【JavaEE】JVM 内存区域划分,以及 Java 垃圾回收机制引用计数器,可达性分析等

目录
1. JVM执行流程
2. JVM运行时数据区
2.1 堆
2.2 Java虚拟机栈(线程私有)
2.3本地方法栈(线程私有)
2.4 程序计数器
2.5 元数据区
3. JVM的类加载机制
1) 加载
2) 验证
3) 准备
4) 解析
5) 初始化
双亲委派模型
4. java垃圾回收
4.1 死亡对象判断方法
a) 引用计数算法
b) 可达性分析算法(JVM使用此方法)
4.2 垃圾回收算法
a) 标记清除算法
b) 复制算法
c) 标记-整理算法
d) 分代算法
1. JVM执行流程
JVM是Java运行的基础,也是实现一次编译到处执行的关键,那么JVM是如何执行的呢?
程序在执行之前先要把java代码转换成字节码 (class文件) , JVM 首先需要把字节码通过一定的方式类加载器(ClassLoader) 把文件加载到内存中 运行时数据区(Runtime Data Area), 而字节码文件是 JVM 的一套指令规范, 并不能直接交给底层操作系统去执行, 因此需要特定的命令解析器 执行引擎(Execution Engine) 将字节码翻译成底层系统指令, 再交由CPU去执行, 而这个过程需要调用其他语言的接口 本地库接口(Native Interface) 来实现整个程序的功能, 这就是4个主要组成部分的职责与功能.

总的来看, JVM 主要通过分为一下4个部分, 来执行Java程序的, 它们分别是:
1. 来加载器(ClassLoader)
2. 运行时数据区 (Runtime Data Area)
3. 执行引擎 (Execution Engine)
4. 本地库接口 (Native Interface)
2. JVM运行时数据区
jvm 从系统申请了一大块内存, 这一大块内存给 java 程序使用的时候, 右会根据实际的使用用途来换分出不同的空间, 这个就是区域划分.
JVM运行时数据区域也叫内存布局,但需要注意的是它和Java内存模型((Java Memory Model, 简
称JMM)完全不同,属于完全不同的两个概念,它由以下5大部分组成:
2.1 堆
堆的作用: 程序中创建(new) 的所有对象都保存在堆中.
我们常见的JVM参数设置-Xms10m最小启动内存是针对堆的,-Xmx10m最大运行内存也是针对堆的。
ms 是 memory start 简称,mx 是 memory max 的简称。
堆里面分为两个区域:新生代和老生代,新生代放新建的对象,当经过一-定 GC次数之后还存活的对象会放入老生代。新生代还有3个区域:一个Endn +两个Survivor (S0/S1) 。
垃圾回收的时候会将Endn中存活的对象放到一个未使用的Survivor中,并把当前的Endn和正在使
用的Survivor清楚掉。
2.2 Java虚拟机栈(线程私有)
栈分为本地方法栈和/虚拟机栈, 其中包含了方法调用关系和局部变量;
虚拟机栈记录了 java 代码的调用关系和java代码的局部变量 ;
本地方法栈记录了本地方法的调用关系和局部变量, 也就是在 jvm 内部通过 C++ 写的代码的调用关系和局部变量. (一般不会关注本地方法栈)
Java虚拟机栈的作用: Java 虚拟机栈的生命周期和线程相同,Java 虚拟机栈描述的是Java方法执行的内存模型: 每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。咱们常说的堆内存、栈内存中,栈内存指的就是虚拟机栈。
Java虚拟机栈中包含了以下4部分:
1. 局部变量表: 存放了编译器可知的各种基本数据类型(8大基本数据类型)和对象引用. 局部变量表是所需内存空间在编译期间完成的分配, 当进入一个方法时, 这个方法需要在帧中分配多大的局部变量是完全确定的, 在执行期间不会改变局部变量表的大小. 简单来说就是存放方法参数和局部变量.
2.操作栈: 每个方法会生成一个先进后出的操作栈。
3.动态链接: 指向运行时常量池的方法引用。
4.方法返回地址: PC 寄存器的地址。
什么是线程私有?
由于JVM的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现,因此在任何一个确定的时刻,一个处理器(多核处理器则指的是一个内核)都只会执行一条线程中的指令。因此为了切换线程后能恢复到正确的执行位置, 每条线程都需要独立的程序计数器,各条线程之间计数器互不影响,独立存储。我们就把类似这类区域称之为"线程私有"的内存。
2.3本地方法栈(线程私有)
本地方法栈和虚拟机栈类似,只不过Java虚拟机栈是给JVM使用的,而本地方法栈是给本地方法使
用的。
2.4 程序计数器
这个区域比较小的空间, 专门用来存储下一条要执行的 java 指令的地址
程序计数器的作用: 用来记录当前线程执行的行号的.
程序计数器是一块比较小的内存空间, 可以看作是当前线程所执行的字节码的行号指示器.
如果当前线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地
址;如果正在执行的是一个Native方法,这个计数器值为空。
程序计数器内存区域是唯一 一个 在JVM规范中没有规定任何OOM情况的区域!
2.5 元数据区
"元数据" 是计算机中的一个常见术语(mete data), 往往指的是一些辅助性质的, 描述性质的属性.
一个程序有哪些类, 每个类都有哪些方法, 每个方法都要包含哪些指令, 都会记录在元数据区
经典笔试题

小结

3. JVM的类加载机制
类加载指的是 java 进程运行的时候, 需要把.class 文件从硬盘读取到内存, 并进行一系列校验解析的过程.
对于一个类来说,它的生命周期是这样的: 
其中前5步是固定的顺序并且也是类加载的过程,其中中间的3步我们都属于连接,所以对于类加载
来说总共分为以下几个步骤:
1.加载
2.连接
a.验证
b.准备
c.解析
3.初始化
下面我们分别来看每个步骤的具体执行内容。
1) 加载
把硬盘上的.class 文件找到, 打开文件读取文件的内容(认为读到的是二进制的数据)
“加载”(Loading) 阶段是整个“类加载”(Class Loading)过程中的一个阶段,它和类加载
Class Loading是不同的,一个是加载Loading另一个是类加载Class Loading,所以不要把二者搞混
了。
在加载Loading阶段,Java虚拟机需要完成以下三件事情:
1) 通过一个类的全限定名来获取定义此类的二进制字节流。
2) 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
3) 在内存中生成-个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
2) 验证
需要确保读到的文件的内容, 是合法的.class 文件(字节码文件)格式
具体的验证依据, 在java的虚拟机规范中, 有明确的格式说明.
验证是连接阶段的第一步,这一阶段的目的是确保Class文件的字节流中包含的信息符合《Java虚 拟机规范》的全部约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全。
验证选项:
- 文件格式验证
- 字节码验证
- 符号引用验证....
3) 准备
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值
的阶段。
比如此时有这样一行代码:
public static int value= 123;它是初始化value的int值为0,而非123。
4) 解析
解析阶段是Java虛拟机 将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
符号应用和直接应用:
5) 初始化
初始化阶段,Java 虚拟机真正开始执行类中编写的Java程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程。
把类对象的各个部分的属性进行赋值填充, 触发对父类的加载, 初始化静态成员, 执行静态代码块.
双亲委派模型
双亲委派模型用于加载环节, 描述了如何查找 .class 文件的策略
双亲委派模型是一种Java类加载器和字节码加载器的实现策略。它主要用于解决类加载器之间的循环依赖问题。
在双亲委派模型中,当一个类加载器收到一个类的加载请求时,它首先不会自己去加载这个类,而是把这个请求委托给父类加载器去完成。只有当父类加载器无法完成这个加载任务时,子类加载器才会尝试自己去加载这个类。这样可以确保Java核心库中的类总是由其父类加载器(如Bootstrap ClassLoader)来加载,从而避免了类加载器之间的循环依赖问题。
JVM 中进行类加载的操作, 是有一个专门的模块, 称为"类加载器"(ClassLoader)
JVM 中的类加载器默认是有三个(也可以自定义)
BootStrapClassLoader : 负责查找标准库中的目录.
ExtensionClassLoader: 负责查找扩展库的目录
ApplicationClassLoader: 负责查找当前项目的代码目录以及第三方库的目录

图示过程:


双亲委派模型的优点:
1.避免重复加载类: 比如A类和B类都有一个父类C类, 那么当A启动时就会将C类加载起来, 那么在B类进行加载时就不需要在重复加载C类了.
2.安全性: 使用双亲委派模型也可以保证了 Java 的核心 API 不被篡改, 如果没有双亲委派模型, 而是每个类加载器加载自己的话就会出现一些问题, 比如我们编写一个称为 java.lang.Object类的话,那么程序运行的时候, 系统就会出现多个不同的Object来, 而有些Object类又是用户自己提供的, 因此安全性就不能得到保证了.
4. java垃圾回收
上面讲了Java运行时内存的各个区域。对于程序计数器、虚拟机栈、本地方法栈这三部分区域而言,其生命周期与相关线程有关,随线程而生,随线程而灭。并且这三个区域的内存分配与回收具有确定性,因为当方法结束或者线程结束时,内存就自然跟着线程回收了。因此我们本节课所讲的有关内存分配和回收关注的为Java堆与方法区这两个区域。
Java堆中存放着几乎所有的对象实例,垃圾回收器在对堆进行垃圾回收前,首先要判断这些对象哪些还存活,哪些已经"死去"。判断对象是否已"死"有如下几种算法
4.1 死亡对象判断方法
a) 引用计数算法
引用计数描述的算法为:
给对象增加一个引用计数器,每当有一个地方引用它时,计数器就+1; 当引用失效时,计数器就-1;
任何时刻计数器为 0 的对象就是不能再被使用的,即对象已"死"。
引用计数法实现简单,判定效率也比较高,在大部分情况下都是一一个不错的算法。比如Python语言 就采用引用计数法进行内存管理。
但是,在主流的JVM中没有选用引用计数法来管理内存,最主要的原因就是引用计数法无法解决对象的循环引用问题.
引用计数缺点:
1.消耗额外的内存空间.
要给每个对象都安排一个计数器.(如果计数器按照2个字节算), 如果整个程序中对象数目很多, 总的消耗空间也会非常多.
尤其是如果每个对象体积很小, (假设每个对象4字节), 计数器消耗的空间已经到达对象的一般
2.引用计数器可能会产生"循环引用的问题", 此时, 引用计数器就无法正常工作了.

b) 可达性分析算法(JVM使用此方法)
在.上面我们讲了,Java并不采用引用计数法来判断对象是否已"死",而采用"可达性分析"来判断对象是否存活(同样采用此法的还有C#、Lisp-最 早的- -门采用动态内存分配的语言)。
此算法的核心思想为:通过一系列称为"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称之为"引用链",当一个对象到GC Roots没有任何的引用链相连时(从GC Roots到这个对象不可达)时,证明此对象是不可用的。以下图为例: 
核心思路: 在写代码的过程中, 会定义很多的变量, 比如栈上的局部变量/方法区中的静态类型的变量/常量池中引用的对象....
就可以从这些变量作为起点出发, 尝试去进行"遍历", 所谓的遍历就是会沿着这些变量中持有的引用类型的成员, 再进一步的往下进行访问...
所有能被访问到的对象, 自然不是垃圾了, 剩下的遍历一圈也访问不到的对象, 自然就是垃圾.
4.2 垃圾回收算法
通过上面的学习我们可以将死亡对象标记出来了,标记出来之后我们就可以进行垃圾回收操作了,在正式学习垃圾收集器之前,我们先看下垃圾回收机器使用的几种算法(这些算法是垃圾收集器的指导思想)
a) 标记清除算法
"标记 - 清除" 算法是最基础的收集算法。算法分为"标记"和"清除"两个阶段: 首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。后续的收集算法都是基于这种思路并对其不足加以改进而已。
"标记 - 清除" 算法的不足主要有两个:
1.效率问题: 标记和清除这两个过程的效率都不高
2.空间问题: 标记清除后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行中需要分配较大对象时,无法找到足够连续内存而不得不提前触发另一次垃圾收集。
b) 复制算法
"复制" 算法是为了解决 "标记清理" 的效率问题。它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这块内存需要进行垃圾回收时,会将此区域还存活着的对象复制到另一块上面,然后再把已经使用过的内存区域一次清理掉。这样做的好处是每次都是对整个半区进行内存回收,内存分配时也就不需要考虑内存碎片等复杂情况,只需要移动堆顶指针,按顺序分配即可。此算法实现简单,运行高效。算法的执行流程如下图:
c) 标记-整理算法
复制收集算法在对象存活率较高时会进行比较多的复制操作,效率会变低。因此在老年代一般不能使用复制算法。
针对老年代的特点,提出了一种称之为 "标记整理算法"。标记过程仍与 "标记-清除" 过程一致,但后续步骤不是直接对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉端边界以外的内存。流程图如下:
d) 分代算法
分代算法和上面讲的3种算法不同,分代算法是通过区域划分,实现不同区域和不同的垃圾回收策
略,从而实现更好的垃圾回收。这就好比中国的一国两制方针一样,对于不同的情况和地域设置更符合当地的规则,从而实现更好的管理,这就时分代算法的设计思想。
当前JVM垃圾收集都采用的是 "分代收集(Generational Collection)" 算法,这个算法并没有新思想,
只是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代。在新生代
中,每次垃圾回收都有大批对象死去,只有少量存活,因此我们采用复制算法; 而老年代中对象存活率高、没有额外空间对它进行分配担保,就必须采用 "标记清理" 或者 "标记-整理" 算法。
哪些对象会进入新生代? 哪些对象会进入老年代?
新生代: 一般创建的对象都会进入新生代;
老年代: 大对象和经历了N次(一般情况默认是15次)垃圾回收依然存活下来的对象会从新生代
移动到老年代。

相关文章:
【JavaEE】JVM 内存区域划分,以及 Java 垃圾回收机制引用计数器,可达性分析等
目录 1. JVM执行流程 2. JVM运行时数据区 2.1 堆 2.2 Java虚拟机栈(线程私有) 2.3本地方法栈(线程私有) 2.4 程序计数器 2.5 元数据区 3. JVM的类加载机制 1) 加载 2) 验证 3) 准备 4) 解析 5) 初始化 双亲委派模型 4. java垃圾回收 4.1 死亡对象判断方法 a) …...

Web开发:C# MVC + Session机制实现授权免登录demo
token基础demo 【需求】 Home/Index 登录界面,校验成功后可以登录到Main/Index ,用户登录3分钟内关闭网站,再次访问Home/Index时可以免密登录Main/Index 【配置文件-Program.cs】 var builder WebApplication.CreateBuilder(args);// Add services t…...

【Qt】QWidget的font属性
QWidget的font属性 API说明 font() 获取当前 widget 的字体信息. 返回 QFont 对象. setFont(const QFont& font) 设置当前 widget 的字体信息. 关于Qfont 属性说明 family 字体家族. ⽐如 "楷体", "宋体", "微软雅⿊" 等. pointSiz…...
- 统计推断)
每天一个数据分析题(四百八十五)- 统计推断
假设检验中,关于p值说法正确的是? A. p值是在原假设成立时,样本观察结果发生的概率。 B. p值是接受原假设的概率 C. p值是相对样本统计量而言的 D. 用p值做决策比用域值做决策更准确 数据分析认证考试介绍:点击进入 题目来源…...
)
基于STM32的农业病虫害检测检测系统:OpenCV、MQTT、Flask框架、MySQL(代码示例)
一、项目概述 随着全球农业现代化的不断推进,智能农业监测系统应运而生。此项目旨在通过实时监测土壤湿度、温度等环境数据,结合作物生长状态的分析,提高农业生产效率和作物质量。通过引入STM32单片机、OpenCV图像处理技术和后端数据分析系统…...

算法日记day 39(动归之打家劫舍)
一、打家劫舍1 题目: 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。…...

Vue 生命周期详解含demo、面试常问问题案例
Vue 生命周期详解、面试常问问题案例 含 demo 文章目录 Vue 生命周期详解、面试常问问题案例 含 demo一、Vue 生命周期是什么二、Vue 中如何使用生命周期钩子1. **beforeCreate**2. **created**3. **beforeMount**4. **mounted**5. **beforeUpdate**6. **updated**7. **beforeD…...

表单自定义规则的校验
在 Vue 3 中使用 Element Plus 的表单组件进行自定义规则的校验非常方便。Element Plus 提供了 ElForm 和 ElFormItem 组件,它们内置了表单验证的功能。下面我将详细介绍如何使用 Element Plus 进行自定义规则的校验。 创建表单及规则 首先,你需要创建…...

JVM 有哪些垃圾回收算法(回收机制)?
JVM 有哪些垃圾回收算法(回收机制)? 标记-清除算法 在Java虚拟机中,标记-清除算法是一种用于垃圾回收的算法。它分为两个阶段:标记阶段和清除阶段。 在标记阶段,垃圾收集器会遍历堆内存中的所有对象&…...

2024年高教社杯数学建模国赛A题思路解析+代码+论文
2024年高教社杯全国大学生数学建模竞赛(以下简称国赛)将于9月5日晚6时正式开始。 下文包含:2024国赛思路解析、国赛参赛时间及规则信息说明、好用的数模技巧及如何备战数学建模竞赛 C君将会第一时间发布选题建议、所有题目的思路解析、相…...
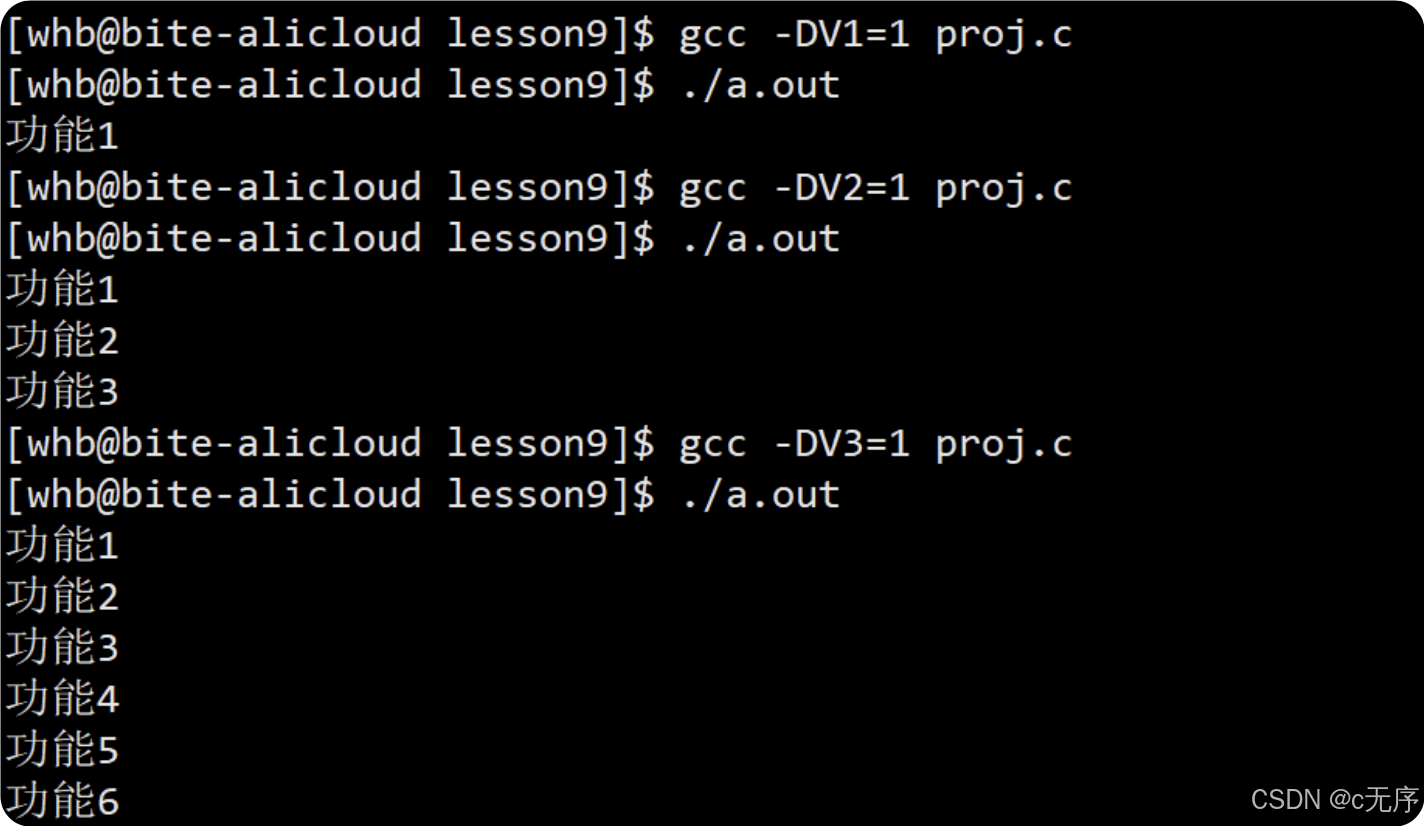
Linux中yum、vim、gcc/g++的使用
目录 一、Linux 软件包管理器 yum 什么是软件包 关于 rzsz 查看软件包★ 如何安装软件★ 如何卸载软件★ Linux 开发工具 二、Linux编译器-vim使用 vim的基本概念 vim的基本操作 vim正常模式命令集 vim末行模式命令集 vim操作总结 如果在vim界面不小心按了Ctrl …...

基于模糊神经网络的金融序列预测算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 基于模糊神经网络的金融序列预测算法matlab仿真,根据序列的MAD,RSI,KD等指标实现序列的预测和最终收益分析。 2.测试软件版本以及运行结果展示 MATLAB2022A版本…...

STM32 HAL库常用功能封装
关中断 /*** brief 关闭所有中断(但是不包括fault和NMI中断)* param 无* retval 无*/ void sys_intx_disable(void) {__ASM volatile("cpsid i"); }开中断 /*** brief 开启所有中断* param 无* retval 无*/ void sys_intx_enabl…...

golang zap日志库 打印日志时显示的源文件始终是同一个问题解决方法 zap.Option函数可选项 zap.AddCallerSkip(1) 使用示例
这种情况一般出现在我们对zap日志库进行二次封装的情况下, 在打印日志的时候的源文件非我们期望的文件,如下 原因分析 出现这个问题的原因是zap函数内部在调用 runtime.Caller 时的skip层级不对了,因为我们进行了二次封装,所以za…...

BL196MQTT远程IO模块助力智能楼宇自动化升级
在智能楼宇自动化领域,每一个细节的优化都能带来整体效率与舒适度的显著提升。钡铼技术的BL196MQTT远程IO模块,以其卓越的灵活性和强大的性能,正在成为这一领域中推动楼宇自动化升级的关键力量。 钡铼技术IOy系列:创新与灵活性的…...
)
【面试宝典】Java面向对象面试题总结(上)
一、重写和重载 在Java中,重写(Override)和重载(Overload)是面向对象编程中两个非常重要的概念,它们都与方法的定义和调用有关,但两者有着本质的区别。 1、重写(Overrideÿ…...

如何运用独特的产业运营体系打造一流的数字媒体产业园
如何运用独特的产业运营体系打造一流的数字媒体产业园 2024-08-15 17:37树莓集团 在数字经济蓬勃发展的今天,数字媒体产业作为其中的重要一环,正展现出巨大的潜力和活力。而如何运用独特的产业运营体系,打造一流的数字媒体产业园࿰…...

安全基础学习-SHA-256
SHA-256 是一种密码学哈希函数,是 SHA-2(Secure Hash Algorithm 2)家族的一部分。它被广泛用于数据完整性验证、数字签名以及密码存储等领域。 1、SHA-256的原理 SHA-256 生成一个固定长度为 256 位(32 字节)的哈希值。无论输入数据的大小或类型,输出的哈希值始终是 25…...

Redis中Big Key该如何解决?
目录 1、Big Key的产生 2、BigKey场景分析 3、Big Key的危害 4、检测 BigKey 5、解决 BigKey 问题 Big Key拆分 (1)按时间/业务拆分 (2)按哈希(Hash)拆分 (3)按前缀树拆分…...

基于springboot的实习管理系统
TOC springboot207基于springboot的实习管理系统 绪论 1.1研究背景与意义 信息化管理模式是将行业中的工作流程由人工服务,逐渐转换为使用计算机技术的信息化管理服务。这种管理模式发展迅速,使用起来非常简单容易,用户甚至不用掌握相关的…...

Oracle数据库的DBCA界面创建数据库
一、采用DBCA界面方式创建数据库搜索dbca用管理员去运行疯狂的点下一步采用默认就行到监听这里会出有一些问题出问题了先把Enterprise Manager关掉就行,出问题了能自己找出来就行,一般不建议关掉,我这里直接图方便了这里选择所有账号使用同一…...

You-Get下载视频音画不同步?可能是FFmpeg路径没配对!附Mac/Linux/Windows三平台配置指南
You-Get跨平台音视频同步解决方案:FFmpeg环境配置全指南 当你在Mac上流畅使用you-get下载合并好的视频,切换到Windows却遭遇音画分离的尴尬时,问题往往出在FFmpeg的环境配置上。本文将带你深入理解多平台下FFmpeg的配置差异,并提…...
)
【限时开源】DeepSeek-VL多模态代码重构检查清单:含19个AST级检测规则+CI/CD嵌入脚本(仅剩47份可下载)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-VL多模态代码重构的背景与价值 随着视觉语言模型(VLM)在真实工业场景中加速落地,传统单模态代码架构在处理图像-文本联合推理任务时暴露出显著瓶颈…...

展锐RM500U 5G CPE固件升级避坑指南:为什么你的QFlash总卡在‘开始下载’?
展锐RM500U 5G CPE固件升级疑难解析:从QFlash卡顿到完美升级的实战手册 当你的展锐RM500U 5G CPE设备需要固件升级时,QFlash工具本应是简单高效的解决方案。然而,许多用户在点击"Start"按钮后,却遭遇了进度条停滞不前的…...

UI-TARS Desktop 深度解析:字节跳动 34K Star 的多模态 AI Agent 栈
🖥️ UI-TARS Desktop 深度解析:字节跳动 34K Star 的多模态 AI Agent 栈 字节跳动 Bytedance 出品 | 34.3K GitHub Stars | Apache 2.0 | 超越 Claude Computer Use 🔥 前言:当 AI 学会操作电脑 2025 年 1 月,字节跳…...

状态机设计模式优雅的进行通信解包~
正文大家好,我是bug菌~在早年玩单片机的时候,最开始接触到的通信协议基本上都是串口通信协议了吧,那时候拿到一个通信需求无非想着怎么设计一个不错的通信协议,然后写出来一套惊艳的解析算法,在实践过程中你肯定遇到过…...

从华为EulerOS到openEuler:一个国产操作系统的开源之路与社区生态
从华为EulerOS到openEuler:一个国产操作系统的开源之路与社区生态在开源软件的世界里,每一个成功项目的背后都有一段独特的故事。当华为决定将其内部使用的EulerOS操作系统开源为openEuler时,这不仅是一个技术决策,更是一次关于开…...

深入理解RAG中的嵌入模型Embedding Model
前言在当前流行的RAG引擎(例如RAGFlow、Qanything、Dify、FastGPT等)中,嵌入模型(Embedding Model)是必不可少的关键组件。在RAG引擎中究竟扮演着怎样的角色呢?本文笔者进行了总结,与大家分享~什…...
)
不只是配置:在AutoDL上为你的深度学习项目打造可复现、可迁移的专属环境(Python 3.8 + CUDA 11.3)
不只是配置:在AutoDL上为你的深度学习项目打造可复现、可迁移的专属环境(Python 3.8 CUDA 11.3)深度学习项目的成功往往始于一个稳定、可复现的环境配置。对于在AutoDL平台上工作的开发者而言,如何超越基础的环境搭建,…...

Token CSS高级技巧:如何扩展自定义设计令牌和主题的终极指南
Token CSS高级技巧:如何扩展自定义设计令牌和主题的终极指南 【免费下载链接】tokencss 项目地址: https://gitcode.com/gh_mirrors/to/tokencss Token CSS是一个革命性的设计令牌工具,它让CSS开发变得更加智能和高效。如果你已经掌握了Token CS…...