Jedis,SpringDataRedis
快速入门
导入依赖
<!--jedis--><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.7.0</version></dependency><!--单元测试--><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>5.7.0</version><scope>test</scope></dependency>测试代码
package com.example;import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;public class JedisTest {private Jedis jedis;@BeforeEachvoid setUp() {jedis = new Jedis("192.168.168.168", 6379);jedis.auth("123456");jedis.select(0);}@Testvoid test() {String name = jedis.get("name");System.out.println(name);}@AfterEachvoid tearDown() {if(jedis != null){jedis.close();}}
}
jedis连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此推荐大家使用Jedis连接池代替Jedis的直连方式。
package com.example.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;public class JedisConnectionFactory {private static JedisPool jedisPool;//在类加载时执行static {JedisPoolConfig poolConfig = new JedisPoolConfig();poolConfig.setMaxTotal(8);//最大连接数poolConfig.setMaxIdle(8);//最大空闲连接数poolConfig.setMinIdle(0);//最小空闲连接数poolConfig.setMaxWaitMillis(1000);//最大等待时间 (单位:毫秒)jedisPool = new JedisPool(poolConfig, "192.168.168.168", 6379, 1000, "123456");}//连接超时时间 1000毫秒public static Jedis getJedis() {return jedisPool.getResource();}
}修改后这样获取jedis对象
@BeforeEachvoid setUp() {jedis = JedisConnectionFactory.getJedis();jedis.auth("123456");jedis.select(0);}SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:Spring Data Redis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
快速入门
导入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency>配置redis
spring:data:redis:host: 192.168.168.168port: 6379password: 123456database: 0lettuce:pool:max-active: 8max-idle: 8min-idle: 0max-wait: 100ms测试
package com.example;import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;@SpringBootTest
public class RedisTemplateTest {@Autowiredprivate RedisTemplate redisTemplate;@Testpublic void test01() {redisTemplate.opsForValue().set("name","lihua");System.out.println(redisTemplate.opsForValue().get("name"));}
}
自定义序列化
jdk序列化(默认的序列化方式)的问题
进行如上测试后,发现并没有修改key为name的值为lihua,而是出现了这样的结果


原因如下
RedisTemplate可以接收任意Object作为值写入Redis:

只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:

缺点:
- 可读性差
- 内存占用较大
***************************************************
自定义序列化方式为json序列化
首先写一个RedisTemplate的配置
package com.example.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;@Configuration
public class RedisTemplateConfig {@Bean//RedisConnectionFactory是spring内置的,在项目启动时会自动装配,因此作为参数传入即可public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {//创建RedisTemplate对象RedisTemplate<String, Object> template = new RedisTemplate<>();//设置连接工厂template.setConnectionFactory(factory);//创建JSON序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();//设置key的序列化 RedisSerializer是redis的一个序列化器template.setKeySerializer(RedisSerializer.string());template.setHashKeySerializer(RedisSerializer.string());//设置value的序列化template.setValueSerializer(jsonRedisSerializer);template.setHashValueSerializer(jsonRedisSerializer);//返回return template;}
}在springboot项目启动时,这个bean就会被加载
重新测试
@Testpublic void test01() {redisTemplate.opsForValue().set("name","zhaosi");System.out.println(redisTemplate.opsForValue().get("name"));}测试结果如下


符合我们的预期
*********************************
也可以存入自定义对象
@Testpublic void test02() {User u1 = new User(1, "laoda", 24);redisTemplate.opsForValue().set("user:001", u1);}@Testpublic void test03() {User user = (User) redisTemplate.opsForValue().get("user:001");System.out.println(user);}测试结果如下


整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。 (我们将用StringRedisTemplate进行改进)
SpringRedisTemplate
为了节省内存空间,我们可以不使用JSON序列化器来处理value,而是统一使用String序列化器(这样value就不用存储对象的字节码文件了),要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。

因为存入和读取时的序列化及反序列化都是我们自己实现的,SpringDataRedis就不会将class信息写入Redis了。
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
导入jackson依赖
<!--Jackson依赖--><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></dependency>省去了我们自定义RedisTemplate的序列化方式的步骤,而是直接使用就好了
@SpringBootTest
public class StringRedisTemplateTest {@Autowiredprivate StringRedisTemplate stringRedisTemplate;private static final ObjectMapper mapper = new ObjectMapper();@Testpublic void test() throws JsonProcessingException {User u1 = new User(2, "赵四", 25);//手动序列化String json = mapper.writeValueAsString(u1);System.out.println("序列化后的json字符串:"+json);//写入数据stringRedisTemplate.opsForValue().set("user:002",json);//获取数据String jsonUser = stringRedisTemplate.opsForValue().get("user:002");//反序列化User user = mapper.readValue(jsonUser, User.class);System.out.println("反序列化得到的结果:"+user);}
}

可以看到,里面是没有对象的字节码的
相关文章:
Jedis,SpringDataRedis
快速入门 导入依赖 <!--jedis--><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.7.0</version></dependency><!--单元测试--><dependency><groupId>org.ju…...

增量模型的优点例题
答案:D 解析:增量模型可以快速开发一个样品供客户查看 选项B 早期的增量作为模型,从而可以加强系统后续需求的理解 一开始给客户一个样本,客户根据样品修改需求 选项C 增量模型就是开发一个个增量模型,供客户使用…...

求绝对值
计算并输出一个实数的绝对值。从键盘任意输入一个实数,不使用计算绝对值函数编程计算并输出该实数的绝对值 输入格式: 输入任一实数。 输出格式: 输出的绝对值包含两位小数。 输入样例: 在这里给出一组输入。例如: -2.5输出样例: 在这里给出相应的输出。…...

AlphaNovel的身份验证失败了..........
我的AlphaNovel的这个身份验证失败了,不知道失败原因是什么... 前两周在网上看到这个项目,在国外这个网站搬运国内小说,但是前提是要通过这个身份验证,可是我等了十多天,结果身份验证失败了,有也在做这个的同志吗? 你们身份验证怎么样...

Sapiens:人类视觉模型的基础
文章目录 摘要1、引言2、相关工作3、方法3.1、Humans-300M 数据集3.2、预训练3.3、二维姿态估计3.4、身体部位分割3.5、深度估计3.6、表面法线估计 4、实验4.1、实现细节4.2、二维姿态估计4.3、身体部位分割4.4、深度估计4.5、表面法线估计4.6、讨论 5、结论 摘要 我们介绍了 …...

“健康中国 医路无忧——公益联盟”积极响应,国内首支公益陪诊师志愿队伍正式成立
在快节奏的现代生活中,就医不再是简单的“看病”那么简单。面对复杂的医疗流程、专业的医学术语、以及在陌生环境中的焦虑,患者及家属往往感到无所适从。此时,陪诊服务如同一束光,照亮了就医之路,它的重要性不仅体现在…...

Java 创建对象方法的演变
1、普通 Java 代码 public class Rectangle {private int width;private int length;public Rectangle() {System.out.println("Hello World!");}public void setWidth(int widTth) {this.width widTth;}public void setLength(int length) {this.length length;}…...

Netty中用到了哪些设计模式
Netty作为一个高性能的网络通信框架,里面有很多优秀的代码值得我们学习,今天我们一起看下Netty中用到了哪些设计模式。 一、单例模式 Netty通过 NioEventLoop 将通道注册到选择器,并在事件循环中多路复用它们。其中提供了一个选择策略对象 S…...

第67期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大语言模型(LLM)等安全领域应用的知识。在这里,您可以找…...

Chrome 浏览器插件获取网页 window 对象(方案三)
前言 最近有个需求,是在浏览器插件中获取 window 对象下的某个数据,当时觉得很简单,和 document 一样,直接通过嵌入 content_scripts 直接获取,然后使用 sendMessage 发送数据到插件就行了,结果发现不是这…...

动态规划-分割回文串ⅡⅣ
在本篇博客中将介绍分割回文串Ⅱ以及分割回文串Ⅳ这两个题目。 分割回文串Ⅱ 题目描述 给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文串。 返回符合要求的 最少分割次数 。 示例: 输入:s "aabac" 输…...

Python编码系列—Python项目维护与迭代:持续进化的艺术
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...
【鸿蒙开发工具报错】Build task failed. Open the Run window to view details.
Build task failed. Open the Run window to view details. 问题描述 在使用deveco-studio 开发工具进行HarmonyOS第一个应用构建开发时,通过Previewer预览页面时报错,报错信息为:Build task failed. Open the Run window to view details.…...

k8s集群部署:容器运行时
1. 卸载旧版本 Docker # 卸载旧版本的 Docker 组件 sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine注释: 该命令会移除系统中现有的 Docker 及其相关组件࿰…...

PHP7 的内核结构
PHP7 是 PHP 语言的一个重要版本,带来了许多性能提升和语言特性改进。要深入了解 PHP7 的内核,我们需要探讨其设计和实现的关键方面,包括 PHP 的执行模型、内存管理、编译和优化过程等。 1. PHP7 的内核结构 1.1 执行模型 PHP 是一种解释型…...
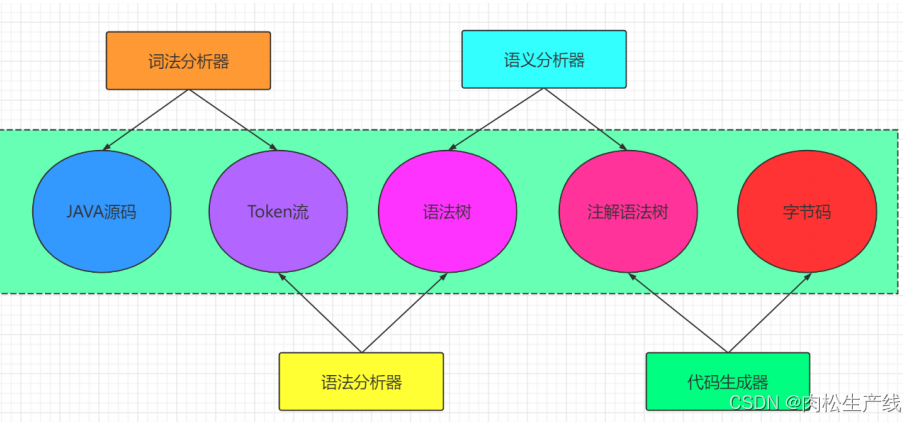
JVM合集
序言: 1.什么是JVM? JVM就是将javac编译后的.class字节码文件翻译为操作系统能执行的机器指令翻译过程: 前端编译:生成.class文件就是前端编译后端编译:通过jvm解释(或即时编译或AOT)执行.class文件时跨平台的,jvm并不是跨平台的通过javap进行反编译2.java文件是怎么变…...
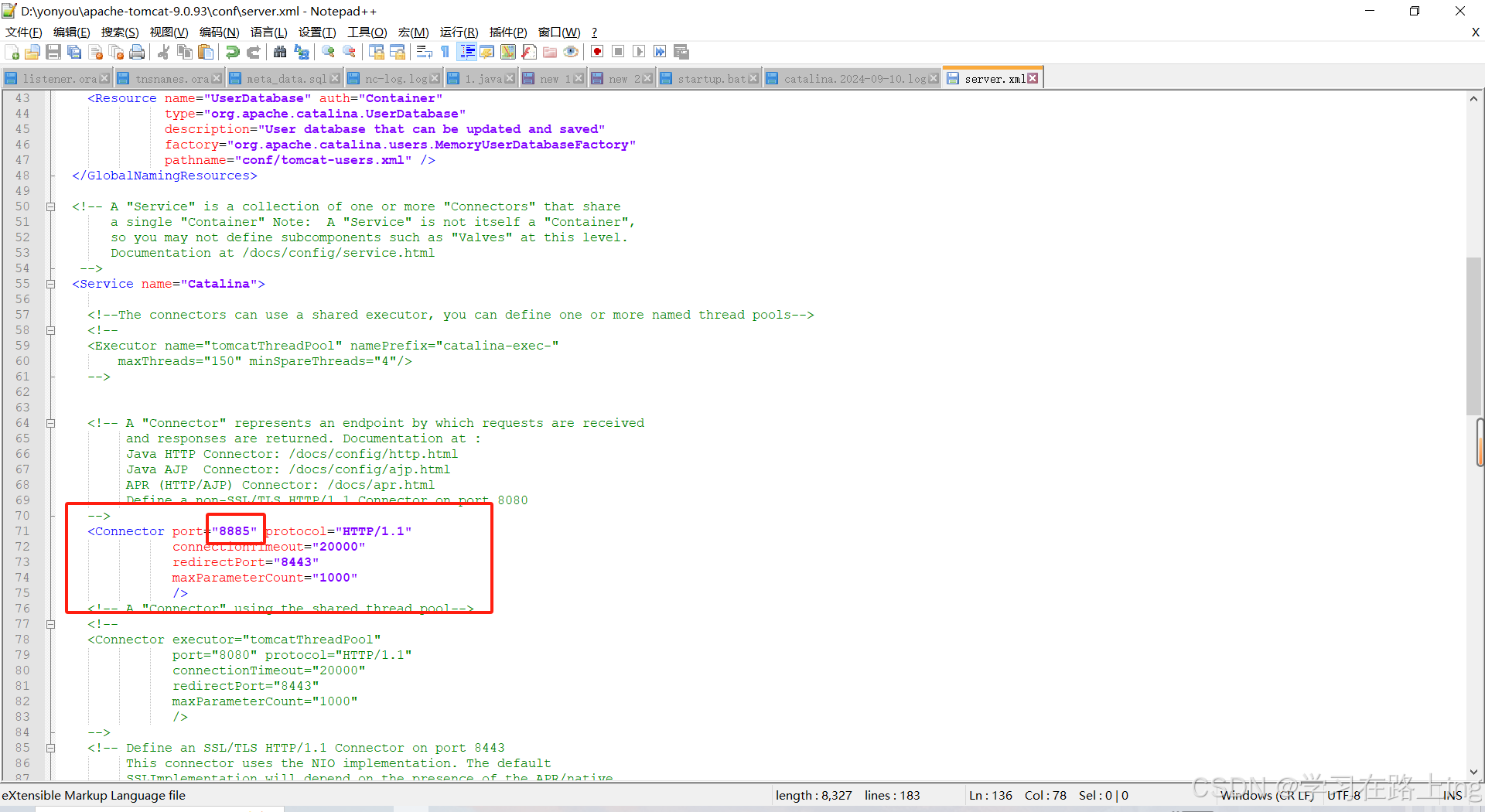
tomcat端口被占用解决方法
在安装目录的conf下修改server.xml文件,修改后保存重启即可...
全新的训练算法:Reflection 70B进入大众的视野
在2024年9月6日,大模型的圈子迎来了一位新成员——Reflection 70B,它横扫了MMLU、MATH、IFEval、GSM8K等知名的模型基准测试,完美超越了GPT-4o,同时也超越了Claude3.5 Sonnet成为了新的大模型之王,Reflection 70B到底是…...

静态标注rtk文件参数解析
目录 在静态标注中,rtk(Real-Time Kinematic)文件的主要作用 rtk文件包含几种类型数据 具体作用 具体示例 %RAWIMUSA #INSPVAXA $GPRMC 背景: 最近工作中涉及到静态标注 slam相关,因为初入门,对于rtk文件中有很多参数&…...

TensorFlow和PyTorch小知识
TensorFlow和PyTorch是当前最流行的两个开源机器学习库,它们都广泛用于研究和工业界的深度学习项目。下面是对它们的介绍: 1,TensorFlow - **开发背景:** TensorFlow最初由Google Brain Team开发,并于2015年11月开源…...

基于WPF开发桌面AI助手:架构设计与实现详解
1. 项目概述:一个开源的WPF桌面AI助手 最近在GitHub上看到一个挺有意思的项目,叫“MayDay-wpf/AIBotPublic”。光看名字,可能有点摸不着头脑,但点进去研究一下,你会发现这其实是一个用WPF(Windows Present…...

快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南
快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾在网易云音乐下载了心爱的歌曲&am…...

生物信息学逆向解析mRNA疫苗序列:从公开数据组装BNT-162b2与mRNA-1273的基因蓝图
1. 项目概述与背景解析 最近在生物信息学和疫苗研究领域,一个名为“NAalytics/Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-sequences-for-vaccines-BNT-162b2-and-mRNA-1273”的项目引起了我的注意。这个项目标题看起来很长,但核心非常明确&…...

Python与ChatGPT构建智能办公自动化:从任务分解到智能体系统
1. 项目概述:用Python与ChatGPT联手,让办公自动化“开口说话”如果你每天还在重复着打开Excel、复制粘贴数据、手动写邮件、整理报告这些枯燥的活儿,那这个项目可能就是你的“数字员工”入职通知书。Sven-Bo/automate-office-tasks-using-cha…...

Supabase AI Agent技能库:安全集成数据库操作与边缘函数调用
1. 项目概述:当Supabase遇上AI Agent,一个技能库的诞生最近在捣鼓AI Agent应用开发,发现一个挺有意思的现象:大家都能用LangChain、LlamaIndex这些框架快速搭出个Agent的架子,但真想让这个Agent去干点具体、有用的活儿…...

AI驱动命令行工具:用自然语言自动化开发任务
1. 项目概述:一个为开发者“下厨”的AI助手如果你是一名开发者,每天在终端里敲打命令,构建、部署、调试,那么你肯定对重复性的命令行操作感到厌倦。比如,每次启动一个新项目,都要手动创建目录结构、初始化G…...

阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程
阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本OAS是一款专门为《阴阳师》游戏设计的智能自动…...

UVa 366 Cutting Up
题目描述 拼布者经常需要将布料切割成 111 \times 111 的小正方形。他们有一种特殊工具(旋转切割刀),可以一次切割多层布料,切割层数的上限由布料类型决定(题目输入的第一个参数 KKK)。切割时,无…...

基于AutoHotkey的Windows桌面自动化工具开发实战
1. 项目概述与核心价值最近在整理个人项目库时,翻到了一个挺有意思的“老伙计”——cua_desktop_operator_skill。这个项目名听起来有点拗口,直译过来是“CUA桌面操作员技能”。乍一看,可能会让人联想到某种工业控制台的专用软件。但实际上&a…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...