理解张量拼接(torch.cat)
拼接
维度顺序:对于 3D 张量,通常可以理解为 (深度, 行, 列) 或 (批次, 行, 列)。 选择一个dim进行拼接的时候其他两个维度大小要相等
![![[Pasted image 20240808214248.png]]](https://i-blog.csdnimg.cn/direct/2d87a36261384c2b92383d078c8e3c88.png)
对于三维张量,理解 torch.cat 的 dim 参数确实变得更加抽象,但原理是相同的。让我们通过一个具体的例子来说明这一点。
import torch# 创建两个 3D 张量
a = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
b = torch.tensor([[[9, 10], [11, 12]], [[13, 14], [15, 16]]])print("Tensor a shape:", a.shape)
print(a)
print("\nTensor b shape:", b.shape)
print(b)# dim=0 连接
c_dim0 = torch.cat([a, b], dim=0)
print("\nResult of torch.cat([a, b], dim=0):")
print("Shape:", c_dim0.shape)
print(c_dim0)# dim=1 连接
c_dim1 = torch.cat([a, b], dim=1)
print("\nResult of torch.cat([a, b], dim=1):")
print("Shape:", c_dim1.shape)
print(c_dim1)# dim=2 连接
c_dim2 = torch.cat([a, b], dim=2)
print("\nResult of torch.cat([a, b], dim=2):")
print("Shape:", c_dim2.shape)
print(c_dim2)现在让我们详细解释这个三维张量的例子:
-
初始张量:
a和b都是形状为 (2, 2, 2) 的 3D 张量。- 可以将它们想象成两个 2x2 的矩阵堆叠在一起。
-
dim=0连接:- 结果形状:(4, 2, 2)
- 这相当于在第一个维度上堆叠张量。
- 可以理解为将
b放在a的"下面",增加了第一个维度的大小。
-
dim=1连接:- 结果形状:(2, 4, 2)
- 这相当于在第二个维度上堆叠张量。
- 可以理解为在每个 2x2 矩阵的"行"方向上扩展,将
b的行添加到a的每个对应部分的下方。
-
dim=2连接:- 结果形状:(2, 2, 4)
- 这相当于在第三个维度(最内层)上堆叠张量。
- 可以理解为在每个 2x2 矩阵的"列"方向上扩展,将
b的列添加到a的每个对应部分的右侧。
理解三维张量 torch.cat 的关键点:
-
维度顺序:对于 3D 张量,通常可以理解为 (深度, 行, 列) 或 (批次, 行, 列)。
-
dim=0:增加"深度"或"批次"的数量。 -
dim=1:增加每个"深度"层或"批次"中的行数。 -
dim=2:增加每行中的元素数量(列数)。 -
保持其他维度:除了被连接的维度,其他维度的大小保持不变。
-
形状变化:只有指定的
dim对应的维度大小会改变(增加),其他维度大小保持不变。 -
一致性:要连接的张量在非连接维度上的大小必须相同。
3D Matrix Visualization
Let’s visualize the 3D matrices a and b, and their concatenation results.
Matrix a (2x2x2):
Depth 0: Depth 1:
+---+---+ +---+---+
| 1 | 2 | | 5 | 6 |
+---+---+ +---+---+
| 3 | 4 | | 7 | 8 |
+---+---+ +---+---+
Matrix b (2x2x2):
Depth 0: Depth 1:
+----+----+ +----+----+
| 9 | 10 | | 13 | 14 |
+----+----+ +----+----+
| 11 | 12 | | 15 | 16 |
+----+----+ +----+----+
Concatenation Results:
dim=0 (4x2x2):
Depth 0: Depth 1: Depth 2: Depth 3:
+---+---+ +---+---+ +----+----+ +----+----+
| 1 | 2 | | 5 | 6 | | 9 | 10 | | 13 | 14 |
+---+---+ +---+---+ +----+----+ +----+----+
| 3 | 4 | | 7 | 8 | | 11 | 12 | | 15 | 16 |
+---+---+ +---+---+ +----+----+ +----+----+
dim=1 (2x4x2):
Depth 0: Depth 1:
+---+---+ +---+---+
| 1 | 2 | | 5 | 6 |
+---+---+ +---+---+
| 3 | 4 | | 7 | 8 |
+---+---+ +---+---+
| 9 | 10 | | 13| 14|
+---+---+ +---+---+
| 11| 12 | | 15| 16|
+---+---+ +---+---+
dim=2 (2x2x4):
Depth 0: Depth 1:
+---+---+---+---+ +---+---+---+---+
| 1 | 2 | 9 | 10| | 5 | 6 | 13| 14|
+---+---+---+---+ +---+---+---+---+
| 3 | 4 | 11| 12| | 7 | 8 | 15| 16|
+---+---+---+---+ +---+---+---+---+
当然可以!让我们通过具体的例子来形象地解释不同维度上的拼接。
定义张量
首先,定义三个张量 x, y, z,它们分别具有如下形状:
x的形状是[2, 1, 3]y的形状是[2, 3, 3]z的形状是[2, 2, 3]
import torchx = torch.tensor([[[0, 0, 0]], [[0, 0, 0]]])
y = torch.tensor([[[0, 0, 0], [0, 0, 0], [0, 0, 0]],[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
])
z = torch.tensor([[[0, 0, 0], [0, 0, 0]],[[0, 0, 0], [0, 0, 0]]
])
(1) 在 dim=0 上拼接
在 dim=0 上拼接,相当于增加“深度”或“批次”的数量。每个张量的“深度”都会堆叠起来。
w_dim0 = torch.cat([x, y, z], dim=0)
print(w_dim0.shape)
形象解释:
x:
[[[0, 0, 0]], # 第一层深度[[0, 0, 0]] # 第二层深度
]y:
[[[0, 0, 0], [0, 0, 0], [0, 0, 0]], # 第一层深度[[0, 0, 0], [0, 0, 0], [0, 0, 0]] # 第二层深度
]z:
[[[0, 0, 0], [0, 0, 0]], # 第一层深度[[0, 0, 0], [0, 0, 0]] # 第二层深度
]拼接结果 w_dim0:
[[[0, 0, 0]], # x 第一层深度[[0, 0, 0]], # x 第二层深度[[0, 0, 0], [0, 0, 0], [0, 0, 0]], # y 第一层深度[[0, 0, 0], [0, 0, 0], [0, 0, 0]], # y 第二层深度[[0, 0, 0], [0, 0, 0]], # z 第一层深度[[0, 0, 0], [0, 0, 0]] # z 第二层深度
]
形状:[6, 3, 3]
(2)dim=1 上拼接
在 dim=1 上拼接,相当于增加每个“深度”层中的行数。每个深度层的行数会拼接起来。
w_dim1 = torch.cat([x, y, z], dim=1)
print(w_dim1.shape)
形象解释:
x:
[[[0, 0, 0]], # 第一层深度的第一行[[0, 0, 0]] # 第二层深度的第一行
]y:
[[[0, 0, 0], [0, 0, 0], [0, 0, 0]], # 第一层深度的三行[[0, 0, 0], [0, 0, 0], [0, 0, 0]] # 第二层深度的三行
]z:
[[[0, 0, 0], [0, 0, 0]], # 第一层深度的两行[[0, 0, 0], [0, 0, 0]] # 第二层深度的两行
]拼接结果 w_dim1:
[[[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]], # 第一层深度的六行[[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]] # 第二层深度的六行
]
形状:[2, 6, 3]
当然可以!为了展示如何在 dim=2(第三个维度)上拼接张量,我们需要确保这些张量在前两个维度上的大小是相同的,而在第三个维度上的大小可以不同。
假设我们定义三个张量 a, b, c,它们分别具有如下形状:
a的形状是[2, 2, 2]b的形状是[2, 2, 3]c的形状是[2, 2, 1]
import torcha = torch.tensor([[[1, 2], [3, 4]],[[5, 6], [7, 8]]
])b = torch.tensor([[[9, 10, 11], [12, 13, 14]],[[15, 16, 17], [18, 19, 20]]
])c = torch.tensor([[[21], [22]],[[23], [24]]
])
(3)在 dim=2 上拼接
在 dim=2 上拼接,相当于增加每行中的元素数量(列数)。每个深度层中的列数会拼接起来:
w_dim2 = torch.cat([a, b, c], dim=2)
print(w_dim2)
print(w_dim2.shape)
形象解释:
a:
[[[1, 2], [3, 4]], # 第一层深度的两行两列[[5, 6], [7, 8]] # 第二层深度的两行两列
]b:
[[[9, 10, 11], [12, 13, 14]], # 第一层深度的两行三列[[15, 16, 17], [18, 19, 20]] # 第二层深度的两行三列
]c:
[[[21], [22]], # 第一层深度的两行一列[[23], [24]] # 第二层深度的两行一列
]拼接结果 w_dim2:
[[[1, 2, 9, 10, 11, 21], [3, 4, 12, 13, 14, 22]], # 第一层深度的两行六列[[5, 6, 15, 16, 17, 23], [7, 8, 18, 19, 20, 24]] # 第二层深度的两行六列
]w_dim2 的形状为:[2, 2, 6]
通过在 dim=2 上拼接,结果张量 w_dim2 的第三个维度是各个张量第三个维度的和:2 + 3 + 1 = 6。
# 代码输出:
# tensor([[[ 1, 2, 9, 10, 11, 21],
# [ 3, 4, 12, 13, 14, 22]],
#
# [[ 5, 6, 15, 16, 17, 23],
# [ 7, 8, 18, 19, 20, 24]]])
#
# 形状: torch.Size([2, 2, 6])
希望这个例子能帮助你更好地理解如何在 dim=2 上拼接张量。
非常好的问题!让我们用书架的比喻来解释这个例子,这将有助于更直观地理解张量的维度。
在这个比喻中:
dim=0(第一个维度)代表书架的数量dim=1(第二个维度)代表每个书架的层板数dim=2(第三个维度)代表每个层板可以放置的书本数量(即层板的宽度)
让我们用这个比喻来解释 a, b, 和 c 这三个张量:
-
张量
a[2, 2, 2]:- 2个书架
- 每个书架有2层层板
- 每个层板可以放2本书
-
张量
b[2, 2, 3]:- 2个书架
- 每个书架有2层层板
- 每个层板可以放3本书
-
张量
c[2, 2, 1]:- 2个书架
- 每个书架有2层层板
- 每个层板可以放1本书
当我们在 dim=2 上拼接这些张量时,相当于我们在不改变书架数量和层板数量的情况下,将每个层板变宽,使其可以容纳更多的书。
拼接后的结果 w_dim2 [2, 2, 6]:
- 仍然是2个书架(dim=0 没变)
- 每个书架仍然有2层层板(dim=1 没变)
- 但是现在每个层板可以放6本书了(dim=2 变成了 2+3+1=6)
形象地说:
原来的书架 a: 原来的书架 b: 原来的书架 c:
[□□] [□□□] [□]
[□□] [□□□] [□][□□] [□□□] [□]
[□□] [□□□] [□]拼接后的新书架 w_dim2:
[□□□□□□] (2+3+1 = 6本书)
[□□□□□□][□□□□□□]
[□□□□□□]
每个 □ 代表一本书(或者说张量中的一个元素)。
这个比喻展示了我们如何在不增加书架数量(dim=0)或层板数量(dim=1)的情况下,通过拼接来增加每个层板可以放置的书本数量(dim=2)。这就是在 dim=2 上进行张量拼接的直观理解。
相关文章:
理解张量拼接(torch.cat)
拼接 维度顺序:对于 3D 张量,通常可以理解为 (深度, 行, 列) 或 (批次, 行, 列)。 选择一个dim进行拼接的时候其他两个维度大小要相等 对于三维张量,理解 torch.cat 的 dim 参数确实变得更加抽象,但原理是相同的。让我们通过一…...

指针基础知识(笔记)
文章目录 1. 概念理解2. 空指针和野指针3. 计算4. 小结5. size_t6. 案例一: 指针查找并返回指定元素索引7. 指针访问多维数组(涉及 int (*ptr)[3]解析)8. 指针数组9. 函数的值传递与地址引用传递① 函数的值传递(pass by value)② 地址传递(pass by reference) 10. 案例二&…...

[Python学习日记-3] 编程前选择一个好用的编程工具
[Python学习日记-3] 编程前选择一个好用的编程工具 简介 PyCharm IDE的安装 PyCharm IDE安装后的一些常规使用 简介 在踏上 Python 编程的精彩旅程之前,选择一款得心应手的编程工具无疑是至关重要的一步。这就如同战士在出征前精心挑选趁手的武器,它将…...

智能化的Facebook未来:AI如何重塑社交网络的面貌?
随着人工智能(AI)技术的飞速发展,社交网络的面貌正在经历深刻的变革。Facebook(现Meta Platforms)作为全球最大的社交媒体平台之一,正积极探索如何利用AI技术来提升用户体验、优化内容管理并推动平台创新。…...

安全启动的原理
安全启动(Secure Boot)是一种用于确保设备只运行经过认证的软件的安全机制。其核心原理和步骤如下: 1. **硬件信任根(Root of Trust, RoT)**: - 安全启动过程始于硬件信任根,通常是设备上的…...

【ML】pre-train model 是什么如何微调它,如何预训练
【ML】pre-train model 是什么如何微调它,如何预训练 0. 预训练模型(Pre-trained Model)0.1 预训练模型的预训练过程0.2 如何微调预训练模型0.3 总结 1. Contextualized word Embedding2. 怎么 让 bert 模型变小3. 如何微调模型 0. 预训练模型…...
)
leetcode代码练习——Java的数据结构(具体使用)
注:Java中所有的泛型必须是引用类型 如<Integer>而不是<int> java提供的数学方法: 求最大值Math.max(10,15),最小值Math.min(10,15) 看取值范围: int范围:-2^31-2^31-1 double范围:-2^63-2^63-1 long范围:-2^63-2…...
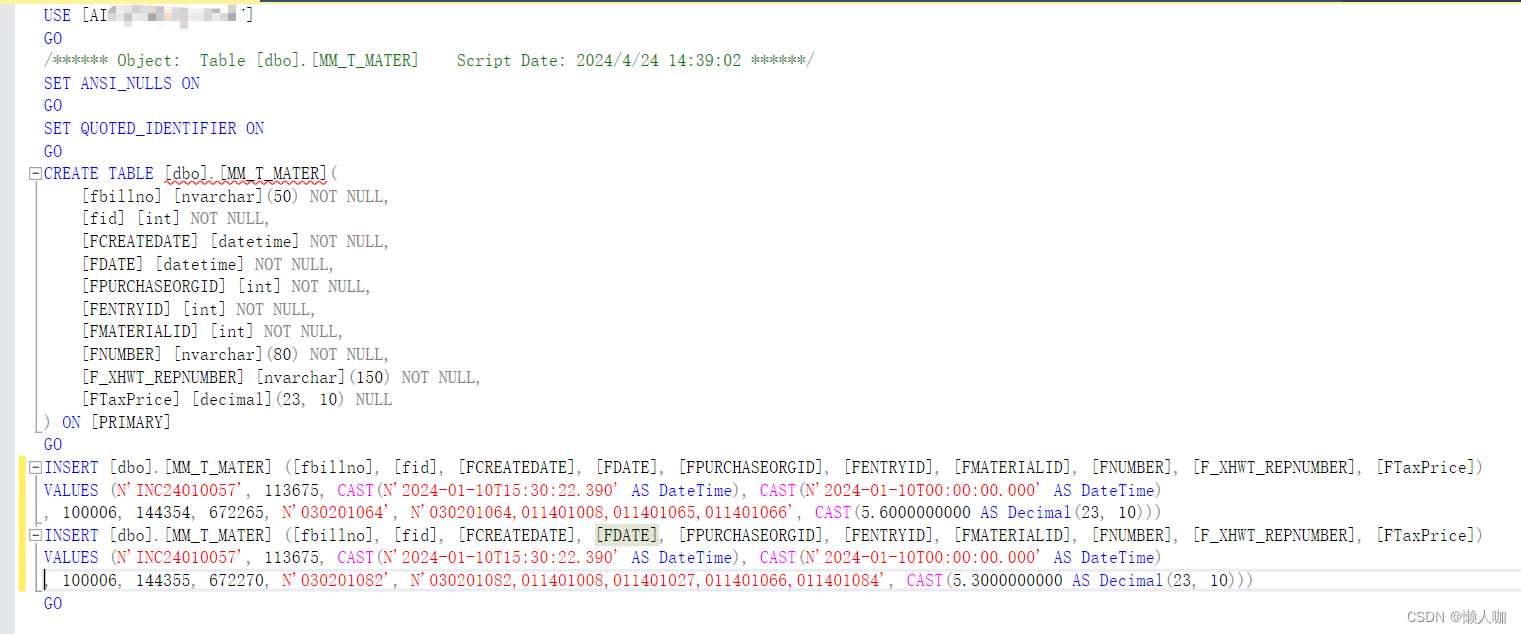
sqlserver导出数据脚本
文章目录 sqlserver导出数据脚本任务-生成脚本 sqlserver导出数据脚本 任务-生成脚本...

html+css 实现hover中间展开背景
前言:哈喽,大家好,今天给大家分享htmlcss 绚丽效果!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目…...

Java 怎么获取支付宝Open ID
在Java中获取支付宝用户的OpenID,通常是通过支付宝的开放平台API来完成的。OpenID是支付宝用于唯一标识一个支付宝用户的字符串,它在OAuth授权流程中被用来获取用户的身份和权限。 下面我将给出一个基于Java使用Spring Boot框架和支付宝开放平台SDK来获…...

Web-server日志分析命令
https://gist.github.com/hvelarde/ceac345c662429447959625e6feb2b47 通过状态码获取请求总数 awk {print $9} /var/log/apache2/access.log | sort | uniq -c | sort –rn按照IP的请求数量排序 awk {print $1} /var/log/apache2/access.log | sort | uniq -c | sort -rn |…...

Typora的markdown笔记使用说明
个人感觉Typora是一款很适合记录编程学习的软件 目录 个人感觉Typora是一款很适合记录编程学习的软件 一、标题 二、段落 1、换行 2、分割线 三、文字显示 1、字体 2、上下标 四、列表 1、无序列表 2、有序列表 3、任务列表 五、区块显示 六、代码显示 1、行内…...

前端如何做单元测试? 看这篇就入门了
前言 对于现在的前端工程,一个标准完整的项目,通常情况单元测试是非常必要的。但很多时候我们只是完成了项目而忽略了项目测试。我认为其中一个很大的原因是很多人对单元测试认知不够,因此我写了这边文章,一方面期望通过这篇文章…...

Chainlit快速实现AI对话应用的聊天记录如何持久性保存
前言 Chainlit 可以设置聊天记录用户搜索和浏览过去的对话。 如何实现 要启用聊天历史记录,您需要启用: 数据持久性身份验证恢复对话 为了让用户继续持久对话,请使用cl.on_chat_resume 生命周期钩子 装饰器使用户能够继续对话。需要同时启用数据持久性和身份验证。 该…...

【探索数据结构与算法】——深入了解双向链表(图文详解)
目录 一、双向链表的基本概念 二、双向链表的结构 三、双向链表的基本操作实现方法 1.双向链表的初始化 2.双向链表的头插 3.双向链表的尾插 6.查找节点 7.在指定位置之前插入节点 8.删除指定位置节点 9.打印链表数据 10.双向链表销毁 四、完整代码实现 …...

linux常用命令备忘录
一、常用命令 查看被占用进程:ps ef|grep 11612 查看当前目录:pwd 查看文件的md5: (linux)md5sum 文件名 (windows)certutil -hashfile some_file MD5 查看当前目录的文件大小:…...

【C++进阶学习】第十二弹——C++ 异常处理:深入解析与实践应用
前言: 在C编程语言中,异常处理是一种重要的机制,它允许程序员在运行时捕获和处理错误或异常情况。本文将详细介绍C异常处理的相关知识点,包括异常的定义、抛出与捕获、异常处理的原则、以及在实际编程中的应用。 目录 1. 异常处理…...

《算法竞赛进阶指南》0x23剪枝
剪枝,就是减少搜索树的规模、尽可能排除搜索书中不必要的分支的一种手段。形象地看,就好像剪掉了搜索树的枝条,故被称为“剪枝”。在深度优先搜索中,有以下常见的剪枝方法。 1.优化搜索顺序 在一些搜索问题中,搜索树的…...

同态加密和SEAL库的介绍(三)BFV - Batch Encoder
写在前面: 在上一篇中展示了如何使用 BFV 方案执行一个非常简单的计算。该计算在 plain_modulus 参数下进行,并且仅使用了 BFV 明文多项式中的一个系数。这种方法有两个显著的问题: 实际应用通常使用整数或实数运算,而不是模运算…...
Docker 环境下使用 Traefik v3 和 MinIO 快速搭建私有化对象存储服务
上一篇文章中,我们使用 Traefik 新版本完成了本地服务网关的搭建。接下来,来使用 Traefik 的能力,进行一系列相关的基础设施搭建吧。 本篇文章,聊聊 MinIO 的单独使用,以及结合 Traefik 完成私有化 S3 服务的基础搭建…...

介绍 YugabyteDB MCP Server
介绍 YugabyteDB MCP Server Sfurti Sarah June 10, 2025 概述 YugabyteDB MCP Server 是一个全新的、轻量级的、基于 Python 的服务器,它允许像 Anthropic’s Claude 这样的大语言模型(Large Language Model, LLM)直接与你的 YugabyteDB…...

FPGA图像处理避坑指南:实现CLAHE时,你的直方图统计与插值模块可能踩的这些雷
FPGA图像处理避坑指南:CLAHE实现中的直方图统计与插值模块陷阱解析 第一次在FPGA上实现CLAHE算法时,我盯着屏幕上那些奇怪的边界伪影和忽明忽暗的色块,整整三天没想明白问题出在哪。直到把示波器接到开发板上,才发现直方图统计模块…...

Windows更新修复利器:Reset Windows Update Tool终极使用指南
Windows更新修复利器:Reset Windows Update Tool终极使用指南 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool Wind…...

基因组调查实战:KMC+GenomeScope2.0多倍体分析全流程解析
1. 为什么需要基因组调查? 当你第一次拿到一个未知物种的测序数据时,最头疼的问题往往是:这个基因组到底有多大?复杂度如何?该投入多少测序量才够用?这就好比装修房子前要先量尺寸,基因组调查就…...

恩雅吉他琴颈变形维修保养指南,正规维修机构实力评测
琴颈是吉他手感的 “灵魂”,恩雅吉他的琴颈采用了专属的 BT 接柄技术,搭配碳纤维加固钢筋,在出厂时就调试到了最佳的演奏状态。但日常存放中,温湿度剧变、长期不规范上弦、意外磕碰,都很容易导致琴颈变形,出…...

西门子1500博途医药系统程序案例:标准化编程实践
西门子1500博途医药系统程序案例。标准化编程! 具体为医药制品,及空调恒温恒湿,PID控制博图程序,带昆仑流程图,西门子1500PLC和昆仑通态触摸屏上位软件,博图版本V16及以上。 适合研究学习标准程序设计。在…...

 Matlab代码)
【独家原创】基于分位数回归PSO-QRLightGBM多变量时序预测-区间预测(多输入单输出) Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。👇 关注我领取海量matlab电子书和数学建模资料🍊个人信条:格物致知,完整Matl…...

SCH1633-D01 |Murata村田|汽车级|±300度的角速率六轴陀螺仪|惯性导航
SCH1633-D01 |Murata村田|汽车级|300度的角速率六轴陀螺仪|惯性导航用于汽车应用的六自由度XYZ轴陀螺仪和XYZ轴加速度计,带数字SPI接口SCH1633-D01SCH1600传感器系列通过冗余设计选项和内置可调双输出通道为资深客户提供更大的灵活性。●300/s的角速率测量范围●8g的…...

2025年中国市场SCA工具深度评测:国产化浪潮下的安全新选择
随着数字化转型进入深水区,软件供应链安全已成为企业不可忽视的战略要地。2025年,在信创政策持续深化与国产化替代加速的双重背景下,软件成分分析(SCA)工具作为DevSecOps体系中的关键一环,正迎来前所未有的市场机遇与挑战。这场由…...