数据仓库: 2- 数据建模
目录
- 2- 数据建模
- 2.1 维度建模
- 2.1.1 维度建模的基本概念
- 2.1.1.1 事实表 (Fact Table)
- 2.1.1.2 维度表 (Dimension Table)
- 2.1.1.3 维度 (Dimension)
- 2.1.1.4 度量 (Measure)
- 2.1.2 维度建模的主要模型
- 2.1.2.1 星型模型 (Star Schema)
- 2.1.2.2 雪花模型 (Snowflake Schema)
- 2.1.2.3 星座模型 (Constellation Schema)
- 2.1.3 维度设计技术
- 2.1.3.1 缓慢变化维 (Slowly Changing Dimensions, SCD)
- 2.1.3.2 退化维度 (Degenerate Dimension)
- 2.1.3.3 巨型维度 (Junk Dimension)
- 2.1.3.4 角色扮演维度 (Role-Playing Dimension)
- 2.1.3.5 桥接表 (Bridge Table)
- 2.1.4 维度建模的步骤
- 2.1.5 维度建模的最佳实践
- 2.1.6 维度建模的优势
- 2.1.7 维度建模的挑战
- 2.2 星型模型
- 2.2.1 组成部分
- 2.2.2 优点
- 2.2.3 应用场景
- 2.2.4 示例
- 2.2.5 总结
- 2.3 雪花模型
- 2.3.1 定义
- 2.3.2 结构组成
- 2.3.3 雪花模型的特点
- 2.3.4 设计步骤
- 2.3.5 示例 以零售销售为例:
- 2.3.6 优势
- 2.3.7 局限性
- 2.3.8 与星型模型的对比
- 2.3.9 实施考虑
- 2.3.10 使用场景
- 2.4 事实表和维度表设计
- 2.4.1 事实表设计
- 2.4.1.1 确定业务过程和粒度
- 2.4.1.2 确定度量值
- 2.4.1.3 设计外键
- 2.4.1.4 其它设计考虑
- 2.4.2 维度表设计
- 2.4.2.1 确定维度
- 2.4.2.2 设计属性
- 2.4.2.3 设计层次结构
- 2.4.2.4 其他设计考虑
- 2.4.3 总结
- end
2- 数据建模
2.1 维度建模
2.1.1 维度建模的基本概念
2.1.1.1 事实表 (Fact Table)
- 包含业务过程的度量值
- 通常是数值型的、可累加的
- 例如: 销售金额、数量等
2.1.1.2 维度表 (Dimension Table)
- 包含描述业务实体的属性
- 通常是文本类型的描述性信息
- 例如: 产品、顾客、时间、地点等
2.1.1.3 维度 (Dimension)
- 提供分析数据的角度
- 用于过滤、分组和标记
2.1.1.4 度量 (Measure)
- 事实表中的数值型数据
- 可以进行数据运算(如: 求和、平均等)
2.1.2 维度建模的主要模型
2.1.2.1 星型模型 (Star Schema)
- 中心是事实表, 周围是维度表
- 维度表直接与事实表相连
- 优点: 查询性能好, 易于理解
- 缺点: 可能存在数据冗余
2.1.2.2 雪花模型 (Snowflake Schema)
- 星型模型的变体, 维度表被进一步规范化
- 减少了数据冗余, 增加了表的数量
- 优点: 节省存储空间, 方便维护
- 缺点: 查询性能可能下降, 结构复杂
2.1.2.3 星座模型 (Constellation Schema)
- 多个实时表共享维表
- 用于复杂的、多主体的数据仓库
2.1.3 维度设计技术
2.1.3.1 缓慢变化维 (Slowly Changing Dimensions, SCD)
- 处理维度属性随时间变化的方法
- 类型1: 直接覆盖旧值
- 类型2: 增加新记录, 保留历史
- 类型3: 增加新属性列, 保留当前和历史
- 类型4: 增加历史表
- 类型5: 结合1、2、3的混合方法
2.1.3.2 退化维度 (Degenerate Dimension)
- 存储在事实表中的维度属性
- 通常是业务过程产生的标识符
- 例如: 订单号、发票号等
2.1.3.3 巨型维度 (Junk Dimension)
- 将多个低基数的标志或属性组合成一个维度
- 减少维度数量, 简化模型
2.1.3.4 角色扮演维度 (Role-Playing Dimension)
- 同一个维度表在事实表中扮演多个角色
- 例如: 日期维度可以是订单日期、发货日期等
2.1.3.5 桥接表 (Bridge Table)
- 用于处理多对多关系
- 链接事实表和维度表
2.1.4 维度建模的步骤
- 选择业务过程: 确定要建模的具体业务活动
- 声明粒度: 定义事实表中单条记录代表的最小细节级别
- 确定维度: 识别描述该业务过程的所有可能角度
- 确定事实: 确定与该业务过程相关的可度量指标
- 存储预计算结果: 在适当的情况下, 预先计算并存储聚合数据
2.1.5 维度建模的最佳实践
- 使用代理键: 为每个维度表使用独立的整数型代理键
- 创建一致性维度: 垮多个事实表使用相同的维度定义
- 创建日期维度: 包含丰富的日期相关属性, 便于时间分析
- 避免过度规范化: 在性能和易用性之间找平衡
- 考虑未来的扩展性: 设计时预留空间为将来可能的变化
2.1.6 维度建模的优势
- 直观易懂, 便于业务用户理解
- 查询性能优秀, 特别是对于复杂的分析查询
- 灵活性高, 易于应对需求变化
- 支持自助式BI和OLAP分析
2.1.7 维度建模的挑战
- 可能存在数据冗余
- 初次设计时可能难以确定最佳粒度
- 处理快速变化的维度可能比较复杂
- 需要权衡存储空间和查询性能
2.2 星型模型
星型模型是一种经典的数据仓库设计模式, 因其结构类似于星星而得名 ; 它由一个中心事实表和多个围绕它的维度表组成, 并通过外键关联 ;
这种简单而直观的结构使其易于理解、查询效率高, 被广泛应用于数据仓库和商业智能领域 ;
2.2.1 组成部分
- 事实表 (Fact Table): 位于星型模型的中心, 存储关键业务指标的数值数据, 例如销售额、订单数量、网站访问量等 ; 每个事实表都与一个特定的业务过程相关联, 例如销售、订单、网站访问等 ;
- 事实表通常包含大量数据行, 因为他们记录了每个业务事件的详细信息 ;
- 事实表的结构相对简单, 通常包含一下两种类型的列:
- 度量值 (Measures): 表示业务指标的数值数据, 例如销售额、数量、成本、例如等 ;
- 外键 (Foreign Keys): 用于链接到维表, 表示与该事实相关的维度信息 ;
- 维度表 (Dimension Table): 围绕在事实表周围, 提供关于事实的上下文, 例如时间、地点、产品、客户等 ; 维度表回答了关于事实的 “谁、什么、何时、何地、为什么” 等问题 ;
- 维度表通常包含较少的数据行, 因为他们描述的是业务体的属性, 例如产品类别、地区、客户类型等 ;
- 维度表的结构可以比较复杂, 可以包含多个层次结构, 例如时间维度可以包含年、季度、月、日等层次结构 ;
- 维度表通常包含以下两种类型的列:
- 主键 (Primary Key): 唯一标识维度表中的每一行数据 ;
- 属性 (Attributes): 描述维度信息的文本或数值数据, 例如产品名称、类别、颜色、尺寸、地区名称、邮编、客户姓名、性别、年龄、地址等 ;
2.2.2 优点
- 易于理解: 星型模型的结构简单直观, 及时是非技术人员也能轻松理解, 方便业务人员理解数据结构和进行数据分析 ;
- 查询性能高: 星型模型采用去规范化的设计, 将数据冗余存储在维度表中, 避免复杂的多表连接, 因此查询效率非常高 ;
- 易于扩展: 可以很容易地添加新的维度表或事实表, 以适应不断变化的业务需求, 例如增加新的产品线、开拓新的市场等 ;
2.2.3 应用场景
星型模型适用于一下场景:
- 数据分析和报表: 星型模型非常适合用于构建报表和仪表板, 因为它可以快速地对数据进行切片、切块、钻取等操作 ;
- 商业智能(BI): 星型模型是许多BI工具的基础, 因为它可以提供对数据的快速访问和分析 ;
- 数据挖掘: 星型模型可以用于构建数据挖掘模型, 因为它可以提供结构化的数据, 方便算法进行训练和预测 ;
2.2.4 示例
以一个电商网站的销售数据为例, 我们可以设计一下的星型模型:
- 事实表: 销售事实表 (FactSales)
- 销售额 (SalesAmount)
- 成本 (Cost)
- 利润 (Profit)
- 订单 ID (外键) (OrderID)
- 产品ID (外键) (ProductID)
- 时间ID (外键) (TimeID)
- 客户ID (外键) (CustomerID)
- 维度表:
- 订单维度表 (DimOrders): 订单ID (OrderID), 订单日期 (OrderDate), 订单状态 (OrderStatus)等
- 产品维度表 (DimProducts): 产品ID (ProductID), 产品名称 (ProductName), 产品类别 (ProductCategory), 产品价格 (Price) 等
- 时间维度表 (DimTime): 时间ID(TimeID), 日期 (Date), 星期 (Week), 月份 (Month), 季度 (Quarter), 年份 (Year) 等
- 客户维度表 (DimCustomers): 客户ID (CustomerID), 客户姓名 (CustomerName), 客户性别 (Gender), 年龄 (Age), 客户地区 (Region) 等
通过将这些表连接起来, 我们可以轻松地查询各种销售数据, 例如:
- 2024 年第一季度华东地区各个产品类别的销售额
- 2024 年 3 月份女性客户购买的各个产品的销售数量
- 不同年龄段客户的平均订单金额
2.2.5 总结
星型模型是一种简单、高效的数据仓库设计模型, 使用与各种数据分析和商业智能应用 ; 其易于理解、查询性能高和易于扩展的特性使其成为构建数据仓库的首选方案之一 ;
2.3 雪花模型
雪花模型是星型模型的一种扩展, 它进一步将维度表规范化, 将具有层次关系的维度属性分离到不同的表中, 形成类似雪花的分支结构 ;
2.3.1 定义
雪花模型是一种数据库设计模型, 其中维度表被进一步规范化, 形成多层结构, 看起来像雪花的形状 ;
2.3.2 结构组成
- 事实表
- 位于模型的中心
- 包含业务度量和指向主要维度表的外键
- 主要维度表
- 直接与事实表相连
- 包含部分描述性属性和指向次级维度表的外键
- 次级维度表
- 与主要维度表相连
- 进一步细分维度属性
2.3.3 雪花模型的特点
- 高度规范化: 维度表被分解成多个相关的表
- 减少数据冗余: 通过规范化降低了数据重复
- 层次结构清晰: 明确展示了维度之间的层次关系
- 灵活性: 可以详细描述复杂的维度关系
2.3.4 设计步骤
- 创建星型模型: 先设计基本的星型结构
- 识别维度层次: 确定维度内的层次关系
- 规范化维度: 将维度表拆分成多个相关表
- 建立关系: 在拆分后的维度表之间建立关系
2.3.5 示例 以零售销售为例:
- 事实表: 销售事实
- 包含: 日期ID、产品ID、商品ID、销售额、销售数量
- 主要维度表:
- 产品维度: 产品ID、产品名称、类别ID、品牌ID
- 商店维度: 商店ID、商店名称、城市ID
- 次级维度表:
- 产品类别: 类别ID、类别名称
- 品牌: 品牌ID、品牌名称
- 城市: 城市ID、城市名称、州ID
- 州: 州ID、州名称、国家ID
- 国家: 国家ID、国家名称
2.3.6 优势
- 数据一致性: 减少数据冗余, 提高了一致性
- 节省存储空间: 规范化结构减少了数据重复
- 维护方便: 更新某些属性时只需要再一个地方修改
- 支持复杂的维度层次: 可以表示更复杂的维度关系
2.3.7 局限性
- 查询性能可能下降: 需要更多的表连接操作
- 复杂度增加: 模型结构比星型模型更复杂
- 不太直观: 对非技术用户来说可能较难理解
2.3.8 与星型模型的对比
- 雪花模型: 更规范化, 节省空间, 但查询可能较慢
- 星型模型: 非规范化, 查询性能好, 结构简单
2.3.9 实施考虑
- 性能优化: 可能需要更复杂的索引策略
- 视图: 考虑使用物化视图来提高查询性能
- ETL复杂性: 数据加载和转换过程可能更复杂
2.3.10 使用场景
- 大型数据仓库: 当数据量巨大, 需要严格控制冗余时
- 复杂的维度层次: 当维度有多层次结构需要表示时
- 频繁更新的维度属性: 当某些维度属性经常变化时
2.4 事实表和维度表设计
在数据仓库设计中, 事实表和维度表是两个最基本的概念, 采用维度模型设计 ; 事实表存储时间度量值, 维度表描述业务实体 ; 两者协同工作, 为分析和报表提供完整的数据视图 ;
2.4.1 事实表设计
2.4.1.1 确定业务过程和粒度
首先需要明确要分析的业务过程是什么, 例如: 销售、订单、网站访问等 ;
然后确定事实表的粒度, 即每行数据代表什么级别的业务事件 ;
- 粒度越细, 数据越详细, 但也意味着数据量越大, 查询销量越低 ;
- 粒度越粗, 数据越汇总, 数据量越小, 但可能会丢失一些细节信息 ;
选择合适的粒度需要权衡数据量、查询性能和业务需求 ;
2.4.1.2 确定度量值
度量值是事实表中最重要的部分, 它们是可以计量的数值指标, 用于描述业务过程的关键特征; 常见的度量值包括:
- 数量: 例如销售数量、订单数量、访问次数等 ;
- 金额: 例如销售额、成本、利润等 ;
- 时间: 例如订单处理时间、页面加载时间等 ;
- 比率: 例如转化率、点击率、满意度等 ;
选择度量值时需要考虑业务需求和数据可获得性 ;
2.4.1.3 设计外键
事实表通过外键与维度表关联, 每个外键都对应一个维度表的主键, 表示该事实发生在哪个维度下 ;
- 外键数量: 取决于事实表需要关联的维度数量 ;
- 外键类型: 通常使用整数类型, 以提高查询效率 ;
2.4.1.4 其它设计考虑
- 添加时间戳: 记录每行数据的创建时间和更新时间, 方便数据跟踪和审计 ;
- 预留扩展字段: 为未来可能增加的度量值预留空间, 提高数据模型的可扩展性 ;
2.4.2 维度表设计
2.4.2.1 确定维度
维度是描述业务实体的属性, 例如时间、地点、产品、客户等; 每个维度对应一个维度表, 用于存储该维度的所有可能取值 ;
2.4.2.2 设计属性
维度表的属性用于描述维度的特征, 例如:
- 时间维度: 年、月、日、小时、分钟、秒等
- 地点维度: 国家、省份、城市、地区等
- 产品维度: 产品类型、名称、品牌、型号、规格等
- 客户维度: 客户姓名、性别、年龄、地址、联系方式等
选择属性时需要考虑业务需求和数据可获得性 ;
2.4.2.3 设计层次结构
一些维度可以按照层次结构组织, 例如:
- 时间维度: 年 > 季度 > 月 > 日 > 小时 > 分钟 > 秒
- 地点维度: 国家 > 省份 > 城市 > 区县
层次结构可以方便进行多层次的钻取分析, 例如从年度销售额下钻到月度销售额, 再下钻到每日销售额 ;
2.4.2.4 其他设计考虑
- 使用代理键: 使用自增整数作为维度表的主键, 而不是使用业务主键, 可以提高查询效率 ;
- 添加描述性字段: 为每个属性添加简短的描述信息, 提高数据可读性 ;
- 处理缓慢变化维度: 对于随时间缓慢变化的维度, 例如客户地址, 需要采用合适的策略来处理历史数据 ;
2.4.3 总结
事实表和维度表的设计是数据仓库建设的基础, 需要根据具体的业务需求和数据特点进行设计 ;
一个良好的数据模型可以提高数据查询效率, 方便进行多维分析, 并支持业务决策 ;
end
相关文章:

数据仓库: 2- 数据建模
目录 2- 数据建模2.1 维度建模2.1.1 维度建模的基本概念2.1.1.1 事实表 (Fact Table)2.1.1.2 维度表 (Dimension Table)2.1.1.3 维度 (Dimension)2.1.1.4 度量 (Measure) 2.1.2 维度建模的主要模型2.1.2.1 星型模型 (Star Schema)2.1.2.2 雪花模型 (Snowflake Schema)2.1.2.3 星…...

Tomcat 漏洞
一.CVE-2017-12615 1.使用burp抓包 把get改成put jsp文件后加/ 添加完成后访问 木马 然后木马的网址 在哥斯拉测试并且添加 添加成功 然后我们就成功进去啦、 二.弱口令 点击后输入默认用户名、密码:tomcat/tomcat 登陆之后上传一个jsp文件 后缀改成war 然后访问我…...

分布式消息队列Kafka
分布式消息队列Kafka 简介: Kafka 是一个分布式消息队列系统,用于处理实时数据流。消息按照主题(Topic)进行分类存储,发送消息的实体称为 Producer,接收消息的实体称为 Consumer。Kafka 集群由多个 Kafka 实…...

C# Unity 面向对象补全计划 七大原则 之 迪米特法则(Law Of Demeter )难度:☆☆☆ 总结:直取蜀汉
本文仅作学习笔记与交流,不作任何商业用途,作者能力有限,如有不足还请斧正 本系列作为七大原则和设计模式的进阶知识,看不懂没关系 请看专栏:http://t.csdnimg.cn/mIitr,查漏补缺 1.迪米特法则(…...

【C++】—— 类与对象(四)
【C】—— 类与对象(四) 6、赋值运算符重载6.1、运算符重载6.1.1、基础知识6.1.2、调用方法6.1.3、前置 与 后置 的重载6.1.4、注意事项6.1.5、<< 和 >> 运算符重载6.1.5.1、<< 和 >> 基础6.1.5.2、日期类 operator<< 的实…...

Qt无边框窗口,关闭后再show,鼠标等事件不响应问题解决办法
问题描述 使用Qt做了一个无边框界面,关闭后再打开,子控件的点击以及hover效果不可用。 setWindowFlags(windowFlags() | Qt::Dialog | Qt::FramelessWindowHint);//去掉标题栏解决方案: 在网上发现可以通过重写showEvent(QShowEvent* showE…...

StringJoiner更优雅创建含分隔符的字符序列
文章目录 1 why2 what3 how4 练习手段 1 why StringBuilder拼接包含分隔符的字符序列时,分隔符需要一个一个添加,或者需要手动删除末尾冗余的分隔符,代码不美观,不好看。 比如,单个字符串依次拼接时: Stri…...

线程池原理(一)线程池核心概述
更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验 线程回顾 创建线程的方式 继承 Thread 类实现 Runnable 接口 创建后的线程有如下状态: NEW:新建的线程,无任何操作 public static void main(String[] args) {Thread…...

关于redisson的序列化配置
由于使用redisson来存储list,返回的数据格式总是不对 原因是配置的序列化格式不对 Bean(value "redissonDtClient") public RedissonClient redissonClient() {RedisConnectionProperties.RedisConfigEntity configEntity properties.getDt();log.inf…...

CentOS安装ax200驱动
如果内核低于5.1需要安装一下内核 详细移步:Centos7安装高版本内核 大致如下: rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm yum --enablerepoelrepo-ke…...

FFMPEG Mac版本编译
Mac下FFMPEG使用 There are a few ways to get FFmpeg on OS X. One is to build it yourself. Compiling on Mac OS X is as easy as any other *nix machine, there are just a few caveats(警告). The general procedure is get the source, then ./configure <flags&g…...

Reactive Programing与“响应式”
将Reactive Programing翻译为“响应式编程”,的确不好理解。什么是Reactive?Reactive被翻译为“反应”,其英文原意是“事物对变化信号的回应、反应”。我热了,空调自动开,这就是空调对我的Reaction,我和空调…...
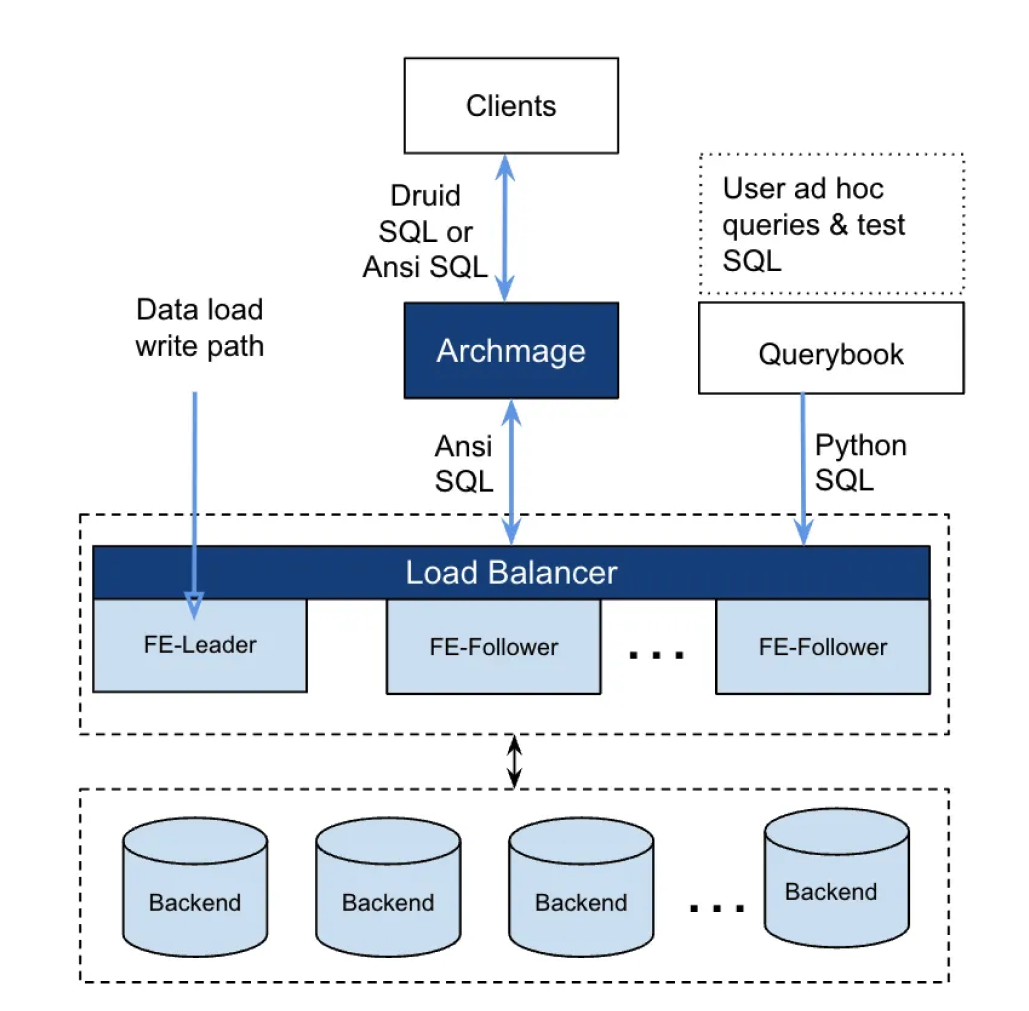
Pinterest:从 Druid 到 StarRocks,实现 6 倍成本效益比提升
导读: 开源无国界,StarRocks 自开源以来,近3年的时间里已在全球数据技术领域崭露头角。我们欣喜地发现,越来越多的海外用户正在使用并积极推广着 StarRocks。为了促进知识共享,StarRocks中文社区将精选优秀文章与大家共…...
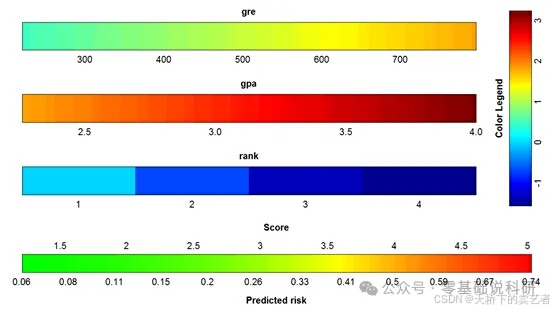
代码+视频,R语言VRPM绘制多种模型的彩色列线图
列线图,又称诺莫图(Nomogram),它是建立在回归分析的基础上,使用多个临床指标或者生物属性,然后采用带有分数高低的线段,从而达到设置的目的:基于多个变量的值预测一定的临床结局或者…...

Python 设计模式之工厂函数模式
文章目录 案例基本案例逐渐复杂的案例 问题回顾什么是工厂模式?为什么会用到工厂函数模式?工厂函数模式和抽象工厂模式有什么关系? 工厂函数模式是一种创建型设计模式,抛出问题: 什么是工厂函数模式?为什么…...
——开发:数据挖掘——概述、关注焦点)
数据赋能(171)——开发:数据挖掘——概述、关注焦点
概述 数据挖掘是从大量的数据中,提取隐藏在其中的、事先不知道的、但潜在有用的信息的过程。 数据挖掘是数据分析过程中的一个核心环节。 数据挖掘的主要目的是从大量数据中自动发现隐藏的模式、关联和趋势,以揭示数据的潜在价值。数据挖掘技术可以帮…...

L1 - OpenCompass 评测 InternLM-1.8B 实践
基础任务(完成此任务即完成闯关) 使用 OpenCompass 评测 internlm2-chat-1.8b 模型在 ceval 数据集上的性能,记录复现过程并截图。 按照教程中的顺序安装包有问题,网上找了解决方案,按一下顺序能正常执行 使用OpenCo…...
)
JS【详解】数据类型检测(含获取任意数据的数据类型的函数封装、typeof、检测是否为 null、检测是否为数组、检测是否为非数组/函数的对象)
【函数封装】获取任意数据的数据类型 /*** 获取任意数据的数据类型** param x 变量* returns 返回变量的类型名称(小写字母)*/ function getType(x) {// 获取目标数据的私有属性 [[Class]] 的值const originType Object.prototype.toString.call(x); //…...

OpenCV图像滤波(10)Laplacian函数的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 功能描述 计算图像的拉普拉斯值。 该函数通过使用 Sobel 运算符计算出的 x 和 y 的二阶导数之和来计算源图像的拉普拉斯值: dst Δ src ∂…...
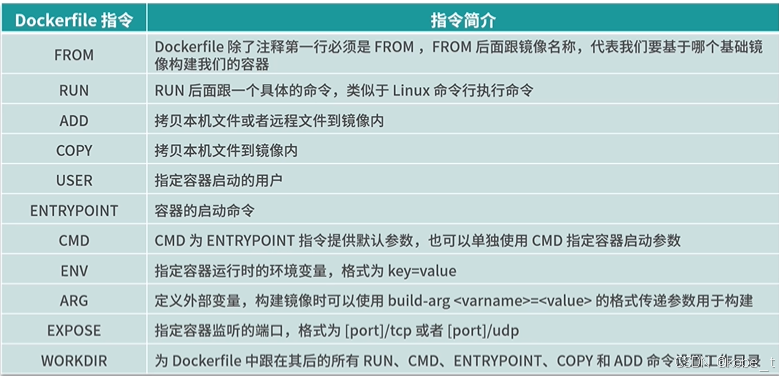
docker系列11:Dockerfile入门
传送门 docker系列1:docker安装 docker系列2:阿里云镜像加速器 docker系列3:docker镜像基本命令 docker系列4:docker容器基本命令 docker系列5:docker安装nginx docker系列6:docker安装redis docker系…...

GEMM内核与MHA中的寄存器分配优化策略
1. GEMM内核与寄存器分配基础解析通用矩阵乘法(GEMM)作为深度学习计算的核心算子,其性能表现直接决定了神经网络训练和推理的效率。在硬件层面,寄存器分配的优劣往往能带来数倍的性能差异。我们以典型的GEMM运算C αAB βC为例&…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...

3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南
3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南 【免费下载链接】Whisper-WebUI A Web UI for easy subtitle using whisper model. 项目地址: https://gitcode.com/gh_mirrors/wh/Whisper-WebUI 还在为视频制作繁琐的字幕而烦恼吗?Whis…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...