黑马在线教育数仓实战1
1. 教育项目的架构说明
项目的架构:
基于cloudera manager大数据统一管理平台, 在此平台之上构建大数据相关的软件(zookeeper,HDFS,YARN,HIVE,OOZIE,SQOOP,HUE...), 除此以外, 还使用FINEBI实现数据报表展示
各个软件相关作用:
zookeeper: 集群管理工具, 主要服务于hadoop高可用以及其他基于zookeeper管理的大数据软件
HDFS: 主要负责最终数据的存储
YARN: 主要提供资源的分配
HIVE: 用于编写SQL, 进行数据分析
oozie: 主要是用来做自动化定时调度
sqoop: 主要是用于数据的导入导出
HUE: 提升操作hadoop用户体验, 可以基于HUE操作HDFS, HIVE ....
FINEBI: 由帆软公司提供的一款进行数据报表展示工具
项目架构中: 数据流转的流程
首先业务是存储在MySQL数据库中, 通过sqoop对MySQL的数据进行数据的导入操作, 将数据导入到HIVE的ODS层中, 对数据进行清洗转换成处理工作, 处理之后对数据进行统计分析, 将统计分析的结果基于sqoop在导出到MySQL中, 最后使用finebi实现图表展示操作, 由于分析工作是需要周期性干活, 采用ooize进行自动化的调度工作, 整个项目是基于cloudera manager进行统一监控管理

2. cloudera manager基本介绍
大数据的发行版本, 主要有三个发行版本: Apache 官方社区版本, cloudera 推出CDH商业版本, Hortworks推出的HDP商业免费版本, 目前HDP版本已经被cloudera 收购了
Apache版本Hadoop生态圈组件的优点和弊端:
优点:
-
完全开源,更新速度很快
-
大数据组件在部署过程中可以深刻了解其底层原理
-
可以了解各个组件的依赖关系
缺点
-
部署过程极其复杂,超过20个节点的时候,手动部署已经超级累
-
各个组件部署完成后,各个为政,没有统一化管理界面
-
组件和组件之间的依赖关系很复杂,一环扣一环,部署过程心累
-
各个组件之间没有统一的metric可视化界面,比如说hdfs总共占用的磁盘空间、IO、运行状况等
-
优化等需要用户自己根据业务场景进行调整(需要手工的对每个节点添加更改配置,效率极低,我们希望的是一个配置能够自动的分发到所有的节点上)
为了解决上述apache产生问题, 出现了一些商业化大数据组件, 其中以 cloudera 公司推出 CDH版本为主要代表
CDH是Apache Hadoop和相关项目中最完整、最稳定的、经过测试和最流行的发行版。 CDH出现帮助解决了各个软件之间的兼容问题, 同时内置大量的常规企业优化方案, 为了提供用户体验, 专门推出一款用于监控管理自家产品的大数据软件: cloudera manager
Cloudera Manager是用于管理CDH群集的B/S应用程序
使用Cloudera Manager,可以轻松部署和集中操作完整的CDH堆栈和其他托管服务(Hadoop、Hive、Spark、Kudu)。其特点:应用程序的安装过程自动化,将部署时间从几周缩短到几分钟; 并提供运行主机和服务的集群范围的实时监控视图; 提供单个中央控制台,以在整个群集中实施配置更改; 并集成了全套的报告和诊断工具,可帮助优化性能和利用率。
教育项目中虚拟机, 坚决不允许挂起, 以及强制关闭操作, 如果做了, 非常大的概率导致服务器出现内存以及磁盘问题, 需要重新解压
关机必须在CRT上直接关机命令: shutdown -h now (每一个节点都要执行)
重启服务器: 执行 reboot (每一个节点都要执行)
需要注意: 如果将虚拟机放置在机械磁盘的, 如果长时间不使用这几个虚拟机, 建议将其关闭, 固态盘一般没啥问题, 但是依然建议关闭
4. 数据仓库的基本概念
回顾1: 什么是数据仓库
存储数据的仓库, 主要是用于存储过去既定发生的历史数据, 对这些数据进行数据分析的操作, 从而对未来提供决策支持回顾2: 数据仓库最大的特点:
既不生产数据, 也不消耗数据, 数据来源于各个数据源回顾3: 数据仓库的四大特征:
1) 面向于主题的: 面向于分析, 分析的内容是什么 什么就是我们的主题
2) 集成性: 数据是来源于各个数据源, 将各个数据源数据汇总在一起
3) 非易失性(稳定性): 存储在数据仓库中数据都是过去既定发生数据, 这些数据都是相对比较稳定的数据, 不会发生改变
4) 时变性: 随着的推移, 原有的分析手段以及原有数据可能都会出现变化(分析手动更换, 以及数据新增)回顾3: ETL是什么
ETL: 抽取 转换 加载指的: 数据从数据源将数据灌入到ODS层, 以及从ODS层将数据抽取出来, 对数据进行转换处理工作, 最终将数据加载到DW层, 然后DW层对数据进行统计分析, 将统计分析后的数据灌入到DA层, 整个全过程都是属于ETL范畴狭义上ETL: 从ODS层到DW层过程回顾四: 数据仓库和 数据库的区别
数据库(OLTP): 面向于事务(业务)的 , 主要是用于捕获数据 , 主要是存储的最近一段时间的业务数据, 交互性强 一般不允许出现数据冗余
数据仓库(OLAP): 面向于分析(主题)的 , 主要是用于分析数据, 主要是存储的过去历史数据 , 交互性较弱 可以允许出现一定的冗余
数据仓库和数据集市:
数据仓库其实指的集团数据中心: 主要是将公司中所有的数据全部都聚集在一起进行相关的处理操作 (ODS层)此操作一般和主题基本没有什么太大的关系数据的集市(小型数据仓库): 在数据仓库基础之上, 基于主题对数据进行抽取处理分析工作, 形成最终分析的结果一个数据仓库下, 可以有多个数据集市5. 维度分析
维度分析: 针对某一个主题, 可以从不同的维度的进行统计分析, 从而得出各种指标的过程
- 什么是维度:
维度一般指的分析的角度, 看待一个问题的时候, 可以多个角度来看待, 而这些角度指的就是维度比如: 有一份2020年订单数据, 请尝试分析可以从时间, 地域 , 商品, 来源 , 用户....维度的分类:定性维度: 指的计算每天 每月 各个的维度 , 一般来说定性维度的字段都是放置在group by 中定量维度: 指的统计某一个具体的维度或者某一个范围下信息, 比如说: 2020年度订单额, 统计20~30岁区间人群的人数 ,一般来说这种维度的字段都是放置在where中维度的分层和分级: 本质上对维度进行细分的过程比如按年统计: 按季度按照月份按照天按照每个小时比如: 按省份统计:按市按县从实际分析中, 统计的层级越多, 意味统计的越细化 设置维度内容越多维度的下钻和上卷: 以某一个维度为基准, 往细化统计的过程称为下钻, 往粗粒度称为上卷比如: 按照 天统计, 如果需要统计出 小时, 指的就是下钻, 如果需要统计 季度 月 年, 称为上卷统计从实际分析中, 下钻和上卷, 意味统计的维度变得更多了- 什么是指标
指标指的衡量事务发展的标准, 就是度量值常见的度量值: count() sum() max() min() avg() 还有一些 比例指标(转化率, 流失率, 同比..)指标的分类:绝对指标: 计算具体的值指标count() sum() max() min() avg()相对指标: 计算比率问题的指标转化率, 流失率, 同比案例:
需求: 请求出在2020年度, 女性 未婚 年龄在18~25岁区间的用户每一天的订单量?维度: 时间维度 , 性别, 婚姻状态, 年龄定性维度: 每一天定量维度: 2020年度,18~25岁,女性,未婚指标: 订单量(绝对指标) --> count()select day,count(1) from 表 where year ='2020' and age between 18 and 25 and 婚姻='未婚' and sex = '女性' group by day;
6. 数仓建模
数仓建模指的规定如何在hive中构建表, 数仓建模中主要提供两种理论来进行数仓建模操作: 三范式建模和维度建模理论
三范式建模: 主要是存在关系型数据库建模方案上, 主要规定了比如建表的每一个表都应该有一个主键, 数据要经历的避免冗余发生等等
维度建模: 主要是存在分析性数据库建模方案上, 主要一切以分析为目标, 只要是利于分析的建模, 都是OK的, 允许出现一定的冗余, 表也可以没有主键
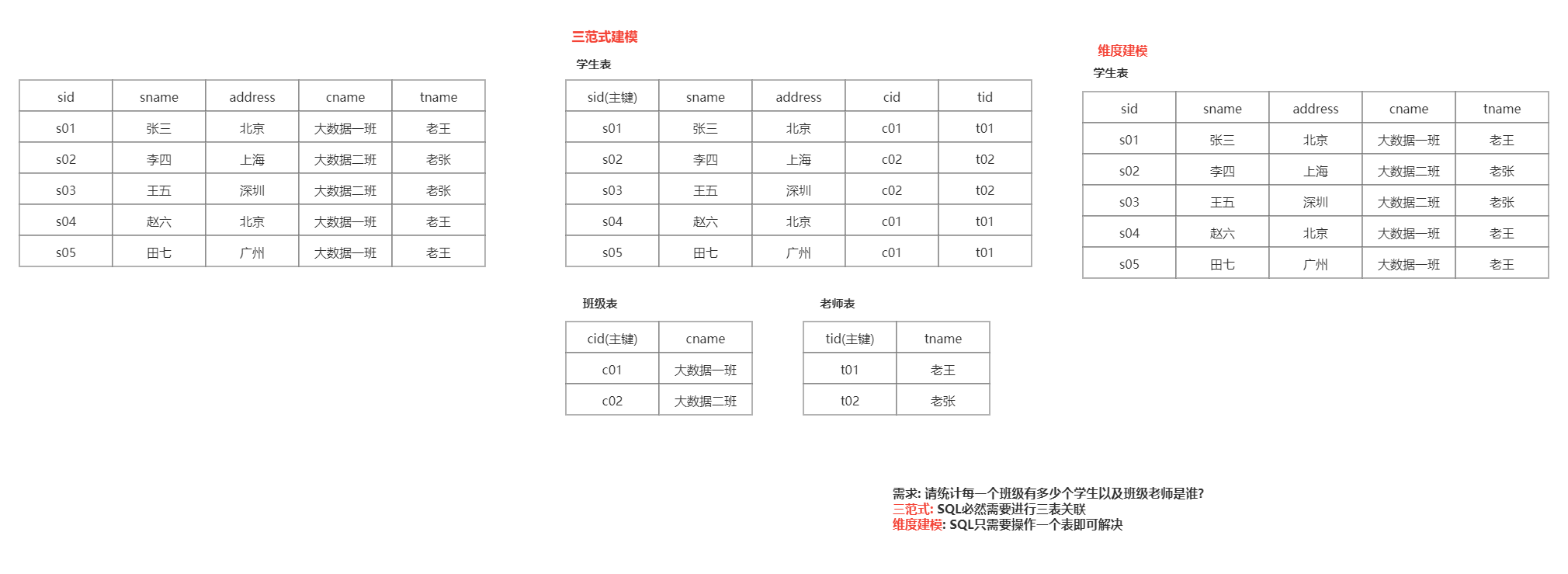
维度建模的两个核心概念:事实表和维度表。
6.1 事实表
事实表: 事实表一般指的就是分析主题所对应的表,每一条数据用于描述一个具体的事实信息, 这些表一般都是一坨主键(外键)和描述事实字段的聚集
例如: 比如说统计2020年度订单销售情况 主题: 订单
相关表: 订单表(事实表)
思考: 在订单表, 一条数据, 是不是描述一个具体的订单信息呢? 是的
思考: 在订单表, 一般有那些字段呢? 订单的ID, 商品id,单价,购买的数量,下单时间, 用户id,商家id, 省份id, 市区id, 县id 商品价格...进行统计分析的时候, 可以结合 商品维度, 用户维度, 商家维度, 地区维度 进行统计分析, 在进行统计分析的时候, 可能需要关联到其他的表(维度表)注意:一般需要计算的指标字段所在表, 都是事实表事实表的分类:
1) 事务事实表:保存的是最原子的数据,也称“原子事实表”或“交易事实表”。沟通中常说的事实表,大多指的是事务事实表。
2) 周期快照事实表:周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,时间间隔如每天、每月、每年等等周期表由事务表加工产生
3) 累计快照事实表:完全覆盖一个事务或产品的生命周期的时间跨度,它通常具有多个日期字段,用来记录整个生命周期中的关键时间点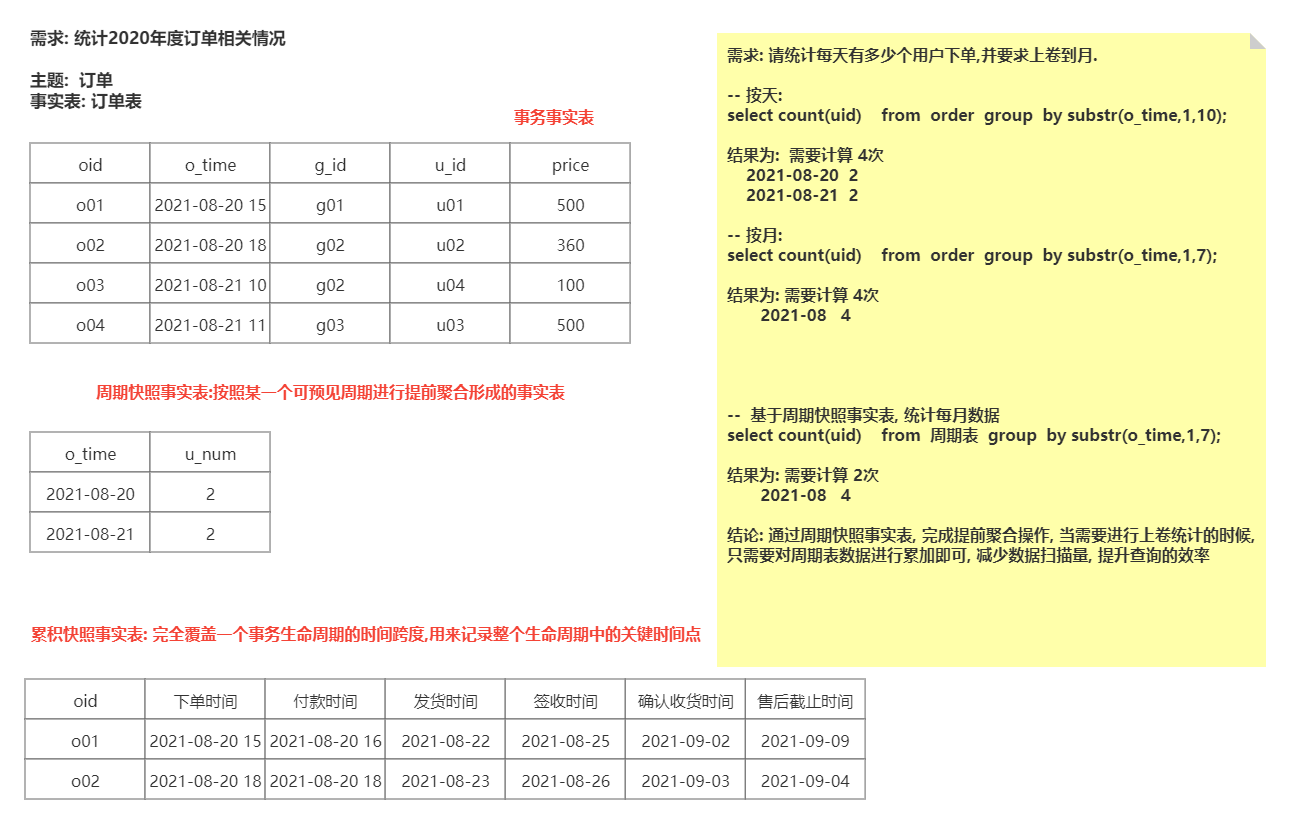
6.2 维度表
维度表: 指的在对事实表进行统计分析的时候, 基于某一个维度, 二这个维度信息可能其他表中, 而这些表就是维度表
维度表并不一定存在, 但是维度是一定存在:比如: 根据用户维度进行统计, 如果在事实表只存储了用户id, 此时需要关联用户表, 这个时候就是维度表比如: 根据用户维度进行统计, 如果在事实表不仅仅存储了用户id,还存储用户名称, 这个时候有用户维度, 但是不需要用户表的参与, 意味着没有这个维度表维度表的分类:
高基数维度表: 指的表中的数据量是比较庞大的, 而且数据也在发送的变化例如: 商品表, 用户表低基数维度表: 指的表中的数据量不是特别多, 一般在几十条到几千条左右,而且数据相对比较稳定例如: 日期表,配置表,区域表6.3 维度建模的三种模型
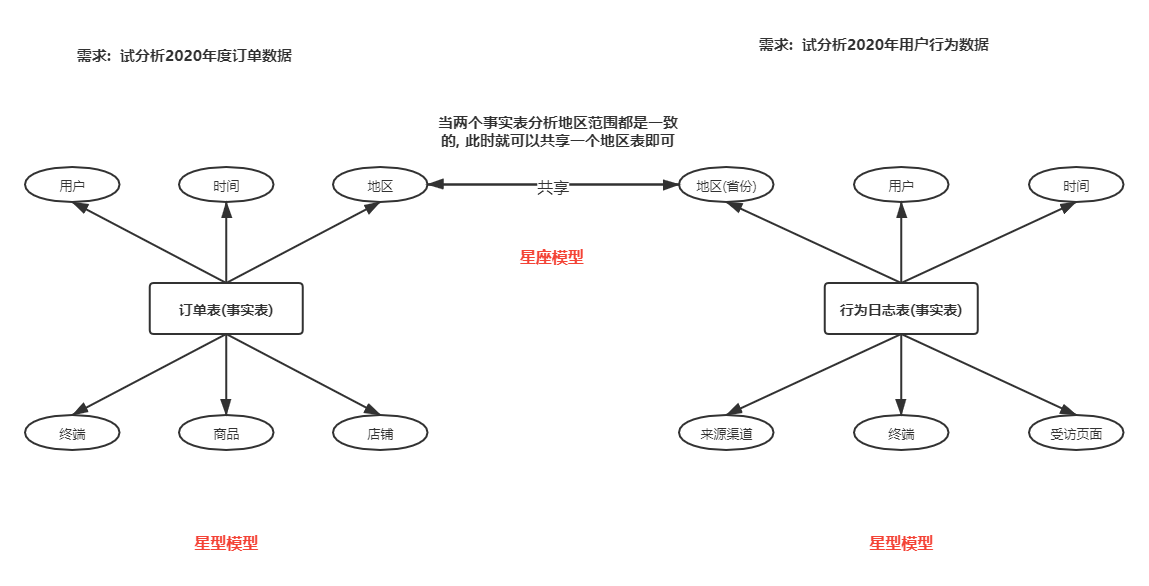
- 第一种: 星型模型
- 特点: 只有一个事实表, 那么也就意味着只有一个分析的主题, 在事实表的周围围绕了多个维度表, 维度表与维度表之间没有任何的依赖
- 反映数仓发展初期最容易产生模型
- 第二种: 雪花模型
- 特点: 只有一个事实表, 那么也就意味着只有一个分析的主题, 在事实表的周围围绕了多个维度表, 维度表可以接着关联其他的维度表
- 反映数仓发展出现了畸形产生模型, 这种模型一旦大量出现, 对后期维护是非常繁琐, 同时如果依赖层次越多, SQL分析的难度也会加大
- 此种模型在实际生产中,建议尽量减少这种模型产生
- 第三种: 星座模型
- 特点: 有多个事实表, 那么也就意味着有了多个分析的主题, 在事实表的周围围绕了多个维度表, 多个事实表在条件符合的情况下, 可以共享维度表
- 反映数仓发展中后期最容易产生模型
6.4 缓慢渐变维
解决问题: 解决历史变更数据是否需要维护的情况
- SCD1: 直接覆盖, 不维护历史变化数据
- 主要适用于: 对错误数据处理
- **SCD2:不删除、不修改已存在的数据, 当数据发生变更后, 会添加一条新的版本记录的数据, 在建表的时候, 会多加两个字段(起始时间, 截止时间), 通过这两个字段来标记每条数据的起止时间 , 一般称为拉链表**
- 好处: 适用于保存多个历史版本, 方便维护实现
- 弊端: 会造成数据冗余情况, 导致磁盘占用率提升
- SCD3: 通过在增加列的方式来维护历史变化数据
- 好处: 减少数据的冗余, 适用于少量历史版本的记录以及磁盘空间不是特别充足情况
- 弊端: 无法记录更多的历史版本, 以及维护比较繁琐
相关文章:
黑马在线教育数仓实战1
1. 教育项目的架构说明 项目的架构: 基于cloudera manager大数据统一管理平台, 在此平台之上构建大数据相关的软件(zookeeper,HDFS,YARN,HIVE,OOZIE,SQOOP,HUE...), 除此以外, 还使用FINEBI实现数据报表展示 各个软件相关作用: zookeeper: 集群管理工具, 主要服务于…...

python中pandas模块数据处理小案例
内容目录1. 添加随机日期2. 聚合求和3.聚合求和排序4. 聚合求和排序取前十5. 聚合取极值6. 重新赋值7. 按条件赋值pandas作为数据处理的得力工具,简便了数据开发过程,之前串联了pandas的使用方法,现在用几个小案例巩固一下常用的pandas方法。…...
机制)
从 X 入门Pytorch——Tensor的自动微分、计算图,常见的with torch.no_grad()机制
这里写目录标题1 Pytorch计算图和自动微分2 将单个数据从计算图中剥离 .detach3 使用with torch.go_grad(): 包含的代码段不会计算微分1 Pytorch计算图和自动微分 从功能上理解: 计算图就是类似于数据结构中的无环有向图,Pytorch中的计算图就是为了记录…...
三十七、实战演练之接口自动化平台的文件上传
上传文件功能 上传文件功能主要针对需要测试上传文件的接口。原理是,把要测试上传的文件先上传到测试平台,然后把路径写入 用例中,后台真正测试时再将其进行上传。 一、上传文件模型 在testplans/models.py 模块中编写如下模型:…...

菜鸟刷题Day1
菜鸟刷题Day1 一.自守数:自守数_牛客题霸_牛客网 (nowcoder.com) 描述 自守数是指一个数的平方的尾数等于该数自身的自然数。例如:25^2 625,76^2 5776,9376^2 87909376。请求出n(包括n)以内的自守数的个数 解题思路&#x…...
cjson文件格式介绍
cjson是一种轻量级的JSON解析库,它支持将JSON格式的数据转换为C语言中的数据结构,同时也支持将C语言中的数据结构转换为JSON格式的数据。cjson的文件格式是指在使用cjson库时,将JSON格式的数据存储在文件中,然后通过cjson库读取文…...
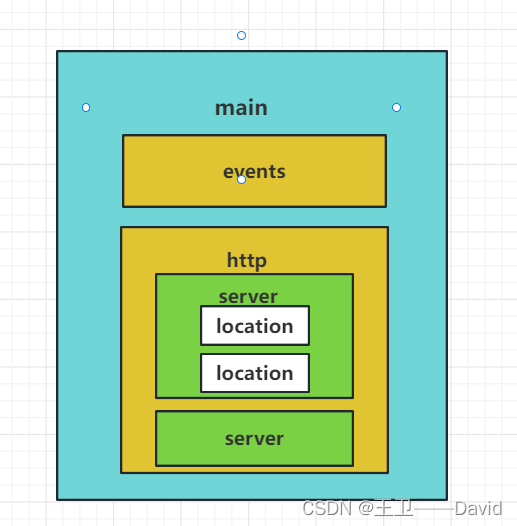
【Nginx二】——Nginx常用命令 配置文件
Nginx常用命令 配置文件常用命令启动和重启 Nginx配置文件maineventshttp常用命令 安装完成nginx后,输入 nginx -?查询nginx命令行参数 nginx version: nginx/1.22.1 Usage: nginx [-?hvVtTq] [-s signal] [-p prefix][-e filename] [-c filename] [-…...
3月最新!AIGC公司生态地图;开发者实用ChatGPT工具清单;上手必会的SD绘图教程;字幕组全自动化流程大公开 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 『光年之外诚邀产品经理加入』古典产品经理的复兴! 光年之外创始人王慧文在社交平台发帖,公布联合创始人团队基…...

python - 递归函数
递归函数 什么是递归 在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数 递归函数必须有一个明确的结束条件每进入更深一层的递归时,问题规模相对于上一次递归都应减少相邻两次重复之间有紧密的联系&…...

ring_log环形日志-6M缓冲区_proc接口
文章目录log_tools.clog.cspin_lockseq_putsseq_readseq_writesingle_openmakefiletest.sh测试:运行./test.sh读取日志插入日志echo cat测试参考:log_tools.c #include <stdlib.h> #include <stdio.h> #include <sys/types.h> #includ…...

Linux内核进程管理几种CPU调度策略
CPU调度我们知道,程序需要获得CPU的资源才能被调度和执行,那么当一个进程由于某种原因放弃CPU然后进入阻塞状态,下一个获得CPU资源去被调度执行的进程会是谁呢?下图中,进程1因为阻塞放弃CPU资源,此时&#…...
SpringBoot整合Flink(施耐德PLC物联网信息采集)
SpringBoot整合Flink(施耐德PLC物联网信息采集)Linux环境安装kafka前情:施耐德PLC设备(TM200C16R)设置好信息采集程序,连接局域网,SpringBoot订阅MQTT主题,消息转至kafka,…...

DFS(深度优先搜索)和BFS(宽度优先搜索)
目录 DFS(深度优先搜索) 全排列的DFS解法 利用DFS递归构建二进制串和递归树的结构剖析 DFS--剪枝 DFS例题--整数划分 BFS(宽度优先搜索) 全排列的BFS解法 DFS(深度优先搜索) 深度优先搜索(Depth First Search&…...

Redis缓存穿透、击穿、雪崩问题及解决方法
系列文章目录 Spring Cache的使用–快速上手篇 分页查询–Java项目实战篇 全局异常处理–Java实战项目篇 完善登录功能–过滤器的使用 上述只是部分文章,对该系列文章感兴趣的可以查看我的主页哦 文章目录系列文章目录前言一、缓存穿透1.1 问题引入1.2 解决方法1.…...

HAL库 STM32 串口通信
一、实验条件将STM32的PA9复用为串口1的TX,PA10复用为串口1的RX。STM32芯片的输出TX和接收RX与CH340的接收RX和发送TX相连(收发交叉且PCB上默认没有相连,所以需要用P3跳线帽进行手动连接),CH340的另一端通过USB口引出与…...

2023-第十四届蓝桥杯冲刺计划!
💬前言 💡本文以目录形式列举大纲,可根据题目点击跳转 🌈冲刺阶段目的:把握高频重点,结合基础算法和常考题型总结,用真题进行模拟练习 根据自己的能力熟练目前已掌握的算法,不会的还可以暴力 ⏳最后三个星期大家一起冲…...
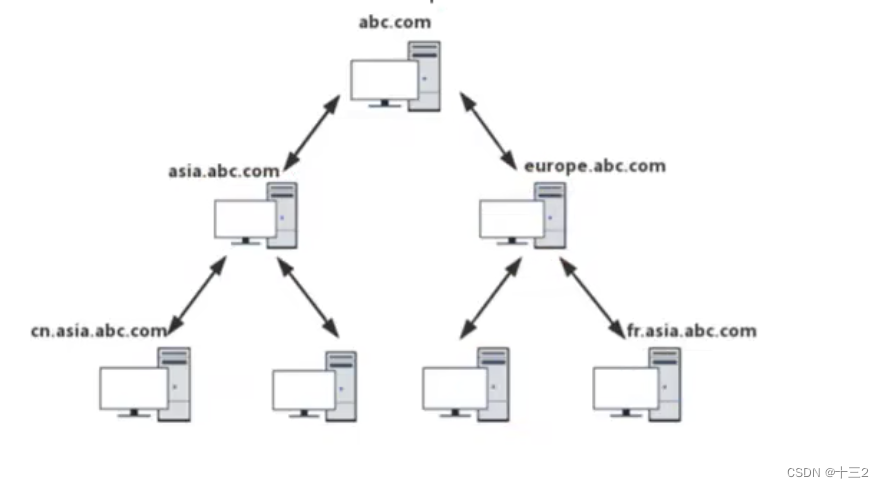
内网渗透基础知识
一、内网概述 内网也指局域网,是指在某一区域内又多台计算机互联成的计算机组。一般是方圆几千米内,局域网可以实现文件管理,应用软件共享,打印机共享,工作组内的历程安排,电子邮件和传真通信服务等功能。…...

鸟哥的Linux私房菜 正则表示法与文件格式化处理
第十一章、正则表示法与文件格式化处理 https://linux.vbird.org/linux_basic/centos7/0330regularex.php 简体版 http://cn.linux.vbird.org/linux_basic/0330regularex.php 11.2.2 grep的一些高级选项 例题一、搜索特定字符串 例题二、利用中括号 [] 来搜寻集合字符 例题四…...
1630.等差子数组
1630. 等差子数组 难度中等 如果一个数列由至少两个元素组成,且每两个连续元素之间的差值都相同,那么这个序列就是 等差数列 。更正式地,数列 s 是等差数列,只需要满足:对于每个有效的 i , s[i1] - s[i] …...
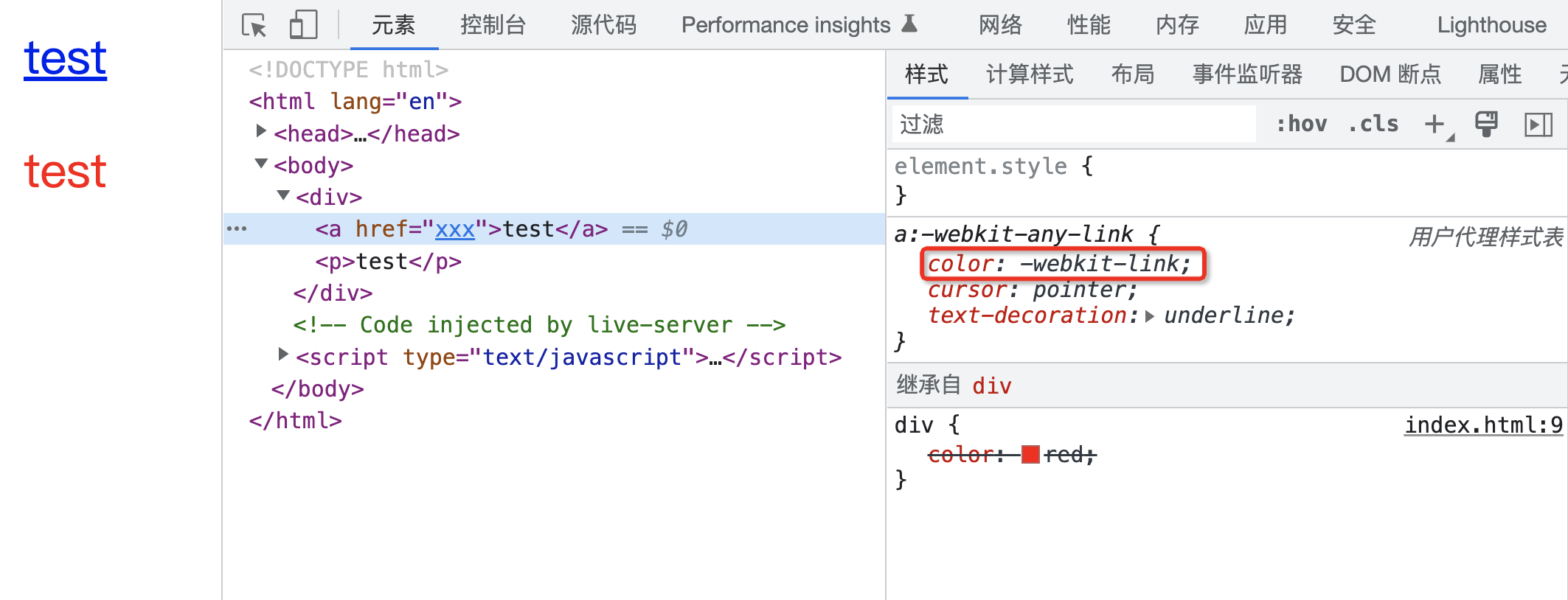
CSS 属性计算过程
CSS 属性计算过程 你是否了解 CSS 的属性计算过程呢? 有的同学可能会讲,CSS属性我倒是知道,例如: p{color : red; }上面的 CSS 代码中,p 是元素选择器,color 就是其中的一个 CSS 属性。 但是要说 CSS 属…...
)
告别卡顿!用UniApp的RenderJS为你的APP手势和动画性能提速(实战解析)
告别卡顿!用UniApp的RenderJS为你的APP手势和动画性能提速(实战解析) 在移动应用开发中,流畅的用户体验往往决定了产品的成败。当你在UniApp框架下开发APP时,是否遇到过这样的场景:地图拖拽时出现明显延迟&…...

二相四线步进电机驱动全解析:从原理到Proteus仿真避坑指南
二相四线步进电机驱动全解析:从原理到Proteus仿真避坑指南 在工业自动化与嵌入式开发领域,步进电机因其精准的位置控制能力成为不可或缺的执行元件。而二相四线制步进电机凭借结构简单、成本低廉的优势,尤其受到电子工程师和创客群体的青睐。…...

Verilog实战精要:从语法基础到高效状态机设计
1. Verilog语法基础:从硬件思维出发 第一次接触Verilog时,很多人会把它当成普通编程语言来学,结果发现处处碰壁。我当年在FPGA项目上栽的第一个跟头,就是把阻塞赋值用在了时钟触发的always块里,导致仿真结果和实际硬件…...

PlayCover 2.0重构Mac游戏体验:社交与云服务双引擎驱动革新
PlayCover 2.0重构Mac游戏体验:社交与云服务双引擎驱动革新 【免费下载链接】PlayCover Community fork of PlayCover 项目地址: https://gitcode.com/gh_mirrors/pl/PlayCover 在Mac平台运行iOS游戏长期面临两大痛点:缺乏社交连接与跨设备数据同…...

4步攻克Python代码执行可视化:开发者调试效率提升指南
4步攻克Python代码执行可视化:开发者调试效率提升指南 【免费下载链接】viztracer VizTracer is a low-overhead logging/debugging/profiling tool that can trace and visualize your python code execution. 项目地址: https://gitcode.com/gh_mirrors/vi/vizt…...

6_Harness驾驭工程可靠性层:混沌工程与服务可靠性管理
6_Harness驾驭工程可靠性层:混沌工程与服务可靠性管理 关键字: Chaos Engineering、混沌工程、SRM、服务可靠性管理、SLI、SLO、错误预算、韧性评分、故障模拟、事件响应、事后分析、韧性验证、自动故障注入、最小爆炸半径、Datadog、New Relic、Prometh…...

G-Helper:释放华硕笔记本性能潜能的轻量级控制工具
G-Helper:释放华硕笔记本性能潜能的轻量级控制工具 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地址: …...

【Mojo+Python混合部署失效真相】:92%开发者忽略的编译期符号冲突、运行时上下文隔离与调试断点丢失问题
第一章:MojoPython混合部署失效真相全景概览Mojo 作为新兴的高性能系统编程语言,设计初衷是与 Python 生态无缝互操作;然而在真实生产部署中,“Mojo Python 混合部署”常出现静默失败、ABI 不兼容、运行时崩溃或性能断崖式下降等…...
)
保姆级教程:用QPST+QFIL给小米/一加备份基带qcn文件(防丢失IMEI必备)
高通机型基带备份与恢复全指南:从QCN文件操作到通信模块保护 在智能手机深度定制与系统优化的过程中,基带数据的安全往往是最容易被忽视却至关重要的环节。我曾亲眼见证一位开发者因为误操作导致IMEI丢失,花费整整两周时间与运营商周旋恢复服…...

NaViL-9B部署稳定性报告:7×24小时双卡运行内存泄漏监测
NaViL-9B部署稳定性报告:724小时双卡运行内存泄漏监测 1. 平台概述 NaViL-9B是一款原生多模态大语言模型,具备纯文本问答和图片理解双重能力。该模型经过特殊优化,可直接复用内置模型目录,无需二次下载大权重文件,显…...