linux | 苹果OpenCL(提高应用软件如游戏、娱乐以及科研和医疗软件的运行速度和响应)
点击上方"蓝字"关注我们
01、引言
>>>OpenCL 1.0 于 2008 年 11 月发布。
OpenCL 是为个人电脑、服务器、移动设备以及嵌入式设备的多核系统提供并行编程开发的底层 API。OpenCL 的编程语言类似于 C 语言。其可以用于包含 CPU、GPU 以及来自主流制造商如 NXP®、NVIDIA®、Intel®、AMD、IBM 等的处理器的异构平台。OpenCL 旨在提高应用软件如游戏、娱乐以及科研和医疗软件的运行速度和响应。
我们使用 Apalis iMX6Q 系统模块测试 OpenCL,对比两个应用 - 一个运行在 GPU 上,另一个则在 CPU。最后我们将分享本次测试的结果。
02、Toradex Embedded Linux 镜像中添加 OpenCL
>>>假设你已经具有能够编译 Apalis iMX6 镜像的 OpenEmbedded 编译环境。你可以参考我们 OpenEmbedded (core) 【http://developer.toradex.com/knowledge-base/board-support-package/openembedded-(core)】文章。
为编译支持 OpenCL 以及相关库文件的嵌入式 Linux 镜像,需要采取以下步骤:
首先,修改下面目录中的文件。
/meta-toradex/recipes-fsl/packagegroups/packagegroup-fsl-tools-gpu.bbappend
添加如下内容:SOC_TOOLS_GPU_append_mx6 = " \libopencl-mx6 \libgles-mx6 \ "并在 local.conf 文件中添加 imx-gpu-viv
IMAGE_INSTALL_append = "imx-gpu-viv"
现在就可以编译镜像:bitbake angstrom-lxde-image
03、GPU 和 CPU 代码
>>>所有的代码可以从 GitHub【https://github.com/giobauermeister/OpenCL-test-apps】上下载。
我们使用数列求和应用作为基本的演示例程。第一部分代码运行在 GPU 上,第二部分则在 CPU 上。应用执行完毕后打印其所消耗的时间。使用 OpenCL 所需的头文件是 cl.h,位于文件系统的 /usr/include/CL 目录。链接程序所需的库文件是 libGAL.so 和 libOpenCL.so,位于 /usr/lib 目录。
为了计算消耗的时间,我们创建带分析功能的队列,在结束的时候获取分析的结果。
下面是 OpenCL 代码:
//************************************************************ // Demo OpenCL application to compute a simple vector addition // computation between 2 arrays on the GPU // ************************************************************ #include #include #include #include <CL/cl.h> // // OpenCL source code const char* OpenCLSource[] = { "__kernel void VectorAdd(__global int* c, __global int* a,__global int* b)", "{", " // Index of the elements to add \n", " unsigned int n = get_global_id(0);", " // Sum the nth element of vectors a and b and store in c \n", " c[n] = a[n] + b[n];", "}" }; // Some interesting data for the vectors Int InitialData1[80] = {37,50,54,50,56,0,43,43,74,71,32,36,16,43,56,100,50,25,15,17,37,50,54,50,56,0,43,43,74,71,32,36,16,43,56,100,50,25,15,17,37,50,54,50,56,0,43,43,74,71,32,36,16,43,56,100,50,25,15,17,37,50,54,50,56,0,43,43,74,71,32,36,16,43,56,100,50,25,15,17}; int InitialData2[80] = {35,51,54,58,55,32,36,69,27,39,35,40,16,44,55,14,58,75,18,15,35,51,54,58,55,32,36,69,27,39,35,40,16,44,55,14,58,75,18,15,35,51,54,58,55,32,36,69,27,39,35,40,16,44,55,14,58,75,18,15,35,51,54,58,55,32,36,69,27,39,35,40,16,44,55,14,58,75,18,15}; // Number of elements in the vectors to be added #define SIZE 600000 // Main function // ************************************************************ int main(int argc, char **argv) { // Two integer source vectors in Host memoryint HostVector1[SIZE], HostVector2[SIZE];//Output Vectorint HostOutputVector[SIZE];// Initialize with some interesting repeating datafor(int c = 0; c < SIZE; c++){HostVector1[c] = InitialData1[c%20];HostVector2[c] = InitialData2[c%20];HostOutputVector[c] = 0;}//Get an OpenCL platformcl_platform_id cpPlatform;clGetPlatformIDs(1, &cpPlatform, NULL);// Get a GPU devicecl_device_id cdDevice;clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, 1, &cdDevice, NULL);char cBuffer[1024];clGetDeviceInfo(cdDevice, CL_DEVICE_NAME, sizeof(cBuffer), &cBuffer, NULL);printf("CL_DEVICE_NAME: %s\n", cBuffer);clGetDeviceInfo(cdDevice, CL_DRIVER_VERSION, sizeof(cBuffer), &cBuffer, NULL);printf("CL_DRIVER_VERSION: %s\n\n", cBuffer);// Create a context to run OpenCL enabled GPUcl_context GPUContext = clCreateContextFromType(0, CL_DEVICE_TYPE_GPU, NULL, NULL, NULL); // Create a command-queue on the GPU devicecl_command_queue cqCommandQueue = clCreateCommandQueue(GPUContext, cdDevice, CL_QUEUE_PROFILING_ENABLE, NULL);// Allocate GPU memory for source vectors AND initialize from CPU memorycl_mem GPUVector1 = clCreateBuffer(GPUContext, CL_MEM_READ_ONLY |CL_MEM_COPY_HOST_PTR, sizeof(int) * SIZE, HostVector1, NULL);cl_mem GPUVector2 = clCreateBuffer(GPUContext, CL_MEM_READ_ONLY |CL_MEM_COPY_HOST_PTR, sizeof(int) * SIZE, HostVector2, NULL);// Allocate output memory on GPUcl_mem GPUOutputVector = clCreateBuffer(GPUContext, CL_MEM_WRITE_ONLY,sizeof(int) * SIZE, NULL, NULL);// Create OpenCL program with source codecl_program OpenCLProgram = clCreateProgramWithSource(GPUContext, 7, OpenCLSource, NULL, NULL);// Build the program (OpenCL JIT compilation)clBuildProgram(OpenCLProgram, 0, NULL, NULL, NULL, NULL);// Create a handle to the compiled OpenCL function (Kernel)cl_kernel OpenCLVectorAdd = clCreateKernel(OpenCLProgram, "VectorAdd", NULL);// In the next step we associate the GPU memory with the Kernel argumentsclSetKernelArg(OpenCLVectorAdd, 0, sizeof(cl_mem), (void*)&GPUOutputVector);clSetKernelArg(OpenCLVectorAdd, 1, sizeof(cl_mem), (void*)&GPUVector1);clSetKernelArg(OpenCLVectorAdd, 2, sizeof(cl_mem), (void*)&GPUVector2);//create eventcl_event event = clCreateUserEvent(GPUContext, NULL);// Launch the Kernel on the GPU// This kernel only uses global datasize_t WorkSize[1] = {SIZE}; // one dimensional RangeclEnqueueNDRangeKernel(cqCommandQueue, OpenCLVectorAdd, 1, NULL, WorkSize, NULL, 0, NULL, &event);// Copy the output in GPU memory back to CPU memoryclEnqueueReadBuffer(cqCommandQueue, GPUOutputVector, CL_TRUE, 0,SIZE * sizeof(int), HostOutputVector, 0, NULL, NULL);// CleanupclReleaseKernel(OpenCLVectorAdd);clReleaseProgram(OpenCLProgram);clReleaseCommandQueue(cqCommandQueue);clReleaseContext(GPUContext);clReleaseMemObject(GPUVector1);clReleaseMemObject(GPUVector2);clReleaseMemObject(GPUOutputVector); clWaitForEvents(1, &event);cl_ulong start = 0, end = 0;double total_time; clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_START, sizeof(cl_ulong), &start, NULL);clGetEventProfilingInfo(event, CL_PROFILING_COMMAND_END, sizeof(cl_ulong), &end, NULL);total_time = end - start; printf("\nExecution time in milliseconds = %0.3f ms", (total_time / 1000000.0) );printf("\nExecution time in seconds = %0.3f s\n\n", ((total_time / 1000000.0))/1000 ); return 0; }CPU 代码是简单的 C 程序,和上面一样计算同样的队列求和。为了计算消耗的时间,我们使用 time.h中的库。代码如下:
#include #include #include int InitialData1[80] = {37,50,54,50,56,0,43,43,74,71,32,36,16,43,56,100,50,25,15,17,37,50,54,50,56,0,43,43,74,71,32,36,16,43,56,100,50,25,15,17,37,50,54,50,56,0,43,43,74,71,32,36,16,43,56,100,50,25,15,17,37,50,54,50,56,0,43,43,74,71,32,36,16,43,56,100,50,25,15,17}; int InitialData2[80] = {35,51,54,58,55,32,36,69,27,39,35,40,16,44,55,14,58,75,18,15,35,51,54,58,55,32,36,69,27,39,35,40,16,44,55,14,58,75,18,15,35,51,54,58,55,32,36,69,27,39,35,40,16,44,55,14,58,75,18,15,35,51,54,58,55,32,36,69,27,39,35,40,16,44,55,14,58,75,18,15};#define SIZE 600000int main(int argc, char **argv) { time_t start, stop; clock_t ticks;time(&start); // Two integer source vectors in Host memory int HostVector1[SIZE], HostVector2[SIZE]; //Output Vector int HostOutputVector[SIZE]; // Initialize with some interesting repeating data //int n; for(int c = 0; c < SIZE; c++) { HostVector1[c] = InitialData1[c%20]; HostVector2[c] = InitialData2[c%20]; HostOutputVector[c] = 0; }for(int i = 0; i < SIZE; i++) {HostOutputVector[i] = HostVector1[i] + HostVector2[i];ticks = clock(); } time(&stop);printf("\nExecution time in miliseconds = %0.3f ms",((double)ticks/CLOCKS_PER_SEC)*1000);printf("\nExecution time in seconds = %0.3f s\n\n", (double)ticks/CLOCKS_PER_SEC);return 0; }
04、交叉编译应用
>>>同一个 Makefile 可以用于交叉编译 GPU 和 CPU 应用。你需要注意下面的三个变量。根据你的系统做相应的调整:
ROOTFS_DIR -> Apalis iMX6 文件系统路径
APPNAME -> 应用的名字
TOOLCHAIN -> 交叉编译工具的路径
export ARCH=arm export ROOTFS_DIR=/usr/local/toradex-linux-v2.5/oe-core/build/out-glibc/sysroots/apalis-imx6APPNAME = proc_sample TOOLCHAIN = /home/prjs/toolchain/gcc-linaroCROSS_COMPILER = $(TOOLCHAIN)/bin/arm-linux-gnueabihf- CC= $(CROSS_COMPILER)gcc DEL_FILE = rm -rf CP_FILE = cp -rf TARGET_PATH_LIB = $(ROOTFS_DIR)/usr/lib TARGET_PATH_INCLUDE = $(ROOTFS_DIR)/usr/include CFLAGS = -DLINUX -DUSE_SOC_MX6 -Wall -std=c99 -O2 -fsigned-char -march=armv7-a -mfpu=neon -DEGL_API_FB -DGPU_TYPE_VIV -DGL_GLEXT_PROTOTYPES -DENABLE_GPU_RENDER_20 -I../include -I$(TARGET_PATH_INCLUDE) LFLAGS = -Wl,--library-path=$(TARGET_PATH_LIB),-rpath-link=$(TARGET_PATH_LIB) -lm -lglib-2.0 -lOpenCL -lCLC -ldl -lpthread OBJECTS = $(APPNAME).o first: all all: $(APPNAME) $(APPNAME): $(OBJECTS) $(CC) $(LFLAGS) -o $(APPNAME) $(OBJECTS) $(APPNAME).o: $(APPNAME).c $(CC) $(CFLAGS) -c -o $(APPNAME).o $(APPNAME).c clean: $(DEL_FILE) $(APPNAME)在应用所在的目录中保持 Makefile 文件,然后运行 make。
将编译生成的文件复制到 Apalis iMX6 开发板上。测试结果
在执行两个应用程序后,我们得到以下结果:
### Processor time Execution time in miliseconds = 778.999 ms Execution time in seconds = 0.779 s ### GPU time Execution time in milliseconds = 12.324 ms Execution time in seconds = 0.012 s根据以上结果,我们可以很清楚地看到在 Apalis iMX6Q GPU 上使用 OpenCL 能够加速队列求和运算。
总结
>>>借助 OpenCL,可以在不同设备从图形显卡到超级计算机以及嵌入式设备,运行代码。用户还可以进一步结合,例如在 OpenCV 中使用 OpenCL 提高计算机视觉的性能。
对于绝大多数嵌入式应用,Linux 是正确的选择。Linux 编译系统,例如 Buildroot 和 OpenEmbedded,能够创建定制化的 BSP,裁剪到任意的大小,并且提供丰富的应用和 SDK,从 gstreamer、Python 到 node.js 等。基于 OpenEmbedded/Yocto 的 Linux 是 Toradex 支持的默认发行版本,开发社区还提供多种开发语言环境和框架。
现在的 GUI 可以使用 Qt、HTML5 来开发,以至于有点难于选择。
你也可以使用 NDK 基于 C/C++ 和 C# 开发你的应用,使用 Qt 作为显示框架或者利用 Cordova 或者 React Native 框架用 Javascript 开发移动应用
故我在
点击下方卡片 关注我
↓↓↓

相关文章:
linux | 苹果OpenCL(提高应用软件如游戏、娱乐以及科研和医疗软件的运行速度和响应)
点击上方"蓝字"关注我们 01、引言 >>> OpenCL 1.0 于 2008 年 11 月发布。 OpenCL 是为个人电脑、服务器、移动设备以及嵌入式设备的多核系统提供并行编程开发的底层 API。OpenCL 的编程语言类似于 C 语言。其可以用于包含 CPU、GPU 以及来自主流制造商如 …...

算法-UKF中Sigma点生成
void UKF::MakeSigmaPoints() {Eigen::VectorXd x_aug_ Eigen::VectorXd(n_x_);x_aug_.head(n_x_) x_;Eigen::MatrixXd P_aug Eigen::MatrixXd::Zero(n_x_, n_x_);// 转成正定矩阵P_aug pdefinite_svd(P_);// LLT分解Eigen::MatrixXd L P_aug.llt().matrixL();sigma_point…...

精选五款热门骨传导耳机分享,让你避免踩坑的陷阱
因为骨传导耳机独特的佩戴方式和声音的传播方式,受到了小耳、油耳以及运动爱好者的的喜爱,但也由于市面上的骨传导耳机品牌越来越多,很多朋友不知道该怎么选择,今天我挑选出市面上体验感较好,各方面比较出色的骨传导给…...

「字符串」前缀函数|KMP匹配:规范化next数组 / LeetCode 28(C++)
概述 为什么大家总觉得KMP难?难的根本就不是这个算法本身。 在互联网上你可以见到八十种KMP算法的next数组定义和模式串回滚策略,把一切都懂得特别混乱。很多时候初学者的难点根本不在于这个算法本身,而是它令人痛苦的百花齐放的定义。 有…...

python人工智能002:jupyter基本使用
小知识:将jupyter修改为中文,修改用户变量, 注意是用户变量,不是系统变量 新增用户变量 变量名:LANG 变量值:zh_CN.UTF8 然后重启jupyter 上一章的软件安装完成之后,就可以创建文件夹来学习写…...

Linux使用 firewalld管理防火墙命令
Linux 发行版中使用的动态防火墙管理工具。使用 firewalld,你可以查看防火墙状态、当前配置的规则以及开放的端口。以下是一些常用的 firewalld 命令来管理和查看防火墙状态及端口配置。 1. 查看防火墙状态 检查 firewalld 是否正在运行 sudo systemctl status f…...

二叉树(三)
一、二叉树的遍历 二叉树遍历是按照某种特定的规则,依次对二叉树中的结点进行相应的操作,并且每个结点只操作一次。 1.前序遍历(先根遍历) 前序遍历(Preorder Traversal也叫先序遍历)——根、左子树、右…...
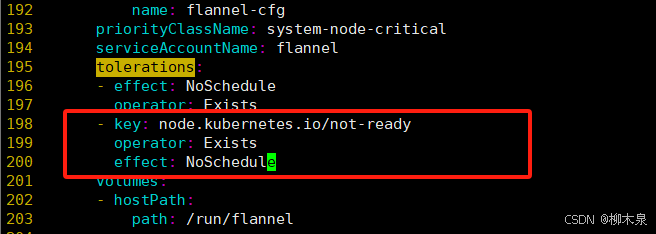
05--kubernetes组件与安装
前言:终于写到kubernetes(k8s),容器编排工具不止k8s一个,它的优势在于搭建集群,也是传统运维和云计算运维的第一道门槛,这里会列出两种安装方式,详细步骤会在下文列出,文…...

EmguCV学习笔记 VB.Net和C# 下的OpenCv开发 C# 目录
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 EmguCV是一个基于OpenCV的开源免费的跨平台计算机视觉库,它向C#和VB.NET开发者提供了OpenCV库的大部分功能。 教程VB.net版本请访问…...

探索TensorFlow:深度学习的未来
标题:探索TensorFlow:深度学习的未来 在当今快速发展的人工智能领域,TensorFlow无疑是最耀眼的明珠之一。TensorFlow是由Google Brain团队开发的一个开源机器学习框架,它以其强大的灵活性、易用性和高效的性能,迅速成…...

探索地理空间分析的新世界:Geopandas的魔力
文章目录 探索地理空间分析的新世界:Geopandas的魔力背景:为何选择Geopandas?这个库是什么?如何安装这个库?五个简单的库函数使用方法场景应用:Geopandas在实际工作中的应用常见bug及解决方案总结 探索地理…...

如何为网站申请免费SSL证书?
一、准备阶段 确定证书类型: 对于大多数个人博客和小型企业网站,DV(域名验证)SSL证书已足够使用,因为它仅验证域名所有权,成本较低且验证快速。准备域名: 确保你拥有一个有效的域名,…...

Java项目集成RocketMQ
文章目录 1.调整MQ的配置1.进入bin目录2.关闭broker和namesrv3.查看进程确认关闭4.编辑配置文件broker.conf,配置brokerIP15.开放端口109116.重新启动1.进入bin目录2.启动mqnamesrv和mqbroker1.启动 NameServer 并将输出重定向到 mqnamesrv.log2.**启动 Broker 并将…...

如何将 Bamboo agent 能力迁移到极狐GitLab tag 上?
极狐GitLab 是 GitLab 在中国的发行版,专门面向中国程序员和企业提供企业级一体化 DevOps 平台,用来帮助用户实现需求管理、源代码托管、CI/CD、安全合规,而且所有的操作都是在一个平台上进行,省事省心省钱。可以一键安装极狐GitL…...

正则表达式入门:Python ‘ re ‘ 模块详解
正则表达式(Regular Expression,简称 re)是一种强大而灵活的工具,广泛用于字符串匹配、替换和分割等操作,尤其在处理网页爬虫数据时非常有用。Python 提供了 " re " 模块来支持正则表达式的使用,…...
pc网站支付)
thinkphp8.0+aliapy(支付宝)pc网站支付
环境:宝塔-centOS8.5,php8.3 第一步:安装alipay v3版本的安装依赖包; composer require alipaysdk/openapi:dev第二步:根据官方文档,把支付相关的类引用进来; <?php declare (strict_types 1);namespace app\p…...

高速信号的眼图、加重、均衡
目录 高速信号的眼图、加重、均衡眼图加重均衡线性均衡器CTLE判决反馈均衡器DFE 高速信号的眼图、加重、均衡 眼图 通常用示波器观察接收信号波形的眼图来分析码间串扰和噪声对系统性能的影响,从而估计系统优劣程度,因而眼图分析是高速互连系统信号完整…...
2024年PMP考前冲刺必背的学习笔记,整理好给你!
项目的四大特点:临时性、独特性、变革驱动性和创造商业价值。 项目管理:将知识、技能、工具与技术应用于项目活动,以满足项目的要求 Pestle:P政治,E经济,S社会,T技术,L法律,E环境 …...

增加服务器带宽可以提高资源加载速度吗?
答案是可以的 ,增加服务器带宽通常能够提高资源加速速度。带宽是服务器与互联网之间传输数据的速率,它决定了在单位时间内可以传输的数据量。以下是增加带宽如何提高资源加速速度的几个方面: 1.更快的数据传输:带宽增加后…...

汽车EDI: NAVISTAR EDI对接
Navistar International Corporation 是一家美国商用车辆制造公司,总部位于伊利诺伊州的Lisle。公司以生产中型和重型卡车、公共汽车、柴油发动机和底盘闻名,其产品广泛应用于运输、建筑、和农业等行业。Navistar 的历史可以追溯到1831年,由国…...

AWS推出新工具简化量子纠错开发流程
谷歌近日将量子计算机实用化时间表提前至2029年,这得益于量子计算机硬件、量子纠错和算法方面的重大改进。2019年,谷歌估计需要2000万个量子比特才能破解RSA加密。到2025年5月,谷歌将这一估计数字下调至100万个。今年2月,澳大利亚…...
✅)
计算机毕业设计:Python汽车销量数据挖掘与预测系统 Flask框架 scikit-learn 可视化 requests爬虫 AI 大模型(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

Linux端口占用排查:工具与实战技巧
1. 网络端口占用排查的必要性遇到"Address already in use"错误提示时,每个Linux系统管理员都会心头一紧。这种端口冲突问题不仅影响服务启动,还可能导致关键业务中断。我刚入行时就曾因为Nginx和Apache争抢80端口,导致公司官网瘫痪…...

信奥赛C++提高组csp-s高频考点知识详解
信奥赛C提高组csp-s高频考点知识详解 高频考点:并查集、最小生成树、拓扑排序、欧拉回路、强连通分量、二分图、Dijkstra、Floyd、Bellman-Ford、SPFA、树状数组、线段树、哈希、哈希表、离散化、KMP、Trie字典树、AC自动机、单调栈、单调队列、快速幂、倍增算法、反…...

零欧姆电阻特性与应用全解析
1. 零欧姆电阻的本质与特性零欧姆电阻,这个看似矛盾的名字在电子工程领域却有着广泛的应用。作为一名硬件工程师,我在多年的电路设计实践中发现,这个小元件远比表面看起来要复杂得多。1.1 零欧姆电阻的真实特性零欧姆电阻并非真正的零阻值&am…...

Three.js实战:打造交互式3D中国地图可视化
1. 从零开始搭建3D中国地图 第一次接触Three.js时,我被它强大的3D渲染能力震撼到了。作为一个长期从事数据可视化的开发者,我一直在寻找能够将地理数据以更生动方式呈现的工具。Three.js配合D3.js的组合,完美解决了这个问题。 1.1 数据准备与…...

三千年的欲望、痕迹与自感:资本批判与伦理中间件
三千年的欲望、痕迹与自感:资本批判与伦理中间件岐金兰 丙午神农---引言:被命名的与未命名的在人类文明的长河中,有一个东西从未缺席,却长期被剥夺了命名的权利。它比语言更古老,比理性更顽强,比任何社会制…...

Claude封号潮下的开发者生存指南:从源码泄露到合规中转的全解析
📌 全文速览:本文深度拆解2026年春季席卷AI编程圈的Claude账号封禁浪潮以及Anthropic源码泄露事件,从技术根源到社区自救,再到终极解决方案,为你呈现AI开发者生存指南。Claude封号潮下的开发者生存指南:从源…...
)
专题:哈希结构(已完结)
1.有效的字母异位词 class Solution { public:bool isAnagram(string s, string t) {unordered_map<char,int> mymap;for(auto c:s){mymap[c]mymap[c]1;}for(auto c:t){mymap[c]mymap[c]-1;}for(auto item:mymap){if(item.second!0){return false;}}return true;} };2.两…...

终极指南:使用Docker快速部署WriteGPT AI创作平台
终极指南:使用Docker快速部署WriteGPT AI创作平台 【免费下载链接】WriteGPT 基于开源GPT2.0的初代创作型人工智能 | 可扩展、可进化 项目地址: https://gitcode.com/gh_mirrors/wri/WriteGPT WriteGPT是一款基于开源GPT-2.0的初代创作型人工智能框架&#x…...