MySQL优化策略(大数据量)
一、 前提:
1.数据规模 :
明确数据量级是上亿级,这需要特殊的处理,比如分区、索引等策略。
2.数据增长率 :
了解数据的增加速度,有助于预估未来存储和性能需求,从而提前规划扩展策略。
3.访问模式 :
分析是读多写少,还是写多读少,还是读写均衡,访问模式不同,处理的方法和侧重点也不同。
4.数据分布情况 :
了解数据是否热点集中(多数查询集中在某些热点数据上),还是均匀分布,有助于进行数据分区和索引处理。
通过工具如MySQL自带的ANALYZE TABLE,以及查询日志和性能分析工具如Slow Query Log、EXPLAIN等,可以帮助你深入了解数据库表的使用情况。
二、 数据库设计优化
是指通过调整数据库的结构、索引、查询等方面来提高数据库的性能和可扩展性。
以下是数据库设计优化的一些关键策略和技巧:
1. 规范化与反规范化
规范化 (Normalization):将数据拆分成多个表,以减少数据冗余,确保数据一致性。这种做法可以避免数据的重复和异常更新问题。
优点:数据一致性好,减少数据冗余。
缺点:查询时可能需要多个表的连接,影响性能。
反规范化 (Denormalization):为了提高查询性能,可以适当反规范化,即减少表的拆分,存储冗余数据以减少查询时的表连接。
优点:查询效率高,减少 JOIN 操作。
缺点:数据冗余,更新时复杂度增加。
2. 选择适当的数据类型
合理选择数据类型可以减少存储空间,提高查询效率。
例如:
使用整数存储日期(如时间戳)而非字符串。
使用合适的浮点数或定点数来存储小数。
避免过大的数据类型,例如不必为一个简单的布尔值选择 VARCHAR(255)。
3. 创建适当的索引
索引是提升查询性能的最有效手段之一。
创建索引:为常用的查询条件创建索引可以显著提高查询速度。
针对常用查询列、主键和外键创建索引。
对频繁用于排序或分组的列进行索引。
索引覆盖查询:确保查询中的所有列都包含在索引中,减少访问数据表的次数。
索引的选择性:索引应该创建在选择性高的列上,即能显著减少返回行数的列。
避免过多索引:过多的索引会降低数据插入、更新和删除的性能,因此需要在查询性能和更新开销之间取得平衡。
4. 缓存策略
使用缓存:对于频繁查询且不经常改变的数据,可以使用缓存技术(如 Redis、Memcached)来加速读取操作。
数据库级别缓存:有些数据库系统(如 MySQL)支持查询缓存,可以通过优化查询和缓存策略来加速响应。
5. 读写分离
对于读多写少的场景,可以采用读写分离的架构。将写操作发送到主数据库,读操作发送到从数据库,减轻主库的负担。
6.事务管理与锁机制
减少长事务:长事务会持有锁较长时间,可能会导致其他事务的阻塞,影响并发性能。
选择合适的事务隔离级别:根据业务需求选择合适的隔离级别,避免过高的隔离级别导致锁争用。
避免大范围锁:尽量使用行级锁,而不是表级锁,以减少并发访问时的锁冲突。
7. 数据量管理
归档历史数据:定期归档不常用的数据到历史表或数据仓库,减少主库的数据量,提高查询效率。
分批处理:对于需要大量更新、删除操作的任务,采用分批处理的方式,避免一次性对大量数据操作,造成数据库性能下降。
8. 监控与调优
定期监控数据库的运行状况,分析查询的执行计划(如 MySQL 的 EXPLAIN),发现性能瓶颈。
利用数据库自带的性能优化工具(如 MySQL 的慢查询日志)定位问题,针对性地优化。
通过合理的数据库设计优化,可以有效提升数据库的性能,尤其是在处理大量数据时。
三、 MySQL数据库查询优化
查询优化是提高数据库查询速度、减少资源消耗的关键。以下是一些常见的MySQL查询优化策略和技巧:
1. 索引优化
创建适当的索引:
针对查询中的 WHERE、JOIN 和 ORDER BY 字段创建索引。主键、唯一键等字段自动建立索引。
对频繁进行排序和过滤的字段添加索引。
避免冗余索引:
不必要的索引会增加数据库的写入开销,建议定期检查和删除重复或无用的索引。
组合索引:
如果查询条件涉及多个列,可以使用组合索引,提高查询效率。例如,针对 WHERE col1 = ? AND col2 = ? 的查询,创建 (col1, col2) 组合索引。
2. 使用覆盖索引
覆盖索引是指索引中包含了查询所需的所有列,这样查询时不需要再访问表中的数据行。可以通过创建包含查询字段的组合索引,来实现覆盖索引。
例如:SELECT name FROM users WHERE id = ?,如果有 id, name 组合索引,则可以直接从索引中获取数据。
3. 避免全表扫描
使用索引扫描:确保查询条件中的字段有相应的索引,避免全表扫描。
限制返回的数据量:
使用 LIMIT 来限制返回结果集的行数,减少资源消耗。
针对分页查询,可以通过优化 LIMIT 查询,例如使用索引或记录上次查询的位置,避免跳过大量数据。对于大量数据的分页查询,可以使用延迟加载策略,避免查询大量不必要的记录。
4. 避免 SELECT * 查询
只查询需要的字段:明确指定查询需要的字段,减少数据传输和处理的时间。因为使用 SELECT * 会查询所有字段,增加不必要的数据传输和处理开销。
例如,使用 SELECT id, name FROM users 而不是 SELECT * FROM users。
5. 合理使用 JOIN
优化 JOIN 查询:
在连接多个表时,尽量减少多表连接的数量,可以通过分解查询或者缓存部分数据来优化复杂的连接操作。确保 JOIN 条件字段上有索引,尤其是对于大表连接时。
使用小表驱动大表:
当进行 JOIN 操作时,使用小表驱动大表,即先从小表查找结果,再去大表查询。
6. 查询重写
子查询优化:尽量避免在 WHERE 中使用子查询,可以通过 JOIN 或者 EXISTS 重写查询。子查询通常效率较低,特别是在大数据集上。
避免复杂表达式:避免在 WHERE 子句中对索引列使用复杂表达式(如函数、计算),因为这样可能导致索引失效。
例如:WHERE DATE(create_time) = '2024-01-01' 可能导致索引失效,改为 WHERE create_time >= '2024-01-01 00:00:00' AND create_time < '2024-01-02 00:00:00'。
7. 使用适当的查询缓存
MySQL 查询缓存:MySQL 自带查询缓存功能,可以缓存重复的查询结果,但该功能在高并发写入时效果不佳,建议根据业务场景评估是否启用。
第三方缓存:对于频繁查询的热点数据,可以将其缓存到 Redis 或 Memcached 中,避免频繁访问数据库。
8. EXPLAIN 分析查询
使用 EXPLAIN 命令查看查询的执行计划,分析每个步骤的开销。
EXPLAIN 会显示表的访问类型(如 ALL、index、range、const 等),是否使用索引、预估的行数等。
优化目标是减少 ALL(全表扫描)和 range(范围扫描),提高 const、eq_ref 类型的访问方式。
EXPLAIN 示例:
EXPLAIN SELECT * FROM users WHERE id = 123;
9. 避免重复查询
缓存热点数据:对于不经常变化的数据,使用应用层缓存或查询缓存避免重复查询。
合理设计应用层逻辑:避免相同查询在短时间内频繁执行,通过程序层优化、缓存查询结果等方式减少数据库压力。
10. 适当使用批量操作
批量插入:使用 INSERT INTO ... VALUES (...), (...), ... 语法进行批量插入,可以减少数据库的写入压力。
批量更新和删除:对于大量数据的更新和删除操作,使用批量操作或分页处理,避免一次性操作过多数据导致锁等待问题。
11. 避免大事务
拆分大事务:长时间运行的事务会持有锁,可能导致锁等待和阻塞其他查询。应尽量将大事务拆分为小事务,减少锁的持有时间。
使用适当的隔离级别:根据业务场景选择合适的事务隔离级别,避免不必要的锁争用。例如,如果不需要严格的隔离,可以选择 READ COMMITTED 而不是 REPEATABLE READ。
12. 定期维护数据库
分析表与优化表:定期使用 ANALYZE TABLE 和 OPTIMIZE TABLE 命令维护表和索引的统计信息,保证查询优化器使用正确的索引。
ANALYZE TABLE:分析并存储表的索引分布信息。
OPTIMIZE TABLE:重组表及索引,清理碎片,适合频繁更新、删除数据的表。
13. 使用合适的数据类型
精简数据类型:使用最合适的字段类型。例如,INT 可以满足时,不要使用 BIGINT。对于长度固定的字符串,使用 CHAR 而非 VARCHAR。
避免使用过大的数据类型:不必要的长文本(如 TEXT 或 BLOB)会显著增加存储和查询的开销。
14. 分区和分表
表分区(键值分区):将大表按照某个条件(如日期、地理位置等)分成多个分区,提高查询性能和管理的灵活性。
垂直分表(哈希分区):将表中列较多的字段拆分到不同的表中,减少表的宽度,提高查询性能。
水平分表(范围分区):将一个表按照某个条件拆分成多个表,减少单表数据量,提升查询性能。
分库:将不同业务模块的数据分布在不同的数据库中,减轻单个数据库的压力。
通过以上方法,结合具体业务场景合理设计和优化,可以显著提高MySQL查询性能。
四、硬件与系统配置优化
MySQL数据库的性能不仅依赖于数据库本身的配置和查询优化,还与硬件和系统配置密切相关。优化硬件和操作系统的配置可以显著提升MySQL的整体性能。
以下是一些硬件和系统级别的优化策略:
1. 硬件配置优化
1.1 CPU
多核处理器:MySQL是多线程应用程序,能够利用多核处理器来并行处理多个查询请求。因此,选择多核、频率较高的CPU能够有效提升并发处理能力。
提升单核性能:虽然MySQL可以利用多核,但某些操作(如单个线程的查询执行)依然依赖单核性能。选择较高主频的处理器有助于提升复杂查询的性能。
1.2 内存
增加内存容量:MySQL依赖内存进行缓存数据,增加内存容量有助于提升性能,尤其是在大量读操作时。尽量将常用数据和索引都缓存到内存中,减少磁盘I/O。
调整缓存大小:适当配置InnoDB缓存池 (innodb_buffer_pool_size) 和查询缓存,可以提升查询效率。一般建议将内存的60%-70%分配给InnoDB缓存池。
1.3 存储
选择SSD硬盘:SSD固态硬盘比传统HDD(机械硬盘)在随机读取和写入操作上更快,能够显著提高数据库的I/O性能。
NVMe SSD 提供更高的I/O吞吐量和更低的延迟,适合高负载的数据库环境。
RAID配置:
RAID 10 是数据库系统中常用的存储方案,结合了RAID 1的镜像功能和RAID 0的条带化功能,提供了数据冗余和高读写性能。
避免使用 RAID 5,因为其写入性能较差,不适合频繁写操作的数据库环境。
1.4 网络
低延迟网络:对于分布式数据库或数据库与应用服务器之间的通信,选择高带宽、低延迟的网络能够减少查询延迟。
优化网络协议:使用 TCP 调优,减少 TCP 连接的延迟,例如配置 TCP_NODELAY 来禁用 Nagle 算法,从而减少网络延迟。
2. 操作系统配置优化
2.1 文件系统
选择合适的文件系统:
对于Linux环境,推荐使用 ext4 或 XFS 文件系统,因其具有较好的性能和稳定性。
XFS 在处理大文件和高并发访问时表现优异。
禁用文件系统日志:在某些情况下,可以禁用文件系统的日志(例如使用noatime选项),以减少写入磁盘时的I/O开销。
2.2 内存管理
禁用交换分区:MySQL运行在交换(swap)中会严重影响性能,因为磁盘I/O远远慢于内存访问。建议:
增加物理内存,避免内存不足。
将 swapiness 参数设置得较低,例如 vm.swappiness=1,以尽量减少操作系统使用交换分区。
HugePages配置:在Linux系统上,可以启用 HugePages 以减少内存分页带来的开销。HugePages 提供了更大的内存页,降低了内存管理的负担。
2.3 I/O 调优
I/O调度器:
Linux默认的I/O调度器可能不适合数据库的随机读写负载。建议选择 deadline 或 noop 调度器,以减少I/O延迟。
使用deadline调度器时,可以减少读取/写入延迟,保证I/O吞吐量的稳定性。
2.4 文件句柄数
数据库可能会同时处理大量文件操作,因此需要增加文件描述符的上限。通过修改 /etc/security/limits.conf 来增加最大文件句柄数,例如:
* soft nofile 65535
* hard nofile 65535
2.5 NUMA配置
禁用NUMA:在多核CPU架构中,NUMA(非一致性内存访问)可能会导致内存分配不均匀,影响数据库性能。建议在数据库服务器上禁用NUMA,或通过numactl确保MySQL可以均匀地访问所有内存节点。
3. MySQL实例配置优化
3.1 InnoDB 存储引擎优化
innodb_buffer_pool_size:
InnoDB缓存池是InnoDB存储引擎中最重要的配置参数,负责缓存数据页和索引页。通常建议分配60%-70%的物理内存给 innodb_buffer_pool_size。
innodb_log_file_size:
调大InnoDB的日志文件大小 (innodb_log_file_size),可以减少日志文件的写入频率,从而提升写操作的性能。通常推荐设置为内存大小的 25%-50%。
innodb_flush_log_at_trx_commit:
此参数控制事务日志的刷新策略。设置为 2 可以在性能和数据安全之间取得平衡(每秒同步日志而不是每次事务提交同步)。
3.2 并发参数调优
max_connections:
设置一个合理的最大连接数,避免过多连接导致内存耗尽。可以根据服务器资源和应用需求动态调整。
innodb_thread_concurrency:
控制InnoDB的并发线程数量。如果MySQL在多核CPU上运行,可以适当增大 innodb_thread_concurrency,让更多线程能够同时处理任务。
3.3 查询缓存
禁用或优化查询缓存:
MySQL的查询缓存在高并发写入时会导致性能下降,因此如果数据库是写密集型,建议禁用查询缓存(query_cache_size = 0)。
对于读密集型场景,可以适当配置查询缓存大小,减少频繁查询带来的负载。
4. 操作系统和MySQL的调优工具
4.1 MySQLTuner
MySQLTuner 是一个轻量级的脚本,用于分析MySQL服务器的性能并给出优化建议。它会根据当前运行状况建议修改某些参数,如缓存大小、连接数等。
wget https://raw.githubusercontent.com/major/MySQLTuner-perl/master/mysqltuner.pl
perl mysqltuner.pl
4.2 Performance Schema
Performance Schema 是MySQL自带的性能监控工具,可以帮助分析查询性能、锁等待和资源消耗。通过启用 Performance Schema,可以监控和优化慢查询、死锁等性能问题。
4.3 使用 sysbench 测试数据库性能
sysbench 是一个数据库和系统性能测试工具。可以通过它模拟高并发读写负载,测试数据库的性能瓶颈,并针对性地进行优化。
5. 备份与恢复策略
定期备份:确保数据库有足够的备份策略,防止硬件故障或系统崩溃造成数据丢失。使用 mysqldump、Xtrabackup 等工具定期进行备份。
备份策略:大数据量的数据库,可以通过增量备份和完全备份结合,减少备份对系统的影响。
通过优化MySQL数据库的硬件和系统配置,可以显著提升数据库的性能和稳定性,尤其是对于高负载的生产环境。调整时应根据实际业务场景、硬件资源和MySQL负载情况进行配置优化,保证最优的资源利用和性能表现。
五、MySQL数据库维护策略
MySQL数据库调优主要涉及调整MySQL服务器的配置参数,以提升数据库的性能、稳定性和响应速度。调优参数的设置取决于具体的硬件环境、数据规模、查询模式和业务需求。以下是一些关键的MySQL调优参数:
1. 内存相关参数
内存管理是数据库性能优化的关键。通过合理配置内存参数,可以提高查询效率并减少磁盘I/O操作。
1.1 innodb_buffer_pool_size
描述:InnoDB引擎用于缓存表数据和索引的缓冲池。较大的缓冲池可以减少磁盘I/O。缓存数据块和索引块,对InnoDB表性能影响最大。
建议值:设置为物理内存的70%-80%(如果MySQL是该服务器上主要的应用)。通过查询show status like 'Innodb_buffer_pool_read%',保证 (Innodb_buffer_pool_read_requests – Innodb_buffer_pool_reads) / Innodb_buffer_pool_read_requests越高越好
优化策略:在大数据量应用中,增加此值可以显著提升查询性能。
1.2 query_cache_size
描述:用于缓存查询结果,提高重复查询的性能。不过在高并发环境下可能导致性能瓶颈。缓存MySQL中的ResultSet,也就是一条SQL语句执行的结果集,所以仅仅只能针对select语句。当某个表的数据有任何任何变化,都会导致所有引用了该表的select语句在Query Cache中的缓存数据失效。所以,当我们的数据变化非常频繁的情况下,使用Query Cache可能会得不偿失。
建议值:如果启用查询缓存,建议值可以设置为32MB-128MB。对于高并发场景建议禁用(query_cache_type = 0)。根据命中率(Qcache_hits/(Qcache_hits+Qcache_inserts)*100))进行调整,一般不建议太大,256MB可能已经差不多了,大型的配置型静态数据可适当调大.可以通过命令show status like 'Qcache_%'查看目前系统Query catch使用大小。
优化策略:对于频繁执行相同查询的低并发环境,查询缓存有助于提升性能。
1.3 tmp_table_size / max_heap_table_size
描述:控制内存临时表的大小。当临时表超过这个大小时,MySQL会将其写入磁盘。
建议值:可以将其设置为128MB或更高,具体视查询复杂度和系统内存大小而定。
优化策略:对于复杂查询,增大这些参数可以减少磁盘I/O。
2. InnoDB存储引擎参数
InnoDB是MySQL的默认存储引擎,优化InnoDB相关参数有助于提升写操作性能和并发处理能力。
2.1 innodb_flush_log_at_trx_commit
描述:控制事务提交时日志刷新的频率。设置为1时保证每个事务提交都写入磁盘,最大程度保证数据安全。
建议值:
1(默认值):每次事务提交都会刷新日志,保证数据持久性,但写操作性能较低。
2:事务日志写入内存,每秒刷新到磁盘一次,性能较好但有数据丢失的风险。
0:事务日志写入内存,每秒同步一次,性能最佳,但风险最大。
优化策略:对于高并发写入场景,可以将其设置为2或0来提升性能,但会降低数据安全性。
2.2 innodb_log_file_size
描述:InnoDB重做日志文件的大小,较大的日志文件可以减少刷写频率,提升写性能。
建议值:128MB-1GB。过大或过小都会影响性能,具体值需要根据负载测试进行调整。
优化策略:适当增加此值,可以减少日志刷新次数,提升写操作性能。
2.3 innodb_io_capacity
描述:定义InnoDB用于处理后台I/O操作(如刷新脏页和插入缓冲合并)的最大磁盘I/O操作数。
建议值:通常设置为磁盘I/O性能的70%-80%。对于SSD,建议设置为2000或更高。
优化策略:适当增加该值,提升后台任务处理速度,减少对前台请求的影响。
3. 并发与连接相关参数
并发控制和连接管理是提升MySQL处理大量请求时的重要因素。
3.1 max_connections
描述:设置MySQL允许的最大并发连接数。
建议值:根据业务需求设置,通常设置为100-1000之间。对于大型应用可以设置为5000或更高。
优化策略:确保设置的值可以支持所有用户请求,避免出现“Too many connections”错误。
3.2 thread_cache_size
描述:MySQL线程缓存大小。线程缓存用于保存已处理完请求的线程,减少线程创建的开销。:保存当前没有与连接关联但是准备为后面新的连接服务的线程,可以快速响应连接的线程请求而无需创建新的
建议值:建议设置为100-500,具体根据并发情况而定。
优化策略:增大线程缓存的大小可以减少线程创建和销毁的开销,提升系统响应速度。
3.3 innodb_thread_concurrency
描述:限制InnoDB存储引擎的并发线程数。
建议值:通常设置为CPU核心数的2-4倍,或不设置(默认值0,表示MySQL自动管理线程并发)。
优化策略:在高并发环境中,合理设置此参数可以提高资源利用率,避免线程争用。
4. 日志与二进制日志相关参数
4.1 log_bin
描述:启用二进制日志,记录所有修改数据的操作,用于数据恢复和主从复制。
建议值:在启用主从复制或需要数据恢复的场景下开启。
优化策略:确保二进制日志存储在独立的磁盘上,避免影响性能。
4.2 sync_binlog
描述:控制二进制日志的同步频率。设置为1时,每次提交事务后同步日志到磁盘。
建议值:1(默认值,保证数据安全),较高并发场景下可以设置为100或更高,提升性能但存在少量数据丢失风险。
优化策略:如果对性能要求较高且允许少量数据丢失,可以增大该值。
5. 网络相关参数
5.1 max_allowed_packet
描述:控制MySQL服务器允许的最大数据包大小。适用于传输大对象(如BLOB或长SQL语句)的场景。
建议值:通常设置为16MB或更高,最大可达1GB。
优化策略:如果应用程序需要传输大数据块,增大该值可以避免“Packet too large”错误。
5.2 wait_timeout / interactive_timeout
描述:控制MySQL允许的空闲连接超时时间。数据库连接闲置时间,闲置连接会占用内存资源。可以从默认的8小时减到半小时
建议值:wait_timeout 通常设置为300-600秒,interactive_timeout 设置为900-3600秒。
优化策略:减少空闲连接的超时时间,释放资源,提升整体性能。
6. 磁盘与文件系统相关参数
6.1 innodb_flush_method
描述:控制InnoDB如何将数据刷新到磁盘。常用值为 O_DIRECT 和 fdatasync。
建议值:对于使用SSD的系统,推荐使用 O_DIRECT,以减少文件系统缓存,提升写入性能。
优化策略:根据磁盘类型选择合适的刷新方法,优化I/O性能。
6.2 innodb_file_per_table
描述:控制InnoDB每个表是否使用独立的表空间文件。如果启用,表的碎片化处理更容易。
建议值:推荐启用(默认启用)。
优化策略:独立表空间有助于进行表的优化和维护,减少碎片,提高查询性能。
通过优化这些关键参数,MySQL的性能可以得到显著提升,但需要根据具体业务场景和系统环境进行调整。
7. 其他的参数
具体的调优参数内容较多,具体可参考官方文档,这里介绍一些比较重要的参数:
back_log:back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。也就是说,如果MySql的连接数据达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。可以从默认的50升至500
max_user_connection: 最大连接数,默认为0无上限,最好设一个合理上限
thread_concurrency:并发线程数,设为CPU核数的两倍
skip_name_resolve:禁止对外部连接进行DNS解析,消除DNS解析时间,但需要所有远程主机用IP访问
key_buffer_size:索引块的缓存大小,增加会提升索引处理速度,对MyISAM表性能影响最大。对于内存4G左右,可设为256M或384M,通过查询show status like 'key_read%',保证key_reads / key_read_requests在0.1%以下最好
innodb_additional_mem_pool_size:InnoDB存储引擎用来存放数据字典信息以及一些内部数据结构的内存空间大小,当数据库对象非常多的时候,适当调整该参数的大小以确保所有数据都能存放在内存中提高访问效率,当过小的时候,MySQL会记录Warning信息到数据库的错误日志中,这时就需要该调整这个参数大小
innodb_log_buffer_size:InnoDB存储引擎的事务日志所使用的缓冲区,一般来说不建议超过32MB
read_buffer_size:MySql读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySql会为它分配一段内存缓冲区。如果对表的顺序扫描请求非常频繁,可以通过增加该变量值以及内存缓冲区大小提高其性能
sort_buffer_size:MySql执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。如果不能,可以尝试增加sort_buffer_size变量的大小
read_rnd_buffer_size:MySql的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySql会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySql会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。
record_buffer:每个进行一个顺序扫描的线程为其扫描的每张表分配这个大小的一个缓冲区。如果你做很多顺序扫描,可能想要增加该值
table_cache:类似于thread_cache_size,但用来缓存表文件,对InnoDB效果不大,主要用于MyISAM
总结
在处理和优化MySQL上亿大表时,理解数据、优化数据库设计、优化查询、调整硬件配置和定期维护是不可忽视的关键环节。通过合理规划和实施这些策略,可以有效地提升数据库的性能和可扩展性,为系统的高效稳健运行提供坚实保障。
相关文章:
)
MySQL优化策略(大数据量)
一、 前提: 1.数据规模 : 明确数据量级是上亿级,这需要特殊的处理,比如分区、索引等策略。 2.数据增长率 : 了解数据的增加速度,有助于预估未来存储和性能需求,从而提前规划扩展策略。 3.访问模式 : 分析是读多写少…...

在Excel里制作简单游戏界面
生成随机激活码 找工具箱 插入按钮 建宏 方法一:新建按钮的时候创建宏 方法二:右键->指定宏 VBA VBA代码界面 调整字体 VBA代码 Public str As String 存储激活码显示的字符 Public st As String 中间变量,用来替代随机数 Public ot…...
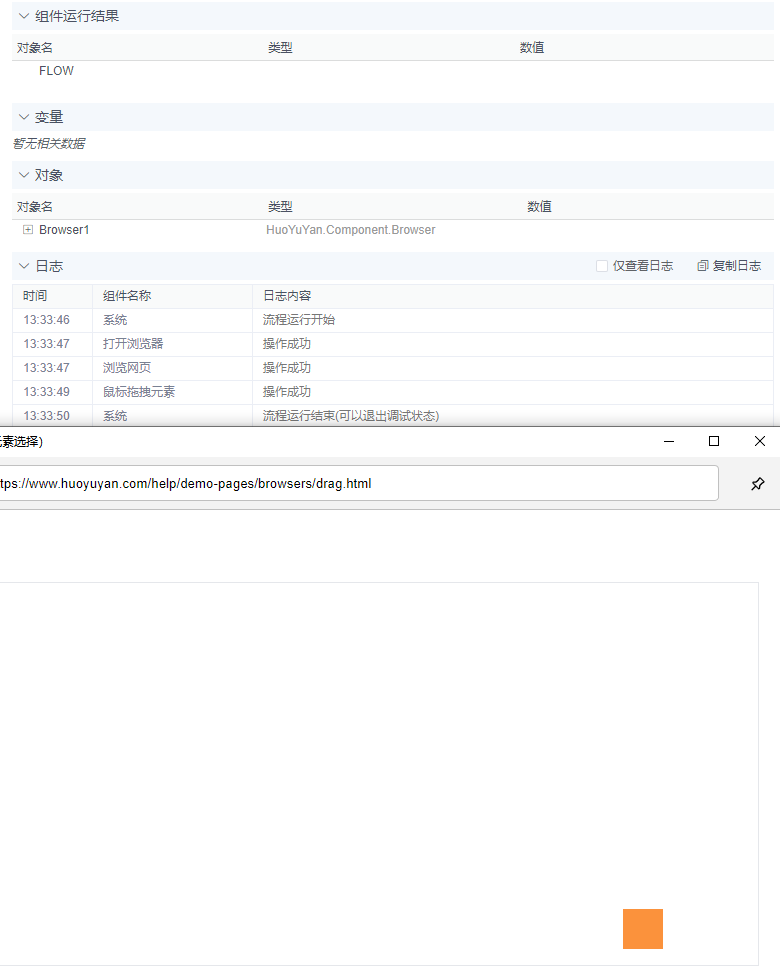
火语言RPA流程组件介绍--鼠标拖拽元素
🚩【组件功能】:在开始位置上按下鼠标,拖动到结束坐标或指定元素上放下鼠标,实现目标元素的拖拽 配置预览 配置说明 丨拖动元素 支持T或# 默认FLOW输入项 开始拖动的元素,并从当前元素开始按下鼠标 丨拖动到 目标元素/目标位…...

计算机三级网络技术总结 第十一章网络管理技术
能正常接受来自路由的通知,说明路由上已设置SNMP代理并具有发出通知的功能。UDP端口号缺省为162攻击者使用无效的IP地址,利用TCP连接的三次握手过程,使得受害主机处于开放会话的请求中,直至连接超时。在此期间,受害主机…...

「豆包 Marscode 体验官」AI 加持的云端 IDE——三种方法高效开发前后端聊天交互功能
以下是「豆包 MarsCode 体验官」优秀文章,作者努力的小雨。 豆包 MarsCode 豆包MarsCode 编程助手支持的 IDE: 支持 Visual Studio Code 1.67.0 及以上版本,以及 JetBrains 系列 IDE,如 IntelliJ IDEA、Pycharm 等,版本要求为 22…...

基于Linux文件编程实现处理Excel表格的数据
目录 前言 整体的代码框架 如何读取数据文件的数据 read_line 如何处理读取到的数据 process_data 运行结果 总结 前言 本文是基于Linux文件编程的一个小实验,用文件IO来读取Excel表格的数据,处理后写入另一个文件,本文只是对文件IO的…...

make 程序规定的 makefile 文件的书写语法(2)
(13)接着开始一个更复杂的例子,课程的素材 2 ,先给出书写 makefile 的框架 : (14) (15) 谢谢...

容器化安装jenkins稳定版长期维护版本LTS
前提已有 docker-compose和docker-ce环境,这里安装稳定的Lts版本即可。 选择稳定版本 这里选择LTS 稳定长期维护的版本 在docker镜像找到LTS稳定版本 部署jenkins服务 创建持久化数据目录 jenkinsdata]# pwd /data/jenkinsdata编写docker-compose文件 jenkins_…...
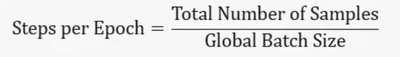
如何让人工智能训练更快
影响人工智能训练时间的因素 在深度学习训练中,训练时间的计算涉及到多个因素,包括 epoch 数、全局 batch size、微 batch size、计算设备数量等。下面是一个基本的公式来说明这些参数之间的关系(注意,这只是一个基本的说明公式&…...

linux/ubuntu国内镜像安装gitleaks敏感信息扫描工具教程及避坑点
1、背景 利用gitleaks扫描git仓库或者文件 GitHub上有比较详细的教程,但是由于每个人的安装环境不同,坑很多,网上能查到的有效信息也比较少。这里就以我坑很多的环境为例,捋一下步骤。 GitHub - gitleaks/gitleaks: Protect an…...
)
JavaScript高级程序设计基础(二)
二、语言基础 2.1语法 (简单的语法基础将在文章省略) 2.1.1严格模式 严格模式是一种不同的 JavaScript 解析和执行模型,不规范写法在这种模式下会被处理 只需在脚本开头加上"use strict" 也可以单独指定一个函数在严格模式下执…...

使用Spring Boot开发自习室预定系统
开发一个自习室预定系统涉及到用户管理、自习室管理、预定管理等功能。以下是使用Spring Boot开发自习室预定系统的步骤和关键点: 1. 需求分析 确定系统的基本需求,例如: 用户注册和登录管理员管理自习室信息用户浏览可用自习室用户预定自…...

最近读书总结
1《More Joel on Software》读后感【2024年8月29日】 1.1 本书概要 本书讲解了如何发现优秀的IT人才,并把他们招聘进来;如何对智力密集型的IT企业(软件企业)进行管理,即最好采用情感认同法;对计算机大学生…...

python列表判断是否为空的三种方式
#列表是否为空判断 a[]一: if a:print(not null) else:print(null)二: b len(a) if b 0:print(null) else:print(not null)三: if not a:print(null) else:print(not null)运行结果:...

二十三种模式之原型模式(类比制作陶器更好理解一些)
1. 设计模式的分类 创建型模式(五种):工厂方法模式、单例模式、抽象工厂模式、原型模式、建造者模式。 结构型模式(七种):适配器模式、代理模式、装饰器模式、桥接模式、外观模式、享元模式、组合模式。 行为型模式(十一种):状态模式、模板方…...

9.9日记录
1.常见排序算法的复杂度 1.快速排序 1.1快速排序为什么快 从名称上就能看出,快速排序在效率方面应该具有一定的优势。尽管快速排序的平均时间复杂度与“归并排序”和“堆排序”相同,但通常快速排序的效率更高,主要有以下原因。 出现最差情况…...
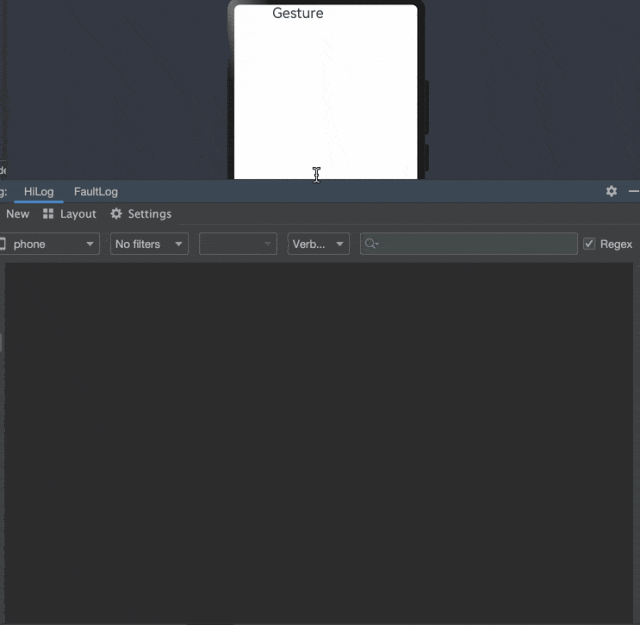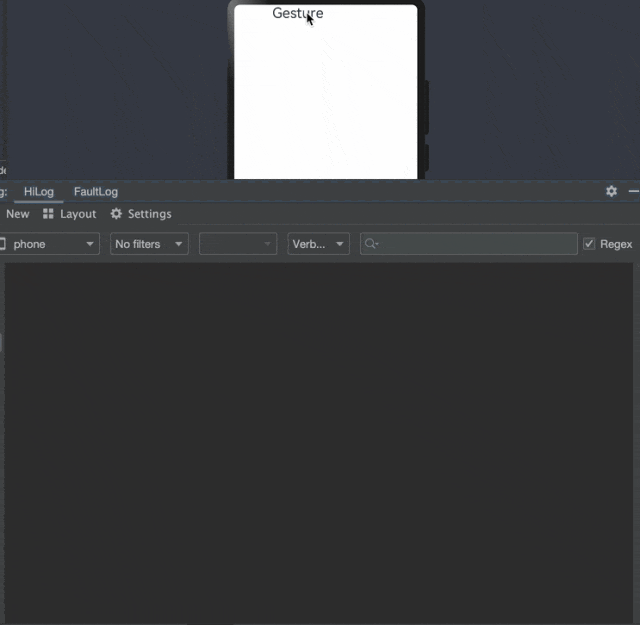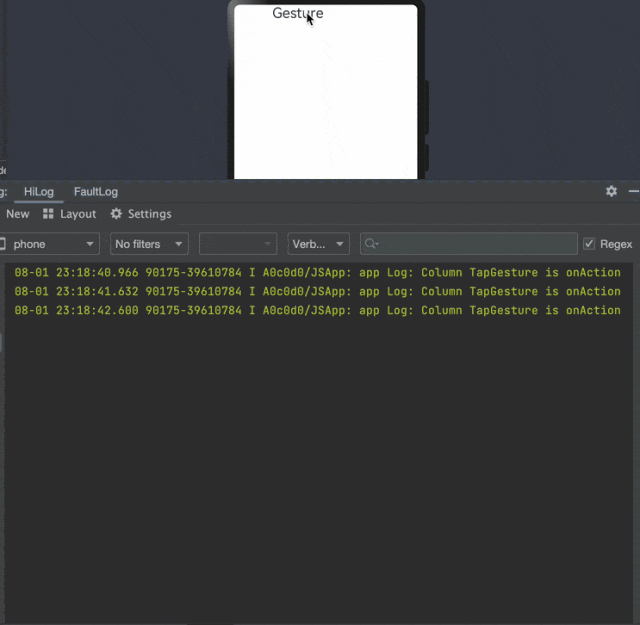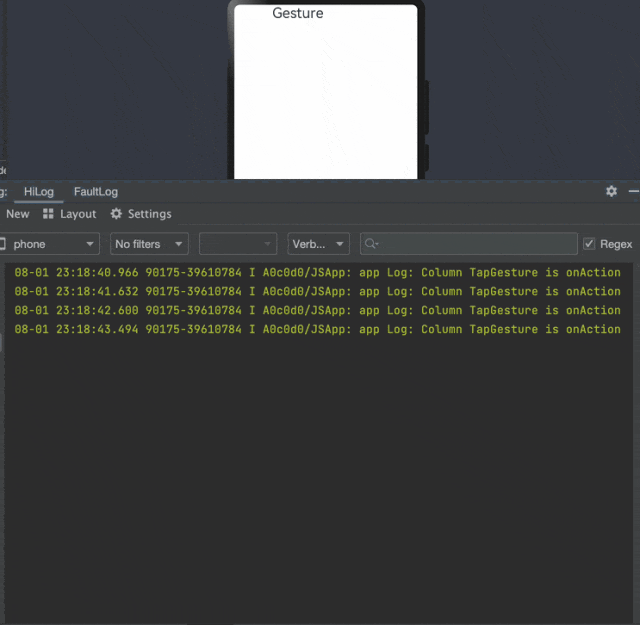
鸿蒙交互事件开发04——手势事件
1 概 述 手势事件是移动应用开发中最常见的事件之一,鸿蒙提供了一些方法来绑定手势事件。通过给各个组件绑定不同的手势事件,并设计事件的响应方式,当手势识别成功时,ArkUI框架将通过事件回调通知组件手势识别的结果。 …...

研1日记9
1.理解conv1d和conv2d a. 1和2处理的数据不同,1维数据和图像 b. 例如x输入形状为(32,19,512)时,卷积公式是针对512的,而19应该变换为参数中指定的输出通道。 2.“SE块”(Squeeze-and-Excitation Block)它可以帮助模…...

HAL库学习目录查询表
日期内容2024.09.11基于STM32C8T6的CubeMX:HAL库点亮LED2024.09.11STMCuBeMX新建项目的两种匪夷所思的问题2024.09.11STMCubeMX文件下载后会出现其他项目无法下载的问题...

pandas DataFrame日期字段数据处理
pandas DataFrame日期字段数据处理 1、pandas读取表格文件日期字段存入数据库不需要时分秒 在使用 pandas 读取表格文件,并将日期字段存入数据库时,如果你只关心日期部分而不需要时分秒,可以通过以下步骤来处理: 读取数据并转换日期字段: 首先,你需要读取你的数据,并确…...

强力解锁:5分钟掌握暗黑破坏神2存档编辑器的核心功能
强力解锁:5分钟掌握暗黑破坏神2存档编辑器的核心功能 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否曾为刷取一件心仪的暗黑2装备耗费数小时?是否想快速测试不同的角色build却苦于重复练级&#x…...
》)
《字节码到JVM:Java基础核心知识点全解析(小林八股·上)》
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

LightV虚拟化技术:基于缓存一致性的高效内存管理方案
1. LightV技术背景与核心挑战虚拟化技术在现代计算系统中扮演着越来越重要的角色,从边缘设备到云基础设施都广泛采用。传统虚拟化通过资源抽象和隔离带来了显著优势,但也面临着几个关键瓶颈问题:1.1 传统虚拟化的性能瓶颈当前主流的虚拟化方案…...
)
Linux玩转硬件调试:用CH347芯片一站式搞定JTAG、SWD、SPI Flash和EEPROM(含中断检测实战)
Linux玩转硬件调试:用CH347芯片一站式搞定JTAG、SWD、SPI Flash和EEPROM(含中断检测实战) 在嵌入式开发和硬件逆向工程领域,调试工具的选择往往决定了工作效率的上限。传统方案需要购置价格高昂的专用调试器,而CH347芯…...

别再手动算日期了!SQL Server里DATEDIFF和DATEADD的5个实战场景,数据分析师必看
SQL Server日期处理实战:DATEDIFF与DATEADD的5个高阶应用场景 在数据分析与报表开发领域,时间维度永远是核心要素之一。无论是用户行为分析、业务指标计算还是系统自动化处理,精准的日期运算能力直接决定了数据价值的挖掘深度。作为SQL Serve…...
跑通你的量化筛选器?)
Qlib实战:如何用自定义数据(比如可转债)跑通你的量化筛选器?
Qlib实战:从可转债数据到动态筛选策略的全流程解析 在量化投资领域,标准化的股票数据往往难以满足专业投资者的特殊需求。当我们需要处理可转债、加密货币或其他另类资产时,如何将这些非标准数据整合到强大的量化框架中,成为许多开…...

零基础也能学!收藏这份AI大模型入门指南,开启你的高薪之路
本文介绍了AI大模型在当前科技趋势中的核心地位,以及各行各业对AI人才的迫切需求。文章指出,即使没有技术基础,普通人也能通过学习应用开发路线掌握AI技能,并提供了循序渐进的学习步骤,包括打好Python编程基础、学习提…...

Cadence Allegro 16.6 环境设置保姆级教程:从绘图参数到自动保存,新手避坑指南
Cadence Allegro 16.6 环境设置实战指南:从零配置到高效设计 第一次打开Cadence Allegro 16.6时,满屏的菜单选项和参数设置可能会让新手感到无所适从。作为一款专业的PCB设计工具,Allegro提供了高度可定制的工作环境,但这也意味着…...

用Unity和PICO SDK 2.3.0+打造你的第一个VR手势交互Demo:手势抓取与触发事件详解
用Unity和PICO SDK 2.3.0打造你的第一个VR手势交互Demo:手势抓取与触发事件详解 VR手势交互正在重塑人机交互的边界。想象一下,当你戴上PICO头显,无需任何控制器,仅凭双手就能在虚拟世界中抓取物体、投掷飞镖甚至弹奏钢琴——这种…...
)
别再死磕PI参数了!用MATLAB/Simulink手把手教你搭建异步电机FOC仿真(附模型下载)
异步电机FOC仿真实战:从零搭建到参数调优全指南 在电机控制领域,矢量控制(FOC)技术因其优异的动态性能和效率表现,已成为工业应用中的主流方案。然而从理论到实践的跨越往往充满挑战——许多工程师能够理解Park变换、空间矢量调制等概念&…...