Pyspark中catalog的作用与常用方法
文章目录
- Pyspark catalog用法
- catalog 介绍
- cache 缓存表
- uncache 清除缓存表
- cleanCache 清理所有缓存表
- createExternalTable 创建外部表
- currentDatabase 返回当前默认库
- tableExists 检查数据表是否存在,包含临时视图
- databaseExists 检查数据库是否存在
- dropGlobalTempView 删除全局临时视图
- dropTempView 删除临时视图
- functionExists 检查函数是否存在
- getDatabase 获取具有指定名称的数据库
- getFunction 获取方法
- getTable 获取数据表
- isCached 检查是否缓存成功
- listCatalogs 列出可用的catalogs
- listColumns 返回数据表的列信息
- listDatabases 获取数据库列表
- listTables 获取数据表,包含临时视图
- setCurrentDatabase 设置当前数据库
- refreshTable 刷新缓存
- refreshByPath 刷新路径
- recoverPartitions 恢复分区
Pyspark catalog用法
catalog 介绍
Catalog是Spark中用于管理元数据信息的接口,这些元数据可能包括库、内部或外部表、函数、表列及临时视图等。
总的来说,PySpark Catalogs是PySpark框架中用于管理和查询元数据的重要组件,它使得Python用户能够更有效地利用PySpark进行大数据处理和分析。
spark = SparkSession.builder.appName('LDSX_TEST') \.config('hive.metastore.uris', 'thrift://hadoop01:9083') \.config('spark.master',"local[2]" ) \.enableHiveSupport().getOrCreate()
cache 缓存表
可以设置缓存等级,默认缓存等级为MEMORY_AND_DISK,是数据表级别的缓存,跟缓存dataframe存在区别,
设置不存在的表报错
# 缓存数据表
spark.catalog.cacheTable('ldsx_test.ldsx_table_one')
#检查是否缓存成功
ldsx = spark.catalog.isCached('ldsx_test.ldsx_table_one')
>True
uncache 清除缓存表
当表不存在数据库会报错
spark.catalog.uncacheTable("ldsx_test.ldsx_table_one")
cleanCache 清理所有缓存表
spark.catalog.clearCache()
createExternalTable 创建外部表
# spark.catalog.createExternalTable(# tableName='ldsx_test_table',# path = './ldsx_one.csv',# database='ldsx_test',## )
currentDatabase 返回当前默认库
返回当前默认所在数据库spark.catalog.setCurrentDatabase 设置所在数据库
data = spark.catalog.currentDatabase()
tableExists 检查数据表是否存在,包含临时视图
data = spark.catalog.tableExists('ldsx_test.ldsx_table_one')
>True
databaseExists 检查数据库是否存在
data = spark.catalog.databaseExists('ldsx_test')
dropGlobalTempView 删除全局临时视图
全局临时表查找时候需要指向global_temp
要删除的表不存在报错
#创建全局临时表
spark.createDataFrame([(1, 1)]).createGlobalTempView("my_table")
#注意查询时候需要指向 global_temp
spark.sql('select * from global_temp.my_table').show()
#删除全局临时
ldsx= spark.catalog.dropGlobalTempView("my_table")
dropTempView 删除临时视图
要删除的表不存在报错
#创建临时表
spark.createDataFrame([(1, 1)]).createTempView("my_table")
spark.sql('select * from my_table').show()
#删除临时表
ldsx = spark.catalog.dropTempView("my_table")
functionExists 检查函数是否存在
spark.catalog.functionExists("count")
>True
getDatabase 获取具有指定名称的数据库
data = spark.catalog.getDatabase("ldsx_test")
print(data)
>>Database(name='ldsx_test', catalog='spark_catalog', description='', locationUri='hdfs://master:7171/home/ldsx/opt/hadoopData/hive_data/ldsx_test.db')
getFunction 获取方法
获取不到方法报错
spark.sql("CREATE FUNCTION my_func1 AS 'test.org.apache.spark.sql.MyDoubleAvg'")
data = spark.catalog.getFunction("my_func1")
print(data)
>>Function(name='my_func1', catalog='spark_catalog', namespace=['default'], description='N/A.', className='test.org.apache.spark.sql.MyDoubleAvg', isTemporary=False)
getTable 获取数据表
获取不到表报错
data = spark.catalog.getTable("ldsx_table_one")
print(data)
>>Table(name='ldsx_table_one', catalog='spark_catalog', namespace=['ldsx_test'], description=None, tableType='MANAGED', isTemporary=False)
isCached 检查是否缓存成功
# 缓存数据表
spark.catalog.cacheTable('ldsx_test.ldsx_table_one')
data = spark.catalog.isCached('ldsx_test.ldsx_table_one')
>True
listCatalogs 列出可用的catalogs
catalogs = spark.catalog.listCatalogs()
print(catalogs)
listColumns 返回数据表的列信息
# 参数:数据表,数据库
catalogs = spark.catalog.listColumns('ldsx_table_one','ldsx_test')
print(catalogs)
>> [Column(name='age', description='??', dataType='string', nullable=True, isPartition=False, isBucket=False),Column(name='name', description='??', dataType='string', nullable=True, isPartition=False, isBucket=False),Column(name='fraction', description='??', dataType='string', nullable=True, isPartition=False, isBucket=False),Column(name='class', description='??', dataType='string', nullable=True, isPartition=False, isBucket=False),Column(name='gender', description='??', dataType='string', nullable=True, isPartition=False, isBucket=False)]
listDatabases 获取数据库列表
data1 = spark.catalog.listDatabases()
print(data1)
>>[Database(name='default', catalog='spark_catalog', description='Default Hive database',locationUri='hdfs://master:7171/home/ldsx/opt/hadoopData/hive_data'),
Database(name='ldsx_test', catalog='spark_catalog', description='',locationUri='hdfs://master:7171/home/ldsx/opt/hadoopData/hive_data/ldsx_test.db')]
listTables 获取数据表,包含临时视图
# 展示数据库中数据表以及临时视图
spark.catalog.setCurrentDatabase('ldsx_test')
spark.createDataFrame([(1,1)]).createTempView('TEST')
data = spark.catalog.listTables()
print(data)
>>[Table(name='ldsx_table_one', catalog='spark_catalog', namespace=['ldsx_test'], description=None,tableType='MANAGED', isTemporary=False),Table(name='TEST', catalog=None, namespace=[], description=None, tableType='TEMPORARY', isTemporary=True)]
setCurrentDatabase 设置当前数据库
spark.catalog.setCurrentDatabase('ldsx_test')
data = spark.catalog.currentDatabase()
print(data)
>> ldsx_test
refreshTable 刷新缓存
看官网案例是,刷新已经缓存的表
当一个表执行了cacheTable后,元数据有变动使用refreshTable进行元数据刷新
refreshByPath 刷新路径
# 假设有一个 Hive 表,其数据存储在 HDFS 上的某个路径
path = "/user/hive/warehouse/mydb.db/mytable"
# 刷新该路径下的表或分区信息
spark.catalog.refreshByPath(path)
df = spark.sql("SELECT * FROM mydb.mytable")
df.show()
recoverPartitions 恢复分区
recoverPartitions尝试恢复 Hive 表中丢失的分区信息,实际使用后更新
相关文章:

Pyspark中catalog的作用与常用方法
文章目录 Pyspark catalog用法catalog 介绍cache 缓存表uncache 清除缓存表cleanCache 清理所有缓存表createExternalTable 创建外部表currentDatabase 返回当前默认库tableExists 检查数据表是否存在,包含临时视图databaseExists 检查数据库是否存在dropGlobalTemp…...

聚焦2024数博会|与天空卫士一起探索AI与数据安全的融合应用
中国国际大数据产业博览会(简称数博会),是全球首个以大数据为主题的博览会,自2015年创办以来,经过多年的深厚沉淀,数博会已发展成为国际知名、引领前沿趋势的专业展示合作平台。 2024年8月28日至30日&#…...

实战docker第二天——cuda11.8,pytorch基础环境docker打包
在容器化环境中打包CUDA和PyTorch基础环境,可以将所有相关的软件依赖和配置封装在一个Docker镜像中。这种方法确保了在不同环境中运行应用程序时的一致性和可移植性: Docker:提供了容器化技术,通过将应用程序及其所有依赖打包在一…...

企业数字化转型的利器:RFID资产管理系统
在当今数字化时代,资产管理的效率和精确度对企业的成功至关重要。常达智能物联的RFID资产管理系统,凭借其高效、智能的管理方式,成为众多企业在数字化转型中的关键工具。 RFID资产管理系统的核心优势 一、精准资产定位与追踪 常达智能物联的…...
matplotlib中文乱码问题
在使用Matplotlib进行数据可视化的过程中,经常会遇到中文乱码的问题。显示乱码是由于编码问题导致的,而matplotlib 默认使用ASCII 编码,但是当使用pyplot时,是支持unicode编码的,只是默认字体是英文字体,导…...

提高开发效率的实用工具库VueUse
VueUse中文网:https://vueuse.nodejs.cn/ 使用方法 安装依赖包 npm i vueuse/core单页面使用(useThrottleFn举例) import { useThrottleFn } from "vueuse/core"; // 表单提交 const handleSubmit useThrottleFn(() > {// 具…...

【数据结构】你真的学会了二叉树了吗,来做一做二叉树的算法题及选择题
文章目录 1. 二叉树算法题1.1 单值二叉树1.2 相同的树1.3 另一棵树的子树1.4 二叉树的遍历1.5 二叉树的构建及遍历 2. 二叉树选择题3. 结语 1. 二叉树算法题 1.1 单值二叉树 https://leetcode.cn/problems/univalued-binary-tree/description/ 1.2 相同的树 https://leetco…...

压力测试知识总结
压力测试知识总结 引言 随着信息技术的飞速发展,软件系统在各个行业中的应用越来越广泛,其稳定性和可靠性成为用户关注的焦点。压力测试作为软件测试中的一种重要方法,对于确保软件在高负载环境下的稳定性和可靠性具有重要意义。本文将从压…...

@import导入样式以及scss变量应用与static目录
import函数:使用import语句可以导入外联样式表,import后跟需要导入的外联样式表的相对路径,用;表示语句结束。 static目录:就是无论你有没有在这个目录里用过,它都会进行编译打包 import函数应用:先在在项目里创建一个common 目录, 目录里面分别创建css,…...
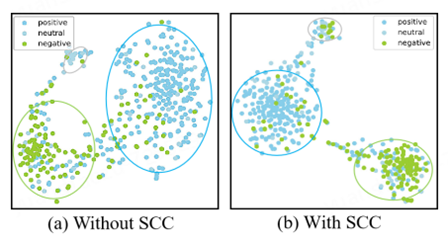
分类中的语义一致性约束:助力模型优化
前言 这里介绍一篇笔者在去年ACL上发表的一篇文章,使用了空间语义约束来提高多模态分类的效果,类似的思路笔者也在视频描述等方向进行了尝试,也都取得了不错的效果。这种建模时对特征进行有意义的划分和约束对模型还是很有帮助的,…...

前端框架介绍
前端框架是Web开发中不可或缺的工具,它们通过提供结构化的开发方式、模块化组件、响应式设计以及高效的性能优化,极大地简化了Web应用程序的开发过程。以下是对当前主流及新兴前端框架的详细介绍,这些框架不仅涵盖了广泛的功能,还…...

java基础知识-JVM知识详解
文章目录 一、JVM内存结构二、常见垃圾回收算法1. 标记-清除算法(Mark-Sweep Algorithm)2. 标记-整理算法(Mark-Compact Algorithm)3. 复制算法(Copying Algorithm)4. 分代收集算法(Generational Collection)5. 增量收集算法(Incremental Collection)6. 并行收集算法…...

流动会场:以声学专利为核心的完美移动场地—轻空间
流动会场作为一种全新的活动场所选择,凭借其便捷的移动性与先进的声学设计,正逐渐成为各类演出、会议和文化活动的热门场地。其独特之处不仅在于搭建速度快、灵活性高,还在于其核心技术——声学专利的强大支持。 专利声学设计,打造…...

深度学习(一)-感知机+神经网络+激活函数
深度学习概述 深度学习的特点 优点 性能更好 不需要特征工程 在大数据样本下有更好的性能 能解决某些传统机器学习无法解决的问题 缺点 小数据样本下性能不如机器学习 模型复杂 可解释性弱 深度学习与传统机器学习相同点 深度学习、机器学习是同一问题不同的解决方法 …...

目标检测-YOLOv4
YOLOv4介绍 YOLOv4 是 YOLO 系列的第四个版本,继承了 YOLOv3 的高效性,并通过大量优化和改进,在目标检测任务中实现了更高的精度和速度。相比 YOLOv3,YOLOv4 在框架设计、特征提取、训练策略等方面进行了全面升级。它在保持实时检…...

一台笔记本电脑的硬件都有哪些以及对应的功能
一台笔记本电脑的硬件通常包括多个关键组件,这些组件共同协作,确保电脑的正常运行。以下是笔记本电脑的主要硬件及其功能: 1. 中央处理器(CPU) 功能:CPU 是电脑的“大脑”,负责处理所有的计算…...

【程序分享1】第一性原理计算 + 数据处理程序
【1】第一性原理计算 数据处理程序 SMATool 程序:VASP QE 零温 有限温度 拉伸、剪切、双轴、维氏硬度的计算 ElasTool v3.0 程序:材料弹性和机械性能的高效计算和可视化工具包 VELAS 程序:用于弹性各向异性可视化和分析 Phasego 程序…...

【数据结构】栈与队列OJ题(用队列实现栈)(用栈实现队列)
目录 1.用队列实现栈oj题 对比 一、初始化 二、出栈 三、入栈 四、取队头元素: 2.用栈实现队列 一、定义 二、入队列 三、出队列 四、队头 五、判空 前言:如果想了解什么是栈和队列请参考上一篇文章进来一起把【数据结构】的【栈与队列】狠…...
element-ui打包之后图标不显示,woff、ttf加载404
1、bug 起因 昨天在 vue 项目中编写 element-ui 的树形结构的表格,发现项目中无法生效,定位问题之后发现项目使用的 element-ui 的版本是 2.4.11 。看了官方最新版本是 2.15.14,然后得知 2.4.11 版本是不支持表格树形结构的。于是决定升级 el…...

探究零工市场小程序如何改变传统兼职模式
近年来,零工市场小程序正逐渐改变传统的兼职模式,为求职者和雇主提供了一个更为高效、便捷的平台。本文将深入探讨零工市场小程序如何影响传统兼职模式,以及它带来的优势和挑战。 一、背景与挑战 传统的兼职市场往往存在信息不对称的问题&am…...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...

Godot 2D随机地图三大静默故障:黑屏、穿墙、寻路失败的根源与修复
1. 为什么刚上手Godot做2D随机地图就总卡在“生成出来是黑的”“角色穿墙”“房间连不通”这三件事上?如果你是刚从Unity或GameMaker转来Godot,或者第一次用GDScript写程序逻辑的新手,大概率已经在2D随机地图生成这个环节反复摔过跟头——不是…...

3步精通WaveTools:鸣潮全场景性能优化终极指南
3步精通WaveTools:鸣潮全场景性能优化终极指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 开源优化工具WaveTools作为《鸣潮》玩家必备的性能调校助手,通过深度配置优化实现画质…...

ESP32屏幕项目救星:用TFT_eSPI库的Touch_calibrate例程,5分钟搞定LittleVGL触摸校准
ESP32屏幕开发实战:5分钟完成LittleVGL触摸校准的高效方法论 当一块全新的ILI9341XPT2046电阻屏摆在你面前时,大多数开发者会迫不及待地跳进LittleVGL的配置深渊。但真正高效的硬件开发者知道,在编写任何图形界面代码之前,有一个关…...

如何高效使用开源电路仿真工具:CircuitJS1桌面版新手快速入门指南
如何高效使用开源电路仿真工具:CircuitJS1桌面版新手快速入门指南 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circ…...

利用Taotoken多模型聚合能力为AIGC应用提供备选方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken多模型聚合能力为AIGC应用提供备选方案 在构建AIGC内容生成应用时,开发者通常会选择一个主流模型作为服务…...