端到端 AWS 定量分析:使用 AWS 和 AWSCLI 自动运行脚本
使用 AWSCLI 启动、运行和关闭 AWS 服务器

添加图片注释,不超过 140 字(可选)
欢迎来到雲闪世界。我们开发了两个 Python 脚本;一个用于为我们获取数据,另一个用于使用 sklearn 的决策树分类器处理数据。然后,我们将它们上传到 AWS 上的 S3 存储桶,以便妥善保管并方便从其他 AWS 服务访问。
在这篇文章中,我们将探讨如何设置一个工作流,该工作流为我们创建一个处理服务器,在该服务器中对我们的数据进行模型训练,然后在完成后删除该服务器。
在 Amazon Web Service (AWS) 上运行一组模型
AWS 的定价模式是“按使用量付费”,这意味着我们可以创建一个服务器,在其上进行一些数据处理,然后将其拆除,我们只需为服务器运行的时间付费。此外,我们将使用一个客户端库来启动服务器(创建服务器的花哨术语)和拆除服务器,称为 AWSCLI(AWS 客户端)。
配置我们的客户端应用程序
首先,我们将安装并配置 AWSCLI。我将使用 AWS CLI v2。安装后,我们可以测试它是否正常工作
aws2 --version >>> aws-cli/2.0.0dev2 Python/3.7.5 Windows/10 botocore/2.0.0dev1
然后我们进行配置。在配置 AWSCLI 时,此页面可能对默认区域选择有用。
我们还应该通过运行来创建默认角色
aws2 emr 创建默认角色
创建引导文件
配置完成后,我们可以使用 AWSCLI 启动服务器。如何创建一个引导文件来为我们初始化服务器。您会注意到我们需要在服务器中安装 pandas 和 matplotlib 等软件包,因为它附带了一些最低限度的 python 软件包。
这将是我们的引导文件:
#!/bin/bash
sudo update-alternatives --set python /usr/bin/python3.6
sudo python3 -m pip install pandas requests numpy matplotlib s3fs
aws s3 sync s3://workflow-scripts/ /home/hadoop/
sudo python3 /home/hadoop/obtain_data.py AAPL --output_directory s3://data-files-
第一行将python命令设置为指向 Python 3(当前为 3.6),而不是默认的 2.7(为什么默认仍然是 2.7?Bezos,自宣布弃用以来已经 6 年了)。这样,我们漂亮的脚本将由 Python 3.x 运行
-
第二条命令使用 python 安装我们所需的库。您可以随意在此处添加对您有用的任何其他库。
-
第三个命令将存储桶的内容复制workflow-scripts到集群中。您必须将其替换workflow-scripts为您的存储桶名称。
-
第四行运行脚本(您可以在此处获取),该脚本将为我们获取数据,并将该数据存储在适当的 S3 存储桶中。您必须将 替换data-files为您的存储桶名称。
这个引导脚本将是我们服务器设置时运行的第一个项目。
配置 S3 的读/写权限
我们现在有了设置脚本和基本数据处理脚本。我们几乎可以运行代码了。我们需要确保脚本可以读取和写入 S3 存储桶。
我们将向默认角色添加允许该操作的策略。 这是什么意思?好吧,当我们创建一个 EMR 集群(一组为我们进行处理的计算机)时,我们会为该集群分配一个角色,这意味着我们赋予它一些权限来执行诸如在集群中安装库之类的操作。它就像我们的集群能够执行的操作的集合。希望我们按照指示创建了默认角色。但是,这些角色不包括与私有的 S3 存储桶交互的权限。有两种方法可以解决这个问题:
-
将存储桶中的文件完全公开(这真是一个糟糕的想法)
-
投入更多时间进行 AWS 配置,并赋予某些角色与我们拥有的 S3 存储桶进行交互的能力(效果要好得多)
导航到 AWS 中的 IAM 控制台,我们将找到所有可用角色的列表:
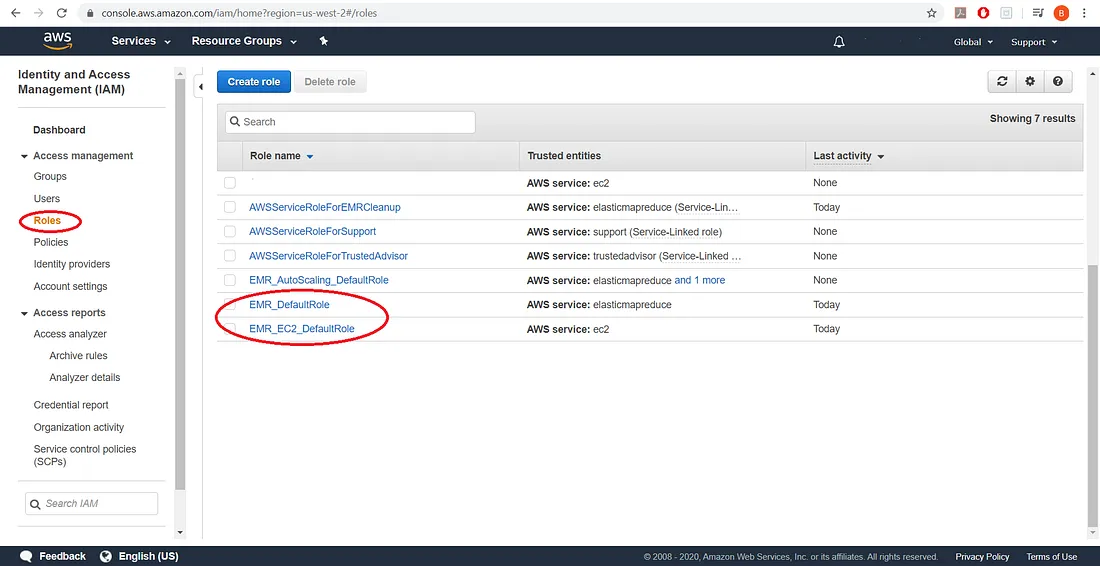
添加图片注释,不超过 140 字(可选)
然后点击每个默认角色,并选择添加内联策略
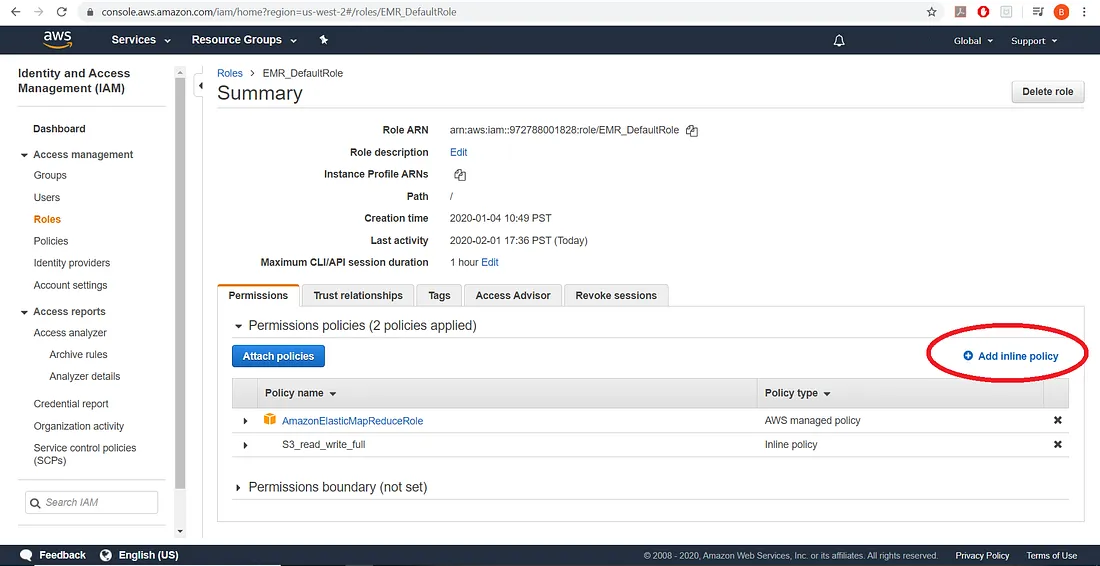
然后我们将为我们的角色添加完整的读写策略,如下所示:
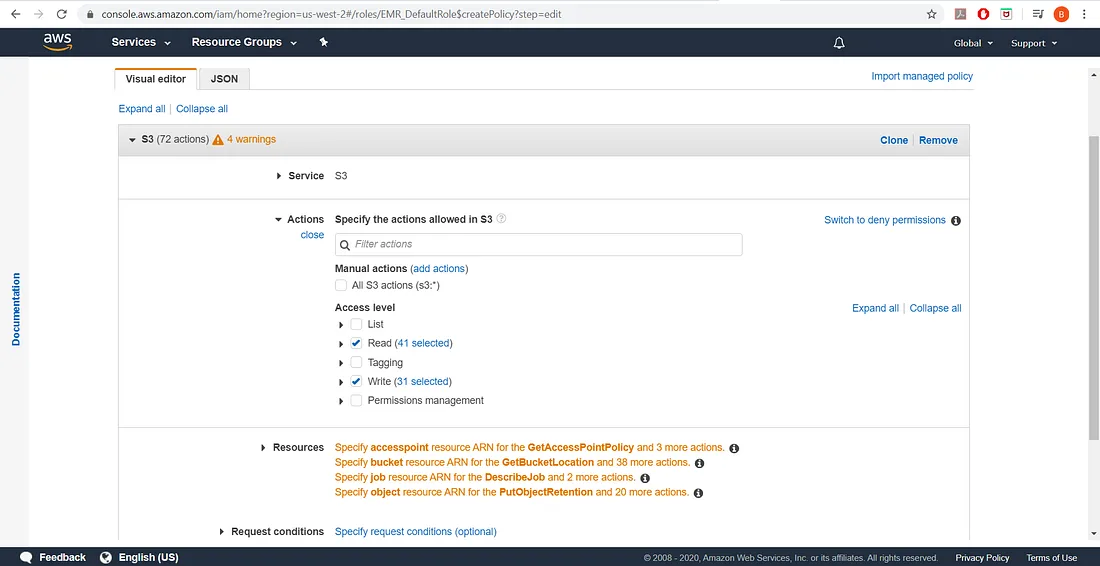
添加图片注释,不超过 140 字(可选)
实际上,我们可以更加具体地制定我们的策略以及我们的角色如何与 S3 存储桶进行交互。现在,我们将为所有四个资源组(访问点、存储桶、作业和对象)选择“任意”,然后我们可以审查策略并批准它。
如果有需要,应该选择更严格的条件。
YARN 的配置文件
我们在本演示中要做的事情将需要机器上大量的 RAM,超过默认值允许的量。因此,我们必须创建一个配置文件来帮助我们解决这个问题。
一般情况下,大数据不会全部加载到 RAM 中,而是使用 HIVE 或 Spark 进行交互。然而,为了将 Spark 与我们的经典机器学习方法进行比较,我们将反其道而行之,将大量数据加载到 RAM 中。
让我们在本地机器上创建一个名为 config.json 的配置文件。配置文件如下所示:
[{"Classification": "yarn-site","Properties": {"yarn.scheduler.minimum-allocation-mb": "1024","yarn.scheduler.maximum-allocation-mb": "30384","yarn.nodemanager.resource.memory-mb": "30384","yarn.nodemanager.vmem-check-enabled": "false","yarn.nodemanager.pmem-check-enabled": "false"}}
]它与我们的资源管理器 YARN(又一个资源协商器)打交道,并告诉我们可以为整个应用程序分配多少内存,以及告诉 YARN 不要检查内存违规(整个内存中只有一小部分会分配给我们的 Python 脚本,因此我们需要停止检查那小块之外的违规行为)。
再次强调,这样做是为了比较我们的基础sklearn决策树,而不是处理大数据的方式。
为我们的集群设置身份验证
我们必须从 EC2 仪表板创建一个密钥对,并将其下载到我们的计算机
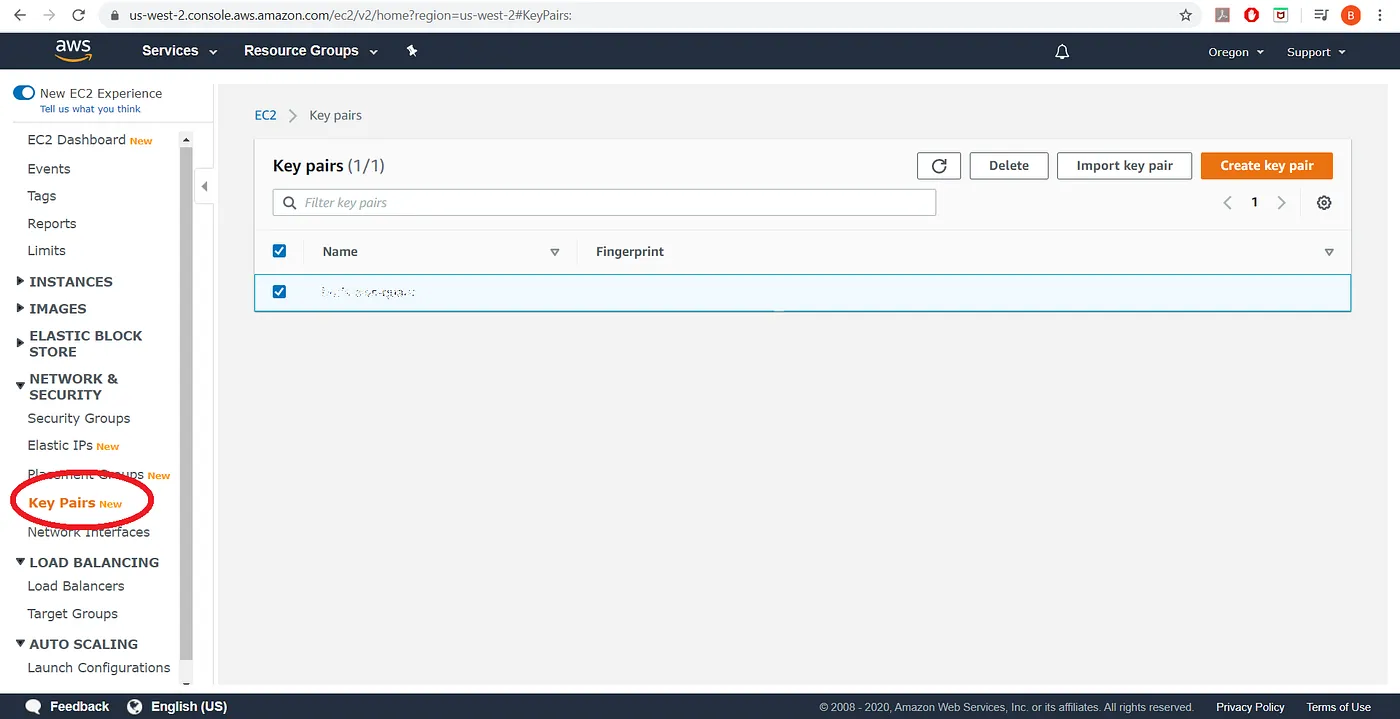
添加图片注释,不超过 140 字(可选)
下载密钥对后,你必须通过运行以下命令使其可读
chmod 400 我的密钥对.pem使用终端 (Mac) 或 Git-Bash (Windows) 在文件上。这样您以后就可以连接到您启动的实例(如果它正在运行)。
通过 AWS CLI 启动 EMR 集群
终于,我们期待已久的时刻到了。使用 AWSCLI,我们可以舒舒服服地在家里启动一个集群来为我们做一些工作。为此,我们将运行以下命令:
aws2 emr create-cluster \ --name "带步骤的 Spark 集群" \ --release-label emr-5.29.0 \ --applications Name=Spark \ --log-uri s3://log-bucket/logs/ \ --ec2-attributes KeyName= my-key-pair \ --instance-type m5.2xlarge \ --instance-count 1 \ --bootstrap-actions Path= s3://scripts-and-setup/bootstrap_file.sh \ --configuration file://config.json \ --steps Name="Command Runner",Jar="command-runner.jar",Args=["spark-submit","--deploy-mode=cluster","--executor-memory","20G"," s3://workflow-script/process_data.py , s3://data-files/ AAPL.csv”] \ --use-default-roles \ --auto-terminate 这个命令有很多内容,所以让我们来解析一下重要内容:
-
aws2 emr create-cluster— 希望这是不言自明的
-
--name "Spark cluster with step"— 将此名称替换为您喜欢的任何名称,但这将是集群的名称
-
--release-label emr-5.29.0— 要使用的集群的版本。不同版本的集群包含各种其他应用程序的不同版本,例如 Hadoop、Spark、Hive 等。
-
--applications Name=Spark— 我们将推出一款 Spark 应用程序
-
--log-uri s3://log-bucket/logs/—这是我们将日志发送到的地方。您需要一个日志存储桶,以防您的集群发生故障,您可以查看出错的日志。您必须用您的存储桶替换它。
-
--ec2-attributes KeyName=my-key-pair—这是您稍后可以使用的密钥对,以便建立与集群的 ssh 连接(如果需要)
-
--instance-type m5.2xlarge— 这是我们将使用的实例类型和大小。AWSCLI 不支持小于 xlarge 的实例
-
--instance-count 1— 我们将仅启动 1 个实例(实际上并不像集群那样,但我们将在下一篇文章中介绍它)
-
--bootstrap-actions Path=s3://scripts-and-setup/bootstrap_file.sh— 这是命令的一部分,告诉集群使用哪个脚本来启动集群。您必须将其替换为您的脚本文件位置
-
--configuration file://config.json— 这告诉 AWSCLI 使用我们创建的 config.json 文件,前缀file://告诉 AWSCLI 这是我们机器的本地文件(尽管我们也可以将其存储在 AWS S3 上)
-
--steps Name="Command Runner",Jar="command-runner.jar",Args=["spark-submit","--deploy-mode=cluster","--executor-memory","20G","s3://workflow-scripts/process_data.py, s3://data-files/AAPL.csv"]— 这个相当复杂,所以我们将其进一步分解。首先,我们将使用command-runner.jarJar 文件运行我们的 python 脚本。这是一个 Java 可执行文件,它将运行我们的 python 脚本并管理所有与 Spark 相关的工作。 我们向该 .jar 文件发送一些参数Args。它们是spark-submit,表示这项作业已提交给 Spark 框架,,--deploy-mode=cluster表示我们正在集群内部启动我们的可执行文件(而不是从我们的家用非 AWS 机器启动),我们要求 Spark 框架在运行我们的脚本及其其他步骤时使用 20GB 内存(实际上,由于 Spark 和 YARN 之间的内存分配方式,我们的脚本会少一些),命令"--executor-memory"和"20G",最后是最后一个参数,它神奇地通过 AWS 魔法被解析成(注意,逗号被空格替换以形成完整的命令)。这是 Spark 环境将运行的完整命令,即我们的 Python 脚本(在此处下载)及其所有参数。对于这一步,您必须将存储桶名称替换为您自己的适当名称。 s3://workflow-scripts/process_data.py, s3://data-files/AAPL.csv s3://workflow-scripts/process_data.py s3://data-files/AAPL.csv
-
--use-default-roles— 告诉 AWS 使用我们之前设置的默认角色
-
--auto-terminate— 这是一个非常漂亮的参数。它告诉集群在完成所有处理后终止,这样我们就不必让集群闲置在那里,不做任何事情就从我们的信用卡中扣款。如果您想让集群保持运行以进行调试,您可以忽略此参数或使用显式版本--no-auto-terminate。但是,请确保您手动终止它。
我们的运行结果
在我的计算机上输入命令后,集群大约需要 2 秒钟才能启动,又需要 12 分钟才能完成我要求的所有操作并终止。检查 S3 存储桶上的日志时,决策树分类器报告已运行 8 分钟进行拟合和预测。
到目前为止,我们已经启动了一个节点来为我们进行一些处理,请注意,我们使用比家用笔记本电脑更强大的机器获得了好处。我们使用 sklearn 进行分析的代码现在在一台功能强大的计算机上运行了约 12 分钟。 虽然这个集群在分布式计算领域还没有做太多事情,但我们已经为 Spark 的运行奠定了基础。我在这里提到过几次 Spark,在下一篇文章中,我将最终展示这个框架在我们用决策树探索的相同数据上的实际运行情况。
迄今总成本
我想在这里停下来谈谈成本问题。练习和磨练 AWS 技能的最大障碍之一是,在大多数数据科学信息和技能都是免费的(Kaggle 的免费数据集、Python 和 R 等免费编程工具)的情况下,AWS 需要花钱,而且直到第二天收到账单后才完全清楚要花多少钱。 在学习和试验如何正确设置此设置的过程中,我已经启动(设置)和拆除了 100 多个集群,到目前为止,我注册 AWS 的总费用约为 1 美元,加上所有这些集群的费用不到 5 美元。到目前为止,我的账单很便宜,主要是因为我的每个“集群”中只有一个实例(--instance-count 1),而且我使用类型集群练习了大多数启动和拆除m5.xlarge。我将数据框的大小缩小到原型,并最终在 上进行了原型设计m5.2xlarge。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
订阅频道(https://t.me/awsgoogvps_Host) TG交流群(t.me/awsgoogvpsHost)
#aws CLI cheat sheet #aws cli Debug #aws cli get S3 object #aws cli login with access key #aws cli to download from s3 #aws command line download from s3 #homebrew install aws cli#aws sdk get caller identity #aws s3 cli get object #aws s3 put object#aws s3 headobject#aws s3 put-object #aws s3 sync vs cp
相关文章:
端到端 AWS 定量分析:使用 AWS 和 AWSCLI 自动运行脚本
使用 AWSCLI 启动、运行和关闭 AWS 服务器 添加图片注释,不超过 140 字(可选) 欢迎来到雲闪世界。我们开发了两个 Python 脚本;一个用于为我们获取数据,另一个用于使用 sklearn 的决策树分类器处理数据。然后…...

数据结构与算法 - B树
一、概述 1. 历史 B树(B-Tree)结构是一种高效存储和查询数据的方法,它的历史可以追溯到1970年代早期。B树的发明人Rudolf Bayer和Edward M. McCreight分别发表了一篇论文介绍了B树。这篇论文是1972年发表于《ACM Transactions on Database Systems》中的ÿ…...

Java二十三种设计模式-观察者模式(15/23)
观察者模式:实现对象间的松耦合通知机制 引言 在当今的软件开发领域,设计模式已成为创建可维护、可扩展和可重用代码的基石。在众多设计模式中,观察者模式以其独特的能力,实现对象间的松耦合通信而脱颖而出。本文将深入探讨观察…...

opencv-python图像增强二:图像去雾(暗通道去雾)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、简介:二、暗通道去雾方案简述:三、算法实现步骤3.1最小值滤波3.2 引导滤波3.3 计算图像全局光强 四:整体代码实现五…...

自研Vue3低代码海报制作平台第一步:基础拖拽组件开发
学习来源:稀土掘金 - 幽月之格大佬的技术专栏可拖拽、缩放、旋转组件 - 著作:可拖拽、缩放、旋转组件实现细节 非常感谢大佬!受益匪浅! 前面我们学习了很多vue3的知识,是时候把它们用起来做一个有意思的平台…...

QT 的 QSettings 读写 INI 文件的示例
在Qt中,QSettings 类提供了一种便捷的方式来存储和访问应用程序的设置,这些设置可以存储在多种格式的文件中,包括INI、Windows注册表(仅Windows平台)、XML和JSON等。以下是一些使用 QSettings 读写INI文件的示例。 写…...

【零基础学习CAPL语法】——testStep:测试结果输出函数
文章目录 1.函数介绍2.在报告中体现 1.函数介绍 testStep——测试结果输出函数 2.在报告中体现 //testStep() void PrintTxMsg() {testStep("Tx","[%x] [%.2x %.2x %.2x %.2x %.2x %.2x %.2x %.2x]",Diag_Req.id,Diag_Req.byte(0),Diag_Req.byte(1),Di…...

8.5.数据库基础技术-规范化
函数依赖 函数依赖:给定一个X,能唯一确定一个Y,就称X决定(确定)Y,或者说Y依赖于X。 例如:YX*X函数,此时X能确定Y的值,但是Y无法确定X的值,比如x2,y4,但是y4无法确定x2。函数依赖又可扩展以下两…...

于博士Cadence视频教程学习笔记备忘
标签:PCB教程 PCB设计步骤 cadence教程 Allegro教程 以下是我学习该视频教程的笔记,记录下备忘,欢迎大家在此基础上完善,能回传我一份是最好了,先谢过。 备注: 1、未掌握即未进行操作 2、操作软件是15.…...

8.3.数据库基础技术-关系代数
并:结果是两张表中所有记录数合并,相同记录只显示一次。交:结果是两张表中相同的记录。差:S1-S2,结果是S1表中有而S2表中没有的那些记录。 笛卡尔积:S1XS2,产生的结果包括S1和S2的所有属性列,并且S1中每条记…...
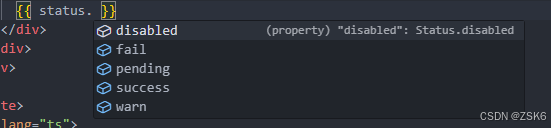
【Vue3】vue模板中如何使用enum枚举类型
简言 有的时候,我们想在vue模板中直接使用枚举类型的值,来做一些判断。 ts枚举 枚举允许开发人员定义一组命名常量。使用枚举可以更容易地记录意图,或创建一组不同的情况。TypeScript 提供了基于数字和字符串的枚举。 枚举的定义这里不说了…...

组合求和2
题目描述: Given a collection of candidate numbers (candidates) and a target number (target), find all unique combinations in candidates where the candidate numbers sum to target. Each number in candidates may only be used once in the combinati…...
Apple Maps现在可在Firefox和Mac版Edge浏览器中使用
Apple Maps最初只能在 Windows 版 Safari、Chrome 浏览器和 Edge 浏览器上运行,现在已在其他浏览器上运行,包括 Mac 版 Firefox 和 Edge。经过十多年的等待,Apple Maps于今年 7 月推出了新版地图应用的测试版,但只能在有限的浏览器…...
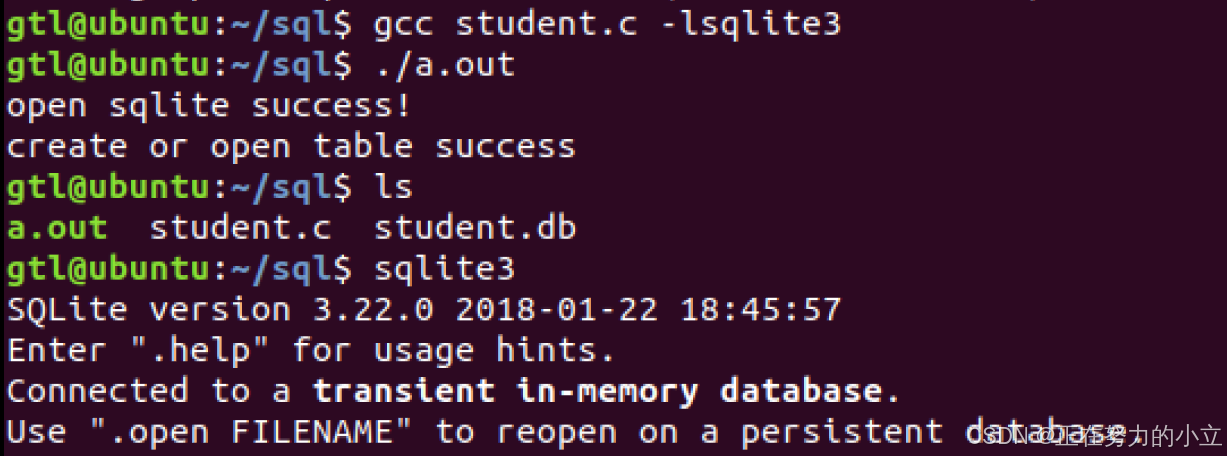
基于嵌入式Linux的数据库
数据库 数据库是在数据库管理系统和控制之下,存放在存储 介质上的数据集合。 基于嵌入式的数据库 基于嵌入式linux的数据库主要有SQlite, Firebird,Berkeley DB,eXtremeDB Firebird是关系型数据库,功能强大,支持存储过 程&…...

C# 使用LINQ找出一个子字符串在另一个字符串中出现的所有位置
一、实现步骤 遍历主字符串,使用IndexOf方法查找子字符串的位置。如果找到了子字符串,记录其位置,并且从该位置的后面继续查找。重复上述步骤直到遍历完整个字符串。 二、简单代码示例 using System; using System.Collections.Generic; usi…...
)
YOLOv8添加MobileViTv3模块(代码+free)
目录 一、理由 二、方法 (1)导入MobileViTv3模块 (2)在ultralytics/nn/tasks.py的函数parse_model中修改 (3)在yaml配置文件中写入 (4)开始训练,先把其他梯度关闭&…...

从概念到落地:全面解析DApp项目开发的核心要素与未来趋势
随着区块链技术的迅猛发展,去中心化应用程序(DApp)逐渐成为Web3时代的重要组成部分。DApp通过智能合约和分布式账本技术,提供了无需信任中介的解决方案,这种去中心化的特性使其在金融、游戏、社交等多个领域得到了广泛…...
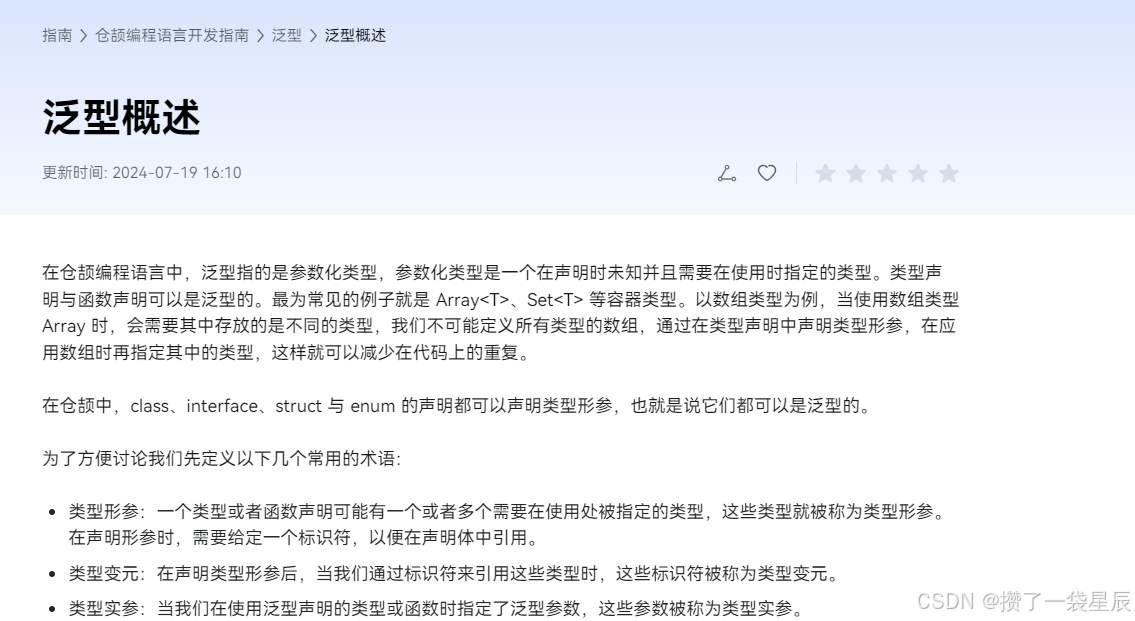
仓颉编程入门 -- 泛型概述 , 如何定义泛型函数
泛型概述 , 如何定义泛型函数 1 . 泛型的定义 在仓颉编程语言中,泛型机制允许我们定义参数化类型,这些类型在声明时不具体指定其操作的数据类型,而是作为类型形参保留,待使用时通过类型实参来明确。这种灵活性在函数和类型声明中…...

SOC估算方法之(OCV-SOC+安时积分法)
一、引言 此方法主要参考电动汽车用磷酸铁锂电池SOC估算方法这篇论文 总结: 开路电压的测量需要将电池静止相当长的一段时间才能达到平衡状态进行测量。 安时积分法存在初始SOC的估算和累积的误差。 所以上述两种方法都存在一定的缺陷,因此下面主要讲…...
)
指针(下)
文章目录 指针(下)野指针、空指针野指针空指针 二级指针**main**函数的原型说明 常量指针与指针常量常量指针指针常量常量指针常量 动态内存分配常用函数**malloc****calloc****realloc****free** **void**与**void***的区别扩展:形式参数和实际参数的对应关系 指针…...

别再自己造轮子了!用DJI Pilot 2 + 上云API,30分钟搞定无人机数据上云
30分钟极速对接:用DJI Pilot 2与上云API实现无人机数据云端整合 在智慧城市巡检或应急指挥场景中,实时获取无人机航拍画面与飞行数据往往是业务闭环的关键。传统方案需要投入数月时间开发定制化App,而大疆最新推出的上云API方案,让…...

OpenClaw多模态技能开发:为Phi-3-vision-128k-instruct增加PDF图表提取功能
OpenClaw多模态技能开发:为Phi-3-vision-128k-instruct增加PDF图表提取功能 1. 为什么需要PDF图表提取能力 上周我在研究一份技术白皮书时遇到了典型痛点——PDF里那些精美的架构图和流程图无法直接复制使用。手动截图再粘贴到文档里不仅效率低下,更重…...

分布式系统CAP理论之如何取舍
在分布式系统中,CAP 理论 是一个基石性、指导性的理论,它告诉我们:在设计分布式系统时,无法同时满足三个核心特性,只能在三者之间做权衡。🌐 一、CAP 理论的三个字母代表什么?字母含义说明CCons…...

【 Claw-Code】 技术深度解析:Claude Code Agent Harness 的开源重实现
文章目录Claw-Code 技术深度解析:Claude Code Agent Harness 的开源重实现一、引言二、项目背景与定位2.1 为什么是"洁室重实现"2.2 项目核心目标三、双语言架构设计3.1 双语言实现对比3.2 Rust Workspace 模块划分四、核心组件解析4.1 运行时(…...

6 鸿蒙应用启动速度优化全流程拆解 | 鸿蒙开发筑基实战
6 鸿蒙应用启动速度优化全流程拆解 | 鸿蒙开发筑基实战 作者:杨建宾(华夏之光永存) 摘要 本文面向鸿蒙应用开发工程师,聚焦应用启动慢、首屏白屏等核心痛点,拆解从代码配置到资源处理的全流程优化方案。内容包含启动流…...

OpenClaw新手入门:千问3.5-9B镜像一键部署与初体验
OpenClaw新手入门:千问3.5-9B镜像一键部署与初体验 1. 为什么选择这个组合? 去年冬天,我第一次在本地尝试用OpenClaw自动整理电脑上的照片。当时对接的是GPT-3.5,每次识别图片内容都要消耗大量token,一个月下来账单让…...

提升Telegraf性能:未使用方法接收器的代码优化实战指南
提升Telegraf性能:未使用方法接收器的代码优化实战指南 在Go语言开发中,方法接收器(Method Receiver)是连接函数与结构体的重要桥梁,但过度使用或不当使用会导致性能损耗和代码冗余。Telegraf作为插件驱动的指标收集代…...

终极指南:gin-vue-admin前端错误监控告警配置详解 - 邮件与钉钉实时通知方案
终极指南:gin-vue-admin前端错误监控告警配置详解 - 邮件与钉钉实时通知方案 【免费下载链接】gin-vue-admin 🚀ViteVue3Gin拥有AI辅助的基础开发平台,企业级业务AI开发解决方案,内置mcp辅助服务,内置skills管理&#…...

EasyAnimation性能优化指南:确保动画流畅运行的7个关键点
EasyAnimation性能优化指南:确保动画流畅运行的7个关键点 【免费下载链接】EasyAnimation A Swift library to take the power of UIView.animateWithDuration(_:, animations:...) to a whole new level - layers, springs, chain-able animations and mixing view…...

工业冷水机控制程序西门子1200plc含压缩机,电子膨胀阀控制策略,饱和温度计算公式
工业冷水机控制程序西门子1200plc含压缩机,电子膨胀阀控制策略,饱和温度计算公式凌晨三点钟的冷水机组房,设备轰鸣声中闪烁着PLC运行指示灯。手指划过TP1200触摸屏的瞬间,压缩机启动电流曲线在屏幕上划出漂亮的爬坡轨迹——这就是…...