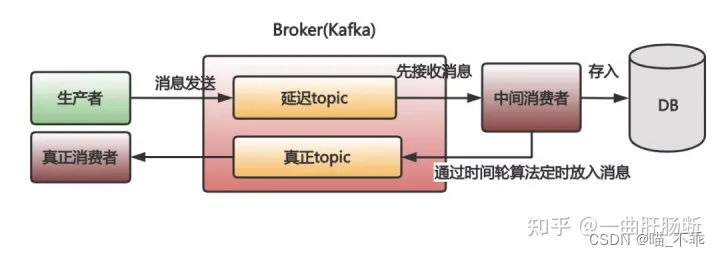
你先需要把消息先放入一个临时的 topic。
然后得自己开发一个做中转的消费者。让这个中间的消费者先去把消息从这个临时的 topic 取出来。
取出来,这消息还不能马上处理啊,因为没到时间呢。也没法保存在自己的内存里,怕崩溃了,消息没了。所以,就得把没有到时间的消息存入到数据库里。
存入数据库中的消息需要在时间到了之后再放入到 Kafka 里,以便真正的消费者去执行真正的业务逻辑。
这次,RabbitMQ ,才是最好的选择。
4. 消息的保持
在微服务里,事件溯源模式是经常用到的。如果想用消息队列实现,一般是把事件当成消息,依次发送到消息队列中。
事件溯源有个最经典的场景,就是事件的重放。简单来讲就是把系统中某段时间发生的事件依次取出来再处理。而且,根据业务场景不同,这些事件重放很可能不是一次,更可能是重复 N 次。
假设,我们现在需要一批在线事件重放,去排查一些问题。
RabbitMQ 此时就真的不行了,因为消息被人取出来就被删除了。想再次被重复消费?对不起。
而 Kafka 呢,消息会被持久化一个专门的日志文件里。不会因为被消费了就被删除。
所以,对消息不离不弃的 Kafka 相对用过就抛的 RabbitMQ,请选择 Kafka。
5. 消息的错误处理
很多时候,在做记录数据相关业务的时候,Kafka 一般是不二选择。不过,有时候在记录数据吞吐量不大时,我自己倒是更喜欢用 RabbitMQ。
原因就是 Kafka 有一个我很不喜欢的设计原则:
当单个分区中的消息一旦出现消费失败,就只能停止而不是跳过这条失败的消息继续消费后面的消息。即不允许消息空洞。
只要消息出现失败,不管是 Kafka 自身消息格式的损坏,还是消费者处理出现异常,是不允许跳过消费失败的消息继续往后消费的。
所以,在数据统计不要求十分精确的场景下选了 Kafka,一旦出现了消息消费问题,就会发生项目不可用的情况。这真是徒增烦恼。
而 RabbitMQ 呢,它由于会在消息出问题或者消费错误的时候,可以重新入队或者移动消息到死信队列,继续消费后面的,会省心很多。
坏消息就像群众中的坏蛋那样,Kafka 处理这种坏蛋太过残暴,非得把坏蛋揪出来不行。相对来说,RabbitMQ 就温柔多了,群众是群众,坏蛋是坏蛋,分开处理嘛。
6. 消息的吞吐量
Kafka 是每秒几十万条消息吞吐,而 RabbitMQ 的吞吐量是每秒几万条消息。
其实,在一家公司内部,有必须用到 Kafka 那么大吞吐量的项目真的很少。大部分项目,像 RabbitMQ 那样每秒几万的消息吞吐,已经非常够了。
在一些没那么大吞吐量的项目中引入 Kafka,我觉得就不如引入 RabbitMQ。
为什么呢?
因为 Kafka 为了更好的吞吐量,很大程度上增加了自己的复杂度。而这些复杂度对项目来说,就是麻烦,主要体现在两个方面:
1、配置复杂、维护复杂
Kafka 的参数配置相对 RabbitMQ 是很复杂的。比如:磁盘管理相关参数,集群管理相关参数,ZooKeeper 交互相关参数,Topic 级别相关参数等,都需要一些思考和调优。
另外,Kafka 本身集群和参与管理集群的 ZooKeeper,这就带来了更多的维护成本。Kafka 要用好,你要考虑 JVM,消息持久化,集群本身交互,以及 ZooKeeper 本身和它与 Kafka 之间的可靠和效率。
2、用好,用对存在门槛
Kafka 的 Producer 和 Consumer 本身要用好用对也存在很高的门槛。
比如,Producer 消息可靠性保障、幂等性、事务消息等,都需要对 KafkaProducer 有深入的了解。
而 Consumer 更不用说了,光是一个日志偏移管理就让一大堆人掉了不少头发。
相对来说,RabbitMQ 就简单得多。你可能都不用配置什么,直接启动起来就能很稳定可靠地使用了。就算配置,也是寥寥几个参数设置即可。
所以,大家在项目中引入消息队列的时候,真的要好好考虑下,不要因为大家都鼓吹 Kafka 好,就无脑引入。
总结
可以看到,如果我们要做消息队列选型,有两件事是必须要做好的:
- 列出业务最重要的几个特点
- 深入到消息队列的细节中去比较
等我们对这些中间件的特点非常熟悉之后,甚至可以把业务分解成不同的子业务,再根据不同的子业务的特征,引入不同的消息队列,即消息队列混用。这样,我们就可能会最大化我们的获益,最小化我们的成本。
说了这么多,其实还有很多 Kafka 和 RabbitMQ 的比较没有说,比如二者集群的区别,占用资源多少的比较等。以后有机会可以再提提。


来源:https://zhuanlan.zhihu.com/p/453970771
相关文章:
Kafka和RabbitMQ有哪些区别,各自适合什么场景?
目录标题1. 消息的顺序2. 消息的匹配3. 消息的超时4. 消息的保持5. 消息的错误处理6. 消息的吞吐量总结1. 消息的顺序 有这样一个需求:当订单状态变化的时候,把订单状态变化的消息发送给所有关心订单变化的系统。 订单会有创建成功、待付款、已支付、已…...

用Pytorch构建一个喵咪识别模型
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052 目录 一、前言 二、问题阐述及理论流程 2.1问题阐述 2.2猫咪图片识别原理 三、用PyTorch 实现 3.1PyTorch介绍 3.2PyTorch 构建模型的五要素 3.3PyTorch 实现的步骤 3.3.…...
QT搭建MQTT开发环境
QT搭建MQTT开发环境 第一步、明确安装的QT版本 注意: 从QT5.15.0版本开始,官方不再提供离线版安装包,除非你充钱买商业版。 而在这里我使用的QT版本为5.15.2,在线安装了好久才弄好,还是建议使用离线安装的版本 在这里…...

Python3,5行代码,生成自动排序动图,这操作不比Excel香?
5行代码生成自动排序动图1、引言2、代码实战2.1 pynimate介绍2.2 pynimate安装2.3 代码示例3、总结1、引言 小屌丝:鱼哥,听说你的excel段位又提升了? 小鱼:你这是疑问的语气? 小屌丝:没有~ 吧… 小鱼&…...
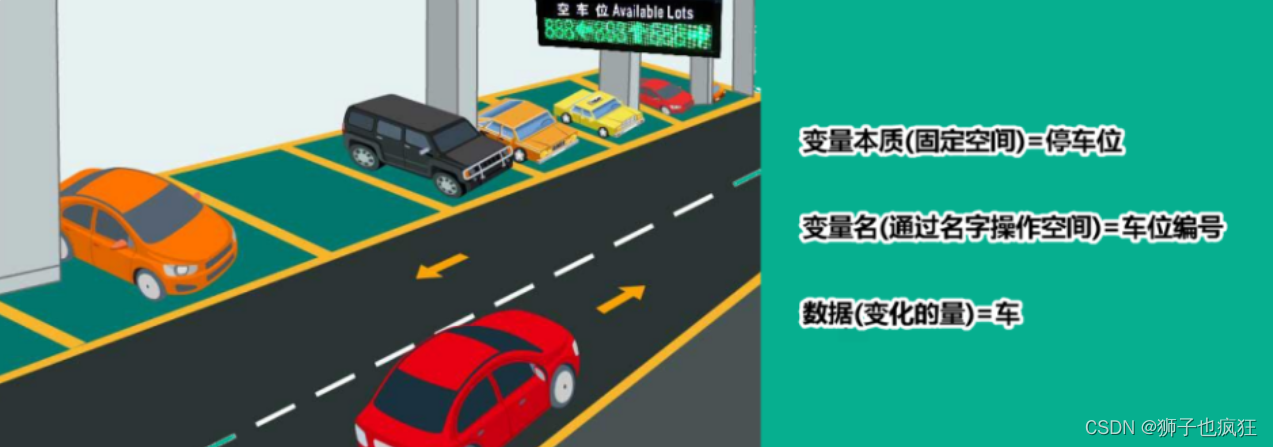
【Java SE】变量的本质
目录一. 前言二. 变量(variable)2.1 性质2.2 变量类型2.2.1 核心区别2.3 变量的使用三. 总结一. 前言 一天一个Java小知识点,助力小伙伴更好地入门Java,掌握更深层次的语法。 二. 变量(variable) 2.1 性质 变量本质上就是代表一个”可操作的存储空间”…...

【Android笔记85】Android之使用Camera和MediaRecorder录制视频
这篇文章,主要介绍Android之使用Camera和MediaRecorder录制视频。 目录 一、录制视频 1.1、案例运行效果 1.2、创建Camera对象 1.3、创建MediaRecorder对象...

MySQL集群搭建与高可用性实现:掌握主从复制、多主复制、负载均衡和故障切换技术,让你的MySQL数据库永不宕机!
MySQL集群和高可用性MySQL是一款广泛使用的关系型数据库管理系统,常用于Web应用和企业级应用中。为了提高MySQL的可用性,我们可以通过搭建MySQL集群和实现高可用性来保障数据的稳定性和可靠性。本文将介绍如何搭建MySQL集群和实现高可用性,包…...

收到6家大厂offer,我把问烂了的《Java八股文》打造成3个文档。共1700页!!
前言大家好,最近有不少小伙伴在后台留言,近期的面试越来越难了,要背的八股文越来越多了,考察得越来越细,越来越底层,明摆着就是想让我们徒手造航母嘛!实在是太为难我们这些程序员了。这不&#…...

多线程 (六) 单例模式
🎉🎉🎉点进来你就是我的人了 博主主页:🙈🙈🙈戳一戳,欢迎大佬指点!人生格言:当你的才华撑不起你的野心的时候,你就应该静下心来学习! 欢迎志同道合的朋友一起加油喔🦾&am…...

Docker入门到放弃笔记之容器
1、启动容器1.1容器hello world1.2 容器bash终端1.3 后台运行容器是 Docker 三大核心概念之一,其余两个是镜像与仓库。本文主讲容器。简单的说,容器是独立运行的一个或一组应用,以及它们的运行态环境。对应的,虚拟机可以理解为模拟…...
项目二 任务三 训练5 交换机的HSRP技术
在“项目二 任务三 训练4 交换机的DHCP技术”基础上继续完成下列操作: 1、二层交换机50-2的配置 50-2>en 50-2#conf t Enter configuration commands, one per line. End with CNTL/Z. 50-2(config)#int 50-2(config)#interface g 50-2(config)#interface gigab…...
计算机网络复习重点
文章目录计算机网络复习重点第一章 计算机网络和因特网概念与应用1、什么是因特网2、协议protocol3、入网方式4、物理媒介5、数据交换模式6、延时与丢包什么时候发生延时?延时的类型丢包何时发生7、协议层次与模型因特网协议栈TCP / IP模型ISO/OSI参考模型协议数据单…...
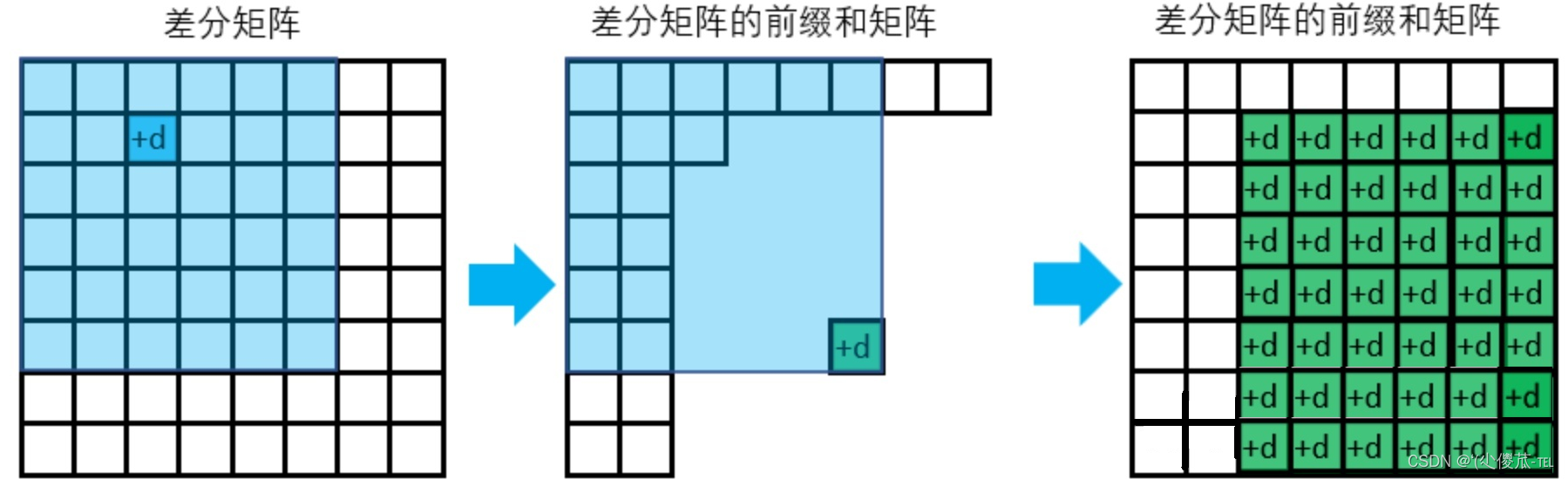
算法基础---基础算法
文章目录 快速排序归并排序二分 整数二分浮点数二分高精度 高精度加法高精度减法高精度乘法高精度除法前缀和 一维前缀和二维前缀和差分 一维差分二维差分双指针位运算离散化区间合并一、快速排序 思想:1.首先确定一个分界点(随机取任意一点为…...

linux中写定时任务
场景:我们生产环境中有大量的日志记录,但是我们的磁盘没有太大,需要定时清理磁盘 文章目录crond 定时任务详解安装定时任务crontab服务启动与关闭crontab操作crontab 命令test.sh查看日志丢弃linux中的执行日志Linux进入nano模式方式一方式二…...

2023.3.21
6:有序数组中找到num // arr保证有序,在arr数组中寻找num,二分查找public static boolean find(int[] arr, int num) {if(arr null || arr.length 0) {return false;}int L 0;int R arr.length - 1;while (L < R) {int mid (L R) /…...

制作数据库框架
一 利用前端条件组装sql与查询条件的集合public void handle() throws Exception{Map<String,String> requestMap new HashMap();String fromdate requestMap.get("fromdate");String todate requestMap.get("todate");String resultcode reque…...

Winbond W25Qxx SPI FLASH 使用示例(基于沁恒CH32V307单片机)
文章目录目的基础说明使用示例总结目的 Winbond(华邦)的 W25Qxx 系列 SPI FLASH 是比较常用的芯片,这篇文章将演示单片机中通过SPI使用该芯片的操作过程。 本文使用沁恒官方的开发板 (CH32V307-EVT-R1沁恒RISC-V模块MCU赤兔评估…...

贪心算法的原理以及应用
文章目录0、概念0.1.定义0.2.特征0.3.步骤0.4.适用1、与动态规划的联系1.1.区别1.2.联系2、例子3、总结4、引用0、概念 0.1.定义 贪心算法(greedy algorithm ,又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是…...
WebRTC拥塞控制原理之一基本介绍
1 基本原理 WebRTC的拥塞控制模块使用的是基于TCP的拥塞控制算法。它是根据网络带宽和延迟等信息来自适应地调整传输速率的。 具体来说,该模块采用的是基于RFC 3550中的延迟抖动调整算法的改进版本。该算法实施的基本原理是在传输的过程中定期探测网络的质量和延迟…...

选择 .NET 的 n 个理由
自从我们启动快速发展的 .NET 开源和跨平台项目以来,.NET 发生了很大变化。我们重新思考并完善了该平台,添加了专为性能和安全性而设计的新低级功能,以及以生产力为中心的高级功能。Span<T>、硬件内在函数和可为空的引用类型都是示例。…...

如何让Apple Touch Bar在Windows完美运行?DFRDisplayKm驱动全攻略
如何让Apple Touch Bar在Windows完美运行?DFRDisplayKm驱动全攻略 【免费下载链接】DFRDisplayKm Windows infrastructure support for Apple DFR (Touch Bar) 项目地址: https://gitcode.com/gh_mirrors/df/DFRDisplayKm Apple Touch Bar作为MacBook Pro的特…...

P1095 守望者的逃离【洛谷算法习题】
P1095 守望者的逃离 网页链接 P1095 守望者的逃离 题目背景 NOIP2007 普及组 T3 题目描述 恶魔猎手尤迪安野心勃勃,他背叛了暗夜精灵,率领深藏在海底的娜迦族企图叛变。 守望者在与尤迪安的交锋中遭遇了围杀,被困在一个荒芜的大岛上。…...

基于Spark+Hadoop+Hive大数据技术的产品评价分析系统设计与实现
前言本研究聚焦于设计与实现一种基于大数据技术的产品评价分析系统,通过构建多层架构体系与融合多元技术方法,为企业决策提供智能化支撑。 研究采用分层架构设计理念,将系统划分为数据采集、存储、处理、分析与展示五大模块。数据采集层综合运…...
✅)
计算机毕业设计:Python汽车销售数据爬虫可视化分析平台 Flask框架 requests爬虫 可视化 数据分析 大数据 机器学习 大模型(建议收藏)✅
博主介绍:✌全网粉丝50W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

忍者像素绘卷参数详解:描绘步数/幻化精度/画幅比例三维度效果对照表
忍者像素绘卷参数详解:描绘步数/幻化精度/画幅比例三维度效果对照表 1. 像素艺术创作新纪元 忍者像素绘卷是基于Z-Image-Turbo深度优化的图像生成工作站,它将传统漫画创作与16-Bit复古游戏美学完美融合。这款工具采用明亮的"云端"视觉设计&a…...

万象视界灵坛惊艳效果展示:同一张宠物图在‘金毛犬’‘幼犬’‘户外玩耍’‘毛发蓬松’多维排序
万象视界灵坛惊艳效果展示:同一张宠物图在"金毛犬""幼犬""户外玩耍""毛发蓬松"多维排序 1. 效果展示开场 今天我要向大家展示万象视界灵坛这个神奇工具的实际效果。它就像一个视觉魔法师,能够深入理解图片中的…...

效率提升秘籍:用快马AI一键生成nt动漫角色管理模块代码
最近在开发一个nt动漫相关的项目,其中角色管理模块是必不可少的部分。这个模块需要实现角色列表展示、详情查看、新增、编辑和删除等功能。传统开发方式下,光是搭建这些基础功能就要花费不少时间。不过我发现用InsCode(快马)平台可以快速生成这些重复性高…...

终端里的“皇帝新衣”:扒开 Claude Code 的源码,我看到了 Agent 的求生欲
下午三点,阳光斜着打在机械键盘的侧边,你刚解决完一个诡异的内存溢出,正打算接杯咖啡。 顺手更新了 Anthropic 刚发布的 Claude Code,这个号称能直接在终端里帮你写代码、改 bug、跑测试的“神级工具”。 [外链图片转存中…(img…...

Performance-Fish:环世界性能优化的全方位解决方案
Performance-Fish:环世界性能优化的全方位解决方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 问题诊断:环世界性能瓶颈深度剖析 🔍 AI决策系统…...
)
告别pip install失败:手把手教你用Anaconda虚拟环境快速部署Mayavi(Python 3.9亲测)
告别pip install失败:手把手教你用Anaconda虚拟环境快速部署Mayavi(Python 3.9亲测) 科学计算和三维可视化是Python生态中的重要应用场景,而Mayavi作为一款强大的三维数据可视化库,在流体力学、医学影像、地质勘探等领…...