Python爬虫技术 第27节 API和RESTful服务
Python 爬虫技术是一种自动化获取网页内容的方法,通常用于数据收集、信息抽取或自动化测试。在讲解 Python 爬虫技术时,我们通常会涉及到以下几个关键概念:
-
HTTP 请求:爬虫通过发送 HTTP 请求来获取网页内容,这是爬虫与服务器交互的基础。
-
API:API(Application Programming Interface)是应用程序编程接口,它允许不同的软件应用之间进行交互。API 通常定义了一组规则和协议,使得不同的系统能够通过 HTTP 请求和响应进行数据交换。
-
RESTful 服务:RESTful 是一种基于 HTTP 协议的网络服务架构风格,它使用标准的 HTTP 方法(如 GET、POST、PUT、DELETE 等)来操作网络上的资源。RESTful 服务通常易于使用和扩展,因为它们遵循统一的接口。
Python 爬虫技术详解
-
请求网页:使用 Python 的
requests库来发送 HTTP 请求,获取网页的 HTML 或 JSON 数据。import requests response = requests.get('http://example.com') -
解析内容:使用
BeautifulSoup或lxml等库来解析 HTML 或 XML 内容,提取所需的数据。from bs4 import BeautifulSoup soup = BeautifulSoup(response.text, 'html.parser') -
数据存储:将提取的数据存储到数据库或文件中,以便进一步分析或使用。
# 假设提取的数据是一个列表 data = [item.text for item in soup.find_all('li')] -
处理 API:如果目标网站提供了 API,可以通过 API 直接获取数据,这通常比直接爬取网页更高效、更稳定。
api_response = requests.get('http://api.example.com/data') -
遵守规则:在使用爬虫技术时,需要遵守目标网站的
robots.txt文件规定,尊重版权和隐私政策。 -
异常处理:编写代码时,需要考虑到网络请求可能失败的情况,并进行相应的异常处理。
try:response = requests.get('http://example.com')response.raise_for_status() # 检查请求是否成功 except requests.exceptions.HTTPError as err:print(f"HTTP error occurred: {err}") -
使用会话:对于需要多次请求同一服务器的情况,使用
requests.Session()可以提高效率。 -
模拟浏览器:有时网站可能需要用户代理(User-Agent)或其他浏览器特性,可以通过设置请求头来模拟浏览器行为。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' } response = requests.get('http://example.com', headers=headers) -
使用代理:在爬取过程中可能会遇到 IP 被封的情况,使用代理可以绕过这些限制。
-
异步请求:对于需要发送大量请求的情况,可以使用
aiohttp等异步库来提高效率。
RESTful 服务的使用
-
理解资源:RESTful 服务通常将数据表示为资源,每个资源都有一个唯一的标识符(URI)。
-
使用 HTTP 方法:根据需要执行的操作(如获取、创建、更新、删除)选择相应的 HTTP 方法。
# 获取资源 response = requests.get('http://api.example.com/resource') # 创建资源 response = requests.post('http://api.example.com/resource', json=data) # 更新资源 response = requests.put('http://api.example.com/resource/1', json=data) # 删除资源 response = requests.delete('http://api.example.com/resource/1') -
处理状态码:理解并处理不同的 HTTP 状态码,例如 200 表示成功,404 表示未找到,500 表示服务器错误等。
-
使用 JSON:RESTful 服务通常使用 JSON 作为数据交换格式,需要熟悉如何发送和解析 JSON 数据。
-
认证和授权:如果 RESTful 服务需要认证,可能需要在请求中包含认证信息,如 OAuth 令牌。
-
错误处理:正确处理 API 调用中可能出现的错误,如网络错误、数据格式错误等。
通过上述步骤,你可以构建一个基本的 Python 爬虫,或者使用 RESTful 服务来获取和操作数据。记住,爬虫的使用应遵守法律法规和网站的使用条款。
让我们通过一个具体的案例来讲解 Python 爬虫技术的应用,以及如何使用 RESTful API 服务。
案例:爬取在线商店的商品信息
假设我们想要爬取一个在线商店的商品信息,包括商品名称、价格、库存状态等。
步骤 1: 确定数据来源
首先,我们需要确定数据来源。如果商店提供了 API,我们应优先使用 API,因为它通常更稳定、更快速,并且可以减少对网站服务器的压力。
步骤 2: 注册 API 并获取密钥
许多 API 服务需要注册并获取一个 API 密钥(API Key),以验证请求的合法性。
步骤 3: 阅读 API 文档
阅读 API 提供的文档,了解如何构造请求,包括基本的 URL、支持的 HTTP 方法、请求参数、认证方式等。
步骤 4: 使用 Python 发送请求
使用 requests 库构造请求并获取数据。
import requestsapi_url = 'https://api.examplestore.com/products'
api_key = 'your_api_key_here'
headers = {'Authorization': f'Bearer {api_key}','Content-Type': 'application/json'
}# 发送 GET 请求获取商品列表
response = requests.get(api_url, headers=headers)
products = response.json()
步骤 5: 解析数据
解析返回的 JSON 数据,提取所需的商品信息。
for product in products['data']:print(f"Product Name: {product['name']}")print(f"Price: {product['price']}")print(f"In Stock: {product['in_stock']}")print("-" * 30)
步骤 6: 存储数据
将提取的数据存储到适当的格式或数据库中。
import csv# 将数据写入 CSV 文件
with open('products.csv', 'w', newline='', encoding='utf-8') as file:writer = csv.writer(file)writer.writerow(['Product Name', 'Price', 'In Stock'])for product in products['data']:writer.writerow([product['name'], product['price'], product['in_stock']])
步骤 7: 处理分页
如果 API 支持分页,需要处理分页以获取所有数据。
page = 1
while True:params = {'page': page}response = requests.get(api_url, headers=headers, params=params)page_data = response.json()if not page_data['data']:breakfor product in page_data['data']:print(f"Product Name: {product['name']}")page += 1
步骤 8: 异常处理
添加异常处理逻辑,确保程序的健壮性。
try:response = requests.get(api_url, headers=headers)response.raise_for_status() # 检查请求是否成功
except requests.exceptions.HTTPError as err:print(f"HTTP error occurred: {err}")
except requests.exceptions.RequestException as e:print(f"Error during requests to {api_url}: {e}")
步骤 9: 遵守爬虫礼仪
确保你的爬虫遵守 robots.txt 规则,不要发送请求过于频繁,以免对服务器造成过大压力。
步骤 10: 使用代理和用户代理
如果遇到 IP 被封的情况,可以使用代理和更改用户代理。
proxies = {'http': 'http://10.10.1.10:3128','https': 'http://10.10.1.10:1080',
}
headers['User-Agent'] = 'Your Custom User Agent'
通过这个案例,你可以看到 Python 爬虫技术的实际应用,以及如何与 RESTful API 服务交互。记住,实际应用中还需要考虑更多的细节,如请求频率控制、数据的进一步清洗和分析等。
好的,让我们继续优化上述案例,使其更加健壮和高效。
优化点 1: 动态处理分页
在处理分页时,我们不仅要考虑循环获取数据,还要考虑 API 的分页参数可能有所不同,以及如何动态地处理分页。
def fetch_all_products(api_url, api_key):headers = {'Authorization': f'Bearer {api_key}','Content-Type': 'application/json'}params = {}products = []while True:response = requests.get(api_url, headers=headers, params=params)page_data = response.json()if not page_data['data']:breakproducts.extend(page_data['data'])# 动态检查API的分页参数,可能是'page'或'offset'if 'next_page' in page_data:params = {'page': page_data['next_page']}elif 'next_offset' in page_data:params['offset'] = page_data['next_offset']else:breakreturn products# 使用函数
api_key = 'your_api_key_here'
all_products = fetch_all_products(api_url, api_key)
优化点 2: 异步请求
如果 API 允许并发请求,使用异步请求可以显著提高数据获取的效率。
import asyncio
import aiohttpasync def fetch_product(session, url, headers):async with session.get(url, headers=headers) as response:return await response.json()async def fetch_all_products_async(api_url, api_key):headers = {'Authorization': f'Bearer {api_key}','Content-Type': 'application/json'}tasks = []products = []page = 1while True:url = f"{api_url}?page={page}"task = fetch_product(aiohttp.ClientSession(), url, headers)tasks.append(task)if len(tasks) >= 5: # 限制同时进行的请求数量responses = await asyncio.gather(*tasks)products.extend([resp['data'] for resp in responses])tasks.clear()if not tasks: # 检查是否还有下一页breakpage += 1return products# 使用异步函数
api_key = 'your_api_key_here'
loop = asyncio.get_event_loop()
all_products_async = loop.run_until_complete(fetch_all_products_async(api_url, api_key))
优化点 3: 错误重试机制
在网络请求中,引入错误重试机制可以提高爬虫的稳定性。
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retrydef requests_retry_session(retries=3,backoff_factor=0.3,status_forcelist=(500, 502, 504),session=None,
):session = session or requests.Session()retry = Retry(total=retries,read=retries,connect=retries,backoff_factor=backoff_factor,status_forcelist=status_forcelist,)adapter = HTTPAdapter(max_retries=retry)session.mount('http://', adapter)session.mount('https://', adapter)return session# 使用带重试的会话
session = requests_retry_session()
response = session.get(api_url, headers=headers)
优化点 4: 日志记录
添加日志记录可以帮助我们更好地监控爬虫的状态和调试问题。
import logginglogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')try:response = session.get(api_url, headers=headers)response.raise_for_status()
except requests.exceptions.HTTPError as err:logging.error(f"HTTP error occurred: {err}")
except requests.exceptions.RequestException as e:logging.error(f"Error during requests to {api_url}: {e}")
优化点 5: 遵守爬虫协议
确保爬虫遵守 robots.txt 文件的规定,并设置合理的请求间隔,避免给网站服务器带来过大压力。
import time
import robotparserrp = robotparser.RobotFileParser()
rp.set_url("http://examplestore.com/robots.txt")
rp.read()if rp.can_fetch("*", api_url): # 检查是否可以爬取API URLresponse = session.get(api_url, headers=headers)
else:logging.warning("Crawling blocked by robots.txt")time.sleep(1) # 休息一段时间再尝试
优化点 6: 数据清洗和验证
在存储数据前,进行数据清洗和验证,确保数据的准确性和一致性。
def clean_data(product):cleaned_product = {}for key, value in product.items():if key in ['name', 'price', 'in_stock']:if key == 'price':cleaned_product[key] = float(value) # 确保价格是数字类型elif key == 'in_stock':cleaned_product[key] = bool(value) # 确保库存是布尔类型else:cleaned_product[key] = value.strip() # 去除字符串两端的空白字符return cleaned_productcleaned_products = [clean_data(product) for product in all_products]
通过这些优化点,我们的爬虫不仅更加健壮和高效,而且更加专业和符合最佳实践。
相关文章:

Python爬虫技术 第27节 API和RESTful服务
Python 爬虫技术是一种自动化获取网页内容的方法,通常用于数据收集、信息抽取或自动化测试。在讲解 Python 爬虫技术时,我们通常会涉及到以下几个关键概念: HTTP 请求:爬虫通过发送 HTTP 请求来获取网页内容,这是爬虫与…...

音视频入门基础:WAV专题(4)——FFmpeg源码中获取WAV文件音频压缩编码格式、采样频率、声道数量、采样位数、码率的实现
音视频入门基础:WAV专题系列文章: 音视频入门基础:WAV专题(1)——使用FFmpeg命令生成WAV音频文件 音视频入门基础:WAV专题(2)——WAV格式简介 音视频入门基础:WAV专题…...

环境变量在Conda中的魔法:控制包安装的秘诀
环境变量在Conda中的魔法:控制包安装的秘诀 Conda不仅是Python和其他语言包的包管理器,它还是一个强大的环境管理器。在使用Conda时,环境变量可以极大地增强其功能,允许用户控制包的安装过程,实现定制化的安装策略。本…...

VS Code C/C++ MSVC编译器
官方教程 通过快捷方式打开VS Code是编译不了的,需要对tasks.json修改(Tasks: Configure default build task) 先创建tasks.json 复制这段配置到tasks.json,记得修改VsDevCmd.bat的路径 {"version": "2.0.0","windows": {"options"…...

【技巧】IDEA 个性化配置
【技巧】IDEA 个性化配置 自动补全 关闭大小写区分 自动导包 插件 Rainbow Brackets 彩色括号 更容易区分是哪个括号...

`pytest` 中一些常用的选项
下面列出的参数和功能涵盖了 pytest 中一些常用的选项,但 pytest 还有许多其他参数和功能。以下是一些补充的 pytest 命令行参数和功能: 其他命令行参数 测试配置 --confcutdir<path>: 只加载指定目录及其子目录中的配置文件。例如 --confcutdirs…...

fme从json中提取位置到kml中
fme从json中提取位置到kml中 简单参考,我自己要用的,越弄越复杂。 概述-模板总体结构 数据就是官方提供的数据,模板的基本节结构是读模块+转换器+写模块,最近爬取一些json文件,用到了。 1.使用json读模块读取数据 首先检查一下源数据 使用文本打开数据集,可以看到非缩…...

在Ubuntu 18.04上安装和配置pgAdmin 4服务器模式的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 pgAdmin 是一个针对 PostgreSQL 及其相关数据库管理系统的开源管理和开发平台。它使用 Python 和 jQuery 编写,支持 P…...
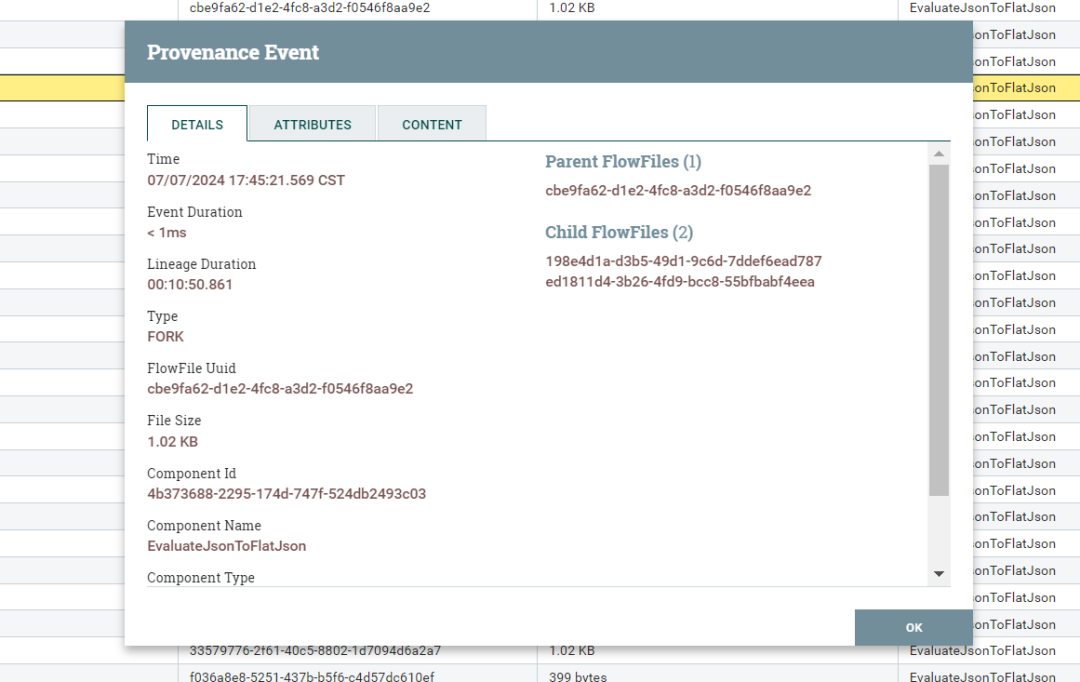
NiFi :1 初识这把“十年一剑”的利器
--->更多内容,请移步“鲁班秘笈”!!<--- “现在AI和数据处理密不可分,80%的企业可以利用Apache NiFi轻松解决复杂的数据问题,快速完成场景建设。犹如花上百来块钱在家享受一顿不亚于五星级西餐厅的法式大餐。对…...

Pyside6实战教程专栏目录
Pyside6实战教程🚀 专栏目录介绍 本专栏将详细地向Python开发者展示如何利用PySide6框架创建功能丰富的桌面应用程序。无论你是刚刚接触GUI编程的新手,还是希望快速提升自己技能水平的进阶用户,本文都将为你提供一系列简单易懂的教程…...
 创建图表)
【Dash】使用 Dash Design Kit (DDK) 创建图表
一、Styling Your App The examples in the previous section used Dash HTML Components to build a simple app layout, but you can style your app to look more professional. This section will give a brief overview of the multiple tools that you can use to enhan…...

C++ 几何算法 - 向量点乘,叉乘及其应用
一:点乘介绍 1. 向量点乘: 2. 向量点乘的性质: 3. 向量点乘公式: 4. 向量的点乘的属性: (1):向量与自身做点乘,会得到向量长度的平方: (2…...
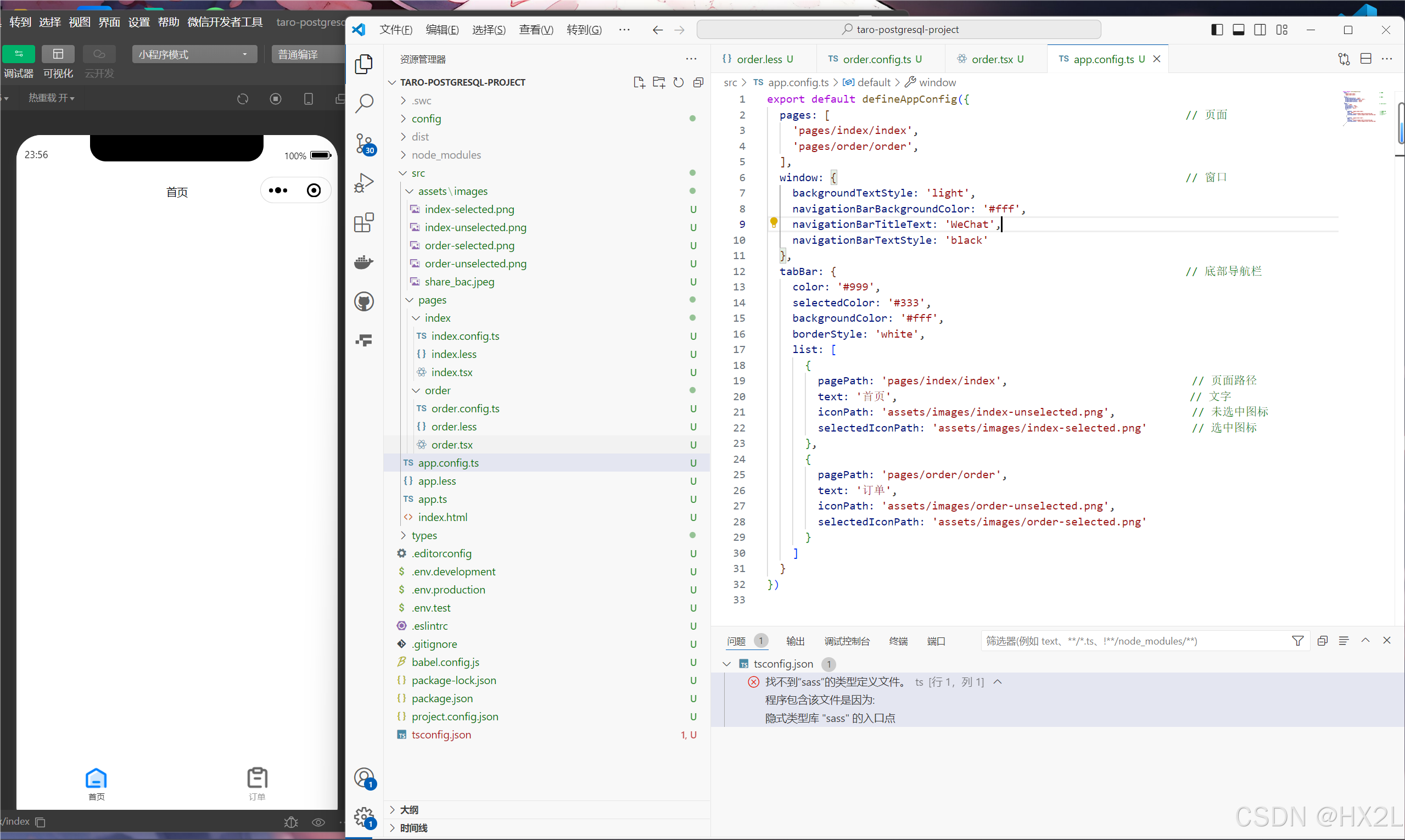
Taro学习记录(具体项目实践)
一、安装taro-cli 二、项目文件 三、项目搭建 1、Eslint配置 在项目生成的 .eslintrc 中进行配置 {"extends": ["taro/react"], //一个配置文件,可以被基础配置中的已启用的规则继承"parser": "babel/eslint-parser…...
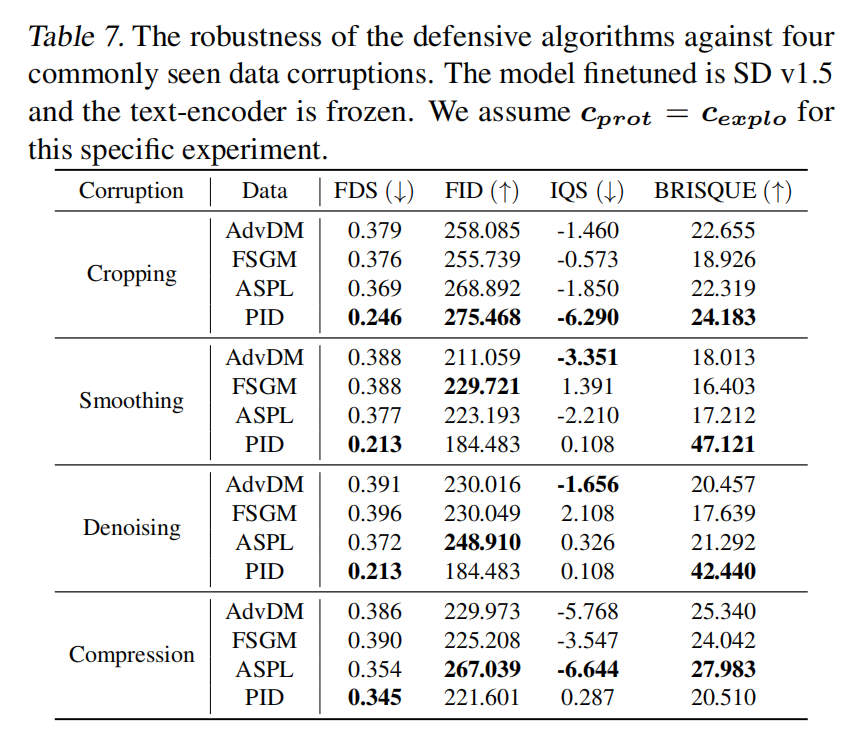
ICML 2024 | 矛与盾的较量!北大提出提示无关数据防御保护算法PID
文章链接:https://arxiv.org/pdf/2406.15305 代码地址:https://github.com/PKU-ML/Diffusion-PID-Protection 亮点直击 本文在实证观察中发现,保护阶段和利用阶段之间的提示不匹配可能会削弱当前数据保护算法的有效性。本文深入探讨了利用LDM…...

Oracle聚合函数LISTAGG和WM_CONCAT简介
目录 Oracle聚合函数LISTAGG和WM_CONCAT简介LISTAGG 函数1.语法2.示例3.去除重复值 WM_CONCAT 函数1.语法2.示例3.去除重复值 比较1.性能2.排序与分隔符3.去除重复值 Oracle聚合函数LISTAGG和WM_CONCAT简介 在处理数据库中的数据聚合任务时,我们经常需要将多行数据…...

【Unity】多种寻路算法实现 —— BFS,DFS,Dijkstra,A*
本实验寻路算法均基于网格实现,整体称呼为Grid,单个瓦片称之为Tile 考虑程序处理的简洁性,所有算法使用同一种Tile,且权值点,A*所需的记录数值也全部放在Tile中记录 前排贴上代码仓库链接: GitHub - Sir…...

十大游戏设计软件:创意实现的利器
在数字娱乐的多彩世界里,游戏设计无疑是一项充满创意与技术挑战的艺术。随着技术的进步,游戏设计师的手中拥有了一系列强大的工具,它们让想象中的世界得以呈现,让玩家的体验更加丰富和真实。本文将带你走进游戏设计的幕后…...

Pandas高级操作:多级索引、窗口函数、数据透视表等
在数据处理和分析中,pandas库提供了强大的功能,支持从简单到复杂的数据操作。本文将介绍一些pandas的高级操作,包括多级索引(MultiIndex)、窗口函数(Window Functions)、数据透视表与复杂聚合、数据合并与连接、高级数据变换以及时间序列数据的高级处理。 1. 多级索引(…...

mysql源码编译启动debug
对于没有C语言基础的同学来说,想看看源码,在搞定编辑器做debug的时候就被劝退了,发生点啥了,完全看不懂,不知道从哪里入手去做debug;我为了看看 mysql 的 insert buffer 到底存的是索引页还是数据页&#x…...

吴恩达机器学习-C1W3L2-逻辑回归之S型函数
可选实验:逻辑回归 在这个不评分的实验中,你会 探索sigmoid函数(也称为logistic函数)探索逻辑回归;哪个用到了s型函数 import numpy as np %matplotlib widget import matplotlib.pyplot as plt from plt_one_addpt_onclick import plt_one_addpt_onclick from l…...

Qt步进电机上位机控制程序源代码,支持串口、Tcp网口、Udp网络三种端口类型,详细注释和讲解
Qt步进电机上位机控制程序源代码Qt跨平台C/C语言编写 支持串口Tcp网口Udp网络三种端口类型 提供,提供详细注释和人工讲解 1.功能介绍: 可控制步进电机的上位机程序源代码,基于Qt库,采用C/C语言编写。 支持串口、Tcp网口、Udp网络三…...

QT点云渲染实战--从QGLWidget到交互式3D可视化
1. 为什么选择QT和QGLWidget做点云可视化 第一次接触3D点云渲染时,我试过用Python的Matplotlib,也折腾过PCL库,但真正要在工业软件中集成可视化功能时,QTQGLWidget的组合给了我惊喜。这个经典方案虽然不如现代WebGL炫酷࿰…...

浙江金华车间酷热难挡?蒸发冷省电空调能否解决降温难题?
浙江金华的夏季,车间内酷热难挡是许多企业面临的难题。高温不仅让员工工作体验变差,还可能影响生产效率。这时,蒸发冷省电空调成为备受关注的解决方案。蒸发冷省电空调的制冷原理有其独特之处。它需要压缩机、制冷剂进行内循环制冷。压缩机作…...
:覆盖LLM编译器、Agent工作流、RAG-Native架构等9大新兴栈)
AI原生研发能力评估体系(2026权威实测版):覆盖LLM编译器、Agent工作流、RAG-Native架构等9大新兴栈
第一章:AI原生软件研发技术雷达图2026版全景概览 2026奇点智能技术大会(https://ml-summit.org) 2026版AI原生软件研发技术雷达图基于全球327个生产级AI应用项目、18家头部云厂商平台能力评估及41项开源工具链实测数据构建,覆盖模型即服务(M…...

从零到一:手把手教你用HBase Shell和Java API管理学生成绩表
从零到一:HBase Shell与Java API双视角构建学生成绩管理系统 1. 场景化教学:为什么选择HBase管理学生成绩? 在教育信息化快速发展的今天,传统的关系型数据库在处理海量学生成绩数据时逐渐暴露出性能瓶颈。某省级教育平台在2023年的…...
驱动应用程序设计)
基于STM32LXXX的数字电位器(AD5290YRMZ10)驱动应用程序设计
一、简介: AD5290是一款支持15V高压的数字电位器,采用SPI接口控制。相比普通数字电位器,它最大的优势是支持30V单电源或15V双电源供电,适合工业控制、可编程电源等需要高压调节的应用场景。 二、主要技术特性: 参数 值 说明 抽头数 256 8位分辨率,0~255可编程 端到端电阻…...

WinISO:解决光盘镜像编辑与制作的三大实际问题
在日常工作中,你是否遇到过这样的场景:下载了一个 ISO 镜像文件,想往里面添加几个补丁或删除一个无用文件,却只能解压后再重新打包;或者你有一个旧版 Windows 安装盘,想替换其中的 install.wim 文件来制作集…...

Claude ACP 配置与避坑指南
Claude ACP 配置与避坑指南OpenClaw Claude Code (ACP Harness) 部署完整指南 | 枢归档1. 什么是 Claude ACP Claude ACP(Agent Client Protocol)是 OpenClaw 与外部 Agent Harness(如 Claude Code)之间的通信协议。通过 ACP&…...

从调参实战看差异:Lattice Planner和EM Planner在Apollo中的参数配置与场景适配心得
从调参实战看差异:Lattice Planner和EM Planner在Apollo中的参数配置与场景适配心得 在自动驾驶系统的开发中,规划算法是决定车辆行为的关键模块。百度Apollo平台提供了Lattice Planner和EM Planner两种主流规划器,它们在算法原理和适用场景上…...
)
OpenClaw 微信部署避坑实操:多模式部署+常见故障速解(附部署包)
前言 在微信私域运营与自动化客服场景中,OpenClaw 可打通微信客户端与后端服务的通信链路,降低接入门槛,支持本地、云端等多环境部署,兼顾数据安全与连接稳定。本文聚焦部署细节与故障排查逻辑,适配中小企业业务落地&…...