Pandas 与 PySpark 强强联手,功能与速度齐飞
Pandas做数据处理可以说是yyds!而它的缺点也是非常明显,Pandas 只能单机处理,它不能随数据量线性伸缩。例如,如果 pandas 试图读取的数据集大于一台机器的可用内存,则会因内存不足而失败。
另外 pandas 在处理大型数据方面非常慢,虽然有像Dask 或 Vaex 等其他库来优化提升数据处理速度,但在大数据处理神之框架Spark面前,也是小菜一碟。
幸运的是,在新的 Spark 3.2 版本中,出现了一个新的Pandas API,将pandas大部分功能都集成到PySpark中,使用pandas的接口,就能使用Spark,因为 Spark 上的 Pandas API 在后台使用 Spark,这样就能达到强强联手的效果,可以说是非常强大,非常方便。
Spark 现在集成了 Pandas API,因此可以在 Spark 上运行 Pandas。只需要更改一行代码:
import pyspark.pandas as ps
由此我们可以获得诸多的优势:
-
如果我们熟悉使用Python 和 Pandas,但不熟悉 Spark,可以省略了需复杂的学习过程而立即使用PySpark。
-
可以为所有内容使用一个代码库:无论是小数据和大数据,还是单机和分布式机器。
-
可以在Spark分布式框架上,更快地运行 Pandas 代码。
最后一点尤其值得注意。
一方面,可以将分布式计算应用于在 Pandas 中的代码。且借助 Spark 引擎,代码即使在单台机器上也会更快!下图展示了在一台机器(具有 96 个 vCPU 和 384 GiBs 内存)上运行 Spark 和单独调用 pandas 分析 130GB 的 CSV 数据集的性能对比。
技术提升
本文由技术群粉丝分享,项目源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:pythoner666,备注:来自CSDN
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
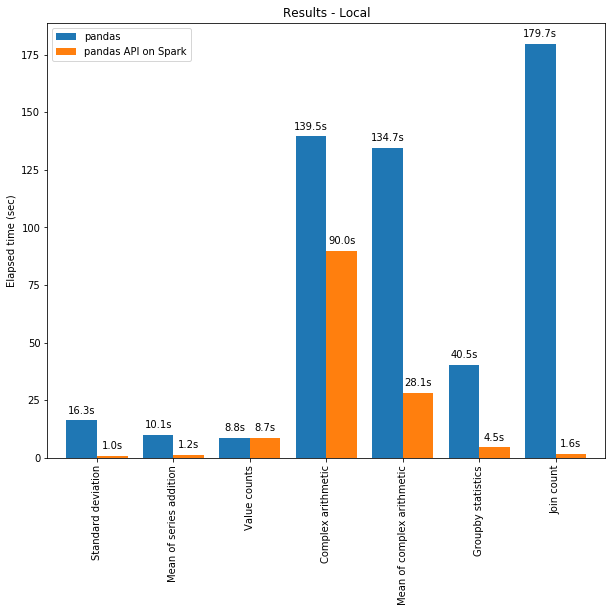
多线程和 Spark SQL Catalyst Optimizer 都有助于优化性能。例如,Join count 操作在整个阶段代码生成时快 4 倍:没有代码生成时为 5.9 秒,代码生成时为 1.6 秒。
Spark 在链式操作(chaining operations)中具有特别显着的优势。Catalyst 查询优化器可以识别过滤器以明智地过滤数据并可以应用基于磁盘的连接(disk-based joins),而 Pandas 倾向于每一步将所有数据加载到内存中。
现在是不是迫不及待的想尝试如何在 Spark 上使用 Pandas API 编写一些代码?我们现在就开始吧!
在 Pandas / Pandas-on-Spark / Spark 之间切换
需要知道的第一件事是我们到底在使用什么。在使用 Pandas 时,使用类pandas.core.frame.DataFrame。在 Spark 中使用 pandas API 时,使用pyspark.pandas.frame.DataFrame。虽然两者相似,但不相同。主要区别在于前者在单机中,而后者是分布式的。
可以使用 Pandas-on-Spark 创建一个 Dataframe 并将其转换为 Pandas,反之亦然:
# import Pandas-on-Spark
import pyspark.pandas as ps # 使用 Pandas-on-Spark 创建一个 DataFrame
ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Pandas Dataframe
pd_df = ps_df.to_pandas() # 将 Pandas Dataframe 转换为 Pandas-on-Spark Dataframe
ps_df = ps.from_pandas(pd_df) 注意,如果使用多台机器,则在将 Pandas-on-Spark Dataframe 转换为 Pandas Dataframe 时,数据会从多台机器传输到一台机器,反之亦然(可参阅PySpark 指南[1])。
还可以将 Pandas-on-Spark Dataframe 转换为 Spark DataFrame,反之亦然:
# 使用 Pandas-on-Spark 创建一个 DataFrame
ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Spark Dataframe
spark_df = ps_df.to_spark() # 将 Spark Dataframe 转换为 Pandas-on-Spark Dataframe
ps_df_new = spark_df.to_pandas_on_spark() 数据类型如何改变?
在使用 Pandas-on-Spark 和 Pandas 时,数据类型基本相同。将 Pandas-on-Spark DataFrame 转换为 Spark DataFrame 时,数据类型会自动转换为适当的类型(请参阅PySpark 指南[2])
下面的示例显示了在转换时是如何将数据类型从 PySpark DataFrame 转换为 pandas-on-Spark DataFrame。
>>> sdf = spark.createDataFrame([
... (1, Decimal(1.0), 1., 1., 1, 1, 1, datetime(2020, 10, 27), "1", True, datetime(2020, 10, 27)),
... ], 'tinyint tinyint, decimal decimal, float float, double double, integer integer, long long, short short, timestamp timestamp, string string, boolean boolean, date date')
>>> sdf
DataFrame[tinyint: tinyint, decimal: decimal(10,0),
float: float, double: double, integer: int,
long: bigint, short: smallint, timestamp: timestamp,
string: string, boolean: boolean, date: date]
psdf = sdf.pandas_api()
psdf.dtypes
tinyint int8
decimal object
float float32
double float64
integer int32
long int64
short int16
timestamp datetime64[ns]
string object
boolean bool
date object
dtype: object
Pandas-on-Spark vs Spark 函数
在 Spark 中的 DataFrame 及其在 Pandas-on-Spark 中的最常用函数。注意,Pandas-on-Spark 和 Pandas 在语法上的唯一区别就是 import pyspark.pandas as ps 一行。
当你看完如下内容后,你会发现,即使您不熟悉 Spark,也可以通过 Pandas API 轻松使用。
导入库
# 运行Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder \ .appName("Spark") \ .getOrCreate()
# 在Spark上运行Pandas
import pyspark.pandas as ps
读取数据
以 old dog iris 数据集为例。
# SPARK
sdf = spark.read.options(inferSchema='True', header='True').csv('iris.csv')
# PANDAS-ON-SPARK
pdf = ps.read_csv('iris.csv')
选择
# SPARK
sdf.select("sepal_length","sepal_width").show()
# PANDAS-ON-SPARK
pdf[["sepal_length","sepal_width"]].head()
删除列
# SPARK
sdf.drop('sepal_length').show()# PANDAS-ON-SPARK
pdf.drop('sepal_length').head()
删除重复项
# SPARK
sdf.dropDuplicates(["sepal_length","sepal_width"]).show()
# PANDAS-ON-SPARK
pdf[["sepal_length", "sepal_width"]].drop_duplicates()
筛选
# SPARK
sdf.filter( (sdf.flower_type == "Iris-setosa") & (sdf.petal_length > 1.5) ).show()
# PANDAS-ON-SPARK
pdf.loc[ (pdf.flower_type == "Iris-setosa") & (pdf.petal_length > 1.5) ].head()
计数
# SPARK
sdf.filter(sdf.flower_type == "Iris-virginica").count()
# PANDAS-ON-SPARK
pdf.loc[pdf.flower_type == "Iris-virginica"].count()
唯一值
# SPARK
sdf.select("flower_type").distinct().show()
# PANDAS-ON-SPARK
pdf["flower_type"].unique()
排序
# SPARK
sdf.sort("sepal_length", "sepal_width").show()
# PANDAS-ON-SPARK
pdf.sort_values(["sepal_length", "sepal_width"]).head()
分组
# SPARK
sdf.groupBy("flower_type").count().show()
# PANDAS-ON-SPARK
pdf.groupby("flower_type").count()
替换
# SPARK
sdf.replace("Iris-setosa", "setosa").show()
# PANDAS-ON-SPARK
pdf.replace("Iris-setosa", "setosa").head()
连接
#SPARK
sdf.union(sdf)
# PANDAS-ON-SPARK
pdf.append(pdf)
transform 和 apply 函数应用
有许多 API 允许用户针对 pandas-on-Spark DataFrame 应用函数,例如:
DataFrame.transform()
DataFrame.apply()
DataFrame.pandas_on_spark.transform_batch()
DataFrame.pandas_on_spark.apply_batch()
Series.pandas_on_spark.transform_batch()
每个 API 都有不同的用途,并且在内部工作方式不同。
transform 和 apply
DataFrame.transform()和DataFrame.apply()之间的主要区别在于,前者需要返回相同长度的输入,而后者不需要。
# transform
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser): return pser + 1 # 应该总是返回与输入相同的长度。 psdf.transform(pandas_plus) # apply
psdf = ps.DataFrame({'a': [1,2,3], 'b':[5,6,7]})
def pandas_plus(pser): return pser[pser % 2 == 1] # 允许任意长度 psdf.apply(pandas_plus)
在这种情况下,每个函数采用一个 pandas Series,Spark 上的 pandas API 以分布式方式计算函数,如下所示。
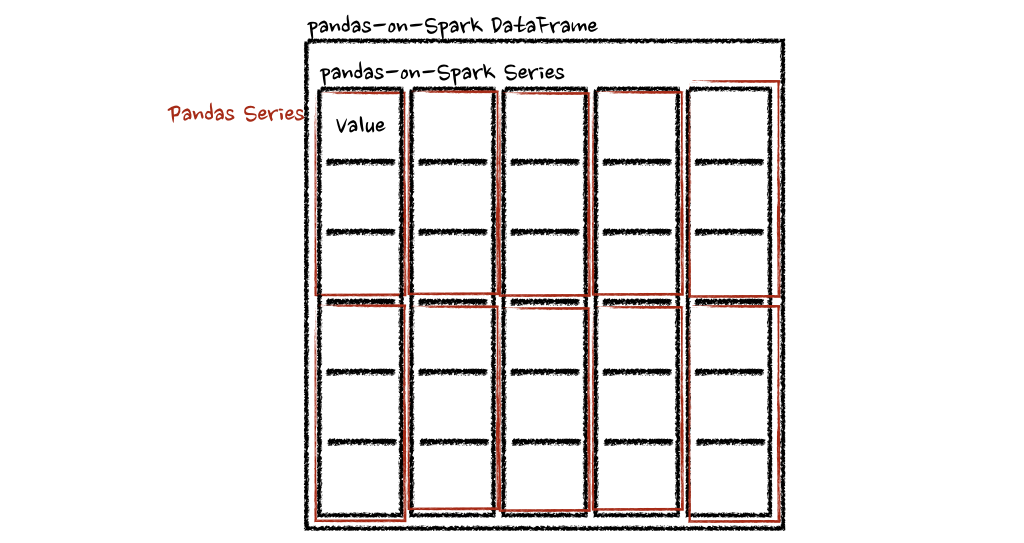
在“列”轴的情况下,该函数将每一行作为一个熊猫系列。
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser): return sum(pser) # 允许任意长度
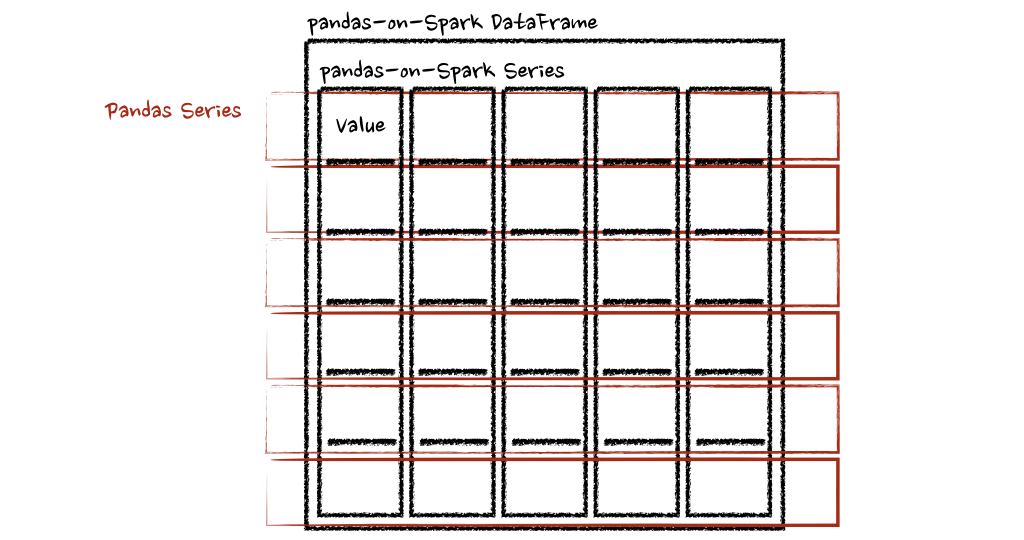
psdf.apply(pandas_plus, axis='columns')
上面的示例将每一行的总和计算为pands Series
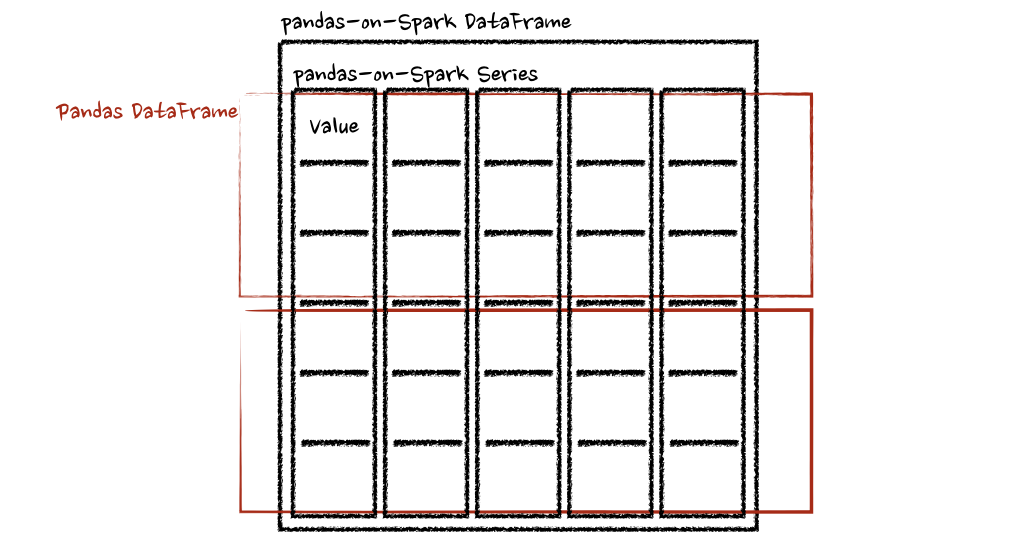
pandas_on_spark.transform_batch和pandas_on_spark.apply_batch
batch 后缀表示 pandas-on-Spark DataFrame 或 Series 中的每个块。API 对 pandas-on-Spark DataFrame 或 Series 进行切片,然后以 pandas DataFrame 或 Series 作为输入和输出应用给定函数。请参阅以下示例:
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf): return pdf + 1 # 应该总是返回与输入相同的长度。 psdf.pandas_on_spark.transform_batch(pandas_plus) psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf): return pdf[pdf.a > 1] # 允许任意长度 psdf.pandas_on_spark.apply_batch(pandas_plus)
两个示例中的函数都将 pandas DataFrame 作为 pandas-on-Spark DataFrame 的一个块,并输出一个 pandas DataFrame。Spark 上的 Pandas API 将 pandas 数据帧组合为 pandas-on-Spark 数据帧。
在 Spark 上使用 pandas API的注意事项
避免shuffle
某些操作,例如sort_values在并行或分布式环境中比在单台机器上的内存中更难完成,因为它需要将数据发送到其他节点,并通过网络在多个节点之间交换数据。
避免在单个分区上计算
另一种常见情况是在单个分区上进行计算。目前, DataFrame.rank 等一些 API 使用 PySpark 的 Window 而不指定分区规范。这会将所有数据移动到单个机器中的单个分区中,并可能导致严重的性能下降。对于非常大的数据集,应避免使用此类 API。
不要使用重复的列名
不允许使用重复的列名,因为 Spark SQL 通常不允许这样做。Spark 上的 Pandas API 继承了这种行为。例如,见下文:
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'b':[3, 4]})
psdf.columns = ["a", "a"]
Reference 'a' is ambiguous, could be: a, a.;
此外,强烈建议不要使用区分大小写的列名。Spark 上的 Pandas API 默认不允许它。
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})
Reference 'a' is ambiguous, could be: a, a.;
但可以在 Spark 配置spark.sql.caseSensitive中打开以启用它,但需要自己承担风险。
from pyspark.sql import SparkSession
builder = SparkSession.builder.appName("pandas-on-spark")
builder = builder.config("spark.sql.caseSensitive", "true")
builder.getOrCreate() import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})
psdf
a A
0 1 3
1 2 4
使用默认索引
pandas-on-Spark 用户面临的一个常见问题是默认索引导致性能下降。当索引未知时,Spark 上的 Pandas API 会附加一个默认索引,例如 Spark DataFrame 直接转换为 pandas-on-Spark DataFrame。
如果计划在生产中处理大数据,请通过将默认索引配置为distributed或distributed-sequence来使其确保为分布式。
有关配置默认索引的更多详细信息,请参阅默认索引类型[3]。
在 Spark 上使用 pandas API
尽管 Spark 上的 pandas API 具有大部分与 pandas 等效的 API,但仍有一些 API 尚未实现或明确不受支持。因此尽可能直接在 Spark 上使用 pandas API。
例如,Spark 上的 pandas API 没有实现__iter__(),阻止用户将所有数据从整个集群收集到客户端(驱动程序)端。不幸的是,许多外部 API,例如 min、max、sum 等 Python 的内置函数,都要求给定参数是可迭代的。对于 pandas,它开箱即用,如下所示:
>>> import pandas as pd
>>> max(pd.Series([1, 2, 3]))
3
>>> min(pd.Series([1, 2, 3]))
1
>>> sum(pd.Series([1, 2, 3]))
6
Pandas 数据集存在于单台机器中,自然可以在同一台机器内进行本地迭代。但是,pandas-on-Spark 数据集存在于多台机器上,并且它们是以分布式方式计算的。很难在本地迭代,很可能用户在不知情的情况下将整个数据收集到客户端。因此,最好坚持使用 pandas-on-Spark API。上面的例子可以转换如下:
>>> import pyspark.pandas as ps
>>> ps.Series([1, 2, 3]).max()
3
>>> ps.Series([1, 2, 3]).min()
1
>>> ps.Series([1, 2, 3]).sum()
6
pandas 用户的另一个常见模式可能是依赖列表推导式或生成器表达式。但是,它还假设数据集在引擎盖下是本地可迭代的。因此,它可以在 pandas 中无缝运行,如下所示:
import pandas as pd
data = []
countries = ['London', 'New York', 'Helsinki']
pser = pd.Series([20., 21., 12.], index=countries)
for temperature in pser: assert temperature > 0 if temperature > 1000: temperature = None data.append(temperature ** 2) pd.Series(data, index=countries)
London 400.0
New York 441.0
Helsinki 144.0
dtype: float64
但是,对于 Spark 上的 pandas API,它的工作原理与上述相同。上面的示例也可以更改为直接使用 pandas-on-Spark API,如下所示:
import pyspark.pandas as ps
import numpy as np
countries = ['London', 'New York', 'Helsinki']
psser = ps.Series([20., 21., 12.], index=countries)
def square(temperature) -> np.float64: assert temperature > 0 if temperature > 1000: temperature = None return temperature ** 2 psser.apply(square)
London 400.0
New York 441.0
Helsinki 144.0
减少对不同 DataFrame 的操作
Spark 上的 Pandas API 默认不允许对不同 DataFrame(或 Series)进行操作,以防止昂贵的操作。只要有可能,就应该避免这种操作。
写在最后
到目前为止,我们将能够在 Spark 上使用 Pandas。这将会导致Pandas 速度的大大提高,迁移到 Spark 时学习曲线的减少,以及单机计算和分布式计算在同一代码库中的合并。
参考资料
[1]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/pandas_pyspark.html
[2]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/types.html
[3]默认索引类型: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/options.html#default-index-type
相关文章:
Pandas 与 PySpark 强强联手,功能与速度齐飞
Pandas做数据处理可以说是yyds!而它的缺点也是非常明显,Pandas 只能单机处理,它不能随数据量线性伸缩。例如,如果 pandas 试图读取的数据集大于一台机器的可用内存,则会因内存不足而失败。 另外 pandas 在处理大型数据…...

【Zabbix实战之部署篇】docker部署Zabbix+grafana监控平台
【Zabbix实战之部署篇】docker部署Zabbix+grafana监控平台 一、Zabbix介绍1.Zabbix简介2.Zabbix的优点3.Zabbix各组件介绍4.Zabbix架构图二、grafana介绍1.grafana简介2.grafana特点三、实践环境规划四、检查本地docker环境1.检查操作系统版本2.检查docker版本3.检查docker服务…...
acm省赛:高桥和低桥(三种做法:区间计数、树状数组、线段树)
题目描述 有个脑筋急转弯是这样的:有距离很近的一高一低两座桥,两次洪水之后高桥被淹了两次,低桥却只被淹了一次,为什么?答案是:因为低桥太低了,第一次洪水退去之后水位依然在低桥之上ÿ…...

stm32-定时器详解
0. 概述 本文针对STM32F1系列,主要讲解了其中的8个定时器的原理和功能 1. 定时器分类 STM32F1 系列中,除了互联型的产品,共有 8 个定时器,分为基本定时器,通用定时器和高级定时器基本定时器 TIM6 和 TIM7 是一个 16 位…...
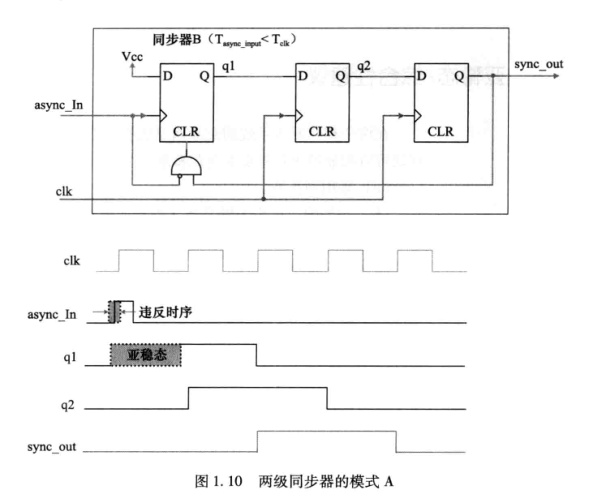
《硬件架构的艺术》读书笔记:Chapter 1 亚稳态的世界
Chapter 1 亚稳态的世界 一、简介 同步系统中,数据和时钟有固定的因果关系(在同一时钟域(Clock Domains))中,只要数据和时钟满足建立时间和保持时间的要求,不会产生亚稳态(meastable) 静态时序分析(STA) 就是基于同步电路设计模型而出现的&am…...
开箱即用的密码框组件
写了一个小玩具,分享一下 - 组件功能: 初次进入页面时,密码隐藏显示,且无法查看真实密码 当修改密码时,触发键盘,输入框则会直接清空 此时输入密码,可以设置密码的隐藏或显示: …...

ChatGPT能否取代程序员?
目录ChatGPT能否取代程序员?ChatGPT和程序员的工作内容和工作方式ChatGPT和程序员的共同点程序员的优势程序员的实力ChatGPT和程序员的关系结论惊喜ChatGPT能否取代程序员? ChatGPT是一种非常普遍的人工智能(AI)系统,…...

案例分享 | 金融微服务场景下如何提升运维可观测性
云原生环境下金融业务的微服务化改造以及分布式架构的部署,使得业务与开发部门的关联更为紧密,传统运维监控已满足不了业务运营需求,亟需建设具备可观测性的运维体系。所以这次我们以某金融客户的实践案例为例,跟大家说一说在金…...
)
CentOS8提高篇3:Centos8安装播放器(mplayer vlc)
1. 准备工作(需要配置epel, rpmfusion源); 配置epel源 下载epel dnf install epel-release 配置rpmfusion源 下载rpmforge dnf install rpmfusion-free-release-8.noarch.rpm 2. 安装mplayer和vlc 直接dnf安装 # dnf install mplayer # dnf install v…...

MySQL-存储过程
什么是存储过程我们前面所学习的MySQL语句都是针对一个表或几个表的单条 SQL 语句,但是在数据库的实际操作中,并非所有操作都那么简单,经常会有一个完整的操作需要多条SQL语句处理多个表才能完成。例如,为了确认学生能否毕业&…...
经典七大比较排序算法 · 下 + 附计数和基数排序
经典七大比较排序算法 下 附计数和基数排序1 插入排序1.1 算法思想1.2 代码实现1.3 插入排序特性2 希尔排序2.1 算法思想2.2 代码实现2.3 希尔排序特性3 七大比较排序特性总结4 计数排序4.1 算法思想4.2 代码实现4.3 计数排序特性5 基数排序5.1 算法思想5.2 代码实现1 插入排…...
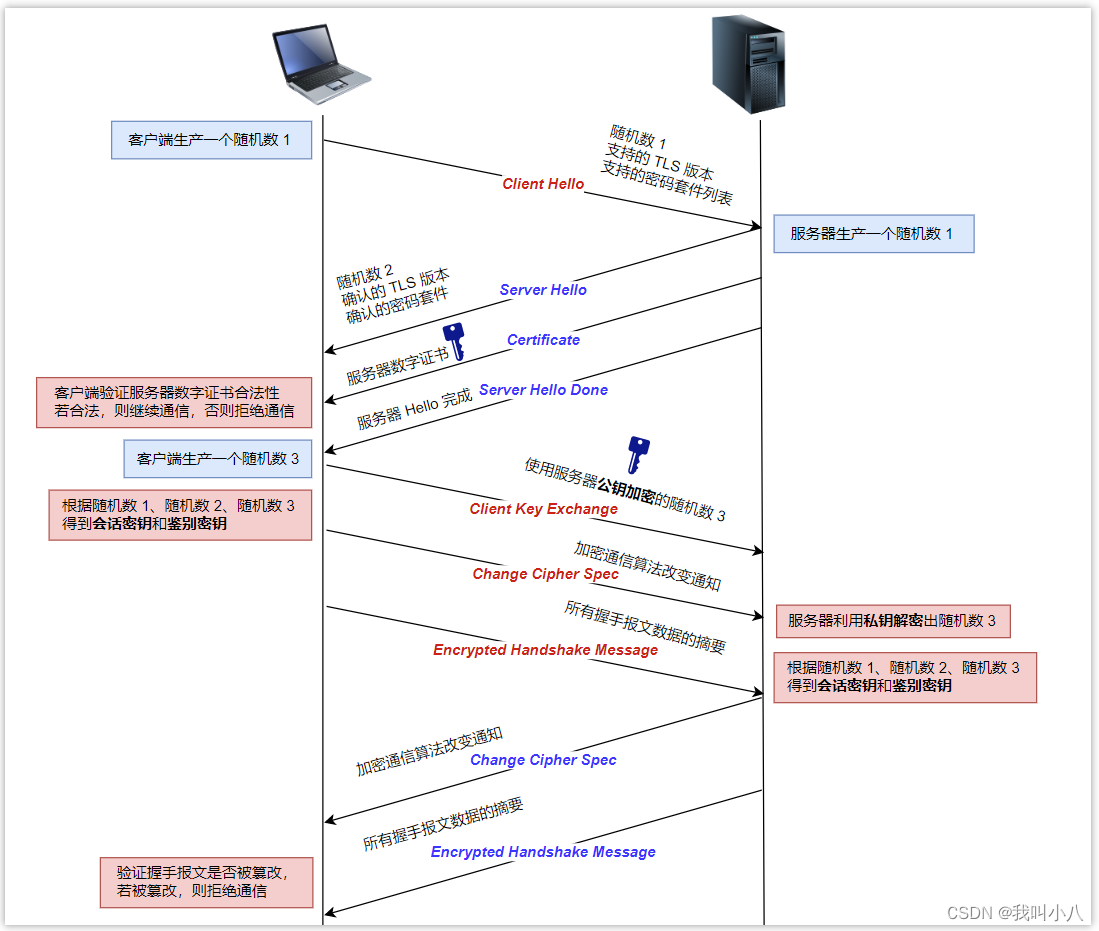
HTTPS协议,看这篇就够了
不安全的HTTP 近些年来,越来越多的网站使用 HTTPS 协议进行数据传输,原因在于 HTTPS 相较于 HTTP 能够提供更加安全的服务。 很多浏览器对于使用 HTTP 协议的网站会加上『警告』的标志表示数据传输不安全,而对于使用 HTTPS 协议的网站会加上…...

C语言学习之路--结构体篇
目录一、前言二、结构体的声明1、结构的基础知识2、结构的声明3、结构体成员的类型4、结构体变量的定义和初始化三、结构体成员的访问四、结构体传参一、前言 本人是一名小白,这一篇是记录我C语言学习中的结构体的所学所得,仅为简单的认识下C语言中的各…...
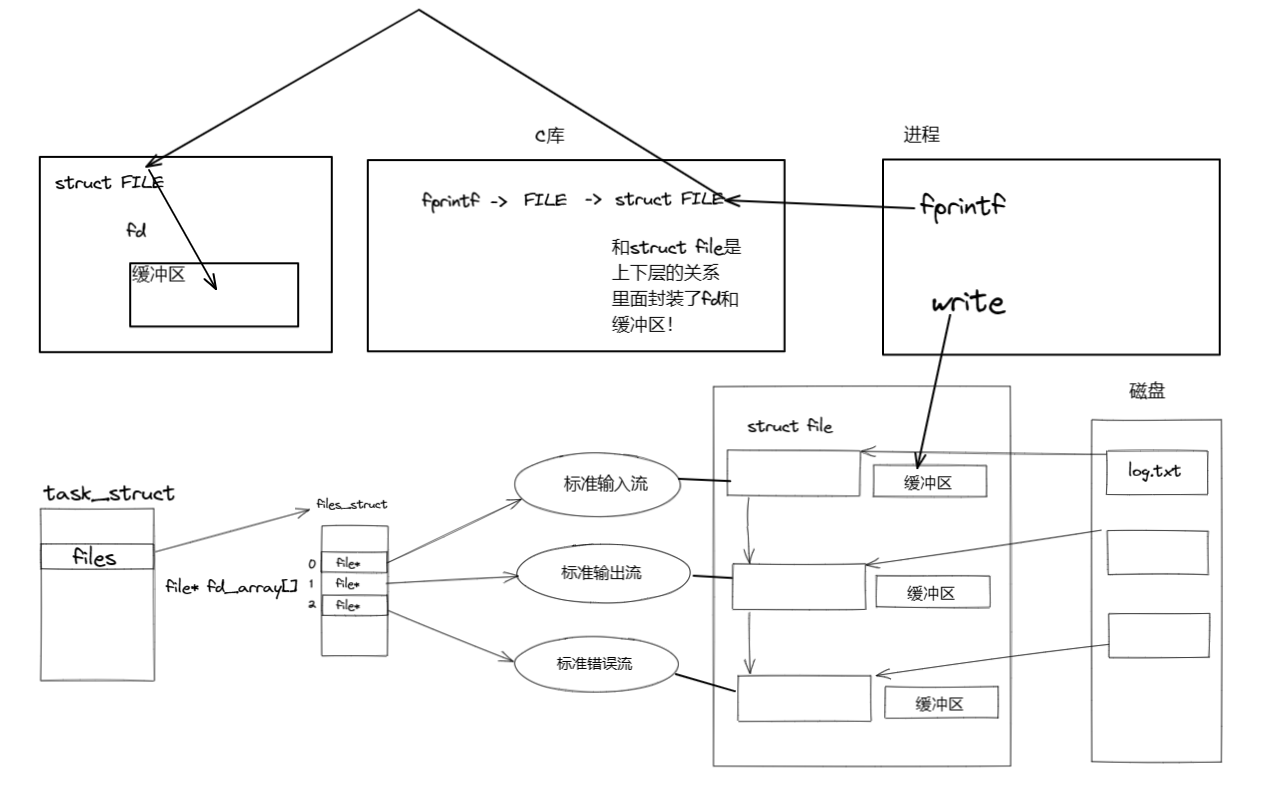
【LINUX】初识文件系统
文章目录一、前言二、回顾C语言文件操作三、初识系统调用openreadwriteclose四、文件系统初识五、结语一、前言 二、回顾C语言文件操作 int main() {FILE* fp fopen("log.txt", "w");if (fp NULL){perror("fopen");}int cnt 0;fputs("…...

金三银四Java面试题及答案整理(2023最新版) 持续更新
作为一名优秀的程序员,技术面试是不可避免的一个环节,一般技术面试官都会通过自己的方式去考察程序员的技术功底与基础理论知识。 如果你参加过一些大厂面试,肯定会遇到一些这样的问题: 1、看你项目都用的框架,熟悉 …...

7个角度,用 ChatGPT 玩转机器学习
大家好,我是机器学习科普创作者章北海mlpy,探索更高效的学习方法是我一直等追求。现在的初学者太幸福了,可以利用ChatGPT来帮助你学习机器学习的各个方面。 比如【个人首测】百度文心一言 VS GPT-4这篇文章中,我就用文心一言、GP…...
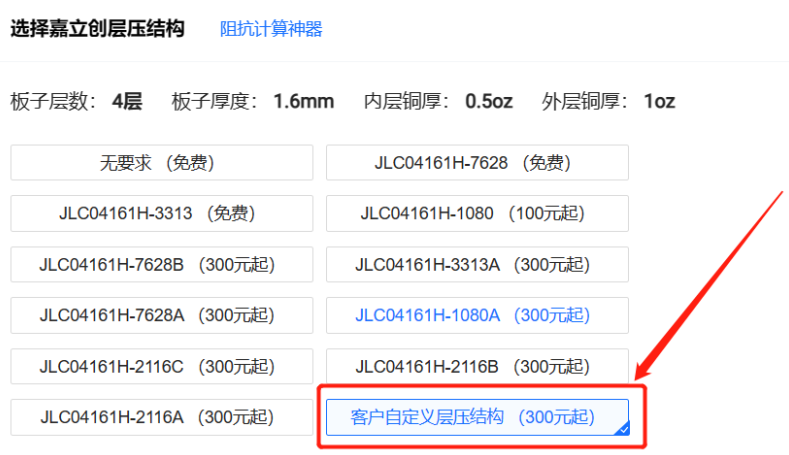
关于多层板,你了解多少?
01 前言 大家好,我是张巧龙。好久没写原创了,记得之前刚接触PCB时,还在用腐蚀单层板,类似这种。 慢慢随着电子产品功能越来越多,产品越来越薄,对PCB设计要求越来越高了,复杂程度也随之增加。因此…...

使用sqlalchemy-gbasedbt连接GBase 8s数据库
测试环境: 操作系统:CentOS 7.9 64-bit数据库版本:GBase8sV8.8_AEE_3.0.0_1,对应的CSDK版本为3.0.0_1 1,确认安装python3 确认已经安装python3和python3-devel [rootlocalhost test]# python3 -V Python 3.6.8如果…...

前端如何丢掉你的饭碗?
对于后端而言,我们常有“删库跑路”的说法,这说明后端的操作对于信息系统而言通常影响很大,可以轻易使信息系统宕机、崩溃,直接导致项目失败。所以,不要去逼后端程序员! 作为前端程序员,我们似…...
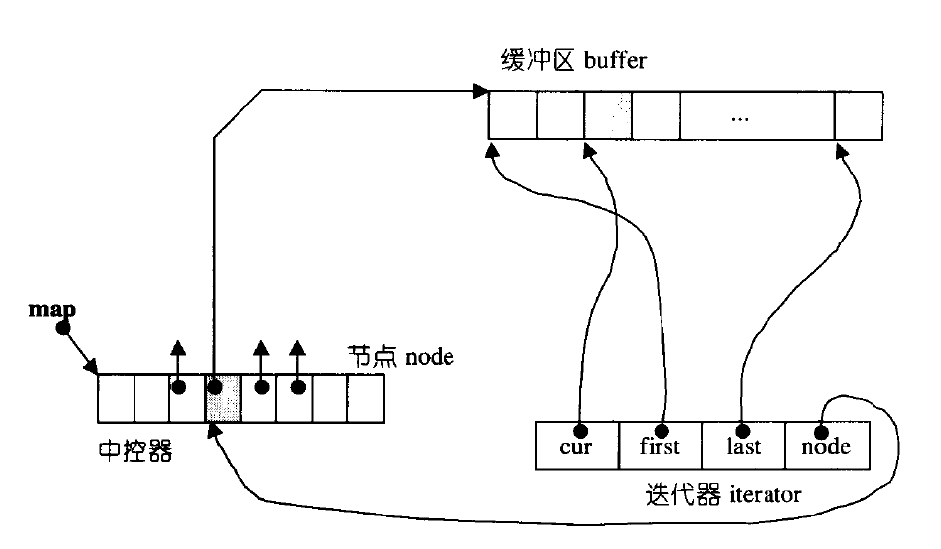
栈、队列、优先级队列的模拟实现
优先级队列的模拟实现栈stack的模拟实现push()pop()top()size()empty()swap()stack总代码队列queue的模拟实现push()pop()front()back()empty()size()swap()queue总代码优先级队列(堆)push()pop()top()empty()size()swap()priority_queue总代码deque的了解栈 在CSTL中栈并不属…...
如何重塑认知研究边界)
从实验室到生活场景:近红外脑成像(fNIRS)如何重塑认知研究边界
1. 从实验室到客厅:fNIRS如何打破认知研究的围墙 十年前我第一次接触近红外脑成像设备时,它还是个需要固定在三脚架上的"庞然大物",被试必须像雕塑般保持静止。如今看着学生戴着LUMO设备在操场自由活动时采集数据,这种技…...

Git【多人协作一】
目前,基本上可以完成的工作如下:基本完成Git的所有本地库的相关操作,git 基本操作,分支理解,版本回退,冲突解决等等申请码云账号,将远端信息clone到本地,以及推送和力量去。但是&…...

ER-Save-Editor:开源工具实现艾尔登法环跨平台存档修改全指南
ER-Save-Editor:开源工具实现艾尔登法环跨平台存档修改全指南 【免费下载链接】ER-Save-Editor Elden Ring Save Editor. Compatible with PC and Playstation saves. 项目地址: https://gitcode.com/GitHub_Trending/er/ER-Save-Editor ER-Save-Editor作为一…...

如何用anyRTC-RTMP-OpenSource打造个性化直播数据源:自定义视频采集完整指南
如何用anyRTC-RTMP-OpenSource打造个性化直播数据源:自定义视频采集完整指南 【免费下载链接】anyRTC-RTMP-OpenSource RTMP 推流器,RTMP(HLS)秒开播放器,直播点播,跨平台(Win,IOS,Android)开源代码 项目…...

单片机:从核心原理到智能应用实战
1. 单片机:智能时代的微型大脑 想象一下清晨醒来,窗帘自动拉开,咖啡机开始工作,室内温度始终保持在最舒适的状态——这些看似简单的智能场景背后,都藏着一个不起眼却至关重要的核心部件:单片机。这块比硬币…...

小白友好!Stable Diffusion v1.5单卡运行多个服务,详细步骤+避坑指南
小白友好!Stable Diffusion v1.5单卡运行多个服务,详细步骤避坑指南 1. 为什么需要单卡多服务? 很多刚接触Stable Diffusion的朋友都会遇到这样的困扰:团队里几个人共用一台服务器,但GPU卡只有一张。一个人用的时候还…...

BACnet4j实战:从模拟设备到点位数据采集的完整流程解析
1. BACnet4j与工业物联网数据采集入门 第一次接触BACnet协议时,我被各种专业术语搞得晕头转向。直到用BACnet4j成功读取到第一个温度传感器的数据,才真正理解这个协议的价值。BACnet/IP就像工业设备间的普通话,而BACnet4j就是让Java程序能说这…...

【GIS】深入解析地理学中的尺度三重性:Size、Level、Relation的实践应用
1. 尺度三重性:GIS分析的基石 第一次接触"尺度"概念时,我也被各种术语绕晕过——为什么1:10000叫大比例尺却显示小范围?为什么生态学家说的"尺度"和城市规划师说的完全不是一回事?直到把尺度拆解成Size&#…...

AI推动SEO关键词优化的全新策略与实践明晰
在当前数字营销环境中,AI技术为SEO关键词优化带来了前所未有的变革。它通过自动化的数据分析与挖掘工具,能够帮助企业更准确地识别用户需求与搜索趋势。通过AI的支持,关键词挖掘变得更加高效和精准,企业可以快速获取相关关键词并优…...

新手福音:用快马AI生成带详解注释的Arduino交通灯实验代码
作为一个刚接触单片机的新手,第一次看到Arduino开发板时既兴奋又迷茫。那些闪烁的LED灯和蜂鸣器背后到底藏着什么秘密?今天我就用InsCode(快马)平台来探索一个有趣的交通灯模拟项目,整个过程比想象中简单多了。 项目构思 我想做一个能模拟真实…...