如何让人工智能训练更快
影响人工智能训练时间的因素
在深度学习训练中,训练时间的计算涉及到多个因素,包括 epoch 数、全局 batch size、微 batch size、计算设备数量等。下面是一个基本的公式来说明这些参数之间的关系(注意,这只是一个基本的说明公式,主要说明比例和反比例关系,实际训练可能还需要考虑更多因素):

他们之中-
- 时期是指模型处理整个训练数据集的次数。
- 样本总数是训练数据集中的样本总数。
- 全局批次大小是每次训练迭代中处理的数据样本总数。
- Time per Step 是每次训练迭代所需的时间,取决于硬件性能、模型复杂度、优化算法等因素。
- 设备数量是用于训练的计算设备的数量,例如 GPU 的数量。
此公式提供了一个基本框架,但请注意,实际训练时间可能受到许多其他因素的影响,包括 I/O 速度、网络延迟(对于分布式训练)、CPU-GPU 通信速度、GPU 训练期间硬件故障的频率 等。因此,此公式只能作为粗略估计,实际训练时间可能会有所不同。
详细解释
深度学习模型的训练时间由多种因素决定,包括但不限于以下因素:
- 周期数:周期表示模型处理了整个训练数据集一次。周期越多,模型需要处理的数据越多,因此训练时间越长。
- 全局批大小:全局批大小是每次训练迭代中处理的数据样本总数。全局批大小越大,每次迭代处理的数据越多,这可能会减少每个时期所需的迭代次数,从而缩短总训练时间。但是,如果全局批大小过大,可能会导致内存溢出。
- 微批次大小:微批次大小是指每个计算设备在每次训练迭代中处理的数据样本数量。微批次大小越大,每个设备每次迭代处理的数据越多,这可以提高计算效率,从而缩短训练时间。但是,如果微批次大小过大,可能会导致内存溢出。
- 硬件性能:所使用的计算设备(如 CPU、GPU)的性能也会影响训练时间。更强大的设备可以更快地进行计算,从而缩短训练时间。
- 模型复杂度:模型的复杂度(例如层数、参数数量等)也会影响训练时间。模型越复杂,需要的计算量就越多,因此训练时间越长。
- 优化算法:所使用的优化算法(例如 SGD、Adam 等)和学习率等超参数设置也会影响训练时间。
- 并行策略:数据并行、模型并行等并行计算策略的采用也会影响训练时间。
决定训练时间长短的因素有很多,需要根据具体的训练任务和环境综合考虑。
所以,在这个公式中
![]()
- 硬件性能:所使用的计算设备(如 CPU、GPU)的性能将直接影响每次训练迭代的速度。功能更强大的设备可以更快地执行计算。
- 模型复杂度:模型的复杂度(例如层数、参数数量等)也会影响每次训练迭代的时间。模型越复杂,所需的计算量就越大。
- 优化算法:所使用的优化算法(例如 SGD、Adam 等)也会影响每次训练迭代的时间。某些优化算法可能需要更复杂的计算步骤来更新模型参数。
- 训练时使用的数据类型:训练时使用的不同数据类型对每步时间有显著影响。数据类型包括FP32,FP/BF16,FP8等。
训练步骤

全局批次大小
那么,什么决定了全局批次大小?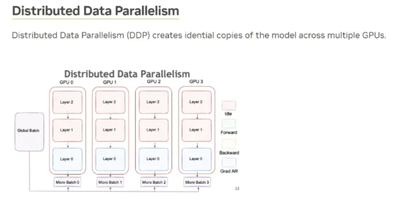
<span style="color:#333333"><span style="background-color:#ffffff"><span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">global_batch_size <span style="color:#00e0e0">=</span>
gradient_accumulation_steps
<span style="color:#00e0e0">*</span> nnodes (node mumbers)
<span style="color:#00e0e0">*</span> nproc_per_node (GPU <span style="color:#00e0e0">in</span> one node)
<span style="color:#00e0e0">*</span> per_device_train_batch_si(micro bs size) </code></span></span></span></span><span style="color:#333333"><span style="background-color:#ffffff"><span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">batch_size <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">10</span> <span style="color:#d4d0ab"># Batch size </span>
total_num <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">1000</span> <span style="color:#d4d0ab"># Total number of training data </span></code></span></span></span></span>当训练一批数据,更新一次梯度时(梯度累积步数=1):
<span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">train_steps <span style="color:#00e0e0">=</span> total_num <span style="color:#00e0e0">/</span> batch_size <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">1000</span> <span style="color:#00e0e0">/</span> <span style="color:#00e0e0">10</span> <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">100</span> </code></span></span>
这意味着每个 epoch 有 100 个步骤,梯度更新步骤也是 100。
当内存不足以支持 10 的批大小时,我们可以使用梯度累积来减少每个微批的大小。假设我们将梯度累积步骤设置为 2:
<span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">gradient_accumulation_steps <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">2</span>
micro_batch_size <span style="color:#00e0e0">=</span> batch_size <span style="color:#00e0e0">/</span> gradient_accumulation_steps <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">10</span> <span style="color:#00e0e0">/</span> <span style="color:#00e0e0">2</span> <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">5</span> </code></span></span>
这意味着对于每次梯度更新,我们从 2 个微批次中累积数据,每个微批次大小为 5。这减少了内存压力,但每次梯度更新的数据大小仍然是 10 个数据点。
结果:
- 每个时期的训练步数(train_steps)保持为 100,因为数据总量和每个时期的步数都没有改变。
- 梯度更新步骤保持为 100,因为每次梯度更新都会累积来自 2 个微批次的数据。
需要注意的是,使用梯度累积时,每个训练步骤都会处理来自多个微批次的梯度的累积,这可能会稍微增加每个步骤的计算时间。因此,如果内存足够,最好增加批次大小以减少梯度累积的次数。当内存不足时,梯度累积是一种有效的方法。
全局批次大小会显著影响模型的训练效果。通常,较大的全局批次大小可以提供更准确的梯度估计,有助于模型收敛。然而,它也会增加每个设备的内存压力。如果内存资源有限,使用较大的全局批次大小可能不可行。
在这种情况下,可以使用梯度累积。通过在每个设备上使用较小的微批次大小进行训练,我们可以减少内存压力,同时保持较大的全局批次大小以获得准确的梯度估计。这允许在有限的硬件资源上训练大型模型,而不会牺牲全局批次大小。
总之,梯度累积是在内存资源有限的情况下平衡全局批次大小和训练效果的一种权衡策略。
因此,如果我们看一下这两个公式:
![]()
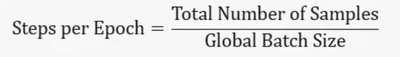
全局batch size越大,在不发生OOM(Out of Memory)且没有充分利用GPU计算能力的前提下,总的训练时间越短。
数据并行和批次大小的关系
本节主要分析一下这个公式:
<span style="color:#333333"><span style="background-color:#ffffff"><span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">global_batch_size <span style="color:#00e0e0">=</span>
gradient_accumulation_steps
<span style="color:#00e0e0">*</span> nnodes (The <span style="color:#abe338">number</span> <span style="color:#00e0e0">of</span> nodes <span style="color:#00e0e0">is</span><span style="color:#fefefe">,</span> <span style="color:#00e0e0">in</span> effect<span style="color:#fefefe">,</span> <span style="color:#00e0e0">the</span> PP)
<span style="color:#00e0e0">*</span> nproc_per_node (The <span style="color:#abe338">number</span> <span style="color:#00e0e0">of</span> cards per node <span style="color:#00e0e0">is</span><span style="color:#fefefe">,</span> <span style="color:#00e0e0">in</span> effect<span style="color:#fefefe">,</span> <span style="color:#00e0e0">the</span> TP)
<span style="color:#00e0e0">*</span> per_device_train_batch_si(micro bs size) </code></span></span></span></span>在分布式深度学习中,数据并行是一种常见的策略。训练数据被分成多个小批量,并分布到不同的计算节点。每个节点都有模型的副本,并在其数据子集上进行训练,从而加快训练过程。
在每个训练步骤结束时,使用 AllReduce 操作同步所有节点的模型权重。AllReduce 会聚合来自所有节点的梯度并广播结果,从而允许每个节点更新其模型参数。
如果在单个设备上进行训练,则不需要 AllReduce,因为所有计算都发生在同一设备上。然而,在分布式训练中,尤其是在数据并行的情况下,AllReduce 或类似操作对于跨设备同步模型参数是必要的。
许多深度学习框架(例如 PyTorch、TensorFlow)使用 NVIDIA 的 NCCL 进行多 GPU 之间的通信。每个 GPU 在其数据子集上进行训练,并在每个步骤结束时使用 NCCL 的 AllReduce 同步模型权重。
虽然 AllReduce 在数据并行中很常用,但根据框架和策略,也可以采用其他 NCCL 操作。
数据并行 (DP) 和微批次大小相互关联。DP 涉及在多台设备上进行训练,每台设备处理一部分数据。微批次大小是每台设备每次迭代处理的样本数。使用 DP,原始批次大小被拆分为跨设备的微批次。如果没有 DP 或模型并行 (MP),微批次大小等于全局批次大小。使用 DP 或 MP,全局批次大小是所有微批次的总和。DP
可应用于单个服务器或跨多个服务器的多个设备。将 DP 设置为 8 表示在 8 台设备上进行训练,这些设备可以位于同一服务器上,也可以分布在多个服务器上。
管道并行 (PP) 是一种不同的策略,其中不同的模型部分在不同的设备上运行。在 PP 中将 DP 设置为 8 表示 8 台设备在每个管道阶段并行处理数据。
总之,DP 和 PP 可同时在单个服务器或跨多个服务器的设备上使用。
相关文章:
如何让人工智能训练更快
影响人工智能训练时间的因素 在深度学习训练中,训练时间的计算涉及到多个因素,包括 epoch 数、全局 batch size、微 batch size、计算设备数量等。下面是一个基本的公式来说明这些参数之间的关系(注意,这只是一个基本的说明公式&…...

linux/ubuntu国内镜像安装gitleaks敏感信息扫描工具教程及避坑点
1、背景 利用gitleaks扫描git仓库或者文件 GitHub上有比较详细的教程,但是由于每个人的安装环境不同,坑很多,网上能查到的有效信息也比较少。这里就以我坑很多的环境为例,捋一下步骤。 GitHub - gitleaks/gitleaks: Protect an…...
)
JavaScript高级程序设计基础(二)
二、语言基础 2.1语法 (简单的语法基础将在文章省略) 2.1.1严格模式 严格模式是一种不同的 JavaScript 解析和执行模型,不规范写法在这种模式下会被处理 只需在脚本开头加上"use strict" 也可以单独指定一个函数在严格模式下执…...

使用Spring Boot开发自习室预定系统
开发一个自习室预定系统涉及到用户管理、自习室管理、预定管理等功能。以下是使用Spring Boot开发自习室预定系统的步骤和关键点: 1. 需求分析 确定系统的基本需求,例如: 用户注册和登录管理员管理自习室信息用户浏览可用自习室用户预定自…...

最近读书总结
1《More Joel on Software》读后感【2024年8月29日】 1.1 本书概要 本书讲解了如何发现优秀的IT人才,并把他们招聘进来;如何对智力密集型的IT企业(软件企业)进行管理,即最好采用情感认同法;对计算机大学生…...

python列表判断是否为空的三种方式
#列表是否为空判断 a[]一: if a:print(not null) else:print(null)二: b len(a) if b 0:print(null) else:print(not null)三: if not a:print(null) else:print(not null)运行结果:...

二十三种模式之原型模式(类比制作陶器更好理解一些)
1. 设计模式的分类 创建型模式(五种):工厂方法模式、单例模式、抽象工厂模式、原型模式、建造者模式。 结构型模式(七种):适配器模式、代理模式、装饰器模式、桥接模式、外观模式、享元模式、组合模式。 行为型模式(十一种):状态模式、模板方…...

9.9日记录
1.常见排序算法的复杂度 1.快速排序 1.1快速排序为什么快 从名称上就能看出,快速排序在效率方面应该具有一定的优势。尽管快速排序的平均时间复杂度与“归并排序”和“堆排序”相同,但通常快速排序的效率更高,主要有以下原因。 出现最差情况…...
鸿蒙交互事件开发04——手势事件
1 概 述 手势事件是移动应用开发中最常见的事件之一,鸿蒙提供了一些方法来绑定手势事件。通过给各个组件绑定不同的手势事件,并设计事件的响应方式,当手势识别成功时,ArkUI框架将通过事件回调通知组件手势识别的结果。 …...

研1日记9
1.理解conv1d和conv2d a. 1和2处理的数据不同,1维数据和图像 b. 例如x输入形状为(32,19,512)时,卷积公式是针对512的,而19应该变换为参数中指定的输出通道。 2.“SE块”(Squeeze-and-Excitation Block)它可以帮助模…...

HAL库学习目录查询表
日期内容2024.09.11基于STM32C8T6的CubeMX:HAL库点亮LED2024.09.11STMCuBeMX新建项目的两种匪夷所思的问题2024.09.11STMCubeMX文件下载后会出现其他项目无法下载的问题...

pandas DataFrame日期字段数据处理
pandas DataFrame日期字段数据处理 1、pandas读取表格文件日期字段存入数据库不需要时分秒 在使用 pandas 读取表格文件,并将日期字段存入数据库时,如果你只关心日期部分而不需要时分秒,可以通过以下步骤来处理: 读取数据并转换日期字段: 首先,你需要读取你的数据,并确…...

swift:qwen2 VL 多模态图文模型lora微调swift
参考: https://swift.readthedocs.io/zh-cn/latest/Multi-Modal/qwen2-vl%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5.html 在线demo: https://colab.research.google.com/drive/16yl6Z0wxHLX3qJ5q-SIbvPn251k3r2JC?usp=sharing 安装: !git clone https://github.com/modelsc…...

Vue.js中computed的使用方法
在Vue.js中,computed 属性是基于它们的依赖进行缓存的响应式属性。只有当相关依赖发生改变时,才会重新求值。这意味着只要computed属性依赖的源数据(如data中的属性)没有发生变化,多次访问computed属性会立即返回之前的…...

python之pyecharts制作可视化数据大屏
文章目录 前言一、安装 Pyecharts二、创建 Pyecharts 图表三、设计大屏布局四、实时数据更新五、部署和展示总结前言 使用 Pyecharts 制作可视化数据大屏是一个复杂但有趣的过程,因为 Pyecharts 本身是一个用于生成 Echarts 图表的 Python 库,而 Echarts 是由百度开发的一个…...

Chrome、Edge、360及Firefox浏览器加载多个ActiveX插件的介绍
allWebPlugin简介 allWebPlugin中间件是一款为用户提供安全、可靠、便捷的浏览器插件服务的中间件产品,致力于将浏览器插件重新应用到所有浏览器。它将现有ActiveX控件直接嵌入浏览器,实现插件加载、界面显示、接口调用、事件回调等。支持Chrome、Firefo…...

裸金属服务器与云服务器的区别有哪些?
随着云计算服务的快速发展,云服务器与裸金属服务器则称为各大企业基础设施的两大核心选择,会运用在不同的场景当中,本文就来介绍一下裸金属服务器与云服务器的区别都有哪些吧! 裸金属服务器相对于云服务器来说有着卓越的性能&…...

Pr:序列设置 - VR 视频
在“新建序列”对话框的“VR 视频” VR Video选项卡,或者在“序列设置”对话框的“VR 属性” VR Properties选项卡中,允许用户创建和编辑虚拟现实 (VR) 视频序列。 VR 视频能够提供 360 沉浸式的观看体验,通常使用专门的相机进行拍摄…...

采用qt做一个命令行终端
qt做一个类似系统命令行终端的工具,方便集成到自己的软件里使用,这样能保证软件的整体性,而且是真正的做到和系统命令行终端一样的交互方式,而不是单独搞个编辑框的方式输入命令(大部分博客都是做成这个样子࿰…...

TQA相关
ReAct Prompting: 原理、实现与应用 ReAct Prompting(推理与行动提示)是一种引导大型语言模型(LLM)进行推理和行动的策略,广泛应用于复杂问题求解、对话生成和自动化任务等领域。ReAct Prompting 通过将模型的思考过程…...

从STM32F103到GD32F303:如何用CubeMX和Keil5低成本‘平替’升级你的项目?
从STM32F103到GD32F303:低成本高性能迁移实战指南 在嵌入式开发领域,芯片选型往往需要在性能与成本之间寻找平衡点。对于已经熟悉STM32F103系列开发但面临成本压力或性能瓶颈的工程师来说,GD32F303系列提供了一个极具吸引力的替代方案。这款国…...
深度解析:如何让你的飞控代码轻松跑在不同芯片上?)
ArduPilot硬件抽象层(HAL)深度解析:如何让你的飞控代码轻松跑在不同芯片上?
ArduPilot硬件抽象层(HAL)深度解析:跨平台飞控开发实战指南 当开发者尝试将ArduPilot移植到一块全新的飞控板时,最常遇到的挑战莫过于如何让同一套控制算法在不同硬件架构上无缝运行。这正是硬件抽象层(HAL)设计的精妙之处——它如同一位技艺高超的翻译官…...

雀巢冰淇淋在华投资的首家冰淇淋工厂迎来成立40周年 | 美通社头条
、美通社消息:近日,雀巢冰淇淋华南生产基地 —— 广州冷冻食品有限公司迎来成立40周年。该工厂是雀巢冰淇淋在华投资的首家冰淇淋工厂,陪伴一代代华南消费者成长的经典甜筒、飞鱼脆皮等产品皆出自广冻厂。1986年,在改革开放的时代…...

番茄小说下载器终极指南:如何轻松下载EPUB、TXT和有声小说
番茄小说下载器终极指南:如何轻松下载EPUB、TXT和有声小说 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾经在番茄小说上找到一部精彩的作品,…...

主流 RAG 架构与方法总结
一. 基础知识库RAG:Naive RAG / Standard RAG 1.1 架构流程 最基础,最常见的 RAG 架构。 文档上传 → 文档解析 → 文本切块 Chunking → Embedding 向量化 → 写入向量库 / 搜索索引 → 用户提问 → 向量检索 Top-K → 拼接上下文 → LLM 生成答案 …...

5秒完成B站缓存视频转换:m4s到MP4无损转换完整指南
5秒完成B站缓存视频转换:m4s到MP4无损转换完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他…...

【致91岁的双胞胎】堡垒复习:3步搭建理科“作战地图”,告别零散刷题效率翻倍
很多学生长期陷入理科复习瓶颈:花费大量时间刷题、背书,成绩却始终原地踏步。核心根源只有一个:照搬文科的复习方式学理科。 文科复习侧重知识点记忆、框架梳理、素材积累,通用的A4纸整理法完全适用;但理科的核心是逻辑闭环、体系串联、题型落地、抗遗忘复盘,死记硬背、…...

从LMS到BLMS:自适应滤波的‘批处理’思想如何解决工程中的收敛难题?
从LMS到BLMS:批处理思想如何重塑自适应滤波的工程实践 在实时信号处理领域,工程师们常常面临一个经典困境:算法响应速度与系统稳定性能之间的微妙平衡。想象一下,当你正在调试一套语音降噪系统时,每次麦克风接收到一个…...

8051中断向量冲突与Keil调试问题解决方案
1. 问题现象与背景分析最近在调试基于MCBx51评估板的8051应用程序时,遇到了一个相当诡异的现象:原本在评估版上运行正常的程序,移植到实际硬件后出现了异常行为,甚至导致调试连接中断。最典型的错误提示就是"CONNECTION TO T…...

别再手动算日期了!SQL Server里DATEDIFF和DATEADD的5个实战场景,数据分析师必看
SQL Server日期处理实战:DATEDIFF与DATEADD的5个高阶应用场景 在数据分析与报表开发领域,时间维度永远是核心要素之一。无论是用户行为分析、业务指标计算还是系统自动化处理,精准的日期运算能力直接决定了数据价值的挖掘深度。作为SQL Serve…...