大数据技术架构(组件)33——Spark:Spark SQL--Join Type
2.2.2、Join Type
2.2.2.1、Broadcast Hash Join (Not Shuffled)
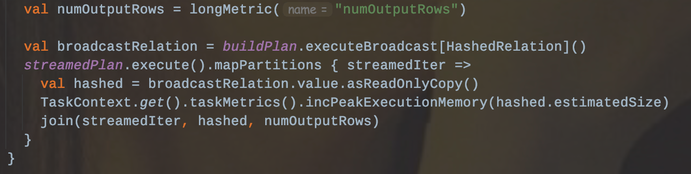
就是常说的MapJoin,join操作在map端进行的。
场景:join的其中一张表要很小,可以放到Driver或者Executor端的内存中。
原理:
1、将小表的数据广播到所有的Executor端,利用collect算子将小表数据从Executor端拉到Driver端,然后在Driver端使用广播到Executor端
2、Executor端将大表和这个广播数据进行Join,这样就避免了Shuffle.
条件:
1、小表必须足够小,可以通过spark.sql.autoBroadcastJoinThreshold参数来设置,默认是10MB。如果设置为-1,则关闭Broadcast Hash Join
2、只能用于等值Join,不要求参与Join的keys排序
3、除了full outer join,支持其他所有Join
4、人为添加Hint(MAPJOIN、BROADCASTJOIN、BROADCAST) (Option)
2.2.2.2、Broadcast Nested Loop Join (Fallback option)
该Join策略是在没有合适的Join机制可以选择的时候,最后选择的一种。在Cartesian和Broadcast Nested Loop Join之间,如果是内连接,或者是非等值连接,那么会优先选择Broadcast Nested Loop策略。该类型Join会根据相关条件对小表进行广播,以减少表的扫描次数。触发条件:
1、Rigth Outer Join是会广播左表
2、Left Outer,Left semi ,Left Anti或者existence Join会广播右表
3、inner join的时候两张表都会广播
条件:
支持等值和非等值Join。
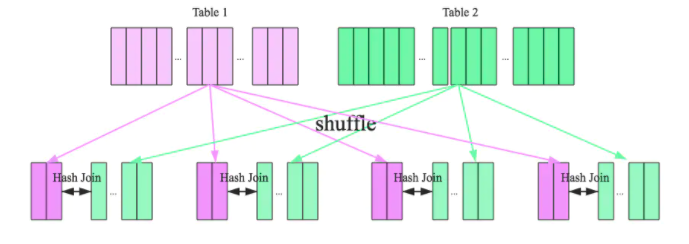
2.2.2.3、Shuffle Hash Join(Single Partition is small engough to build a hash table)
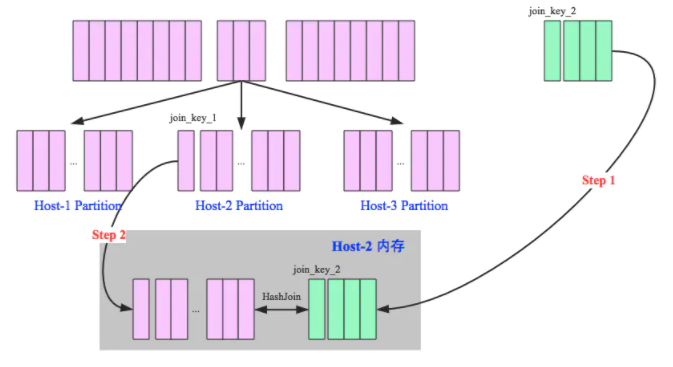
当Join一张小表的时候,可以使用Broadcast Hash Join,但是如果小表逐渐变大,那么广播所需要的内存、网络IO资源也相应变大,所以如果小表的数据量超过了10M的限制,那么可以使用Shuffle Hash Join策略。
原理:(Key相同,分区必然相同)
1、Shuffle:大表和小表按照相同分区算法和分区数进行分区(根据参与join的keys进行分区),这样保证了hash值一样的数据都被分发到了同一个分区中,然后在同一个Executor中两个表hash值一样的分区就可以进行本地hash join了。
2、单机Hash Join:在进行join之前,还会对小表hash完的分区构建hash map。shuffle hash join采用了分治思想,把大问题拆解成小问题去解决
条件:
1、仅支持等值join,不要求参与join的keys排序
2、spark.sql.join.preferSortMergeJoin 参数必须设置为 false,参数是从 Spark 2.0.0 版本引入的,默认值为 true,也就是默认情况下选择 Sort Merge Join
3、小表的大小(plan.stats.sizeInBytes)必须小于 spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions;而且小表大小(stats.sizeInBytes)的三倍必须小于等于大表的大小(stats.sizeInBytes),也就是 a.stats.sizeInBytes * 3 < = b.stats.sizeInBytes

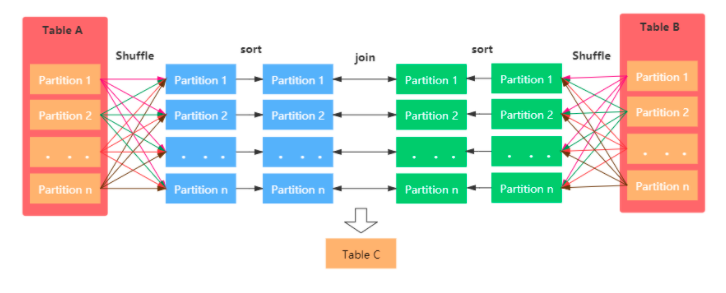
2.2.2.4、Shuffle Sort Merge Join (Matching join keys are sortable)
Hash Join通常适用于存在至少一个小表的情况,但如果都是大表的话,那么就需要考虑Sort Merge Join了。该Join策略是Spark默认的,可以通过spark.sql.join.preferSortMergeJoin进行配置(默认就是true)
原理:
1、Shuffle阶段:对两个表参与Join的keys使用相同的分区算法和分区数进行分区,目的就是为了保障相同的key都分配到相同的分区里面
2、Sort阶段:分区之后再对每个分区按照参与keys进行排序
3、Merge阶段:最后reducer端获取两张表相同分区的数据基于顺序查找的方式进行Merge Join,如果keys相同就说明join上了。如果流表的迭代遍历器得到的Key值比构建表迭代得到的Key值小,那么就移动流表的迭代器;如果流表的迭代遍历器比构建表迭代得到的Key值要大,那么则移动构建表的迭代器;如果二者相同,则说明满足Join条件。
条件:
仅支持等值join,而且要求参与join的keys是可排序的
2.2.2.5、Cartesian Product Nested Loop Join
如果Spark中多个表参与Join而且没有指定Key,那么就会产生Cartesian Product Join。
产生的数据行数是两表的乘积,当Join的表很大的时候,效率是非常低的。尽量不使用
条件:
1、必须是inner join,支持等值和不等值Join
2、参数spark.sql.crossJoin.enabled=true
2.2.2.6、Conclusion
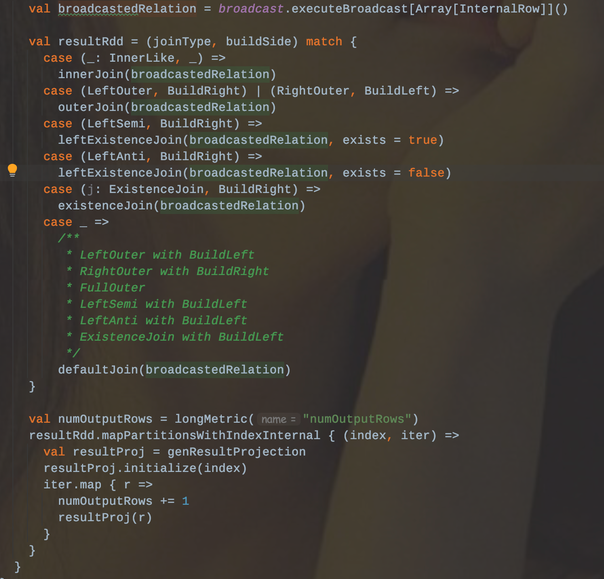
Spark2.4 + 引入了Join Hint,来优化spark的计算引擎,从而选择正确的Join策略。当然用户也可以手动选择策。用户指定的Join Hint优先级是最高的。逻辑如下:
1、先判断是不是等值Join
1.1、判断用户是否指定了BroadCast Hint(Broadcast、BroadcastJoin以及MapJoin中的一个),如果指定了则用Broadcast Hash Join。
1.2、判断用户是否指定了Shuffle Merge Hint(Shuffle_Merge,Merge以及MergeJoin中的一个),如果指定了则用Shuffle Sort Merge。
1.3、判断用户是否指定了Shuffle Hash Join Hint(SHUFFLE_HASH),如果指定了则用Shuffle Hash Join。
1.4、判断用户是否指定了Shuffle-and-replicate Nested Loop Join(SHUFFLE_REPLICATE_NL),如果指定了则用Cartesian Product Join。
1.5、如果用户没有指定任何Join Hint,那么就根据Join的策略Broadcast Hash Join ---> Shuffle Hash Join --> Sort Merge Join ---> Cartesian Product Join --> Broadcast Nested Loop Join顺序选择Join策略。
2、如果不是等值Join,则按照下面的顺序选择Join策略
2.1、判断用户是不是指定了 BROADCAST hint (BROADCAST、BROADCASTJOIN 以及 MAPJOIN 中的一个),如果指定了,那就广播对应的表,并选择 Broadcast Nested Loop Join;
2.2、用户是不是指定了 shuffle-and-replicate nested loop join hint (SHUFFLE_REPLICATE_NL),如果指定了,那就用 Cartesian product join;
2.3、如果用户没有指定任何 Join hint,那根据 Join 的适用条件按照 Broadcast Nested Loop Join--->Cartesian Product Join 顺序选择 Join 策略
相关文章:
大数据技术架构(组件)33——Spark:Spark SQL--Join Type
2.2.2、Join Type2.2.2.1、Broadcast Hash Join (Not Shuffled)就是常说的MapJoin,join操作在map端进行的。场景:join的其中一张表要很小,可以放到Driver或者Executor端的内存中。原理:1、将小表的数据广播到所有的Executor端,利用collect算子…...

Linux: bash起后台进程引发的僵尸进程
1. 前言 限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。 2. 案例 原来的故事是 这样 的,感兴趣的读者可以直接前往。我从中截取了一段重现故事中问题的代码(对原代码做了小小调整&a…...
网络安全攻防中,Rock-ON自动化的多功能网络侦查工具,Burpsuite被动扫描流量转发
网络安全攻防中,Rock-ON自动化的多功能网络侦查工具,Burpsuite被动扫描流量转发。 #################### 免责声明:工具本身并无好坏,希望大家以遵守《网络安全法》相关法律为前提来使用该工具,支持研究学习ÿ…...
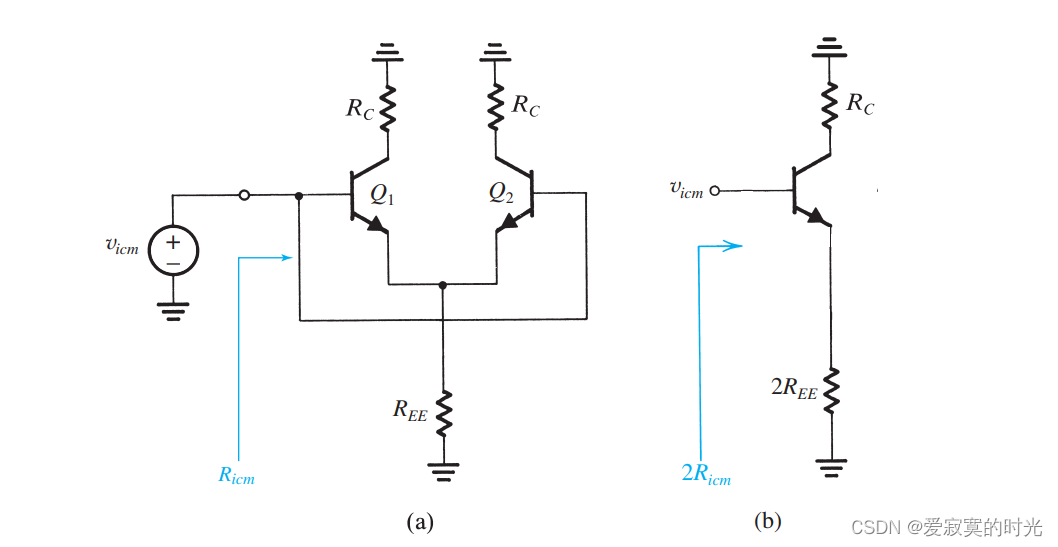
电子技术——共模抑制
电子技术——共模抑制 我们在之前学习过,无论是MOS还是BJT的差分输入对,共模信号并不会改变漏极电流的大小,因此我们说差分输入对共模信号无响应。但是实际上由于各种客观非理想因素,例如电流源有限阻抗等,此时共模是影…...

对KMP简单的理解
声明:下边的例子均表示下标从1开始的数组 ne数组的定义: next[i] 就是使子串 s[1…i] 有最长相等前后缀的前缀的最后一位的下标。ne[i]也可以表示相等子串的长度 准备执行jne[j]时, 表示当前s[i]!p[j1] , 如果ne[j]1 ,那么下…...

Hibernate不是过时了么?SpringDataJpa又是什么?和Mybatis有什么区别?
一、前言 ps: 大三下学期,拿到了一份实习。进入公司后发现用到的技术栈有Spring Data Jpa\Hibernate,但对于持久层框架我只接触了Mybatis\Mybatis-Plus,所以就来学习一下Spring Data Jpa。 1.回顾MyBatis 来自官方文档的介绍:MyBatis 是一款…...
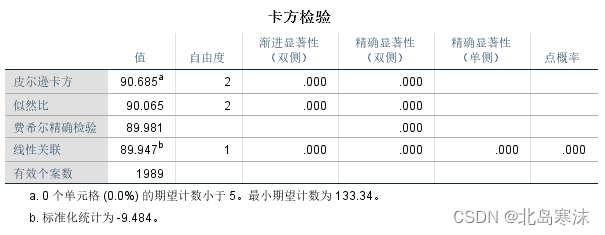
数学建模拓展内容:卡方检验和Fisher精确性检验(附有SPSS使用步骤)
卡方检验和Fisher精确性检验卡方拟合度检验卡方独立性检验卡方检验的前提假设Fisher精确性检验卡方拟合度检验 卡方拟合度检验概要:卡方拟合度检验也被称为单因素卡方检验,用于检验一个分类变量的预期频率和观察到的频率之间是否存在显著差异。 卡方拟…...

【Python学习笔记之七大数据类型】
Python数据类型:Number数字、Boolean布尔值、String字符串、list列表、tuple元组、set集合、dictionary字典 int整数 a1 print(a,type(a))float浮点数 b1.1 print(b,type(b))complex复数 c100.5j print(c,type(c))bool布尔值:True、False,true和false并非Python…...

Android系统之onFirstRef自动调用原理
前言:抽丝剥茧探究onFirstRef究竟为何在初始化sp<xxx>第一个调用?1.onFirstRef调用位置<1>.system/core/libutils/RefBase.cpp#include <utils/RefBase.h>//1.初始化强指针 void RefBase::incStrong(const void* id) const {weakref_i…...
ipv6上网配置
一般现在的宽带都已经支持ipv6了,但是需要一些配置才能真正用上ipv6。记录一下配置过程。 当前测试环境为移动宽带,光猫下面接了一个路由器,家里所有的设备都挂到这个路由器下面的。 1. 光猫改桥接 光猫在使用路由模式下,ipv6无…...

python实现聚类技术—复杂网络社团检测 附完整代码
实验内容 某跆拳道俱乐部数据由 34 个节点组成,由于管理上的分歧,俱乐部要分解成两个社团。 该实验的任务即:要求我们在给定的复杂网络上检测出两个社团。 分析与设计 实验思路分析如下: 聚类算法通常可以描述为用相似度来衡量两个数据的远近,搜索可能的划分方案,使得目标…...
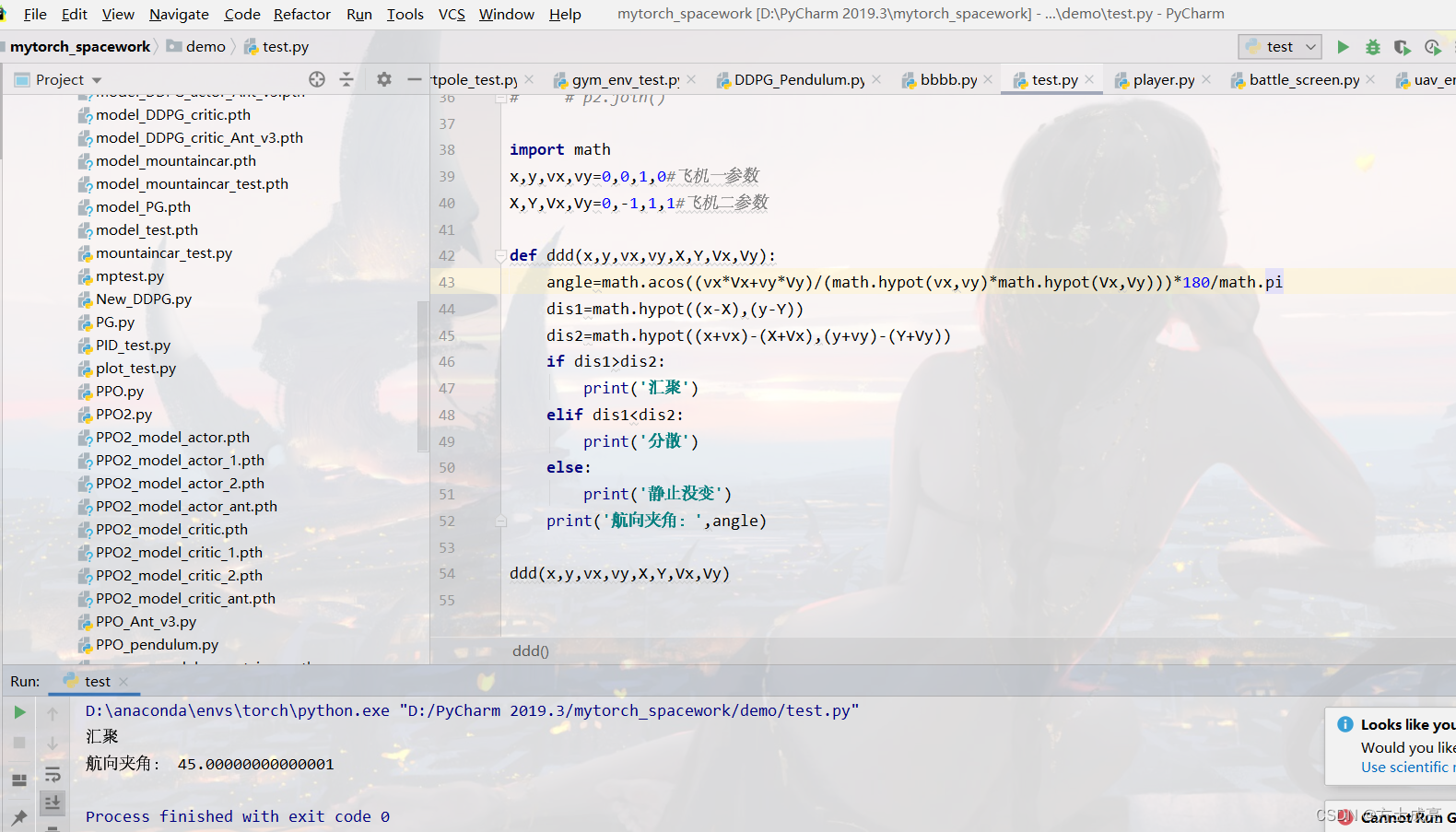
如何判断两架飞机在汇聚飞行?(如何计算两架飞机的航向夹角?)内含程序源码
ok,在开始一切之前,让我先猜一猜,你是不是想百度“二维平面下如何计算两个移动物体的航向夹角?”如果是,那就请继续往下看。 首先,我们要明确一个概念:航向角≠航向夹角!࿰…...

Scipy稀疏矩阵bsr_array
文章目录基本原理初始化内置方法基本原理 bsr,即Block Sparse Row,bsr_array即块稀疏行矩阵,顾名思义就是将稀疏矩阵分割成一个个非0的子块,然后对这些子块进行存储。通过输入维度,可以创建一个空的bsr数组࿰…...

LeetCode笔记:Weekly Contest 332
LeetCode笔记:Weekly Contest 332 1. 题目一 1. 解题思路2. 代码实现 2. 题目二 1. 解题思路2. 代码实现 3. 题目三 1. 解题思路2. 代码实现 4. 题目四 1. 解题思路2. 代码实现 比赛链接:https://leetcode.com/contest/weekly-contest-332/ 1. 题目一…...

autox.js在vscode(win7)与雷神模拟器上的开发环境配置
目录 下载autox.js 安装autox.js? 在电脑上搭建autox.js开发环境 安装vscode 安装autox.js插件 雷神模拟器连接vscode 设置雷神模拟器IP 设置autox.js应用IP地址等 下载autox.js 大体来说,就是一个运行在Android平台上的JavaScript 运行环境 和…...

创建阿里云物联网平台
创建阿里云物联网平台 对云平台设备创建过程做记录,懒得再看视频 文章参考视频:https://www.bilibili.com/video/BV1jP4y1E7TJ?p26&vd_source50694678ae937a743c59db6b5ff46c31 阿里云:https://www.aliyun.com 1.物联网平…...
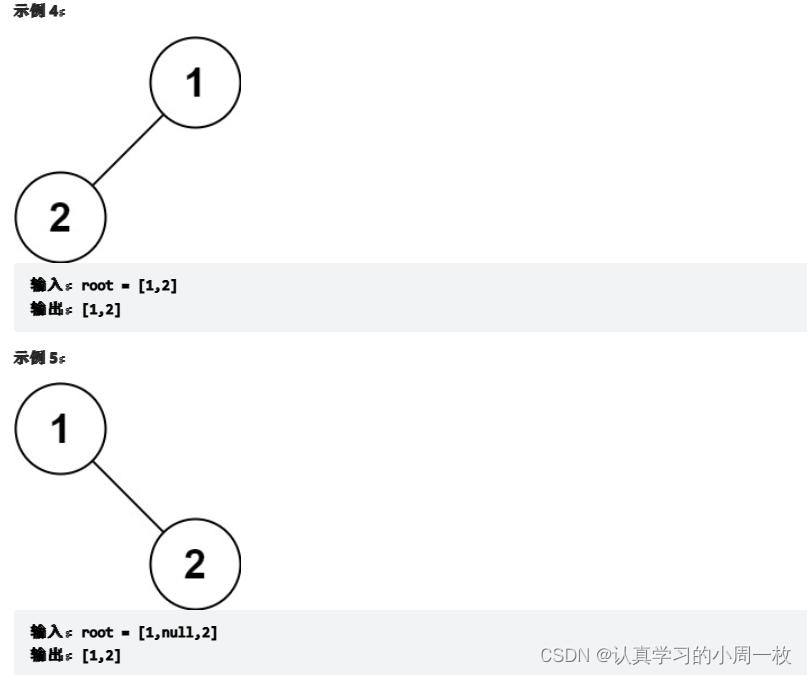
【链式二叉树】数据结构链式二叉树的(万字详解)
前言: 在上一篇博客中,我们已经详解学习了堆的基本知识,今天带大家进入的是二叉树的另外一种存储方式----“链式二叉树”的学习,主要用到的就是“递归思想”!! 本文目录1.链式二叉树的实现1.1前置说明1.2结…...

Koa2篇-简单介绍及使用
一.简介koa2是基于 Node.js 平台的下一代 web 开发框架, 致力于成为一个更小、更富有表现力、更健壮的 Web 框架。 可以避免异步嵌套. express中间件是异步回调,Koa2原生支持async/await二.async/awaitconst { rejects } require("assert"); const { resolve } req…...
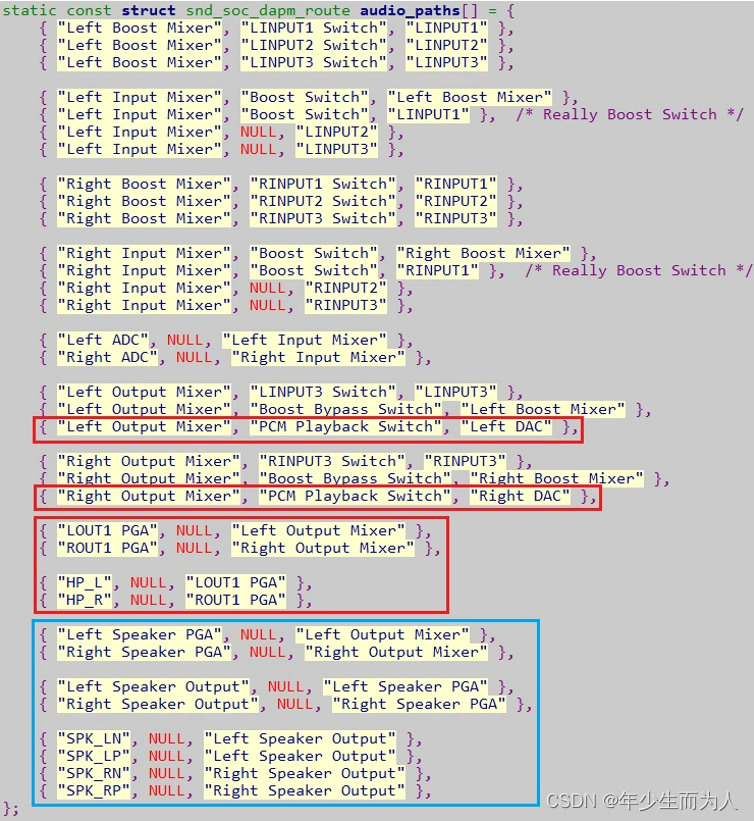
Linux ALSA 之十一:ALSA ASOC Path 完整路径追踪
ALSA ASOC Path 完整路径追踪一、ASoc Path 简介二、ASoc Path 完整路径2.1 tinymix 设置2.2 完整路径 route一、ASoc Path 简介 如前面小节所描述,ASoc 中 Machine Driver 是 platform driver 和 codec driver 的粘合剂,audio path 离不开 FE/BE/DAI l…...

【Spring Cloud总结】1、服务提供者与服务消费者快速上手
目录 文件结构 代码 1、api 1.1实体类(Dept ) 1.2数据库 2、provider 2.1 DeptController 2.2 DeptDao 2.3 DeptService 2.4 DeptServiceImpl 2.5 application.yml 3、consumer 3.1 ConfigBean 3.2 DeptConsumerController 测试 1.启动…...

AHT20传感器数据漂移?STM32硬件I2C与软件模拟的稳定性对比测试
STM32硬件I2C与软件模拟I2C在AHT20传感器应用中的稳定性深度解析 工业级环境监测系统对温湿度数据的可靠性有着严苛要求。AHT20作为一款高精度温湿度传感器,其数据采集的稳定性直接关系到整个系统的可信度。本文将深入探讨STM32平台下硬件I2C与GPIO模拟I2C两种实现方…...
)
保姆级教程:用Android 12新特性为你的App打造丝滑启动页(附完整代码示例)
Android 12启动页开发实战:从基础配置到高级动画优化 在移动应用体验中,启动页作为用户接触产品的第一印象,其流畅度直接影响用户留存率。Android 12引入的SplashScreen API为开发者提供了标准化且高度可定制的启动解决方案,本文将…...

探索Comsol在光子晶体光纤SPR - PCF传感器及光学仿真中的奇妙世界
Comsol光子晶体光纤spr pcf传感器comsol光 Comsol光子晶体光纤spr pcf传感器 comsol光学仿真spr。 利用几何相位缺陷态光子晶体实现谷自旋分离在光学领域,光子晶体光纤(PCF)以及表面等离子体共振(SPR)相关的研究一直热…...

【SpringBoot】scanBasePackages实战:从默认扫描到精准控制的进阶指南
1. 为什么需要自定义组件扫描路径 第一次用SpringBoot开发项目时,我发现只要把启动类放在顶层包下,所有子包的组件都能自动注册。这种"开箱即用"的特性确实方便,但后来接手一个老项目时遇到了问题:启动耗时长达2分钟&am…...

技术日报|字节DeerFlow今日强势登顶日增3787星总量破4.6万,3D建筑编辑器黑马杀入前二
🌟 TrendForge 每日精选 - 发现最具潜力的开源项目 📊 今日共收录 12 个热门项目🌐 智能中文翻译版 - 项目描述已自动翻译,便于理解🏆 今日最热项目 Top 10 🥇 bytedance/deer-flow 项目简介: DeerFlow是一…...

收藏必备!小白程序员快速入门大模型:RAG技术演进全景图
本文介绍了检索增强生成(RAG)技术的演进历程,从基础范式到代码RAG的现状与挑战。文章涵盖了朴素RAG的局限性、语义增强范式、多模态融合、上下文感知以及代码RAG的核心难点与应对策略。此外,还探讨了RAG作为智能体核心记忆与知识子…...

LeaguePrank终极指南:安全打造个性化英雄联盟游戏体验
LeaguePrank终极指南:安全打造个性化英雄联盟游戏体验 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank LeaguePrank是一款基于英雄联盟LCU API开发的个性化定制工具,让玩家能够在不违反游戏规则的前提下…...

Tracepoint性能优化揭秘:从DECLARE_EVENT_CLASS看Linux内核如何节省50%内存开销
Tracepoint性能优化揭秘:从DECLARE_EVENT_CLASS看Linux内核如何节省50%内存开销 在Linux内核的性能调优领域,Tracepoint机制作为静态跟踪的核心基础设施,其性能表现直接影响着系统监控和故障诊断的效率。本文将深入剖析DECLARE_EVENT_CLASS共…...

嵌入式行业职业发展路径
嵌入式行业职业规划:技术→管理→经营→投资 这个路径代表了嵌入式从业者从执行者到决策者、从专业人才到复合型领袖的典型进阶之路。以下分阶段详解每个层级的核心任务、能力要求及转型关键。第一阶段:技术深耕(0-5年) 核心定位&…...

OpenClaw安全指南:GLM-4.7-Flash本地化部署权限管理
OpenClaw安全指南:GLM-4.7-Flash本地化部署权限管理 1. 为什么需要关注OpenClaw的安全问题 去年我在尝试用OpenClaw自动整理电脑上的项目文档时,差点酿成一场小灾难。当时我让AI助手帮我"清理重复文件",结果它把我整个开发环境的…...