Redis面试题大全
文章目录
- Redis有哪几种基本类型
- Redis为什么快?
- 为什么Redis6.0后改用多线程?
- 什么是热key吗?热key问题怎么解决?
- 什么是热Key?
- 解决热Key问题的方法
- 什么是缓存击穿、缓存穿透、缓存雪崩?
- 缓存击穿
- 缓存穿透
- 缓存雪崩
- Redis的过期策略
- Redis持久化方式有哪些?区别?
- Redis高可用
- 1. 主从复制(Master-Slave Replication)
- 2. Sentinel(哨兵)
- 3. Cluster(集群)
Redis有哪几种基本类型
Redis 提供了丰富的数据类型,这些数据类型使得 Redis 不仅仅是一个简单的键值存储系统,而是一个多功能的 NoSQL 数据库。下面是 Redis 支持的主要数据类型及简介:
-
String(字符串)
最基本的数据类型,可以存储单个值,如字符串、整型或浮点型数据。适用于大多数简单的键值存储需求。 -
Hashes(哈希)
哈希是一个键值对的集合,每个键都是一个字段名,值可以是任意类型。哈希非常适合存储对象,比如用户信息,其中每个字段代表用户的一个属性。 -
Lists(列表)
列表是由字符串元素构成的有序集合,可以看作是一个双端队列。可以在列表的头部或尾部添加或弹出元素,常用于消息队列或任务队列。 -
Sets(集合)
集合是一组无序的不重复的字符串元素。集合成员是唯一的,可以进行交集、并集和差集等集合运算,适用于处理唯一元素的集合。 -
Sorted Sets(有序集合)
类似于集合,但每个成员都有一个分数(score)与其关联,以此来确定成员的排序。有序集合可以高效地获取指定范围内的成员,适用于排行榜、时间序列数据等场景。
详细的介绍可以看文章:Redis的几种基本类型详解
Redis为什么快?
Redis之所以非常快速,主要归功于以下几个设计特点和技术优势:
-
内存存储:
Redis将所有的数据都保存在主服务器的内存中,读写速度极快,不受磁盘I/O速度的影响。由于内存访问速度远高于硬盘,这大大提升了数据的读取和写入效率。 -
非阻塞架构:
Redis采用了事件驱动的非阻塞I/O模型,可以同时处理多个客户端请求,无需等待慢速的I/O操作完成,提高了并发处理能力。 -
多路复用器(epoll/kqueue):
Redis使用了高效的事件处理器,如Linux下的epoll和BSD下的kqueue,这些机制可以让Redis在高负载下仍然保持良好的性能。 -
异步数据交换:
在主从复制和持久化过程中,Redis采用异步方式处理背景任务,避免影响主线程的工作效率,保证在线服务的速度不受影响。 -
精简的数据结构:
Redis提供了多种高度优化的数据结构(如跳跃表、压缩列表、整数集合),针对不同的应用场景进行了专门的设计,在节省空间的同时也加快了操作速度。 -
单线程模型:
Redis采用单线程模型处理命令请求,避免了复杂的锁竞争问题,简化了内部调度流程,减少了上下文切换带来的开销。
为什么Redis6.0后改用多线程?
redis使用多线程并非是完全摒弃单线程,redis还是使用单线程模型来处理客户端的请求,只是使用多线程来处理数据的读写和协议解析,执行命令还是使用单线程。
需要注意的是,Redis的多线程仅限于后台任务如AOF、BGSAVWE、IO等,对于数据处理和客户端请求的处理依然保持单线程,这是因为单线程模型可以避免复杂的并发控制问题,保证数据的一致性和安全性。多线程的引入主要是为了释放CPU资源,让主线程专注于更关键的实时数据处理工作。
什么是热key吗?热key问题怎么解决?
什么是热Key?
在分布式缓存系统中,热Key指的是那些访问频率非常高,以至于对整个系统的性能产生负面影响的键值。
解决热Key问题的方法
- 分散热点
-
Key前缀随机化:通过对Key增加随机前缀,可以使原本相同的Key分布到不同的节点上,从而分散请求的压力。
-
一致性Hash:使用一致性Hash算法可以更好地均衡各个节点间的负载,避免单一节点成为瓶颈。
- 缓存更新策略
-
延时双删法:即“Cache Aside”模式的变体,先删除缓存再更新数据库,然后再异步更新缓存,这样即使缓存失效,也能防止所有请求立即打到数据库。
-
加锁更新:在更新热Key时,可以使用分布式锁,确保同一时间内只有一个进程能够更新这个Key,其他请求则可以从旧缓存中读取数据,直到新数据准备好。
- 缓存降级
- 备用数据源:当热Key失效时,可以暂时使用预先准备好的静态数据或默认值作为替代,避免直接访问数据库。
- 读写分离
- 对于读多写少的场景,可以考虑将读操作和写操作分离,使用只读副本应对大部分读请求,减少主节点的负载。
- 限流与熔断
-
限流:对访问频率过高的Key实施限流措施,避免过度消耗资源。
-
熔断:当检测到某个Key的访问异常时,自动切断对该Key的访问,直到恢复正常。
什么是缓存击穿、缓存穿透、缓存雪崩?
缓存击穿
缓存击穿的概念就是单个key并发访问过高,过期时导致所有请求直接打到db上,这个和热key的问题比较类似,只是说的点在于过期导致请求全部打到DB上而已。
解决方案:
加锁更新,比如请求查询A,发现缓存中没有,对A这个key加锁,同时去数据库查询数据,写入缓存,再返回给用户,这样后面的请求就可以从缓存中拿到数据了。
将过期时间组合写在value中,通过异步的方式不断的刷新过期时间,防止此类现象。

缓存穿透
缓存穿透是指查询不存在缓存中的数据,每次请求都会打到DB,就像缓存不存在一样。

针对这个问题,加一层布隆过滤器。布隆过滤器的原理是在你存入数据的时候,会通过散列函数将它映射为一个位数组中的K个点,同时把他们置为1。
这样当用户再次来查询A,而A在布隆过滤器值为0,直接返回,就不会产生击穿请求打到DB了。
显然,使用布隆过滤器之后会有一个问题就是误判,因为它本身是一个数组,可能会有多个值落到同一个位置,那么理论上来说只要我们的数组长度够长,误判的概率就会越低,这种问题就根据实际情况来就好了。

缓存雪崩
当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了,会有大量的请求进来直接打到DB上,这样可能导致整个系统的崩溃,称为雪崩。雪崩和击穿、热key的问题不太一样的是,他是指大规模的缓存都过期失效了。

针对雪崩几个解决方案:
针对不同key设置不同的过期时间,避免同时过期
限流,如果redis宕机,可以限流,避免同时刻大量请求打崩DB
二级缓存,同热key的方案。
Redis的过期策略
redis主要有2种过期删除策略
惰性删除
惰性删除指的是当我们查询key的时候才对key进行检测,如果已经达到过期时间,则删除。显然,他有一个缺点就是如果这些过期的key没有被访问,那么他就一直无法被删除,而且一直占用内存。
定期删除
定期删除指的是redis每隔一段时间对数据库做一次检查,删除里面的过期key。由于不可能对所有key去做轮询来删除,所以redis会每次随机取一些key去做检查和删除。
那么定期+惰性都没有删除过期的key怎么办?
假设redis每次定期随机查询key的时候没有删掉,这些key也没有做查询的话,就会导致这些key一直保存在redis里面无法被删除,这时候就会走到redis的内存淘汰机制。
volatile-lru:从已设置过期时间的key中,移除最近最少使用的key进行淘汰
volatile-ttl:从已设置过期时间的key中,移除将要过期的key
volatile-random:从已设置过期时间的key中随机选择key淘汰
allkeys-lru:从key中选择最近最少使用的进行淘汰
allkeys-random:从key中随机选择key进行淘汰
noeviction:当内存达到阈值的时候,新写入操作报错
Redis持久化方式有哪些?区别?
Redis 提供了两种主要的持久化方式:RDB (Redis Database Backup) 和 AOF (Append Only File)。
RDB
使用定时记录某个时间点的内存快照,将数据存储到磁盘中进行持久化。
所以,可能存在数据丢失的风险,在保存周期内发生故障就会丢失数据,但重启后数据恢复速度相较于AOF快。
AOF
AOF 记录每一次写操作命令,类似于事务日志,可以追加到文件末尾,因此不会覆盖已有的数据。
所以相较于RDB数据完整性好,但重启需要重新加载所有命令,启动速度慢。
Redis高可用
Redis 高可用性的实现主要包括以下几种方式,每种方法都有其特定的适用场景和优缺点:
1. 主从复制(Master-Slave Replication)
- 原理:通过建立一个或多个从服务器(slave),从主服务器(master)同步数据。从服务器可以用来处理读请求,实现读写分离,提高系统性能;同时,当主服务器宕机时,可以从中服务器中选择一台升级为主服务器,实现故障转移。
- 优点:简单易行,可以实现读写分离,提高读操作的性能。
- 缺点:写操作依然是单点,如果主服务器失败,需要手动干预进行故障转移。

2. Sentinel(哨兵)
- 原理:Sentinel 是一组运行在独立 Redis 服务器上的进程,它们负责监控主从服务器的状态,当主服务器不可用时,Sentinel 能够自动选出一个新的主服务器,实现故障转移。
- 优点:自动化故障检测和故障转移,降低了运维难度。
- 缺点:Sentinel 本身也需要管理,增加了系统的复杂度。

3. Cluster(集群)
- 原理:Redis Cluster 是一种原生的集群解决方案,它不仅提供了数据分区的能力,还可以实现自动故障转移。每个节点都是一个完整的 Redis 实例,数据按照哈希槽的方式分布到不同节点上。
- 优点:支持水平扩展,可以动态添加或删除节点;自动故障转移,高可用性较好。
- 缺点:配置相对复杂,不适合简单的读写分离场景;不支持所有 Redis 命令,有一定的限制。

相关文章:
Redis面试题大全
文章目录 Redis有哪几种基本类型Redis为什么快?为什么Redis6.0后改用多线程?什么是热key吗?热key问题怎么解决?什么是热Key?解决热Key问题的方法 什么是缓存击穿、缓存穿透、缓存雪崩?缓存击穿缓存穿透缓存雪崩 Redis…...

【langchain学习】BM25Retriever和FaissRetriever组合 实现EnsembleRetriever混合检索器的实践
展示如何使用 LangChain 的 EnsembleRetriever 组合 BM25 和 FAISS 两种检索方法,从而在检索过程中结合关键词匹配和语义相似性搜索的优势。通过这种组合,我们能够在查询时获得更全面的结果。 1. 导入必要的库和模块 首先,我们需要导入所需…...

【C语言】预处理详解(上)
文章目录 前言1. 预定义符号2. #define 定义常量3. #define定义宏4. 带有副作用的宏参数5. 宏替换的规则 前言 在讲解编译和链接的知识点中,我提到过翻译环境中主要由编译和链接两大部分所组成。 其中,编译又包括了预处理、编译和汇编。当时,…...

uni-app内置组件(基本内容,表单组件)()二
文章目录 一、 基础内容1.icon 图标2.text3.rich-text4.progress 二、表单组件1.button2.checkbox-group和checkbox3.editor 组件4.form5.input6.label7.picker8.picker-view 和 picker-view-column9.radio-group 和 radio10.slider11.switch12.textarea 一、 基础内容 1.icon…...

linux搭建redis超详细
1、下载redis包 链接: https://download.redis.io/releases/ 我以7.0.11为例 2、上传解压 mkdir /usr/local/redis tar -zxvf redis-7.0.11.tar.gz3、进入redis-7.0.11,依次执行 makemake install4、修改配置文件redis.conf vim redis.conf为了能够远程连接redis…...

Flink-DataWorks第二部分:数据集成(第58天)
系列文章目录 数据集成 2.1 概述 2.1.1 离线(批量)同步简介 2.1.2 实时同步简介 2.1.3 全增量同步任务简介 2.2 支持的数据源及同步方案 2.3 创建和管理数据源 文章目录 系列文章目录前言2. 数据集成2.1 概述2.1.1 离线(批量)同步…...
4个从阿里毕业的P7打工人,当起了包子铺的老板
吉祥知识星球http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247483727&idx1&sndb05d8c1115a4539716eddd9fde4e5c9&chksmc0e47813f793f105017fb8551c9b996dc7782987e19efb166ab665f44ca6d900210e6c4c0281&scene21#wechat_redirect 《网安面试指南》h…...

javaweb_07:分层解耦
一、三层架构 (一)基础 在请求响应中,将代码都写在controller中,看起来内容很复杂,但是复杂的代码总体可以分为:数据访问、逻辑处理、接受请求和响应数据三个部分。在程序中我们尽量让一个类或者一个方法…...

调用 Python 开源库,获取油管英文视频的手动或自动英文srt字幕,以及自动中文简体翻译srt字幕
前提条件 非常抱歉,这个程序就是个雏形,非常不完善,输入需要手动编辑,凑活着可以用,请自己完善吧。 开源声明:此文代码引用了一个开源MIT License的Python库,其他代码是本人自写自用。你可以随…...
)
UDP协议实现通信与数据传输(创建客户端和服务器)
目录 一、UDP (传输层,用户数据报协议) 二、服务器Server的创建 三、客户端Client的创建 四、效果实现(描述) 一、UDP (传输层,用户数据报协议) UDP(User Datagram Pr…...

【红黑树】
红黑树 小杨 红黑树的概念 红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。 通过对任何一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出俩倍&am…...

排序算法——简单选择排序
一、算法原理 简单选择排序是一种基本的排序算法,其原理是每次从未排序的元素中选择最小(或最大)的元素,然后与未排序部分的第一个元素交换位置,直到所有元素都被排序。 二、算法实现流程 简单选择排序法(Simple Se…...
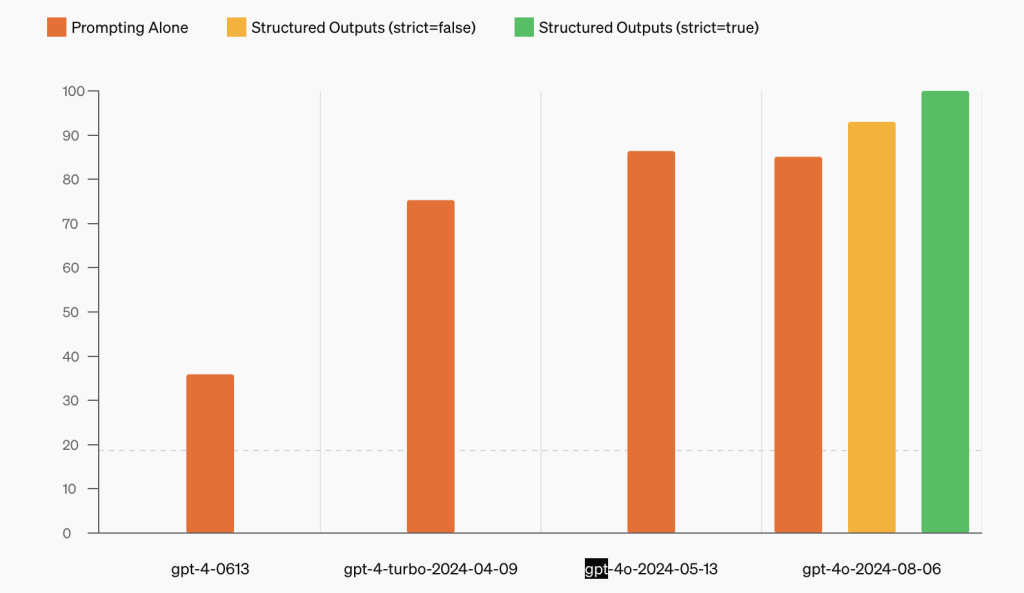
OpenAI API推出结构化输出功能
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
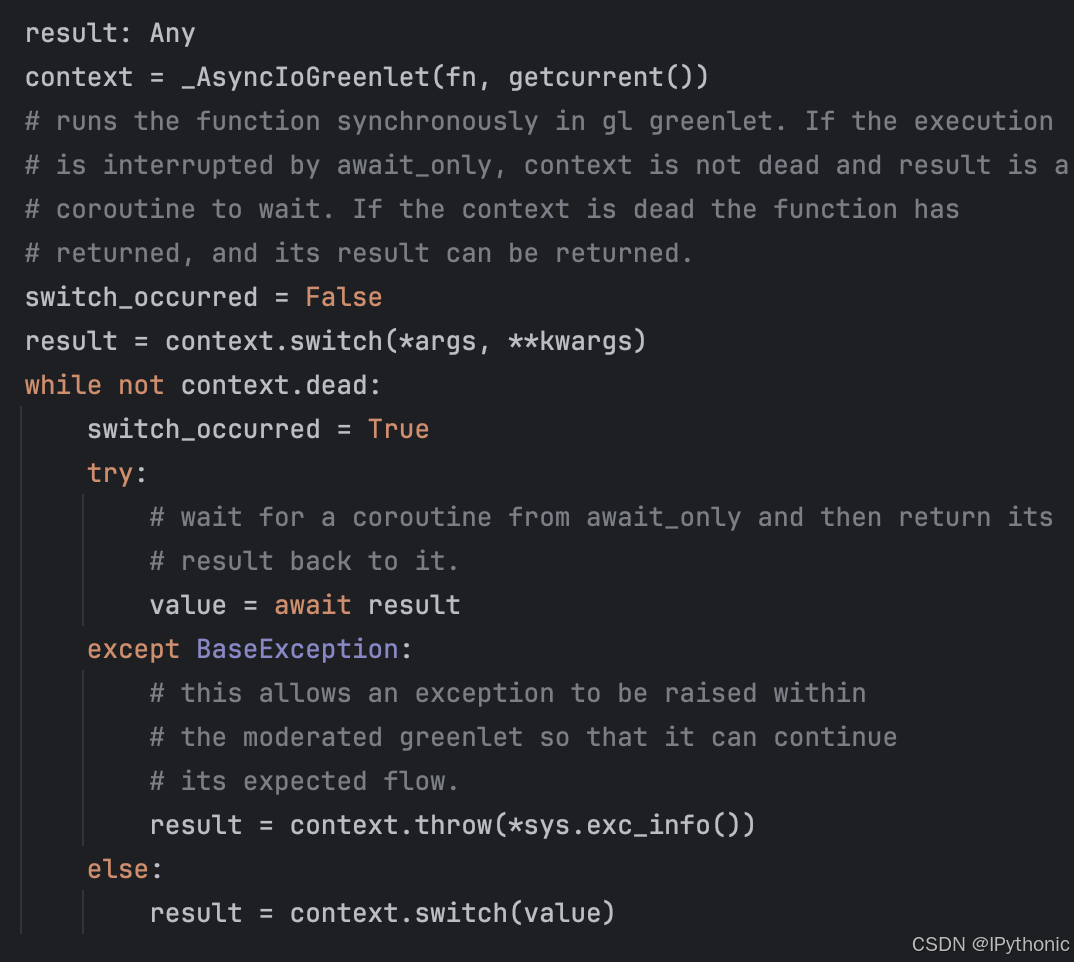
Python 异步编程:Sqlalchemy 异步实现方式
SQLAlchemy 是 Python 中最流行的数据库工具之一,在新版本中引入了对异步操作的支持。这为使用异步框架(如 FastAPI)开发应用程序带来了极大的便利。在这篇文章中,简单介绍下 SQLAlchemy 是如何利用 Greenlet 实现异步操作的。 什…...

父类引用指向子类对象
在 Java 中,父类引用可以指向子类对象,这是多态的一种表现。这种特性允许你使用父类的引用来操作子类对象,从而实现更灵活和可扩展的代码设计。 基本概念 多态:父类引用可以指向子类对象。这使得你可以用统一的接口处理不同的对象…...
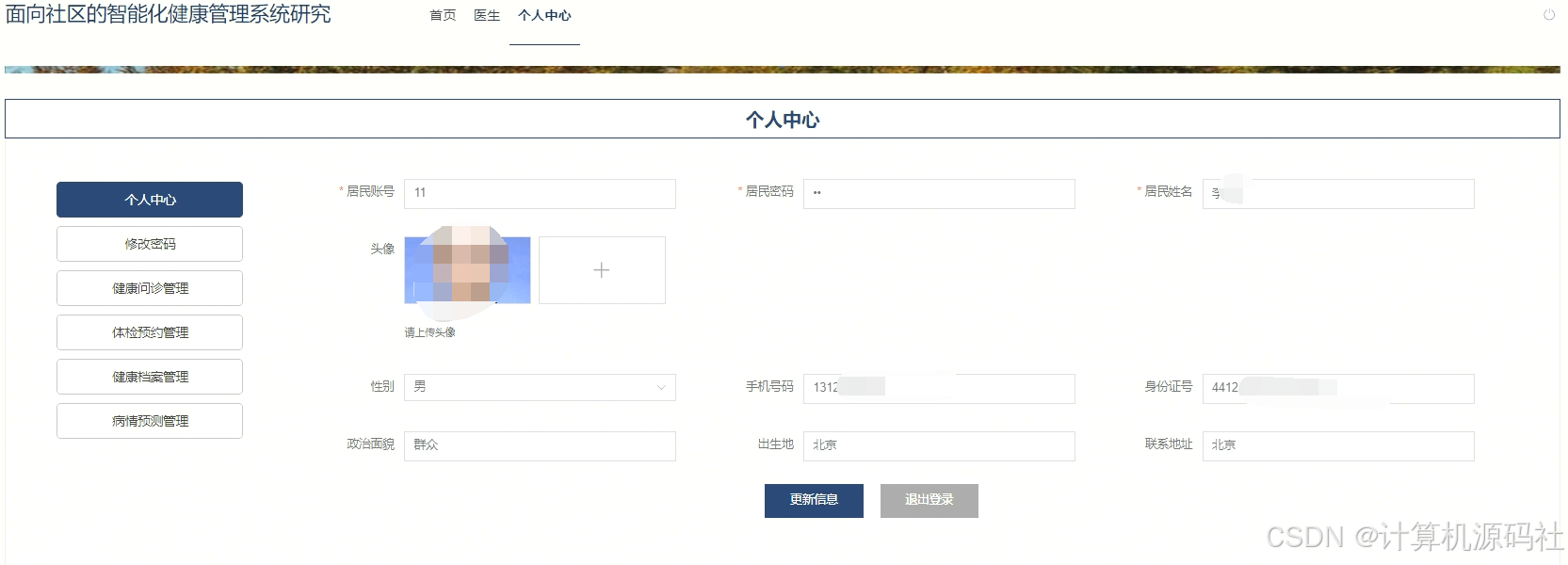
分享一个基于Spring Boot的面向社区的智能化健康管理系统的设计与实现(源码、调试、LW、开题、PPT)
💕💕作者:计算机源码社 💕💕个人简介:本人 八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流&…...

【扒代码】reduction参数是什么
model DensityMapRegressor(in_channels256, reduction8)reduction 参数在 DensityMapRegressor 类中用于决定模型在上采样过程中的层级配置。具体来说,它决定了上采样过程中使用多少个 UpsamplingLayer,从而影响输出的分辨率。 reduction 参数的作用 …...
Python,Spire.Doc模块,处理word、docx文件,极致丝滑
Python处理word文件,一般都是推荐的Python-docx,但是只写出一个,一句话的文件,也没有什么样式,就是36K。 再打开word在另存一下,就可以到7-8k,我想一定是python-docx的问题,但一直没…...

redis的安装与命令
一、redis与memcache总体对比 1.性能 Redis:只使用单核,平均每一个核上Redis在存储小数据时比Memcached性能更高。 Memcached:可以使用多核,而在100k以上的数据中,Memcached性能要高于Redis。 2.内存使用效率 Mem…...

【C++】特殊类设计类型转换
目录 💡前言一,特殊类设计1. 请设计一个类,不能被拷贝2. 请设计一个类,只能在堆上创建对象3. 请设计一个类,只能在栈上创建对象4. 请设计一个类,不能被继承5. 请设计一个类,只能创建一个对象(单…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...

在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型 开发代码辅助工具时,选择合适的模型是平衡效果与成本的关…...

SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程
SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程 【免费下载链接】speakingurl Generate a slug – transliteration with a lot of options 项目地址: https://gitcode.com/gh_mirrors/sp/speakingurl SpeakingURL是一款强大的URL友好化工具&…...

ZYNQ中断避坑指南:PL端信号线如何正确‘连线’到PS端处理函数?
ZYNQ中断系统深度解析:从硬件信号到软件响应的全链路实践 在嵌入式系统开发中,中断处理是实时响应的核心机制。对于ZYNQ这种集成了ARM处理器(PS)和可编程逻辑(PL)的异构计算平台,其中断系统既有传统处理器的特性,又具备FPGA灵活定…...