【人工智能】Transformers之Pipeline(八):文生图/图生图(text-to-image/image-to-image)

目录
一、引言
二、文生图/图生图(text-to-image/image-to-image)
2.1 文生图
2.2 图生图
2.3 技术原理
2.3.1 Diffusion扩散模型原理
2.3.2 Stable Diffusion扩散模型原理
2.4 文生图实战
2.4.1 SDXL 1.0
2.4.2 SD 2.0
2.5 模型排名
三、总结
一、引言
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理(NLP)、多模态(Multimodal)等4大类,28小类任务(tasks)。共计覆盖32万个模型

今天介绍CV计算机视觉的第四篇,文生图/图生图(text-to-image/image-to-image)。transformers的pipeline只有图生图(image-to-image),没有(text-to-image),在实际应用中,文生图更加主流,通常先进行文生图,再进行图生图。所以本篇文章重点介绍文生图,附带进行图生图的讲解。本篇也未使用transformers的pipeline,而是使用DiffusionPipeline,目前主流的文生图、图生图方法。本文更加注重如何使用代码进行文生图、图生图,如果你的工作不需要部署api服务,推荐您使用AUTOMATIC1111的stable-diffusion-webui。

如果您是windows,建议搜索“秋叶大佬整合包”,一键部署属于你的文生图工作台。
当然,如果您的土豪,推荐您使用midjourney,封装的更加简单易用。
二、文生图/图生图(text-to-image/image-to-image)
2.1 文生图
输入提示词,模型理解提示词,生成图片。

2.2 图生图
图像处理与增强,通过给定的提示词,对源图像进行加工与处理,使其满足清晰度、定制等需求。

2.3 技术原理
我们以Stable Diffusion为例,讲讲文生图/图生图的原理。
2.3.1 Diffusion扩散模型原理
将到扩散模型,一定要了解DDPM: Denoising Diffusion Probabilistic Models(基于概率的降噪扩散模型),主要包含两个过程:
- Diffusion Process (又被称为Forward Process) 扩散过程:对图片进行加噪,每一步都往图片上加入一个高斯分布的噪声,直到图片变为一个基本是纯高斯分布的噪声
- Denoise Process(又被称为Reverse Process)降噪过程:基于UNet对含有噪音的图片进行逐步还原,直到还原至清晰可见的图片。

2.3.2 Stable Diffusion扩散模型原理
主要由AutoEncoder、扩散模型和Condition条件模块三部分组成。具体方法是
- 首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器 E和一个解码器D )。
- 扩散过程:利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,
- 文本处理:SD采用OpenAI的CLIP(Contrastive Language-Image Pre-Training语言图片对比学习预训练模型)进行文字到图片的处理,具体使用的是clip-vit-large-patch14。对于输入text,送入CLIP text encoder后得到最后的hidden states,其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。
- 去噪过程:去噪实际上就是SD文生图模型的推理过程,通过UNet网络对图片/文字的embedding层层去噪,得到最终需要的图片。

2.4 文生图实战
2.4.1 SDXL 1.0
首先要安装扩散diffusers、invisible_watermark、transformers、accelerate、safetensors等依赖库:
pip install diffusers invisible_watermark transformers accelerate safetensors -i https://mirrors.cloud.tencent.com/pypi/simple其次,引用diffusers库中的DiffusionPipeline类,下载基础模型stabilityai/stable-diffusion-xl-base-1.0和精炼模型stabilityai/stable-diffusion-xl-refiner-1.0。使用基础base(文生图)模型生成(噪声)潜在数据,然后使用专门去噪的refiner(图生图)细化模型进行高分辨率去噪处理。

import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"from diffusers import DiffusionPipeline
import torchbase = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
base.to("cuda")
refiner = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-refiner-1.0",text_encoder_2=base.text_encoder_2,vae=base.vae,torch_dtype=torch.float16,use_safetensors=True,variant="fp16",
)
refiner.to("cuda")# Define how many steps and what % of steps to be run on each experts (80/20) here
n_steps = 40
high_noise_frac = 0.8prompt = "A beautiful sexy girl"# run both experts
image = base(prompt=prompt,num_inference_steps=n_steps,denoising_end=high_noise_frac,output_type="latent",
).imagesimage = refiner(prompt=prompt,num_inference_steps=n_steps,denoising_start=high_noise_frac,image=image,
).images[0]
image.save("base+refiner.png")python run_sd_xl_base_1.0+refiner.py运行后:

来看一下针对提示词"A beautiful sexy girl"生成的图片,好棒!

2.4.2 SD 2.0
安装的python库同SDXL 1.0,同样采用diffusers的DiffusionPipeline下载模型
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"from diffusers import DiffusionPipeline
import torch#pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
prompt = "a beautiful sexy girl"
image = pipe(prompt).images[0]
image.save("sd-xl.png")python run_sd.py运行后

来看一下效果:

对比来看,SDXL 1.0要更强一些,当然在实际的应用中,要花非常多的精力去抽卡、调正反向提示词,前往C站下载并使用别人训练好的lora与embedding。这是一门大学问。
2.5 模型排名
在huggingface上,我们将文生图(text-to-image)模型按下载量从高到低排序:在开源模型领域,stabilityai的stable-diffusion没有对手!闭源领域,独有Midjourney!

三、总结
本文对文生图/图生图(text-to-image/image-to-image)从概述、SD技术原理、SD文生图实战、模型排名等方面进行介绍,读者可以基于DiffusionPipeline使用文中的极简代码进行文生图的初步体验,如果想更加深入的了解,再次推荐您使用stable-diffusion-webui。
期待您的3连+关注,如何还有时间,欢迎阅读我的其他文章:
《Transformers-Pipeline概述》
【人工智能】Transformers之Pipeline(概述):30w+大模型极简应用
《Transformers-Pipeline 第一章:音频(Audio)篇》
【人工智能】Transformers之Pipeline(一):音频分类(audio-classification)
【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)
【人工智能】Transformers之Pipeline(三):文本转音频(text-to-audio/text-to-speech)
【人工智能】Transformers之Pipeline(四):零样本音频分类(zero-shot-audio-classification)
《Transformers-Pipeline 第二章:计算机视觉(CV)篇》
【人工智能】Transformers之Pipeline(五):深度估计(depth-estimation)
【人工智能】Transformers之Pipeline(六):图像分类(image-classification)
【人工智能】Transformers之Pipeline(七):图像分割(image-segmentation)
【人工智能】Transformers之Pipeline(八):图生图(image-to-image)
【人工智能】Transformers之Pipeline(九):物体检测(object-detection)
【人工智能】Transformers之Pipeline(十):视频分类(video-classification)
【人工智能】Transformers之Pipeline(十一):零样本图片分类(zero-shot-image-classification)
【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
《Transformers-Pipeline 第三章:自然语言处理(NLP)篇》
【人工智能】Transformers之Pipeline(十三):填充蒙版(fill-mask)
【人工智能】Transformers之Pipeline(十四):问答(question-answering)
【人工智能】Transformers之Pipeline(十五):总结(summarization)
【人工智能】Transformers之Pipeline(十六):表格问答(table-question-answering)
【人工智能】Transformers之Pipeline(十七):文本分类(text-classification)
【人工智能】Transformers之Pipeline(十八):文本生成(text-generation)
【人工智能】Transformers之Pipeline(十九):文生文(text2text-generation)
【人工智能】Transformers之Pipeline(二十):令牌分类(token-classification)
【人工智能】Transformers之Pipeline(二十一):翻译(translation)
【人工智能】Transformers之Pipeline(二十二):零样本文本分类(zero-shot-classification)
《Transformers-Pipeline 第四章:多模态(Multimodal)篇》
【人工智能】Transformers之Pipeline(二十三):文档问答(document-question-answering)
【人工智能】Transformers之Pipeline(二十四):特征抽取(feature-extraction)
【人工智能】Transformers之Pipeline(二十五):图片特征抽取(image-feature-extraction)
【人工智能】Transformers之Pipeline(二十六):图片转文本(image-to-text)
【人工智能】Transformers之Pipeline(二十七):掩码生成(mask-generation)
【人工智能】Transformers之Pipeline(二十八):视觉问答(visual-question-answering)
相关文章:
【人工智能】Transformers之Pipeline(八):文生图/图生图(text-to-image/image-to-image)
目录 一、引言 二、文生图/图生图(text-to-image/image-to-image) 2.1 文生图 2.2 图生图 2.3 技术原理 2.3.1 Diffusion扩散模型原理 2.3.2 Stable Diffusion扩散模型原理 2.4 文生图实战 2.4.1 SDXL 1.0 2.4.2 SD 2.0 2.5 模型排名 三、总…...

AI Agent 工程师认证-学习笔记(1)——【单Agent】ModelScope-Agent
学习链接: 【单Agent】ModelScope-Agent学习指南https://datawhaler.feishu.cn/wiki/GhOLwvAPkiSWmokjUgqc1eGonDf 手把手Agent开发开源教程(觉得不错的话可以star一下)https://github.com/datawhalechina/agent-tutorial 动手学Agent应用…...

【Python机器学习】树回归——将CART算法用于回归
要对数据的复杂关系建模,可以借用树结构来帮助切分数据,如何实现数据的切分?怎样才能知道是否已经充分切分?这些问题的答案取决于叶节点的建模方式。回归树假设叶节点是常数值,这种策略认为数据中的复杂关系可以用树结…...

前端(HTML + CSS)小兔鲜儿项目(仿)
前言 这是一个简单的商城网站,代码部分为HTML CSS 和少量JS代码 项目总览 一、头部区域 头部的 购物车 和 手机 用的是 文字图标,所以效果可以和文字一样 购物车右上角用的是绝对定位 logo用的是 h1 标签,用来提高网站搜索排名 二、banne…...

【Rust光年纪】构建高效终端用户界面:Rust库全面解析
构建优雅终端应用:深度评析六大Rust库 前言 随着Rust语言的流行和应用场景的不断扩大,对于终端操作和用户界面构建的需求也日益增长。本文将介绍一些在Rust语言中常用的终端操作库和用户界面构建库,以及它们的核心功能、使用场景、安装与配…...
)
鼠标滑动选中表格部分数据列(vue指令)
文章目录 代码指令代码使用代码 代码 指令代码 // 获得鼠标移动的范围 function getMoveRange(startClientX, endClientX, startClientY, endClientY) {const _startClientX Math.min(startClientX, endClientX);const _endClientX Math.max(startClientX, endClientX);con…...

“5G+Windows”推动全场景数字化升级:美格智能5G智能模组SRM930成功运行Windows 11系统
操作系统作为连接用户与数字世界的桥梁,在数字化迅速发展的时代扮演着至关重要的角色,智能设备与操作系统的协同工作,成为推动现代生活和商业效率的关键力量。其中,Windows系统以其广泛的应用基础和强大的兼容性成为全球最广泛使用…...

c语言学习,isupper()函数分析
1:isupper() 函数说明: 检查参数c,是否为大写英文字母。 2:函数原型: int isupper(int c) 3:函数参数: 参数c,为检测整数 4:返回值: 参数c是大写英文字母&…...

Adnroid 数据存储:SharedPreferences详解【SharedPreferencesUtils,SharedPreferences的ANR】
目录 1)SP是什么、如何使用,SPUtils 2)SP的流程 3)comit和apply 一、SP是什么,如何使用,SPUtils 1.1 SP是什么? SharedPreferences是Android平台提供的一种轻量级的数据存储方式,…...

Sentinel 规则持久化到 Nacos 实战
前言: 前面系列文章我们对 Sentinel 的作用及工作流程源码进行了分析,我们知道 Sentinel 的众多功能都是通过规则配置完成的,但是我们前面在演示的时候,发现 Sentinel 一重启,配置的规则就没有了,这是因为…...
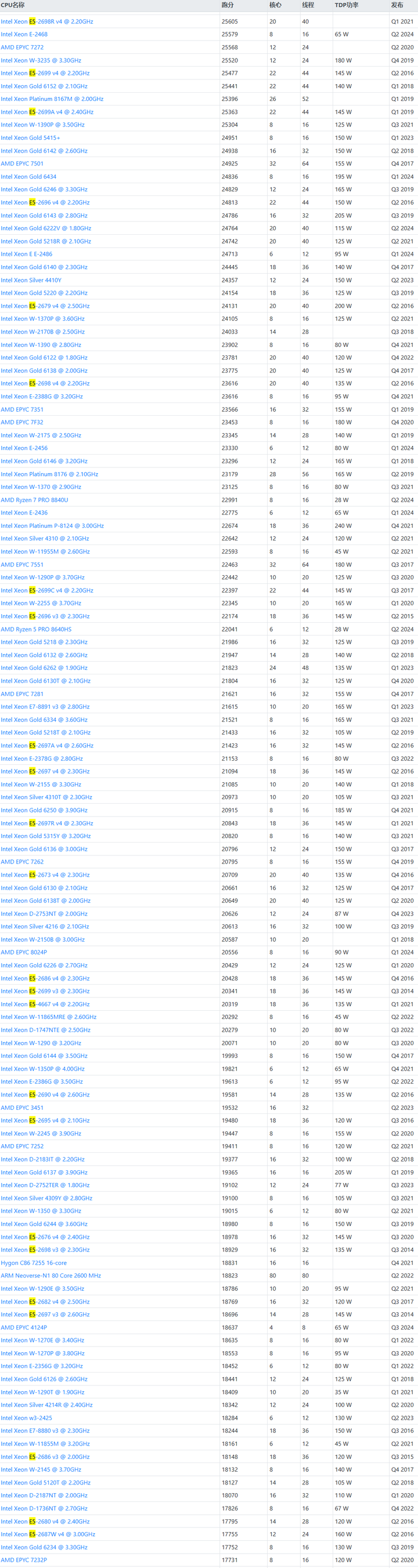
服务器CPU天梯图2024年8月,含EYPC/至强及E3/E5
原文地址(高清无水印原图/持续更新/含榜单出处链接): >>>服务器CPU天梯图<<< 本文提供的服务器CPU天梯图数据均采集自各大专业网站,榜单图片末尾会标准其来源(挂太多链接有概率会被ban,…...

SpringBoot加载dll文件示例
1、将动态库放在resource文件目录下 2、编写相关加载逻辑 import lombok.extern.slf4j.Slf4j; import java.io.File; import java.io.IOException; import java.lang.reflect.Field; import java.util.HashMap;/*** Description: 加载动态库 .dll文件* author: Be.insighted* c…...

9.C基础_指针与数组
数组指针(一维数组) 数组指针就是" 数组的指针 ",它是一个指向数组首地址的指针变量。 1、数组名的含义 对于一维数组,数组名就是一个指针,指向数组的首地址。 基于如下代码进行分析: int a…...

C语言——结构体与共用体
C语言——结构体与共用体 结构体共用体 结构体 如果将复杂的复杂的数据类型组织成一个组合项,在一个组合项中包含若干个类型不同(当然也可以相同)的数据项。 C语言允许用户自己指定这样一种数据结构,它称为结构体。 结构体的语法…...
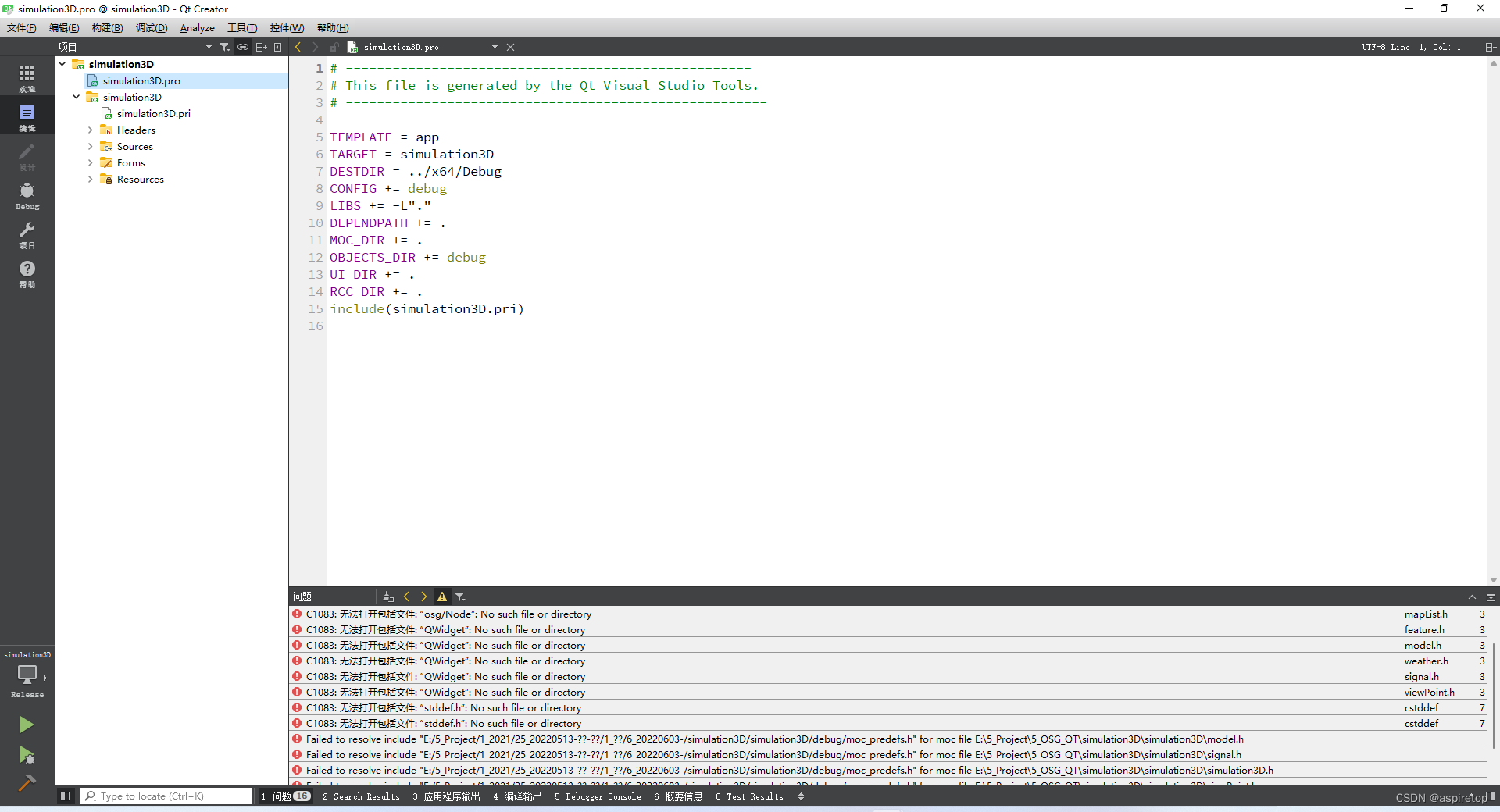
vs+qt项目转qt creator
1、转换方法 打开vs工程,右键项目,Qt->Create Base .pro File 后面默认OK 如果工程有include和lib路径需要配置,则转换后的工程,需要修改pro文件 2.修改pro文件 例如转换后的工程如下: 修改后 # ------------…...

微信小程序 checkbox 实现双向绑定以及特殊交互处理
wxml文件代码如下: <!--页面顶部 引入wxs文件--> <wxs module"tools" src"../../filter/tools.wxs"></wxs> ... <checkbox-group bindchange"checkboxChange"><label class"weui-cell weui-check__…...

我在高职教STM32——I2C通信之读写EEPROM(1)
大家好,我是老耿,高职青椒一枚,一直从事单片机、嵌入式、物联网等课程的教学。对于高职的学生层次,同行应该都懂的,老师在课堂上教学几乎是没什么成就感的。正是如此,才有了借助CSDN平台寻求认同感和成就感的想法。在这里,我准备陆续把自己花了很多心思设计的教学课件分…...

【ARM】应用ArmDS移植最小FreeRTOS系统
【更多软件使用问题请点击亿道电子官方网站】 一、文档背景 FreeRTOS(Free Real-Time Operating System)是一个开源的实时操作系统内核,广泛应用于嵌入式系统。它具有小巧、灵活、低功耗等特点,支持多任务调度、信号量、队列等实…...

golang下载、上传文件MD5高效计算方法,利用io.TeeReader函数特性 实时计算文件md5签名
在go语言的开发中,当我们在操作下载或者上传文件对象时, 我们可以利用golang内置的io包中的 TeeReader函数特性,高效实时计算文件的md5值。 方法如下: TeeReader高效计算文件md5示例 保存上传文件,并使用文件的md5签…...

TreeMap实现根据值比较
前言: TreeMap普通的排序方法都是根据键来比较来排序,本篇文章实现两种方式实现值排序 1.使用 SortedSet 和 Stream API 如果你想要一个持久化的排序结果,你可以使用 SortedSet 结构来存储键值对的条目。 TreeSet<Map.Entry<String, …...

Arduino I²C pH传感器库:高鲁棒性嵌入式pH测量方案
1. 项目概述 iarduino_I2C_pH 是一款专为 iArduino 系列 IC 接口 pH 传感器模块设计的 Arduino 兼容 C 库。该库面向嵌入式硬件工程师与固件开发者,提供对 pH-метр(pH 计)模块的完整底层控制能力,支持标准硬件 IC 外设&#…...

实战指南:基于快马AI开发具备核心功能的电商比价插件
最近在做一个电商比价插件的开发项目,正好用到了InsCode(快马)平台,整个过程特别顺畅,分享下我的实战经验。 项目背景与需求分析 电商比价插件是很多网购达人的刚需工具。核心要解决三个问题:实时比价、历史价格追踪和降价提醒。传…...
)
阿里通义实验室FunAudioLLM实战:如何用SenseVoice快速搭建多语言语音识别系统(附代码)
基于SenseVoice构建多语言语音识别系统的工程实践指南 语音识别技术正在重塑人机交互的边界,而阿里通义实验室开源的FunAudioLLM项目中的SenseVoice模型,为开发者提供了一把打开多语言语音世界的钥匙。不同于传统ASR系统需要针对不同语言单独训练模型的繁…...

Vibe Coding氛围编程系列:AI 模型 服务选择之哪个模型编程能力最强?
前言 2026年,AI辅助编程早已告别了“单行代码补全”的初级阶段,正式进入了Vibe Coding(氛围编程) 的全新时代。所谓氛围编程,核心是AI能完全贴合开发者的编码思路、节奏与工作流,实现无断点、沉浸式的流畅…...

ANDOVER PS120/240电源模块
ANDOVER PS120/240 电源模块是一款工业控制系统用电源设备,主要用于为控制器、I/O 模块及相关设备提供稳定的直流或交流电源。一、基本概述型号:PS120/240类型:电源模块用途:为工业控制系统提供稳定可靠的电力支持二、主要功能提供…...

Agentic SOC:AI原生时代,安全运营的终极范式革命
2026年RSAC全球网络安全大会上,一个现象级的行业转折正在发生:全场超过90%的主流安全厂商将核心展位与重磅发布聚焦于Agentic SOC,全球500强企业中超过62%已启动相关试点,21%完成了核心生产环境的规模化落地。与之形成强烈对比的是…...
)
Android蓝牙开发避坑指南:如何正确监听设备连接状态(附完整代码示例)
Android蓝牙开发避坑指南:如何正确监听设备连接状态(附完整代码示例) 蓝牙技术在现代移动应用中扮演着重要角色,从智能家居控制到健康监测设备,稳定的蓝牙连接是用户体验的基础。然而,Android平台上的蓝牙状…...

C语言完美演绎6-17
/* 范例:6-17 */#include <stdio.h>#include <conio.h>int main(){int a;printf("请输入你的分数(0-100)");scanf("%d",&a);if(a>0) if(a<100) printf("你输入的分数…...

KMS_VL_ALL_AIO:Windows和Office智能激活的革命性解决方案
KMS_VL_ALL_AIO:Windows和Office智能激活的革命性解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office激活问题烦恼吗?KMS_VL_ALL_AIO是一款创…...
)
Zynq Linux FPGA Manager实战:5分钟搞定PL配置(含bit转bin避坑指南)
Zynq Linux FPGA Manager实战:5分钟搞定PL配置(含bit转bin避坑指南) 第一次在Zynq开发板上尝试配置PL逻辑时,我盯着Vivado生成的.bit文件发愁——官方文档里提到的PCAP、ICAP协议像天书一样,而网上各种教程要么步骤不全…...