爬虫中使用多进程、多线程的混合方式遇到的数据丢失问题

项目场景:
网络爬虫项目,主要实现多进程、多线程方式快速缓存网页资源到MongoDB,并解析网页数据,将信息写入到csv文件中。
问题描述
在单独使用多线程的过程中,是没有问题的,比如这个爬虫示例是爬取豆瓣电影排行榜TOP250,解析到csv中数据还是250条,在实现多进程的方式中,主要是通过MongoDB来实现一个队列的效果,多条进程从数据库中取出待解析的链接进行解析,在实现的过程中,发现解析数据是没有问题的,打印到控制台的数据是没有丢失数据的情况,但是在最终写出的csv文件中,数据只有一小部分。
在尝试了国内所有能用的AI之后无果,AI只能对逻辑问题判断,而对一些Runtime问题还是差点意思,好在CSDN有大佬,将问题发布到问答区后,大佬一句话就点醒了我,在此表示感谢。

from concurrent.futures import ThreadPoolExecutor
from datetime import datetime,timedelta
from multiprocessing.dummy import Pool
import os
import random
import re
import threading
import time
import urllib.parse
import urllib.request
import urllib3
from urllib.parse import urlparse, urlsplit
from urllib.parse import urljoin
import urllib.robotparser
from lxml import html as lhtml
import csv
import pickle
import zlib
from bson.binary import Binary
from pymongo import MongoClient
from zipfile import ZipFile
from io import StringIO
# 多线程爬虫
# 封装MongoDB缓存类
class MongoCache:def __init__(self,client=None,expires=timedelta(days=30)):if client == None:self.client = MongoClient('localhost',27017)else:self.client = clientself.db = self.client['cache']self.webpage = self.db['webcrawler']self.expires = expiresself.webpage.create_index('timestamp',expireAfterSeconds=expires.total_seconds())def __getitem__(self,url):'''根据url从磁盘提取缓存'''record = self.webpage.find_one({'_id':url})if record:return pickle.loads(zlib.decompress(record['result']))else:raise KeyError(url + "不存在")def __setitem__(self,url,result):'''将数据存入磁盘缓存中'''record = {'result':Binary(zlib.compress(pickle.dumps(result))),'timestamp':datetime.now()}self.webpage.update_one({'_id':url},{'$set':record},upsert=True)
# 将下载功能封装成一个类
class Downloader:def __init__(self,delay=5,user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0',proxies=None,request_max=3,cache=None):self.throttle = Throttle(delay=delay)self.user_agent = user_agentself.proxies = proxiesself.request_max = request_maxself.cache = cache# 定义连接管理池self.http = urllib3.PoolManager()def __call__(self,url):result = Noneif self.cache:try:result = self.cache[url]except KeyError:passelse:if self.request_max > 0 and 500 <= result['code'] < 600:result = Noneif result is None:self.throttle.wait(url)proxy = random.choice(self.proxies) if self.proxies else Noneheaders = {'User-agent':self.user_agent}result = self.download(url,headers,self.request_max,proxy)if self.cache:self.cache[url] = resultreturn result['html']def download(self,url,headers,request_max,proxy=None):print("正在下载, URL==>{}".format(url))# 发起GET请求request = urllib.request.Request(url,headers=headers)response = self.http.request('GET', url,headers=headers)# 如果使用代理的话if proxy:opener = urllib.request.build_opener()proxy_params = {urlparse.urlparse(url).scheme:proxy}opener.add_handler(urllib.request.ProxyHandler(proxy_params))try:response = opener.open(request)if response.status == 200:html = response.dataelse:print("遇到了错误,状态码是:{}".format(response.status))if request_max >= 0:self.download(url,headers,request_max-1,proxy)except Exception as e:print("下载遇到了错误,错误代码是==>{}".format(e))html = Noneif request_max >=3:html = self.download(url,headers,request_max-1,proxy)finally:response.release_conn()return {'html':html,'code':response.status}else:# 如果没有选择代理,那就正常请求try:if response.status == 200:html_file = response.data # 或者 response.data.decode('utf-8') 如果需要字符串# 在这里处理 htmlfile,比如保存到文件或进行解析等return {'html':html_file,'code':response.status}else:print("遇到了错误,状态码是:{}".format(response.status))if request_max >= 0:self.download(url,headers,request_max-1)except urllib3.exceptions.HTTPError as e:print("遇到了错误,错误代码是==>{}".format(e))except Exception as ex:print("遇到了错误,错误代码是==>{}".format(ex))finally:response.release_conn()
# 定义一个scrape_callback类,用于存储解析到的数据
class Scrape_callback:def __init__(self):self.writer = csv.writer(open('D:/Crawl_Results/downloaded_data.csv','w', encoding='utf-8',newline='',errors='replace'))self.fields = ('中文名','外文名','评分','上映时间','国家','导演','时长','类型')self.writer.writerow(self.fields)def __call__(self,html):if not self.writer:raise RuntimeError("CSV writer is not initialized. Call open_writer() first.")html_string = html.decode("utf-8")root = lhtml.fromstring(html_string)result_list = []try:# 解析电影标题title_content = root.cssselect("div#content")[0]span_title = title_content.cssselect('span[property="v:itemreviewed"]')[0]title_text = span_title.text_content().split(" ",1)for name in title_text:result_list.append(name)if len(title_text) == 1:result_list.append('--')# 解析电影评分rate_span = root.cssselect('strong[property="v:average"]')[0]rate_text = rate_span.text_content()result_list.append(rate_text)# 解析上映国家及日期date_span = root.cssselect('span[property="v:initialReleaseDate"]')[0]date_text = date_span.text_content()parenthesis_index = date_text.find('(')if parenthesis_index != -1:# 提取日期部分(括号前的所有字符)date = date_text[:parenthesis_index]# 提取国家部分(括号内及之后的字符,再去除括号)country = date_text[parenthesis_index + 1:-1]else:# 如果没有找到括号,则只有日期部分date = date_textcountry = "--"result_list.append(date)result_list.append(country)# 解析导演direct_by_a = root.cssselect('a[rel="v:directedBy"]')[0]direct_by_text = direct_by_a.text_content()result_list.append(direct_by_text)# 解析片长runtime_span = root.cssselect('span[property="v:runtime"]')[0]runtime_text = runtime_span.text_content()result_list.append(runtime_text)gener_text=''# 解析类型gener_spans = root.cssselect('span[property="v:genre"]')for gener_span in gener_spans:gener_text += gener_span.text_content() + '|'gener_text = gener_text.rstrip('|')result_list.append(gener_text)print("{}|{}|{}|{}|{}".format(title_text,rate_text,date,country,direct_by_text,gener_text))self.writer.writerow(result_list)result_list.clear() # 清空列表以备下次使用,而不是重新创建except IndexError:print("未找到指定的元素")except Exception as e:print(f"处理过程中发生错误: {e}")def do_write(self,result_list):if not self.writer == None:self.writer.writerow(result_list)else:print("打开文件失败")def close_writer(self):# 如果writer是外部创建的,则不应在此关闭文件# 但在当前上下文中,文件是在这个类中打开的,所以应该在这里关闭if self.writer:#self.writer.writerow([]) # 写入空行作为结束标记(可选)# 注意:在with块外不需要手动关闭文件,它会自动处理self.writer = None # 清除writer引用,帮助垃圾回收
# 定义一个类,用于控制延时
class Throttle:'''用于控制爬虫访问统一域名资源时的延时'''# 初始化函数def __init__(self,delay):self.delay = delayself.domains = {}# 控制延时def wait(self,url):# 解析url,获取域名domain = urlparse(url).netloc# 获取上一次访问的时间last_accessed = self.domains.get(domain)# 如果设置到延时并且已经访问过了if self.delay > 0 and last_accessed is not None:# 计算从上次访问到当前时间过去的秒数与规定的延迟时长的差值sleep_secs = self.delay - (datetime.now() - last_accessed).seconds# 判断距离上次访问的时间间隔是否达到了延迟要求if sleep_secs > 0:print("正在休眠,将等待{}秒后再次连接".format(sleep_secs))# 如果时间还没有达到,就调用time.sleep,进行休眠time.sleep(sleep_secs)# 更新本次访问的时间self.domains[domain] = datetime.now()
# 爬取网页的函数
def threaded_crawler(delay,request_max,seed_url,link_regex,max_deepth=5,max_threads=6,scrape_callback=Scrape_callback(),cache=MongoCache(),proxies=None):# 定义一个User_agent列表user_agent_list = ['BadCrawler','GoodCrawler']# 解析网站的robots.txtrp = urllib.robotparser.RobotFileParser()rp.set_url(f"{seed_url}/robots.txt")rp.read()# 定义一个用户当前设置的user_agentcurrent_user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'# 只有当默认的火狐这个User-agent被禁,再从user_agent_list中找看还有合适的没if not rp.can_fetch(current_user_agent,seed_url):# 从列表中找一个网站允许的user_agentfor user_agent in user_agent_list:if rp.can_fetch(user_agent,seed_url):current_user_agent = user_agentbreakelse:print("该网站的robots.txt禁止我们访问")# 从提供的种子url生成一个待解析的url列表crawl_url_queue = [seed_url]# 定义一个字典,记录链接和深度,用于判断链接是否已经下载,避免在不同页面中反复横跳have_crawl_url_queue = {seed_url:0}downloader = Downloader(delay=delay,user_agent=current_user_agent,cache=cache,request_max=request_max,proxies=proxies)for item_count in range(1,10):current_url = "{}?start={}".format(seed_url,item_count*25)crawl_url_queue.append(current_url)have_crawl_url_queue[current_url] = 0def process_queue():current_thread = threading.current_thread()thread_name = current_thread.namewhile crawl_url_queue:try:# 只要列表中有值,则弹出一个url用于解析url = crawl_url_queue.pop()print("线程{}==>正在处理:{}".format(thread_name,url))except IndexError as index_error:breakelse:# 读取当前要解析url的深度,如果深度超过最大值,则停止deepth = have_crawl_url_queue[url]if deepth <= max_deepth:# 执行下载html = downloader(url)if not html == None:# 如果有传入提取数据的回调函数,则调用它if scrape_callback:scrape_callback(html)# 从下载到的html网页中递归的获取链接links_from_html = get_links(html)if not links_from_html == None:for link in links_from_html:link = urljoin(seed_url,link)# 判断找到的链接是否符合我们想要的正则表达式if re.match(link_regex,link):# 如果符合,再判断是否已经下载过了,如果没有下载过,就把它加到待解析的url列表和已下载集合中if link not in have_crawl_url_queue:have_crawl_url_queue[link] = deepth + 1crawl_url_queue.append(link)threads = []while threads or crawl_url_queue:for thread in threads:if not thread.is_alive():threads.remove(thread)while len(threads) < max_threads and crawl_url_queue:thread = threading.Thread(target=process_queue)thread.setDaemon(True)thread.start()threads.append(thread)# 从下载到的html中继续解析连接
def get_links(html):webpage_regex = re.compile('<a[^>]+href=["\'](.*?)["\']',re.IGNORECASE)if not html == None:html_string = html.decode("utf-8")return webpage_regex.findall(html_string)else:return None# 测试
seed_url="https://movie.douban.com/top250"
link_regex="^https://(?!music\\.douban\\.com/subject/)movie\\.douban\\.com/subject/(\\d+)/$"
threaded_crawler(5,5,seed_url,link_regex,5)原因分析:
当多个进程或线程试图同时写入同一个CSV文件时,因为文件I/O操作不是线程安全的,特别是在没有适当锁定机制的情况下,在这个脚本中,虽然使用了锁,但是锁只是锁定了线程间的竞争,多个进程在写入的时候,实际上是存在文件覆盖的情况的;为了解决这个问题,我们可以采用“分而治之”的策略:让每个进程将其结果写入一个独立的CSV文件,然后再合并这些文件。
解决方案:
在调用Scrape_callback()类时,为其传入进程的ID,让每一条进程单独处理一个csv文件,这样就不存在文件覆盖的问题,在解析完所有的文件后,再将这些csv文件合并为一个文件输出。
from datetime import datetime,timedelta
import multiprocessing
import os
import random
import re
import threading
import time
import urllib.parse
import urllib.request
import urllib3
from urllib.parse import urlparse, urlsplit
from urllib.parse import urljoin
import urllib.robotparser
from lxml import html as lhtml
import csv
import pickle
import zlib
from bson.binary import Binary
from pymongo import MongoClient,errors
from zipfile import ZipFile
from io import StringIO
# 多进程
# 封装MongoDB进程队列
class MongoQueue:OUTSTANDING,PROCESSING,COMPLETE = range(3)def __init__(self,client=None,timeout=300):if client == None:self.client = MongoClient('localhost',27017)else:self.client = clientself.db = self.client['cache']self.webpage = self.db['crawler_queue']self.timeout = timeoutself.lock = threading.Lock()def __bool__(self):record = self.webpage.find_one({'status':{'$ne':self.COMPLETE}})if record:return Trueelse:return Falsedef push(self,url):with self.lock:try:self.webpage.insert_one({'_id':url,'status':self.OUTSTANDING,'timestamp':datetime.now()})except errors.DuplicateKeyError as e:self.repair()passdef pop(self):with self.lock:record = self.webpage.find_one_and_update(filter = {'status':self.OUTSTANDING},update={'$set':{'status':self.PROCESSING,'timestamp':datetime.now()}})if record:return record['_id']else:self.repair()raise KeyError()def complete(self,url):#self.webpage.update_one({'_id':url},{'$set':{'status':self.COMPLETE}})self.webpage.delete_one({'_id':url})def repair(self):record = self.webpage.find_one_and_update(filter={'timestamp':{'$lt':datetime.now() - timedelta(seconds=self.timeout)},'status':{'$ne':self.OUTSTANDING}},update={'$set':{'status':self.OUTSTANDING}})if record:print("Released:{}".format(record['_id']))def clear(self):self.webpage.delete_many({'status':{'$ne':self.OUTSTANDING}})# 封装磁盘缓存类
class DiskCache:def __init__(self,max_length,cache_dir='D:\\Crawl_Results\\cache',expires=timedelta(days=30)):self.cache_dir = cache_dirself.max_length = max_lengthself.expires = expiresdef url_to_path(self,url):'''从传入的url中创建文件路径'''components = urlsplit(url)path = components.pathif not path:path = '/index.html'elif path.endswith('/'):path += 'index.html'filename = components.netloc + path + components.queryfilename = re.sub('[^/0-9a-zA-Z\\-.,;]','_',filename)filename = '/'.join(segment[:255] for segment in filename.split('/'))return os.path.join(self.cache_dir,filename)def __getitem__(self,url):'''根据url从磁盘提取缓存'''path = self.url_to_path(url)if os.path.exists(path):with open(path,'rb') as fp:#result,timestamp = pickle.loads(zlib.decompress(fp.read()))result = fp.read()# if self.has_expired(timestamp):# raise KeyError(url + '缓存资源已过期')# return resultelse:raise KeyError(url + "不存在")def __setitem__(self,url,result):'''将数据存入磁盘缓存中'''path = self.url_to_path(url)folder = os.path.dirname(path)# 时间戳# timestamp = datetime.now()# data = pickle.dumps((result,timestamp))if not os.path.exists(folder):os.makedirs(folder)print("保存到了{}".format(folder))with open(path,'wb') as fp:#fp.write(zlib.compress(data))fp.write(result)def has_expired(self, timestamp):'''判断缓存是否过期'''return datetime.now() > timestamp + self.expires# 封装MongoDB缓存类
class MongoCache:def __init__(self,client=None,expires=timedelta(days=30)):if client == None:self.client = MongoClient('localhost',27017)else:self.client = clientself.db = self.client['cache']self.webpage = self.db['webcrawler']self.expires = expiresself.webpage.create_index('timestamp',expireAfterSeconds=expires.total_seconds())def __getitem__(self,url):'''根据url从磁盘提取缓存'''record = self.webpage.find_one({'_id':url})if record:return pickle.loads(zlib.decompress(record['result']))else:raise KeyError(url + "不存在")def __setitem__(self,url,result):'''将数据存入磁盘缓存中'''record = {'result':Binary(zlib.compress(pickle.dumps(result))),'timestamp':datetime.now()}self.webpage.update_one({'_id':url},{'$set':record},upsert=True)# 将下载功能封装成一个类
class Downloader:def __init__(self,delay=5,user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0',proxies=None,request_max=3,cache=None):self.throttle = Throttle(delay=delay)self.user_agent = user_agentself.proxies = proxiesself.request_max = request_maxself.cache = cache# 定义连接管理池self.http = urllib3.PoolManager()def __call__(self,url):result = Noneif self.cache:try:result = self.cache[url]except KeyError:passelse:if self.request_max > 0 and 500 <= result['code'] < 600:result = Noneif result is None:self.throttle.wait(url)proxy = random.choice(self.proxies) if self.proxies else Noneheaders = {'User-agent':self.user_agent}result = self.download(url,headers,self.request_max,proxy)if self.cache:self.cache[url] = resultreturn result['html']def download(self,url,headers,request_max,proxy=None):print("正在下载, URL==>{}".format(url))# 发起GET请求request = urllib.request.Request(url,headers=headers)response = self.http.request('GET', url,headers=headers)# 如果使用代理的话if proxy:opener = urllib.request.build_opener()proxy_params = {urlparse.urlparse(url).scheme:proxy}opener.add_handler(urllib.request.ProxyHandler(proxy_params))try:response = opener.open(request)if response.status == 200:html = response.dataelse:print("遇到了错误,状态码是:{}".format(response.status))if request_max >= 0:self.download(url,headers,request_max-1,proxy)except Exception as e:print("下载遇到了错误,错误代码是==>{}".format(e))html = Noneif request_max >=3:html = self.download(url,headers,request_max-1,proxy)finally:response.release_conn()return {'html':html,'code':response.status}else:# 如果没有选择代理,那就正常请求try:if response.status == 200:html_file = response.data # 或者 response.data.decode('utf-8') 如果需要字符串# 在这里处理 htmlfile,比如保存到文件或进行解析等return {'html':html_file,'code':response.status}else:print("遇到了错误,状态码是:{}".format(response.status))if request_max >= 0:self.download(url,headers,request_max-1)except urllib3.exceptions.HTTPError as e:print("遇到了错误,错误代码是==>{}".format(e))except Exception as ex:print("遇到了错误,错误代码是==>{}".format(ex))finally:response.release_conn()# 定义一个scrape_callback类,用于存储解析到的数据
class Scrape_callback:def __init__(self,process_id):self.writer = csv.writer(open(f'D:/Crawl_Results/downloaded_data_{process_id}.csv','w', encoding='utf-8',newline='',errors='replace'))self.fields = ('中文名','外文名','评分','上映时间','国家','导演','时长','类型')self.writer.writerow(self.fields)self.process_id = process_idself.lock = threading.Lock()def __call__(self,html):with self.lock:if not self.writer:raise RuntimeError("CSV writer is not initialized. Call open_writer() first.")html_string = html.decode("utf-8")root = lhtml.fromstring(html_string)result_list = []try:# 解析电影标题title_content = root.cssselect("div#content")[0]span_title = title_content.cssselect('span[property="v:itemreviewed"]')[0]title_text = span_title.text_content().split(" ",1)for name in title_text:result_list.append(name)if len(title_text) == 1:result_list.append('--')# 解析电影评分rate_span = root.cssselect('strong[property="v:average"]')[0]rate_text = rate_span.text_content()result_list.append(rate_text)# 解析上映国家及日期date_span = root.cssselect('span[property="v:initialReleaseDate"]')[0]date_text = date_span.text_content()parenthesis_index = date_text.find('(')if parenthesis_index != -1:# 提取日期部分(括号前的所有字符)date = date_text[:parenthesis_index]# 提取国家部分(括号内及之后的字符,再去除括号)country = date_text[parenthesis_index + 1:-1]else:# 如果没有找到括号,则只有日期部分date = date_textcountry = "--"result_list.append(date)result_list.append(country)# 解析导演direct_by_a = root.cssselect('a[rel="v:directedBy"]')[0]direct_by_text = direct_by_a.text_content()result_list.append(direct_by_text)# 解析片长runtime_span = root.cssselect('span[property="v:runtime"]')[0]runtime_text = runtime_span.text_content()result_list.append(runtime_text)gener_text=''# 解析类型gener_spans = root.cssselect('span[property="v:genre"]')for gener_span in gener_spans:gener_text += gener_span.text_content() + '|'gener_text = gener_text.rstrip('|')result_list.append(gener_text)print("{}|{}|{}|{}|{}".format(title_text,rate_text,date,country,direct_by_text,gener_text))self.writer.writerow(result_list)result_list.clear() # 清空列表以备下次使用,而不是重新创建except IndexError:print("未找到指定的元素")except Exception as e:print(f"处理过程中发生错误: {e}")def do_write(self,result_list):if not self.writer == None:self.writer.writerow(result_list)else:print("打开文件失败")def close_writer(self):# 如果writer是外部创建的,则不应在此关闭文件# 但在当前上下文中,文件是在这个类中打开的,所以应该在这里关闭if self.writer:#self.writer.writerow([]) # 写入空行作为结束标记(可选)# 注意:在with块外不需要手动关闭文件,它会自动处理self.writer = None # 清除writer引用,帮助垃圾回收# 定义一个类,用于控制延时
class Throttle:'''用于控制爬虫访问统一域名资源时的延时'''# 初始化函数def __init__(self,delay):self.delay = delayself.domains = {}# 控制延时def wait(self,url):# 解析url,获取域名domain = urlparse(url).netloc# 获取上一次访问的时间last_accessed = self.domains.get(domain)# 如果设置到延时并且已经访问过了if self.delay > 0 and last_accessed is not None:# 计算从上次访问到当前时间过去的秒数与规定的延迟时长的差值sleep_secs = self.delay - (datetime.now() - last_accessed).seconds# 判断距离上次访问的时间间隔是否达到了延迟要求if sleep_secs > 0:print("正在休眠,将等待{}秒后再次连接".format(sleep_secs))# 如果时间还没有达到,就调用time.sleep,进行休眠time.sleep(sleep_secs)# 更新本次访问的时间self.domains[domain] = datetime.now()# 爬取网页的函数
def threaded_crawler(seed_url,link_regex,process_id,max_threads=3,crawl_queue = MongoQueue()):# 创建用于文件解析的类scrape_callback = Scrape_callback(process_id)# 定义一个User_agent列表user_agent_list = ['BadCrawler','GoodCrawler']# 解析网站的robots.txtrp = urllib.robotparser.RobotFileParser()rp.set_url(f"{seed_url}/robots.txt")rp.read()# 定义一个用户当前设置的user_agentcurrent_user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'# 只有当默认的火狐这个User-agent被禁,再从user_agent_list中找看还有合适的没if not rp.can_fetch(current_user_agent,seed_url):# 从列表中找一个网站允许的user_agentfor user_agent in user_agent_list:if rp.can_fetch(user_agent,seed_url):current_user_agent = user_agentbreakelse:print("该网站的robots.txt禁止我们访问")# 创建队列并把种子url添加进去crawl_queue.push(seed_url)downloader = Downloader(delay=5,user_agent=current_user_agent,cache=MongoCache(),request_max=5,proxies=None)for item_count in range(1,10):current_url = "{}?start={}".format(seed_url,item_count*25)crawl_queue.push(current_url)def process_queue():current_thread = threading.current_thread()thread_name = current_thread.namewhile crawl_queue:try:#print("当前有带解析的链接共{}条".format(len(crawl_queue)))# 只要列表中有值,则弹出一个url用于解析url = crawl_queue.pop()except IndexError as index_error:print("出错了")breakexcept KeyError as keyerror:passelse:# 执行下载html = downloader(url)if not html == None:# 如果有传入提取数据的回调函数,则调用它scrape_callback(html)# 从下载到的html网页中递归的获取链接links_from_html = get_links(html)if not links_from_html == None:for link in links_from_html:link = urljoin(seed_url,link)# 判断找到的链接是否符合我们想要的正则表达式if re.match(link_regex,link):crawl_queue.push(link)# 修改url的状态crawl_queue.complete(url)threads = []while threads or crawl_queue:for thread in threads:if not thread.is_alive():threads.remove(thread)while len(threads) < max_threads and crawl_queue:thread = threading.Thread(target=process_queue)thread.setDaemon(True)thread.start()threads.append(thread)scrape_callback.close_writer()crawl_queue.clear()# 多进程函数
def process_link_crawler(args,**kwargs):# 解包参数以获取seed_url和link_regexseed_url, link_regex = argsnum_cpus = multiprocessing.cpu_count()processes = []csv_files = []use_cpu = num_cpus//4for i in range(use_cpu):process_id = f"pid_{os.getpid()}_{i}" # 生成唯一的进程ID标识符csv_files.append(f'D:/Crawl_Results/downloaded_data_{process_id}.csv')p = multiprocessing.Process(target=threaded_crawler, args=(seed_url, link_regex, process_id))p.start()processes.append(p)for p in processes:p.join()# 解析完毕,开始合并文件# 合并CSV文件merge_csv_files(csv_files, 'D:/Crawl_Results/merged_data.csv')# 用于合并csv的
def merge_csv_files(csv_files, output_file):with open(output_file, 'w', encoding='utf-8', newline='') as outfile:writer = csv.writer(outfile)for csv_file in csv_files:with open(csv_file, 'r', encoding='utf-8', errors='replace') as infile:reader = csv.reader(infile)next(reader) # 跳过标题行,因为它已经在第一个文件中写入了for row in reader:writer.writerow(row)print("合并成功!")# 清理单独的CSV文件(可选)for csv_file in csv_files:os.remove(csv_file)# 从下载到的html中继续解析连接
def get_links(html):webpage_regex = re.compile('<a[^>]+href=["\'](.*?)["\']',re.IGNORECASE)if not html == None:html_string = html.decode("utf-8")return webpage_regex.findall(html_string)else:return Nonedef main():# 测试seed_url2="https://movie.douban.com/annual/2023/"seed_url="https://movie.douban.com/top250"link_regex="^https://(?!music\\.douban\\.com/subject/)movie\\.douban\\.com/subject/(\\d+)/$"process_link_crawler((seed_url,link_regex))if __name__ == '__main__':main()相关文章:
爬虫中使用多进程、多线程的混合方式遇到的数据丢失问题
项目场景: 网络爬虫项目,主要实现多进程、多线程方式快速缓存网页资源到MongoDB,并解析网页数据,将信息写入到csv文件中。 问题描述 在单独使用多线程的过程中,是没有问题的,比如这个爬虫示例是爬取豆瓣电…...

多云应用安全平台RegData利用MongoDB简化数据控制和合规流程
在高度规范化市场中,为了保障数据安全,企业可能需要部署一系列繁琐且成本高昂的IT基础设施系统。随着各项数据安全保护措施的出台,企业需要遵守的法规数量越多,尤其是跨越多个地域的企业,其IT基础设施就会越复杂。如今…...

VUE实现TAB切换不同页面
VUE实现TAB切换不同页面 实现效果 资源准备 ReceiveOrderList, TodoListMulti, SignList 这三个页面就是需要切换的页面 首页代码 <template><div><el-tabs v-model"activeTab" type"card" tab-click"handleTabClick"><…...

C++ 80行 极简扫雷
一共5346个字符,MinGW编译通过(强烈不建议写这种代码!!!) 压行规则:一行不超过80个字符 代码: #include<windows.h> #include<stdio.h> #include<time.h> #def…...

常见VPS服务器附加组件一览
网络主机行业竞争非常激烈,因此主机服务提供商竭尽全力为客户提供完整的解决方案,其中包含构建和管理在线项目所需的一切。但客户通常有特定需求,因此需要不同的附加组件。在管理自己的网络服务器时尤其如此。 今天,我们将介绍您…...

Electron 使用Electron-build 进行打包
看完下面两篇就可以完成! 基于vue3vite的web项目改为Electron桌面应用(一)_vue3转electron-CSDN博客 将web项目打包成electron桌面端教程(二)vue3vitets_vue3 打包桌面端-CSDN博客 打包报错 1. 首先确定依赖包 npm …...

Springboot+Websocket+Security+Vue 实现弹幕推送功能
后端部分 (Spring Boot) 1. 创建一个 Spring Boot 项目 创建一个新的 Spring Boot 项目并添加以下依赖: <dependencies><!-- Spring Boot Starter Web --><dependency><groupId>org.springframework.boot</groupId><artifactId…...
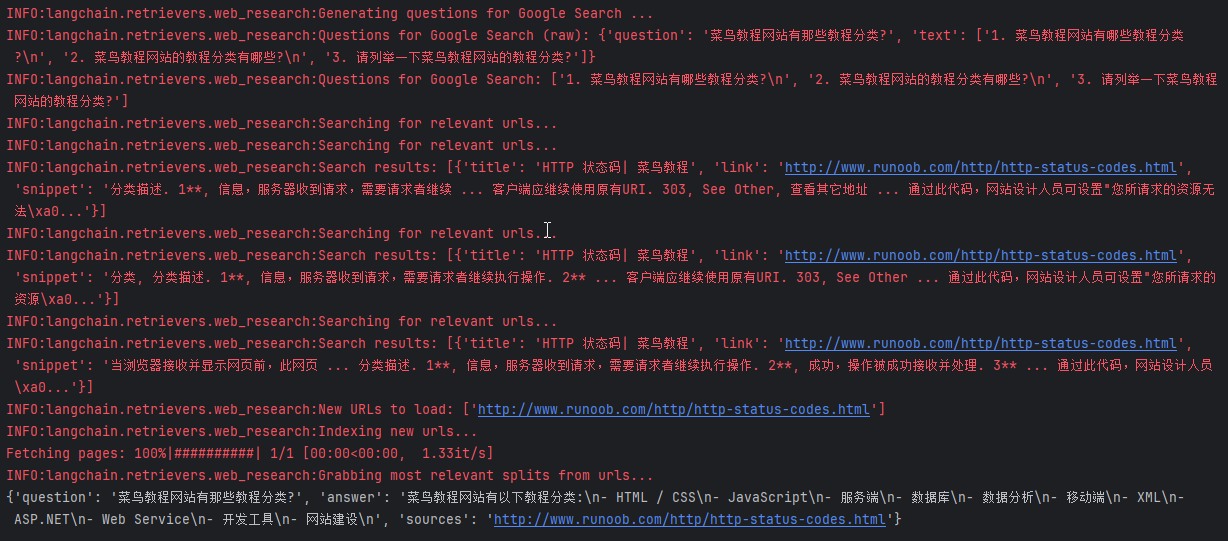
LangChain之网络爬虫
网络爬虫 概述 网络爬虫是LangChain中的一项关键功能,允许用户自动从互联网上收集信息。这项功能对于研究和数据收集尤其有价值,因为它可以大幅减少手动搜索和信息整理的工作量。 从网络收集内容有几个主要组件: Search搜索:使用…...

VueRouter 相关信息
VueRouter 是Vue.js官方路由插件,与Vue.js深度集成,用于构建单页面应用。构建的单页面是基于路由和组件,路由设定访问路径,将路径与组件进行映射。VueRouter有两中模式 :hash 和 history ,默认是hash模式。…...
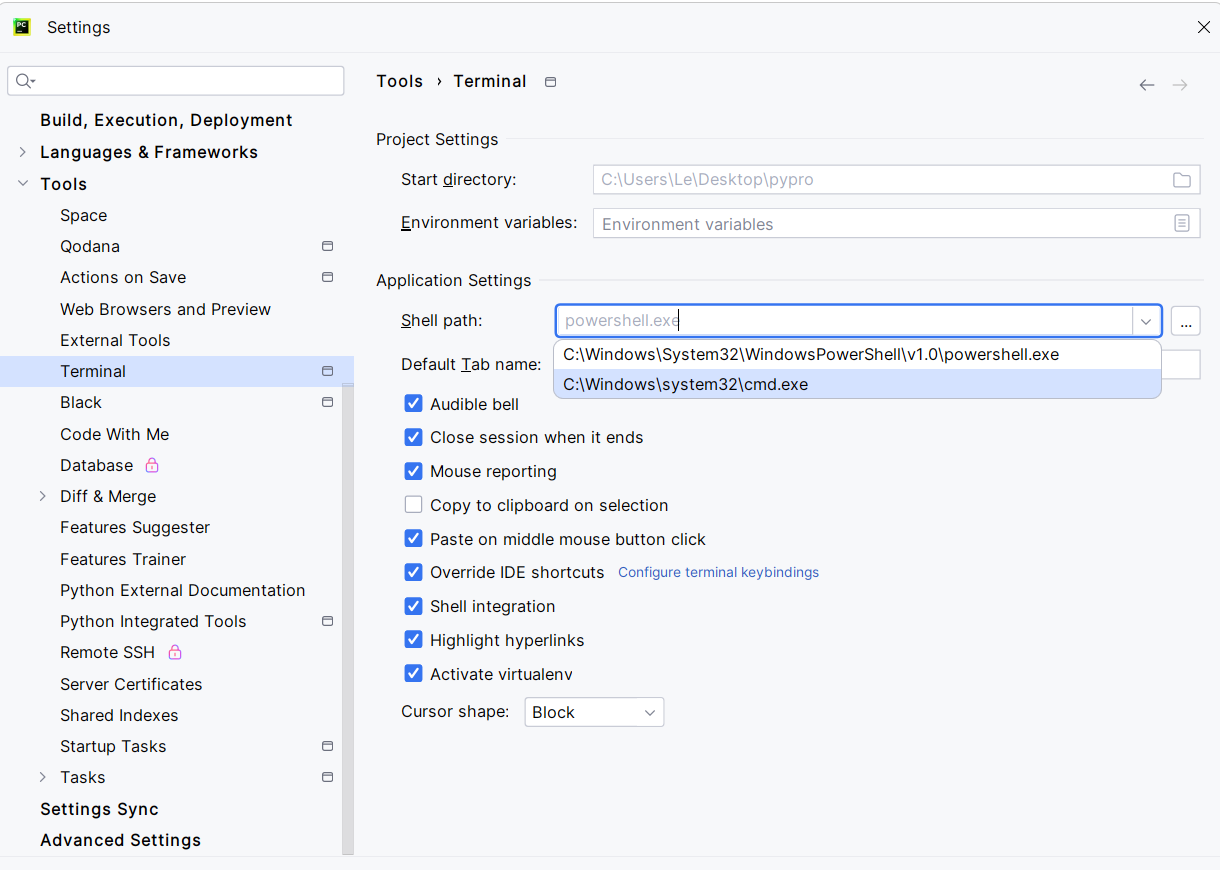
[环境配置]Pycharm:Failed to start [PowerShell.exe]
解决方法,点Local旁边的 号,点击Command Prompt,即可在Pycharm中呼出控制台。 如果要修改Command Prompt的启动时访问的cmd.exe的路径,可以去Settings→Tools→Terminal中,修改Shell Path实现,改为cmd.exe…...

搜狗爬虫(www.sogou.com)IP及UA,真实采集数据
一、数据来源: 1、这批搜狗爬虫(www.sogou.com)IP来源于尚贤达猎头网站采集数据; 2、数据采集时间段:2023年10月-2024年7月; 3、判断标准:主要根据用户代理是否包含“www.sogou.com”和IP核实…...

北京青蓝智慧科技ITSS服务经理:长安链ChainBridge“链桥”问世 加速国家级区块链网络互联互通
8月5日,据国家区块链技术创新中心消息,我国首个完全自主控制的区块链软硬件技术系统——长安链,正式推出了全场景技术平台ChainBridge“链桥”。 此平台能够支持所有异构和同构的区块链进行协作,满足跨领域、跨地域、跨行业及跨层…...

音视频入门基础:WAV专题(5)——FFmpeg源码中解码WAV Header的实现
音视频入门基础:WAV专题系列文章: 音视频入门基础:WAV专题(1)——使用FFmpeg命令生成WAV音频文件 音视频入门基础:WAV专题(2)——WAV格式简介 音视频入门基础:WAV专题…...

爬虫:csv存储:写入和读取
目录 csv写入 csv读取 csv写入 import csv# data [ # (tf, 20, 180), # (dl, 20, 170), # (hc, 18, 190) # ] # header (姓名,年龄,身高) # # # csv写入数据会默认写一行隔一行 newline就是让它不要有空行 # with open(text.csv,w,encodingutf8,newline) as f:…...
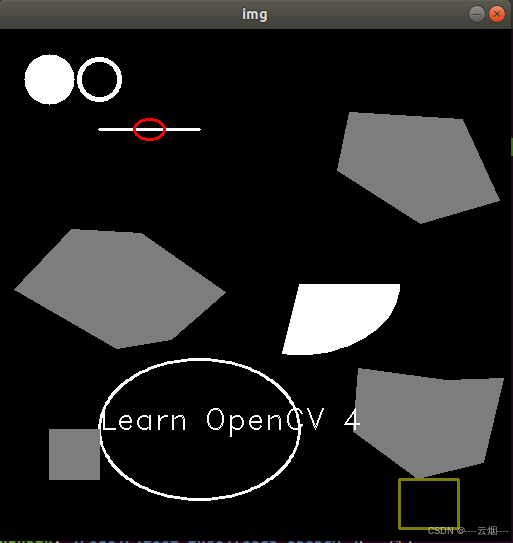
Opencv-绘制几何图形
1. 绘制圆形 1.1 circle()函数原型 void cv::circle(InputOutputArray img, Point center, int radius, const Scalar & color, int thickness 1, int lineType LINE_8, int shift 0 ) img:需要绘制圆形的图像。 center:圆形的圆心位置坐标。 …...

ElasticSearch安装与集群部署
ElasticSearch安装与集群部署 很多小伙伴第一次接触ElasticSearch的时候是一脸愁容,这个东西他怎么用啊,不知道从哪里安装,那我们今天就着重从哪里下载?怎么下载?怎么安装?来研究一下吧! windows下载安装ElasticSearch 下载地址:https://www.elastic.co/cn/do…...

盘点12款企业常用源代码加密软件,源代码防泄密很重要!
在当今的商业环境中,源代码作为企业的核心资产之一,其安全性不容忽视。源代码的泄露可能导致企业丧失竞争优势、面临法律诉讼甚至经济损失。因此,选择合适的源代码加密软件成为企业保护知识产权和核心技术的关键步骤。 1. 安秉源代码加密软件…...

文件上传和下载
要想实现文件上传和下载,其实只需要下述代码即可: 文件上传和下载 import cn.hutool.core.io.FileUtil; import cn.hutool.core.util.StrUtil; import com.example.common.Result; import org.springframework.web.bind.annotation.*; import org.sprin…...

机械学习—零基础学习日志(高数22——泰勒公式理解深化)
核心思想:函数逼近 在泰勒的年代,如果想算出e的0.001次方,这是很难计算的。那为了能计算这样的数字,可以尝试逼近的思想。 但是函数又不能所有地方都相等,那退而求其次,只要在一个极小的范围,…...

Java | Leetcode Java题解之第318题最大单词长度乘积
题目: 题解: class Solution {public int maxProduct(String[] words) {Map<Integer, Integer> map new HashMap<Integer, Integer>();int length words.length;for (int i 0; i < length; i) {int mask 0;String word words[i];in…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器
BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

从API Key管理视角看Taotoken平台的安全与审计功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API Key管理视角看Taotoken平台的安全与审计功能 对于依赖大模型API进行开发的团队而言,API Key的管理与安全是项目稳…...