chartgpt 告诉我的,loss 函数的各种知识

一、libtorch中常见的损失函数及其使用场景的总结
1. CrossEntropyLoss:
CrossEntropyLoss(交叉熵损失)主要用于分类任务。它适用于多分类问题,其中每个样本只属于一个类别(互斥)。该损失函数将预测概率与真实标签的one-hot向量进行比较,并计算交叉熵的值。通常用于神经网络的最后一层输出的softmax操作之后。
2. BCELoss:
BCELoss(二元交叉熵损失)是一种适用于二分类任务(正类和负类)的损失函数,它将预测概率与真实标签进行比较,并逐个元素地计算二元交叉熵。适用于不平衡的二分类问题。
3. NLLLoss:
NLLLoss(负对数似然损失)用于多分类任务,适用于不进行softmax操作的情况。NLLLoss将log_softmax的输出与真实标签的索引进行比较,并计算对数似然值的负数。
4. MSELoss:
MSELoss(均方误差损失)是一种用于回归问题的损失函数,它比较模型预测值和真实标签之间的均方误差。适用于需要预测连续值的任务。
5. L1Loss:
L1Loss(绝对值损失)也是用于回归问题的一种损失函数,它比较模型预测值和真实标签之间的绝对值误差。跟MSELoss相比,L1Loss更加关注异常值。
6. SmoothL1Loss:
SmoothL1Loss是一种用于回归问题的平滑L1损失,它比MSELoss和L1Loss更加平滑,既可以减少异常值的影响,又可以在尽可能保留良好拟合的情况下降低对大残差的敏感度。
7. CosineEmbeddingLoss:
CosineEmbeddingLoss是一种衡量两个样本相似度的损失函数,它主要是通过两个向量之间的余弦相似度来计算样本之间的相似度。适用于相关任务,比如计算文本或图像之间的相似度。
8. TripletMarginLoss:
TripletMarginLoss是用于学习嵌入向量的一种损失函数。它使用三元组(锚点、正例和负例)的方式来训练模型,同时最小化锚点和正例之间的距离,最大化锚点和负例之间的距离。适用于新颖类别识别、人脸识别等任务。
除了以上这些可以单独使用的损失函数外,还有一些损失函数可以进行组合,以解决特定的问题。例如,结合使用CrossEntropyLoss和Dice Loss,以便在图像分割问题中更准确地估计模型的性能等。
分割任务中的各种损失函数和对应的libtorch 实现
DiceLoss
Dice Loss是一种广泛用于医学图像分割等领域的损失函数,适用于二分类或多分类问题。Dice Loss的主要优点是在处理类别不平衡数据时效果好,尤其是当正负样本比例非常不均衡时。由于Dice Loss更加关注像素级别的相似度,因此它通常能够产生更加准确的预测结果,特别是在分割任务中。
总的来说,Dice Loss主要适用于像素级别的分类问题,尤其是针对不均衡数据的情况。它可以在目标实例与背景之间实现更精细的分割,从而提高模型的性能。
好的,以下是一个实现DiceLoss的基本代码:
torch::Tensor dice_loss(torch::Tensor input, torch::Tensor target)
{torch::Tensor smooth = 1e-5;torch::Tensor intersection = (input * target).sum();torch::Tensor union_ = (input + target).sum();torch::Tensor dice = (2 * intersection + smooth) / (union_ + smooth);return 1 - dice;
}这个函数采用输入张量`input`和目标张量`target`,并返回一个`torch::Tensor`代表DiceLoss。
我们首先给损失函数中添加了一个平滑系数`smooth`,以防止当分子或分母变为零时的除法错误。然后计算交集和并集,并计算Dice系数。最后用1减去Dice系数,即可得到DiceLoss。
FocalLoss
Focal Loss是一种针对于解决不平衡数据问题的损失函数,其将贡献较大的难以分类的样本进行了放大,以便更加注重分类效果较差的样本。常常用于目标检测和图像分割等任务中。
相比于传统的交叉熵损失,在存在类别不均衡的情况下,它可以更加注重真实的正样本来进行训练。在Focal Loss中,每个正样本都被乘以一个“难度因子”,难度因子越大,对分类影响越大,容易分错的样本会得到比较大的权重,从而可以更加关注分类效果差的样本,而忽略分类效果好的样本。
下面是一个简单的用于二分类的Focal Loss函数实现:
```c++
torch::Tensor focal_loss(torch::Tensor output, torch::Tensor target)
{torch::Tensor alpha = 0.25;torch::Tensor gamma = 2;torch::Tensor pt = torch::sigmoid(output);torch::Tensor p = (target * pt) + ((1 - target) * (1 - pt));torch::Tensor w = alpha * target + (1 - alpha) * (1 - target);w = w * torch::pow((1 - p), gamma);torch::Tensor loss = -w * torch::log(pt + 1e-8);return loss.mean();
}
```此函数采用输入张量`output`和目标张量`target`,并返回用于Focal Loss的损失。 `alpha`参数用于调节正负样本的不均衡情况,`gamma`参数用于调节“难易度因子”的大小。在本例中,使用sigmoid函数将输出变为了概率,然后按照公式计算权重`w`和损失`loss`,最后返回平均损失。
3.Jaccard Loss
Jaccard Loss,也称为 Intersection Over Union (IoU) Loss 或 Jaccard Index Loss,是一种常用的用于图像分割和目标检测的损失函数。
Jaccard Loss 基于 jaccard 系数,也称为 IoU(交并比),其度量了预测掩码与真实掩码之间的相似性。Jaccard Loss 的计算方式是用1减去两个掩码的交集除以它们的并集。
在图像分割中,如果掩码的像素值为0或1,那么IoU可以表示为:
`IoU = (predict & target).sum() / (predict | target).sum()`
掩码的像素值是0或1时,Jaccard Loss的计算方式可以表示为:
```c++
torch::Tensor jaccard_loss(torch::Tensor input, torch::Tensor target)
{torch::Tensor smooth = 1e-5;torch::Tensor intersection = (input * target).sum();torch::Tensor union_ = (input + target).sum() - intersection;torch::Tensor jaccard = (intersection + smooth) / (union_ + smooth);return 1 - jaccard;
}
```以上是一个Jaccard Loss的实现,参数`input`是模型预测的掩码,`target`是图像真实的掩码。计算交集和并集,并根据公式计算Jaccard系数。最后用1减去Jaccard系数,即可得到Jaccard Loss。
4.Lovasz Loss
Lovasz Loss是用于分类问题的一种损失函数,它与交叉熵损失一样用于计算模型的预测结果和真实结果之间的差异。与交叉熵不同的是, Lovasz Loss不需要将预测结果通过Softmax函数转换为概率分布,因此适用于多标签分类问题,并且在训练集不平衡的情况下通常比交叉熵表现更好。 Lovasz Loss的计算方式基于Lovasz扩展来衡量模型的考虑到每一个样本的结果贡献,而非单纯地考虑整个数据集的总体差异。
以下是使用libtorch实现Lovasz Loss的示例代码:
```C++
#include <torch/torch.h>torch::Tensor lovasz_hinge(const torch::Tensor& logits, const torch::Tensor& labels) {// 首先对预测结果进行排序,便于后面的计算torch::Tensor logits_sorted, dec_indices;std::tie(logits_sorted, dec_indices) = torch::sort(logits, 1, true);torch::Tensor labels_sorted = labels.index_select(0, dec_indices);// 计算每个样本的贡献值torch::Tensor labels_f = labels_sorted;torch::Tensor signs = 2 * labels_f - 1;torch::Tensor errors = 1 - logits_sorted * signs;torch::Tensor errors_sorted, permute_indices;std::tie(errors_sorted, permute_indices) = torch::sort(errors, 1, true);torch::Tensor permute_back = torch::argsort(permute_indices, 1);torch::Tensor values = errors_sorted.clone();torch::Tensor permutation = permute_back.clone();values = values * permute_indices.sign();permutation = permutation.index_select(1, permute_indices.abs() - 1);// 计算Lovasz Lossint num_examples = logits.size(0);torch::Tensor errors_flatten = values.flatten();torch::Tensor labels_flatten = labels_f.index_select(0, permutation.flatten()).unsqueeze(1);torch::Tensor signs_flatten = torch::ones_like(labels_flatten);signs_flatten[labels_flatten <= 0] = -1;torch::Tensor supergradient = torch::cumsum(signs_flatten, 0);torch::Tensor nonzeros = torch::where(errors_flatten > 0.0, torch::ones_like(errors_flatten), torch::zeros_like(errors_flatten));torch::Tensor gradient = 2 * supergradient - nonzeros;torch::Tensor loss = torch::dot(torch::relu(errors_flatten), gradient) / num_examples;return loss;
}
```此代码实现了一个求解多标签分类问题中Lovasz Loss的函数`lovasz_hinge()`,该函数接受两个张量作为输入,分别是预测结果logits和真实标签labels。它首先对logits进行排序,并根据预测结果计算每个样本对于总体损失的贡献,最后根据Lovasz扩展计算总体损失值。
5.MCCLoss
MCC(Matthews Correlation Coefficient) Loss是一种用于分类问题的损失函数,它是基于MCC指标来计算模型的预测结果和真实结果之间的差异,能够更准确地反映分类算法的效果。MCC Loss的优点包括:不受类别分布不均衡的影响、可用于多标签分类和二分类问题,以及具有良好的分数回归表现。MCC指标的取值范围在-1到1之间,1表示完美预测,0表示随机预测,-1表示完全反向预测。对于MCC Loss的计算,通常是通过将预测结果和真实结果分别二值化,将问题转化为一个多分类问题,最终计算出所有类别的MCC值的加权平均数作为损失函数的值。
好的,下面是用libtorch实现MCC LOSS的代码:
```c++
#include <iostream>
#include <torch/torch.h>
#include <cmath>// define multi-class Mcnemar loss
class McCrossEntropyLoss : public torch::nn::Module {public:McCrossEntropyLoss() = default;torch::Tensor forward(torch::Tensor input, torch::Tensor target) {int k = input.size(1);int n = input.size(0);torch::Tensor output = torch::zeros(k, k);for (int i = 0; i < k; i++) {for (int j = i + 1; j < k; j++) {torch::Tensor mask_i = (target == i);torch::Tensor mask_j = (target == j);torch::Tensor mask_ij = (mask_i + mask_j) > 0;torch::Tensor logits_ij = input.index_select(0, mask_ij.nonzero().view(-1));torch::Tensor labels_ij = target.index_select(0, mask_ij.nonzero().view(-1));torch::Tensor num = (((labels_ij == i).int()) * ((logits_ij[:, j] > logits_ij[:, i]).int())) +(((labels_ij == j).int()) * ((logits_ij[:, j] < logits_ij[:, i]).int()));torch::Tensor den = (((labels_ij == i).int()) * ((logits_ij[:, j] < logits_ij[:, i]).int())) +(((labels_ij == j).int()) * ((logits_ij[:, j] > logits_ij[:, i]).int()));torch::Tensor freq_ij = (num - den) / mask_ij.sum().float();output[i][j] = freq_ij.item<float>();output[j][i] = -freq_ij.item<float>();}}torch::Tensor loss = torch::trace(output.mm(output));return loss;}
};int main() {int classes = 3;int instances = 10;int dims = 5;torch::Tensor inputs = torch::rand({instances, dims});torch::Tensor targets = torch::randint(classes, {instances});McCrossEntropyLoss mcc_loss = McCrossEntropyLoss();torch::Tensor loss = mcc_loss(inputs, targets);std::cout << "MCC loss: " << loss.item<float>() << std::endl;return 0;
}
```其中,McCloss继承于torch::nn::module,重载了forward函数,实现MCC LOSS的计算。在main函数中,我们使用随机生成的输入和目标张量测试了MCC LOSS计算是否正确。
6.SOFT BCE LOSS
Soft Binary Cross-Entropy(Soft BCE)Loss,是一种用于多标签分类任务的损失函数。
在多标签分类任务中,每个样本对应多个标签,因此不能像单标签分类任务中那样使用交叉熵损失函数。Soft BCE Loss将样本和标签视为一个二维矩阵,其中每一行代表一个样本的所有标签,每一列代表所有样本中同一个标签。然后,对每个标签的预测值应用sigmoid函数(将预测值压缩到[0,1]之间),并与真实标签的值比较,最终计算所有标签的平均损失值。
Soft BCE Loss的公式如下:
$$ L_{i,j}=-w_j[y_{i,j}\log(p_{i,j})+(1-y_{i,j})\log(1-p_{i,j})] $$
其中,$w_j$代表第 $j$ 个标签的权重,$y_{i,j}$ 代表第 $i$ 个样本的第 $j$ 个标签的真实值,$p_{i,j}$ 代表第 $i$ 个样本的第 $j$ 个标签的预测值(通过sigmoid函数压缩)。
Soft BCE Loss的优点是能够处理多标签分类任务,且预测结果具有可解释性,即每个标签的预测值都在[0,1]之间,代表样本属于该标签的概率。
好的,下面是使用libtorch实现soft bce loss的示例代码:
```c++
#include <torch/torch.h>class SoftBCELoss : public torch::nn::Module {
public:SoftBCELoss() {}~SoftBCELoss() {}torch::Tensor forward(torch::Tensor input, torch::Tensor target) {torch::Tensor log_probs = torch::log_softmax(input, /*dim=*/1);torch::Tensor loss = -target * log_probs;loss = loss.mean(/*dim=*/0);return loss;}
};```这里我们创建了一个继承自`torch::nn::Module`的类`SoftBCELoss`,它的`forward`函数实现了soft bce loss的计算逻辑。其中,`input`是模型预测的输出,`target`是实际标签。我们首先对`input`使用`log_softmax`函数进行处理,然后计算`target`和`log_probs`的负值相乘,并求每个样本的均值,最终返回损失值。
希望这个示例代码对你有所帮助。
7.SOFT CE LOSS
Soft cross-entropy (CE) loss是一种常用的多分类损失函数。与普通的CE-loss不同,soft CE-loss可以将标签看作概率分布而非one-hot向量,使得模型的训练更加平滑。
在soft CE-loss中,标签即为每个类别的概率值$y_i$,它们总和必须等于1。而模型的输出也是一个由softmax函数输出的概率向量$p$,其中每个元素$p_i$表示预测为第$i$类的概率。两者的损失函数为cross-entropy loss的扩展形式:
$$
\text{CE}(p, y) = -\sum_{i=1}^C y_i\log(p_i),
$$
其中$C$为类别数。当$y$是one-hot向量时,上式就是普通的CE-loss;而当$y$是一个概率分布时,$y_i$表示样本属于第$i$类的概率,则上式等价于对每个类别的交叉熵做加权平均。
需要注意的是,如果样本的实际标签$y$是one-hot向量,那么使用soft CE-loss相比于普通的CE-loss并不会有太大的区别,因为两者的表现基本一致。但是,当$y$是一个概率分布时,soft CE-loss能够更好地指导模型学习到合适的概率分布输出,从而达到更好的效果。
好的,下面是使用libtorch实现soft cross-entropy loss的示例代码:
```c++
#include <torch/torch.h>class SoftCELoss : public torch::nn::Module {
public:SoftCELoss() {}~SoftCELoss() {}torch::Tensor forward(torch::Tensor input, torch::Tensor target) {torch::Tensor log_probs = torch::log_softmax(input, /*dim=*/1);torch::Tensor loss = -torch::sum(target * log_probs, /*dim=*/1);loss = loss.mean(/*dim=*/0);return loss;}
};```这里我们创建了一个继承自`torch::nn::Module`的类`SoftCELoss`,它的`forward`函数实现了soft cross-entropy loss的计算逻辑。其中,`input`是模型预测的输出,`target`是实际标签的概率分布。我们首先对`input`使用`log_softmax`函数进行处理,然后计算每个样本的cross-entropy loss并求平均值,最终返回损失值。
希望这个示例代码对你有所帮助。
8.Tversky LOSS
Tversky损失(Tversky loss)是一种用于计算图像分割任务中的损失函数。它是由以色列的心理学家Amos Tversky在1977年提出的,用于度量分类任务中两个概念之间的相似性。
在图像分割领域中,Tversky损失通常被用来度量预测标签(如前景和背景)与真实标签之间的相似性。它主要是通过计算两个集合的相似度来实现的,而不是通过计算它们的交集或并集。
Tversky损失函数具有比较好的平衡性,它可以平衡不同类别之间的权重差异,并且可以避免类别之间的平衡问题。因此,在图像分割任务中,Tversky损失被广泛应用,并取得了良好的性能。
好的,以下是使用C++和libtorch实现Tversky loss的示例代码:
```c++
#include <torch/torch.h>torch::Tensor tversky_loss(torch::Tensor y_true, torch::Tensor y_pred, float alpha, float beta) {// calculate true positivesauto true_pos = torch::sum(y_true * y_pred);// calculate false positivesauto false_pos = torch::sum((1 - y_true) * y_pred);// calculate false negativesauto false_neg = torch::sum(y_true * (1 - y_pred));// calculate Tversky indexauto tversky_index = true_pos / (true_pos + alpha * false_neg + beta * false_pos);// calculate Tversky lossauto tversky_loss = 1 - tversky_index;// return Tversky loss as tensorreturn tversky_loss;
}
```其中,`y_true`是真实标签,`y_pred`是预测标签。`alpha`和`beta`是两个权重参数,用于平衡假负和假正的影响。函数返回一个`Tensor`对象,表示Tversky loss。
需要注意的是,使用该函数需要事先安装并配置好libtorch库,并且在代码中添加对应的头文件和链接库。
相关文章:
chartgpt 告诉我的,loss 函数的各种知识
一、libtorch中常见的损失函数及其使用场景的总结1. CrossEntropyLoss:CrossEntropyLoss(交叉熵损失)主要用于分类任务。它适用于多分类问题,其中每个样本只属于一个类别(互斥)。该损失函数将预测概率与真实标签的one-…...
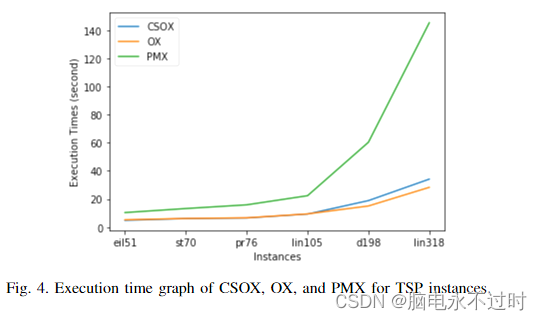
旅行推销员问题的遗传算法中的完整子路线顺序交叉
摘要 旅行商问题(TSP)是许多著名的组合问题之一。TSP可以解释为很难找到从第一个城市出发,经过所有城市,然后返回起点的最短距离。在标准问题中,TSP通常用于确定新算法的效率。遗传算法是求解TSP问题的一种成功算法。…...

Python实现词频统计
词频统计是自然语言处理的基本任务,针对一段句子、一篇文章或一组文章,统计文章中每个单词出现的次数,在此基础上发现文章的主题词、热词。 1. 单句的词频统计 思路:首先定义一个空字典my_dict,然后遍历文章…...
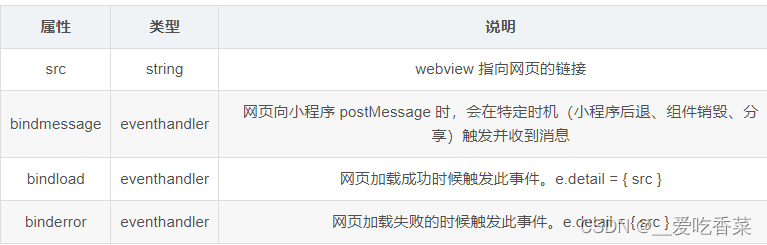
微信小程序面试题(day08)
文章目录微信小程序自定义组件的使用?微信小程序事件通道的使用?微信小程序如何使用vant组件库?微信小程序自定义组件父传子子传父?微信小程序自定义组件生命周期有哪些?微信小程序授权登录流程?web-view。…...
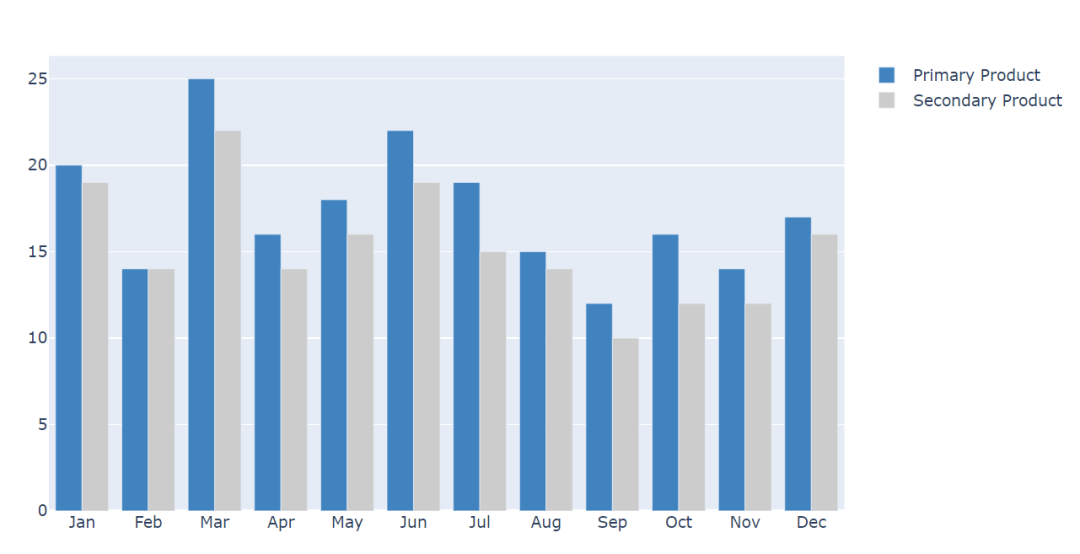
最强的Python可视化神器,你有用过么?
数据分析离不开数据可视化,我们最常用的就是Pandas,Matplotlib,Pyecharts当然还有Tableau,看到一篇文章介绍Plotly制图后我也跃跃欲试,查看了相关资料开始尝试用它制图。 1、Plotly Plotly是一款用来做数据分析和可视…...
Ubuntu使用vnc远程桌面【远程内网穿透】
文章目录1.前言2.两台互联电脑的设置2.1 Windows安装VNC2.2 Ubuntu安装VNC2.3.Ubuntu安装cpolar3.Cpolar设置3.1 Cpolar云端设置3.2.Cpolar本地设置4.公网访问测试5.结语1.前言 记得笔者刚刚开始接触电脑时,还是win95/98的时代,那时的电脑桌面刚迈入图形…...

【C++】map、set、multimap、multiset的介绍和使用
我讨厌世俗,也耐得住孤独。 文章目录一、键值对二、树形结构的关联式容器1.set1.1 set的介绍1.2 set的使用1.3 multiset的使用2.map2.1 map的介绍2.2 map的使用2.3 multimap的使用三、两道OJ题1.前K个高频单词(less<T>小于号是小的在左面升序&…...
)
css学习14(多媒体查询)
目录 多媒体查询 语法 示例代码 通用媒体查询 媒体功能参考列表 多媒体查询 CSS的媒体查询是一种CSS的技术,它可以根据不同的设备类型、屏幕尺寸、方向、分辨率等条件来应用不同的CSS样式,从而为不同的设备和屏幕提供最佳的浏览体验。这样ÿ…...
【C++进阶】C++11(中)左值引用和右值引用
文章目录左值引用左值引用的概念左值引用的使用右值引用右值引用的概念右值引用的使用左右值相互引用左值引用对右值进行引用右值引用对左值进行引用右值引用使用场景和意义左值引用的优势左值引用的短板右值引用的优势完美转发模板万能引用完美转发实际运用场景左值引用 左值…...

Python中的生成器【generator】总结,看看你掌握了没?
人生苦短,我用python python 安装包资料:点击此处跳转文末名片获取 1.实现generator的两种方式 python中的generator保存的是算法, 真正需要计算出值的时候才会去往下计算出值。 它是一种惰性计算(lazy evaluation)。 要创建一个…...
MD5加密竟然不安全,应届生表示无法理解?
前言 近日公司的一个应届生问我,他做的一个毕业设计密码是MD5加密存储的,为什么密码我帮他调试的时候,我能猜出来明文是什么? 第六感,是后端研发的第六感! 正文 示例,有个系统,前…...
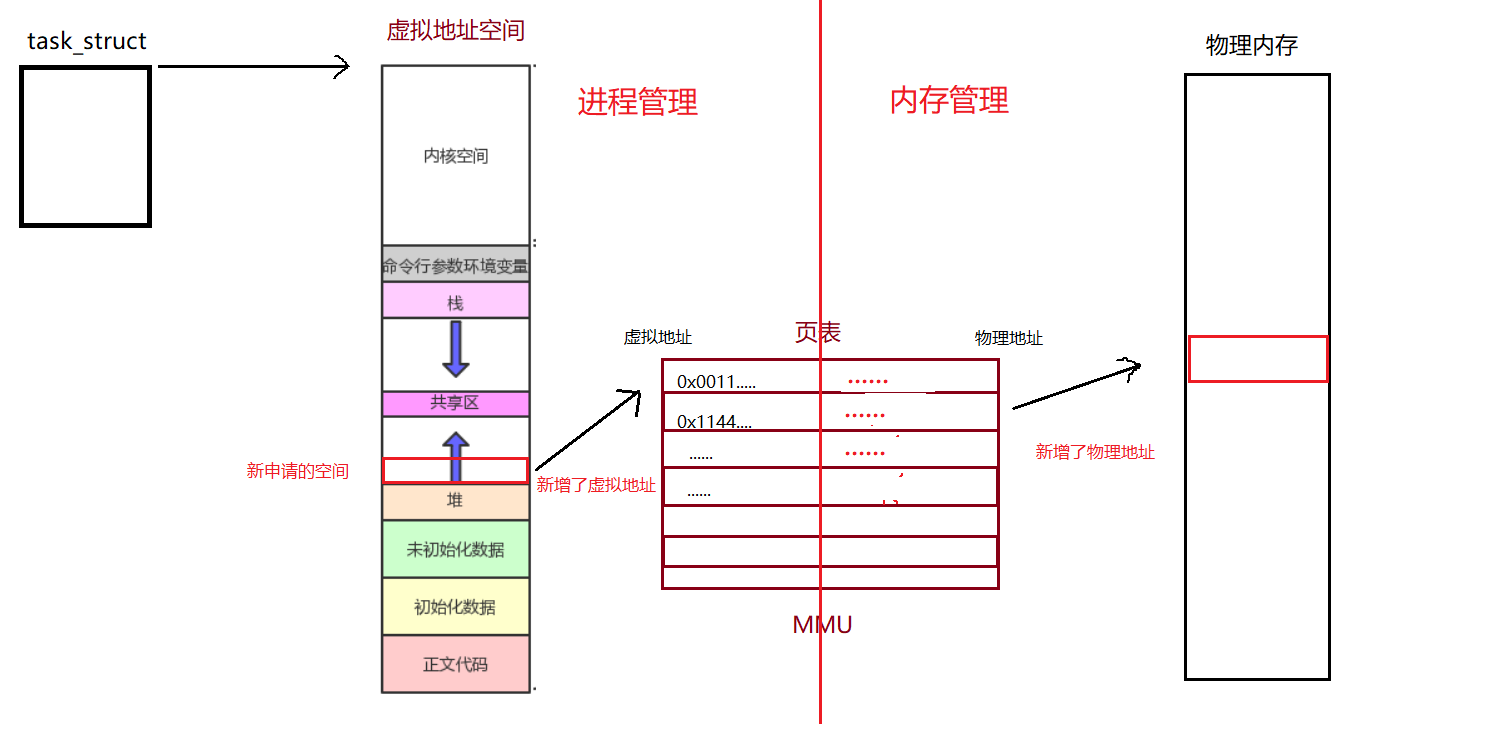
【Linux】虚拟地址空间
进程地址空间一、引入二、虚拟地址与物理内存的联系三、为什么要有虚拟地址空间一、引入 对于C/C程序,我们眼中的内存是这样的: 我们利用这种对于与内存的理解看一下下面这段代码: 运行结果: 观察父子进程中 val 变量的值&…...
四平方和题解(二分习题)
四平方和 暴力做法 Y总暴力做法,蓝桥云里能通过所有数据 总结:暴力也分好坏,下面这份代码就是写的好的暴力 如何写好暴力:1. 按组合枚举 2. 写好循环结束条件,没必要循环那么多次 #include<iostream> #include<cmath>…...

一篇文章搞定js正则表达式
我们测试正则表达式是否正确的方法有很多,例如通过正则表达式找到拼配的字符串: 在vscode编辑器中点击搜索框中的第三个按钮就可以实现: 或者 在浏览器中的控制台也可以实现: 我们可以通过下面的在线网站来测试你写的正则是否正确…...
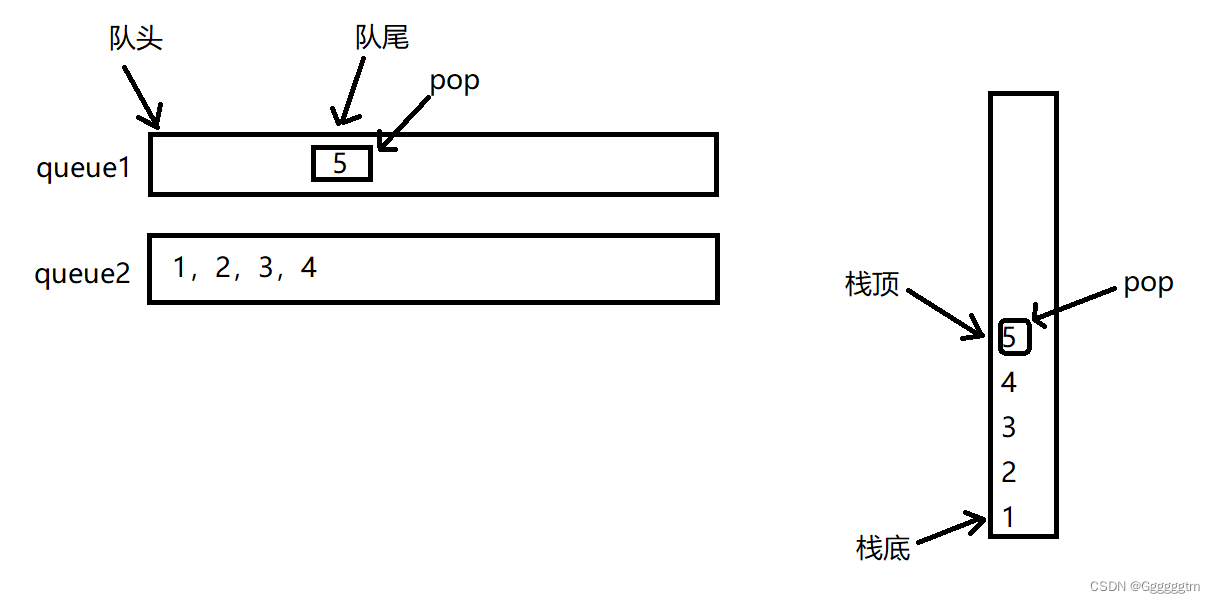
[数据结构] 用两个队列实现栈详解
文章目录 一、队列实现栈的特点分析 1、1 具体分析 1、2 整体概括 二、队列模拟实现栈代码的实现 2、1 手撕 队列 代码 queue.h queue.c 2、2 用队列模拟实现栈代码 三、总结 🙋♂️ 作者:Ggggggtm 🙋♂️ 👀 专栏࿱…...

官宣|Apache Flink 1.17 发布公告
Apache Flink PMC(项目管理委员)很高兴地宣布发布 Apache Flink 1.17.0。Apache Flink 是领先的流处理标准,流批统一的数据处理概念在越来越多的公司中得到认可。得益于我们出色的社区和优秀的贡献者,Apache Flink 在 Apache 社区…...
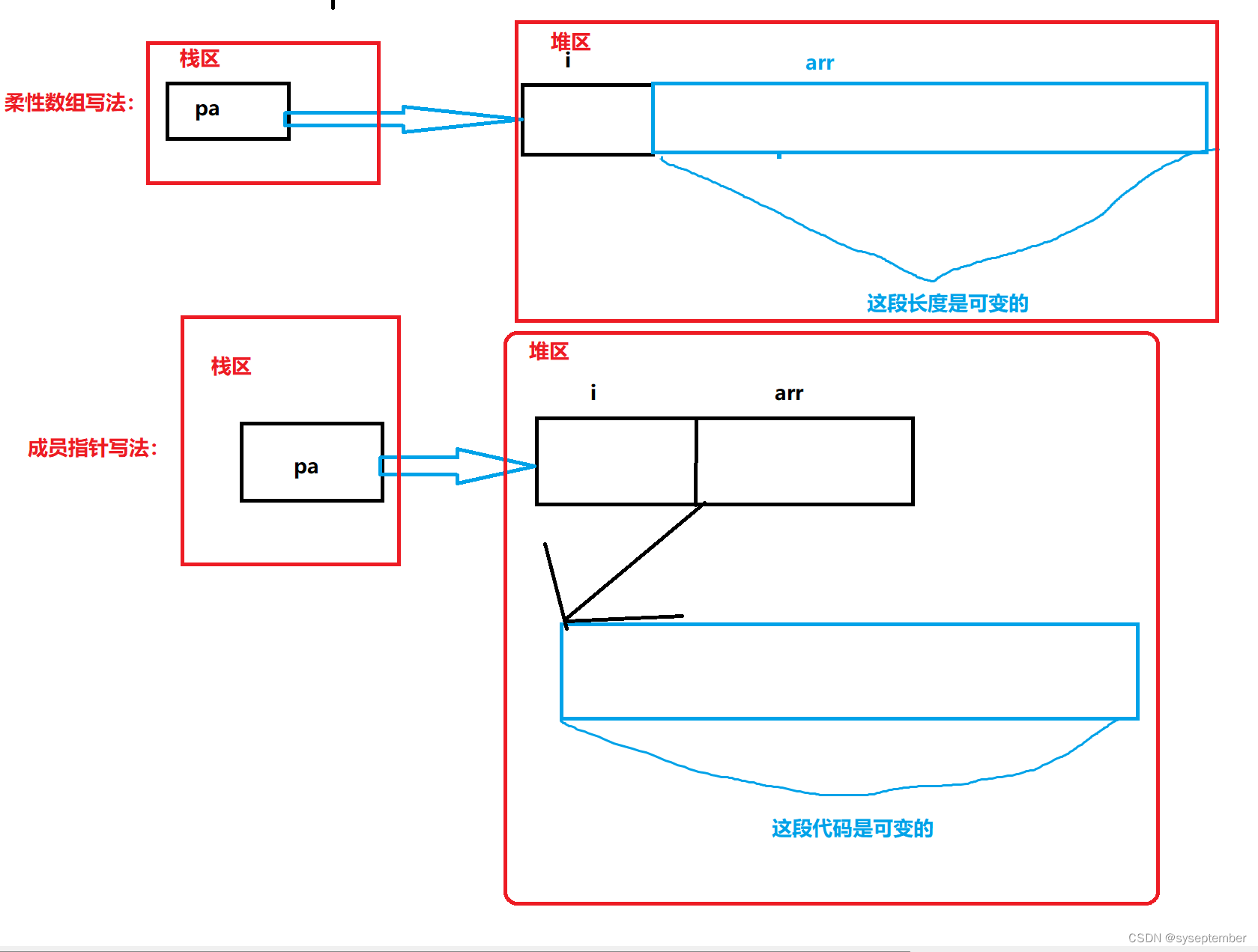
动态内存管理+动态通讯录【C进阶】
文章目录为什么存在动态内存分配❓👉动态内存函数👈malloc&freecallocrealloc❌常见的动态内存错误❌练习题🫠C/C程序的内存开辟🤔柔性数组柔性数组的特点柔性数组的优势:star:动态通讯录:star:初始化添加销毁为什么存在动态内…...
基于pytorch+Resnet101加GPT搭建AI玩王者荣耀
本源码模型主要用了SamLynnEvans Transformer 的源码的解码部分。以及pytorch自带的预训练模型"resnet101-5d3b4d8f.pth"本资源整理自网络,源地址:https://github.com/FengQuanLi/ResnetGPT注意运行本代码需要注意以下几点 注意!&a…...
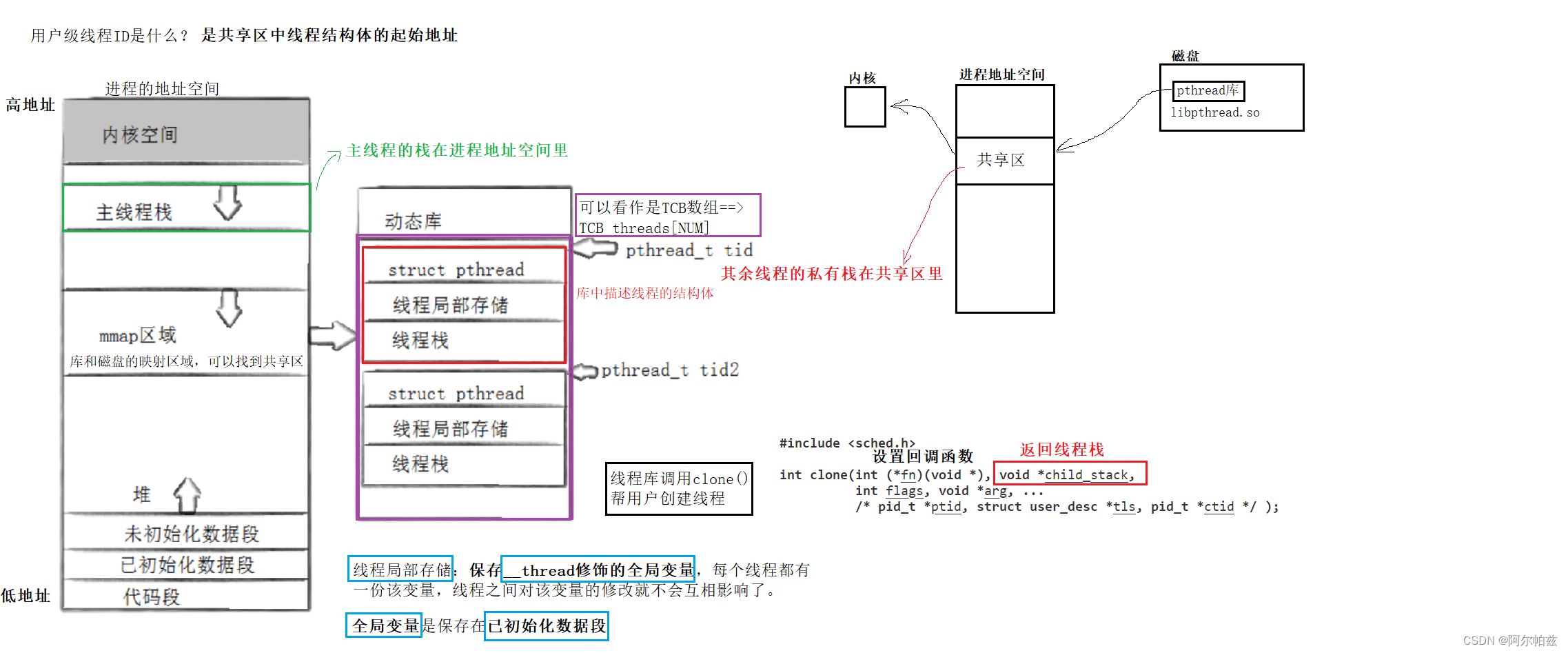
多线程控制讲解与代码实现
多线程控制 回顾一下线程的概念 线程是CPU调度的基本单位,进程是承担分配系统资源的基本单位。linux在设计上并没有给线程专门设计数据结构,而是直接复用PCB的数据结构。每个新线程(task_struct{}中有个指针都指向虚拟内存mm_struct结构&am…...
清晰概括:进程与线程间的区别的联系
相关阅读: 🔗通俗简介:操作系统之进程的管理与调度🔗如何使用 jconsole 查看Java进程中线程的详细信息? 目录 一、进程与线程 1、进程 2、线程 二、进程与线程之间的区别和联系 1、区别 2、联系 一、进程与线程 …...

AI专著生成神器来袭!用AI写专著,20万字专著轻松到手!
创新是学术专著的核心,也是写作中最具挑战性的部分。一部合格的专著不能仅仅是已有成果的简单堆叠,而是需要展现贯穿整本书的独到见解、理论框架或者研究方法。面对浩如烟海的学术文献,寻找那些尚未被挖掘的研究空白实属不易——有时选题已经…...

3分钟学会使用elan:告别Lean版本混乱的智能版本管理器
3分钟学会使用elan:告别Lean版本混乱的智能版本管理器 【免费下载链接】elan The Lean version manager 项目地址: https://gitcode.com/gh_mirrors/el/elan 还在为不同Lean项目需要不同版本而头疼吗?elan作为Lean定理证明器的智能版本管理器&…...

TPU加速GAN训练:从Colab实操到混合精度调优
1. 项目概述:为什么在Kaggle/Colab上用TPU训GAN不是“炫技”,而是刚需你有没有试过在笔记本电脑上跑一个DCGAN,等了47分钟,loss曲线刚抖两下,风扇就发出濒死的哀鸣?或者在普通GPU上训StyleGAN2,…...

使用TaotokenCLI工具一键配置开发环境与模型密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境与模型密钥 在接入大模型进行开发时,手动配置API密钥、Base URL和模型ID是常见的…...

RK3588嵌入式主板如何以ARM架构重塑智能医疗设备设计
1. 项目概述:当医疗设备遇上“能效比”难题在医疗设备这个对稳定性和可靠性要求近乎苛刻的领域,硬件平台的每一次选择都像是一场精密的外科手术,需要权衡性能、功耗、尺寸、成本与长期供应。过去很长一段时间,当设备需要更强的算力…...

yt-fts高级配置技巧:数据库路径、Chroma设置与性能优化
yt-fts高级配置技巧:数据库路径、Chroma设置与性能优化 【免费下载链接】yt-fts YouTube Full Text Search - Search all of YouTube from the command line 项目地址: https://gitcode.com/gh_mirrors/yt/yt-fts yt-fts是一款强大的YouTube全文搜索工具&…...

围棋AI训练新境界:5步掌握KaTrain智能陪练核心技巧
围棋AI训练新境界:5步掌握KaTrain智能陪练核心技巧 【免费下载链接】katrain Improve your Baduk skills by training with KataGo! 项目地址: https://gitcode.com/gh_mirrors/ka/katrain 想要在围棋对弈中快速提升水平?KaTrain作为一款基于Kata…...

聊聊6G试验频率
2026年5月8日,工业和信息化部向IMT-2030(6G)推进组批复6G试验频率使用许可,支持其在部分地区开展6G技术试验。这一看似平常的行政批复,却有里程碑式的意义。它标志着中国6G产业进入到新的阶段,正加速从实验…...

终极文档下载指南:如何用kill-doc一键拯救30+平台的文档资源
终极文档下载指南:如何用kill-doc一键拯救30平台的文档资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是…...

1987年7月14日晚上19-21点出生性格、运势和命运
1987年6月28日,距离二十四节气中的“小暑”(通常在7月6-8日)约8-10天。小暑意为“天气开始炎热但未到极致”,是盛夏的序曲。这个时节的哲学,与个人成长有着奇妙的呼应。性格的“小暑特质”:温润与韧性 小暑…...