【Hot100算法刷题集】哈希-02-字母异位词分组(含排序构造键、自定义键、自定义哈希函数法)

🏠关于专栏:专栏用于记录LeetCode中Hot100专题的所有题目
🎯每日努力一点点,技术变化看得见
题目转载
题目描述
🔒link->题目跳转链接
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
题目示例
示例 1:
输入: strs = [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
输出: [[“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]]
示例 2:
输入: strs = [“”]
输出: [[“”]]
示例 3:
输入: strs = [“a”]
输出: [[“a”]]
题目提示
● 1 1 1 <= strs.length <= 1 0 4 10^4 104
● 0 0 0 <= strs[i].length <= 100 100 100
● strs[i] 仅包含小写字母
解题思路及代码
整理题意
题目中给出了异位字母词的概念,其指的是,如果两个单词的26个英文字母数相同,但位于的位置不同,则称为异位字母词。如eat和ate就是异位字母词,它们都有1个a、1个e、1个t;如queue和queen就不是异位字母词,因为他们的u和n字母的数量不同。
[1]排序
从异位字母词的概念我们可以知道,如果对两个互为异位字母词的字母串进行排序,则它们都会得到相同的字符串。如eat和ate排序后均为aet。那么我们可以使用哈希表进行存储,键域(key)保存异位字母词排序后的字符串,值域(value)保存一个vector<string>类型,用于保存所有排序后为键(key)的字符串。
class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string, vector<string>> m;for(auto str : strs){string tmp = str;sort(tmp.begin(), tmp.end());m[tmp].push_back(str);}vector<vector<string>> ret;for(auto member : m){ret.push_back(member.second);}return ret;}
};
[2]计数
既然互为异位字母词的字符串的各个字母数量相等,我们可不可以将上面哈希表中的键(key)改为26个字母的计数数组呢?在C++中,unordered_map无法直接将数组作为键(key),需要将数组转换为unordered_map支持的类型,如string、int等;或借助于仿函数,实现数组的直接比较。
自主定义键(key)
以纯数字字符串为键
从题目的提示可知,每个字母最多出现10000次,如果使用数字字符表示,需要5个;而26个字母,每个用5个数字字符表示,即需要 26 × 5 26×5 26×5,即130个字符表示,由这个字符串作为哈希表的键(key)。

class Solution {
public:string arrToSting(vector<int>& arr){string ret;for(auto elem : arr){string tmp; tmp.push_back(elem);while(tmp.size() < 5) tmp.insert(tmp.begin(), '0');ret.append(tmp);}return ret;}vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string, vector<string>> m;for(auto& str : strs){vector<int> count(26);for(auto e : str) ++count[e - 'a'];m[arrToSting(count)].push_back(str);}vector<vector<string>> ret;for(auto elem : m){ret.push_back(elem.second);}return ret;}
};
以数字、字母交替字符串为键
除了上面的方式,我们可以使用“字母+字母数量”组合而成的字符串作为键(key),如下图所示。

class Solution {
public:string arrToSting(vector<int>& arr){string ret;for(int i = 0; i < arr.size(); ++i){ret.push_back(i + '1');ret.push_back(arr[i]);}return ret;}vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string, vector<string>> m;for(auto& str : strs){vector<int> count(26);for(auto e : str) ++count[e - 'a'];m[arrToSting(count)].push_back(str);}vector<vector<string>> ret;for(auto elem : m){ret.push_back(elem.second);}return ret;}
};
自定义哈希函数
在介绍该方法前,先对一些C++中的操作进行介绍并给出相关示例。首先介绍std::hash,该哈希函数对象位于functional库中,它可用于为不同的类型生成哈希值,下方是关于std::hash的示例:
#include <iostream>
#include <functional>int main()
{int num = 666;std::hash<int> hasher;size_t hashValue = hasher(num);std::cout << num << "'s hashValue is " << hashValue << std::endl;return 0;
}
🔍注意:C++中规定,哈希值为size_t类型
下面再认识一下std::accumulate,它位于numeric库中,默认情况下,它所实现的就是将数组中的所有数据累加。第一个参数为待计算区间的起始迭代器,第二个参数是待计算区间的终止迭代器,第三个参数是起始值,代码示例如下(下方输出结果为10):
#include <iostream>
#include <vector>
#include <numeric>int main()
{std::vector<int> arr = {1, 2, 3, 4};std::cout << std::accumulate(arr.begin(), arr.end(), 0) << std::endl;return 0;
}
我们可以通过lambda表达式,自定义accumulate的累加操作。下方的acc表示当前所累加的数字综合,num表示当前数字,由accumulate函数自动传入。
#include <iostream>
#include <vector>
#include <numeric>int main()
{std::vector<int> arr = {1, 2, 3, 4};int ret = std::accumulate(arr.begin(), arr.end(), 0, [&](int acc, int num){std::cout << "before add num, acc is " << acc << std::endl;acc += num;std::cout << "after add num values " << num << " acc is " << acc << std::endl;retrun acc;});std::cout << "final ret is " << ret << std::endl;return 0;
}

介绍完上述的操作后,下面开始介绍自定义哈希函数的方法。unordered_map在存储值域(value)时,先使用哈希函数对键域(key)进行映射操作,找到对应的映射位置后才能存储值(value)。而unordered_map之所以无法使用数组作为键域(key),就是因为缺少对应的哈希映射函数,那我们只要提供对应的哈希映射函数即可。下面提供了一个哈希映射函数。
auto arrayHash = [fn = hash<int>{}](const array<int, 26>& arr) -> size_t {return accumulate(arr.begin(), arr.end(), 0u, [&](size_t acc, int num){return (acc << 1) ^ fn(num);});
};
这里的哈希映射函数是将累加的数值总和acc<<2,即将acc乘以2,再与生成的哈希值做异或运算。下面我们将哈希映射函数提供给unordered_map,它就可以实现对数组作为键域(key)的位置映射。
class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {auto arrayHash = [fn = hash<int>{}](const array<int, 26>& arr) -> size_t {return accumulate(arr.begin(), arr.end(), 0u, [&](size_t acc, int num) {return (acc << 1);});};unordered_map<array<int, 26>, vector<string>, decltype(arrayHash)> mp(0, arrayHash);for(string& str : strs){array<int, 26> counts{};int length = str.length();for(int i = 0; i < length; i++){counts[str[i] - 'a']++;}mp[counts].emplace_back(str);}vector<vector<string>> ans;for (auto it = mp.begin(); it != mp.end(); ++it) {ans.emplace_back(it->second);}return ans;}
};
这里的思路和哈希算法均为官方给出的题解,我们可能会有疑惑,这里的哈希映射函数,我们可以修改吗?当然可以,只要我们保证不同的值映射到的位置尽可能不同,尽量避免哈希冲突,这个哈希映射函数就是相对成功的。
对于queen的累次计算结果如下:
| 计算次序/对应字母 | acc原值 | acc<<2后数值 | num原值 | fn(num)值 | acc << 2 ^ fn(num)数值 |
|---|---|---|---|---|---|
| 0/a | 0 | 0 | 0 | 0 | 0 |
| 1/b | 0 | 0 | 0 | 0 | 0 |
| 2/c | 0 | 0 | 0 | 0 | 0 |
| 3/d | 0 | 0 | 0 | 0 | 0 |
| 4/e | 0 | 0 | 2 | 2 | 2 |
| 5/f | 2 | 8 | 0 | 0 | 8 |
| 6/g | 8 | 32 | 0 | 0 | 32 |
| 7/h | 32 | 128 | 0 | 0 | 128 |
| 8/i | 128 | 512 | 0 | 0 | 512 |
| 9/j | 512 | 2048 | 0 | 0 | 2048 |
| 10/k | 2048 | 8192 | 0 | 0 | 8192 |
| 11/l | 8192 | 32768 | 0 | 0 | 32768 |
| 12/m | 32768 | 131072 | 0 | 0 | 131072 |
| 13/n | 131072 | 524288 | 1 | 1 | 524289 |
| 14/o | 524289 | 2097156 | 0 | 0 | 2097156 |
| 15/p | 2097156 | 8388624 | 0 | 0 | 8388624 |
| 16/q | 8388624 | 33554496 | 1 | 1 | 33554497 |
| 17/r | 33554497 | 134217988 | 0 | 0 | 134217988 |
| 18/s | 134217988 | 536871952 | 0 | 0 | 536871952 |
| 19/t | 536871952 | 2147487808 | 0 | 0 | 2147487808 |
| 20/u | 2147487808 | 8589951232 | 1 | 1 | 8589951233 |
| 21/v | 8589951233 | 34359804932 | 0 | 0 | 34359804932 |
| 22/w | 34359804932 | 137439219728 | 0 | 0 | 137439219728 |
| 23/x | 137439219728 | 549756878912 | 0 | 0 | 549756878912 |
| 24/y | 549756878912 | 2199027515648 | 0 | 0 | 2199027515648 |
| 25/z | 2199027515648 | 8796110062592 | 0 | 0 | 8796110062592 |
这里的<<(左移)操作本质是扩大acc的数值。不断扩大结果集有助于降低哈希冲突的概率,但这却并不表明我们可以完全避免哈希冲突。由于每个字母至多出现10000次,10000至多需要13个比特位表示,若对acc每次左移13位,可完全避免哈希冲突。但左移位数越多,键域(key)所占的比特数越大。这里通过^(异或)操作尽量打乱二进制位,而不是增加<<(左移)数量的方式来减少哈希冲突概率,可以避免键(key)占用的二进制位过多。至于如何设计函数需要根据不同题目给出,这里不再讨论。这个方法建议作为了解即可,哈希函数的构造需要的数学理论和难度相对较高,这个方法也不容易想到。
刷题使我快乐😭
文章如有错误,请私信或在下方留言😀
相关文章:
【Hot100算法刷题集】哈希-02-字母异位词分组(含排序构造键、自定义键、自定义哈希函数法)
🏠关于专栏:专栏用于记录LeetCode中Hot100专题的所有题目 🎯每日努力一点点,技术变化看得见 题目转载 题目描述 🔒link->题目跳转链接 给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺…...

用华为智驾,开启MPV的下半场
作者 |老缅 编辑 |德新 8月28日,岚图正式对外公布了全球首款搭载华为乾崑智驾和鸿蒙座舱的MPV——全新岚图梦想家。 新车定位「全景豪华科技旗舰MPV」,全系标配四驱,分为四驱鲲鹏版和四驱乾崑版。 其中岚图逍遥座舱和鲲鹏智驾构成的鲲鹏版…...

发烧时眼睛胀痛的多种原因
发烧时眼睛胀痛的多种原因 发烧时眼睛胀痛可能由多种原因引起,主要包括以下几个方面: 上呼吸道感染: 发烧通常由上呼吸道感染引起,如感冒等。这些疾病多由病毒或细菌感染导致,如流感病毒、副流感病毒、腺病毒等。当机…...

用ACF和PACF计算出一堆数据的周期个数以及周期时长,数据分析python
具体步骤 1使用ACF和PACF:可以通过查看ACF图中的周期性峰值,找到数据中的周期性。如果ACF图在某个滞后期处出现显著的正相关峰值,并且这种模式在多个滞后周期中重复出现,这就是周期性信号的特征。而PACF则可以帮助确定延迟的直接影…...

生活方式对人健康影响非常大 第三篇
身体健康因素中 生活方式占到60% 赶紧去调整自己哪错了 上游的生活方式管理 是药三分毒 药物会影响身体肝肾功能,代谢 所以你要去找上游到底是我哪错了 短板越多 个健康状态越差 饮食管理是生活方式管理中难度最大的 原则1:与基因相对应相平衡 只吃素 会导致大脑萎…...

ubuntu22.04 qemu 安装windows on arm虚拟机
ubuntu22.04 qemu 安装windows on arm虚拟机 iso: https://uupdump.net/ https://massgrave.dev/windows_arm_links vivo driver: https://fedorapeople.org/groups/virt/virtio-win/direct-downloads/archive-virtio/virtio-win-0.1.262-2/ qemu sudo apt update sudo a…...

前端框架的演变与选择
目录 前端框架的演变与选择 1. 什么是前端框架? 2. 前端框架的演变 2.1 早期的Web开发 2.2 JavaScript库的兴起 2.3 MVC架构的引入 3. 现代前端框架概览 3.1 React 3.2 Vue.js 3.3 Angular 4. 其他值得关注的前端框架 4.1 Svelte 4.2 Ember.js 5. 如何…...
如何管理用户密码策略?)
Oracle(109)如何管理用户密码策略?
管理用户密码策略是确保数据库安全性的重要措施之一。通过定义和实施密码策略,可以确保用户使用强密码,并定期更新密码,以防止未经授权的访问。以下是如何在 MySQL 和 PostgreSQL 中详细配置和管理用户密码策略的步骤和代码示例。 MySQL 用户…...

【重学MySQL】十三、基本的 select 语句
【重学MySQL】十三、基本的 select 语句 基本结构示例检索所有列检索特定列带有条件的检索dual 列的别名基本的列别名使用别名在表达式中的使用别名在聚合函数中的应用 distinct基本用法注意事项示例 空值参与运算数学运算字符串连接比较运算逻辑运算处理NULL的函数 着重号为什…...

vue3.5新特性整理
本文章介绍vue3.5更新的几个新特性 1.vue中watch中深度监听更新的层级 在之前deep 属性是一个boolean值 我们要监听对象的变化需要使用deep: true 在vue3.5之后 deep 也可以是一个number 表示对象要监听的层级数量 这个功能还是比较实用的 因为层级过深的时候我们可能需要监听…...

RK3588 系列之3—rknn使用过程中遇到的bug
RK3588 系列之3—rknn使用过程中遇到的bug 1.librockchip_mpp.so: file format not recognized; treating as linker scrip2.Could not find a package configuration file provided by "OpenCV" with any of the following names参考文献 1.librockchip_…...

Java中的强引用、软引用、弱引用和虚引用于JVM的垃圾回收机制
参考资料 https://juejin.cn/post/7123853933801373733 在 Java 中,引用类型分为四种:强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)和虚引用…...

网络协议的基础知识
前言 本文将详细介绍IP地址、端口号、协议、协议分层、封装、分用、客户端、服务器、请求、响应以及两台主机之间的网络通信流程等网络原理知识。 一、IP 地址 概念 IP地址主要用于标识网络中的主机和其他网络设备(如路由器)的位置。 类似于快递中的…...

Java高级Day37-UDP网络编程
109.netstat指令 netstat -an 可以查看当前主机网络情况,包括端口监听情况和网络连接情况 netstat -an|more 可以分页显示 要求在dos控制台下执行 说明: LISTENING表示某个端口在监听 如果有一个外部程序(客户端)连接到该端口…...

如何利用ChatGPT提升学术论文讨论部分的撰写质量和效率
大家好,感谢关注。我是七哥,一个在高校里不务正业,折腾学术科研AI实操的学术人。关于使用ChatGPT等AI学术科研的相关问题可以和作者七哥(yida985)交流,多多交流,相互成就,共同进步,为大家带来最酷最有效的智能AI学术科研写作攻略。经过数月爆肝,终于完成学术AI使用教…...

谷歌seo网址如何快速被收录?
想让你的网站快速被搜索引擎收录,可以采取几种不同的策略。首先,确保你的网站内容丰富、有价值,搜索引擎更喜欢收录内容质量高的网站。同时,增强网站的外链建设,做好这些站内优化,接下来就是通过谷歌搜索控…...
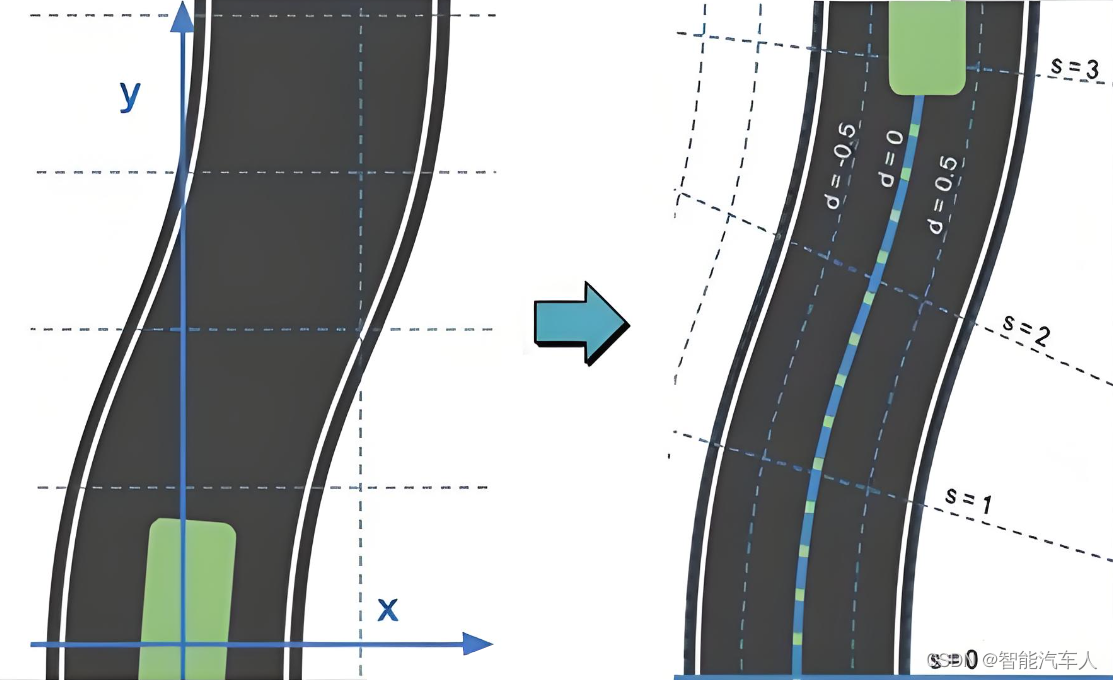
自动驾驶---什么是Frenet坐标系?
1 背景 为什么提出Frenet坐标系?Frenet坐标系的提出主要是为了解决自动驾驶系统在路径规划的问题,它基于以下几个原因: 符合人类的驾驶习惯: 人类驾驶员在驾驶过程中,通常不会关心自己距离起点的横向和纵向距离&#x…...

如何编写Linux PCI设备驱动器 之一
如何编写Linux PCI设备驱动器 之一 PCI寻址PCI驱动器使用的APIpci_register_driver()pci_driver结构pci_device_id结构 如何查找PCI设备存取PCI配置空间读配置空间APIs写配置空间APIswhere的常量值共用部分类型0类型1 PCI总线通过使用比ISA更高的时钟速率来实现更好的性能&…...

梯度弥散问题及解决方法
梯度弥散问题及解决方法 简要阐述梯度弥散发生的原因以及现象针对不同发生原因有什么解决方案1. 使用ReLU及其变体激活函数2. 权重初始化3. 批量归一化(Batch Normalization)4. 残差连接(Residual Connections)5. 梯度裁剪(Gradient Clipping)简要阐述梯度弥散发生的原因…...

Python中pickle文件操作及案例-学习篇
一、简介 Pickle 算是Python的一种数据序列化方法,它能够将对象转换为字节流,进而可以保存到文件中或通过网络传输给其他Python程序。这种方式非常适合快速简便地保存复杂的数据结构,例如列表、字典、自定义对象等。 二、pickle文件的读写 …...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

【DeepSeek架构评审功能深度解密】:20年架构师亲授3大避坑指南与5步落地 checklist
更多请点击: https://kaifayun.com 第一章:DeepSeek架构评审功能全景概览 DeepSeek架构评审功能是一套面向大模型系统设计与工程落地的自动化分析框架,聚焦于模型结构合理性、计算图优化潜力、内存访问模式、算子兼容性及部署约束等多维度评…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...