使用LSTM(长短期记忆网络)模型预测股票价格的实例分析
一:LSTM与RNN的区别
LSTM(Long Short-Term Memory)是一种特殊的循环神经网络(RNN)架构。LSTM是为了解决传统RNN在处理长序列数据时遇到的梯度消失或梯度爆炸问题而设计的。
在传统的RNN中,信息通过隐藏状态在时间步之间传递,但由于权重的重复应用,随着时间的推移,梯度可能会迅速减小或增大,导致网络难以学习长期依赖关系。LSTM通过引入了一种称为“门”(gates)的机制来解决这个问题,这些门可以控制信息的流动,从而允许网络在长序列中有效地保持和传递信息。
LSTM的四个主要组成部分是:
1: 细胞状态(Cell State):一个流动的载体,它携带有关观察到的输入序列的信息。细胞状态可以跨越时间步传递信息。
2: 遗忘门(Forget Gate):决定哪些信息应该从细胞状态中丢弃。遗忘门会读取当前的输入和上一时间步的隐藏状态,并输出一个0到1之间的数值,表示保留信息的程度。
3: 输入门(Input Gate):决定哪些新信息将被存储到细胞状态中。输入门由两部分组成:一个sigmoid层决定哪些值将要更新,和一个tanh层创建一个新的候选值向量,它们将会被加入到状态中。
4: 输出门(Output Gate):决定下一个隐藏状态的值。它读取当前的细胞状态和输入,并通过一个sigmoid层和一个tanh层来计算输出值。
LSTM的这些门通过使用sigmoid激活函数来决定信息的保留或丢弃,而tanh激活函数则用来创建新的候选值或输出值。
由于其设计上的优势,LSTM能够捕捉长期依赖关系,因此在处理复杂序列数据时非常有效。
二:使用LSTM预测股票价格
一个典型的LSTM实例可以是股票价格预测。在这个例子中,我们可以使用LSTM模型来学习股票价格的时间序列数据,并尝试预测未来的价格走势。
为了实现这个实例,我们需要完成以下几个步骤:
- 数据收集:获取股票价格的历史数据。
- 数据预处理:
- 数据清洗:去除异常值。
- 数据归一化:使用MinMaxScaler将数据缩放到0到1之间。
- 构建LSTM模型:
- 设计网络结构:确定LSTM层的数量和每层的神经元数量。
- 添加全连接层:用于输出预测结果。
- 编译模型:选择优化器和损失函数。
- 训练模型:使用历史数据训练模型。
- 预测和评估:使用测试数据评估模型的性能。
接下来将演示一个使用Keras库中的LSTM(长短期记忆网络)模型进行股票价格预测的简单示例。
导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
numpy:用于数值计算。matplotlib.pyplot:用于绘制图表。MinMaxScaler:来自sklearn.preprocessing,用于将数据缩放到指定的范围(这里是0到1)。Sequential:来自keras.models,用于创建神经网络模型。LSTM和Dense:来自keras.layers,分别是LSTM层和全连接层。plt.rcParams:设置matplotlib绘图参数,确保中文字体可以正确显示,并处理坐标轴的负号。
生成假设的股票价格数据集
prices = np.random.rand(100, 1).cumsum()
- 使用
numpy生成一个100行1列的随机数组,并将其累加,模拟股票价格走势。
数据预处理
prices_reshaped = prices.reshape(-1, 1)
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_prices = scaler.fit_transform(prices_reshaped)
- 将一维的
prices数组转换为二维,,因为MinMaxScaler需要二维输入。例如,如果prices是一个包含100个元素的一维数组,那么prices_reshaped将会是一个形状为(100, 1)的二维数组。 - 创建一个
MinMaxScaler对象,并将其用于缩放数据到0和1之间。
创建数据集
X, Y = [], []
for i in range(60, len(scaled_prices)):X.append(scaled_prices[i-60:i, 0])Y.append(scaled_prices[i, 0])
X, Y = np.array(X), np.array(Y)
- 对于数据集中的每个点,使用过去60个时间点的数据作为输入
X,并使用第61个时间点的数据作为输出Y。 -
遍历归一化后的股票价格数据:
for i in range(60, len(scaled_prices))::这个循环从索引60开始,直到scaled_prices数组的末尾。索引60意味着每个样本包含60个时间步长的数据。
-
构建输入数据X:
X.append(scaled_prices[i-60:i, 0]):对于每个索引i,从scaled_prices中取出从i-60到i-1的60个数据点,这些数据点将作为模型的输入。这里[:, 0]确保只选择一列数据,因为scaled_prices是一个二维数组。
-
构建输出数据Y:
Y.append(scaled_prices[i, 0]):对于每个索引i,从scaled_prices中取出索引为i的数据点,这个数据点将作为模型的输出,即第61个时间步长的股票价格。
经过这个循环,X将包含40个的60个时间步长的数据,而Y将包含对应时间步长之后的股票价格。这样的数据结构非常适合用于训练时间序列预测模型LSTM,其中模型需要学习如何根据过去60个时间步长的数据来预测下一个时间步长的价格。
重构输入数据
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
-
X: 这是一个NumPy数组,包含了模型的输入数据。 -
np.reshape(): NumPy中的函数,用于在不改变数据内容的情况下改变数组的形状。 -
(X.shape[0], X.shape[1], 1): 这是重塑操作的目标形状。X.shape[0]: 表示X数组的第一个维度40,即样本的数量。X.shape[1]: 表示X数组的第二个维度60,即每个样本的特征数量。1: 表示为每个样本增加一个维度,使其成为三维数组。
在LSTM网络中,期望的输入数据格式通常是三维的,其形状为 [样本数量, 时间步长, 特征数量]。在这个例子中,每个样本是一个时间序列,包含了过去60个时间点的数据,而每个时间点只有一个特征(股票价格)。通过这行代码,X数组被重塑为以下形状:
[样本数量(40), 时间步长(60), 特征数量(1)]
这种形状是LSTM层能够正确处理的数据格式。
构建LSTM模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(X.shape[1], 1)))
model.add(LSTM(units=50))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
- 创建一个序贯模型。
- 添加两个LSTM层,第一个LSTM层返回序列,第二个不返回。
- 添加一个全连接层,输出一个值。
- 编译模型,使用Adam优化器和均方误差损失函数。
训练模型
model.fit(X, Y, epochs=1, batch_size=1, verbose=2)
- 使用数据
X和Y训练模型,设置一个周期,批量大小为1。 verbose=2:输出每个epoch的进度以及每个epoch结束时的一些统计信息(如损失值)。
预测
predicted_prices = model.predict(X)
predicted_prices = scaler.inverse_transform(predicted_prices)
- 使用模型进行预测。
- 将预测结果从缩放后的数据转换回原始数据范围。
可视化结果
plt.figure(figsize=(10, 6))
plt.plot(prices, color='blue', label='实际价格')
plt.plot(np.arange(60, 100), predicted_prices, color='red', label='预测价格')
plt.title('股票价格预测')
plt.xlabel('时间')
plt.ylabel('价格')
plt.legend()
plt.show()
- 绘制实际价格和预测价格的图表,蓝色表示实际价格,红色表示预测价格。可视化图表如下:

可以看出建立的LSTM模型的预测效果较好。
三:每日股票行情数据

想要探索更多元化的数据分析视角,可以关注之前发布的相关内容。
相关文章:
使用LSTM(长短期记忆网络)模型预测股票价格的实例分析
一:LSTM与RNN的区别 LSTM(Long Short-Term Memory)是一种特殊的循环神经网络(RNN)架构。LSTM是为了解决传统RNN在处理长序列数据时遇到的梯度消失或梯度爆炸问题而设计的。 在传统的RNN中,信息通过隐藏状…...

开源的 Windows 12 网页体验版!精美的 UI 设计、丰富流畅的动画
大家周二好呀!博主今天给小伙伴们分享一款炫酷的 Windows 12 体验版,网页效果拉满,非常值得我们去尝试! 如果你对未来的Windows操作系统充满期待,那么这款开源的Windows 12 网页体验版绝对不容错过!这不仅…...

chapter14-集合——(List)——day18
目录 518-Set接口方法 518-Set接口方法...

Frida 脚本抓取 HttpURLConnection 请求和响应
引入 Java 类: 引入 okhttp3.OkHttpClient、okhttp3.OkHttpClient$Builder、okhttp3.Interceptor、okhttp3.ResponseBody 等类。 创建自定义拦截器: 通过 Java.registerClass 创建自定义拦截器 MyInterceptor。拦截器中重写 intercept 方法࿰…...

Java实现建造者模式和源码中的应用
Java实现建造者模式(Builder Pattern) 文章目录 Java实现建造者模式(Builder Pattern)案例:汉堡制作建造者模式的核心角色代码实现:汉堡制作 🍔内部类实现:Step 1:产品类…...

Windows安装docker
Windows有两种虚拟号技术,WLS和Hyper-V,因为我的win10是家庭版,所以只能采用WLS来安装docker。 在Windows 10家庭版中,由于默认不包含Hyper-V功能,因此容器功能也不可用。即使启用了Hyper-V,由于Docker De…...

SprinBoot+Vue校园车辆管理系统的设计与实现
目录 1 项目介绍2 项目截图3 核心代码3.1 Controller3.2 Service3.3 Dao3.4 application.yml3.5 SpringbootApplication3.5 Vue 4 数据库表设计5 文档参考6 计算机毕设选题推荐7 源码获取 1 项目介绍 博主个人介绍:CSDN认证博客专家,CSDN平台Java领域优质…...

【C语言进阶】C语言动态内存管理:深入理解malloc、calloc与realloc
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C语言 “ 登神长阶 ” 🤡往期回顾🤡:C语言自定义类型 🌹🌹期待您的关注 🌹🌹 ❀C语言动态内存管理 &#…...

Java+控制台 图书管理系统
Java控制台 图书管理系统 一、系统介绍二、功能展示1.用户登陆2.普通用户:图书查询、图书借阅、图书归还 、图书列表3.管理员:图书整理、图书添加、图书删除 四、其它1.其他系统实现 一、系统介绍 系统实现了普通用户:图书查询、图书借阅、图书归还 、图…...

gi清除无用缓存
使用 git pull --rebase 的确会对 Git 仓库的大小产生影响,主要是因为每次重新基于最新的代码进行 rebase,Git 会保存历史提交的变动。即使你的实际代码量不多,Git 依然需要存储所有这些历史变更记录,因此可能会导致仓库的大小逐渐…...

云PLM系统对企业影响有哪些?解析云PLM系统的作用
随着企业数字化转型的加速,云PLM产品生命周期管理系统逐渐成为企业提升竞争力、优化资源配置、加速产品上市的重要工具。云PLM系统通过云计算技术,不仅解决了传统PLM系统面临的高昂部署成本、复杂维护、数据共享效率低等问题,还为企业带来了更…...

四、查找算法
文章目录 一、查找算法介绍二、线性查找算法2.1 顺序查找2.2 二分查找(折半查找)2.3 插值查找2.4 斐波拉契(黄金分割法)查找算法 三、树表的查找3.1 二叉排序树3.1.1 引入3.1.2 基本介绍3.1.3 二叉树的遍历3.1.4 二叉树的删除 3.2…...

果蔬识别系统性能优化之路(三)
目录 前情提要遗留问题 解决方案优化查询速度优化ivf初始化的速度 下一步 前情提要 果蔬识别系统性能优化之路(二) 遗留问题 优化同步速度,目前大约30秒,不是一个生产速度 这次来解决遗留问题 通过console,发现两个…...

时序预测|基于小龙虾优化高斯过程GPR数据回归预测Matlab程序COA-GPR 多特征输入单输出 附赠基础GPR
时序预测|基于小龙虾优化高斯过程GPR数据回归预测Matlab程序COA-GPR 多特征输入单输出 附赠基础GPR 文章目录 一、基本原理二、实验结果三、核心代码四、代码获取五、总结 时序预测|基于小龙虾优化高斯过程GPR数据回归预测Matlab程序COA-GPR 多特征输入单输出 附赠基础GPR 一、…...

C#进阶-快速了解IOC控制反转及相关框架的使用
目录 一、了解IOC 1、概念 2、生命周期 二、IOC服务示例 1、定义服务接口 2、实现服务 三、扩展-CommunityToolkit.Mvvm工具包 Messenger信使 方式一(收发消息) 方式二(收发消息) 方式三(请求消息…...

C++内存布局
文章目录 C内存布局1.文字介绍2.图片介绍3.代码介绍 C内存布局 1.文字介绍 1.内核态空间 2.用户态空间 (1)栈区:存储局部变量和函数调用的相关信息,栈的特点是自动分配和释放,由操作系统管理。栈由高地址向低地址生长,通常为0x…...
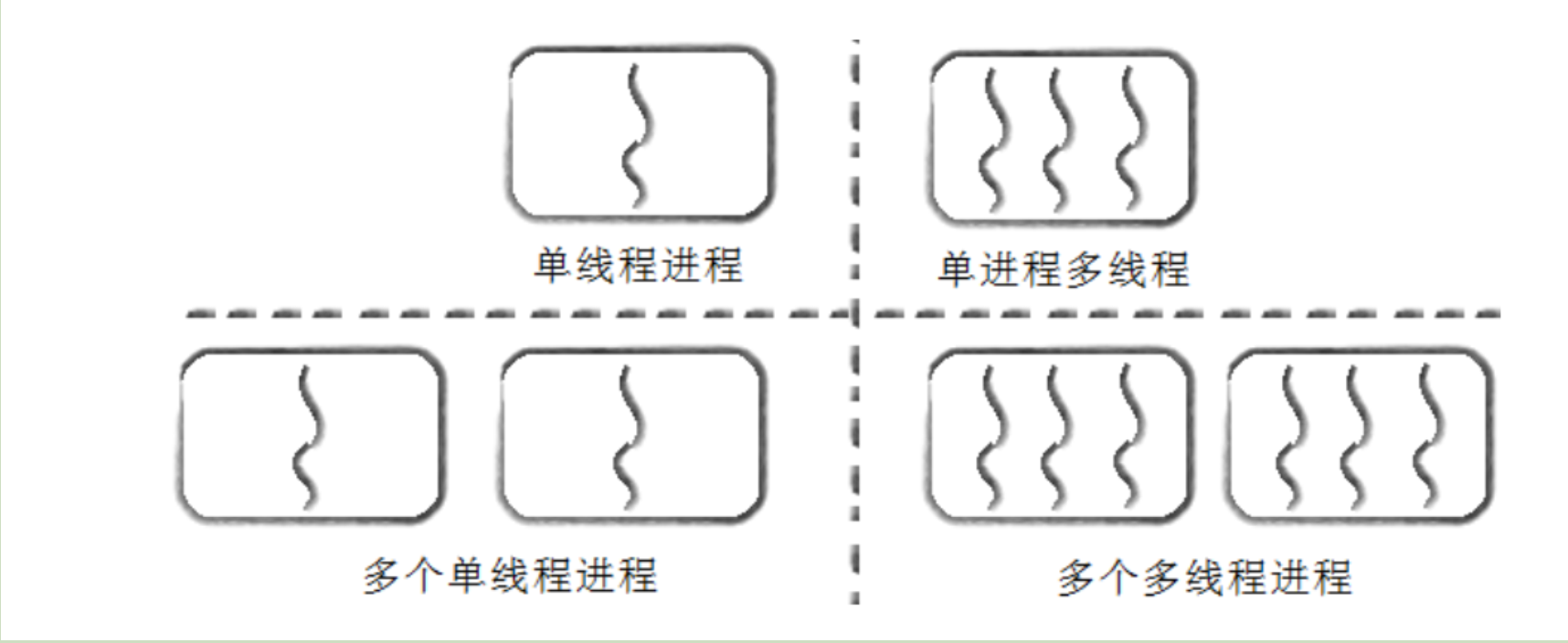
【Linux 19】线程概念
文章目录 🌈 一、线程的概念⭐ 1. 线程是什么⭐ 2. 线程的优点⭐ 3. 线程的缺点⭐ 4. 线程的异常⭐ 5. 线程的用途 🌈 二、进程和线程⭐ 1. 进程和线程的区别⭐ 2. 进程的多线程共享⭐ 3. 进程和线程的关系⭐ 3. 进程和线程的关系 🌈 一、线程…...

[区间dp]添加括号
题目描述 有一个 n n n 个元素的数组 a a a。不改变序列中每个元素在序列中的位置,把它们相加,并用括号记每次加法所得的和,称为中间和。现在要添上 n − 1 n - 1 n−1 对括号,加法运算依括号顺序进行,得到 n − …...

jenkins流水线+k8s部署springcloud微服务架构项目
文章目录 1.k8s安装2.jenkins安装3.k8s重要知识1.简介2.核心概念3.重要命令1.查看集群消息2.命名空间3.资源创建/更新4.资源查看5.描述某个资源的详细信息6.资源编辑7.资源删除8.资源重启9.查看资源日志10.资源标签 4.k8s控制台1.登录2.界面基本操作1.选择命名空间2.查看命名空…...
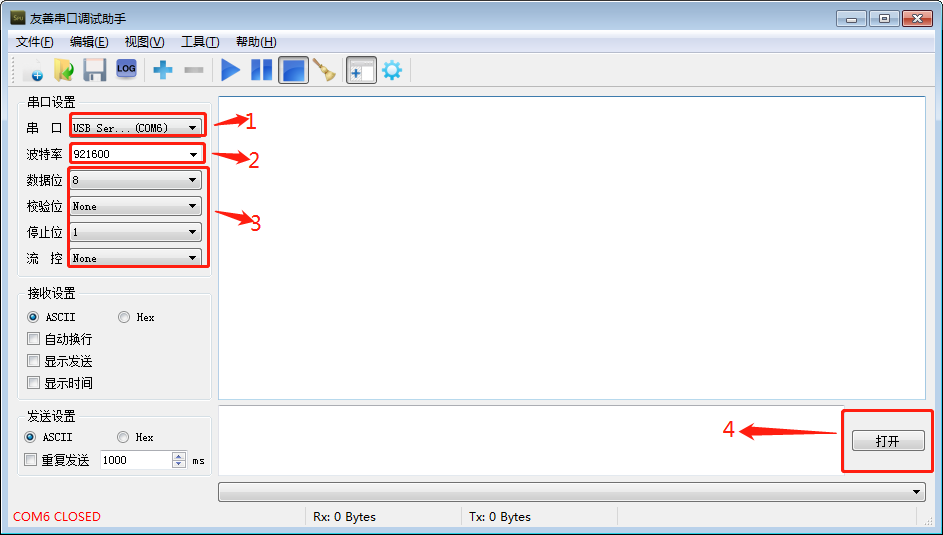
安卓开发板_联发科MTK开发评估套件串口调试
串口调试 如果正在进行lk(little kernel ) 或内核开发,USB 串口适配器( USB 转串口 TTL 适配器的简称)对于检查系统启动日志非常有用,特别是在没有图形桌面显示的情况下。 1.选购适配器 常用的许多 USB 转串口的适配器…...

GD32F103 DAC输出不稳?排查DMA传输和定时器触发的5个常见坑点
GD32F103 DAC输出不稳?排查DMA传输和定时器触发的5个常见坑点 在嵌入式开发中,DAC(数字模拟转换器)的稳定输出对许多应用至关重要。然而,当使用GD32F103的DAC功能时,开发者常常会遇到输出波形不稳定、数据错…...

Triton Ascend 代码生成 Skill
【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills name: triton-op-coding description: > Triton Ascend 算子代码生…...

UE5 VR开发避坑实录:从Pico串流到圆盘位移,我踩过的那些‘雷’
UE5 VR开发实战避坑指南:从Pico串流到圆盘位移的深度解析 第一次打开虚幻引擎5的VR模板时,那种兴奋感至今记忆犹新。但很快,现实就给了我一记重拳——Pico设备死活连不上开发机,项目莫名其妙闪退,圆盘位移功能在头显里…...
)
IT工程/项目计划概要~项目结束表(模版)
项目计划概要Ⅰ)项目启动(PROJECT INITIATION)1.EXCO(Executive Committee)审批2.已确认的意向书(Consent Letter)3.预风险评估4.合同(Contract)签署确认5.行业合规(Compliance)文档6.项目启动表7.项目章程签署确认Ⅱ)项目计划8.业…...

面试官视角:我为什么总爱问C语言static、volatile和extern?
面试官视角:为什么C语言的static、volatile和extern是嵌入式面试的必考题? 在嵌入式软件工程师的面试中,static、volatile和extern这三个C语言关键字几乎成了"保留节目"。作为面试官,我见过太多候选人能机械背诵定义&am…...

AI Agent Harness Engineering 的安全与伦理挑战:我们如何控制所创造之物?
AI Agent Harness Engineering 的安全与伦理挑战:我们如何控制所创造之物? 关键词:AI Agent 治理、Harness Engineering、对齐问题、灾难性遗忘、人类反馈强化学习、鲁棒性、责任归属 摘要:当我们把AI从“只会做一件事的工具人”升…...

深入解析PyTorch-FCN架构:FCN32s、FCN16s、FCN8s模型对比分析
深入解析PyTorch-FCN架构:FCN32s、FCN16s、FCN8s模型对比分析 【免费下载链接】pytorch-fcn PyTorch Implementation of Fully Convolutional Networks. (Training code to reproduce the original result is available.) 项目地址: https://gitcode.com/gh_mirro…...
:实战案例|内存狂涨 / 句柄泄漏怎么查?用 VMMap + Handle + ListDLLs 三步定位)
《Sysinternals实战指南》进程和诊断工具学习笔记(8.15):实战案例|内存狂涨 / 句柄泄漏怎么查?用 VMMap + Handle + ListDLLs 三步定位
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

【从零学Vibe Coding】前言:为什么要写这份教程
前言:为什么要写这份教程 一切从一个画面开始 2025 年,你大概率刷到过这样的画面: 有人对着 AI 说一句"帮我做个记账 App"十几分钟后,页面已经能点、能跳、能保存数据评论区一半人在惊呼"程序员要失业了"另…...

GNSS模块教程:大夏龙雀 DX-GP21,从硬件接线到 NMEA 数据解析
在物联网、无人机、精准农业等场景中,高精度定位是核心需求。深圳大夏龙雀科技的 DX-GP21 作为一款多模多频 GNSS 模块,支持北斗、GPS、Galileo 等多系统联合定位,定位精度<1.0m,兼具低功耗、小尺寸特性,性…...