LangChain之网络爬虫
网络爬虫
概述
网络爬虫是LangChain中的一项关键功能,允许用户自动从互联网上收集信息。这项功能对于研究和数据收集尤其有价值,因为它可以大幅减少手动搜索和信息整理的工作量。
从网络收集内容有几个主要组件:
Search搜索:使用工具如GoogleSearchAPIWrapper查询并获取URL列表。Loading加载:将URL转换为HTML内容,使用工具如AsyncHtmlLoader或AsyncChromiumLoader。Transforming转换:将HTML内容转换为格式化文本,使用HTML2Text或BeautifulSoup等工具。
准备
安装相关依赖库
pip install langchain-openai langchain playwright beautifulsoup4
设置OpenAI的BASE_URL、API_Key
import osos.environ["OPENAI_BASE_URL"] = "https://xxx.com/v1"
os.environ["OPENAI_API_KEY"] = "sk-dtRXRfYzHDZQT8Cr2874xxxx13F97bF24b7a"
加载器
使用Chromium的无头实例爬取HTML内容,无头模式意味着浏览器在没有图形用户界面的情况下运行,这通常用于网页抓取。
主要有2种方式:
| 方式 | 加载器 | 描述 |
|---|---|---|
| Python的asyncio库 | AsyncHtmlLoader | 使用该库aiohttp发出异步 HTTP 请求,适合更简单、轻量级的抓取。 |
| Playwright | AsyncChromiumLoader | 使用 Playwright 启动 Chromium 实例,该实例可以处理 JavaScript 渲染和更复杂的 Web 交互。 |
注意:
Chromium 是 Playwright 支持的浏览器之一,Playwright 是一个用于控制浏览器自动化的库。
from langchain_community.document_loaders import AsyncChromiumLoader# 加载HTML
loader = AsyncChromiumLoader(["https://www.langchain.com"])
html = loader.load()
转换
html2text
html2text 是一个 Python 包,它将 HTML 页面转换为干净、易于阅读的纯文本,无需任何特定的标签操作。它最适合目标是提取人类可读文本而不需要操作特定HTML元素的场景。
要使用html2text,首先需要额外安装
pip install html2text
使用示例如下:
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import Html2TextTransformer# 加载HTML
loader = AsyncChromiumLoader(["https://www.langchain.com"])
html = loader.load()# # 转换
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(html)# 结果
res = docs_transformed[0].page_content[0:500]
print(res)
Beautiful Soup
Beautiful Soup 提供对 HTML 内容更细粒度的控制,支持特定标签的提取、删除和内容清理。它适合根据需要提取特定信息并清理 HTML 内容的情况。
要使用Beautiful Soup,首先也是需要安装
pip install beautifulsoup4
使用示例如下
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
# 加载HTML
loader = AsyncChromiumLoader(["https://www.langchain.com"])
html = loader.load()# # 转换
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(html, tags_to_extract=["h1"])# 结果
res = docs_transformed[0].page_content[0:500]
print(res)
从HTML内容中爬取文本内容标签说明
<p>:段落标签。在HTML中定义段落,并用于组合相关句子或短语<li>:列表项标签。用于有序(<ol>)和无序(<ul>)列表中,定义列表中的各个项<div>:分区标签。块级元素,用于组合其他内联或块级元素<a>:锚点标签。用于定义超链接<span>:内联容器,用于标记文本的一部分或文档的一部分
提取
定义模式、架构来指定想要提取的数据类型。键名很重要,因为它告诉 LLM想要什么样的信息。
# 定义模式、架构来指定想要提取的数据类型
schema = {"properties": {"all_tutorial_category": {"type": "string"},"category_item": {"type": "string"},},"required": ["all_tutorial_category"],
}
提取网页内容的爬虫实现如下
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from langchain_openai import ChatOpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitterllm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
from langchain.chains import create_extraction_chain# 定义模式、架构来指定想要提取的数据类型
schema = {"properties": {"category_item": {"type": "string"},},"required": ["category_item"],
}# 执行提取链
def extract(content: str, schema: dict):return create_extraction_chain(schema=schema, llm=llm).invoke(content)# 使用AsyncChromiumLoader加载器
def scrape_with_playwright(urls, schema):loader = AsyncChromiumLoader(urls)docs = loader.load()bs_transformer = BeautifulSoupTransformer()# 限制爬取指定标签内容docs_transformed = bs_transformer.transform_documents(docs, tags_to_extract=["h4"])print("使用 LLM 提取内容")# 获取网站的前 1000 个token文本splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=0)splits = splitter.split_documents(docs_transformed)# 拆分处理extracted_content = extract(schema=schema, content=splits[0].page_content)# 打印内容# pprint.pprint(extracted_content)return extracted_contentif __name__ == '__main__':urls = ["https://www.runoob.com/"]extracted_content = scrape_with_playwright(urls, schema=schema)print(extracted_content)
执行部分日志如下,可以看出数据提前成功
text': [{'category_item': 'HTML'}, {'category_item': 'CSS'}, {'category_item': 'Bootstrap'},
{'category_item': 'Font Awesome'}, {'category_item': 'Foundation'}, {'category_item': 'JavaScript'},
{'category_item': 'HTML DOM'}, {'category_item': 'jQuery'}, ........{'category_item': 'Markdown'}, {'category_item': 'HTTP'},
{'category_item': 'TCP/IP'}, {'category_item': 'W3C'}]}
自动化
可以使用检索器(如WebResearchRetriever)来自动化网络研究过程,以便使用搜索内容回答特定问题。
借助Google的Custom Search JSON API,以程序化地检索和显示来自可编程搜索引擎的搜索结果。,具体阅读文档创建GOOGLE_API_KEY和GOOGLE_CSE_ID
自动化爬取实现如下
from langchain.retrievers.web_research import WebResearchRetriever
from langchain_chroma import Chroma
from langchain_community.utilities import GoogleSearchAPIWrapper
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import logging
from langchain.chains import RetrievalQAWithSourcesChainimport osos.environ["GOOGLE_API_KEY"] = 'AIzaSyBNrdu0_xxxxx-Vk2nDs'
os.environ["GOOGLE_CSE_ID"] = '405fxxxxxx64ca1'# 向量存储:使用 Chroma 客户端进行初始化
vectorstore = Chroma(embedding_function=OpenAIEmbeddings(), persist_directory="./chroma_db_oai"
)# LLM
llm = ChatOpenAI(temperature=0)# 搜索
search = GoogleSearchAPIWrapper()"""
使用上述工具初始化检索器:使用 LLM 生成多个相关搜索查询(一次 LLM 调用)
对每个查询执行搜索
选择每个查询的前 K 个链接(并行多个搜索调用)
从所有选定的链接加载信息(并行抓取页面)
将这些文档索引到矢量存储中
为每个原始生成的搜索查询查找最相关的文档
"""
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search
)# 设置日志
logging.basicConfig()
logging.getLogger("langchain.retrievers.web_research").setLevel(logging.INFO)# 执行
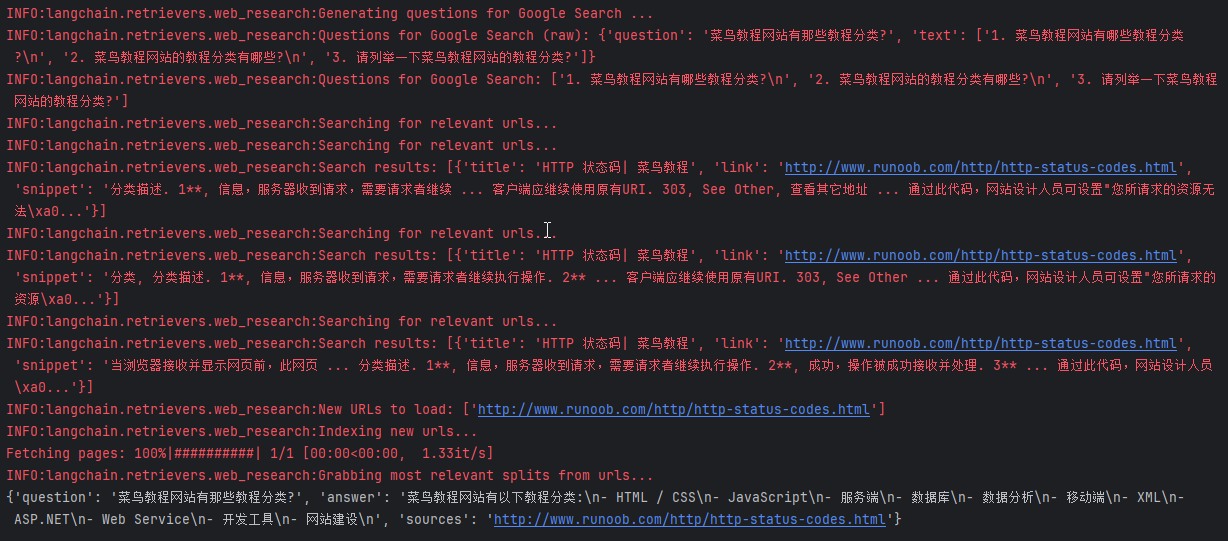
user_input = "菜鸟教程网站有那些教程分类?"
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=web_research_retriever
)
result = qa_chain.invoke({"question": user_input})
print(result)
输出结果如下
相关文章:
LangChain之网络爬虫
网络爬虫 概述 网络爬虫是LangChain中的一项关键功能,允许用户自动从互联网上收集信息。这项功能对于研究和数据收集尤其有价值,因为它可以大幅减少手动搜索和信息整理的工作量。 从网络收集内容有几个主要组件: Search搜索:使用…...

VueRouter 相关信息
VueRouter 是Vue.js官方路由插件,与Vue.js深度集成,用于构建单页面应用。构建的单页面是基于路由和组件,路由设定访问路径,将路径与组件进行映射。VueRouter有两中模式 :hash 和 history ,默认是hash模式。…...
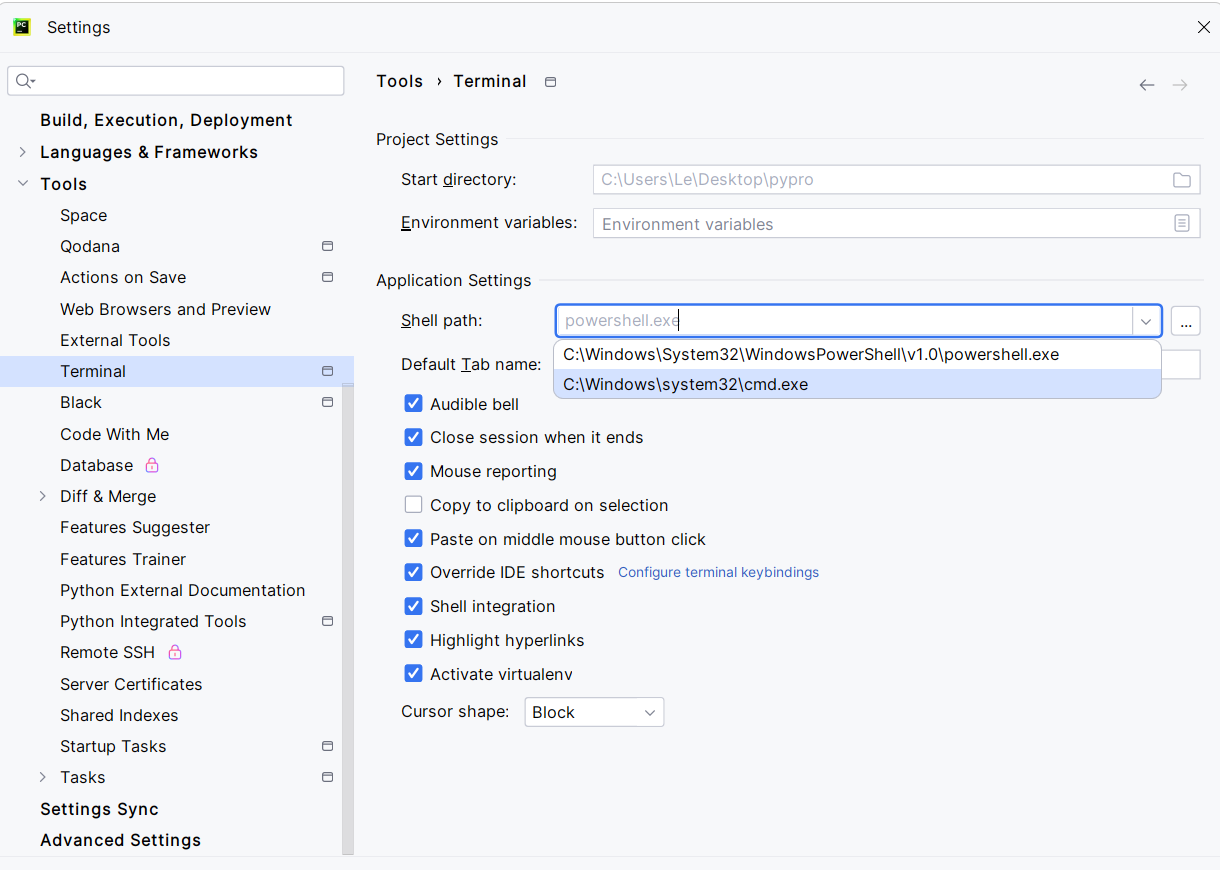
[环境配置]Pycharm:Failed to start [PowerShell.exe]
解决方法,点Local旁边的 号,点击Command Prompt,即可在Pycharm中呼出控制台。 如果要修改Command Prompt的启动时访问的cmd.exe的路径,可以去Settings→Tools→Terminal中,修改Shell Path实现,改为cmd.exe…...

搜狗爬虫(www.sogou.com)IP及UA,真实采集数据
一、数据来源: 1、这批搜狗爬虫(www.sogou.com)IP来源于尚贤达猎头网站采集数据; 2、数据采集时间段:2023年10月-2024年7月; 3、判断标准:主要根据用户代理是否包含“www.sogou.com”和IP核实…...

北京青蓝智慧科技ITSS服务经理:长安链ChainBridge“链桥”问世 加速国家级区块链网络互联互通
8月5日,据国家区块链技术创新中心消息,我国首个完全自主控制的区块链软硬件技术系统——长安链,正式推出了全场景技术平台ChainBridge“链桥”。 此平台能够支持所有异构和同构的区块链进行协作,满足跨领域、跨地域、跨行业及跨层…...

音视频入门基础:WAV专题(5)——FFmpeg源码中解码WAV Header的实现
音视频入门基础:WAV专题系列文章: 音视频入门基础:WAV专题(1)——使用FFmpeg命令生成WAV音频文件 音视频入门基础:WAV专题(2)——WAV格式简介 音视频入门基础:WAV专题…...

爬虫:csv存储:写入和读取
目录 csv写入 csv读取 csv写入 import csv# data [ # (tf, 20, 180), # (dl, 20, 170), # (hc, 18, 190) # ] # header (姓名,年龄,身高) # # # csv写入数据会默认写一行隔一行 newline就是让它不要有空行 # with open(text.csv,w,encodingutf8,newline) as f:…...
Opencv-绘制几何图形
1. 绘制圆形 1.1 circle()函数原型 void cv::circle(InputOutputArray img, Point center, int radius, const Scalar & color, int thickness 1, int lineType LINE_8, int shift 0 ) img:需要绘制圆形的图像。 center:圆形的圆心位置坐标。 …...

ElasticSearch安装与集群部署
ElasticSearch安装与集群部署 很多小伙伴第一次接触ElasticSearch的时候是一脸愁容,这个东西他怎么用啊,不知道从哪里安装,那我们今天就着重从哪里下载?怎么下载?怎么安装?来研究一下吧! windows下载安装ElasticSearch 下载地址:https://www.elastic.co/cn/do…...

盘点12款企业常用源代码加密软件,源代码防泄密很重要!
在当今的商业环境中,源代码作为企业的核心资产之一,其安全性不容忽视。源代码的泄露可能导致企业丧失竞争优势、面临法律诉讼甚至经济损失。因此,选择合适的源代码加密软件成为企业保护知识产权和核心技术的关键步骤。 1. 安秉源代码加密软件…...

文件上传和下载
要想实现文件上传和下载,其实只需要下述代码即可: 文件上传和下载 import cn.hutool.core.io.FileUtil; import cn.hutool.core.util.StrUtil; import com.example.common.Result; import org.springframework.web.bind.annotation.*; import org.sprin…...

机械学习—零基础学习日志(高数22——泰勒公式理解深化)
核心思想:函数逼近 在泰勒的年代,如果想算出e的0.001次方,这是很难计算的。那为了能计算这样的数字,可以尝试逼近的思想。 但是函数又不能所有地方都相等,那退而求其次,只要在一个极小的范围,…...

Java | Leetcode Java题解之第318题最大单词长度乘积
题目: 题解: class Solution {public int maxProduct(String[] words) {Map<Integer, Integer> map new HashMap<Integer, Integer>();int length words.length;for (int i 0; i < length; i) {int mask 0;String word words[i];in…...

科普文:JUC系列之多线程门闩同步器Condition的使用和源码解读
一、概述 条件锁就是指在获取锁之后发现当前业务场景自己无法处理,而需要等待某个条件的出现才可以继续处理时使用的一种锁。 比如,在阻塞队列中,当队列中没有元素的时候是无法弹出一个元素的,这时候就需要阻塞在条件notEmpty上…...
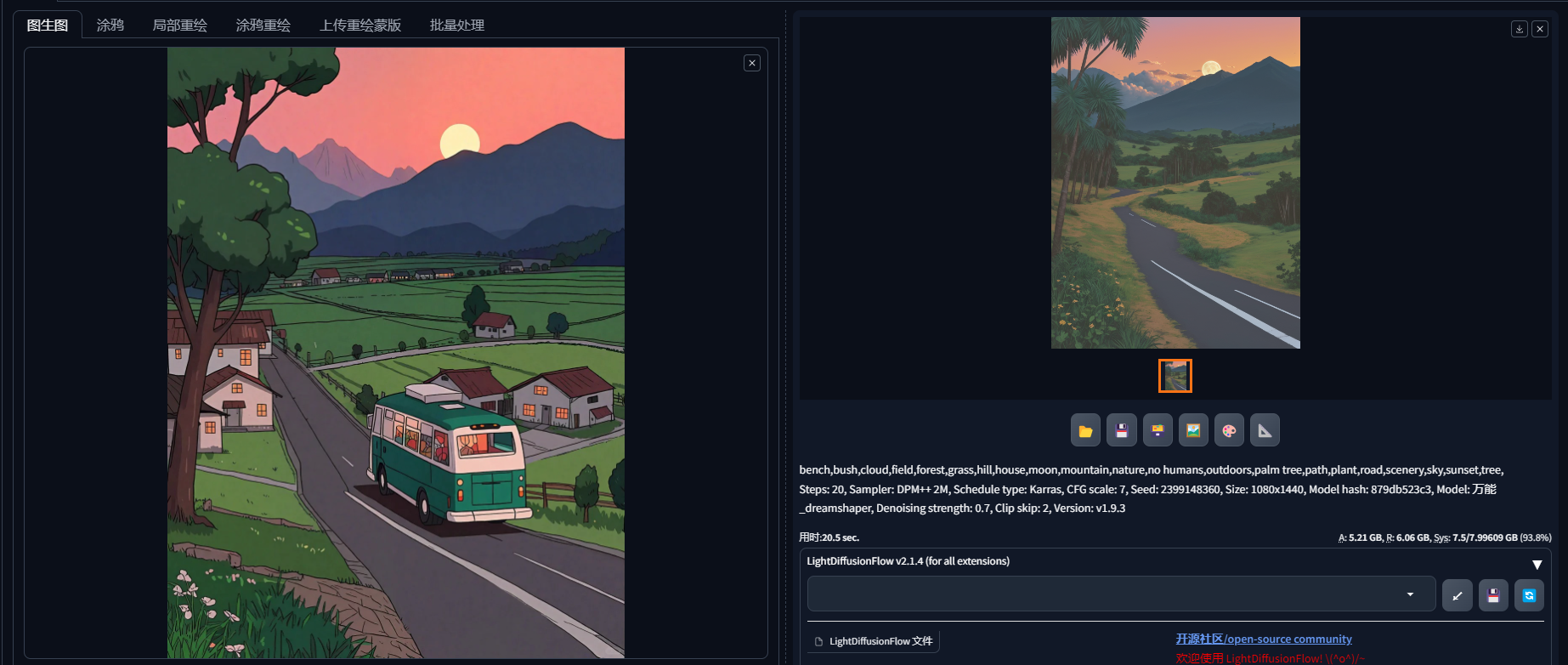
Stable Diffusion绘画 | 图生图-基础使用介绍—提示词反推
按默认设置直接出图 拖入图片值图生图框中,保持默认设置,直接生成图片,出图效果如下: 因为重绘幅度0.7,所出图片与原图有差异,但整体的框架构图与颜色与原图类似。 输入关键词后出图 在正向提示词中输入…...

正点原子imx6ull-mini-Linux驱动之Linux SPI 驱动实验(22)
跟上一章一样,其实这些设备驱动,无非就是传感器对应寄存器的读写。而这个读写是建立在各种通信协议上的,比如上一章的i2c,我们做了什么呢,就是把设备注册成一个i2c平台驱动,这个i2c驱动怎么搞的呢ÿ…...

TypeScript 函数
函数是JavaScript应用程序的基础。 它帮助你实现抽象层,模拟类,信息隐藏和模块。 在TypeScript里,虽然已经支持类,命名空间和模块,但函数仍然是主要的定义 行为 的地方。 TypeScript为JavaScript函数添加了额外的功能&…...

C++ : namespace,输入与输出,函数重载,缺省参数
一,命名空间(namespace) 1.1命名空间的作用与定义 我们在学习c的过程中,经常会碰到命名冲突的情况。就拿我们在c语言中的一个string函数来说吧: int strncat 0; int main() {printf("%d", strncat);return 0; } 当我们运行之后&…...

目标检测 | yolov1 原理和介绍
1. 简介 论文链接:https://arxiv.org/abs/1506.02640 时间:2015年 作者:Joseph Redmon 代码参考:https://github.com/abeardear/pytorch-YOLO-v1 yolo属于one-stage算法,仅仅使用一个CNN网络直接预测不同目标的类别与…...

excel中有些以文本格式存储的数值如何批量转换为数字
一、背景 1.1 文本格式存储的数值特点 在平时工作中有时候会从别地方导出来表格,表格中有些数值是以文本格式存储的(特点:单元格的左上角有个绿色的小标)。 1.2 文本格式存储的数值在排序时不符合预期 当我们需要进行排序的时候…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...

Git Bash 中无法启动 Claude Code ?
最近需要在 git bash 中跑 Claude Code 。git bash 是随 git for windows 套件安装的,很久没更新了,结果启动 Claude Code 报错:Warning: no stdin data received in 3s, proceeding without it. If piping from a slow command, redirect st…...

终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式
终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多个窗口间来回切换,浪费宝…...

3分钟快速上手:bilibili-parse视频解析API终极指南
3分钟快速上手:bilibili-parse视频解析API终极指南 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse bilibili-parse是一款高效专业的B站视频解析工具,为开发者和内容创作者提供…...

告别硬编码!在UE5 GAS中实现动态技能键位绑定:从DataAsset配置到运行时热更新的完整流程
告别硬编码!在UE5 GAS中实现动态技能键位绑定:从DataAsset配置到运行时热更新的完整流程在当代RPG游戏开发中,技能系统的灵活性和可配置性往往决定了项目的迭代效率。传统硬编码的键位绑定方式不仅增加了程序与策划的沟通成本,更在…...