YOLO系列:从yolov1至yolov8的进阶之路 持续更新中
一、基本概念
1.YOLO简介
YOLO(You Only Look Once):是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。
2.目标检测算法
-
RCNN:该系列算法实现主要为两个步骤:先从图片中搜索出一些可能存在对象的候选区(Selective Search),大概2000个左右;然后对每个候选区进行对象识别。检测精度较高,但速度慢。
-
YOLO:将筛选候选区域与目标检测合二为一,大大加快目标检测速度,但准确度相对较低。
3.评价目标
3.1.IOU
IOU(Intersection over Union):交并比,候选框(candidate bound,紫色框)与原标记框(ground truth bound,红色框)的交叠率,IOU值越高,说明算法对目标的预测精度越高。
- Area of overlap:原标记框与候选框的交集面积
- Area of union:原标记框与候选框的并集面积
3.2.置信度

3.3.二分类指标
在「二分类」任务中,对样本的描述:
- Position:正例,二分类中的一类样本,一般是想要的
- Negative:负例,二分类中另一类样本,一般是不想要的
- TP(True Position):在拿出样本中,正确识别为正例
- FP(False Position) :在拿出样本中,错误识别为正例,即本身是负例(误判)
- TN(True Negative) :未拿出样本中,正确当负例舍弃
- FP(False Negative) :未拿出样本中,错误当负例舍弃,即本身是正例(遗漏)
二分类结果的评判指标:

3.4.AP
由于 Precision 与 Recall 只适用于「二分类问题」。当存在多样本分类时,对每一类样本单独考虑其「二分类问题」,即目标样本与其他样本的分类问题。
当确认的样本越少,出错的风险也就越小;当选择出的样本量越大,得到全部目标样本的可能性越大。因此 Precision 与 Recall 是一度矛盾的关系
- Precision 较大时,Recall 较小:当要分辨 10 个苹果时,我只拿出一个苹果,那么 Precision 就是
100 %,而 Recall 确是10 % - Precision 较大时,Recall 较小:若选择出 100 个水果,10 个苹果我们都拿出来了,但是还有 90 个其他水果。Precision 就是
10 %,而 Recall 是100 %
假设模型的任务为从图片中,检测出三类物体:(1,2,3)。「一张图片」的模型预测结果如下所示

现在对每一类别分别绘制 Precision-Recall曲线:
每个预测的 box 与其分类对应的所有 Ground True box 进行 IOU 计算,并选择出最大的 IOU 作为输出结果。 认为当前预测 box 就是 IOU 最大的这个 Ground True box 的预测结果。(若多个预测box 与同一个 Ground True box 相对应,则只记录一个)

将 max_iou 与给定阈值 thresh = 0.5 进行比较,大于阈值就标记 1

数据根据「分类置信度 class_conf」 进行排序

取出分类 1

假设在当前图片中,存在 3 个 1 类目标,计算其 Precision 与 Recall。
根据上面的结果,假设只找出 1 个 1 类目标时:
![]()
假设只找出 2 个 1 类目标时

假设只找出 3 个 1 类目标时

以此类推,找出全部时

根据上述 Precision 与 Recall 序列绘制出的曲线,就是 1 类别目标对应的Precision-Recall曲线,重复上述步骤,就是绘制出 2, 3 类别的曲线。 根据Precision-Recall曲线就能计算 AP 值了。

AP(Average Precision):Precision-Recall曲线下方的面积。结合 Precision 与 Recall ,更加全面的对模型的好坏进行评价。
绘制完整的 Precision-Recall曲线:将 Precision 与 Recall 绘制成曲线。

查找 precision 突然变大的点

利用这个突变点来代表这个区间内的 Precision

最后计算彩色矩形区域的面积,该值就是 AP
二、YOLO V1
1.网络模型

对于第一版 YOLO 的网络模型就两个部分: 卷积层、全连接层 。
-
输入: 尺寸为
448x448x3的图片, 图片尺寸定死 -
输出: 图片中被检测目标的位置(矩形框坐标)与被检测物体的分类。

2.目标检测原理

- 将输入图片通过
7x7网格,划分为49个单元格 - 每个单元格负责一个检测目标:存储检测目标外接矩形的「中心点坐标」、长宽;存储检测目标的类型。 即当检测目标的外接矩形「中心点坐标」位于该单元格内时,就让该单元格全权负责储存这个检测目标的信息。
- 每个单元格持有
2个候选矩形框,会通过置信度选择一个最好的当作预测结果输出

3.模型输出
V1 版本的输出结果为 7x7x30 的一个向量,对该向量进行维度转换得到

其中 7x7 表示利用 7x7 的网格,将输入图片划分为 49 个单元格;30 表示对每个单元格预测结果的描述:两个目标位置候补框、置信度、目标的分类

- bounding box 1 :第一个候补框的参数,外接矩形中心坐标 (x1,y1)(x1,y1) ;长宽 (w1,h1)(w1,h1)
- confidence 1 :第一个候补框是待检测目标的置信度
- bounding box 2 :第二个候补框的参数,外接矩形中心坐标 (x1,y1)(x1,y1) ;长宽 (w1,h1)(w1,h1)
- confidence 2 :第二个候补框是待检测目标的置信度
- 分类:检测目标为
20个分类的概率
其中,对于中心坐标 (x,y)(x,y) 、长宽 (w,h)(w,h) 值的存储是一个百分比。
- 中心坐标 (x,y)(x,y) :相对单元格长宽的比值
- 长宽 (w,h)(w,h):相对于输入图片长宽的比值
4.损失函数
4.1.定义


4.2.位置预测

当预测外接框与目标外接框的宽度、高度的差值一样时,对于较大的物体而言相对误差小,而对于较小物体而言相对误差较大。因此为了让损失函数对小物体的外接矩形的宽度、高度更敏感一些,在 YOLO V1 中采用了 「根号」: 自变量在[0,1]取值时,根号的斜率变化比直线要大。
5.模型预测
5.1.思路
训练好的 YOLO 网络,输入一张图片,将输出一个 7x7x30 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和可信程度(置信度)。每个单元格有两个 bounding box ,一共有 7x7 个单元格,现在将所有的 7x7x2=98 个 bounding box 绘制出来

可以看见图上到处都是 bounding box,现在就需要从这些 bounding box 中,筛选出能正确表示目标的 bounding box。

为了实现该目的, YOLO 采用 NMS(Non-maximal suppression,非极大值抑制)算法
三、YOLO V2
1.模型改进

1.1.卷积化
在 V1 中,最后的输出结果是靠「全连接层」得到的,这也就限制了输入图片的尺寸。因此在 V2 将所有的全连接层转为了卷积层,构造了新的网络结果 DarkNet19,其中还利用 1x1 卷积对模型进行优化。
1.2.Batch Nomalization
在 DarkNet19 网络中,对于卷积层加入了 Batch Normalization ,并删除了 dropout 。
由于 DarkNet19 做了 5 次池化且卷积均进行了padding,所以输入图片将会被缩放 25=3225=32 倍,即 448x448 的输入,输出结果应当是 448/32=14,但是14x14的结果没有特定的中心点,为了制造一个中心点,模型的输入图片尺寸就更改为了416x416,输出结果就变为了13x13。
1.3.Fine-Grained Features
在 DarkNet19 模型中,存在一个 PassThrough Layer 的操作,该操作就是将之前阶段的卷积层结果与模型输出结果进行相加。根据 感受野 可知,越靠前的网络层对细节的把握越好,越靠后的网络更注重于目标整体,为了使得输出结果对小物体有更好的把握,就可以利用 PassThrough Layer 来提升结果特征图对小物体的敏感度。
1.4.图片输入
由于历史原因,ImageNet分类模型基本采用大小为 224x224 的图片作为输入,所以 YOLO V1 模型训练使用的输入图片大小其实为 224x224,在模型预测时,又使用的是 448x448 的图片作为输入,这样就导致模型的训练和模型的预测,输入其实是有差异的。为了弥补这个差异,模型训练的最后几个 epoch 采用 448x448 的图片进行训练。
2.Anchor Box
YOLO V1 的 bounding box 缺陷:
- 一个单元格只能负责一个目标检测的结果,如果该单元格是多个目标的中心点区域时,V1 版本将不能识别。
- V1 中,对于 bounding box 的预测结果并未加限制,这就会导致 bounding box 的中心点可能会跑到其他单元格内
- bounging box 的宽度与高度是靠模型自己学习的,这就可能走很多弯路。
2.1.Anchor
-
模型训练开始前,人为为每个单元格预定义几个不同大小的 Anchor Box,这样从训练开始,每个单元格的bounding box就有了各自预先的检测目标,例如瘦长的 bounging box 就适合找人,矮胖的 bounging box 就适合找车等。
-
模型训练就是调整这些预定义的bounding box 的中心点位置与长宽比列。
2.2.Box 数据结构

在引入 Anchor box 后, YOLO V2 对于一个 bounging box 的数据结构为:
- 中心点坐标 (x,y)(x,y),相对于单元格宽度的比列值
- 相对于 Anchor box 宽高的偏移量 (w,h)(w,h)
- 当前 bounging box 存在检测目标的置信度 ConfidenceConfidence
- 检测目标对应各个类型的概率 pipi
一个单元格能检测多少目标,就输出多少个上述 Box 数据结构。
2.3.Box 解析



2.4.确定Anchor


3.损失函数

四、YOLO SPP
五、YOLO V4
六、YOLO V5
相关文章:
YOLO系列:从yolov1至yolov8的进阶之路 持续更新中
一、基本概念 1.YOLO简介 YOLO(You Only Look Once):是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。 2.目标检测算法 RCNN:该系列算法实现主要为两个步骤&…...

欧拉系统离线安装界面ukui
1、官网下载安装镜像iso后,默认没有gui openEuler | 开源社区 | openEuler社区官网openEuler是一个开源、免费的 Linux 发行版平台,将通过开放的社区形式与全球的开发者共同构建一个开放、多元和架构包容的软件生态体系。同时,openEuler 也是…...

Milvus向量数据库的简介以及用途
Milvus 是一个开源的向量数据库,专门用于处理和存储高维向量数据。它可以高效地支持各种数据科学和机器学习应用,特别是在涉及到大规模相似度搜索和推荐系统等领域。 以下是 Milvus 的简介以及它的主要用途。 1. Milvus 简介 Milvus 是由 Zilliz 开发的开源分布式向量数据库…...

恒创科技:IPv4 和 IPv6 之间的主要区别
IPv4 和 IPv6 是互联网协议 (IP) 系统中使用的两种版本的 IP 地址格式。虽然它们的主要目的是准确识别、发送和接收互联网上的数据,但 IPv4 和 IPv6 之间存在许多关键差异。 地址格式 IPv4 采用 32 位格式,由 4 个数值(称为八位字节)表示,以点…...

TinyWebserver的复现与改进(1):服务器环境的搭建与测试
计划开一个新坑, 主要是复现qinguoyi/TinyWebServer项目,并且使用其它模块提升性能。 本文开发服务器配置:腾讯云轻量级服务器,CPU - 2核 内存 - 2GB,操作系统 Ubuntu Server 18.04.1 LTS 64bit 打开端口 需要打开服务器3306、80…...

【Python】练习题附带答案
1、使用for循环实现输出9*9乘法表 代码: 2、写代码实现累乘计算器。 示例:用户输入:5*9*87输出答案:3915 代码: 3、写代码实现,循环提示用户输入的内容(Q/q终止循环),…...

Springboot集成Proguard生成混淆jar包
背景 当我们需要将 JAR 包交付给第三方时,常常担心代码可能会被反编译。因此,对 JAR 包进行混淆处理显得尤为重要。 市面上有许多 JAR 包源码混淆工具,但真正能稳定投入使用的并不多。例如,ClassFinal (ClassFinal: Java字节码加…...

什么是NLP分词(Tokenization)
在自然语言处理和机器学习的领域里,咱们得聊聊一个超基础的技巧——就是“分词”啦。这个技巧啊,就是把一长串的文字切分成小块,让机器能更容易地“消化”。这些小块,不管大小,单个的字符也好,整个的单词也…...

基于深度学习的图像伪造检测
基于深度学习的图像伪造检测主要利用深度学习技术来识别和检测伪造的图像内容,尤其是在生成对抗网络(GAN)等技术发展的背景下,伪造图像的逼真程度大大提升。图像伪造检测在信息安全、隐私保护、司法鉴定等领域具有重要意义。以下是…...

Windows11 WSL2 Ubuntu编译安装perf工具
在Windows 11上通过WSL2安装并编译perf工具(Linux性能分析工具)可以按以下步骤进行。perf工具通常与Linux内核一起发布,因此你需要确保你的内核版本和perf版本匹配。以下是安装和编译perf的步骤: 1. 更新并升级系统 首先&#x…...

探索算法系列 - 前缀和算法
目录 一维前缀和(原题链接) 二维前缀和(原题链接) 寻找数组的中心下标(原题链接) 除自身以外数组的乘积(原题链接) 和为 K 的子数组(原题链接) 和可被 …...

Stable Diffusion绘画 | 提示词基础原理
提示词之间使用英文逗号“,”分割 例如:1girl,black long hair, sitting in office 提示词之间允许换行 但换行时,记得在结尾添加英文逗号“,”来进行区分 权重默认为1,越靠前权重越高 每个提示词自身的权重默认值为1,但越靠…...

利用python写一个可视化的界面
要利用Python编写一个可视化界面,你可以使用一些图形库来实现,例如Tkinter、PyQt、wxPython等。以下是一个使用Tkinter的示例代码: import tkinter as tk# 创建一个窗口对象 window tk.Tk()# 定义一个按钮点击事件的处理函数 def buttonCli…...

第13节课:Web Workers与通信——构建高效且实时的Web应用
目录 Web Workers简介Web Workers的基本概念创建和使用Web WorkersWeb Workers的应用场景 WebSocket通信WebSocket的基本概念创建和使用WebSocketWebSocket的应用场景 实践:使用Web Workers和WebSocket示例:使用Web Workers进行大数据集处理示例…...

pam_pwquality.so模块制定密码策略
目录 设置密码策略的方法pam_pwquality.so配置详解pam_pwquality.so默认密码规则pam_pwquality.so指定密码规则问题补充设置密码策略的方法 这篇文章重点讲通过pam_pwquality.so模块配置密码策略 指定pam_pwquality.so模块参数Centos7开始使用pam_pwquality模块进行密码复杂度…...
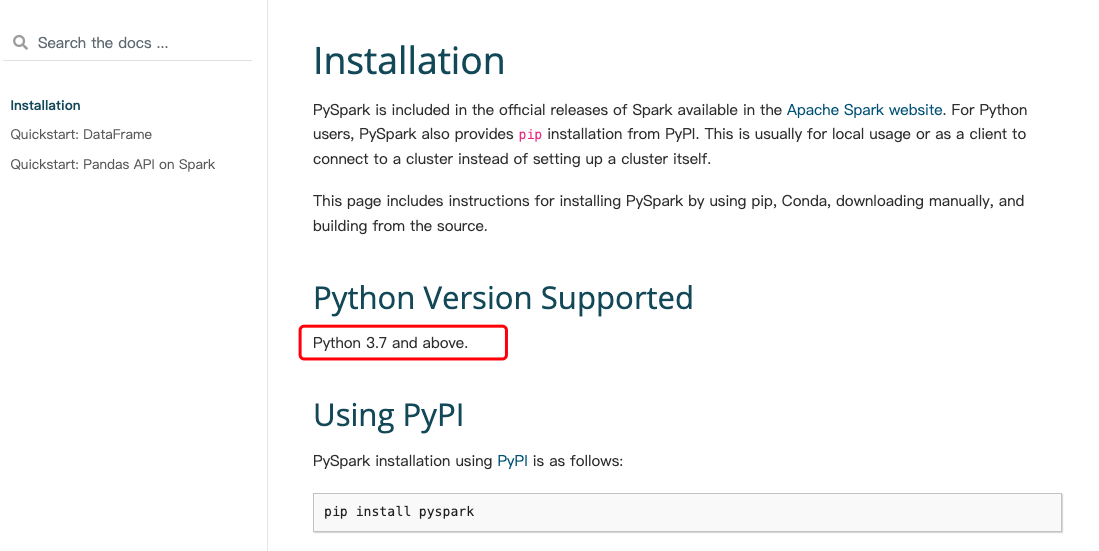
spark3.3.4 上使用 pyspark 跑 python 任务版本不一致问题解决
问题描述 在 spark 上跑 python 任务最常见的异常就是下面的版本不一致问题了: RuntimeError: Python in worker has different version 3.7 than that in driver 3.6, PySpark cannot run with different minor versions. Please check environment variables PY…...

处理Pandas中的JSON数据:从字符串到结构化分析
在数据科学领域,JSON作为一种灵活的数据交换格式,被广泛应用于存储和传输数据。然而,JSON数据的非结构化特性在进行数据分析时可能会带来一些挑战。本文将指导读者如何使用Pandas库将DataFrame中的JSON字符串列转换为结构化的表格数据&#x…...

国内的 Ai 大模型,有没有可以上传excel,完成数据分析的?
小说推文AI视频生成:小说文案智能分镜智能识别角色和场景批量Ai绘图自动配音添加音乐一键合成视频百万播放量https://aitools.jurilu.com/ 有啊!智谱清言、KiMI、豆包都可以做数分,在计算领域尤其推荐智谱清言,免费、快速还好使&a…...

Spring: jetcache
一、介绍 JetCache是一个基于Java的缓存系统封装,提供统一的API和注解来简化缓存的使用。 JetCache提供了比SpringCache更加强大的注解,可以原生的支持TTL(Time To Live,即缓存生存时间)、两级缓存、分布式自动…...
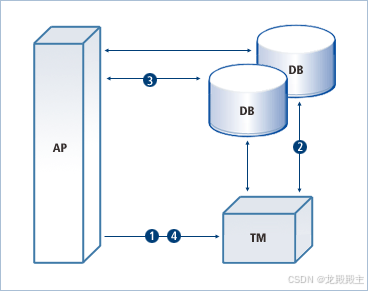
什么是分布式事务?
分布式事务跨越多个系统,确保所有操作一起成功或失败,这对于在现代计算环境中跨不同地理位置分离的资源维护数据完整性和一致性至关重要。 1. 为什么需要分布式事务? 分布式事务的需求源于确保分布式计算环境中多个独立系统或资源之间的数据…...

大模型“幻觉“频现?RAG技术如何根治三大痛点,实现精准问答?
文章深入解析了RAG(检索增强生成)技术的核心原理与实现流程,指出大模型普遍存在的三大缺陷:幻觉现象、知识更新缓慢以及领域知识理解有限。RAG通过结合向量数据库、嵌入模型和大语言模型,实现从外部私有知识库检索信息…...

社交媒体 SEO 优化应该注意哪些
社交媒体 SEO 优化的核心要点 在当今数字化时代,社交媒体已经成为品牌营销和用户互动的重要平台。单靠社交媒体上的粉丝数量不能保证品牌的成功。为了在众多用户中脱颖而出,社交媒体 SEO 优化显得尤为重要。社交媒体 SEO 优化应该注意哪些关键点呢&…...
)
帕拉丁调试指南之SDL 语言编写指南(快速参考)
1. SDL 文件基本结构SDL 程序由三个主要部分组成:text// 1. 全局定义段(可选) scope ...; define ...; enum ...; tdef ...; trigger ...; if (...) trigger; ...// 2. 实例定义段(至少一个实例,可多个) i…...

【CW32无线抄表项目】W25Q+CW32程序示例
资料下载: https://telesky.yuque.com/bdys8w/01/zr02y6vd0r7mnzcl?singleDoc# 参考仓库: https://gitee.com/Armink/SFUD 一、程序分析 硬件总线映射(引脚与时钟的“避坑点”) #define FLASH_SPIx CW_SPI2 // 注意&…...

TypeVar
## 关于Python里的TypeVar,你可能想知道的 最近在整理一些旧代码,翻到几年前写的一个通用缓存工具类,里面用到了TypeVar。当时注释里只简单写了一句“用于类型提示”,现在回头看,觉得可以展开聊聊这个东西。 TypeVar是…...

LeetCode //C - 1002. Find Common Characters
1002. Find Common Characters Given a string array words, return an array of all characters that show up in all strings within the words (including duplicates). You may return the answer in any order. Example 1: Input: words [“bella”,“label”,“roll…...

Qwen2.5-VL-7B-InstructGPU优化指南:视觉特征缓存机制与响应速度实测对比
Qwen2.5-VL-7B-Instruct GPU优化指南:视觉特征缓存机制与响应速度实测对比 1. 项目概述与优化背景 Qwen2.5-VL-7B-Instruct作为一款先进的多模态视觉-语言模型,在处理图像和文本交互任务时展现出强大能力。但在实际部署中,我们发现其GPU资源…...
)
【限时开源】我们刚在GitHub归档的Python MCP生产模板——含自动证书轮换、配置热重载、灰度指令通道(仅开放72小时)
第一章:Python MCP服务器开发模板概览与核心设计哲学Python MCP(Model-Controller-Protocol)服务器开发模板是一个面向协议驱动、可插拔架构的轻量级服务框架,专为构建高内聚、低耦合的远程控制与设备交互服务而设计。它并非传统W…...

LFM2.5-1.2B-Thinking-GGUF压力测试与性能调优:寻找最佳并发参数
LFM2.5-1.2B-Thinking-GGUF压力测试与性能调优:寻找最佳并发参数 1. 为什么需要压力测试 当你把LFM2.5-1.2B-Thinking-GGUF模型部署上线后,最担心的问题可能就是:这个服务能承受多少用户同时访问?会不会在高并发时崩溃ÿ…...

D3KeyHelper:如何通过智能操作优化解放暗黑3玩家双手的效率工具
D3KeyHelper:如何通过智能操作优化解放暗黑3玩家双手的效率工具 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 一、问题场景:…...