Python PDF文本处理技巧 - 查找和高亮文字
目录
使用工具
Python在PDF中查找和高亮文字并统计出现次数和页码
Python在PDF的特定页面区域中查找和高亮文字
Python使用正则表达式在PDF中查找和高亮文字
Python在PDF中查找文字并获取它的坐标位置
其他查找条件设置
在日常工作和学习中,我们常常需要处理各种PDF文件。其中对文字内容进行查找和高亮是非常常见的需求。以工作场景为例,我们可能需要快速检索一份长篇报告中的关键信息。利用PDF的查找功能,我们能够迅速定位到相关内容,大幅提高工作效率。同时,通过高亮标注重要信息,我们能够方便地进行日后复习和回顾。这篇博客将探讨如何使用Python实现在PDF中查找和高亮文字,主要涵盖以下内容:
- Python在PDF中查找和高亮文字并统计出现次数和页码
- Python在PDF的特定页面区域中查找和高亮文字
- Python使用正则表达式在PDF中查找和高亮文字
- Python在PDF中查找文字并获取它的坐标位置
- 其他查找条件设置
使用工具
要在Python应用程序中查找和高亮PDF中的文字,可以使用Spire.PDF for Python库。它支持在Python应用程序中创建、读取、操作和转换PDF文档。
你可以通过在终端运行以下命令来从PyPI安装Spire.PDF for Python:
pip install Spire.PDFPython在PDF中查找和高亮文字并统计出现次数和页码
Spire.PDF for Python提供了PdfTextFinder类,用于查找PDF页面上的文字。使用该类的Find() 方法,你可以搜索特定的文字或句子。找到后,你可以为其设置高亮颜色,同时还能获取该文字在PDF文档中出现的次数以及所在的页码信息。
下面是在PDF中查找和高亮文字的具体步骤:
- 创建PdfDocument类的实例并使用PdfDocument.LoadFromFile()加载PDF文档。
- 初始化一个计数器来跟踪文本出现的次数以及一个列表来存储文本出现的页码。
- 遍历PDF中的页面。
- 为每个页面创建一个PdfTextFinder实例并将当前页面对象作为参数传入该类的构造函数。
- 使用PdfTextFinder.Find()方法查找特定文本。该方法将返回一个PdfTextFragment对象列表,其中每个对象代表该文本在文档中的一个实例。
- 遍历列表中的PdfTextFragment对象,使用PdfTextFragment.Highlight()方法高亮每个实例,同时递增文本出现的次数并将当前页码添加到列表。
- 使用PdfDocument.SaveToFile()方法保存结果文档。
- 打印文本在PDF中出现的次数和页码。
下面是在PDF中查找和高亮文字的Python代码:
from spire.pdf.common import *
from spire.pdf import *# 创建 PdfDocument 类的对象
doc = PdfDocument()
# 加载 PDF 文件
doc.LoadFromFile("什么是python.pdf")# 初始化一个计数器来跟踪文本出现的次数
occurrence_count = 0
# 初始化一个列表来存储页码
page_numbers = []# 遍历文档中的页面
for i in range(doc.Pages.Count):page = doc.Pages[i]# 创建 PdfTextFinder 实例finder = PdfTextFinder(page)# 查找特定文本results = finder.Find("Python")# 遍历找到的所有实例for text in results:# 设置高亮颜色text.HighLight(Color.get_Yellow())# 递增文本出现次数occurrence_count += 1# 将页码添加到列表中page_numbers.append(i+1)# 保存结果文档
doc.SaveToFile("查找和高亮文本.pdf")
doc.Close()# 打印出现次数和页码
print(f"文本 'Python' 在 PDF 中出现了 {occurrence_count} 次。")
print(f"该文本出现在以下页码: {', '.join(map(str, page_numbers))}")

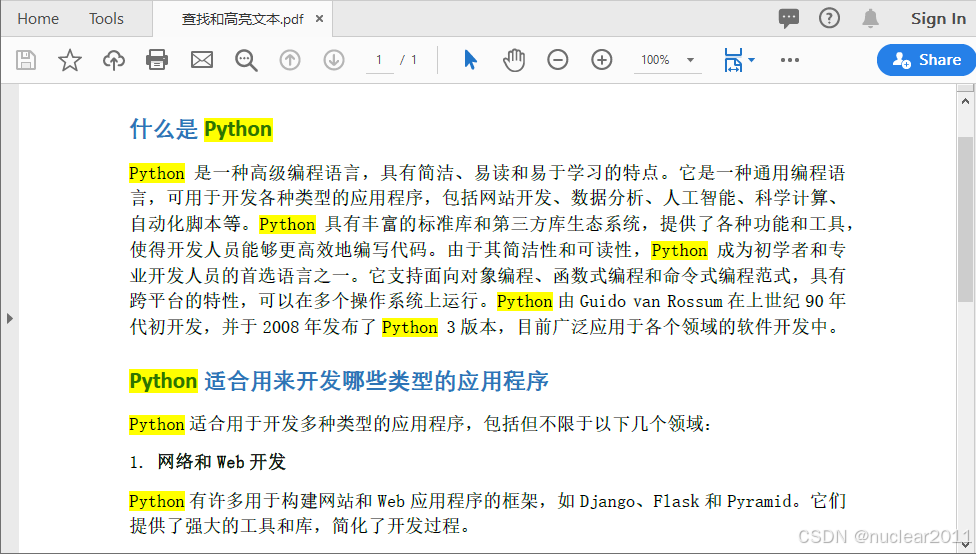
Python在PDF的特定页面区域中查找和高亮文字
除了在PDF文档的所有页面或特定页面中查找和高亮文字(见以上例子)以外,你还可以在特定的页面区域中查找和高亮文字。使用PdfTextFinder.Options.Area属性,你可以指定查找的页面区域。
下面是在PDF的特定页面区域中查找和高亮文字的具体步骤:
- 创建PdfDocument类的实例并使用PdfDocument.LoadFromFile()加载PDF文档。
- 遍历PDF中的页面。
- 为每个页面创建一个PdfTextFinder实例并将当前页面对象作为参数传入该类的构造函数。
- 通过PdfTextFinder.Options.Area属性指定查找的页面区域。
- 使用PdfTextFinder.Find()方法查找特定文本。
- 使用PdfTextFragment.Highlight()方法高亮每个找到的实例。
- 使用PdfDocument.SaveToFile()方法保存结果文档。
下面是在PDF的特定页面区域中查找和高亮文字的Python代码:
from spire.pdf.common import *
from spire.pdf import *# 创建 PdfDocument 类的对象
doc = PdfDocument()
# 加载 PDF 文件
doc.LoadFromFile("什么是python.pdf")# 遍历文档中的页面
for i in range(doc.Pages.Count):page = doc.Pages[i]# 创建 PdfTextFinder 实例finder = PdfTextFinder(page)# 指定查找的页面区域finder.Options.Area = RectangleF(0.0, 0.0, 300.0, 300.0)# 查找特定文本results = finder.Find("Python")# 遍历找到的所有实例for text in results:# 设置高亮颜色text.HighLight(Color.get_Yellow())# 保存结果文档
doc.SaveToFile("在页面区域中查找和高亮文本.pdf")
doc.Close()
Python使用正则表达式在PDF中查找和高亮文字
要在PDF中使用正则表达式查找和高亮文字,你首先需要将PdfTextFinder.Options.Parameter属性设置为TextFindParameter.Regex,以启用正则表达式查找。然后,你需要将正则表达式作为参数传递给Find()方法来实现基于正则表达式查找文字。
下面是使用正则表达式在PDF中查找和高亮文字的具体步骤:
- 创建PdfDocument类的实例并使用PdfDocument.LoadFromFile()加载PDF文档。
- 遍历PDF中的页面。
- 为每个页面创建一个PdfTextFinder实例并将当前页面对象作为参数传入该类的构造函数。
- 将PdfTextFinder.Options.Parameter属性设置为TextFindParameter.Regex以启用正则表达式文本查找模式。
- 将正则表达式传递给PdfTextFinder.Find()方法来实现基于正则表达式查找特定文本。
- 使用PdfTextFragment.Highlight()方法高亮每个匹配到的实例。
- 使用PdfDocument.SaveToFile()方法保存结果文档。
下面是使用正则表达式在PDF中查找和高亮文字的Python代码:
from spire.pdf.common import *
from spire.pdf import *# 创建 PdfDocument 类的对象
doc = PdfDocument()
# 加载 PDF 文件
doc.LoadFromFile("示例.pdf")# 遍历文档中的页面
for i in range(doc.Pages.Count):page = doc.Pages[i]# 创建 PdfTextFinder 实例finder = PdfTextFinder(page)# 设置文本查找条件为使用正则表达式查找finder.Options.Parameter = TextFindParameter.Regex# 查找以符号 “#” 开头的文本results = finder.Find("""\\#\\w+\\b""")# 遍历找到的所有实例for text in results:# 设置高亮颜色text.HighLight(Color.get_Yellow())# 保存结果文档
doc.SaveToFile("使用正则表达式查找和高亮文本.pdf")
doc.Close()
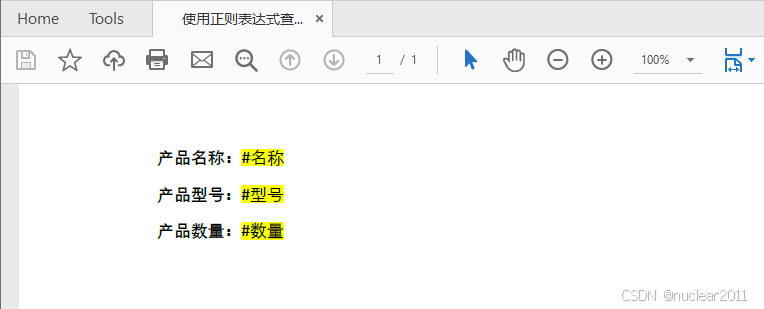
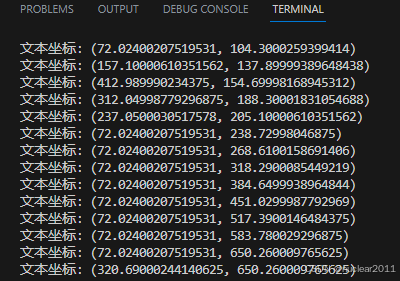
Python在PDF中查找文字并获取它的坐标位置
在找到特定的文字后,你还可以获取它的相关信息,例如它的坐标位置。下面是在PDF中查找文字并获取它的坐标信息的具体步骤:
- 创建PdfDocument类的实例并使用PdfDocument.LoadFromFile()加载PDF文档。
- 遍历PDF中的页面。
- 为每个页面创建一个PdfTextFinder实例并将当前页面对象作为参数传入该类的构造函数。
- 使用PdfTextFinder.Find()方法查找特定文本。
- 使用PdfTextFragment.Positions[0].X和PdfTextFragment.Positions[0].Y属性获取每个找到的实例的X和Y坐标。
下面是在PDF中查找文字并获取它的坐标位置的Python代码:
from spire.pdf.common import *
from spire.pdf import *# 创建 PdfDocument 类的对象
doc = PdfDocument()
# 加载 PDF 文件
doc.LoadFromFile("什么是python.pdf")# 遍历文档中的页面
for i in range(doc.Pages.Count):page = doc.Pages[i]# 创建 PdfTextFinder 实例finder = PdfTextFinder(page)# 查找特定文本results = finder.Find("Python")# 遍历找到的所有实例for text in results:# 打印当前实例的坐标信息print(f"文本坐标: ({text.Positions[0].X}, {text.Positions[0].Y})") doc.Close()
其他查找条件设置
Spire.PDF for Python还支持设置其他查找条件,如不区分大小写或全词匹配。具体代码如下:
from spire.pdf.common import *
from spire.pdf import *# 创建 PdfDocument 类的对象
doc = PdfDocument()
# 加载 PDF 文件
doc.LoadFromFile("什么是python.pdf")# 遍历文档中的页面
for i in range(doc.Pages.Count):page = doc.Pages[i]# 创建 PdfTextFinder 实例finder = PdfTextFinder(page)# 设置文本查找条件为不区分大小写和全词匹配finder.Options.Parameter = TextFindParameter.IgnoreCasefinder.Options.Parameter = TextFindParameter.WholeWord# 查找特定文本results = finder.Find("Python")# 遍历找到的所有实例for text in results:# 设置高亮颜色text.HighLight(Color.get_Yellow())# 保存结果文档
doc.SaveToFile("其他查找条件.pdf")
doc.Close()
这篇文章介绍了使用Python在PDF中查找和高亮文字的多种不同的场景,你需要根据自己的实际情况对代码中的文档路径、待查找的文字、页面区域、或正则表达式等内容进行相应的修改。
本文完结。
相关文章:
Python PDF文本处理技巧 - 查找和高亮文字
目录 使用工具 Python在PDF中查找和高亮文字并统计出现次数和页码 Python在PDF的特定页面区域中查找和高亮文字 Python使用正则表达式在PDF中查找和高亮文字 Python在PDF中查找文字并获取它的坐标位置 其他查找条件设置 在日常工作和学习中,我们常常需要处理各…...

虚幻引擎 C++ 实现平面阴影
1、平面阴影介绍 平面阴影是一种相对简单的渲染阴影的方式,可以理解为对一个模型渲染两次,一次是渲染模型本身,另一次是渲染模型的投影。渲染投影可以看作是将模型的顶点变换到地面的投影空间再渲染,可以理解为渲染了一个“压扁”…...

leetcode 67. 二进制求和
二进制求和 已解答 简单 相关标签 相关企业 给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 示例 1: 输入:a “11”, b “1” 输出:“100” 示例 2: 输入:a “1010”, b “1011” 输出&…...
)
【C++ 面试 - 基础题】每日 3 题(一)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/fYaBd 📚专栏简介:在这个专栏中,我将会分享 C 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏&…...

【动态规划】1、不同路径II+2、三角形最小路径和
1、不同路径II(难度中等) 该题对应力扣网址 AC代码 只会写简单的if-else class Solution { public:int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {//1、定义子问题//2、子问题递推关系//3、确定dp数组的计算顺序…...

JavaEE-多线程编程单例模式
一、等待通知 系统内部,线程之间是抢占式执行的,随即调度,程序可以通过手动干预的方式,能够让线程一定程度的按咱们想要的顺序执行,无法主动让某个线程被调度,但可以主动让某个线程等待。等待通知可以安排…...

RHCA III之路---EX436-6
RHCA III之路---EX436-6 1. 题目2. 解题3. 确认 1. 题目 2. 解题 三台node分别运行 yum install -y device-mapper-multipath mpathconf --enable systemctl enable --now multipathd3. 确认 fdisk -l...

Vuex模块化 深入浅出超详细
Vuex 模块化 为什么需要模块化? 随着项目规模的增长,单一的 store 文件会变得庞大且难以管理; Vuex 的模块化是一种组织和管理应用状态的策略:,它允许将全局的状态管理分解成更小、更可管理的部分; 逻辑清…...
 的实现方法)
细说MCU检测按键输入的外部中断和修改HAL_GPIO_EXTI_IRQHandler() 的实现方法
目录 一、 硬件板及设计目的 二、建立工程 1.配置GPIO 2.配置时钟源和Debug 3.配置系统时钟 4.配置NVIC 三、代码编写 四、修改HAL_GPIO_EXTI_IRQHandler() 一、 硬件板及设计目的 本文使用的硬件板是ST的开发板NUCLEO-G474RE,板上MCU型号为ST…...

昂科烧录器支持XHSC小华半导体的32位微控制器HC32F005C6P
芯片烧录行业领导者-昂科技术近日发布最新的烧录软件更新及新增支持的芯片型号列表,其中XHSC小华半导体的32位微控制器HC32F005C6P已经被昂科的通用烧录平台AP8000所支持。 HC32F005C6P是Low Pin Count、宽电压工作范围的MCU,集成12位1Msps高精度SARADC…...

根据 IP 地址配置子网示例(下挂 hub 接不同 vlan 终端)
我们一般根据端口配置子网比较简单,但是如果换接口,就又要到交换机上重新配置端口所属 vlan 了,紧急情况下,还是比较耽误时间的。但如果根据IP地址配置 vlan,则可以插在交换机上任意端口,排障时比较节省时间…...

Flink-DataWorks第四部分:数据同步(第60天)
系列文章目录 2.4.2 DataStudio侧实时同步 2.4.3 数据集成侧同步任务 文章目录 系列文章目录前言2.4.2 DataStudio侧实时同步2.4.3 数据集成侧同步任务 前言 本文主要详解了DataWorks的数据同步,为第四部分: 由于篇幅过长,分章节进行发布。…...

go post请求,参数是raw json格式,response是固定结构。
在Go语言中,使用net/http包可以很方便地发送HTTP请求,包括POST请求。当需要发送raw JSON格式的参数时,通常会使用encoding/json包来将Go的结构体序列化为JSON字符串,然后使用http.NewRequest函数创建请求,并通过http.C…...
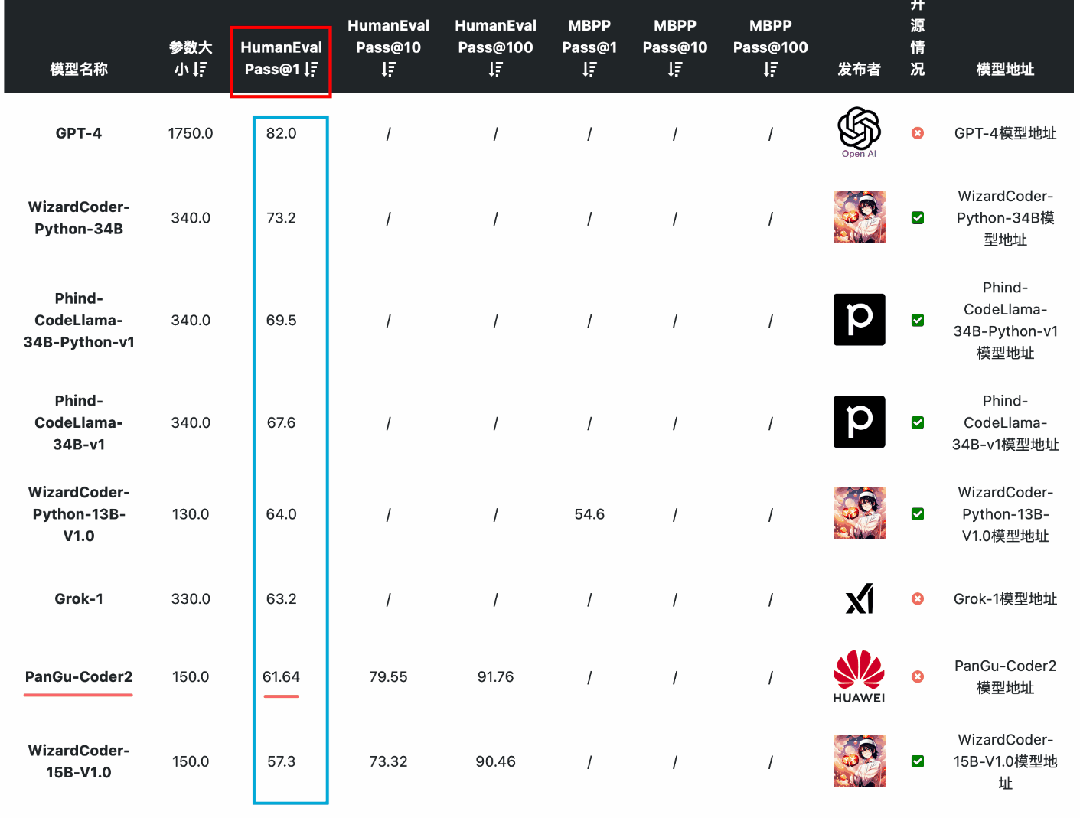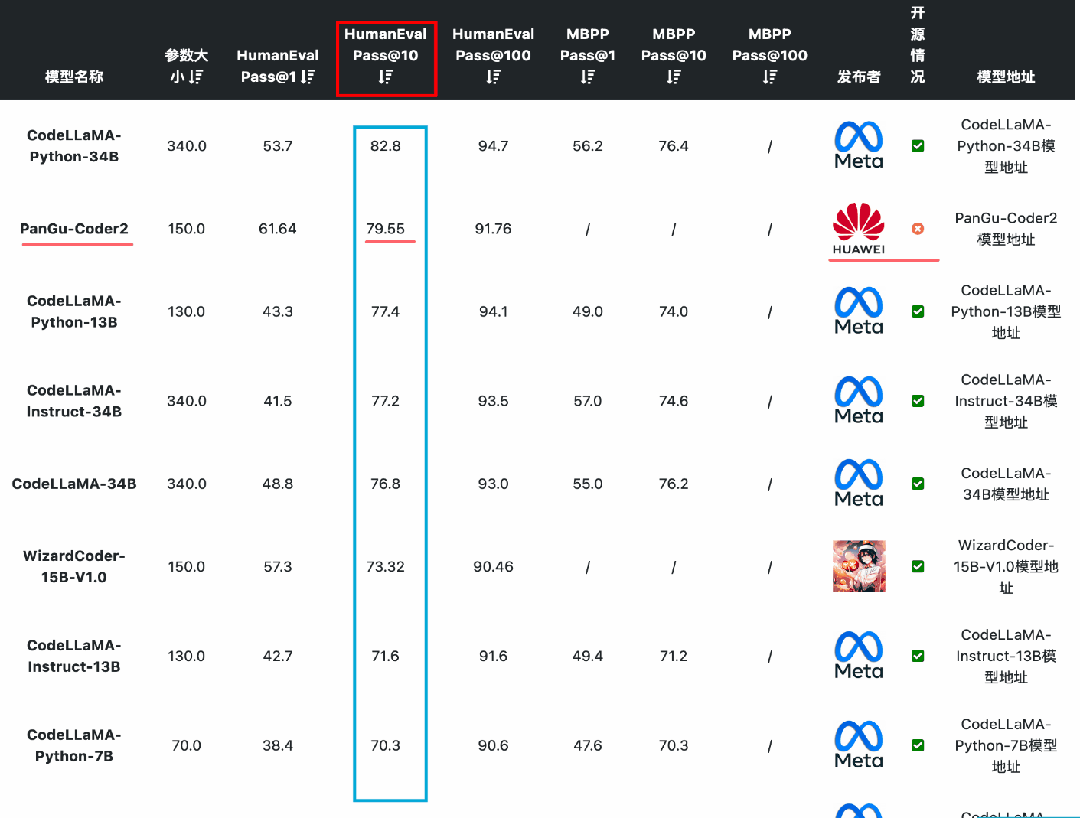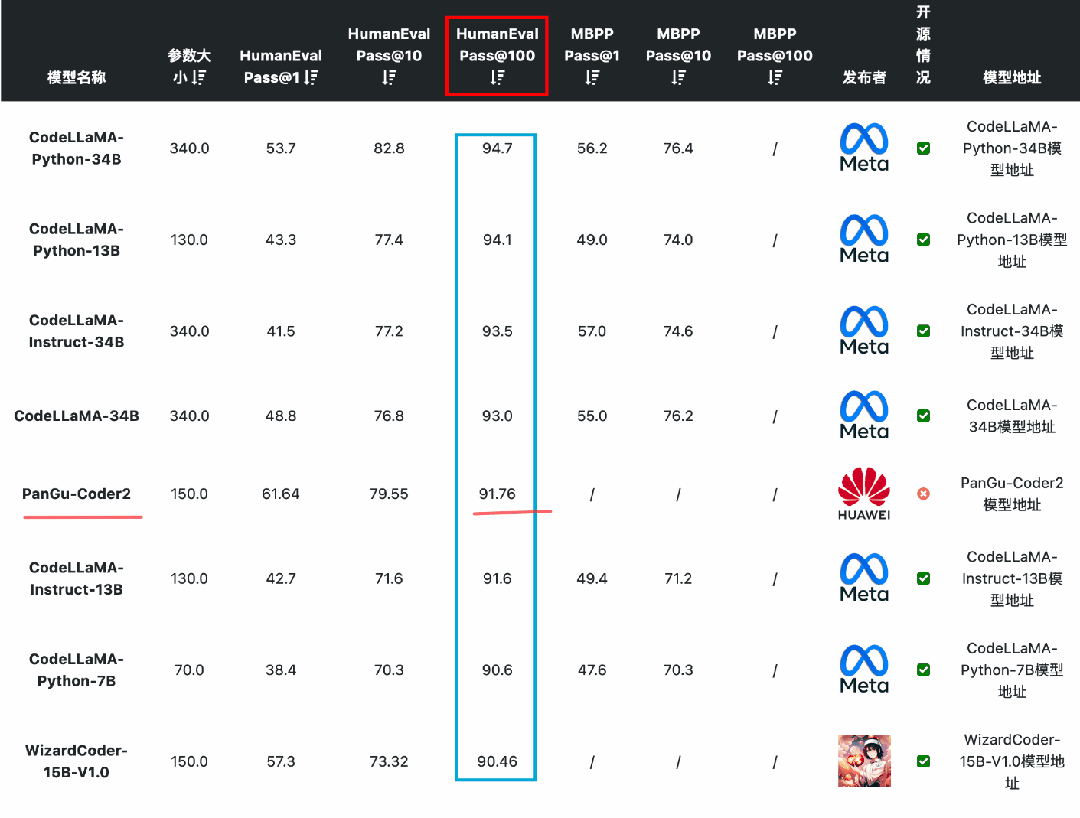
国产开源大模型都有哪些?
随着ChatGPT引领的大模型热潮,国内的公司开始相继投入研发自己的人工智能大模型,截止到2023年10月,国产公司的大模型有近百个,包括一些通用大模型,比如百度的文心一言,也有特定领域的专用大模型,…...

基于Hadoop的超市进货推荐系统设计与实现【springboot案例项目】
文章目录 有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主项目介绍系统分析系统设计数据表设计表4-1:关于我们表4-2:用户表4-3:管理员表表4-4:token表表4-5:系统简介表4-6:收藏…...

ChatGPT能从这几个方面提升学术论文质量
学境思源,一键生成论文初稿: AcademicIdeas - 学境思源AI论文写作 写作和编辑高质量的学术论文是一项具有挑战性的任务。随着人工智能技术的进步,ChatGPT作为一种强大的语言生成工具,正逐渐成为提升论文质量的得力助手。从头脑风…...

Python3的安装及基础指令
Day 20 基础语法 1、环境:python2内置,安装并使用python3,最新版3.12版可以使用源码安装 # 查看python版本号 [rootpython ~]#yum list installed|grep python [rootpython ~]#yum list installed|grep epel [rootpython ~]# yum -y …...

使用Spring与JDK动态代理实现事务管理
使用Spring与JDK动态代理实现事务管理 在现代企业级应用开发中,事务管理是一项关键的技术,它可以保证一系列操作要么全部成功,要么全部失败,从而确保数据的一致性和完整性。Spring框架提供了强大的事务管理能力,但有时…...

服务器硬件及RAID配置
服务器及 RAID 磁盘阵列介绍 RAID0 俗称 “ 条带 ” ,它将两个或多个硬盘组成一个逻辑硬盘,容量是所有硬盘之和,因 为是多个硬盘组合成一个,故可并行写操作,写入速度提高,但此方式硬盘数据没有冗余&#…...
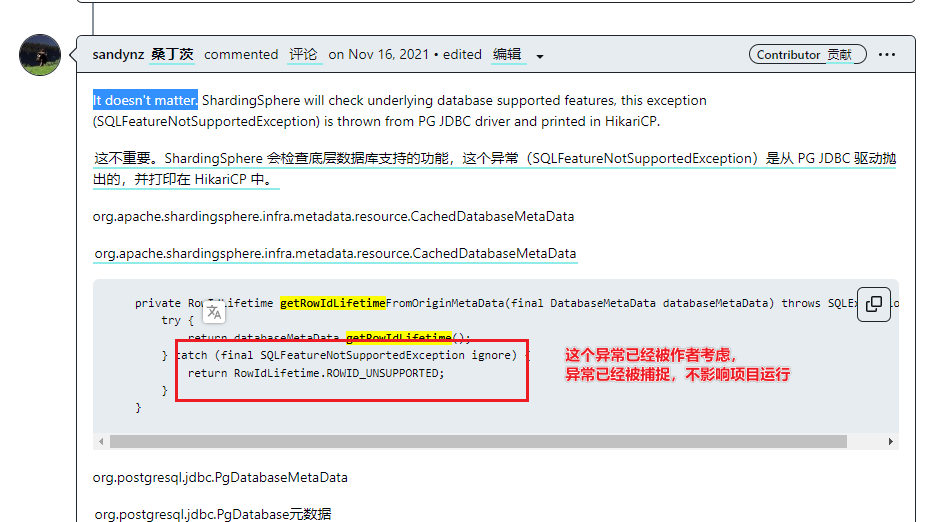
【经验总结】ShardingSphere5.2.1 + Springboot 快速开始
Sharding Sphere 官方文档地址: https://shardingsphere.apache.org/document/current/cn/overview/maven仓库:https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc 官方的文档写的很详尽到位,这里会截取部分…...

模板号:每一家创业公司都应该有企业官网
模板号(mobanhao.com):让每一家创业公司都能轻松拥有专业官网品牌定位:专注WordPress模板建站,服务创业型企业的数字化伙伴模板号(mobanhao.com)是一家专注于WordPress模板网站搭建的专业服务机构,总部位于中国改革开放的前沿阵地…...

3个步骤实现Windows直接运行安卓应用:开发者与玩家的跨平台解决方案
3个步骤实现Windows直接运行安卓应用:开发者与玩家的跨平台解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为手机应用无法在电脑上运行而困扰…...

在WSL2上搞定PyTorch模型转昇腾OM:我的Atlas 200DK部署踩坑实录
在WSL2上实现PyTorch模型到昇腾OM的高效转换:避坑指南与实战解析 对于希望在Windows环境下完成昇腾模型转换的开发者来说,WSL2提供了一个近乎完美的解决方案。本文将深入探讨如何在这一环境中高效完成从PyTorch到昇腾OM模型的完整转换流程,同…...

终极JSONPlaceholder版本演进指南:从0.1.0到0.3.3的完整解析
终极JSONPlaceholder版本演进指南:从0.1.0到0.3.3的完整解析 【免费下载链接】jsonplaceholder A simple online fake REST API server 项目地址: https://gitcode.com/gh_mirrors/js/jsonplaceholder JSONPlaceholder是一款简单易用的在线假REST API服务器&…...

SpringBoot项目结构深度解析:为什么你的Controller总报404?这些目录规范必须掌握
SpringBoot项目结构深度解析:为什么你的Controller总报404?这些目录规范必须掌握 在企业级SpringBoot开发中,目录结构看似简单却暗藏玄机。我曾见过团队因为一个包名大小写问题排查三天,也遇到过新人将Controller放在resources目录…...

Mac环境OpenClaw深度配置:Qwen3-14B镜像多模型切换技巧
Mac环境OpenClaw深度配置:Qwen3-14B镜像多模型切换技巧 1. 为什么需要多模型切换? 去年冬天,当我第一次尝试用OpenClaw自动化处理团队周报时,遇到了一个典型问题:同样的模型配置在处理"数据分析"和"文…...

MySQL数据库备份实战:全量、增量、差异备份到底怎么选?
MySQL数据库备份实战:全量、增量、差异备份到底怎么选? 作为数据库管理员,每天最担心的莫过于数据丢失。记得去年我们团队遇到过一次硬盘故障,当时如果没有完善的备份策略,后果不堪设想。选择正确的备份方式不仅关系到…...

Swagger Client 性能优化:10个技巧让你的 API 调用快如闪电
Swagger Client 性能优化:10个技巧让你的 API 调用快如闪电 【免费下载链接】swagger-js Javascript library to connect to swagger-enabled APIs via browser or nodejs 项目地址: https://gitcode.com/gh_mirrors/sw/swagger-js Swagger Client 是一款强大…...

零基础玩转Qwen3-TTS:手把手教你搭建个人语音工作室
零基础玩转Qwen3-TTS:手把手教你搭建个人语音工作室 1. 为什么选择Qwen3-TTS搭建语音工作室 语音合成技术已经从实验室走向大众生活,但大多数工具要么操作复杂,要么效果不尽如人意。Qwen3-TTS-12Hz-1.7B-Base的出现改变了这一局面ÿ…...

效率提升:用快马AI自动生成技能创建器的核心判断逻辑代码
最近在开发一个技能创建器时,遇到了一个很常见的痛点:每次新增技能都要手动编写大量重复的条件判断逻辑。这种机械劳动不仅耗时,还容易出错。经过一番摸索,我发现用InsCode(快马)平台的AI辅助功能可以完美解决这个问题。 问题分析…...