Java怎么实现几十万条数据插入(30万条数据插入MySQL仅需13秒)
本文主要讲述通过MyBatis、JDBC等做大数据量数据插入的案例和结果。
30万条数据插入插入数据库验证
- 实体类、mapper和配置文件定义
- User实体
- mapper接口
- mapper.xml文件
- jdbc.properties
- sqlMapConfig.xml
- 不分批次直接梭哈
- 循环逐条插入
- MyBatis实现插入30万条数据
- JDBC实现插入30万条数据
- 总结
验证的数据库表结构如下:
CREATE TABLE `t_user` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户id',`username` varchar(64) DEFAULT NULL COMMENT '用户名称',`age` int(4) DEFAULT NULL COMMENT '年龄',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户信息表';
话不多说,开整!
实体类、mapper和配置文件定义
User实体
/*** <p>用户实体</p>** @Author zjq* @Date 2021/8/3*/
@Data
public class User {private int id;private String username;private int age;}
mapper接口
public interface UserMapper {/*** 批量插入用户* @param userList*/void batchInsertUser(@Param("list") List<User> userList);}
mapper.xml文件
<!-- 批量插入用户信息 --><insert id="batchInsertUser" parameterType="java.util.List">insert into t_user(username,age) values<foreach collection="list" item="item" index="index" separator=",">(#{item.username},#{item.age})</foreach></insert>
jdbc.properties
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/test
jdbc.username=root
jdbc.password=root
sqlMapConfig.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><!--通过properties标签加载外部properties文件--><properties resource="jdbc.properties"></properties><!--自定义别名--><typeAliases><typeAlias type="com.zjq.domain.User" alias="user"></typeAlias></typeAliases><!--数据源环境--><environments default="developement"><environment id="developement"><transactionManager type="JDBC"></transactionManager><dataSource type="POOLED"><property name="driver" value="${jdbc.driver}"/><property name="url" value="${jdbc.url}"/><property name="username" value="${jdbc.username}"/><property name="password" value="${jdbc.password}"/></dataSource></environment></environments><!--加载映射文件--><mappers><mapper resource="com/zjq/mapper/UserMapper.xml"></mapper></mappers></configuration>不分批次直接梭哈
MyBatis直接一次性批量插入30万条,代码如下:
@Testpublic void testBatchInsertUser() throws IOException {InputStream resourceAsStream =Resources.getResourceAsStream("sqlMapConfig.xml");SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);SqlSession session = sqlSessionFactory.openSession();System.out.println("===== 开始插入数据 =====");long startTime = System.currentTimeMillis();try {List<User> userList = new ArrayList<>();for (int i = 1; i <= 300000; i++) {User user = new User();user.setId(i);user.setUsername("共饮一杯无 " + i);user.setAge((int) (Math.random() * 100));userList.add(user);}session.insert("batchInsertUser", userList); // 最后插入剩余的数据session.commit();long spendTime = System.currentTimeMillis()-startTime;System.out.println("成功插入 30 万条数据,耗时:"+spendTime+"毫秒");} finally {session.close();}}
可以看到控制台输出:
Cause: com.mysql.jdbc.PacketTooBigException: Packet for query is too large (27759038 >yun 4194304). You can change this value on the server by setting the max_allowed_packet’ variable.
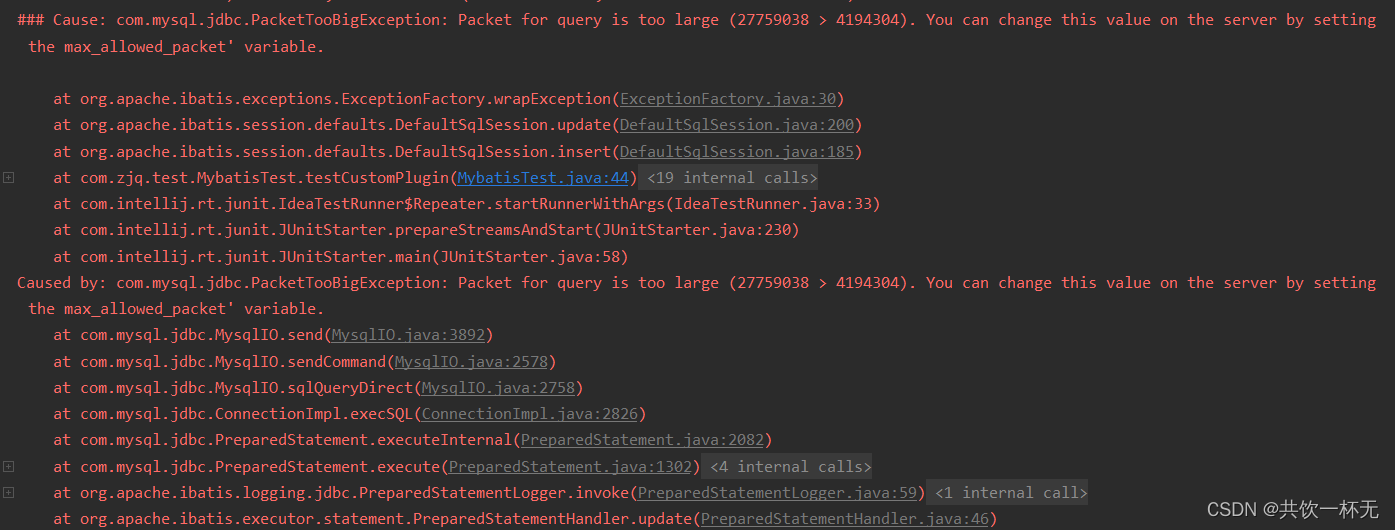
超出最大数据包限制了,可以通过调整max_allowed_packet限制来提高可以传输的内容,不过由于30万条数据超出太多,这个不可取,梭哈看来是不行了 😅😅😅
既然梭哈不行那我们就一条一条循环着插入行不行呢
循环逐条插入
mapper接口和mapper文件中新增单个用户新增的内容如下:
/*** 新增单个用户* @param user*/void insertUser(User user);
<!-- 新增用户信息 --><insert id="insertUser" parameterType="user">insert into t_user(username,age) values(#{username},#{age})</insert>
调整执行代码如下:
@Testpublic void testCirculateInsertUser() throws IOException {InputStream resourceAsStream =Resources.getResourceAsStream("sqlMapConfig.xml");SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);SqlSession session = sqlSessionFactory.openSession();System.out.println("===== 开始插入数据 =====");long startTime = System.currentTimeMillis();try {for (int i = 1; i <= 300000; i++) {User user = new User();user.setId(i);user.setUsername("共饮一杯无 " + i);user.setAge((int) (Math.random() * 100));// 一条一条新增session.insert("insertUser", user);session.commit();}long spendTime = System.currentTimeMillis()-startTime;System.out.println("成功插入 30 万条数据,耗时:"+spendTime+"毫秒");} finally {session.close();}}
执行后可以发现磁盘IO占比飙升,一直处于高位。
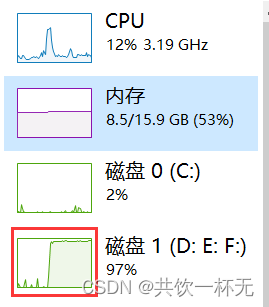
等啊等等啊等,好久还没执行完

先不管他了太慢了先搞其他的,等会再来看看结果吧。
two thousand year later …
控制台输出如下:
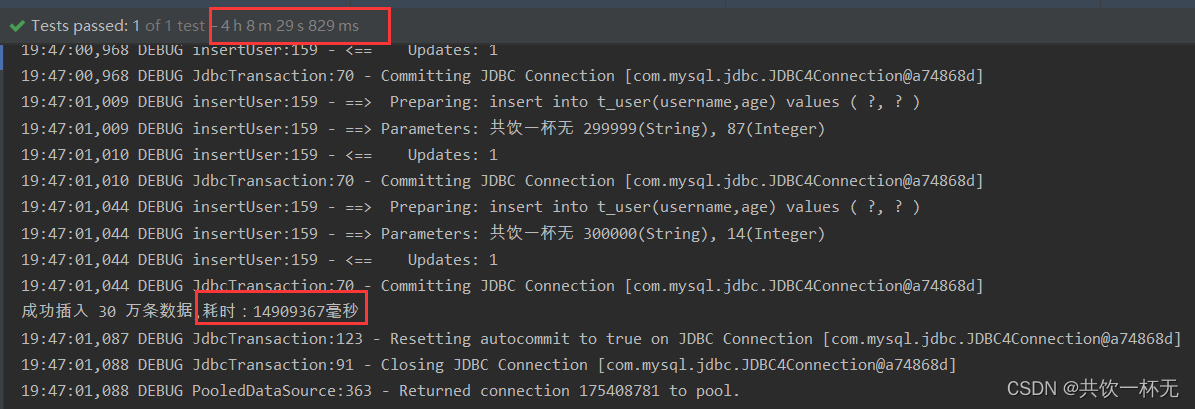
总共执行了14909367毫秒,换算出来是4小时八分钟。太慢了。。

👇👇👇还是优化下之前的批处理方案吧
MyBatis实现插入30万条数据
先清理表数据,然后优化批处理执行插入:
-- 清空用户表
TRUNCATE table t_user;
以下是通过 MyBatis 实现 30 万条数据插入代码实现:
/*** 分批次批量插入* @throws IOException*/@Testpublic void testBatchInsertUser() throws IOException {InputStream resourceAsStream =Resources.getResourceAsStream("sqlMapConfig.xml");SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);SqlSession session = sqlSessionFactory.openSession();System.out.println("===== 开始插入数据 =====");long startTime = System.currentTimeMillis();int waitTime = 10;try {List<User> userList = new ArrayList<>();for (int i = 1; i <= 300000; i++) {User user = new User();user.setId(i);user.setUsername("共饮一杯无 " + i);user.setAge((int) (Math.random() * 100));userList.add(user);if (i % 1000 == 0) {session.insert("batchInsertUser", userList);// 每 1000 条数据提交一次事务session.commit();userList.clear();// 等待一段时间Thread.sleep(waitTime * 1000);}}// 最后插入剩余的数据if(!CollectionUtils.isEmpty(userList)) {session.insert("batchInsertUser", userList);session.commit();}long spendTime = System.currentTimeMillis()-startTime;System.out.println("成功插入 30 万条数据,耗时:"+spendTime+"毫秒");} catch (Exception e) {e.printStackTrace();} finally {session.close();}}
使用了 MyBatis 的批处理操作,将每 1000 条数据放在一个批次中插入,能够较为有效地提高插入速度。同时请注意在循环插入时要带有合适的等待时间和批处理大小,以防止出现内存占用过高等问题。此外,还需要在配置文件中设置合理的连接池和数据库的参数,以获得更好的性能。
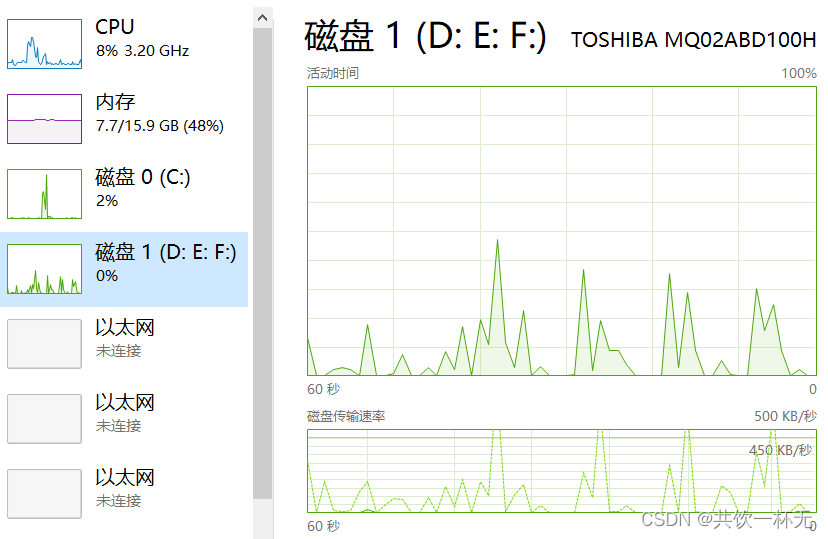
在上面的示例中,我们每插入1000行数据就进行一次批处理提交,并等待10秒钟。这有助于控制内存占用,并确保插入操作平稳进行。

五十分钟执行完毕,时间主要用在了等待上。
如果低谷时期执行,CPU和磁盘性能又足够的情况下,直接批处理不等待执行:
/*** 分批次批量插入* @throws IOException*/@Testpublic void testBatchInsertUser() throws IOException {InputStream resourceAsStream =Resources.getResourceAsStream("sqlMapConfig.xml");SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);SqlSession session = sqlSessionFactory.openSession();System.out.println("===== 开始插入数据 =====");long startTime = System.currentTimeMillis();int waitTime = 10;try {List<User> userList = new ArrayList<>();for (int i = 1; i <= 300000; i++) {User user = new User();user.setId(i);user.setUsername("共饮一杯无 " + i);user.setAge((int) (Math.random() * 100));userList.add(user);if (i % 1000 == 0) {session.insert("batchInsertUser", userList);// 每 1000 条数据提交一次事务session.commit();userList.clear();}}// 最后插入剩余的数据if(!CollectionUtils.isEmpty(userList)) {session.insert("batchInsertUser", userList);session.commit();}long spendTime = System.currentTimeMillis()-startTime;System.out.println("成功插入 30 万条数据,耗时:"+spendTime+"毫秒");} catch (Exception e) {e.printStackTrace();} finally {session.close();}}
则24秒可以完成数据插入操作:
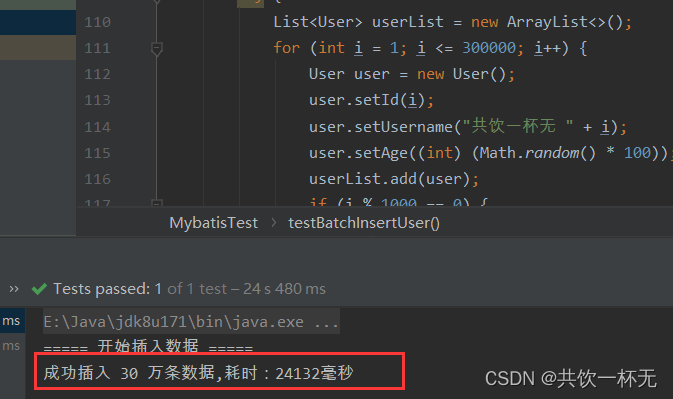

可以看到短时CPU和磁盘占用会飙高。
把批处理的量再调大一些调到5000,在执行:
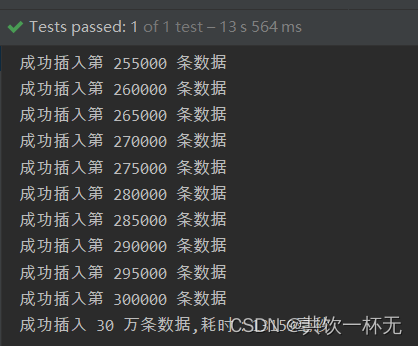
13秒插入成功30万条,直接芜湖起飞🛫🛫🛫
JDBC实现插入30万条数据
JDBC循环插入的话跟上面的mybatis逐条插入类似,不再赘述。
以下是 Java 使用 JDBC 批处理实现 30 万条数据插入的示例代码。请注意,该代码仅提供思路,具体实现需根据实际情况进行修改。
/*** JDBC分批次批量插入* @throws IOException*/@Testpublic void testJDBCBatchInsertUser() throws IOException {Connection connection = null;PreparedStatement preparedStatement = null;String databaseURL = "jdbc:mysql://localhost:3306/test";String user = "root";String password = "root";try {connection = DriverManager.getConnection(databaseURL, user, password);// 关闭自动提交事务,改为手动提交connection.setAutoCommit(false);System.out.println("===== 开始插入数据 =====");long startTime = System.currentTimeMillis();String sqlInsert = "INSERT INTO t_user ( username, age) VALUES ( ?, ?)";preparedStatement = connection.prepareStatement(sqlInsert);Random random = new Random();for (int i = 1; i <= 300000; i++) {preparedStatement.setString(1, "共饮一杯无 " + i);preparedStatement.setInt(2, random.nextInt(100));// 添加到批处理中preparedStatement.addBatch();if (i % 1000 == 0) {// 每1000条数据提交一次preparedStatement.executeBatch();connection.commit();System.out.println("成功插入第 "+ i+" 条数据");}}// 处理剩余的数据preparedStatement.executeBatch();connection.commit();long spendTime = System.currentTimeMillis()-startTime;System.out.println("成功插入 30 万条数据,耗时:"+spendTime+"毫秒");} catch (SQLException e) {System.out.println("Error: " + e.getMessage());} finally {if (preparedStatement != null) {try {preparedStatement.close();} catch (SQLException e) {e.printStackTrace();}}if (connection != null) {try {connection.close();} catch (SQLException e) {e.printStackTrace();}}}}

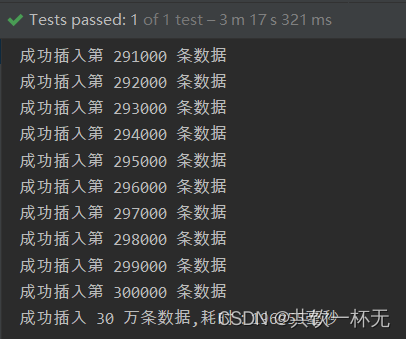
上述示例代码中,我们通过 JDBC 连接 MySQL 数据库,并执行批处理操作插入数据。具体实现步骤如下:
- 获取数据库连接。
- 创建 Statement 对象。
- 定义 SQL 语句,使用 PreparedStatement 对象预编译 SQL 语句并设置参数。
- 执行批处理操作。
- 处理剩余的数据。
- 关闭 Statement 和 Connection 对象。
使用setAutoCommit(false) 来禁止自动提交事务,然后在每次批量插入之后手动提交事务。每次插入数据时都新建一个 PreparedStatement 对象以避免状态不一致问题。在插入数据的循环中,每 10000 条数据就执行一次 executeBatch() 插入数据。
另外,需要根据实际情况优化连接池和数据库的相关配置,以防止连接超时等问题。
总结
实现高效的大量数据插入需要结合以下优化策略(建议综合使用):
批处理:批量提交SQL语句可以降低网络传输和处理开销,减少与数据库交互的次数。在Java中可以使用Statement或者PreparedStatement的addBatch()方法来添加多个SQL语句,然后一次性执行executeBatch()方法提交批处理的SQL语句。
- 在循环插入时带有
适当的等待时间和批处理大小,从而避免内存占用过高等问题:- 设置适当的批处理大小:批处理大小指在一次插入操作中插入多少行数据。如果批处理大小太小,插入操作的频率将很高,而如果批处理大小太大,可能会导致内存占用过高。通常,建议将批处理大小设置为1000-5000行,这将减少插入操作的频率并降低内存占用。
- 采用适当的等待时间:等待时间指在批处理操作之间等待的时间量。等待时间过短可能会导致内存占用过高,而等待时间过长则可能会延迟插入操作的速度。通常,建议将等待时间设置为几秒钟到几十秒钟之间,这将使操作变得平滑且避免出现内存占用过高等问题。
- 可以考虑使用一些内存优化的技巧,例如使用内存数据库或使用游标方式插入数据,以减少内存占用。
- 总的来说,选择适当的批处理大小和等待时间可以帮助您平稳地进行插入操作,避免出现内存占用过高等问题。
索引: 在大量数据插入前暂时去掉索引,最后再打上,这样可以大大减少写入时候的更新索引的时间。数据库连接池:使用数据库连接池可以减少数据库连接建立和关闭的开销,提高性能。在没有使用数据库连接池的情况,记得在finally中关闭相关连接。数据库参数调整:增加MySQL数据库缓冲区大小、配置高性能的磁盘和I/O等。
本文内容到此结束了,
如有收获欢迎点赞👍收藏💖关注✔️,您的鼓励是我最大的动力。
如有错误❌疑问💬欢迎各位指出。
主页:共饮一杯无的博客汇总👨💻保持热爱,奔赴下一场山海。🏃🏃🏃
相关文章:
Java怎么实现几十万条数据插入(30万条数据插入MySQL仅需13秒)
本文主要讲述通过MyBatis、JDBC等做大数据量数据插入的案例和结果。 30万条数据插入插入数据库验证实体类、mapper和配置文件定义User实体mapper接口mapper.xml文件jdbc.propertiessqlMapConfig.xml不分批次直接梭哈循环逐条插入MyBatis实现插入30万条数据JDBC实现插入30万条数…...
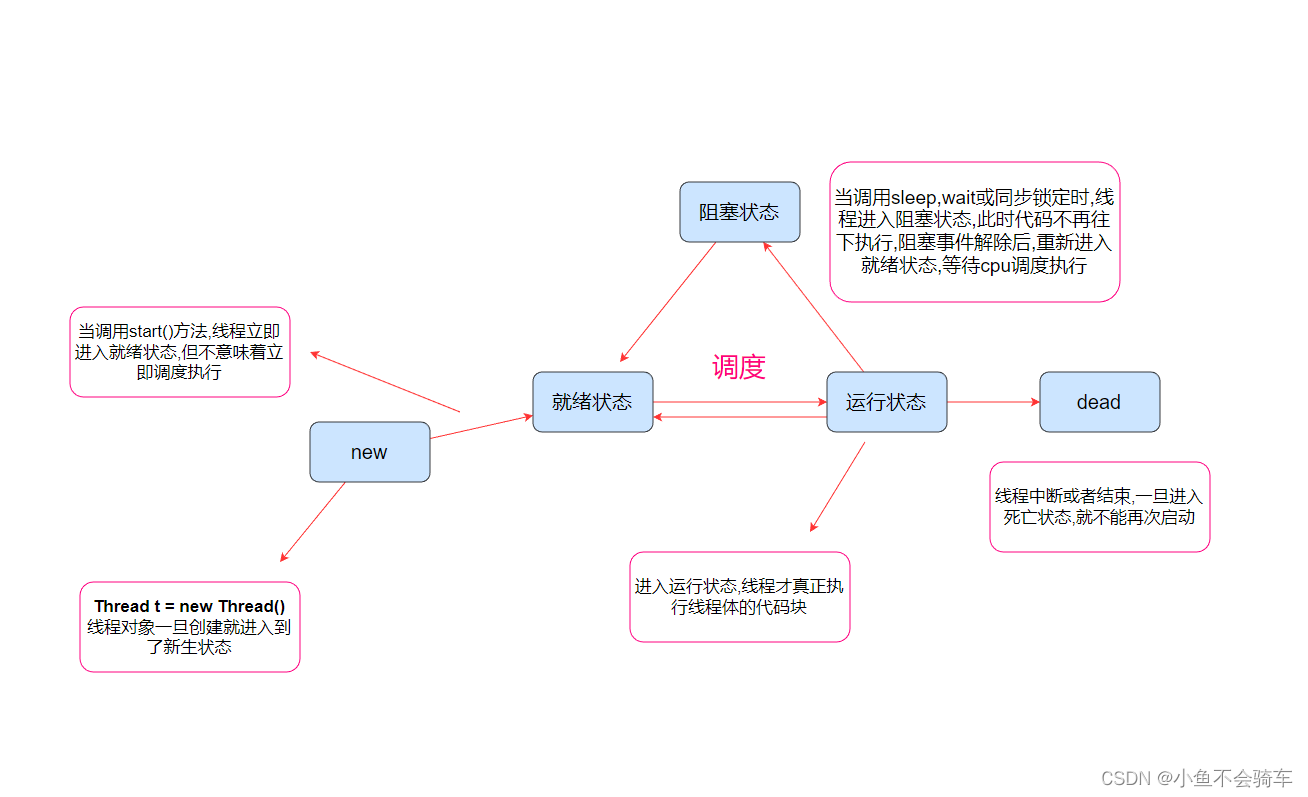
java多线程之线程的六种状态
线程的六种状态(1) NEW(初始状态)(2) TERMINATED(终止状态 / 死亡状态)(3) RUNNABLE(运行时状态)(4) TIMED_WAITING(超时等待状态)(5) WAITING(等待状态)(6) BLOCK(阻塞状态)sleep和wait的区别:操作系统里的线程自身是有一个状态的,但是java Thread 是对系统线程的封装,把这里的…...
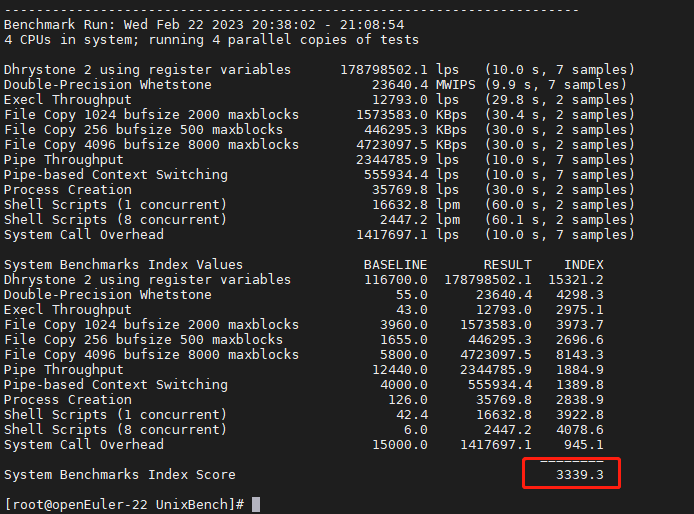
UnixBench----x86架构openEuler操作系统上进行性能测试
【原文链接】UnixBench----x86架构openEuler操作系统上进行性能测试 (1)打开github上 UnixBench 地址,找到发布的tag (2)找到tar.gz包,右键复制链接 比如这里是 https://github.com/kdlucas/byte-unix…...
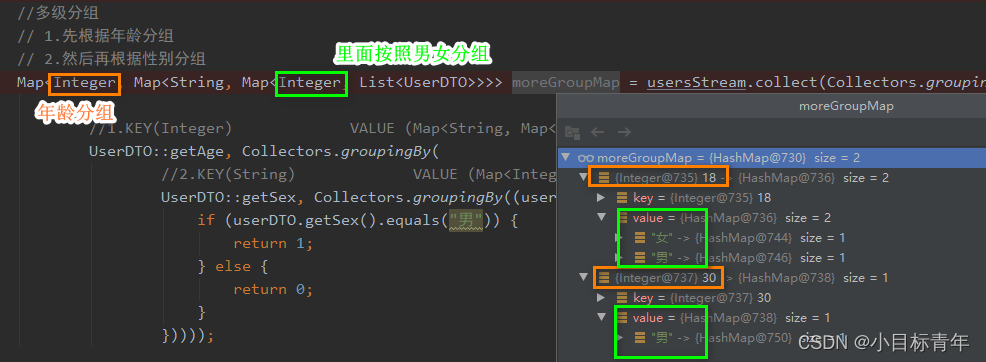
于Java8 Stream教程之collect()
目录 前言正文第一个小玩法 将集合通过Stream.collect() 转换成其他集合/数组:第二个小玩法 聚合(求和、最小、最大、平均值、分组)总结前言 本身我是一个比较偏向少使用Stream的人,因为调试比较不方便。 但是, 不得不说&#…...

Python
1、str 三个关键点: 正着数,0,1,2 反着数,0,-1,-2 str[a,b] 左闭右开 [a,b) str123456789 print(str) # 输出字符串 print(str[0:-1]) # 输…...
Spring框架中IOC和DI详解
Spring框架学习一—IOC和DI 来源黑马Spring课程,觉得挺好的 目录 文章目录Spring框架学习一---IOC和DI目录学习目标第一章 Spring概述1、为什么要学习spring?2、Spring概述【了解】【1】Spring是什么【2】Spring发展历程【3】Spring优势【4】Spring体系…...
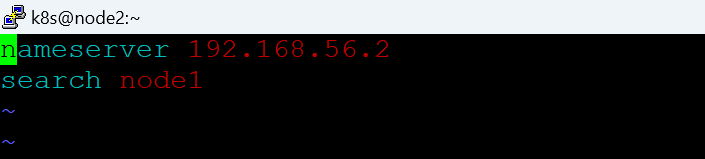
本地快速搭建Kubernetes单机版实验环境(含问题解决方案)
Kubernetes是一个容器编排系统,用于自动化应用程序部署、扩展和管理。本指南将介绍Kubernetes的基础知识,包括基本概念、安装部署和基础用法。 一、什么是Kubernetes? Kubernetes是Google开发的开源项目,是一个容器编排系统&…...
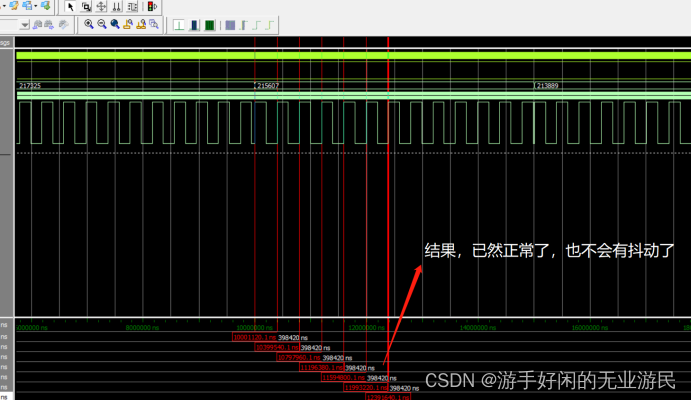
FPGA控制DDS产生1CLK周期误差的分析(二)
前文简短的介绍了DDS的产生原理,其实相当的简单,所以也不需要多做解释,本文详细阐述一下在调试DDS的过程中所产生的一个bug 问题发现 正如上文所述,再用FPGA控制存储在rom中的波形信号输出之后,在上板之前࿰…...

这一次,吃了Redis的亏,也败给了GPT
关注【离心计划】,一起离开地球表面 背景 组内有一个系统中有一个延迟任务的需求,关于延迟任务常见的做法有时间轮、延迟MQ还有Redis Zset等方案,关于时间轮,这边小苏有一个大学时候做的demo: https://github.com/JA…...

第一章 信息化知识
1、信息是客观事物状态和运动特征的一种普遍形式,信息的概念存在两个基本的层次,即本体论层次和认识论层次: 本体论层次:就是事物的运动状态和状态变化方式的自我表述认识论层次:就是主体对于该事物的运动状态以及状态…...
如何用matlab工具箱训练一个SOM神经网络
本站原创文章,转载请说明来自《老饼讲解-BP神经网络》bp.bbbdata.com本文展示如何用matlab工具箱训练一个SOM神经网络的DEMO并讲解其中的代码含义和相关使用说明- 01.SOM神经网络DEMO代码 -- 本文说明 -下面,我们先随机初始化一些样本点,然后…...

音视频技术开发周刊 | 285
每周一期,纵览音视频技术领域的干货。新闻投稿:contributelivevideostack.com。GPT-4 Office全家桶发布谷歌前脚刚宣布AI工具整合进Workspace,微软后脚就急匆匆召开了发布会,人狠话不多地祭出了办公软件王炸——Microsoft 365 Cop…...

安装flume
flume最主要的作用就是实时读取服务器本地磁盘的数据,将数据写入到hdfs中架构:开始安装一,上传压缩包,解压并更名解压:[rootsiwen install]# tar -zxf apache-flume-1.9.0-bin.tar.gz -C ../soft/[rootsiwen install]#…...

为工作排好优先级
工作,是干不完的,因此我们需要分清轻重缓急,为它们划分优先级,这样才不至于让自己手忙脚乱。 给手头的事情排上正确的优先级,是一项很重要的工作能力。 优先级有很多考量,并不是简单的先来后到的线性时间…...
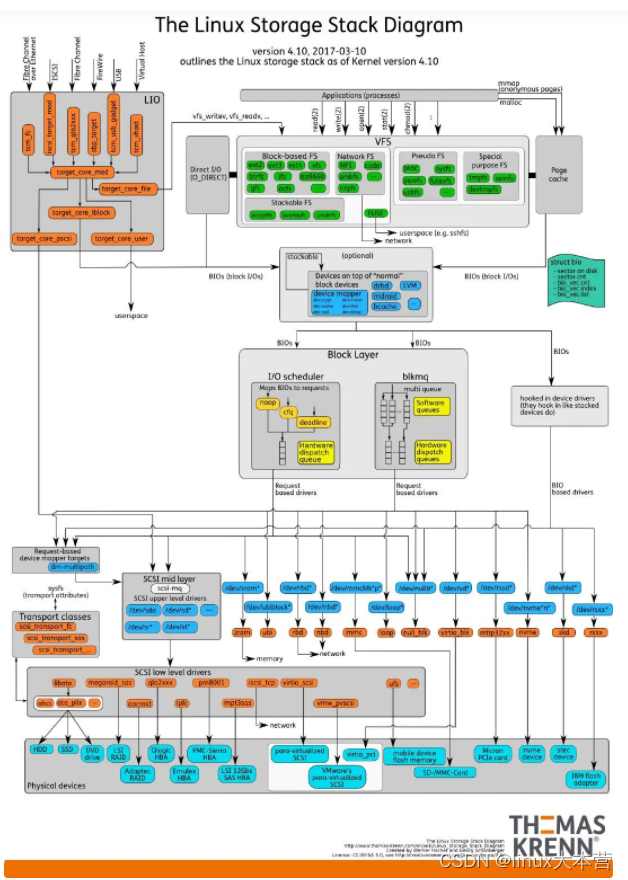
超专业解析!10分钟带你搞懂Linux中直接I/O原理
我们先看一张图: 这张图大体上描述了 Linux 系统上,应用程序对磁盘上的文件进行读写时,从上到下经历了哪些事情。 这篇文章就以这张图为基础,介绍 Linux 在 I/O 上做了哪些事情。 文件系统 什么是文件系统 文件系统࿰…...

【C++】面试101,用两个栈实现队列,包含min函数的栈,有效括号序列,滑动窗口的最大值,最小的K个数,倒置字符串,排序子序列,跳跃,数字三角形,蓝肽子序列
目录 1. 用两个栈实现队列 2.包含min函数的栈 3.有效括号序列 4.滑动窗口的最大值 5.最小的K个数 6.倒置字符串 7.排序子序列 8.数字三角形(蓝桥杯,学习一个大佬的博客....) 9.跳跃(蓝桥杯) 10.蓝肽子序列 1. 用…...

WPF 认识WPF
什么是WPF?WPF是Windows Presentation Foundation(Windows展示基础)简称,顾名思义是专门编写表示层的技术。WPF绚丽界面如下:GUI发展及WPF历史?Windows系统平台上从事图形用户界面GUI(Graphic User Interface)已经经历了多次换代,…...

【建议收藏】PHP单例模式详解以及实际运用
PHP单例模式详解以及实际运用 什么是单例模式? 首先我们百度百科他怎么说? 单例模式,属于创建类型的一种常用的软件设计模式。通过单例模式的方法创建的类在当前进程中只有一个实例(根据需要,也有可能一个线程中属于单例,如&a…...

【十二天学java】day04-流程控制语句
第一章 流程控制语句 在一个程序执行的过程中,各条语句的执行顺序对程序的结果是有直接影响的。所以,我们必须清楚每条语句的执行流程。而且,很多时候要通过控制语句的执行顺序来实现我们想要的功能。 1.1 流程控制语句分类 顺序结构 判断…...
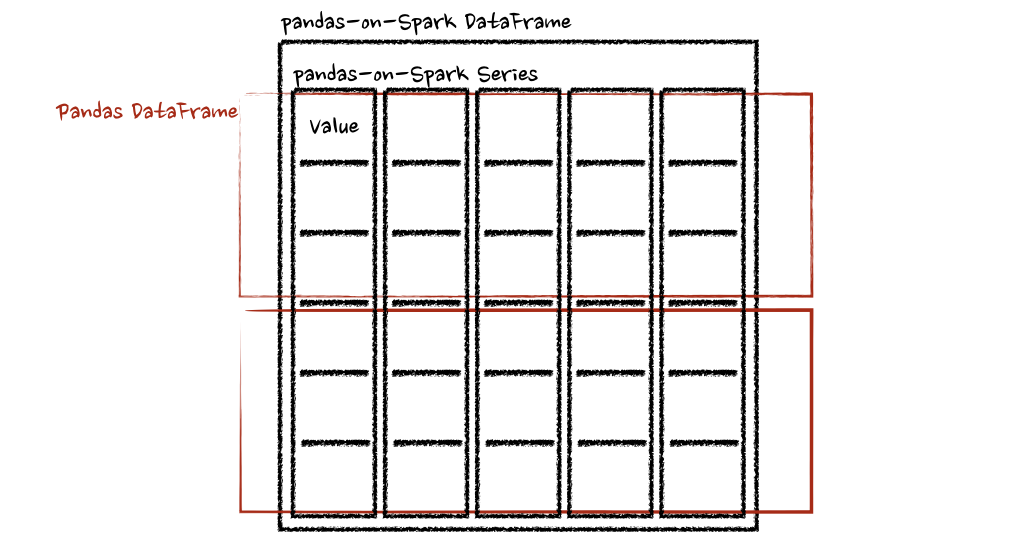
Pandas 与 PySpark 强强联手,功能与速度齐飞
Pandas做数据处理可以说是yyds!而它的缺点也是非常明显,Pandas 只能单机处理,它不能随数据量线性伸缩。例如,如果 pandas 试图读取的数据集大于一台机器的可用内存,则会因内存不足而失败。 另外 pandas 在处理大型数据…...

桌面高颜值时钟工具,支持置顶鼠标穿透
软件介绍 今天要说的这款工具叫WithClock,它是一个时钟工具。这款工具的设计特别简洁,看着很舒服,没什么多余的东西,颜值也挺高。 功能操作 它支持鼠标穿透,你只需要在时钟上点右键,选择“置顶”…...
)
AFL++实战:从零开始用WSL搭建模糊测试环境(附libxml2案例)
AFL实战指南:WSL环境下的模糊测试从入门到精通 模糊测试(Fuzz Testing)作为软件安全测试的重要手段,近年来在漏洞挖掘领域展现出惊人的效果。对于Windows平台开发者而言,Windows Subsystem for Linux(WSL&…...

从大疆NAZA换到匿名P2飞控:一个DIY玩家的真实体验与参数调试避坑指南
从大疆NAZA到匿名P2飞控:一位DIY玩家的深度迁移指南 当我的F450机架在狭小卧室里显得笨拙不堪时,我意识到需要一次彻底的"瘦身计划"。这不是简单的机架更换,而是一次从商业飞控到开源系统的完整迁移——将大疆NAZA积累的经验移植到…...

高效智能转换方案:B站缓存视频一键处理实战指南
高效智能转换方案:B站缓存视频一键处理实战指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在B站视频频繁下架的当下,…...

掌握TegraRcmGUI:从入门到精通的Switch注入实践指南
掌握TegraRcmGUI:从入门到精通的Switch注入实践指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是一款基于C开发的图形化界面工具…...

实战指南:基于快马平台,快速构建可部署的unet卫星图像分割系统
今天想和大家分享一个实战项目:基于UNet的卫星图像建筑物分割系统。这个项目特别适合在InsCode(快马)平台上快速搭建,因为它涉及从数据处理到模型部署的完整流程,而平台的一键部署功能正好能省去繁琐的环境配置工作。 项目背景与需求分析 卫星…...

3分钟搭建免费B站视频解析服务:零基础教程
3分钟搭建免费B站视频解析服务:零基础教程 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse 你是否曾经想要保存B站的精彩视频却不知道如何操作?或者需要在自己的网站上嵌入B站视…...

springboot+vue基于web的在线学习资源推荐的设计与实现
目录功能模块分析推荐系统功能交互功能设计后台管理功能技术实现要点项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作功能模块分析 用户管理模块 用户注册与登录:支持邮箱/手机号注册,提供密码找回功能…...

Step3-VL-10B内网穿透应用:安全远程模型调用方案
Step3-VL-10B内网穿透应用:安全远程模型调用方案 1. 场景需求与痛点分析 很多企业和机构在内部部署了强大的多模态AI模型,比如Step3-VL-10B这样的视觉语言模型,能够处理图像和文本的复杂任务。但这些模型通常运行在内网环境中,外…...

图图的嗨丝造相-Z-Image-Turbo效果对比:8bit vs 16bit精度推理对渔网袜边缘锐度的影响
图图的嗨丝造相-Z-Image-Turbo效果对比:8bit vs 16bit精度推理对渔网袜边缘锐度的影响 1. 引言:当AI绘画遇上“渔网袜”细节 最近在玩一个挺有意思的AI绘画模型——图图的嗨丝造相-Z-Image-Turbo。这个模型专门针对“大网渔网袜”这种特定服饰的生成做…...