SpringBoot整合Flink(施耐德PLC物联网信息采集)
SpringBoot整合Flink(施耐德PLC物联网信息采集)
Linux环境安装kafka
前情:
施耐德PLC设备(TM200C16R)设置好信息采集程序,连接局域网,SpringBoot订阅MQTT主题,消息转至kafka,由flink接收并持久化到mysql数据库;

Wireshark抓包如下:
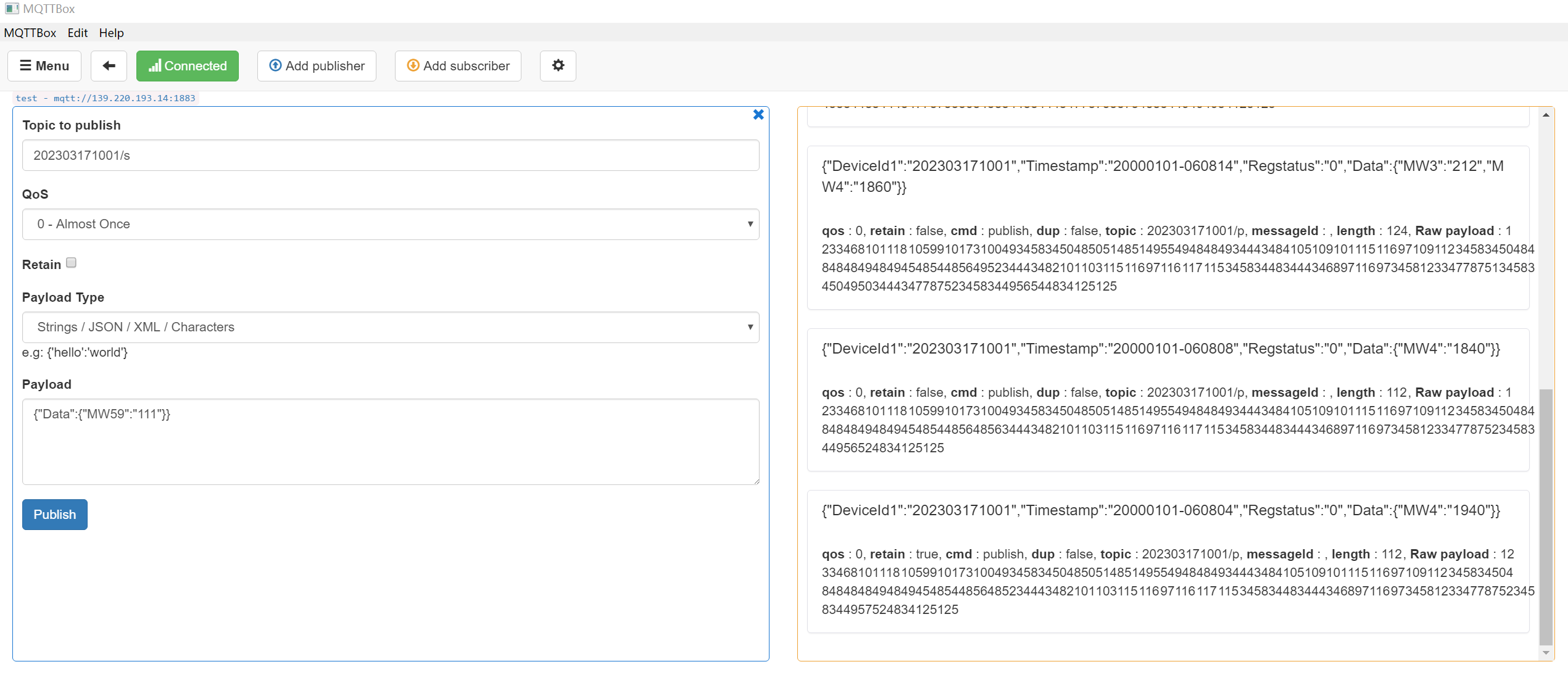
MQTTBox测试订阅如下:
已知参数:
服务器IP:139.220.193.14
端口号:1883
应用端账号:admin@tenlink
应用端密码:Tenlink@123
物联网账号:202303171001
物联网账号密码:03171001
订阅话题(topic):
202303171001/p(发布话题,由设备发送,应用端接收)
202303171001/s(订阅话题,由应用端发送,设备接收)
订阅mqtt (前提是kafka是已经就绪状态且plc_thoroughfare主题是存在的)
maven pom
<dependency><groupId>org.eclipse.paho</groupId><artifactId>org.eclipse.paho.client.mqttv3</artifactId><version>1.2.5</version></dependency>yaml配置
spring:kafka:bootstrap-servers: ip:9092producer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer## 自定义
kafka:topics:# kafka 主题plc1: plc_thoroughfareplc:broker: tcp://139.220.193.14:1883subscribe-topic: 202303171001/pusername: admin@tenlinkpassword: Tenlink@123client-id: subscribe_client订阅mqtt并将报文发送到kafka主题
import org.eclipse.paho.client.mqttv3.*;
import org.eclipse.paho.client.mqttv3.persist.MemoryPersistence;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;/*** PLC 订阅消息*/
@Component
public class SubscribeSample {private static final Logger log = LoggerFactory.getLogger(SubscribeSample.class);@Autowiredprivate KafkaTemplate<String,Object> kafkaTemplate;@Value("${kafka.topics.plc1}")private String plc1;@Value("${plc.broker}")private String broker;@Value("${plc.subscribe-topic}")private String subscribeTopic;@Value("${plc.username}")private String username;@Value("${plc.password}")private String password;@Value("${plc.client-id}")private String clientId;@PostConstructpublic void plcGather() {int qos = 0;Thread thread = new Thread(new Runnable() {@Overridepublic void run() {MqttClient client = null;try {client = new MqttClient(broker, clientId, new MemoryPersistence());// 连接参数MqttConnectOptions options = new MqttConnectOptions();options.setUserName(username);options.setPassword(password.toCharArray());options.setConnectionTimeout(60);options.setKeepAliveInterval(60);// 设置回调client.setCallback(new MqttCallback() {public void connectionLost(Throwable cause) {System.out.println("connectionLost: " + cause.getMessage());}public void messageArrived(String topic, MqttMessage message) {String data = new String(message.getPayload());kafkaTemplate.send(plc1,data).addCallback(success ->{// 消息发送到的topicString kafkaTopic = success.getRecordMetadata().topic();// 消息发送到的分区
// int partition = success.getRecordMetadata().partition();// 消息在分区内的offset
// long offset = success.getRecordMetadata().offset();log.info("mqtt成功将消息:{},转入到kafka主题->{}", data,kafkaTopic);},failure ->{throw new RuntimeException("发送消息失败:" + failure.getMessage());});}public void deliveryComplete(IMqttDeliveryToken token) {log.info("deliveryComplete---------{}", token.isComplete());}});client.connect(options);client.subscribe(subscribeTopic, qos);} catch (MqttException e) {e.printStackTrace();}}});thread.start();}
}
采集报文测试(如下图表示成功,并且已经发送到了kafka主题上)

Flink接收kafka数据
maven pom
<!--工具类 开始--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.83</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-collections4</artifactId><version>4.4</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.26</version></dependency><!--工具类 结束--><!-- flink依赖引入 开始--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.13.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>1.13.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>1.13.1</version></dependency><!-- flink连接kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>1.13.1</version></dependency><!-- flink连接es--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>1.13.1</version></dependency><!-- flink连接mysql--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-jdbc_2.11</artifactId><version>1.10.0</version></dependency><!-- flink依赖引入 结束--><!--spring data jpa--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>yaml配置
# 服务接口
server:port: 8222spring:kafka:bootstrap-servers: ip:9092consumer:group-id: kafkakey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerdatasource:url: jdbc:mysql://127.0.0.01:3306/ceshi?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghaidriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: rootdruid:initial-size: 5 #初始化时建立物理连接的个数min-idle: 5 #最小连接池数量maxActive: 20 #最大连接池数量maxWait: 60000 #获取连接时最大等待时间,单位毫秒timeBetweenEvictionRunsMillis: 60000 #配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒minEvictableIdleTimeMillis: 300000 #配置一个连接在池中最小生存的时间,单位是毫秒validationQuery: SELECT 1 #用来检测连接是否有效的sqltestWhileIdle: true #申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效testOnBorrow: false #申请连接时执行validationQuery检测连接是否有效,如果为true会降低性能testOnReturn: false #归还连接时执行validationQuery检测连接是否有效,如果为true会降低性能poolPreparedStatements: true # 打开PSCache,并且指定每个连接上PSCache的大小maxPoolPreparedStatementPerConnectionSize: 20 #要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100filters: stat,wall,slf4j #配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙#通过connectProperties属性来打开mergeSql功能;慢SQL记录connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000jpa:hibernate:ddl-auto: noneshow-sql: truerepositories:packages: com.hzh.demo.domain.*#自定义配置
customer:#flink相关配置flink:# 功能开关plc-status: trueplc-topic: plc_thoroughfare# 定时任务定时清理失效数据
task:plc-time: 0 0/1 * * * ?表结构
-- plc_test definition
CREATE TABLE `plc_test` (`pkid` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '主键id',`json_str` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT 'json格式数据',`create_time` bigint NOT NULL COMMENT '创建时间',PRIMARY KEY (`pkid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='plc存储数据测试表';启动类
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.domain.EntityScan;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.scheduling.annotation.EnableScheduling;@SpringBootApplication
@EnableJpaRepositories(basePackages = "repository basePackages")
@EntityScan("entity basePackages")
@EnableScheduling
public class PLCStorageApplication {public static void main(String[] args) {SpringApplication.run(PLCStorageApplication.class, args);}
}实体类
import lombok.Builder;
import lombok.Data;import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import java.io.Serializable;/*** PLC接收实体*/
@Table(name = "plc_test")
@Data
@Builder
@Entity
public class PLCDomain implements Serializable {private static final long serialVersionUID = 4122384962907036649L;@Id@Column(name = "pkid")public String id;@Column(name = "json_str")public String jsonStr;@Column(name = "create_time")private Long createTime;public PLCDomain(String id, String jsonStr,Long createTime) {this.id = id;this.jsonStr = jsonStr;this.createTime = createTime;}public PLCDomain() {}
}
jpa 接口
import com.hzh.demo.domain.PLCDomain;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;@Repository
public interface PLCRepository extends JpaRepository<PLCDomain,String> {}封装获取上下文工具类(ApplicationContextAware)由于加载先后顺序,flink无法使用spring bean注入的方式,特此封装工具类
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.context.i18n.LocaleContextHolder;
import org.springframework.stereotype.Component;@Component
public class ApplicationContextProviderimplements ApplicationContextAware {/*** 上下文对象实例*/private static ApplicationContext applicationContext;/*** 获取applicationContext** @return*/public static ApplicationContext getApplicationContext() {return applicationContext;}@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {ApplicationContextProvider.applicationContext = applicationContext;}/*** 通过name获取 Bean.** @param name* @return*/public static Object getBean(String name) {return getApplicationContext().getBean(name);}/*** 通过class获取Bean.** @param clazz* @param <T>* @return*/public static <T> T getBean(Class<T> clazz) {return getApplicationContext().getBean(clazz);}/*** 通过name,以及Clazz返回指定的Bean** @param name* @param clazz* @param <T>* @return*/public static <T> T getBean(String name, Class<T> clazz) {return getApplicationContext().getBean(name, clazz);}/*** 描述 : <获得多语言的资源内容>. <br>* <p>* <使用方法说明>* </p>** @param code* @param args* @return*/public static String getMessage(String code, Object[] args) {return getApplicationContext().getMessage(code, args, LocaleContextHolder.getLocale());}/*** 描述 : <获得多语言的资源内容>. <br>* <p>* <使用方法说明>* </p>** @param code* @param args* @param defaultMessage* @return*/public static String getMessage(String code, Object[] args,String defaultMessage) {return getApplicationContext().getMessage(code, args, defaultMessage,LocaleContextHolder.getLocale());}
}
FIink 第三方输出(mysql写入)
import com.hzh.demo.config.ApplicationContextProvider;
import com.hzh.demo.domain.PLCDomain;
import com.hzh.demo.repository.PLCRepository;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.stereotype.Component;import java.util.UUID;/*** 向mysql写入数据*/
@Component
@ConditionalOnProperty(name = "customer.flink.plc-status")
public class MysqlSink implements SinkFunction<String> {private static final Logger log = LoggerFactory.getLogger(MysqlSink.class);@Overridepublic void invoke(String value, Context context) throws Exception {long currentTime = context.currentProcessingTime();PLCDomain build = PLCDomain.builder().id(UUID.randomUUID().toString().replaceAll("-", "")).jsonStr(value).createTime(currentTime).build();PLCRepository repository = ApplicationContextProvider.getBean(PLCRepository.class);repository.save(build);log.info("持久化写入:{}",build);SinkFunction.super.invoke(value, context);}
}
Flink订阅kafka topic读取持续数据
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import java.util.Properties;/*** 接收 kafka topic 读取数据*/
@Component
@ConditionalOnProperty(name = "customer.flink.plc-status")
public class FlinkReceivingPLC {private static final Logger log = LoggerFactory.getLogger(MyKeyedProcessFunction.class);@Value("${spring.kafka.bootstrap-servers:localhost:9092}")private String kafkaServer;@Value("${customer.flink.plc-topic}")private String topic;@Value("${spring.kafka.consumer.group-id:kafka}")private String groupId;@Value("${spring.kafka.consumer.key-deserializer:org.apache.kafka.common.serialization.StringDeserializer}")private String keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer:org.apache.kafka.common.serialization.StringDeserializer}")private String valueDeserializer;/*** 执行方法** @throws Exception 异常*/@PostConstructpublic void execute(){final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.enableCheckpointing(5000);//设定全局并发度env.setParallelism(1);Properties properties = new Properties();//kafka的节点的IP或者hostName,多个使用逗号分隔properties.setProperty("bootstrap.servers", kafkaServer);//kafka的消费者的group.idproperties.setProperty("group.id", groupId);properties.setProperty("key-deserializer",keyDeserializer);properties.setProperty("value-deserializer",valueDeserializer);FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties);DataStream<String> stream = env.addSource(myConsumer);stream.print().setParallelism(1);stream//分组.keyBy(new KeySelector<String, String>() {@Overridepublic String getKey(String value) throws Exception {return value;}})//指定处理类
// .process(new MyKeyedProcessFunction())//数据第三方输出,mysql持久化.addSink(new MysqlSink());//启动任务new Thread(() -> {try {env.execute("PLCPersistenceJob");} catch (Exception e) {log.error(e.toString(), e);}}).start();}
}失效数据清理机制(为了方便测试,所以清理机制执行频率高且数据失效低)
import com.hzh.demo.repository.PLCRepository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import java.util.Optional;/*** 定时任务配置*/
@Component
@Configuration
public class QutrzConfig {private static final Logger log = LoggerFactory.getLogger(QutrzConfig.class);@Autowiredprivate PLCRepository plcRepository;/*** 数据清理机制*/@Scheduled(cron = "${task.plc-time}")private void PLCCleaningMechanism (){log.info("执行数据清理机制:{}","PLCCleaningMechanism");long currentTimeMillis = System.currentTimeMillis();Optional.of(this.plcRepository.findAll()).ifPresent(list ->{list.forEach(plc ->{Long createTime = plc.getCreateTime();//大于1分钟为失效数据if ((currentTimeMillis - createTime) > (1000 * 60 * 1) ){this.plcRepository.delete(plc);log.info("过期数据已经被清理:{}",plc);}});});}
}
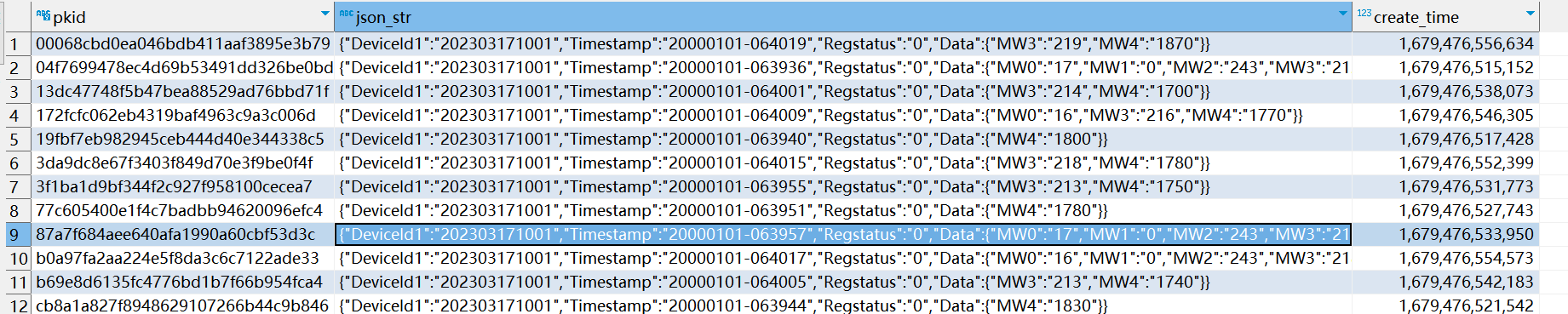
测试结果
mysql入库数据
相关文章:
SpringBoot整合Flink(施耐德PLC物联网信息采集)
SpringBoot整合Flink(施耐德PLC物联网信息采集)Linux环境安装kafka前情:施耐德PLC设备(TM200C16R)设置好信息采集程序,连接局域网,SpringBoot订阅MQTT主题,消息转至kafka,…...

DFS(深度优先搜索)和BFS(宽度优先搜索)
目录 DFS(深度优先搜索) 全排列的DFS解法 利用DFS递归构建二进制串和递归树的结构剖析 DFS--剪枝 DFS例题--整数划分 BFS(宽度优先搜索) 全排列的BFS解法 DFS(深度优先搜索) 深度优先搜索(Depth First Search&…...

Redis缓存穿透、击穿、雪崩问题及解决方法
系列文章目录 Spring Cache的使用–快速上手篇 分页查询–Java项目实战篇 全局异常处理–Java实战项目篇 完善登录功能–过滤器的使用 上述只是部分文章,对该系列文章感兴趣的可以查看我的主页哦 文章目录系列文章目录前言一、缓存穿透1.1 问题引入1.2 解决方法1.…...

HAL库 STM32 串口通信
一、实验条件将STM32的PA9复用为串口1的TX,PA10复用为串口1的RX。STM32芯片的输出TX和接收RX与CH340的接收RX和发送TX相连(收发交叉且PCB上默认没有相连,所以需要用P3跳线帽进行手动连接),CH340的另一端通过USB口引出与…...

2023-第十四届蓝桥杯冲刺计划!
💬前言 💡本文以目录形式列举大纲,可根据题目点击跳转 🌈冲刺阶段目的:把握高频重点,结合基础算法和常考题型总结,用真题进行模拟练习 根据自己的能力熟练目前已掌握的算法,不会的还可以暴力 ⏳最后三个星期大家一起冲…...
内网渗透基础知识
一、内网概述 内网也指局域网,是指在某一区域内又多台计算机互联成的计算机组。一般是方圆几千米内,局域网可以实现文件管理,应用软件共享,打印机共享,工作组内的历程安排,电子邮件和传真通信服务等功能。…...

鸟哥的Linux私房菜 正则表示法与文件格式化处理
第十一章、正则表示法与文件格式化处理 https://linux.vbird.org/linux_basic/centos7/0330regularex.php 简体版 http://cn.linux.vbird.org/linux_basic/0330regularex.php 11.2.2 grep的一些高级选项 例题一、搜索特定字符串 例题二、利用中括号 [] 来搜寻集合字符 例题四…...
1630.等差子数组
1630. 等差子数组 难度中等 如果一个数列由至少两个元素组成,且每两个连续元素之间的差值都相同,那么这个序列就是 等差数列 。更正式地,数列 s 是等差数列,只需要满足:对于每个有效的 i , s[i1] - s[i] …...
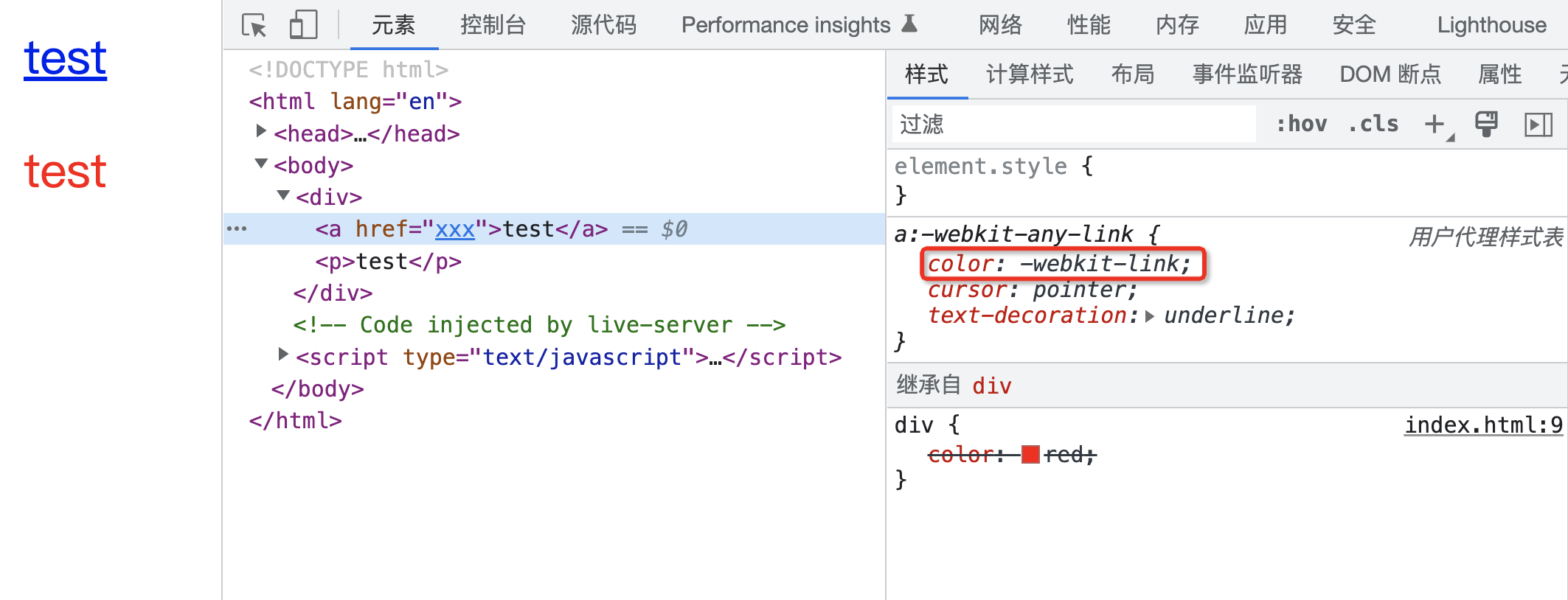
CSS 属性计算过程
CSS 属性计算过程 你是否了解 CSS 的属性计算过程呢? 有的同学可能会讲,CSS属性我倒是知道,例如: p{color : red; }上面的 CSS 代码中,p 是元素选择器,color 就是其中的一个 CSS 属性。 但是要说 CSS 属…...

ThinkPHP02:路由
ThinkPHP02:路由一、路由定义二、变量规则三、路由地址四、路由参数五、路由分组六、MISS七、资源路由八、注解路由九、URL生成一、路由定义 路由默认开启,在 config/app.php 中可以关闭路由。 路由配置在 config/route.php 中,路由定义在 r…...

制作简单进销存管理系统(C#)
实验三:制作简单进销存管理系统 任务要求: 在进销存管理系统中,商品的库存信息有很多种类,比如商品型号、商品名称、商品库存量等。在面向对象编程中,这些商品的信息可以存储到属性中,然后当需要使用这些…...
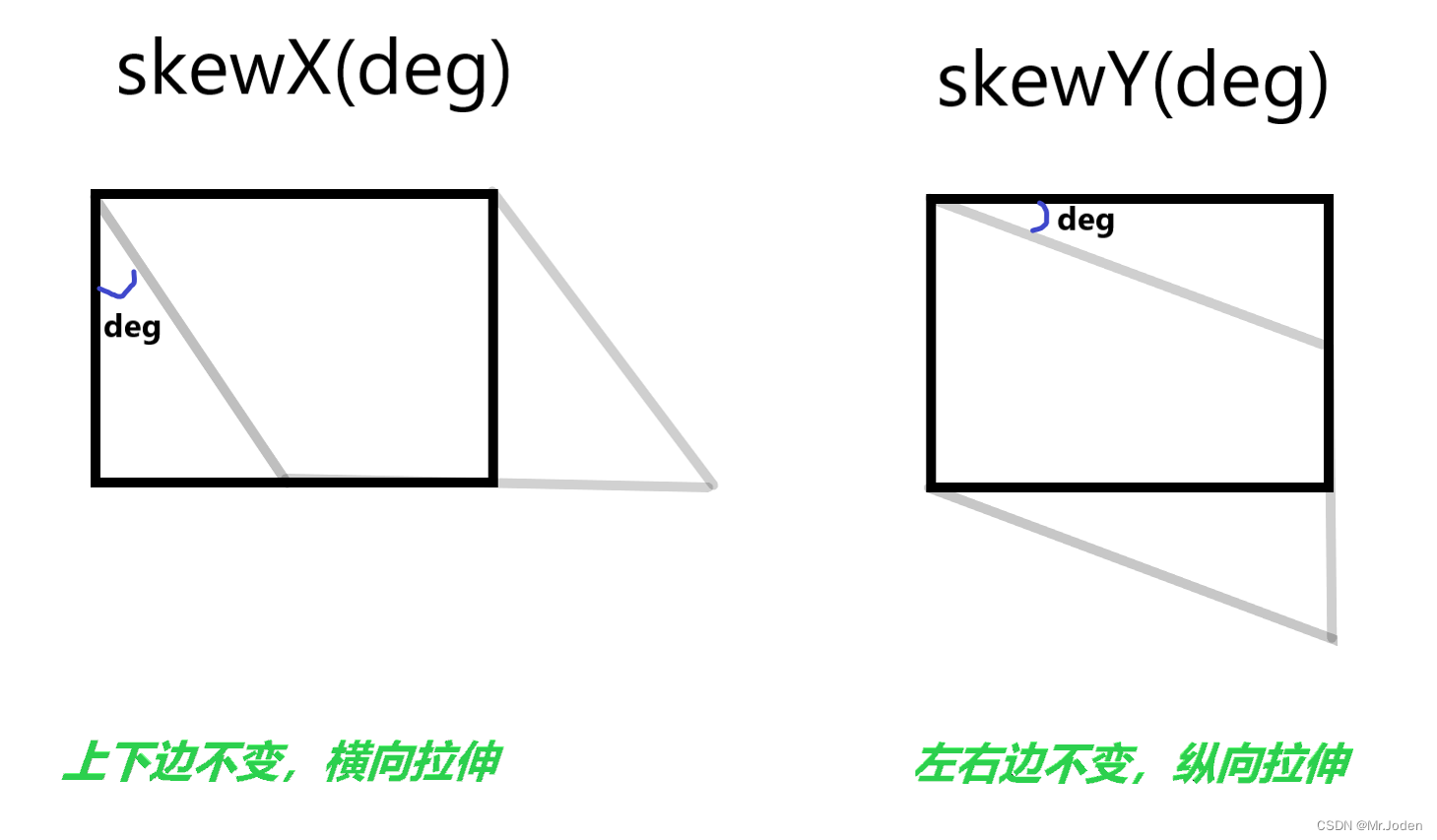
css总结9(过渡和2D变换)
目录 过渡 2D变换 3D变换 过渡 属性结构图 过渡补充 ### 过渡多个元素样式属性 transition:style1 duration , style2 duration,...; ### 过渡所有属性 transition: all duration; 简单示例 ### 移入时改变长度且加入过渡效果 div { width:100px; height:100px; …...
SpringBoot 结合RabbitMQ与Redis实现商品的并发下单【SpringBoot系列12】
SpringCloud 大型系列课程正在制作中,欢迎大家关注与提意见。 程序员每天的CV 与 板砖,也要知其所以然,本系列课程可以帮助初学者学习 SpringBooot 项目开发 与 SpringCloud 微服务系列项目开发 1 项目准备 SpringBoot 整合 RabbitMQ 消息队…...

【python进阶】序列切片还能这么用?切片的强大比你了解的多太多
📚引言 🙋♂️作者简介:生鱼同学,大数据科学与技术专业硕士在读👨🎓,曾获得华为杯数学建模国家二等奖🏆,MathorCup 数学建模竞赛国家二等奖🏅,…...
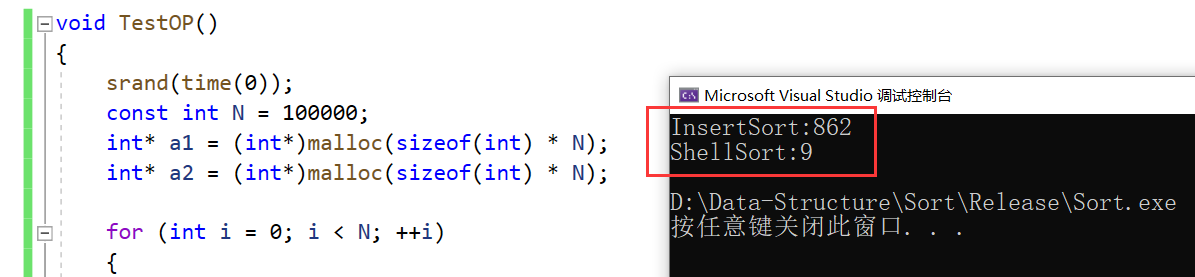
[数据结构]直接插入排序、希尔排序
文章目录排序的概念和运用排序的概念排序运用常见的排序算法常见的排序算法直接插入排序希尔排序性能对比排序的概念和运用 排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操…...

CNN、LeNet、AlexNet、VGG、GoogLeNet、RCNN、Fast RCNN、Faster RCNN、YOLO、YOLOv2、SSD等的关系
卷积神经网络的现状1943年美国数学家提出人工智能1949年心理学家建立神经元模型1957年弗兰克提出 感知器人工神经网络模型1980年建立多层感知器模型1984日本学者提出卷积神经网络原始模型神经感知机1998年提出LeNet-5卷积神经网络,并发展了其在音符和字符上的优势20…...
)
IO-day1-(fscanf、fprintf.........)
作业一、有一个usr.txt的文件,其中存储着用户的账户和密码,格式如下:zhangsan aaaalisi bbbbb空格前面是账户,空格后面是密码,一行一个账户、密码要求如下:从终端获取一个账户名和密码判断是否能够登录成功…...
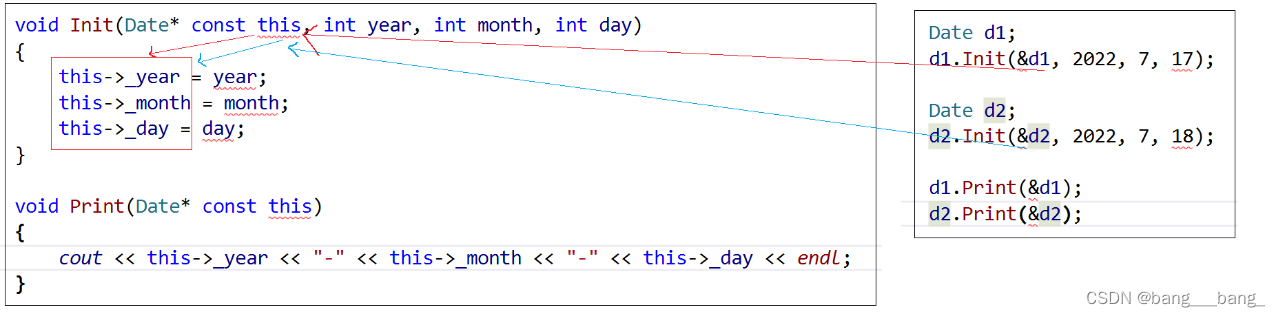
C++类和对象(上篇)
目录 1.类的定义 2.类的访问限定符及封装 2.1类的访问限定符 2.2封装 3.类的作用域 4.类的实例化 5.类的大小 6.this 指针 1.类的定义 class className {// 类体:由成员函数和成员变量组成}; // 一定要注意后面的分号 class为定义类的关键字,Clas…...
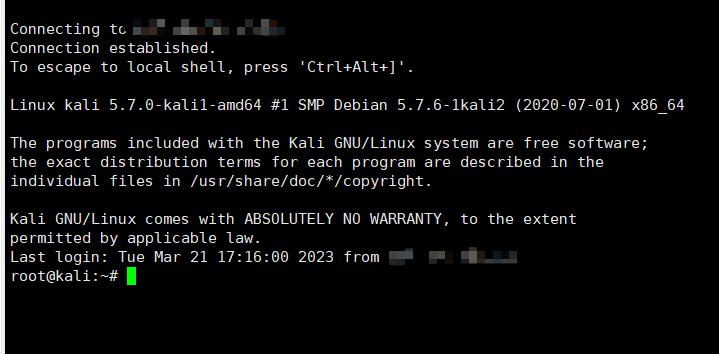
解决Xshell无法连接Kali Linux 2020.1(2019.3)版本
使用Xshell远程终端工具连接虚拟机的Kali Linux却提示连接不上原因:Kali Linux默认没有打开SSH远程登录,SSH就是一种网络协议,用于加密的远程登录,所以在没有打开SSH协议之前是无法使用Xshell连接Kali Linux的。解决办法ÿ…...
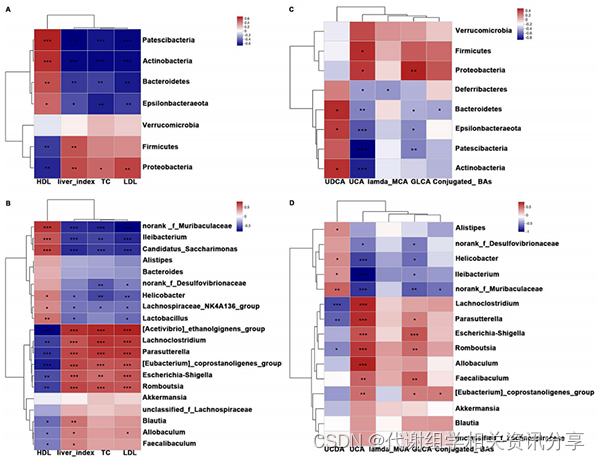
项目文章 | 缓解高胆固醇血症 ,浒苔多糖如何相助?
文章标题:Polysaccharides from Enteromorpha prolifera alleviate hypercholesterolemia via modulating the gut microbiota and bile acid metabolism 发表期刊:Food & Function 影响因子:6.317 作者单位:福建医科大…...

Matlab中的QRBiGRU分位数回归双向门控循环单元模型:多图输出与多指标评估的时间序列区间预测
Matlab实现基于QRBiGRU分位数回归双向门控循环单元的时间序列区间预测模型: 1.Matlab实现基于QRBiGRU分位数回归双向门控循环单元的时间序列区间预测模型 2.多图输出、多指标输出(MAE、RMSE、MSE、R2),多输入单输出,含不同置信区间图、概率密…...

3步在Mac上免费运行Stable Diffusion的终极指南
3步在Mac上免费运行Stable Diffusion的终极指南 【免费下载链接】MochiDiffusion Run Stable Diffusion on Mac natively 项目地址: https://gitcode.com/gh_mirrors/mo/MochiDiffusion 还在为寻找合适的Mac AI绘画工具而烦恼吗?想要完全离线生成惊艳的AI艺术…...
)
Anaconda+AKShare保姆级教程:5分钟搞定Python量化环境(附常见报错解决方案)
AnacondaAKShare极速配置指南:零基础搭建Python量化环境全攻略 刚接触量化投资的新手们,往往在第一步——环境搭建上就卡壳了。明明跟着教程一步步操作,却总是遇到各种报错提示,让人望而生畏。本文将手把手带你用Anaconda和AKSha…...
)
STM32F103C8T6 DHT11温湿度监测系统 HAL库 CubeMX实战(避坑指南)
1. 项目背景与硬件选型 温湿度监测是物联网领域最基础也最实用的功能之一。我最近用STM32F103C8T6和DHT11搭建了一个环境监测节点,整个过程踩了不少坑,也积累了一些实战经验。这个方案特别适合需要低成本、快速上手的场景,比如智能家居、农业…...

告别蓝牙!用STM32F103和NRF24L01搭建低成本2.4G无线通信,实测传输距离与稳定性
STM32F103与NRF24L01构建高性能2.4G私有通信系统实战指南 在物联网设备爆发式增长的今天,无线通信模块的选择成为硬件开发者面临的首要难题。面对市面上琳琅满目的蓝牙、Wi-Fi和私有协议模块,如何根据项目需求选择最具性价比的解决方案?本文将…...

当地的美国展会搭建制作公司口碑排行
随着中国企业出海参展日益频繁,选择一家可靠的美国本土搭建商成为关键决策。许多企业主发现,直接对接海外供应商时,常面临沟通不畅、报价模糊、落地效果与设计图相差甚远等问题。这背后,是原有依赖单一信息渠道或熟人推荐的模式正…...

如何用SVGnest提升材料利用率:从问题到解决方案的完整指南
如何用SVGnest提升材料利用率:从问题到解决方案的完整指南 【免费下载链接】SVGnest An open source vector nesting tool 项目地址: https://gitcode.com/gh_mirrors/sv/SVGnest 制造业材料浪费的隐形成本:您的企业是否正在损失30%利润ÿ…...

STC89C52单片机+槽型光耦,手把手教你DIY一个低成本电机转速测量仪
STC89C52单片机槽型光耦DIY电机转速测量仪实战指南 从零搭建低成本测速系统的完整方案 电机转速测量在工业控制、机器人开发、智能小车等领域都是基础但关键的环节。市面上专业测速仪动辄上千元的价格让许多电子爱好者望而却步。其实,利用手头常见的STC89C52单片机…...
)
Surface硬盘不够用?教你用cfadisk把SD卡变本地硬盘(附详细图文)
Surface硬盘扩容实战:用cfadisk将SD卡完美变身本地存储 每次打开Surface的存储设置,看到那根触目惊心的红色容量条,相信不少用户都会感到焦虑。作为微软旗下最受欢迎的移动生产力工具,Surface系列在便携性和性能上表现出色&#x…...

OpenClaw技能开发入门:为Qwen3-VL:30B编写图片翻译插件
OpenClaw技能开发入门:为Qwen3-VL:30B编写图片翻译插件 1. 为什么需要自定义技能开发 去年冬天,我接手了一个跨国团队的文档协作项目,每天需要处理大量包含多语言图片的飞书消息。当我在深夜第三次手动将日文截图粘贴到翻译软件时ÿ…...