Springboot集成Proguard生成混淆jar包
背景
当我们需要将 JAR 包交付给第三方时,常常担心代码可能会被反编译。因此,对 JAR 包进行混淆处理显得尤为重要。
市面上有许多 JAR 包源码混淆工具,但真正能稳定投入使用的并不多。例如,ClassFinal (ClassFinal: Java字节码加密工具)`是国内开发者开发的一款 JAR 包加密工具,它采用的是字节码加密的方案。然而,ClassFinal (ClassFinal: Java字节码加密工具)已经停止维护多年,并且它的使用需要额外提供一个加密包来解密,这种方式虽然注重安全性,但增加了使用的复杂性。由于 JVM 的跨平台特性,理想的工具应该是简洁、易于使用的,而不是增加额外的“挂件”来进行保护。
另一款常用的工具是 ProGuard(GitHub - Guardsquare/proguard: ProGuard, Java optimizer and obfuscator),它是一款开源的 Java 代码混淆工具。准确来说是一个插件,不需要对他进行编码,只需要进行配置即可。代码混淆,并不是把所有代码进行混淆,这样反而会出错,比如枚举类型如果也进行混淆,那么在使用反射创建实例,并给实例赋值的时候,枚举类型会反序列化失败。ProGuard 的主要功能是在不影响程序功能的前提下,混淆 JAR 包内的源码,通过增加代码的混乱程度,使得反编译后的代码可读性大大降低,从而有效地提高了代码的安全性。对于第三方来说,反编译后的代码难以理解,与其花费大量时间研究,可能更倾向于重新开发实现。因此,从这个角度来看,ProGuard 确实可以满足一定的代码安全性需求。proguard提供了可以对哪些包,类,方法等不进行混淆的配置,我们可以将枚举配置在这里。
然而,需要注意的是,ProGuard 是一款通用的 Java 代码混淆工具,并非针对 Spring 框架的专用工具。因此,它对 Spring 相关的注解并没有特殊的处理。这意味着在使用 ProGuard 混淆 Spring Boot 应用时,开发者可能需要进行额外的配置和定制,这对不熟悉该工具的开发者来说增加了使用难度和成本。
实现流程
springboot提供了打包插件spring-boot-maven-plugin,所以我们的混淆需要在springboot打包的插件之前,就是我们要对混淆之后的代码通过spring-boot-maven-plugin进行打包。
Proguard核心内容是两个配置文件,一个pom.xml、一个proguard.cfg,这里提供最关键的两个能够直接使用的配置文件内容,其余的配置相关描述可以通过文末的参考文献获取。
proguard.cfg配置示例
# 指定不警告尚未解决的引用和其他问题
-dontwarn
#指定Java的版本
-target 1.8
#proguard会对代码进行优化压缩,他会删除从未使用的类或者类成员变量等(删除注释、未被引用代码)
-dontshrink
#是否关闭字节码级别的优化,如果不开启则设置如下配置 不做优化(变更代码实现逻辑)
-dontoptimize
#混淆时不生成大小写混合的类名,默认是可以大小写混合
-dontusemixedcaseclassnames
# 不去忽略非公共的库类
-dontskipnonpubliclibraryclasses
# 指定不跳过包可见的库类成员(字段和方法)。
# 默认情况下,proguard在解析库类时会跳过包可见的库类成员。当我们确实引用了包可见的类成员时,需要设置此项
-dontskipnonpubliclibraryclassmembers
# 对于类成员的命名的混淆采取唯一策略
-useuniqueclassmembernames
# 优化时允许访问并修改有修饰符的类和类的成员
-allowaccessmodificatio
# 不混淆所有包名
#-keeppackagename
#混淆类名之后,对使用Class.forName('className')之类的地方进行相应替代
-adaptclassstrings
#保持目录结构
-keepdirectories
#对异常、注解信息予以保留
-keepattributes Exceptions,InnerClasses,Signature,Deprecated,SourceFile,LineNumberTable,*Annotation*,EnclosingMethod,Qualifier
# 此选项将保存接口中的所有原始名称(不混淆)-->
#-keepnames interface ** { *; }#混淆时是否记录日志
#-verbose# 此选项将保存所有软件包中的所有原始接口文件(不进行混淆)
#-keep interface * extends * { *; }#保留参数名,因为控制器,或者Mybatis等接口的参数如果混淆会导致无法接受参数,xml文件找不到参数
-keepparameternames
# 保留枚举成员及方法
#-keepclassmembers enum * { *; }
# 不混淆所有类,保存原始定义的注释-
-keepclassmembers class * {@org.springframework.context.annotation.Bean *;@org.springframework.context.annotation.Bean *;@org.springframework.beans.factory.annotation.Autowired *;@org.springframework.beans.factory.annotation.Value *;@org.springframework.stereotype.Service *;@org.springframework.stereotype.Component *;@org.springframework.transaction.annotation.ProxyTransactionManagementConfiguration *;@org.springframework.boot.context.properties.ConfigurationProperties *;@org.springframework.web.bind.annotation.RestController *;@org.springframework.beans.factory.annotation.Qualifier *;@io.swagger.annotations.ApiParam *;@org.springframework.validation.annotation.Validated *;@io.swagger.annotations.ApiModelProperty *;@javax.validation.constraints.NotNull *;@javax.validation.constraints.Size *;@javax.validation.constraints.NotBlank *;@javax.validation.constraints.Pattern *;}
-keep class org.springframework.** {*;}
-keep public class ch.qos.logback.**{*;}
-keep class com.fasterxml.jackson.** { *; }#忽略warn消息
-ignorewarnings
#打印配置信息
-printconfiguration#入口程序类不能混淆,混淆会导致springboot启动不了
-keep public class com.zhubayi.proguarddemo.ProguardDemoApplication { *;}#mybatis的mapper/实体类不混淆,否则会导致xml配置的mapper找不到 ( 保持该目录下所有类及其成员不被混淆)
#-keep class com.zhubayi.proguarddemo.mapper.** {*;}# 实体类,枚举方法不能混淆
#-keep class com.zhubayi.proguarddemo.enums.** {*;}
-keep class com.zhubayi.proguarddemo.entity.** {*;}
#controller不进行混淆
-keep class com.zhubayi.proguarddemo.controller.** {*;}# 保留特定框架或库的类,注解类
#-keep class com.zhubayi.proguarddemo.elasticsearch.** { *; }
#-keep class com.zhubayi.proguarddemo.annotation.** {*;}#还有一些配置类和Bean不能混淆 比如logPointCut prefix 这些 @Pointcut @ConfigurationProperties(prefix = "redisson")
#-keep class com.zhubayi.proguarddemo.aspectj.** {*;}# 全放开
#-keep class com.ugdsec.** {*;}
#保留Serializable序列化的类不被混淆
# controller 层映射前台参数的类、后端返回的 bean 属性类等,不能混淆类的成员属性(如变成 string a;)
-keepclassmembers class * implements java.io.Serializable {*;}# 不混淆所有的set/get方法
#-keepclassmembers public class * {void set*(***);*** get*();}pom.xml配置示例 (注意:它必须要放到spring-boot-maven-plugin上面)
<build><plugins><plugin><groupId>com.github.wvengen</groupId><artifactId>proguard-maven-plugin</artifactId><version>2.6.0</version><executions><!-- 以下配置说明执行mvn的package命令时候,会执行proguard--><execution><phase>package</phase><goals><goal>proguard</goal></goals></execution></executions><configuration><!-- 是否混淆 默认是true --><obfuscate>true</obfuscate><!-- 防止本地编译的时候路径太长编译失败--><putLibraryJarsInTempDir>true</putLibraryJarsInTempDir><!-- 就是输入Jar的名称,我们要知道,代码混淆其实是将一个原始的jar,生成一个混淆后的jar,那么就会有输入输出。 --><injar>${project.build.finalName}.jar</injar><!-- 输出jar名称,输入输出jar同名的时候就是覆盖,也是比较常用的配置。 --><outjar>${project.build.finalName}.jar</outjar><!-- 配置一个文件,通常叫做proguard.cfg,该文件主要是配置options选项,也就是说使用proguard.cfg那么options下的所有内容都可以移到proguard.cfg中 --><proguardInclude>${project.basedir}/proguard.cfg</proguardInclude><!-- 额外的jar包,通常是项目编译所需要的jar --><libs><lib>${java.home}/lib/rt.jar</lib><lib>${java.home}/lib/jce.jar</lib><lib>${java.home}/lib/jsse.jar</lib></libs><!-- 对输入jar进行过滤比如,如下配置就是对META-INFO文件不处理。 --><!-- <inLibsFilter>!META-INF/**,!META-INF/versions/9/**.class</inLibsFilter>--><!-- 这是输出路径配置,但是要注意这个路径必须要包括injar标签填写的jar --><outputDirectory>${project.basedir}/target</outputDirectory><!--这里特别重要,此处主要是配置混淆的一些细节选项,比如哪些类不需要混淆,哪些需要混淆--><options><!-- 可以在这里写option标签配置,不过我上面使用了proguardInclude,所以可以在proguard.cfg中配置 --><!--JDK8--><!--<option>-target 1.8</option>--><!-- 不做收缩(删除注释、未被引用代码)--><!--<option>-dontshrink</option>--><!-- 不做优化(变更代码实现逻辑)--><!--<option>-dontoptimize</option>--><!-- 不路过非公用类文件及成员--><!--<option>-dontskipnonpubliclibraryclasses</option>--><!--<option>-dontskipnonpubliclibraryclassmembers</option>--><!--不用大小写混合类名机制--><!--<option>-dontusemixedcaseclassnames</option>--></options><!--子模块--><assembly><inclusions><!--<inclusion>--><!-- <groupId>com.zhubayi</groupId>--><!-- <artifactId>chen-system</artifactId>--><!--</inclusion>--></inclusions></assembly></configuration><dependencies><dependency><groupId>com.guardsquare</groupId><artifactId>proguard-base</artifactId><version>7.1.1</version><scope>runtime</scope></dependency><!--<dependency>--><!-- <groupId>com.guardsquare</groupId>--><!-- <artifactId>proguard-core</artifactId>--><!-- <version>7.1.1</version>--><!-- <scope>runtime</scope>--><!--</dependency>--></dependencies></plugin><!-- proguard 代码混淆配置 结束--><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><!-- 如果没有该配置,devtools不会生效 --><fork>true</fork><mainClass>com.zhubayi.proguarddemo.ProguardDemoApplication</mainClass><!--<excludeGroupIds>com.zhubayi</excludeGroupIds>--></configuration><executions><execution><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build>
注意:
<proguardInclude>${project.basedir}/proguard.cfg</proguardInclude>
${project.basedir}/proguard.cfg表示当前项目的根目录,所以需要把proguard.cfg放在当前项目的根目录
然后进行打包

打包之后会多出三个文件

<!-- 就是输入Jar的名称,我们要知道,代码混淆其实是将一个原始的jar,生成一个混淆后的jar,那么就会有输入输出。 -->
<injar>${project.build.finalName}.jar</injar><!-- 输出jar名称,输入输出jar同名的时候就是覆盖,也是比较常用的配置。 -->
<outjar>${project.build.finalName}.jar</outjar>
从pom打包配置可以得到,proguard-demo-0.0.1-SNAPSHOT.jar,就是项目混淆后的jar包。
而proguard-demo-0.0.1-SNAPSHOT_proguard_base.jar就是正常的包,没有进行混淆。
反编译查看
下载反编译工具 jd-gui

打开然后选择刚刚的混淆jar包

这里面对springboot相关的都进行过过滤,所以剩下的都是和springboot无关的类, entity包、主启动类和controller包配置没有进行混淆,所以还是原来的名字,其他都进行了混淆,类名称都直接缩写成了小写字母a,b,c…
启动测试
D:\IdeaProjects\mytools\proguard-demo\target>java -jar proguard-demo-0.0.1-SNAPSHOT.jar. ____ _ __ _ _/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \\\/ ___)| |_)| | | | | || (_| | ) ) ) )' |____| .__|_| |_|_| |_\__, | / / / /=========|_|==============|___/=/_/_/_/:: Spring Boot :: (v2.3.12.RELEASE)2024-08-09 10:45:52.197 INFO 18600 --- [ main] c.z.p.ProguardDemoApplication : Starting ProguardDemoApplication v0.0.1-SNAPSHOT on zhubayi-computer with PID 18600 (D:\IdeaProjects\mytools\proguard-demo\target\proguard-demo-0.0.1-SNAPSHOT.jar started by zhubayi in D:\IdeaProjects\mytools\proguard-demo\target)
2024-08-09 10:45:52.199 INFO 18600 --- [ main] c.z.p.ProguardDemoApplication : No active profile set, falling back to default profiles: default
2024-08-09 10:45:53.664 INFO 18600 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
2024-08-09 10:45:53.674 INFO 18600 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2024-08-09 10:45:53.675 INFO 18600 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.46]
2024-08-09 10:45:53.730 INFO 18600 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2024-08-09 10:45:53.730 INFO 18600 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 1488 ms
2024-08-09 10:45:53.887 INFO 18600 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor'
2024-08-09 10:45:54.028 INFO 18600 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2024-08-09 10:45:54.035 INFO 18600 --- [ main] c.z.p.ProguardDemoApplication : Started ProguardDemoApplication in 2.143 seconds (JVM running for 2.561)
成功获取到了数据。
相关文章:
Springboot集成Proguard生成混淆jar包
背景 当我们需要将 JAR 包交付给第三方时,常常担心代码可能会被反编译。因此,对 JAR 包进行混淆处理显得尤为重要。 市面上有许多 JAR 包源码混淆工具,但真正能稳定投入使用的并不多。例如,ClassFinal (ClassFinal: Java字节码加…...

什么是NLP分词(Tokenization)
在自然语言处理和机器学习的领域里,咱们得聊聊一个超基础的技巧——就是“分词”啦。这个技巧啊,就是把一长串的文字切分成小块,让机器能更容易地“消化”。这些小块,不管大小,单个的字符也好,整个的单词也…...

基于深度学习的图像伪造检测
基于深度学习的图像伪造检测主要利用深度学习技术来识别和检测伪造的图像内容,尤其是在生成对抗网络(GAN)等技术发展的背景下,伪造图像的逼真程度大大提升。图像伪造检测在信息安全、隐私保护、司法鉴定等领域具有重要意义。以下是…...

Windows11 WSL2 Ubuntu编译安装perf工具
在Windows 11上通过WSL2安装并编译perf工具(Linux性能分析工具)可以按以下步骤进行。perf工具通常与Linux内核一起发布,因此你需要确保你的内核版本和perf版本匹配。以下是安装和编译perf的步骤: 1. 更新并升级系统 首先&#x…...

探索算法系列 - 前缀和算法
目录 一维前缀和(原题链接) 二维前缀和(原题链接) 寻找数组的中心下标(原题链接) 除自身以外数组的乘积(原题链接) 和为 K 的子数组(原题链接) 和可被 …...

Stable Diffusion绘画 | 提示词基础原理
提示词之间使用英文逗号“,”分割 例如:1girl,black long hair, sitting in office 提示词之间允许换行 但换行时,记得在结尾添加英文逗号“,”来进行区分 权重默认为1,越靠前权重越高 每个提示词自身的权重默认值为1,但越靠…...

利用python写一个可视化的界面
要利用Python编写一个可视化界面,你可以使用一些图形库来实现,例如Tkinter、PyQt、wxPython等。以下是一个使用Tkinter的示例代码: import tkinter as tk# 创建一个窗口对象 window tk.Tk()# 定义一个按钮点击事件的处理函数 def buttonCli…...

第13节课:Web Workers与通信——构建高效且实时的Web应用
目录 Web Workers简介Web Workers的基本概念创建和使用Web WorkersWeb Workers的应用场景 WebSocket通信WebSocket的基本概念创建和使用WebSocketWebSocket的应用场景 实践:使用Web Workers和WebSocket示例:使用Web Workers进行大数据集处理示例…...

pam_pwquality.so模块制定密码策略
目录 设置密码策略的方法pam_pwquality.so配置详解pam_pwquality.so默认密码规则pam_pwquality.so指定密码规则问题补充设置密码策略的方法 这篇文章重点讲通过pam_pwquality.so模块配置密码策略 指定pam_pwquality.so模块参数Centos7开始使用pam_pwquality模块进行密码复杂度…...
spark3.3.4 上使用 pyspark 跑 python 任务版本不一致问题解决
问题描述 在 spark 上跑 python 任务最常见的异常就是下面的版本不一致问题了: RuntimeError: Python in worker has different version 3.7 than that in driver 3.6, PySpark cannot run with different minor versions. Please check environment variables PY…...

处理Pandas中的JSON数据:从字符串到结构化分析
在数据科学领域,JSON作为一种灵活的数据交换格式,被广泛应用于存储和传输数据。然而,JSON数据的非结构化特性在进行数据分析时可能会带来一些挑战。本文将指导读者如何使用Pandas库将DataFrame中的JSON字符串列转换为结构化的表格数据&#x…...

国内的 Ai 大模型,有没有可以上传excel,完成数据分析的?
小说推文AI视频生成:小说文案智能分镜智能识别角色和场景批量Ai绘图自动配音添加音乐一键合成视频百万播放量https://aitools.jurilu.com/ 有啊!智谱清言、KiMI、豆包都可以做数分,在计算领域尤其推荐智谱清言,免费、快速还好使&a…...

Spring: jetcache
一、介绍 JetCache是一个基于Java的缓存系统封装,提供统一的API和注解来简化缓存的使用。 JetCache提供了比SpringCache更加强大的注解,可以原生的支持TTL(Time To Live,即缓存生存时间)、两级缓存、分布式自动…...
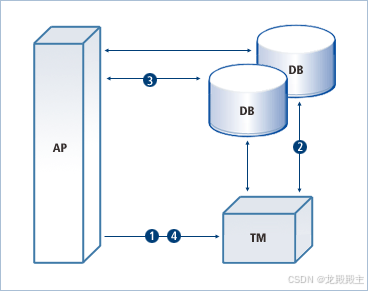
什么是分布式事务?
分布式事务跨越多个系统,确保所有操作一起成功或失败,这对于在现代计算环境中跨不同地理位置分离的资源维护数据完整性和一致性至关重要。 1. 为什么需要分布式事务? 分布式事务的需求源于确保分布式计算环境中多个独立系统或资源之间的数据…...

深入Java内存区域:堆栈、方法区与程序计数器的奥秘
引言 在Java开发过程中,合理地管理和利用内存资源对于提高程序的运行效率至关重要。特别是在大型项目或高并发场景下,一个小小的内存泄漏就可能导致整个系统崩溃。因此,掌握Java内存区域的相关知识,不仅能帮助我们更好地理解程序…...

【ML】异常检测、二分类问题
【ML】异常检测、二分类问题 1. 异常检测、二分类问题1.1 异常检测(Anomaly Detection)1.2 二分类问题(Binary Classification)1.3 异常检测与二分类问题的对比1.4 总结 2. 模型额训练与评估3. 为什么会出现比较高的误识别&#x…...

8.8-配置python3环境+python语法的使用
1.环境 python2 ,python3 [rootpython ~]# yum list installed|grep python [rootpython ~]# yum list installed|grep epel epel-release.noarch 7-11 extras #安装python3 [rootpython ~]# yum -y install python3…...

高质量WordPress下载站模板5play主题源码
5play下载站是由国外站长开发的一款WordPress主题,主题简约大方,为v1.8版本, 该主题模板中包含了上千个应用,登录后台以后只需要简单的三个步骤就可以轻松发布apk文章, 我们只需要在WordPress后台中导入该主题就可以…...

【C++】类的概念与基本使用介绍
C类是面向对象编程(OOP)的基础,它允许我们将数据(属性)和行为(方法)封装在一起,形成一个自定义的数据类型。以下是C类的基本概念、特点、特性以及使用注意事项,最后会提供…...

基于Python和OpenCV的图像处理的轮廓查找算法及显示
文章目录 概要轮廓查找算法示例代码代码解释小结 概要 在图像处理中,轮廓查找是一个重要的步骤,它可以帮助我们识别图像中的形状和边界。Python结合OpenCV库可以非常方便地实现这一功能。本文将详细介绍如何使用Python和OpenCV来查找图像中的轮廓&#…...
)
【2026年最新600套毕设项目分享】springboot智慧医疗管理系统(14315)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...
)
MySQL 生产环境故障排查与性能优化全攻略(8.0 版本实战)
前言MySQL 作为目前企业级应用最广泛的开源关系型数据库,在生产环境中承担着核心数据存储与处理任务。默认配置往往无法满足高并发、大数据量的业务场景,同时运维过程中也会频繁遇到各类故障。本文基于 MySQL 8.0 版本,从单实例故障、主从复制…...

构建高效Cursor Pro功能解锁的模块化架构实现指南
构建高效Cursor Pro功能解锁的模块化架构实现指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial request limi…...

Buck电路PCB布局优化与EMI控制技巧
1. Buck电路PCB布局的重要性在开关电源设计中,PCB布局的好坏直接决定了电源的稳定性、效率和EMI性能。以Buck电路为例,不合理的布局可能导致输出电压纹波增大、转换效率降低、甚至引发系统振荡等问题。我从事电源设计多年,见过太多因为PCB布局…...

多线程——基础
普通线程与多线程示意图 通常 系统中运行的程序/软件当做一个进程[迅雷],迅雷里面多个任务看做多个线程。 总结:一个程序一个进程,一个进程可多个线程。线程是CPU调度和执行的的单位。多线程中至少一个为主线程 注意:真正多线程…...
)
WireGuard排除私网地址聚类表(掩码形式)
事情缘由: 玩过WireGuard的都知道,它的配置文件是如下形式的: [Interface] PrivateKey *********************** Address **********/32 DNS 8.8.8.8 MTU1420 [Peer] PublicKey ************************ Endpoint 8.8.8.8:12345 A…...

Netty-learning-example数据持久化实战:JPA+MySQL与MyBatis+MongoDB对比
Netty-learning-example数据持久化实战:JPAMySQL与MyBatisMongoDB对比 【免费下载链接】netty-learning-example :egg: Netty实践学习案例,见微知著!带着你的心,跟着教程。我相信你行欧。 项目地址: https://gitcode.com/gh_mir…...

史上最快破 10 万 Star!Claude Code Python 重写版震撼上线!
文章目录 📖 介绍 📖 🏡 演示环境 🏡 📒 史上最快10万Star项目 📒 📝 事件始末 🔧 项目架构 🗂️ 目录结构 ⭐ Rust工作区模块 🚀 快速开始 📦 Python版 🦀 Rust版 💡 核心特色 🎯 清洁室重写 🔄 AI辅助开发 📊 Rust性能优化 🌟 项目影响力 …...

Kotlin重构与跨平台通信:Linphone的开源通信解决方案革新
Kotlin重构与跨平台通信:Linphone的开源通信解决方案革新 【免费下载链接】linphone-android Linphone.org mirror for linphone-android (https://gitlab.linphone.org/BC/public/linphone-android) 项目地址: https://gitcode.com/gh_mirrors/li/linphone-andro…...

效率倍增:用快马打造Ollama多模型对比测试工具
最近在折腾本地大模型时,发现Ollama虽然能方便地运行多个模型,但每次想对比不同模型的表现都得手动切换,特别影响效率。于是琢磨着做个工具来提升测试效率,顺便把实现过程记录下来分享给大家。 需求痛点分析 本地测试不同模型时&a…...