大数据技术——实战项目:广告数仓(第五部分)
目录
第9章 广告数仓DIM层
9.1 广告信息维度表
9.2 平台信息维度表
9.3 数据装载脚本
第10章 广告数仓DWD层
10.1 广告事件事实表
10.1.1 建表语句
10.1.2 数据装载
10.1.2.1 初步解析日志
10.1.2.2 解析IP和UA
10.1.2.3 标注无效流量
10.2 数据装载脚本
第9章 广告数仓DIM层
DIM层设计要点:
(1)DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
(2)DIM层的数据存储格式为orc列式存储+snappy压缩。
(3)DIM层表名的命名规范为dim_表名_全量表或者拉链表标识(full/zip)。
9.1 广告信息维度表
1)建表语句
drop table if exists dim_ads_info_full;
create external table if not exists dim_ads_info_full
(ad_id string comment '广告id',ad_name string comment '广告名称',product_id string comment '广告产品id',product_name string comment '广告产品名称',product_price decimal(16, 2) comment '广告产品价格',material_id string comment '素材id',material_url string comment '物料地址',group_id string comment '广告组id'
) PARTITIONED BY (`dt` STRING)STORED AS ORCLOCATION '/warehouse/ad/dim/dim_ads_info_full'TBLPROPERTIES ('orc.compress' = 'snappy');
2)加载数据
insert overwrite table dim_ads_info_full partition (dt='2023-01-07')
selectad.id,ad_name,product_id,name,price,material_id,material_url,group_id
from
(selectid,ad_name,product_id,material_id,group_id,material_urlfrom ods_ads_info_fullwhere dt = '2023-01-07'
) ad
left join
(selectid,name,pricefrom ods_product_info_fullwhere dt = '2023-01-07'
) pro
on ad.product_id = pro.id;
9.2 平台信息维度表
1)建表语句
drop table if exists dim_platform_info_full;
create external table if not exists dim_platform_info_full
(id STRING comment '平台id',platform_name_en STRING comment '平台名称(英文)',platform_name_zh STRING comment '平台名称(中文)'
) PARTITIONED BY (`dt` STRING)STORED AS ORCLOCATION '/warehouse/ad/dim/dim_platform_info_full'TBLPROPERTIES ('orc.compress' = 'snappy');
2)加载数据
insert overwrite table dim_platform_info_full partition (dt = '2023-01-07')
selectid,platform_name_en,platform_name_zh
from ods_platform_info_full
where dt = '2023-01-07';
9.3 数据装载脚本
1)在hadoop102的/home/atguigu/bin目录下创建ad_ods_to_dim.sh
[atguigu@hadoop102 bin]$ vim ad_ods_to_dim.sh
2)编写如下内容
#!/bin/bashAPP=ad# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$2" ] ;thendo_date=$2
else do_date=`date -d "-1 day" +%F`
fidim_platform_info_full="
insert overwrite table ${APP}.dim_platform_info_full partition (dt='$do_date')
selectid,platform_name_en,platform_name_zh
from ${APP}.ods_platform_info_full
where dt = '$do_date';
"dim_ads_info_full="
insert overwrite table ${APP}.dim_ads_info_full partition (dt='$do_date')
selectad.id,ad_name,product_id,name,price,material_id,material_url,group_id
from
(selectid,ad_name,product_id,material_id,group_id,material_urlfrom ${APP}.ods_ads_info_fullwhere dt = '$do_date'
) ad
left join
(selectid,name,pricefrom ${APP}.ods_product_info_fullwhere dt = '$do_date'
) pro
on ad.product_id = pro.id;
"case $1 in
"dim_ads_info_full")hive -e "$dim_ads_info_full"
;;
"dim_platform_info_full")hive -e "$dim_platform_info_full"
;;
"all")hive -e "$dim_ads_info_full$dim_platform_info_full"
;;
esac
3)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod +x ad_ods_to_dim.sh
4)脚本用法
[atguigu@hadoop102 bin]$ ad_ods_to_dim.sh all 2023-01-07
第10章 广告数仓DWD层
DWD层设计要点:
(1)DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
(2)DWD层的数据存储格式为orc列式存储+snappy压缩。
(3)DWD层表名的命名规范为dwd_数据域_表名_单分区增量全量标识(inc/full)
10.1 广告事件事实表
10.1.1 建表语句
drop table if exists dwd_ad_event_inc;
create external table if not exists dwd_ad_event_inc
(event_time bigint comment '事件时间',event_type string comment '事件类型',ad_id string comment '广告id',ad_name string comment '广告名称',ad_product_id string comment '广告商品id',ad_product_name string comment '广告商品名称',ad_product_price decimal(16, 2) comment '广告商品价格',ad_material_id string comment '广告素材id',ad_material_url string comment '广告素材地址',ad_group_id string comment '广告组id',platform_id string comment '推广平台id',platform_name_en string comment '推广平台名称(英文)',platform_name_zh string comment '推广平台名称(中文)',client_country string comment '客户端所处国家',client_area string comment '客户端所处地区',client_province string comment '客户端所处省份',client_city string comment '客户端所处城市',client_ip string comment '客户端ip地址',client_device_id string comment '客户端设备id',client_os_type string comment '客户端操作系统类型',client_os_version string comment '客户端操作系统版本',client_browser_type string comment '客户端浏览器类型',client_browser_version string comment '客户端浏览器版本',client_user_agent string comment '客户端UA',is_invalid_traffic boolean comment '是否是异常流量'
) PARTITIONED BY (`dt` STRING)STORED AS ORCLOCATION '/warehouse/ad/dwd/dwd_ad_event_inc/'TBLPROPERTIES ('orc.compress' = 'snappy');
10.1.2 数据装载
该表的数据装载逻辑相对复杂,所以我们分步完成,其包含的步骤如下所示:
1)初步解析日志
解析出日志中的事件类型、广告平台、广告id、客户端ip及ua等信息。
2)解析ip和ua
进一步对ip和ua信息进行解析,得到ip对应的地理位置信息以及ua对应得浏览器和操作系统等信息。
3)标注异常流量
异常流量分为GIVT(General Invalid Traffic 的缩写,即常规无效流量)和SIVT(Sophisticated Invalid Traffic,即复杂无效流量)。这两类流量分别具有如下特点:
常规无效流量可根据已知“蜘蛛”程序和漫游器列表或通过其他例行检查识别出来。
复杂无效流量往往难以识别,这种类型的流量无法通过简单的规则识别,需要通过更深入的分析才能识别出来。
常规无效流量一般包括:来自数据中心的流量(通过IP识别),来自已知抓取工具的流量(通过UA识别)等等。
复杂无效流量一般包括:高度模拟真人访客的机器人和爬虫流量,虚拟化设备中产生的流量,被劫持的设备产生的流量等等。
以下是本课程包含的异常流量识别逻辑:
(1)根据已知的爬虫UA列表进行判断
(2)根据异常访问行为进行判断,具体异常行为如下:
- 同一ip访问过快
- 同一设备id访问过快
- 同一ip固定周期访问
- 同一设备id固定周期访问
10.1.2.1 初步解析日志
该步骤,只需将日志中的所有信息解析为单独字段,并将结果保存至临时表即可。
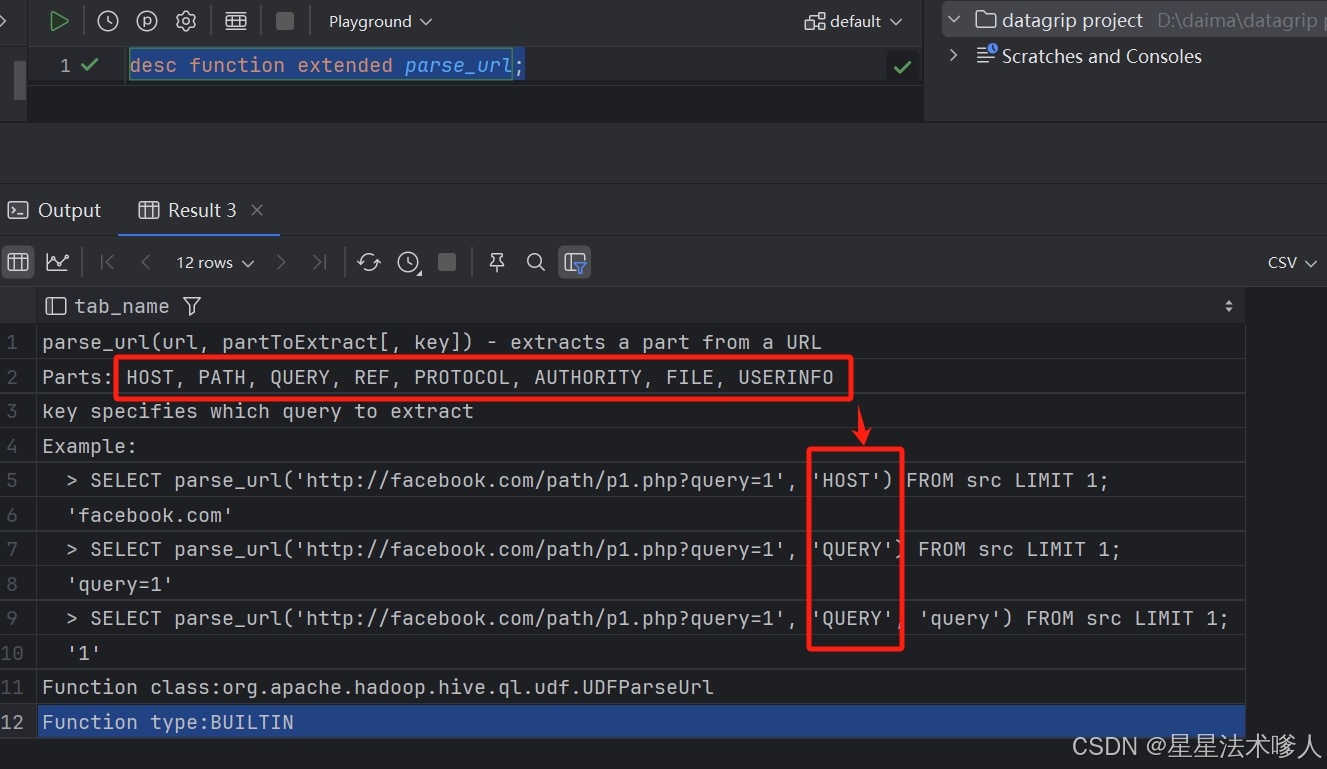
使用parse_url()方法进行处理,通过desc function extended parse_url;查看方法用法
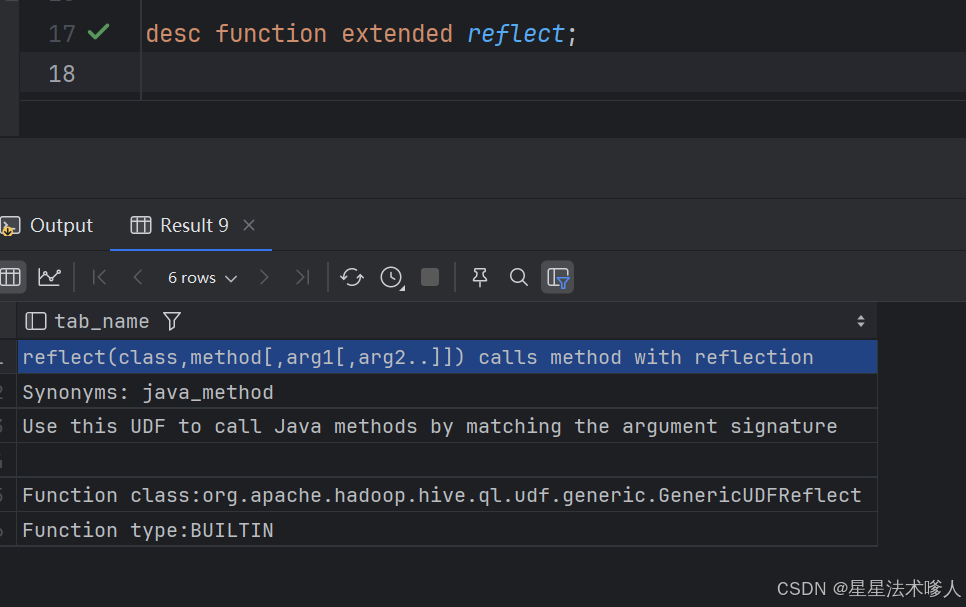
使用reflect()方法进行反射,对ua进行解码
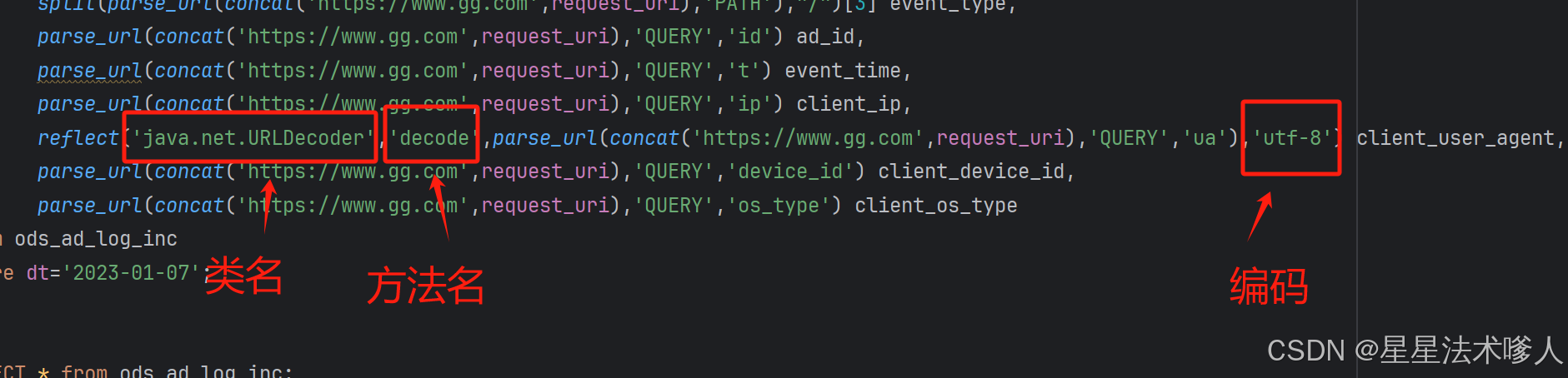
使用示例
create temporary table coarse_parsed_log
as
select split(parse_url(concat('https://www.gg.com',request_uri),'PATH'),"/")[2] platform_name_en,split(parse_url(concat('https://www.gg.com',request_uri),'PATH'),"/")[3] event_type,parse_url(concat('https://www.gg.com',request_uri),'QUERY','id') ad_id,parse_url(concat('https://www.gg.com',request_uri),'QUERY','t') event_time,parse_url(concat('https://www.gg.com',request_uri),'QUERY','ip') client_ip,reflect('java.net.URLDecoder','decode',parse_url(concat('https://www.gg.com',request_uri),'QUERY','ua'),'utf-8') client_user_agent,parse_url(concat('https://www.gg.com',request_uri),'QUERY','device_id') client_device_id,parse_url(concat('https://www.gg.com',request_uri),'QUERY','os_type') client_os_type
from ods_ad_log_inc
where dt='2023-01-07';注:
(1)临时表(temporary table)只在当前会话有效,使用时需注意
(2)parse_url函数和reflect函数的用法可使用以下命令查看
hive>desc function extended parse_url;desc function extended reflect;10.1.2.2 解析IP和UA
该步骤,需要根据IP得到地理位置信息(例如省份、城市等),并根据UA得到客户端端操作系统及浏览器等信息。需要注意的是,Hive并未提供用于解析IP地址和User Agent的函数,故我们需要先自定义函数。
1)自定义IP解析函数
该函数的主要功能是根据IP地址得到其所属的地区、省份、城市等信息。
上述功能一般可通过以下方案实现:
方案一:请求某些第三方提供的的IP定位接口(例如:高德开放平台),该方案的优点是IP定位准确、数据可靠性高;缺点是,一般有请求次数和QPS(Queries Per Second)限制,若超过限制需付费使用。
方案二:使用免费的离线IP数据库进行查询,该方案的优点是无任何限制,缺点是数据的准确率、可靠性略差。
在当前的场景下,我们更适合选择方案二。主要原因是,方案一的效率较低,因为这些IP定位接口,一般是每次请求定位一个IP,若采用该方案,则处理每条数据都要请求一次接口,在加上这些API的QPS限制,就会导致我们的SQL运行效率极低。
(1)免费IP地址库介绍
我们采用的免费IP地址库为ip2region v2.0,其地址如下:
https://github.com/lionsoul2014/ip2region.git
ip2region是一个离线IP地址定位库和IP定位数据管理框架,有着10微秒级别的查询效率,并提供了众多主流编程语言的客户端实现。
(2)使用说明
其官方案例如下:
public class TestIP2Region {public static void main(String[] args) throws Exception {//1.ip2region.xdb是其ip地址库文件,下载地址如为: https://github.com/lionsoul2014/ip2region/raw/master/data/ip2region.xdbbyte[] bytes;Searcher searcher =null;try {// 读取本地磁盘的ip解析库进入到内存当中bytes = Searcher.loadContentFromFile("src\\main\\resources\\ip2region.xdb");// 创建解析对象searcher = Searcher.newWithBuffer(bytes);// 解析ipString search = searcher.search("223.223.182.174");// 打印结果System.out.println(search);searcher.close();} catch (Exception e) {e.printStackTrace();}finally {if (searcher!=null){try {searcher.close();} catch (IOException e) {e.printStackTrace();}}}
}
}
(3)自定义函数实现
①函数功能定义
- 函数名:parse_ip
- 参数:
| 参数名 | 类型 | 说明 |
| filepath | string | ip2region.xdb文件路径。 注:该路径要求为HDFS路径,也就是我们需将ip2region.xdb文件上传至hdfs。 |
| ipv4 | string | 需要解析的ipv4地址 |
- 输出:
输出类型为结构体,具体定义如下:

②创建一个maven项目,pom文件内容如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.gg</groupId><artifactId>ad_hive_udf</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><!-- hive-exec依赖无需打到jar包,故scope使用provided--><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.3</version><scope>provided</scope></dependency><!-- ip地址库--><dependency><groupId>org.lionsoul</groupId><artifactId>ip2region</artifactId><version>2.7.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><!--将依赖编译到jar包中--><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><!--配置执行器--><execution><id>make-assembly</id><!--绑定到package执行周期上--><phase>package</phase><goals><!--只运行一次--><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>③创建com.gg.ad.hive.udf.ParseIP类,并编辑如下内容:
package com.gg.ad.hive.udf;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ConstantObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.IOUtils;
import org.lionsoul.ip2region.xdb.Searcher;import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.OutputStream;
import java.util.ArrayList;public class ParseIP extends GenericUDF{Searcher searcher = null;/*** 判断函数传入的参数个数以及类型 同时确定返回值类型* @param arguments* @return* @throws UDFArgumentException*/@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {// 传入参数的个数if (arguments.length != 2){throw new UDFArgumentException("parseIP必须填写2个参数");}// 校验参数的类型ObjectInspector hdfsPathOI = arguments[0];if (hdfsPathOI.getCategory() != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("parseIP第一个参数必须是基本数据类型");}PrimitiveObjectInspector hdfsPathOI1 = (PrimitiveObjectInspector) hdfsPathOI;if (hdfsPathOI1.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {throw new UDFArgumentException("parseIP第一个参数必须是string类型");}// 校验参数的类型ObjectInspector ipOI = arguments[1];if (ipOI.getCategory() != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("parseIP第二个参数必须是基本数据类型");}PrimitiveObjectInspector ipOI1 = (PrimitiveObjectInspector) ipOI;if (ipOI1.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {throw new UDFArgumentException("parseIP第二个参数必须是string类型");}// 读取ip静态库进入内存中// 获取hdfsPath地址if (hdfsPathOI instanceof ConstantObjectInspector){String hdfsPath = ((ConstantObjectInspector) hdfsPathOI).getWritableConstantValue().toString();// 从hdfs读取静态库Path path = new Path(hdfsPath);try {FileSystem fileSystem = FileSystem.get( new Configuration());FSDataInputStream inputStream = fileSystem.open(path);ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();IOUtils.copyBytes(inputStream,byteArrayOutputStream,1024);byte[] bytes = byteArrayOutputStream.toByteArray();//创建静态库,解析IP对象searcher = Searcher.newWithBuffer(bytes);}catch (Exception e){e.printStackTrace();}}// 确定函数返回值的类型ArrayList<String> structFieldNames = new ArrayList<>();structFieldNames.add("country");structFieldNames.add("area");structFieldNames.add("province");structFieldNames.add("city");structFieldNames.add("isp");ArrayList<ObjectInspector> structFieldObjectInspectors = new ArrayList<>();structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(structFieldNames, structFieldObjectInspectors);}/*** 处理数据* @param arguments* @return* @throws HiveException*/@Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {String ip = arguments[1].get().toString();ArrayList<Object> result = new ArrayList<>();try {String search = searcher.search(ip);String[] split = search.split("\\|");result.add(split[0]);result.add(split[1]);result.add(split[2]);result.add(split[3]);result.add(split[4]);}catch (Exception e){e.printStackTrace();}return result;}/*** 描述函数* @param children* @return*/@Overridepublic String getDisplayString(String[] children) {return getStandardDisplayString("parse_ip", children);}
}
④编译打包,并将xxx-1.0-SNAPSHOT-jar-with-dependencies.jar上传到HFDS的/user/hive/jars目录下
⑤创建永久函数,hive里运行
create function parse_ip
as 'com.gg.ad.hive.udf.ParseIP'
using jar 'hdfs://hadoop102:8020/user/hive/jars/ad_hive_udf-1.0-SNAPSHOT-jar-with-dependencies.jar';⑥上传ip2region.xdb到HDFS/ip2region/路径下
⑦测试函数
select client_ip,parse_ip('hdfs://hadoop102:8020/ip2region/ip2region.xdb',client_ip)
from coarse_parsed_log;输出结果:

2)自定义User Agent解析函数
该函数的主要功能是从UserAgent中解析出客户端的操作系统、浏览器等信息。该函数的实现思路有:
- 使用正则表达式来从UserAgent中提取需要的信息
- 使用一些现有的工具类,例如Hutool提供的UserAgentUtil(原理也是正则匹配)
本课程使用后者,具体实现思路如下:
(1)函数功能定义
- 函数名:parse_ua
- 参数:
| 参数名 | 类型 | 说明 |
| ua | string | User-agent |
- 输出:
输出类型为结构体,具体定义如下:

(2)创建一个maven项目,pom文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.gg</groupId><artifactId>ad_hive_udf</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><!-- hive-exec依赖无需打到jar包,故scope使用provided--><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.3</version><scope>provided</scope></dependency><!-- ip地址库--><dependency><groupId>org.lionsoul</groupId><artifactId>ip2region</artifactId><version>2.7.0</version></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-http</artifactId><version>5.8.11</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><!--将依赖编译到jar包中--><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><!--配置执行器--><execution><id>make-assembly</id><!--绑定到package执行周期上--><phase>package</phase><goals><!--只运行一次--><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>与上面的xml文件就多了个hutool依赖,可以直接在依赖里添加这段代码也是可以的,就不用重新创建项目,在原有的项目里面写。
这里我们继续原有的项目的添加即可。

(3)创建com.gg.ad.hive.udf.ParseUA类,编辑内容如下
package com.gg.ad.hive.udf;import cn.hutool.http.useragent.UserAgent;
import cn.hutool.http.useragent.UserAgentUtil;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList;public class ParseUA extends GenericUDF {@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {// 传入参数的个数if (arguments.length != 1){throw new UDFArgumentException("parseUA必须填写1个参数");}// 校验参数的类型ObjectInspector uaOI = arguments[0];if (uaOI.getCategory() != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("parseUA第一个参数必须是基本数据类型");}PrimitiveObjectInspector uaOI1 = (PrimitiveObjectInspector) uaOI;if (uaOI1.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {throw new UDFArgumentException("parseUA第一个参数必须是string类型");}// 确定函数返回值的类型ArrayList<String> structFieldNames = new ArrayList<>();structFieldNames.add("browser");structFieldNames.add("browserVersion");structFieldNames.add("engine");structFieldNames.add("engineVersion");structFieldNames.add("os");structFieldNames.add("osVersion");structFieldNames.add("platform");structFieldNames.add("isMobile");ArrayList<ObjectInspector> structFieldObjectInspectors = new ArrayList<>();structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(structFieldNames, structFieldObjectInspectors);}@Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {String ua = arguments[0].get().toString();ArrayList<Object> result = new ArrayList<>();UserAgent parse = UserAgentUtil.parse(ua);result.add(parse.getBrowser().getName());result.add(parse.getVersion());result.add(parse.getEngine());result.add(parse.getEngineVersion());result.add(parse.getOs().getName());result.add(parse.getOsVersion());result.add(parse.getPlatform().getName());result.add(parse.isMobile());return result;}@Overridepublic String getDisplayString(String[] children) {return getStandardDisplayString("parseUA", children);}
}
(4)编译打包,并将xxx-1.0-SNAPSHOT-jar-with-dependencies.jar上传到HFDS的/user/hive/jars目录下
我们将HFDS的/user/hive/jars目录下原有的jar包删除,上传新的jar包
(5)创建永久函数
在hive里运行
create function parse_ua
as 'com.gg.ad.hive.udf.ParseUA'
using jar 'hdfs://hadoop102:8020/user/hive/jars/ad_hive_udf-1.0-SNAPSHOT-jar-with-dependencies.jar';(6)测试函数
select client_user_agent,parse_ua(client_user_agent)
from coarse_parsed_log;运行如下:

3)使用自定义函数解析ip和ua
解析完的数据同样保存在临时表,具体逻辑如下:
set hive.vectorized.execution.enabled=false;
create temporary table fine_parsed_log
as
selectevent_time,event_type,ad_id,platform_name_en,client_ip,client_user_agent,client_os_type,client_device_id,parse_ip('hdfs://hadoop102:8020/ip2region/ip2region.xdb',client_ip) region_struct,if(client_user_agent != '',parse_ua(client_user_agent),null) ua_struct
from coarse_parsed_log;10.1.2.3 标注无效流量
该步骤的具体工作是识别异常流量,并通过is_invalid_traffic字段进行标识,计算结果同样暂存到临时表,具体识别逻辑如下:
1)根据已知爬虫列表进行判断
此处我们可创建一张维度表,保存所有的已知爬虫UA,这样只需将事实表中的client_ua和该表中的ua做比较即可进行识别。
爬虫UA列表的数据来源为:
GitHub - monperrus/crawler-user-agents: Syntactic patterns of HTTP user-agents used by bots / robots / crawlers / scrapers / spiders. pull-request welcome :star:
(1)建表语句,爬虫ua维度表
drop table if exists dim_crawler_user_agent;
create external table if not exists dim_crawler_user_agent
(pattern STRING comment '正则表达式',addition_date STRING comment '收录日期',url STRING comment '爬虫官方url',instances ARRAY<STRING> comment 'UA实例'
)STORED AS ORCLOCATION '/warehouse/ad/dim/dim_crawler_user_agent'TBLPROPERTIES ('orc.compress' = 'snappy');
(2)加载数据
①创建临时表
create temporary table if not exists tmp_crawler_user_agent
(pattern STRING comment '正则表达式',addition_date STRING comment '收录日期',url STRING comment '爬虫官方url',instances ARRAY<STRING> comment 'UA实例'
)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'STORED AS TEXTFILELOCATION '/warehouse/ad/tmp/tmp_crawler_user_agent';
②上传crawler_user_agent.txt到临时表所在路径

③执行如下语句将数据导入dim_crawler_user_agent
insert overwrite table dim_crawler_user_agent select * from tmp_crawler_user_agent;2)同一ip访问过快
具体判断规则如下:若同一ip在短时间内访问(包括曝光和点击)同一广告多次,则认定该ip的所有流量均为异常流量,此处我们需要找出所有的异常ip,并将其结果暂存在临时表。
具体判断规则:5分钟内超过100次,SQL实现逻辑如下:
-- 同一个ip5分钟访问100次
create temporary table high_speed_ip
as
selectdistinct client_ip
from (selectevent_time,client_ip,ad_id,count(1) over (partition by client_ip,ad_id order by cast(event_time as bigint) range between 300000 precedingand current row ) event_count_last_5minfrom coarse_parsed_log
)t1
where event_count_last_5min>100;3)同一ip固定周期访问
具体判断规则如下:若同一ip对同一广告有周期性的访问记录(例如每隔10s,访问一次),则认定该ip的所有流量均为异常流量,此处我们需要找出所有的异常ip,并将其结果暂存在临时表。
具体判断规则:固定周期访问超过5次,SQL实现逻辑如下:
-- 相同ip固定周期访问超过5次
create temporary table cycle_ip
as
selectdistinct client_ip
from (selectad_id,client_ipfrom (selectad_id,client_ip,event_time,time_diff,sum(mark) over (partition by ad_id,client_ip order by event_time) groupsfrom(selectad_id,client_ip,event_time,time_diff,`if`(lag(time_diff,1,0) over (partition by ad_id,client_ip order by event_time) != time_diff,1,0) markfrom (selectad_id,client_ip,event_time,lead(event_time,1,0) over (partition by ad_id,client_ip order by event_time) - event_time time_difffrom coarse_parsed_log)t1)t2)t3group by ad_id,client_ip,groupshaving count(*) >= 5)t4;4)同一设备访问过快
具体判断规则如下:若同一设备在短时间内访问(包括曝光和点击)同一广告多次,则认定该设备的所有流量均为异常流量,此处我们需要找出所有的异常设备id,并将其结果暂存在临时表。
具体判断规则:5分钟内超过100次,SQL实现逻辑如下:
-- 相同设备id访问过快
create temporary table high_speed_device
as
selectdistinct client_device_id
from
(selectevent_time,client_device_id,ad_id,count(1) over(partition by client_device_id,ad_id order by cast(event_time as bigint) range between 300000 preceding and current row) event_count_last_5minfrom coarse_parsed_logwhere client_device_id != ''
)t1
where event_count_last_5min>100;5)同一设备固定周期访问
具体判断规则如下:若同一设备对同一广告有周期性的访问记录(例如每隔10s,访问一次),则 认定该设备的所有流量均为异常流量,此处我们需要找出所有的异常设备id,并将其结果暂存在临时表。
具体判断规则:固定周期访问超过5次。
-- 相同设备id周期访问超过5次
create temporary table cycle_device
as
selectdistinct client_device_id
from
(selectclient_device_id,ad_id,sfrom(selectevent_time,client_device_id,ad_id,sum(num) over(partition by client_device_id,ad_id order by event_time) sfrom(selectevent_time,client_device_id,ad_id,time_diff,if(lag(time_diff,1,0) over(partition by client_device_id,ad_id order by event_time)!=time_diff,1,0) numfrom(selectevent_time,client_device_id,ad_id,lead(event_time,1,0) over(partition by client_device_id,ad_id order by event_time)-event_time time_difffrom coarse_parsed_logwhere client_device_id != '')t1)t2)t3group by client_device_id,ad_id,shaving count(*)>=5
)t4;6)标识异常流量并做维度退化
该步骤需将fine_parsed_log与上述的若干张表进行关联,完成异常流量的判断以及维度的退化操作,然后将最终结果写入dwd_ad_event_inc表,SQL逻辑如下:
insert overwrite table dwd_ad_event_inc partition (dt='2023-01-07')
selectevent_time,event_type,log.ad_id,ad_name,ads_info.product_id ad_product_id,ads_info.product_name ad_product_name,ads_info.product_price ad_product_price,ads_info.material_id ad_material_id,ads_info.material_url ad_material_url,ads_info.group_id ad_group_id,platform_info.id platform_id,platform_info.platform_name_en platform_name_en,platform_info.platform_name_zh platform_name_zh,region_struct.country client_country,region_struct.area client_area,region_struct.province client_province,region_struct.city client_city,log.client_ip,log.client_device_id,`if`(client_os_type !='',client_os_type,ua_struct.os) client_os_type,nvl(ua_struct.osVersion,'') client_os_version,nvl(ua_struct.browser,'') client_browser_type,nvl(ua_struct.browserVersion,'') client_browser_version,client_user_agent,`if`(coalesce(hsi.client_ip,ci.client_ip,hsd.client_device_id,cd.client_device_id,cua.pattern) is not null,true,false) is_invalid_traffic
from fine_parsed_log log
left join high_speed_ip hsi
on log.client_ip = hsi.client_ip
left join cycle_ip ci
on log.client_ip = ci.client_ip
left join high_speed_device hsd
on log.client_device_id = hsd.client_device_id
left join cycle_device cd
on log.client_device_id = cd.client_device_id
left join dim_crawler_user_agent cua
on log.client_user_agent regexp cua.pattern
left join (select *from dim_ads_info_fullwhere dt='2023-01-07'
)ads_info
on log.ad_id = ads_info.ad_id
left join (select *from dim_platform_info_fullwhere dt='2023-01-07'
)platform_info
on log.platform_name_en = platform_info.platform_name_en;10.2 数据装载脚本
1)在hadoop102的/home/atguigu/bin目录下创建ad_ods_to_dwd.sh
[atguigu@hadoop102 bin]$ vim ad_ods_to_dwd.sh
2)编写如下内容
#!/bin/bashAPP=ad# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$2" ] ;thendo_date=$2
else do_date=`date -d "-1 day" +%F`
fidwd_ad_event_inc="
set hive.vectorized.execution.enabled=false;
--初步解析
create temporary table coarse_parsed_log
as
selectparse_url('http://www.example.com' || request_uri, 'QUERY', 't') event_time,split(parse_url('http://www.example.com' || request_uri, 'PATH'), '/')[3] event_type,parse_url('http://www.example.com' || request_uri, 'QUERY', 'id') ad_id,split(parse_url('http://www.example.com' || request_uri, 'PATH'), '/')[2] platform,parse_url('http://www.example.com' || request_uri, 'QUERY', 'ip') client_ip,reflect('java.net.URLDecoder', 'decode', parse_url('http://www.example.com'||request_uri,'QUERY','ua'), 'utf-8') client_ua,parse_url('http://www.example.com'||request_uri,'QUERY','os_type') client_os_type,parse_url('http://www.example.com'||request_uri,'QUERY','device_id') client_device_id
from ${APP}.ods_ad_log_inc
where dt='$do_date';
--进一步解析ip和ua
create temporary table fine_parsed_log
as
selectevent_time,event_type,ad_id,platform,client_ip,client_ua,client_os_type,client_device_id,${APP}.parse_ip('hdfs://hadoop102:8020/ip2region/ip2region.xdb',client_ip) region_struct,if(client_ua != '',${APP}.parse_ua(client_ua),null) ua_struct
from coarse_parsed_log;
--高速访问ip
create temporary table high_speed_ip
as
selectdistinct client_ip
from
(selectevent_time,client_ip,ad_id,count(1) over(partition by client_ip,ad_id order by cast(event_time as bigint) range between 300000 preceding and current row) event_count_last_5minfrom coarse_parsed_log
)t1
where event_count_last_5min>100;
--周期访问ip
create temporary table cycle_ip
as
selectdistinct client_ip
from
(selectclient_ip,ad_id,sfrom(selectevent_time,client_ip,ad_id,sum(num) over(partition by client_ip,ad_id order by event_time) sfrom(selectevent_time,client_ip,ad_id,time_diff,if(lag(time_diff,1,0) over(partition by client_ip,ad_id order by event_time)!=time_diff,1,0) numfrom(selectevent_time,client_ip,ad_id,lead(event_time,1,0) over(partition by client_ip,ad_id order by event_time)-event_time time_difffrom coarse_parsed_log)t1)t2)t3group by client_ip,ad_id,shaving count(*)>=5
)t4;
--高速访问设备
create temporary table high_speed_device
as
selectdistinct client_device_id
from
(selectevent_time,client_device_id,ad_id,count(1) over(partition by client_device_id,ad_id order by cast(event_time as bigint) range between 300000 preceding and current row) event_count_last_5minfrom coarse_parsed_logwhere client_device_id != ''
)t1
where event_count_last_5min>100;
--周期访问设备
create temporary table cycle_device
as
selectdistinct client_device_id
from
(selectclient_device_id,ad_id,sfrom(selectevent_time,client_device_id,ad_id,sum(num) over(partition by client_device_id,ad_id order by event_time) sfrom(selectevent_time,client_device_id,ad_id,time_diff,if(lag(time_diff,1,0) over(partition by client_device_id,ad_id order by event_time)!=time_diff,1,0) numfrom(selectevent_time,client_device_id,ad_id,lead(event_time,1,0) over(partition by client_device_id,ad_id order by event_time)-event_time time_difffrom coarse_parsed_logwhere client_device_id != '')t1)t2)t3group by client_device_id,ad_id,shaving count(*)>=5
)t4;
--维度退化
insert overwrite table ${APP}.dwd_ad_event_inc partition (dt='$do_date')
selectevent_time,event_type,event.ad_id,ad_name,product_id,product_name,product_price,material_id,material_url,group_id,plt.id,platform_name_en,platform_name_zh,region_struct.country,region_struct.area,region_struct.province,region_struct.city,event.client_ip,event.client_device_id,if(event.client_os_type!='',event.client_os_type,ua_struct.os),nvl(ua_struct.osVersion,''),nvl(ua_struct.browser,''),nvl(ua_struct.browserVersion,''),event.client_ua,if(coalesce(pattern,hsi.client_ip,ci.client_ip,hsd.client_device_id,cd.client_device_id) is not null,true,false)
from fine_parsed_log event
left join ${APP}.dim_crawler_user_agent crawler on event.client_ua regexp crawler.pattern
left join high_speed_ip hsi on event.client_ip = hsi.client_ip
left join cycle_ip ci on event.client_ip = ci.client_ip
left join high_speed_device hsd on event.client_device_id = hsd.client_device_id
left join cycle_device cd on event.client_device_id = cd.client_device_id
left join
(selectad_id,ad_name,product_id,product_name,product_price,material_id,material_url,group_idfrom ${APP}.dim_ads_info_fullwhere dt='$do_date'
)ad
on event.ad_id=ad.ad_id
left join
(selectid,platform_name_en,platform_name_zhfrom ${APP}.dim_platform_info_fullwhere dt='$do_date'
)plt
on event.platform=plt.platform_name_en;
"case $1 in
"dwd_ad_event_inc")hive -e "$dwd_ad_event_inc"
;;
"all")hive -e "$dwd_ad_event_inc"
;;
esac
3)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod +x ad_ods_to_dwd.sh
4)脚本用法
[atguigu@hadoop102 bin]$ ad_ods_to_dwd.sh all 2023-01-07

到此,我们DWD层就完成了。
前面章节:
大数据项目——实战项目:广告数仓(第一部分)-CSDN博客
大数据项目——实战项目:广告数仓(第二部分)-CSDN博客
大数据技术——实战项目:广告数仓(第三部分)-CSDN博客
大数据技术——实战项目:广告数仓(第四部分)-CSDN博客
相关文章:
大数据技术——实战项目:广告数仓(第五部分)
目录 第9章 广告数仓DIM层 9.1 广告信息维度表 9.2 平台信息维度表 9.3 数据装载脚本 第10章 广告数仓DWD层 10.1 广告事件事实表 10.1.1 建表语句 10.1.2 数据装载 10.1.2.1 初步解析日志 10.1.2.2 解析IP和UA 10.1.2.3 标注无效流量 10.2 数据装载脚本 第9章 广…...

计算机毕业设计 家电销售展示平台 Java+SpringBoot+Vue 前后端分离 文档报告 代码讲解 安装调试
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...

C# 根据MySQL数据库中数据,批量删除OSS上的垃圾文件
protected void btndeleteTask_Click(object sender, EventArgs e){//获取标识为已删除数据,一次加载500条int countlocks _goodsItemsApplication.CountAllNeedExecuteTask();int totalPagelocks (countlocks 500 - 1) / 500;//分批次处理for (int curentpage …...

Vue3+Element-plus+setup使用vuemap/vue-amap实现高德地图API相关操作
首先要下载依赖并且引入 npm安装 // 安装核心库 npm install vuemap/vue-amap --save// 安装loca库 npm install vuemap/vue-amap-loca --save// 安装扩展库 npm install vuemap/vue-amap-extra --save cdn <script src"https://cdn.jsdelivr.net/npm/vuemap/vue-a…...
Windows配置开机直达桌面并跳过锁屏登录界面在 Windows 10 中添加在启动时自动运行的应用
目录 Win10开机直达桌面并跳过锁屏登录界面修改组策略修改注册表跳过登录界面 在 Windows 10 中添加在启动时自动运行的应用设置系统级别服务一、Windows下使用sc将应用程序设置为系统服务1. 什么是sc命令?2. sc命令的基本语法3. 创建Windows服务的步骤与示例创建服…...
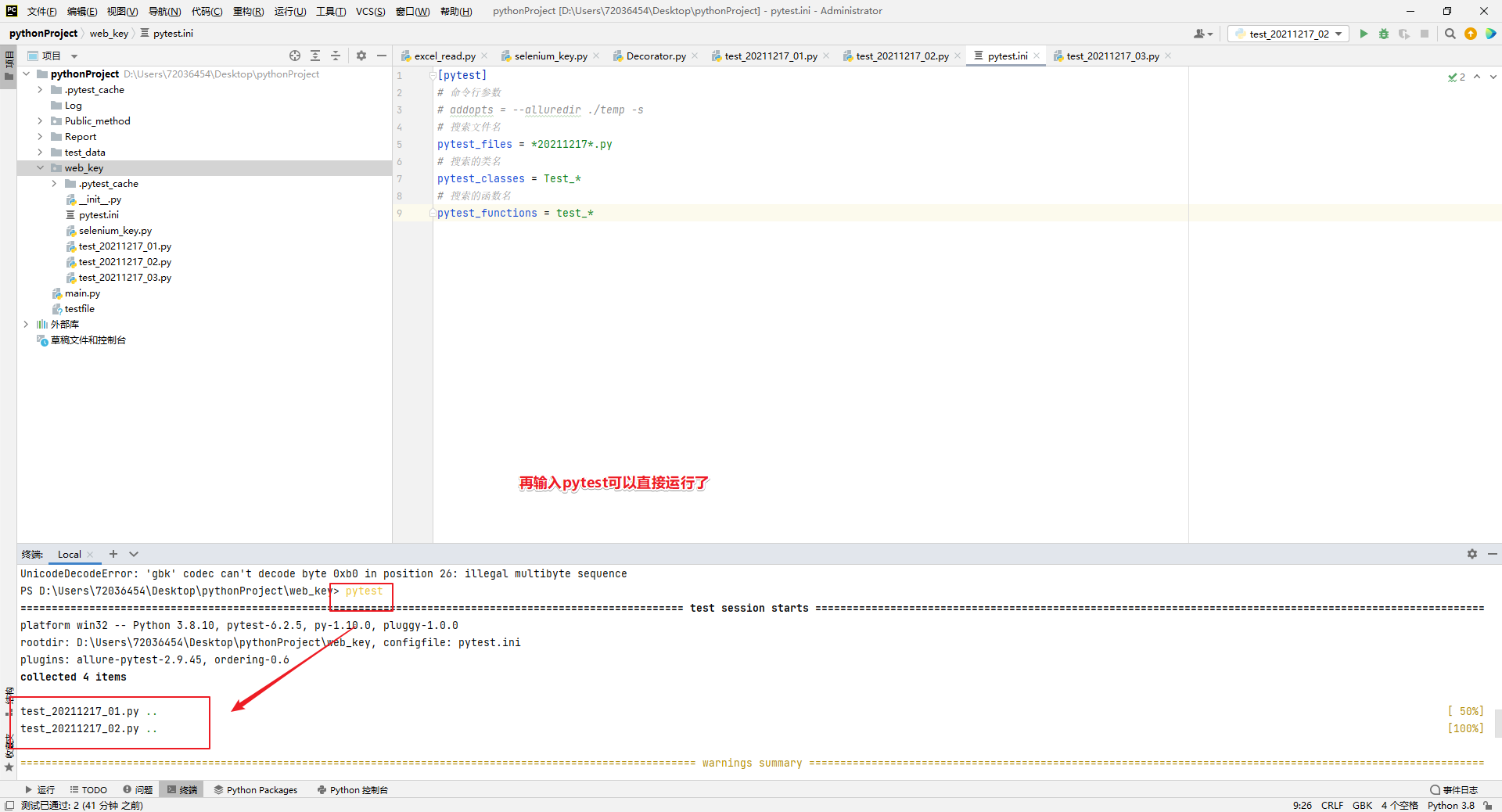
pythonUI自动化007::pytest的组成以及运行
pytest组成: 测试模块:以“test”开头或结尾的py文件 测试用例:在测试模块里或测试类里,名称符合test_xxx函数或者示例函数。 测试类:测试模块里面命名符合Test_xxx的类 函数级: import pytestclass Test…...

开放式耳机哪个品牌好用又实惠?五大口碑精品分享
如今开放式耳机市场日益火爆,不少知名品牌都在对产品进行升级迭代,那么如何在一众品牌型号中选择到自己最满意的那一款呢?开放式耳机哪个品牌好用又实惠?这就需要更专业的选购攻略,因此笔者专门整理出了专业机构的开放…...
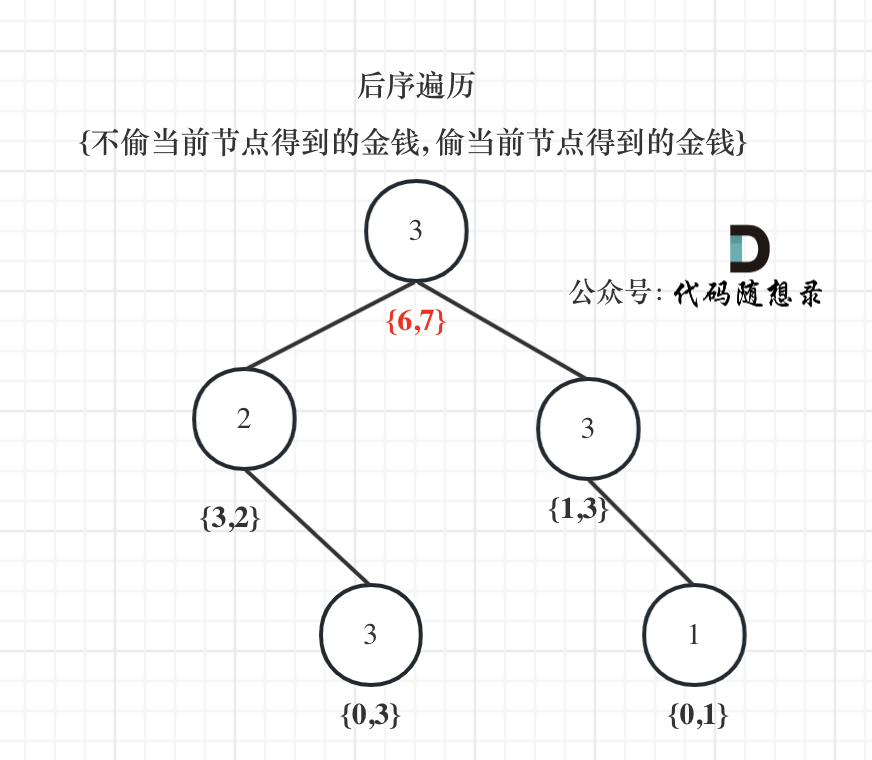
代码随想录算法训练营day39||动态规划07:多重背包+打家劫舍
多重背包理论 描述: 有N种物品和一个容量为V 的背包。 第i种物品最多有Mi件可用,每件耗费的空间是Ci ,价值是Wi 。 求解将哪些物品装入背包可使这些物品的耗费的空间 总和不超过背包容量,且价值总和最大。 本质: …...

WebSocket革新:用PHP实现实时Web通信
标题:WebSocket革新:用PHP实现实时Web通信 在现代Web应用中,实时通信是一个不可或缺的功能。WebSocket作为一种在单个TCP连接上进行全双工通信的协议,它允许服务器主动向客户端推送数据,极大地简化了客户端和服务器之…...

Python教程(十三):常用内置模块详解
目录 专栏列表1. os 模块2. sys 模块3. re 模块4. json 模块5. datetime 模块6. math 模块7. random 模块8. collections 模块9. itertools 模块10. threading 模块11. 加密 模块 总结 专栏列表 Python教程(十):面向对象编程(OOP…...

Linux 下的进程状态
文章目录 一、运行状态运行队列运行状态和运行队列 二、睡眠状态S状态D状态D状态产生的原因 三、暂停状态T状态t 状态 四、僵尸状态为什么有僵尸状态孤儿进程 一、运行状态 R状态:进程已经准备好随时被调度了。 运行队列 每个 CPU 都会维护一个自己的运行队列&am…...

【设计模式】六大基本原则
文章目录 开闭原则里氏替换原则依赖倒置原则单一职责原则接口隔离原则迪米特原则总结 开闭原则 核心就一句话:对扩展开放,对修改关闭。 针对的目标可以是语言层面的类、接口、方法,也可以是系统层面的功能、模块。当需求有变化的时候&#…...

Selenium网页的滚动
网页滚动功能实现 网页的滚动 如果需要对网页进行滑动操作,可以借助浏览器对象调用execute_script()方法来执行js语句,从而实现网页中的滚动下滑操作。 使用js语法实现网页滚动: # 根据x轴和y轴的值来定向滚动对应数值的距离 window.scrol…...

图算法系列1: 图算法的分类有哪些?(上)
大约在公元9世纪上半叶,来自中亚古国花剌子模的波斯数学家花剌子米(al-Khwarizmi)先后出版了两本对数学界有深远影响的书籍《印度数字算术》与《代数学》,前者在12世纪被翻译为拉丁文传入欧洲,十进制也因此传入欧洲,最终所形成的…...
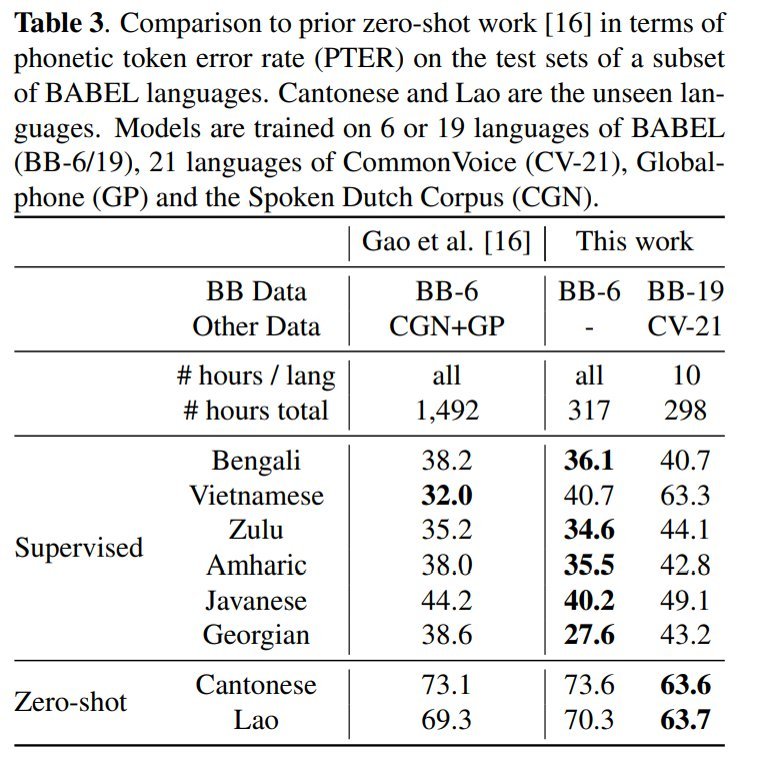
零样本学习——从多语言语料库数据中对未学习语言进行语音识别的创新技术
引言 在全球众多的语言中,只有极少数的语言在语音识别领域取得了显著的进展。这种不平衡现象的主要原因是,现有的语音识别模型往往依赖于大量的标注语音数据,而这些数据对于许多语言来说难以获得。 近年来,尽管语音识别技术取得…...

ViewStub的原理
**ViewStub是Android开发中的一个轻量级控件,主要用于懒加载布局以提高应用程序的性能和响应速度。**其原理和工作方式如下: 定义与特点 轻量级与不可见:ViewStub是一个不可见的、不占布局位置的轻量级View,它在初始化时不会实例…...

十一、Spring AOP
十一、Spring AOP 1. AOP概述2. Spring AOP快速⼊⻔2.1 引⼊AOP依赖2.2 编写AOP程序 3. Spring AOP 详解3.1 Spring AOP核⼼概念3.1.1 切点(Pointcut) Around 哪个包3.1.2 连接点(Join Point) 包下面的方法3.1.3 通知(Advice) 就是要执行的方法3.1.4 切⾯(Aspect) 3.2 通知类型…...
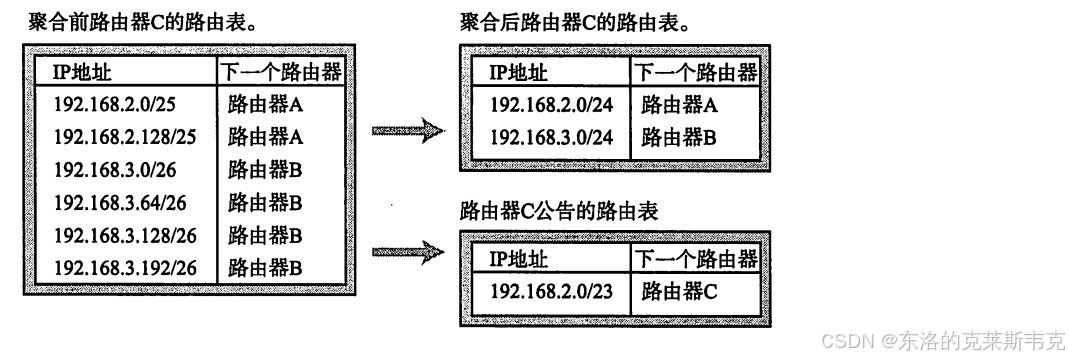
【网络】IP的路径选择——路由控制
目录 路由控制表 默认路由 主机路由 本地环回地址 路由控制表的聚合 网络分层 个人主页:东洛的克莱斯韦克-CSDN博客 路由控制表 在数据通信中,IP地址作为网络层的标识,用于指定数据包的目标位置。然而,仅有IP地址并不足以确…...
Unity动画模块 之 2D IK(反向动力学)
本文仅作笔记学习和分享,不用做任何商业用途 本文包括但不限于unity官方手册,unity唐老狮等教程知识,如有不足还请斧正 1.什么是IK 反向动力学 IK(Inverse Kinematics)是一种方法,可以根据某些子关节的最…...
关于kickstart自动安装脚本以及dhcp的设置
我将在rhel7.9内进行本次实验,需要安装并启动图形界面 hostnamectl查看是否有图形界面 没有的话 可以使用yum group list 查看,并安装server with GUI yum group install "server with GUI" -y安装完成后可以使用init 5启动 安装kickstart自…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...
损坏诊断全解)
半导体元件(二极管/三极管/MOS管/IC)损坏诊断全解
半导体元件(二极管、三极管、MOS 管、集成电路)是 PCB 的核心功能单元,对过压、过流、ESD、高温极度敏感,损坏后直接导致电路功能失效、短路烧板。很多工程师维修时盲目更换芯片,不仅成本高,还易误判。一…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

告别多头对接!DMXAPI 为企业打造国产大模型 “统一入口”
一、企业 AI 落地的普遍痛点:被接口和平台消耗的成本在企业数字化转型的浪潮中,AI 大模型已经成为标配,但很多企业在落地时,都会陷入一个共同的困境:为了满足不同业务场景的需求,需要同时对接 DeepSeek、阿…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...

正视孩童情绪波动,耐心陪伴平稳疏导
孩子的情绪就像夏天的天气,前一秒还晴空万里,后一秒可能就乌云密布。面对突如其来的哭闹、发脾气或者闷闷不乐,很多家长会急着“灭火”——要么讲道理,要么直接制止。但其实,情绪波动本身不是问题,它是孩子…...