ConvMixer:Patches Are All You Need
Patches Are All You Need
发表时间:[Submitted on 24 Jan 2022];
发表期刊/会议:Computer Vision and Pattern Recognition;
论文地址:https://arxiv.org/abs/2201.09792;
代码地址:https://github.com/locuslab/convmixer;
0 摘要
尽管CNN多年以来一直是计算机视觉任务的主要架构,但最近的一些工作表明,基于Transformer的模型,尤其是ViT,在某些情况下会超越CNN的性能(尤其是后来的swin transformer,完全超越CNN, 里程碑);
然而,因为Transformer的self-attention运行时间为二次的/平方的(O(n2)O(n^2)O(n2)),ViT使用patch embedding,将图像的小区域组合成单个输入特征,以便应用于更大的图像尺寸。
这就引出一个问题: ViT的性能是由于Transformer本身就足够强大,还是因为输入是patch?
本文为后者提供了一些证据;
本文提出一种非常简单的模型:ConvMixer,思想类似于MLP-Mixer;
-
MLP-Mixer直接在作为输入的patch上操作,分离空间和通道维度的混合信息,并在整个网络中保持相同的大小和分辨率。
-
ConvMixer只使用标准卷积来实现混合步骤。
尽管它很简单,但本文表明ConvMixer在类似的参数计数和数据集大小方面优于ViT、MLP-Mixer和它们的一些变体,此外还优于经典视觉模型(如ResNet)。
1 简介
本文探索一个问题:ViT的性能强大是因为Transformer结构本身,还是更多的来源于这种patch的表征形式?
本文提出一个非常简单的卷积架构,我们称之为“ConvMixer”,因为它与最近提出的MLP-Mixer相似(Tolstikhin et al, 2021)。
ConvMixer的许多方面都和ViT或MLP-Mixer类似:
- 直接对patch进行操作;
- 在所有层中保持相同的分辨率和大小表示(feature map不降维、没有下采样);
- 不会对连续层的表示进行下采样;
- 将信息的“通道混合”与“空间混合”分开(depthwise 和 pointwise conv);
不同之处:
- ConvMixer只通过标准卷积来完成所有这些操作;
结论:patch的表征形式很重要;
2 ConvMixer模型
2.0 模型概述
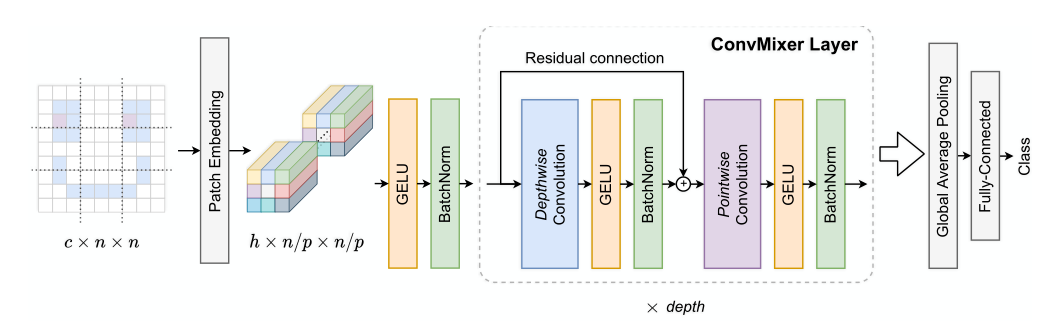
如图2所示:
- 输入图像大小为c×n×nc×n×nc×n×n,c-通道,n-宽度/高度;
- patch大小为ppp,进行patch embedding后,个数为n/p×n/pn/p × n/pn/p×n/p,一个嵌入成h维的向量,得到向量块(也可以叫feature map) h×(n/p)×(n/p)h×(n/p)×(n/p)h×(n/p)×(n/p);
- 这个patch embedding不同于Transformer的patch embedding;
- 这一步相当于用一个输入通道为ccc,输出通道为hhh,卷积核大小=patch_size, stride = patch_size的卷积核去卷出的feature map;
- 将这个feature map进行GeLU激活和BN,输入进ConvMixer Layer中;
- ConvMixer层由深度卷积depthwise conv和逐点卷积pointwise conv和残差连接组成,每一个卷积之后都会有GeLU激活和BN;
- depthwise conv: 将hhh个通道各自进行卷积=>空间混合;
- pointwise conv:1×1的卷积,对通道之间混合;
- ConvMixer层会循环depth次;
- 最后接入分类头;

Pytorch实现:
class ConvMixerLayer(nn.Module):def __init__(self,dim,kernel_size = 9):super().__init__()#残差结构self.Resnet = nn.Sequential(nn.Conv2d(dim,dim,kernel_size=kernel_size,groups=dim,padding='same'),nn.GELU(),nn.BatchNorm2d(dim))#逐点卷积self.Conv_1x1 = nn.Sequential(nn.Conv2d(dim,dim,kernel_size=1),nn.GELU(),nn.BatchNorm2d(dim))def forward(self,x):x = x +self.Resnet(x)x = self.Conv_1x1(x)return xclass ConvMixer(nn.Module):def __init__(self,dim,depth,kernel_size=9, patch_size=7, n_classes=1000):super().__init__()self.conv2d1 = nn.Sequential(nn.Conv2d(3,dim,kernel_size=patch_size,stride=patch_size),nn.GELU(),nn.BatchNorm2d(dim))self.ConvMixer_blocks =nn.ModuleList([])for _ in range(depth):self.ConvMixer_blocks.append(ConvMixerLayer(dim=dim,kernel_size=kernel_size))self.head = nn.Sequential(nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(),nn.Linear(dim,n_classes))def forward(self,x):#编码时的卷积x = self.conv2d1(x)#多层ConvMixer_block 的计算for ConvMixer_block in self.ConvMixer_blocks:x = ConvMixer_block(x)#分类输出x = self.head(x)return xmodel = ConvMixer(dim=128,depth=2)
print(model)
ConvMixer((conv2d1): Sequential((0): Conv2d(3, 128, kernel_size=(7, 7), stride=(7, 7))(1): GELU()(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(ConvMixer_blocks): ModuleList((0): ConvMixerLayer((Resnet): Sequential((0): Conv2d(128, 128, kernel_size=(9, 9), stride=(1, 1), padding=same, groups=128)(1): GELU()(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(Conv_1x1): Sequential((0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))(1): GELU()(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): ConvMixerLayer((Resnet): Sequential((0): Conv2d(128, 128, kernel_size=(9, 9), stride=(1, 1), padding=same, groups=128)(1): GELU()(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(Conv_1x1): Sequential((0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))(1): GELU()(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))))(head): Sequential((0): AdaptiveAvgPool2d(output_size=(1, 1))(1): Flatten(start_dim=1, end_dim=-1)(2): Linear(in_features=128, out_features=1000, bias=True))
)
2.1 参数设计
ConvMixer的实例化依赖于四个参数:
- the “width” or hidden dimension: hhh (patch embedding的维度);
- ConvMixer层的循环次数:depthdepthdepth;
- 控制模型内部分辨率的patch size: ppp;
- 深度卷积层的核大小:kkk;
其他ConvMixer模型的命名规则:ConvMixer-h/d;
2.2 动机
本文的架构是基于混合的想法;特别地,我们选择了深度卷积dw来混合空间位置和点卷积来pw混合通道位置。
以前工作的一个关键观点是,MLP和自我注意可以混合远的空间位置,也就是说,它们可以有任意大的接受域。因此,我们使用大核卷积来混合遥远的空间位置。
虽然自我注意和MLP理论上更灵活,允许大的接受域和内容感知行为,但卷积的归纳偏差非常适合视觉任务。通过使用这样的标准操作,我们也可以看到与传统的金字塔形、逐步下采样的卷积网络设计相比,patch表示本身的效果。
3 实验
3.1 训练设置
主要在ImageNet-1k分类上评估ConvMixers,没有任何预训练或其他数据;
将ConvMixer添加到timm框架,并使用接近标准的设置对其进行训练: 除了默认的timm增强外,我们还使用RandAugment、mixup、CutMix、随机擦除和梯度范数裁剪。使用AdamW优化器;
由于计算量有限,我们绝对没有在ImageNet上进行超参数调优,并且训练的epoch比竞争对手少。
因此,我们的模型可能过度正则化或不正则化,我们报告的准确性可能低估了我们模型的能力。
3.2 实验结果
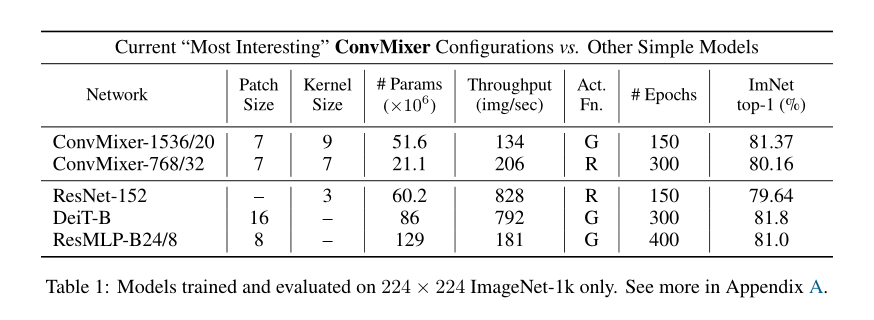
- 精度:在ImageNet上,参数为52M的ConvMixer-1536/20可以达到81.4%的top-1精度,参数为21M的ConvMixer-768/32可以达到80.2%的top-1精度;
- 宽度:更宽的ConvMixer似乎收敛更快,但需要大量内存和计算;
- 内核大小:当将内核大小从k = 9减小到k = 3时,ConvMixer-1536/20的精度下降了≈1%;
- patch大小:较小patch的ConvMixers基本上更好,更大的patch可能需要更深的ConvMixers;除了将patch大小从7增加到14,其他都保持不变,ConvMixer-1536/20达到了78.9%的top-1精度,但速度快了大约4倍;
- 激活函数:用ReLU训练了一个模型,证明在最近的各向同性模型中流行的GELU是不必要的。
3.3 比较
将ConvMixer模型与ResNet/DeiT/ResMLP比较,结果如表1、图1所示;
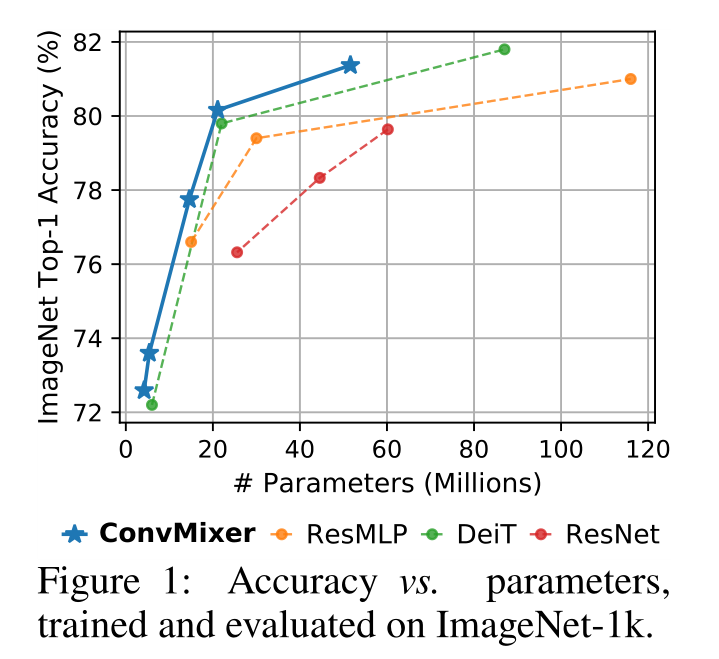
- 同等参数量,ConvMixer-1536/20的性能优于ResNet-152和ResMLP-B24;
- ConvMixers在推理方面比竞争对手慢得多,可能是由于它们的patch尺寸更小; 超参数调优和优化可以缩小这一差距。有关更多讨论和比较,请参见表2和附录A。
4 相关工作
相关文章:
ConvMixer:Patches Are All You Need
Patches Are All You Need 发表时间:[Submitted on 24 Jan 2022]; 发表期刊/会议:Computer Vision and Pattern Recognition; 论文地址:https://arxiv.org/abs/2201.09792; 代码地址:https:…...

day10—编程题
文章目录1.第一题1.1题目1.2思路1.3解题2.第二题2.1题目2.2涉及的相关知识2.3思路2.4解题1.第一题 1.1题目 描述: 给定一个二维数组board,代表棋盘,其中元素为1的代表是当前玩家的棋子,0表示没有棋子,-1代表是对方玩…...
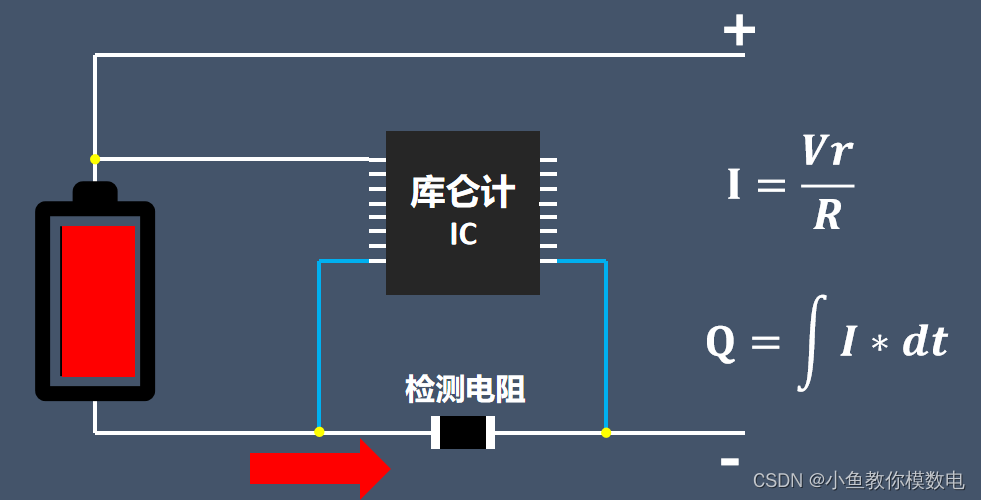
如何测量锂电池的电量
锂电池在放电时我们有时需要知道电池的实时电量,如电池电量低了我们就需要及时给锂电池充电,避免电池过度放电。我手里的这个就是个单节锂电池电量显示模块,只需要将这个模块接到锂电池的正负极即可显示电量。这个模块的电量分为四档…...

菜鸟刷题Day6
⭐作者:别动我的饭 ⭐专栏:菜鸟刷题 ⭐标语:悟已往之不谏,知来者之可追 一.链表内指定区间反转:链表内指定区间反转_牛客题霸_牛客网 (nowcoder.com) 描述 将一个节点数为 size 链表 m 位置到 n 位置之间的区间反转…...

DecimalFormat格式化显示数字
DecimalFormat 是 NumberFormat 的一个具体子类,用于格式化十进制数字,可以实现以最快的速度将数字格式化为你需要的样子。 DecimalFormat 类主要靠 # 和 0 两种占位符号来指定数字长度。0 表示如果位数不足则以 0 填充, # 表示只要有可能就…...

cpu中缓存简介
一级缓存是什么: 一级缓存都内置在CPU内部并与CPU同速运行,可以有效的提高CPU的运行效率。一级缓存越大,CPU的运行效率越高,但受到CPU内部结构的限制,一级缓存的容量都很小。 CPU缓存(Cache Memory…...
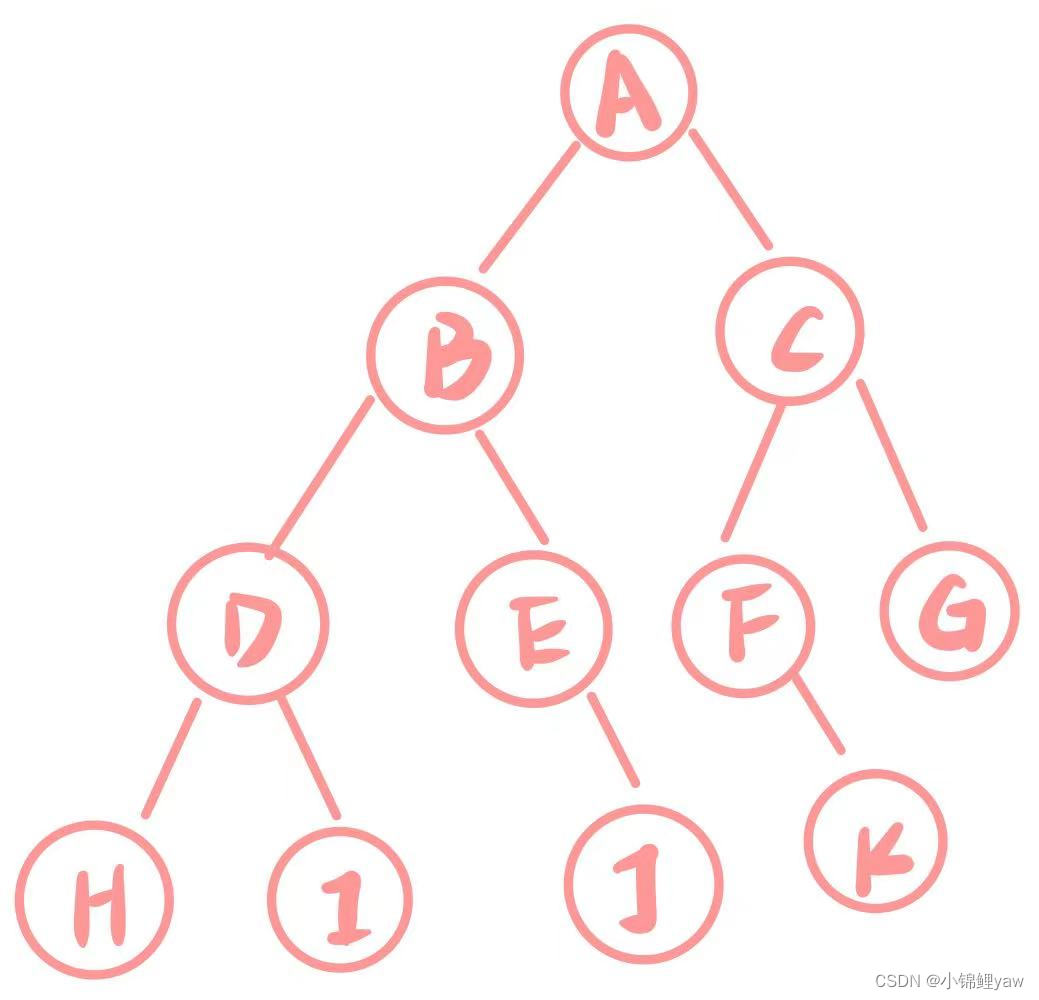
【数据结构】二叉树的遍历以及基本操作
目录 1.树形结构 1.概念 2.二叉树 2.1概念 2.2 两种特殊的二叉树 2.3二叉树的存储 2.4二叉树的基本操作 1.手动快速创建一棵简单的二叉树 2.二叉树的遍历 (递归) 3.二叉树的层序遍历 4.获取树中节点的个数 5.获取叶子节点的个数 6.获取第K层节点的个数 7.获取二叉…...
若依框架 --- ruoyi 表格的设置
表格 字典值转换 (1) 方式1:使用字典枚举的方式 var isDownload [[${dict.getType(YES_OR_NO)}]];{field : isDownload,title : 是否允许下载,formatter: function(value, row, index) {return $.table.selectDictLabel(isDownload, value);} }, (2) 方式2&…...

“两会”网络安全相关建议提案回顾
作为新一年的政治、经济、社会等发展的“风向标”,今年“两会”在3月13日顺利闭幕。在今年“两会”期间,多位人大代表也纷纷围绕网络安全、数据安全的未来发展做了提案和建议。 01 “两会”网络安全相关建议和提案回顾 建议统筹智能网联汽车数据收集与共…...

一篇文章带你真正了解接口测试(附视频教程+面试真题)
目录 一、什么是接口测试? 二、为什么要做接口测试? 三、如何开展接口测试? 四、接口测试常见面试题 一、什么是接口测试? 所谓接口,是指同一个系统中模块与模块间的数据传递接口、前后端交互、跨系统跨平台跨数据…...

C/C++每日一练(20230325)
目录 1. 搜索插入位置 🌟 2. 结合两个字符串 🌟 3. 同构字符串 🌟 🌟 每日一练刷题专栏 🌟 Golang每日一练 专栏 Python每日一练 专栏 C/C每日一练 专栏 Java每日一练 专栏 1. 搜索插入位置 给定一个排序数…...

Linux操作系统ARM指令集与汇编语言程序设计
一、实验目的1.了解并掌握ARM汇编指令集2.应用ARM指令集编写一个程序操控开发板上的LED灯二、实验要求应用ARM汇编指令集编写程序,实现正常状态下开发板上的LED灯不亮,按下一个按键之后开发板上的LED灯进入流水灯模式。三、实验原理四个LED灯的电路如下图…...
计网之HTTP协议和Fiddler的使用
文章目录一. HTTP概述和fidder的使用1. 什么是HTTP2. 抓包工具fidder的使用2.1 注意事项2.2 fidder的使用二. HTTP协议格式1. HTTP请求格式1.1 基本格式1.2 认识URL1.3 方法2. 请求报头关键字段3. HTTP响应格式3.1 基本格式3.2 状态码一. HTTP概述和fidder的使用 1. 什么是HTT…...

sql性能优化:MS-SQL(SQL Server)跟踪日志信息结果列字段说明,MSSQL的列字段说明(column)
sql性能优化:MS-SQL(SQL Server)跟踪日志信息结果列字段说明,MSSQL的列字段说明(column) 参考: SQL:BatchCompleted 事件类 | Microsoft Learn SQL 跟踪 | Microsoft Learn sp_trace_setevent (…...

DNS主从复制
#前提准备:关闭SElinux 关闭防火墙 时间同步 #环境说明:Centos7 #ip地址:dns-master:10.0.0.100 dns-slave:10.0.0.103 web:10.0.0.101 主DNS服务配置 1.安装软件包: yum install bind -…...

常见的js加密/js解密方法
常见的js加密/js解密方法 当今互联网世界中,数据安全是至关重要的。为了保护用户的隐私和保密信息,开发人员必须采取适当的安全措施。在前端开发中,加密和解密技术是一种常见的数据安全措施,其中 JavaScript 是最常用的语言之一。…...

6 python函数
函数 在实现某个功能对应的代码的时候,如果将实现功能对应的函数放到函数中,那么下一次再需要这个功能的时候,就可以不用再写这个功能对应的代码,直接调用这个功能对应的函数。 1.什么是函数 函数就是实现某一特点功能的代码的封装…...

7.避免不必要的渲染
目录 1 组件更新机制 2 虚拟DOM配合Diff算法 3 减轻state 4 shouldComponentUpdate() 4.1 基本使用 4.2 使用参数 5 纯组件 5.1 基本使用 5.2 纯组件的比较方法 shallow compere 1 组件更新机制 当父组件重新渲染时,父组件的所有子组件也会重新…...

国产化大趋势下学习linux的必要性
由于国际上的一些国家的制裁和威胁。最近几年国产化大趋势慢慢的兴起,我们国产化硬件的需求越来越大。对国产操作系统的需求也越来越多,那么我们一直用的Windows系统为什么不用了呢?众所周知的原因,不管是最新的Windows11还是正值…...

浅谈虚树
问题引入 你是否遇到过下面这种问题: SDOI2011 消耗战 在一场战争中,战场由 nnn 个岛屿和 n−1n-1n−1 个桥梁组成,保证每两个岛屿间有且仅有一条路径可达。现在,我军已经侦查到敌军的总部在编号为1的岛屿,而且他们已…...

打破网盘限速:9大平台直链解析工具全攻略
打破网盘限速:9大平台直链解析工具全攻略 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅雷云…...

Voice-Pro 免费开源杀疯了:语音翻译、AI克隆、人声分离、YouTube下载全打包,狂省上千元
你是否也曾想过做视频,英文视频翻译成中文发到国内,或者把自己做的中文视频配上地道的英文,扬帆出海? 然而,现实往往会给你迎头痛击: 工具太碎片 :用 yt-dlp 下载了视频,要用 Demu…...

DCGAN原理解析:用卷积结构根治GAN模式坍缩
1. 项目概述:从手写数字到逼真猫脸,DCGAN如何让生成模型真正“看见”图像结构你有没有试过训练一个最基础的GAN,结果生成器输出的全是模糊的、像打了马赛克的灰扑扑色块?或者更糟——所有生成的图片都长得一模一样,只是…...

1.2 struct page 与 PFN:VMA 背后的物理存储
本篇目标:理解 Linux 如何为每个物理页帧维护元数据(struct page),以及虚拟地址最终如何落实到物理内存。HMM 的关键创新之一,是让设备内存(GPU VRAM)也拥有 struct page,从而被内核…...

从云台控制理解双环PID:手把手调试大疆GM6020电机的角度与速度环
从云台控制理解双环PID:手把手调试大疆GM6020电机的角度与速度环 在机器人控制领域,精准的位置控制是实现高性能运动的基础。无论是工业机械臂的重复定位,还是竞技机器人云台的快速响应,都离不开对电机运动的精确控制。而在这其中…...

鸿蒙中的自由流转
鸿蒙自由流转是 HarmonyOS(鸿蒙系统) 实现多设备协同的核心能力之一,旨在打破设备边界,让应用和服务在不同终端间无缝流转,提升用户体验。什么是鸿蒙自由流转?鸿蒙自由流转是指用户在多个搭载 Harm…...

AI犯了错没人追责,工程师犯了错丢饭碗?
芯片公司开始大量引入AI辅助设计工具,生成RTL代码、跑仿真、做时序分析。与此同时,公司对工程师的容错空间越来越小,考核越来越严,出了bug第一反应是找人背锅。这两件事放在一起,细想一下,其实挺荒诞的。AI…...

SVM实战调参指南:从标准化、核函数到支持向量解读
1. 这不是教科书里的SVM,而是我亲手调过37次参数后才敢写的入门实录Support Vector Machine(SVM)这个词,第一次见是在三年前的某次算法面试里。面试官问:“你说说SVM为什么叫‘支持向量’?”我张了张嘴&…...

Unity编辑器性能优化:工作流、场景与预制体三大资源创建瓶颈
1. 为什么编辑器资源创建环节是Unity性能优化的“隐形地雷区”很多人一提Unity性能优化,第一反应就是Profiler里看Draw Call、GC Alloc、CPU耗时,或者去改Shader、压贴图、拆合批。这没错,但90%的团队在项目中后期卡顿频发、打包失败、CI构建…...

什么是虚拟化
什么是虚拟化? 什么是虚拟化 虚拟化长期以来一直是一项基础 IT 技术,使企业能够在一台物理机器上运行多个独立的系统。 虚拟化是一种允许从单个物理机创建多个虚拟环境的技术。这些虚拟环境基本上是以前与硬件绑定的功能的逻辑(虚拟ÿ…...