Linux内核设计与实现第四章学习笔记
文章目录
- Linux内核设计与实现第四章学习笔记
- 具体场景
- Linux调度算法
- 传统的调度
- 公平调度
- 调度的实现
- 时间记账
- 调度器实体
- 虚拟实时
- 进程选择
- 调度器入口
- 睡眠和唤醒
- 抢占和上下文切换
- 用户抢占
- 内核抢占
- 实时调度策略
Linux内核设计与实现第四章学习笔记
进程优先级:Linux中采用了两种不同的优先级返回
- nice值:范围是-20到+19,默认为0,值越大优先级越低
- 实时优先级,越高优先级越高,范围是0到99
任何实时进程的优先级都高于普通的进程,也就是说实时优先级和nice优先级是处于两个不同的范畴
时间片:表明进程在被抢占前所能持续运行的时间,调度策略规定必须有一个默认的时间片,但是这并不好,太长系统的交互性差,太短增大进程切换的处理器消耗。并且IO型进程不需要太多时间片,处理器消耗型则希望越长越好
Linux系统的CFS调度器并没有直接分配时间片到进程,而且将处理器的使用比例给了进程,这个比例会受nice值影响,高nice值低权重,低nice值高权重。
多数操作系统中,是否要将一个进程立刻投入运行(抢占当前进程),完全由进程优先级和是否有时间片决定的。而Linux系统中使用的新的CFS调度器,抢占时机取决于新进程消耗了多少处理器占比,如果消耗的使用比 比当前进程小,则新进程立刻投入运行,抢占当前进程,否则则继续等待
具体场景
假设有以下场景,一个系统有两个可运行的进程,一个文字编辑程序和视频编码程序。文字编辑显然是IO消耗型,因为它大部分时间等待用户的键盘输入。相反,视频编码是处理器消耗型,除了从磁盘上读出原始数据和最后把视频输出外,其他时间都是在对原始数据进程编码。
用户希望按下按键,系统马上就能响应,用户却分辨不出视频编码程序是立刻运行还是半秒钟后才开始,当然,视频编码程序越早完成越好
这样的场景里,理想情况是调度器应该基于文字编辑程序相比于视频编码程序更多的处理器时间,因为它是交互型。因而,在多数操作系统中,上述目标的达成是依赖系统分配给文字编辑器比视频编码程序更多时间片和更高优先级。
Linux则采用不同的方法,不再分配既定的优先级和时间片,而是分配一个处理器比。
如果两个进程是仅有的且又具有相同的nice值,那么它们都会得到50%的处理器使用比,但因为文本编辑器将更多时间用于等待用户输入,因此它们肯定真的用到50%,同时,视频编码程序无疑有机会得到超50%的处理器时间
关键的来了:当文本编辑程序被唤醒时,我们首要目标是确保能在用户输入时马上运行。因而,一旦文本编辑器被唤醒,CFS注意到给它的处理器使用比是50%,但是它实际上却用的非常少,特别是,CFS发送文本编辑器运行实际比视频编码程序少,这种情况下,为了兑现让所有进程公平的承诺,CFS会立刻抢占视频编码程序,让文本编辑程序投入运行。文本编辑程序运行以后,处理掉用户的输入,有一次进入睡眠等待用户下一次输入。
因为文本编辑程序并没有消费承诺给它的50%处理器使用比,因此情况依旧,CFS总是会毫不犹豫地让文本编辑程序在需要的时候投入运行,视频处理程序只能在剩下的时间运行
Linux调度算法
Linux调度器是以模块方式提供的,这样做的目的是允许不同类型的进程可以针对性的选择调度算法
这种模块化结构被称之为调度器类,它允许多个不同的可动态添加的调度器算法并存,调度属于自己范畴的进程,每个调度器都有一个优先级,基础的调度器代码定义在kernel/sched.c文件中,他会按照优先级遍历调度器类,然后由调度器类去选择下面要指定哪一个程序
传统的调度
现代进程调度器有两个通用的概念,进程优先级和时间片。时间片是指进程运行多少时间,进程一旦启动就会有一个默认时间片。具有更高优先级的进程将会运行得更频繁,并且时间片也会被赋予得更多。在unix系统上,优先级以nice值输出给用户空间,这点听起来简单,但却有很多问题
第一个问题,若要把nice值映射到时间片,就必须把nice单位值对应到处理器的绝对时间。但这样会导致进程切换无法最优化进行,比如说,假定我们把默认nice值(0)分配给一个进程——对应的是一个100ms的时间片,同时再分配一个最高的nice值(+20)给另一个进程——对应5ms。假定两个进程都可运行,那么默认优先级进程会得到20/21 (105ms中的100)的处理器时间,而低优先级的进程会获得1/21(105ms中的5ms)处理器时间。
再假如,两个同等低优先级的进程,我们希望它们各获得一半的处理器时间,但是每次每个进程只能获得5ms(10ms中的5ms),也就是说,上面的例子105进行一次进程切换,现在却要10ms内两次进程切换
显然这些时间片的分配并不理想,它们是给定nice值到时间片映射与进程运行优先级混合计算的共同作用结果。事实上,高nice值(低优先级)的进程往往是后台进程,且多数是计算密集型,普通优先级的进程更多是前台用户任务
第二个问题,假设我们有两个进程,分别具有不同的优先级,第一个假设nice值只是0,第二个假设是1,它们分别映射到时间片100ms和95ms,那么它们的时间片几乎一样,差别微乎其微。但是如果进程分别被赋予18和19的nice值,则它们分别被映射为10ms和5ms。如果这样,前者比后者获得两倍的处理器时间!不过nice值通常都使用相对值,也就是说,把进程的nice值减小,带来的效果极大取决于nice值的初始值
第三个问题,如果执行nice值到时间片的映射,我们需要能分配一个绝对时间片,并且这个绝对时间片必须能在内核的测试范围内。多数操作系统中,上述要求意味着时间片必须是节拍器的整数倍,但是这么做又引发一些问题。首先最小时间片比如是定时器节拍的整数倍,也就是10ms或1ms的倍数,其次,系统定时器限制了两个时间片的差异:连续的nice值映射到时间片,其差别范围多至10ms,少则1ms。最后,时间片还会随着定时器节拍改变而改变
第四个问题,你可能为了进程能够更快的投入运行,而对新唤醒的进程提升优先级,即使它们的时间片已用完,虽然这种办法能够提升不少交互性能,但是还是有一些例外,比如说给某些特殊的睡眠/唤醒的进程一个玩弄调度器的后门,使得打破公平的原则,损害其他进程的利益
可以把nice值呈几何增长而不是算术增长,这样可以解决问题二
采用新的度量机制把nice值到时间片的映射与定时器节拍分离开,这样可以解决问题三
但是这些方案都避开了本质的问题——分配绝对的时间片引发固定的切换频率
公平调度
CFS出发点基于一个简单的理念:进程调度的效果应该如同系统具备一个理想中的完美的多任务处理器,在这种系统中,每个进程能够获得1/n处理器时间,n是指可运行进程的数量。同时,我们可以调度给它无限小的时间周期,在任何可测量周期内,我们给予n个进程中每个进程同样多的运行时间。
举个例子:
有两个进程,我们先运行一个5ms,另一个亦然,但他们任何一个运行时都占有100%的处理器,在理想情况下,完美的多任务处理器模型应该是这样的:我们能在10ms内同时运行两个进程,它们各自使用处理器的一半
当然,这个只是理想模型,我们无法在一个处理器中真的同时运行多个进程,而且每个进程运行无限小的时间周期也是不对的,因为调度时进程抢占也会有一定的代价:将一个进程换出,另一个换入本身就有消耗,同时还会影响到缓存的效率,所以我们喜欢所有进程只运行一个非常短的周期,并考虑这将带来的消耗
CSF的做法是:允许每个进程运行一段时间、循环轮转、选择运行最少的进程作为下一个运行进程,而不再采用分配给每个进程时间片的做法了。CFS在所有可运行进程总数的基础上计算出一个进程应该运行多久,而不是依靠nice值来计算时间片。
nice值在CFS中被作为进程获得的处理器运行比的权重,更高的nice值(越低的优先级)进程获得更低的处理器使用权重。这是相对默认nice值进程的进程而言的
CFS为完美多任务中的无限小调度周期的近似值设立了一个目标,这个目标称之为:目标延迟,越小的调度周期将带来越好的交互性,同时还引入了时间片的底线,称之为最小粒度,确保每个进程最小获得1ms的运行时间,同时切换进程的消耗被限制在一定范围内
nice值对时间片不再是算术加权而是几何加权,任何nice值对应的相对时间不再是一个绝对值而是处理器的使用比
调度的实现
相关代码位于kernel/shced_fair.c文件中,我们将特别关注四个组成部分:
- 时间记账
- 进程选择
- 调度器入口
- 睡眠和唤醒
时间记账
调度器实体
所有的调度器都必须对进程的运行时间做记账,即使CFS不再有时间片的概念,但是它也必须维护进程运行的时间记账,因为它需要确保每个进程公平分配给它的处理器时间内运行,CFS使用调度器实体结构(定义在<linux/sched.h>中的struct_sched_entity)来追踪进程运行记账
虚拟实时
vruntime变量存放进程的虚拟运行时间,该运行时间的计算是经过所有可运行进程总数的计算,虚拟时间是以ns为单位的,所以vruntime和定时器节拍不再相关。虚拟运行时间可以帮助我们逼近理想模型,显然相同优先级的进程的虚拟运行时间都是相同的,当然处理器无法实现完美的多任务,它必须依次运行每个任务,因此CFS使用vruntime变量来记录一个程序到底运行了多长时间以及它应该再运行多久
定义在kernel/sched.fair.c文件中的update_cur函数实现了记账功能
update_cur()函数计算了当前进程的执行时间,并且将其存放在变量delta_exec中,然后它又将运行时间传递给_update_cur()函数,后者再根据当前进程总数对运行时间进行加权计算,最终将上诉权重值与当前运行进程的vruntime相加
update_cur由系统定时器周期性调用的,无论是在进程处于可运行状态还是被阻塞处于不可运行状态。根据这种方法,vruntime可以准确的测量给定进程的运行时间,而且可以知道谁应该是下一个被运行的进程
进程选择
当CFS需要选择下一个运行进程的时候,它会挑选一个具有最小vruntime的进程,这其实就是CFS调度算法的核心:选择具有最小vruntime的任务,那么剩下的我们只需要关心如何选择最小的vruntime即可
CFS选择红黑树来组织可运行进程队列,并利用其迅速找到最小vruntime值的进程,在linux中,红黑树被称之为:rbtree,他是一个自平衡二叉搜索树
- 挑选下一个任务:有那么一颗红黑树存储了系统中所有可运行进程,其中节点的键值便是可运行进程的虚拟运行时间,CFS只要选择具有最小vruntime的叶子节点,也就是最左侧的叶子节点,实现这一过程的函数称之为:_pick_next_entity(),它定义在kernel/sched_fair.c中。这个函数的返回值便是CFS调度器选择的下一个运行进程,如果该函数返回值是NULL,那么表示没有最左叶子节点,也就是说树中没用任何节点,这种情况下表示系统中没有任何可运行进程,CFS调度器便会选择idle任务运行
值得注意的是:这个函数并不会遍历树找到最左叶子节点,因为该值已经缓存在rb_leftmost字段中
- 向树中加入进程:在进程变为可运行状态(被唤醒)或者是通过fork()调用第一次创建进程时候,CFS会将进程加入红黑树中,以及缓存最左侧叶子节点,enqueue_entity()函数实现了这一切
该函数更新运行时间和其他一些统计数据,然后调用__enqueue_entity()进行繁重的插入操作
- 从树中删除进程:删除动作发生在进程阻塞(变成不可运行状态)或者终止时(结束运行)
其实和红黑树添加进程一样,实际工作由辅助函数_enqueue_entity完成
唯一要注意的是,如果删除的节点是最左侧节点,那么要调用rb_next()按顺序遍历,找到谁是下一个节点
调度器入口
进程调度的主要入口是函数schedule(),它定义在文件kernel/sched.c中,它正是内核其他部分用于调用进程调度器的入口,选择哪个进程可以运行,何时将其投入运行。schedle()通常都需要和一个具体的调度器类相关联,也就是说,他会找到一个最高优先级的调度类——后者需要有自己的可运行队列,然后问后者谁才是下一个该运行的进程。所以,该函数唯一做的重要的事情就是:pick_next_task()(kernel/sched.c),pick_next_task()会以优先级为序,从高到底,依次检查每一个调度器类,并且从最高优先级的调度器类中选择最高优先级的进程
每个调度器类都是先了pick_next_task函数,CFS中的pick_next_task会调用pick_next_entity,该函数会调用__pick_next_entity函数
睡眠和唤醒
- 休眠通过等待队列进行处理,等待队列是由等待某些事件发生的进程组成的简单链表,内核用wake_queu_head_t表示等待队列。等待队列可以通过DECLARE_WAITQUEUE静态创建,也可以由init_waitqueue_head()动态创建,进程把自己放入等待队列并设置成不可运行状态
进程通过执行下面几个步骤把自己加入一个等待队列中:
- 调用宏DEFINE_WAIT创建一个等待队列的项
- 调用add_wait_queue把自己加入到队列中,该队列会在进程等待的条件满足时唤醒它,所以我们必须在某个地方撰写相关代码,在事件发生的时候,对等待队列执行wake_up操作
- 调用prepare_to_wait方法把进程状态变更为TASK_INTERRUPTIBLE或者TASK_UNINTERRUPTIBLE。而且该进程如果有必要的话会把进程加回到等待队列中
- 如果状态被设置为TASK_INTERRUPTIBLE,则信号唤醒进程,这就是所谓的伪唤醒,因此检查并处理信号
- 当进程被唤醒的时候,它会再次检查条件是否为真,如果是,就退出循环,如果不是,它再次调用schedule并一直重复这步操作
- 当条件满足后,进程将自己设置为TASK_RUNNING并调用finish_wait函数把自己移出等待队列
函数inotify_read,位于文件fs/notify/inotify/inotify_user.c文件中,负责从文件描述符中读取信息
唤醒操作通过调用wake_up函数进程,他会唤醒等待队列上的所有进程,它调用函数try_to_wake_up,该函数负责将进程设置为TASK_RUNNING状态,调用enqueue_task将此进程放入红黑树中,如果被唤醒的进程优先级比当前正在执行的进程的优先级高,还要设置need_resched标志,通常哪一段代码促使等待条件达成,他就要负责随后调用wake_up函数,比如说:当磁盘数据到来时,VFS就要负责对等待队列调用wake_up函数,以便唤醒队列中等待这些数据的进程
值得注意的是:存在虚假的唤醒,有时候进程被唤醒并不是因为它所等待的条件达成了
抢占和上下文切换
上下文切换,也就是从一个可执行进程切换到另一个可执行进程,由dkernel/sched.c中的context_switch函数负责,每当一个新的进程被选处理准备投入运行的时候,schedule()函数就会调用此函数,它完成两项基本的任务
- 调用声明在<asm/mmu_context.h>中的switch_mm(),该函数负责把虚拟内存从上一个进程映射切换到新进程中
- 调用声明在<asm/sysytem.h>中的switch_to()函数,该函数负责从上一个进程处理器状态切换到新进程的处理器状态,这包括保存、恢复栈信息和寄存器信息。还有其他任何与体系相关的状态信息,都必须以进程为对象进程管理和保存
内核必须知道什么时候调用schedule(),如果仅靠用户程序显式的调用schedule,他们可能就会永远执行下去。所以,内核提供一个need_resched标志表明是否需要重新执行一次调度,当某个优先级高的进程进入可执行状态的时候,try_to_wake_up也会设置这个标志,内核检查该标志,确认其被设置,调用schedule()来切换一个新的进程,该标志对内核来说表示尽快调用调度程序
| 函数 | 目的 |
|---|---|
| set_task_need_resched() | 设置指定进程中的need_resched标志 |
| clear_tsk_need_resched() | 清楚指定进程中的need_reschedule标志 |
| need_reschedule | 检查need_reschedule标志的值,如果被设置就返回真,反之返回假 |
再返回用户空间以及从中断返回的时候,内核也会检查need_resched标志
每一个进程都包含这个标志,这是因为访问进程描述符内的数值要比访问一个全局变量快(因为current宏速度很快并且描述符通常都在高速缓存中)
用户抢占
内核即将返回用户空间的时候,如果need_reschedule标志被设置,那么会调用schedule,此时就会发生用户抢占,所以内核无论再中断处理处返回还是再系统调用后返回,都会检查need_resched标志,如果它被设置,那么内核会选择一个其他的进程投入运行。
也就是说,用户抢占再以下情况下发生:
- 从系统调用返回用户空间时
- 从中断处理程序返回用户空间时
内核抢占
只要重新调度是安全的,内核就可以再任何时间抢占正在执行的任务
那么,什么时候重新调度才是安全的呢?只要没有持有锁,内核就可以进行抢占,锁是非抢占区域的标志
为了支持内核抢占所作的第一处改动就是为每个进程thread_info引入preempt_count计数器,该计数器初始值为0,每当使用锁的时候,数值+1,释放锁的时候数值-1,当数值为0表示可以抢占。从中断返回内核空间的时候,内核会检查need_reschedule标志和preemmpt_count的值,如果need_reschedule被设置,并且preempt_count为0的话,这说明有一个更为重要的任务需要执行并且可以安全的抢占。如果此时prermpt_count不为0,说明当前任务持有锁,抢占就是不安全的,此时内核就会像通常一样从中断处返回当前执行进程。
如果内核中的进程都被阻塞了,或它显式的调用schedule,内核抢占也会显式的发生
所以,内核抢占会发生在:
- 中断处理程序证字啊执行且返回内核空间之前
- 内核代码再一次具有可抢占性的时候
- 如果内核中的任务显式调用schedule
- 内核中的任务被阻塞,(其实也是因为被阻塞会显式调用schedule)
实时调度策略
Linux提供了两种实时调度策略,SCHED_FIFO, SCHED_RR。普通的、非实时的调度策略是SCHED_NORMAL。借助调度器的框架,这些实时策略并不被完全公平策略来管理,而是被一个特殊的实时调度器管理
FIFO:一旦一个FIFO进程处于可运行状态,就会一直执行,知道它自己受阻塞或者显式的释放处理器为止,它不基于时间片,可以一直执行下去,只有更高优先级的FIFO或者RR才能抢占它
RR也类似
这两种实时算法都是静态优先级的
相关文章:

Linux内核设计与实现第四章学习笔记
文章目录Linux内核设计与实现第四章学习笔记具体场景Linux调度算法传统的调度公平调度调度的实现时间记账调度器实体虚拟实时进程选择调度器入口睡眠和唤醒抢占和上下文切换用户抢占内核抢占实时调度策略Linux内核设计与实现第四章学习笔记 进程优先级:Linux中采用…...
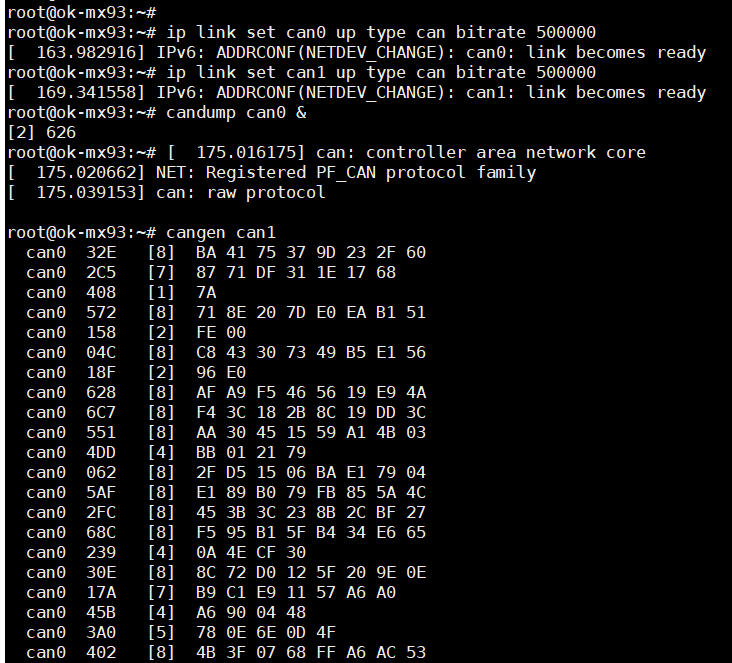
i.MX9352——介绍一款多核异构开发板
本篇来介绍一款多核异构的Linux开发板——OK-MX9352-C开发板。 1 开发板硬件介绍 OK-MX9352-C开发板由核心板和底板组成,核心板采用处理器芯片为NXP的i.MX9352,这是一款多核异构的芯片,核心板基础配置如下 CPU:2Cortex-A551.5G…...
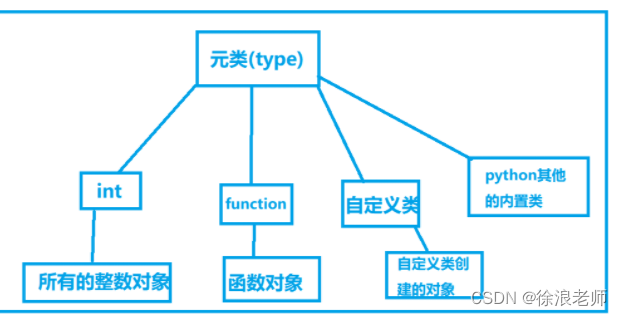
【Python】一文学会面向对象?当然可以的
文章目录前言一、万物皆对象二、类也是对象三,元类总结前言 在大家学习python的时候,一定听说过一句话: 在我们python中万物皆对象,不管是整数、字符串、列表、字典这些基本数据类型,还是函数、以及自定义类创建出来…...

ElasticSearch - SpringBoot整合ES:精确值查询 term
文章目录00. 数据准备01. ElasticSearch 结构化搜索是什么?02. ElasticSearch 结构化搜索方式有哪些?03. ElasticSearch 全文搜索方式有哪些?04. ElasticSearch term 查询数字?05. ElasticSearch term 查询会不会计算评分…...

【GPT4】微软对 GPT-4 的全面测试报告(2)
欢迎关注【youcans的GPT学习笔记】原创作品,火热更新中 微软对 GPT-4 的全面测试报告(1) 微软对 GPT-4 的全面测试报告(2) 【GPT4】微软对 GPT-4 的全面测试报告(2)2. 多模态与跨学科的组合&…...
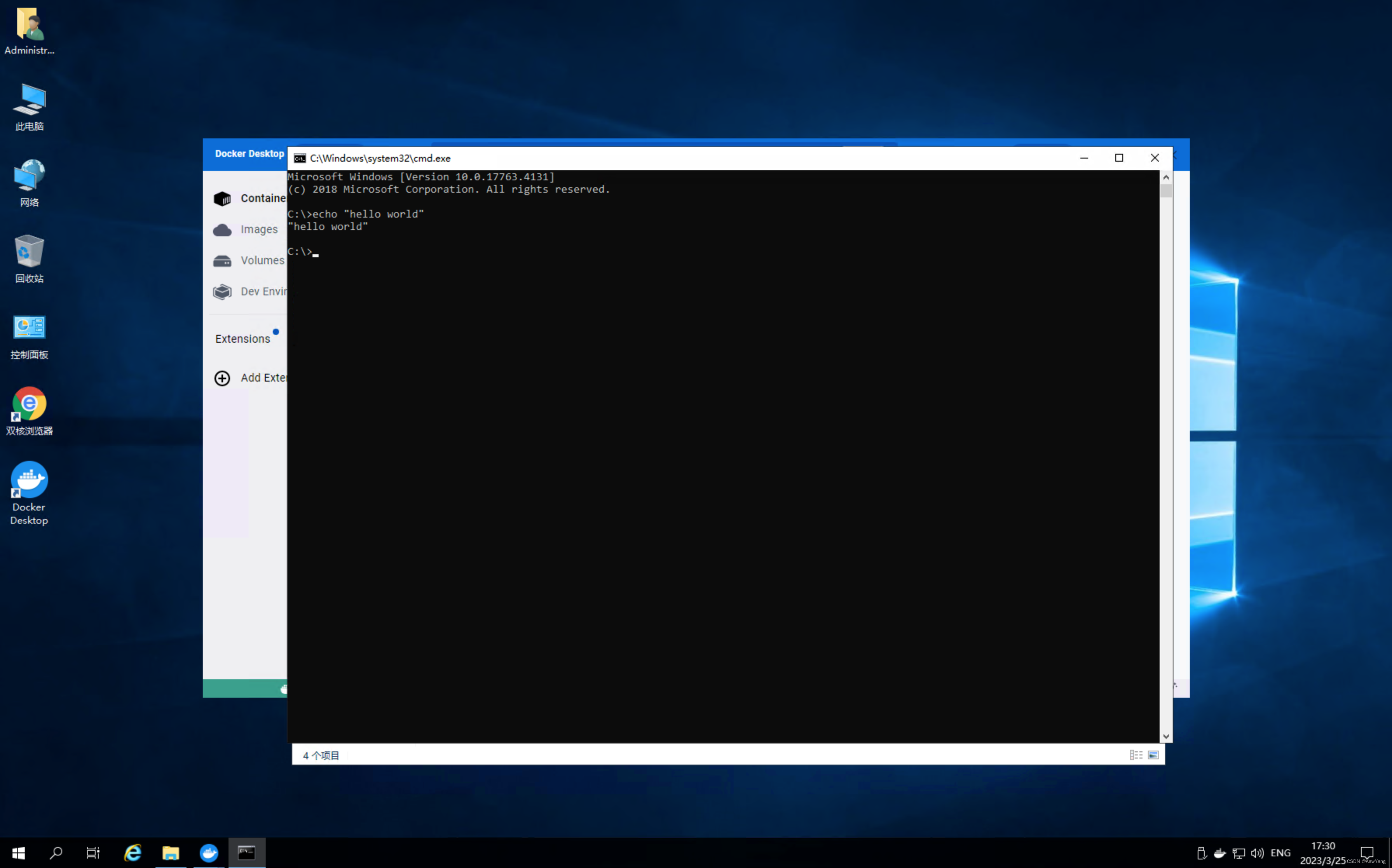
Docker打包exe运行环境
Docker打包exe运行环境 本文运行环境 Window安装Docker环境 修改配置 点击Switch to Window containers OS/Arch 变为 windows/amd64 拉取window镜像 访问Nano Server找到需要的Window版本拉取镜像 运行镜像测试 进入到容器内部 其他内容就自由发挥啦~~ 参考内容…...
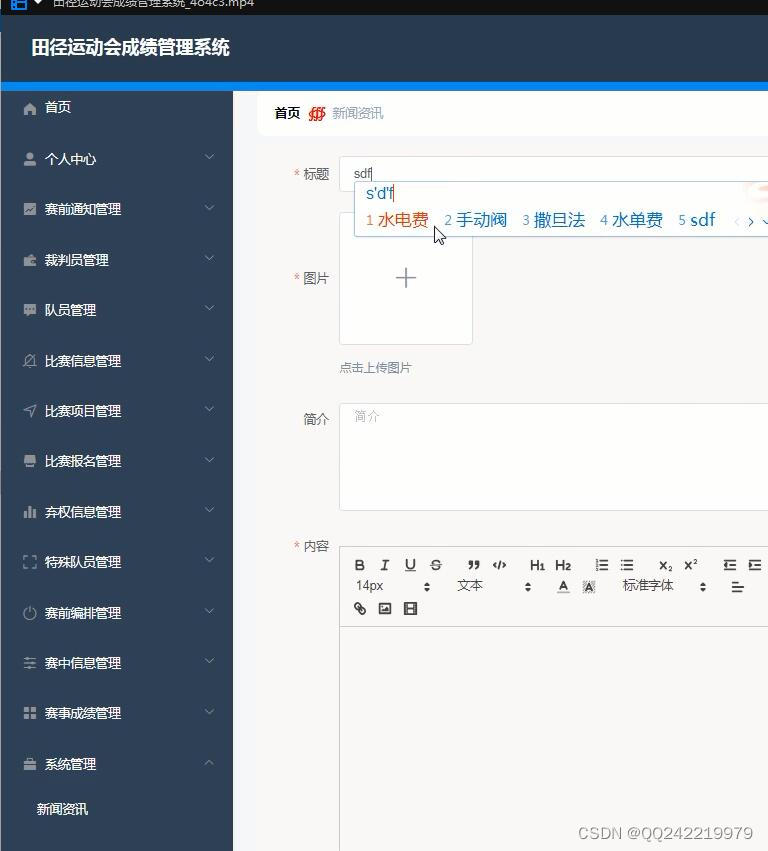
springboot+vue田径运动会成绩管理系统java
springboot是基于spring的快速开发框架, 相比于原生的spring而言, 它通过大量的java config来避免了大量的xml文件, 只需要简单的生成器便能生成一个可以运行的javaweb项目, 是目前最火热的java开发框架 田径运动会成绩管理系统,主要的模块包括首页、个人中心、赛…...

我能“C”——详解操作符(上)
目录 1.操作符的分类: 2. 算数操作符 3.移位操作符 4.位操作符 5.赋值操作符 6.单目操作符 7.关系操作符 8.逻辑操作符 THE END 1.操作符的分类: 操作符也叫运算符 算术操作符 移位操作符 位操作符 赋值操作符 单目操作符 关系操作符 逻辑…...

第一章Vue基础
文章目录前端发展史前端三要素JavaScript框架UI框架JavaScript构建工具三端合一什么是VueVue的好处什么是MVVM为什么要使用MVVM环境配置第一个Vue程序声明式渲染模板语法绑定样式数据绑定为什么要实现数据的双向绑定el与data的两种写法条件渲染事件驱动事件的基本用法事件修饰符…...

【虚幻引擎UE】UE5核心效率插件推荐
一、UnrealEditorPythonScripts (基于UE5 的Python支持插件) 支持Python语言基于UE5进行开发 GIT地址:https://github.com/mamoniem/UnrealEditorPythonScripts 二、Haxe-UnrealEngine5 (基于UE5 的Haxe支持插件) Haxe是一门新兴的开源编程语言,是一种开源的编程语言。…...

记录丨阿里云校招生的成长经历
为了帮助大家更好地了解阿里云云原生应用平台团队同学的成长路径,我们采访了6位各个时间点加入阿里云的学长学姐们,希望他们的经历可以帮助到大家。 经历分享 钰诚丨2022年加入阿里云,校招 大家好,我叫钰诚,目前刚来…...
蓝桥杯第14天(Python版)
并查集的使用# 并查集模板 N400 fa[] def init(): # 初始化,默认自身为根接点for i in range(N):fa.append(i)def merge(x,y): # 发现可以合并,默认选x的根节点为根接点fa[find(x)]find(y)def find(x): # 相等就是根结点,不然就递归查找根…...
双指针常用方法
1.双指针介绍 双指针是解题时一种常见的思路,一般有两种用法。 1)两个指针反方向,分别从数组开头和结尾开始移动,例如对有序数组的搜索。 2)两个指针同方向移动,例如快慢指针,都是从数组开头…...

人工智能大模型之ChatGPT原理解析
前言 近几个月ChatGPT爆火出圈,一路狂飙;它功能十分强大,不仅能回答各种各样的问题,还可以信写作,给程序找bug…我经过一段时间的深度使用后,十分汗颜,"智障对话"体验相比,…...

傅里叶谱方法-傅里叶谱方法的原理、快速傅里叶变换及其Matlab程序实现
第 3 章 傅里叶谱方法 本章介绍的求解偏微分方程(组)的方法都包含着周期性边界条件, 尽管周期性边界条件不属于数学物理方法中常见的传统三类边界条件, 但它并不脱离实际。某些科学问题的研究重点不受边界的影响, 如孤子之间的相互作用 (非线性薛定谔方程或 K d V \mathrm{…...
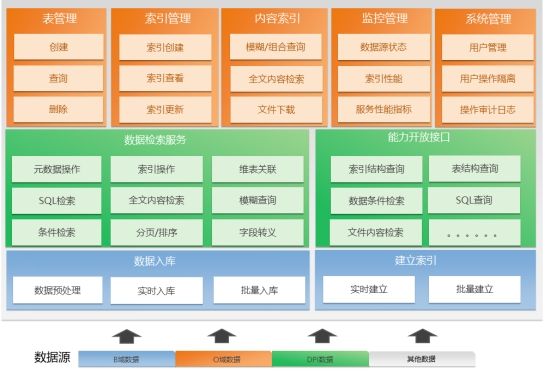
11万字数字政府智慧政务大数据建设平台(大数据底座、数据治理)
本资料来源公开网络,仅供个人学习,请勿商用,如有侵权请联系删除。部分资料内容: 一.1.1 数据采集子系统 数据采集需要实现对全区各委办单位的数据采集功能,包括离线采集、准实时采集和实时采集的采集方式,根…...
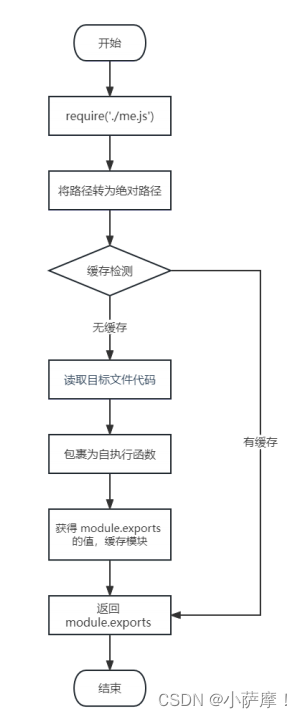
Node.js学习笔记——Node.js模块化
一、介绍 1.1.什么是模块化与模板? 将一个复杂的程序文件依据一定规则(规范)拆分成多个文件的过程称之为模块化。 其中拆分出的每个文件就是一个模块,模块的内部数据是私有的,不过模块可以暴露内部数据以便其他模块…...

【洛谷刷题】蓝桥杯专题突破-广度优先搜索-bfs(12)
目录 写在前面: 题目:P1746 离开中山路 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目描述: 输入格式: 输出格式: 输入样例: 输出样例: 解题思路: 代码: …...
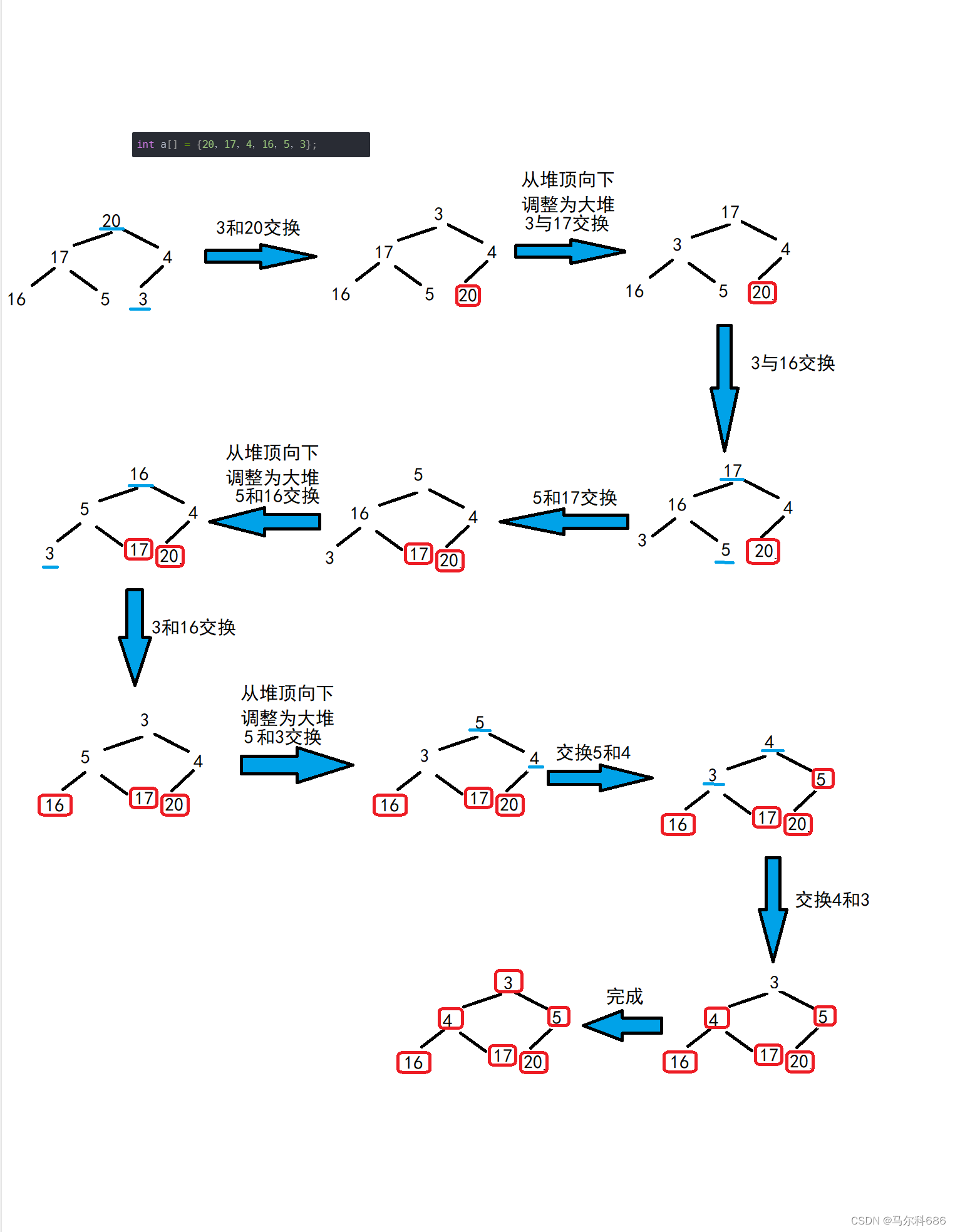
【数据结构】堆(堆的实现 堆向下调整算法 堆的创建 堆的插入 堆的删除 堆的代码实现 堆的应用)
文章目录堆的实现堆向下调整算法堆的创建堆的插入堆的删除堆的代码实现堆的应用堆的实现 堆是属于操作系统进程地址空间内存区域的划分。 我们下面实现数据结构中的堆。 堆是一个完全二叉树:分为小根堆和大根堆。 小根堆:任何一个节点的值都<孩子的…...
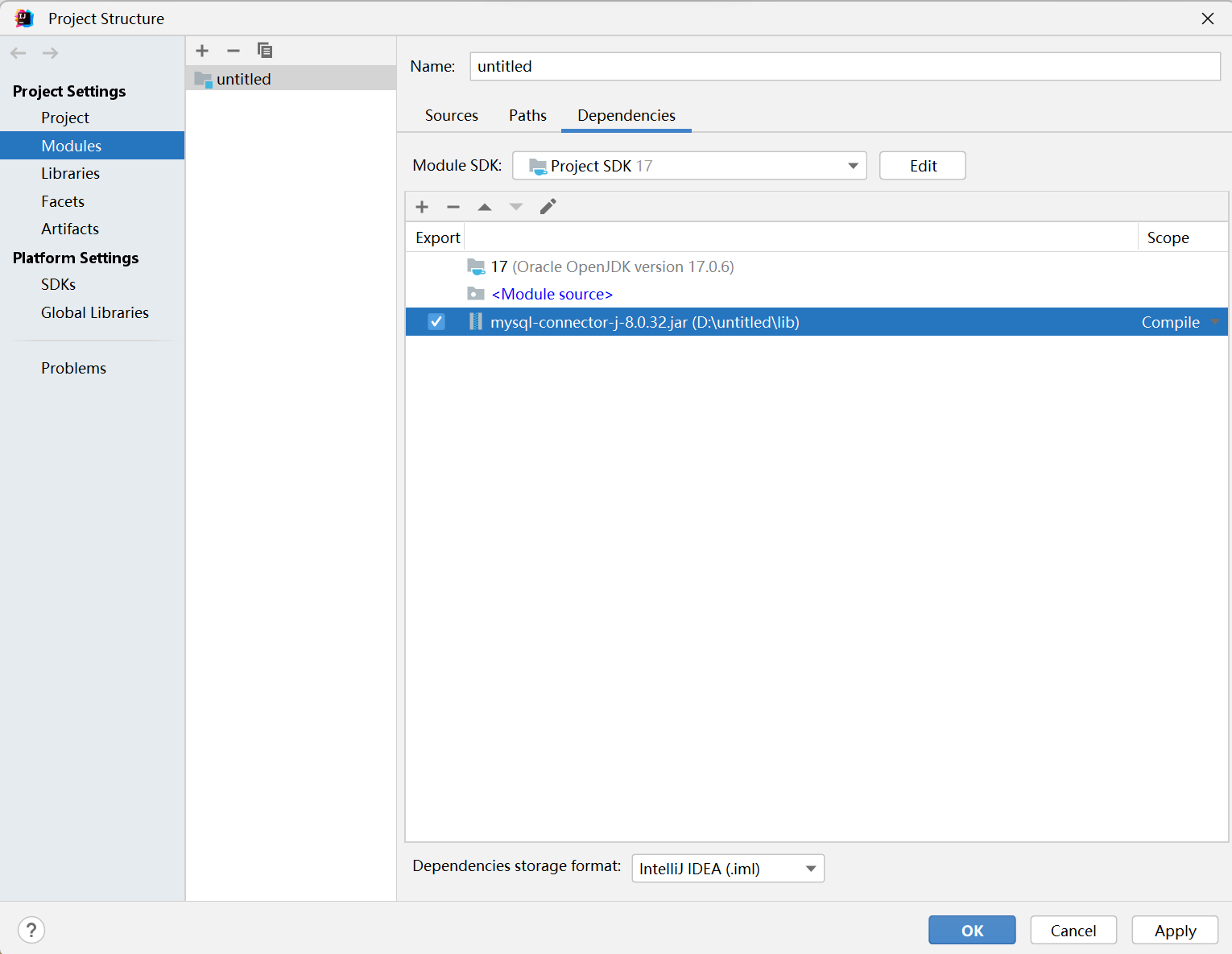
JDBC数据库驱动的下载与安装与连接
目录 JDBC数据库驱动下载 Intellij IDEA安装JDBC驱动 在使用 JDBC 之前,需要下载相应的 JDBC 驱动程序,该驱动程序应该与你使用的数据库的版本相对应。可以在数据库官网上找到相应的 JDBC 驱动程序。 JDBC数据库驱动下载 点击官方链接 MySQL :: MySQ…...

简单三步让Windows焕然一新:Winhance中文版完整优化指南
简单三步让Windows焕然一新:Winhance中文版完整优化指南 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-…...

从公式到代码:傅里叶级数系数的完整推导与实现
1. 从三角函数到傅里叶级数:数学基础回顾 第一次接触傅里叶级数时,我被那一堆积分符号和三角函数搞得头晕眼花。后来才发现,理解它的关键其实藏在高中数学课本里——那些看似简单的三角函数公式,正是打开傅里叶变换大门的钥匙。 让…...
注入失败,除了配置文件还有这8个地方要检查)
SpringBoot新手避坑:@Value(“${xxx}“)注入失败,除了配置文件还有这8个地方要检查
SpringBoot配置注入深度排查:当Value("${xxx}")失效时的8个关键检查点 刚接触SpringBoot的开发者往往会被其"约定优于配置"的理念所吸引,直到在控制台看到那个令人困惑的Could not resolve placeholder错误。这个看似简单的配置问题…...
Translumo终极指南:3个简单技巧掌握实时屏幕翻译
Translumo终极指南:3个简单技巧掌握实时屏幕翻译 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾在游…...

从LED驱动到继电器控制:深入解析NPN与PNP三极管在电路设计中的选型避坑指南
从LED驱动到继电器控制:深入解析NPN与PNP三极管在电路设计中的选型避坑指南 在电子电路设计中,三极管作为基础却关键的元件,其选型直接影响着电路的可靠性和性能。特别是当我们需要驱动LED、继电器或电机等负载时,NPN与PNP三极管的…...

PX4飞控IMU频率上不去?手把手教你用MAVLink命令和SD卡配置文件,稳定提升到200Hz
PX4飞控IMU频率优化实战:从原理到200Hz稳定配置 引言 在无人机开发领域,IMU数据的高频采集对于飞行控制精度至关重要。许多开发者在使用PX4飞控时都遇到过这样的困扰:默认的50Hz IMU频率无法满足高动态飞行需求,而手动调整后要么…...

MarkFlowy桌面应用打包与发布:Tauri框架实战经验分享
MarkFlowy桌面应用打包与发布:Tauri框架实战经验分享 【免费下载链接】MarkFlowy The AI Markdown Editor 项目地址: https://gitcode.com/gh_mirrors/ma/MarkFlowy MarkFlowy作为一款高性能智能化跨端Markdown编辑器,采用Tauri框架实现了轻量级桌…...

数据与大语言模型融合:从NL2SQL到RAG架构的实践指南
1. 项目概述:当数据遇见大语言模型如果你是一名数据工程师、数据分析师,或者任何需要和数据打交道的开发者,最近肯定被“大语言模型”和“数据智能”这两个词轮番轰炸。我们手里有海量的数据,从结构化的业务表到非结构化的日志、文…...

从手机充电到车载电源:TVS管在消费电子和汽车电子中的实战应用避坑
从手机充电到车载电源:TVS管在消费电子和汽车电子中的实战应用避坑 当你的手机充电器在插拔瞬间冒出火花,或是汽车点火时中控屏幕突然黑屏,背后往往隐藏着一个共同的电子防护难题——瞬态电压冲击。TVS管(瞬态电压抑制二极管&…...

Python-ADB协议实现原理:深入理解ADB和Fastboot通信机制
Python-ADB协议实现原理:深入理解ADB和Fastboot通信机制 【免费下载链接】python-adb Python ADB Fastboot implementation 项目地址: https://gitcode.com/gh_mirrors/py/python-adb Python-ADB是一个强大的开源项目,提供了ADB(Andr…...