Python爬虫新手指南及简单实战
网络爬虫是自动化获取网络信息的高效工具,Python因其强大的库支持和简洁的语法成为编写网络爬虫的首选语言。本教程将通过一个具体的案例(基于Microsoft Edge浏览器的简单爬取),指导你使用Python实现一个完整的网络爬虫,涵盖环境准备、网站爬取、数据处理及存储等环节,内容简单,适合小白。
目录
一、环境准备与基本理论
1. Python与相关库安装
2.下载并配置Microsoft Edge WebDriver
3. 网络爬虫的基本概念与原理
二、实战案例:简单爬取获取信息
1. 打开浏览器并访问网站
2. 获取并打印网页标题
3. 提取并打印网页中的链接
4. 获取并打印网页源代码
5. 提取并保存所有图片的URL
6.注意事项
三、进阶技巧与问题处理
1. 处理动态内容
2. 处理JavaScript弹窗
3. 处理多种网页结构
4. 处理网页爬取速度
5. 遵守法律和道德规范
四、实际案例的高阶应用
1. 电商网站价格监控
2. 新闻聚合
3. 社交媒体分析
4. 品牌声誉监控
五、总结
Python爬虫新手指南及简单实战

一、环境准备与基本理论
在开始之前,确保你的计算机上安装了Python环境,并熟悉基本的Python语法。
1. Python与相关库安装
- Python: 访问Python官网下载并安装最新版本的Python。
- Pip: Python的包管理器,通常与Python一起安装。
- Requests: 用于发起网络请求。安装方法:
pip install requests。
- BeautifulSoup: 用于解析HTML文档。安装方法:
pip install beautifulsoup4。
- Selenium: 用于处理JavaScript渲染的页面。安装方法:
pip install selenium。
2.下载并配置Microsoft Edge WebDriver
Microsoft Edge WebDriver是用于Microsoft Edge浏览器的自动化测试工具,我们可以从这里下载适用于你的操作系统的WebDriver: https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
下载完成后,将WebDriver解压到一个文件夹,并将该文件夹的路径添加到系统环境变量PATH中。
3. 网络爬虫的基本概念与原理
网络爬虫是一种自动获取网页内容的程序,其基本原理包括种子页面、链接抓取、内容分析以及链接跟踪等步骤。 而它的核心原理则基于超文本传输协议(HTTP)来获取网页资源。网络爬虫主要经历以下几个步骤:
- 种子页面:
- 爬虫启动时需要一个或多个初始URL,这些被称为种子页面。
- 种子页面的选择对爬虫的起始方向有决定性作用。
- 通常,种子页面与爬取目标密切相关,以确保后续爬取内容的相关度。
- 链接抓取:
- 爬虫通过访问种子页面,解析页面上的HTML代码,抓取其中的所有链接。
- 这些链接可能是内部链接,也可能是外部链接,它们为爬虫提供了进一步爬取的路径。
- 内容分析:
- 爬虫会对抓取的每个页面进行内容分析,提取出有价值的信息,如文本、图片、视频等。
- 在分析过程中,可能涉及到网页内容的渲染、执行JavaScript代码以及解码加密数据等操作。
- 链接跟踪:
- 提取出的链接会被加入到爬取队列中,爬虫会按照一定的策略跟踪这些链接,继续抓取新页面。
- 爬虫会根据设定的爬行策略,比如深度优先或广度优先策略,循环地进行爬取,直到满足停止条件。
- 数据存储:
- 抓取到的数据会被存储到适当的位置,例如文件、数据库或其他存储系统中。
- 存储方式取决于数据类型及后续使用的需求,比如数据分析、信息检索或其他自动化任务。
- 异常处理:
- 在爬虫工作中会遇到各种异常情况,包括但不限于网络请求失败、页面解析错误、反爬机制等。
- 良好的异常处理机制能够保证爬虫稳定运行,比如通过重试、延时、代理切换等方式应对不同的异常。
二、实战案例:简单爬取获取信息
在这部分,我们将通过Microsoft Edge浏览器爬取某些网站上更多的信息,并展示如何提取这些信息。
1. 打开浏览器并访问网站
首先,我们需要启动Edge浏览器并打开目标网站。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 创建一个Microsoft Edge浏览器实例
driver = webdriver.Edge(executable_path="<你的Microsoft Edge WebDriver路径>")# 访问目标网站
url = "网站"
driver.get(url)# 等待页面加载完成
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.TAG_NAME, "body")))
2. 获取并打印网页标题
接下来,我们将获取网页的标题并打印出来。
# 获取网页标题
title = driver.title
print("网页标题:", title)
3. 提取并打印网页中的链接
我们可以使用selenium来定位所有的链接元素,并打印出它们的URL和文本。
# 找到页面中的所有链接
links = driver.find_elements(By.TAG_NAME, "a")# 遍历链接并打印
for link in links:link_text = link.textlink_url = link.get_attribute('href')print(f"链接文本:{link_text} | 链接地址:{link_url}")
4. 获取并打印网页源代码
最后,我们可以获取整个网页的源代码,这在需要查找特定元素或进行更复杂操作时非常有用。
# 获取网页源代码
page_source = driver.page_source
print("网页源代码:", page_source)# 关闭浏览器
driver.quit()
5. 提取并保存所有图片的URL
假设我们想要提取网页上所有图片的URL并保存。
# 找到页面中的所有图片
images = driver.find_elements(By.TAG_NAME, "img")# 创建一个列表来保存图片的URL
image_urls = []# 遍历图片并获取它们的URL
for image in images:image_url = image.get_attribute('src')image_urls.append(image_url)# 打印图片的URL
for url in image_urls:print("图片链接:", url)# 保存图片URL到文件(可选)
with open('image_urls.txt', 'w') as file:for url in image_urls:file.write(url + '
')
6.注意事项
通过上述代码,我们不仅爬取了网站的标题,还提取了网页中的所有链接和图片URL。这些数据可以用于进一步分析或保存为后期使用,同时在上述代码中,需要将<你的Microsoft Edge WebDriver路径>替换为您实际下载并解压的Microsoft Edge WebDriver的路径。例如,如果您将其保存在C:\webdrivers\msedgedriver.exe,则应将代码中的<你的Microsoft Edge WebDriver路径>替换为"C:\\webdrivers\\msedgedriver.exe"。
此外,您还可以根据需要修改目标网站的URL。在示例代码中,我们使用了“网站”作为目标网站。你需要将他替换为你想要爬取的任何其他网站的URL。
代码简单讲解:
- 导入所需的库和模块。
- 创建一个Microsoft Edge浏览器实例,并指定WebDriver的路径。
- 访问目标网站。
- 等待页面加载完成。
- 获取网页标题并打印。
- 提取网页中的所有链接,并打印它们的文本和URL。
- 获取网页源代码并打印。
- 关闭浏览器实例。
- 可选:提取网页上所有图片的URL并保存到文件中。
三、进阶技巧与问题处理
在进行网页爬取时,我们可能会遇到各种问题,如网页结构变化、动态内容加载等。本节将介绍一些进阶技巧和常见问题的处理方法。
1. 处理动态内容
有时,网页上的内容是通过JavaScript动态加载的。selenium可以处理这种情况,因为它会模拟浏览器操作,等待JavaScript执行完成后再进行爬取。但在某些情况下,如果页面加载时间过长,我们可能需要手动设置一个等待时间。
# 设置显式等待时间
wait = WebDriverWait(driver, 20)
element = wait.until(EC.presence_of_element_located((By.ID, "someId")))
2. 处理JavaScript弹窗
有些网站在爬取过程中可能会弹出JavaScript对话框,这可能会中断爬取过程。我们可以使用selenium来接受或取消这些弹窗。
# 接受警告框
driver.switch_to.alert.accept()# 取消警告框
driver.switch_to.alert.dismiss()
3. 处理多种网页结构
不同的网页可能有不同的布局和结构。在定位元素时,我们需要根据实际的网页结构来选择最适合的定位方式。例如,如果我们无法通过ID定位元素,可以尝试使用其他方式,如类名、XPath等。
# 通过类名定位元素
elements = driver.find_elements_by_class_name("someClassName")# 通过XPath定位元素
element = driver.find_element_by_xpath("//some/xpath/selector")
4. 处理网页爬取速度
在爬取大量数据时,速度可能成为一个问题。我们可以使用多线程或异步的方式来提高爬取速度。此外,适当设置延时,模拟人类浏览行为,也可以减少被网站封禁的风险。
# 设置延时
time.sleep(2)
5. 遵守法律和道德规范
在进行网页爬取时,我们必须遵守相关的法律法规和道德规范。确保我们的行为合法,并且不会侵犯网站的版权或其他权利。此外,我们还应该尊重网站的robots.txt文件,该文件指定了哪些页面可以被爬取,哪些不可以。

通过掌握这些进阶技巧,我们可以更有效地处理网页爬取过程中的各种问题,并确保我们的爬虫程序能够稳定、高效地运行。
四、实际案例的高阶应用
在掌握了基础和进阶技巧之后,我们来看看一些具体的实际案例,这些案例展示了如何运用我们到目前为止学到的技术来解决实际问题。
1. 电商网站价格监控
许多电商网站会定期更改商品价格。我们可以创建一个爬虫来监控特定商品的价格变动,并在价格低于某个阈值时发送通知。
# 假设我们正在监控一个具有特定ID的商品
product_price = driver.find_element_by_id("productPrice").text
if float(product_price) < price_threshold:# 发送通知的代码send_notification("Price dropped below threshold!")
2. 新闻聚合
我们可以创建一个聚合器,从多个新闻网站抓取最新的新闻报道,并将这些信息汇总到一个单一的界面中。
# 爬取新闻标题和链接
news_headlines = driver.find_elements_by_class_name("newsHeadline")
for headline in news_headlines:news_title = headline.textnews_link = headline.get_attribute('href')# 保存或显示新闻标题和链接
3. 社交媒体分析
使用爬虫技术,我们可以分析社交媒体上的趋势,例如跟踪特定话题的热度或情绪。
# 收集关于特定话题的推文
tweets = driver.find_elements_by_css_selector(".tweet")
for tweet in tweets:tweet_text = tweet.text# 分析推文情绪或保存数据
4. 品牌声誉监控
通过监控论坛、评论和社交媒体,企业可以了解自己的品牌在公众中的形象,并及时响应可能的问题。
# 收集品牌相关的评论
comments = driver.find_elements_by_xpath("//div[contains(text(), '品牌名称')]/following-sibling::div")
for comment in comments:comment_text = comment.text# 分析或保存评论
通过这些实际的案例,我们可以看到网络爬虫技术在解决现实问题中的广泛应用。每一个案例都需要对基础知识的深入理解和应用,以及对进阶技巧的灵活使用。希望通过这些实例,您能找到解决问题的灵感,并将其应用到您的项目中去。
五、总结
在本文中,我们全面介绍了使用Python和Microsoft Edge浏览器进行网页爬取的过程,从环境准备到编写爬虫代码,再到进阶技巧与问题处理,最后通过实际案例展示了爬虫技术的应用。我们强调了安装selenium库和配置Microsoft Edge WebDriver的重要性,并逐步介绍了如何使用selenium库编写简单的爬虫代码,包括打开浏览器、访问网页、获取网页标题、提取链接和图片等操作。此外,我们还讨论了如何处理动态内容加载、JavaScript弹窗、不同的网页结构以及提高爬取速度等进阶技巧。通过电商价格监控、新闻聚合、社交媒体分析、竞争对手分析和品牌声誉监控等案例,我们展示了爬虫技术在实际应用中的多样性和潜力。总之,网络爬虫技术是一个强大而复杂的领域,需要我们不断学习和实践,以便充分利用Python和Microsoft Edge浏览器的功能,从互联网上获取有价值的数据。希望本文能为您的网络爬虫之旅提供一个坚实的起点,并助您在实际项目中取得成功。
相关文章:
Python爬虫新手指南及简单实战
网络爬虫是自动化获取网络信息的高效工具,Python因其强大的库支持和简洁的语法成为编写网络爬虫的首选语言。本教程将通过一个具体的案例(基于Microsoft Edge浏览器的简单爬取),指导你使用Python实现一个完整的网络爬虫࿰…...

如何有效开展产业链招商?
产业链招商是一种以产业大数据为依托、以产业链图谱为基础、以产业链分析为核心、以完善产业链结构为目标的招商引资方式。相比于传统招商模式,产业链招商比拼的并不是土地、政策优惠,而是以产业链分析为核心,诊断区域产业链结构及长短板&…...

爬虫中使用多进程、多线程的混合方式遇到的数据丢失问题
项目场景: 网络爬虫项目,主要实现多进程、多线程方式快速缓存网页资源到MongoDB,并解析网页数据,将信息写入到csv文件中。 问题描述 在单独使用多线程的过程中,是没有问题的,比如这个爬虫示例是爬取豆瓣电…...

多云应用安全平台RegData利用MongoDB简化数据控制和合规流程
在高度规范化市场中,为了保障数据安全,企业可能需要部署一系列繁琐且成本高昂的IT基础设施系统。随着各项数据安全保护措施的出台,企业需要遵守的法规数量越多,尤其是跨越多个地域的企业,其IT基础设施就会越复杂。如今…...

VUE实现TAB切换不同页面
VUE实现TAB切换不同页面 实现效果 资源准备 ReceiveOrderList, TodoListMulti, SignList 这三个页面就是需要切换的页面 首页代码 <template><div><el-tabs v-model"activeTab" type"card" tab-click"handleTabClick"><…...

C++ 80行 极简扫雷
一共5346个字符,MinGW编译通过(强烈不建议写这种代码!!!) 压行规则:一行不超过80个字符 代码: #include<windows.h> #include<stdio.h> #include<time.h> #def…...

常见VPS服务器附加组件一览
网络主机行业竞争非常激烈,因此主机服务提供商竭尽全力为客户提供完整的解决方案,其中包含构建和管理在线项目所需的一切。但客户通常有特定需求,因此需要不同的附加组件。在管理自己的网络服务器时尤其如此。 今天,我们将介绍您…...

Electron 使用Electron-build 进行打包
看完下面两篇就可以完成! 基于vue3vite的web项目改为Electron桌面应用(一)_vue3转electron-CSDN博客 将web项目打包成electron桌面端教程(二)vue3vitets_vue3 打包桌面端-CSDN博客 打包报错 1. 首先确定依赖包 npm …...

Springboot+Websocket+Security+Vue 实现弹幕推送功能
后端部分 (Spring Boot) 1. 创建一个 Spring Boot 项目 创建一个新的 Spring Boot 项目并添加以下依赖: <dependencies><!-- Spring Boot Starter Web --><dependency><groupId>org.springframework.boot</groupId><artifactId…...
LangChain之网络爬虫
网络爬虫 概述 网络爬虫是LangChain中的一项关键功能,允许用户自动从互联网上收集信息。这项功能对于研究和数据收集尤其有价值,因为它可以大幅减少手动搜索和信息整理的工作量。 从网络收集内容有几个主要组件: Search搜索:使用…...

VueRouter 相关信息
VueRouter 是Vue.js官方路由插件,与Vue.js深度集成,用于构建单页面应用。构建的单页面是基于路由和组件,路由设定访问路径,将路径与组件进行映射。VueRouter有两中模式 :hash 和 history ,默认是hash模式。…...
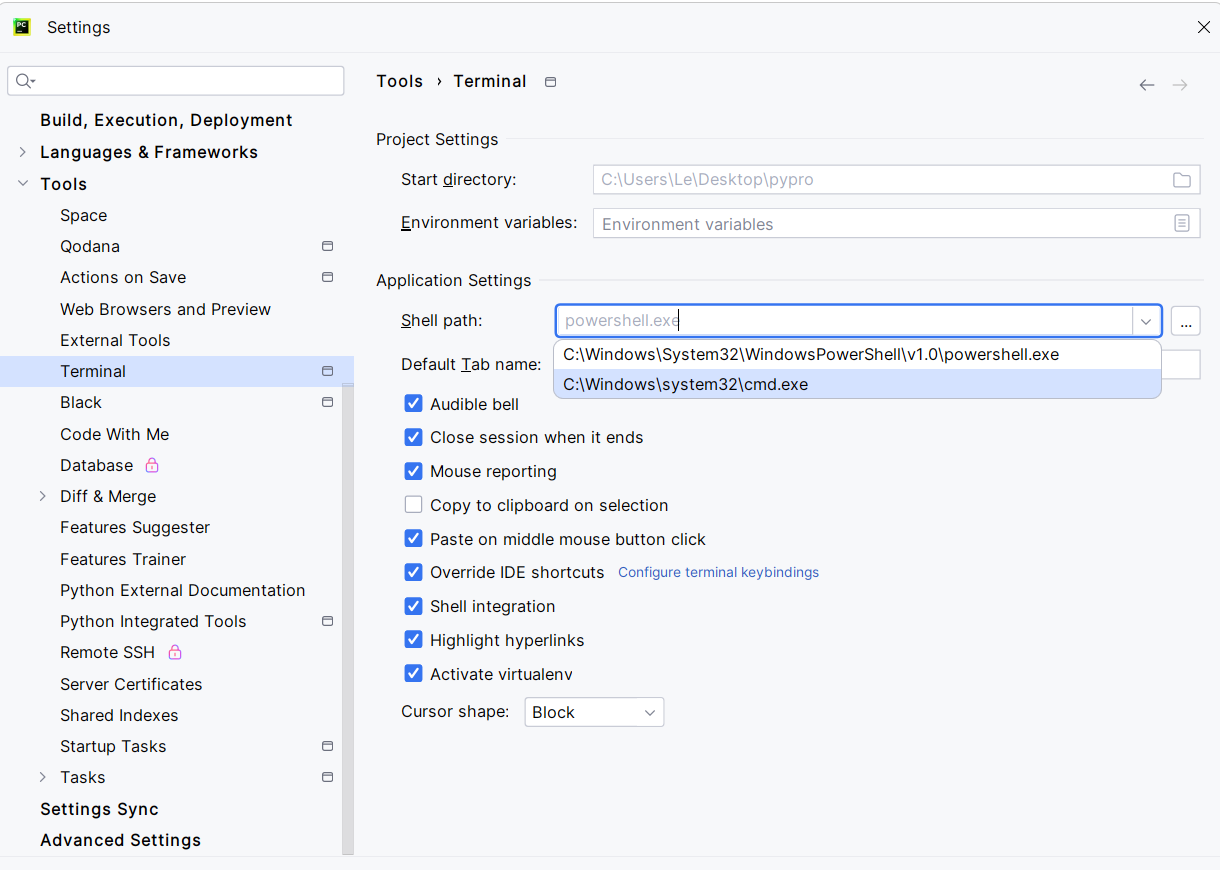
[环境配置]Pycharm:Failed to start [PowerShell.exe]
解决方法,点Local旁边的 号,点击Command Prompt,即可在Pycharm中呼出控制台。 如果要修改Command Prompt的启动时访问的cmd.exe的路径,可以去Settings→Tools→Terminal中,修改Shell Path实现,改为cmd.exe…...

搜狗爬虫(www.sogou.com)IP及UA,真实采集数据
一、数据来源: 1、这批搜狗爬虫(www.sogou.com)IP来源于尚贤达猎头网站采集数据; 2、数据采集时间段:2023年10月-2024年7月; 3、判断标准:主要根据用户代理是否包含“www.sogou.com”和IP核实…...

北京青蓝智慧科技ITSS服务经理:长安链ChainBridge“链桥”问世 加速国家级区块链网络互联互通
8月5日,据国家区块链技术创新中心消息,我国首个完全自主控制的区块链软硬件技术系统——长安链,正式推出了全场景技术平台ChainBridge“链桥”。 此平台能够支持所有异构和同构的区块链进行协作,满足跨领域、跨地域、跨行业及跨层…...

音视频入门基础:WAV专题(5)——FFmpeg源码中解码WAV Header的实现
音视频入门基础:WAV专题系列文章: 音视频入门基础:WAV专题(1)——使用FFmpeg命令生成WAV音频文件 音视频入门基础:WAV专题(2)——WAV格式简介 音视频入门基础:WAV专题…...

爬虫:csv存储:写入和读取
目录 csv写入 csv读取 csv写入 import csv# data [ # (tf, 20, 180), # (dl, 20, 170), # (hc, 18, 190) # ] # header (姓名,年龄,身高) # # # csv写入数据会默认写一行隔一行 newline就是让它不要有空行 # with open(text.csv,w,encodingutf8,newline) as f:…...
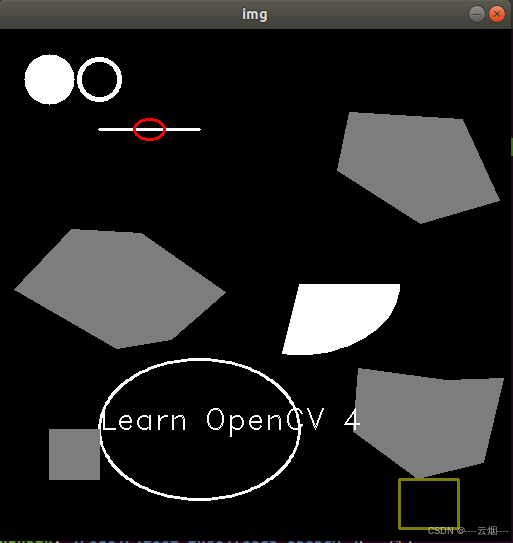
Opencv-绘制几何图形
1. 绘制圆形 1.1 circle()函数原型 void cv::circle(InputOutputArray img, Point center, int radius, const Scalar & color, int thickness 1, int lineType LINE_8, int shift 0 ) img:需要绘制圆形的图像。 center:圆形的圆心位置坐标。 …...

ElasticSearch安装与集群部署
ElasticSearch安装与集群部署 很多小伙伴第一次接触ElasticSearch的时候是一脸愁容,这个东西他怎么用啊,不知道从哪里安装,那我们今天就着重从哪里下载?怎么下载?怎么安装?来研究一下吧! windows下载安装ElasticSearch 下载地址:https://www.elastic.co/cn/do…...

盘点12款企业常用源代码加密软件,源代码防泄密很重要!
在当今的商业环境中,源代码作为企业的核心资产之一,其安全性不容忽视。源代码的泄露可能导致企业丧失竞争优势、面临法律诉讼甚至经济损失。因此,选择合适的源代码加密软件成为企业保护知识产权和核心技术的关键步骤。 1. 安秉源代码加密软件…...

文件上传和下载
要想实现文件上传和下载,其实只需要下述代码即可: 文件上传和下载 import cn.hutool.core.io.FileUtil; import cn.hutool.core.util.StrUtil; import com.example.common.Result; import org.springframework.web.bind.annotation.*; import org.sprin…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

PentestGPT实战部署指南:AI驱动的渗透测试工作流落地
1. 这不是另一个“AI安全”的概念玩具,而是一套能真正跑起来的渗透测试辅助工作流“PentestGPT”这个名字刚在GitHub上出现时,我第一反应是点开又关掉——过去三年里,我见过太多打着“AI渗透”旗号的项目:有的只是把ChatGPT API封…...

PCL 基于强度的双边滤波【2026最新版】
目录 一、算法原理 1、计算步骤 2、算法源码 3、函数解析 4、参考文献 二、代码实现 三、结果展示 四、滤波后未发生变化的原因 五、解决办法 六、结果展示 七、相关链接 本文由CSDN点云侠原创,博客长期更新,本文最近一次更新时间为:2026年5月24日。 一、算法原理 1、计算…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题
终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 你是否还在为Windows…...

遭遇薪酬倒挂后的反向谈判与资产重估策略「蒸汽求职分享」
在 2026 年全球科技大厂与跨国泛金融巨头追求极致人效、频繁进行组织架构重组(Reorg)的买方市场中,一个让无数海外名校留学生在入职两年后心态瞬间崩塌的现象,正在高频发生——“薪酬倒挂(Salary Inversion)…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

MPC Video Renderer终极指南:如何在Windows上实现专业级视频渲染体验
MPC Video Renderer终极指南:如何在Windows上实现专业级视频渲染体验 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer MPC Video Renderer是一款专为Windows平台设计…...